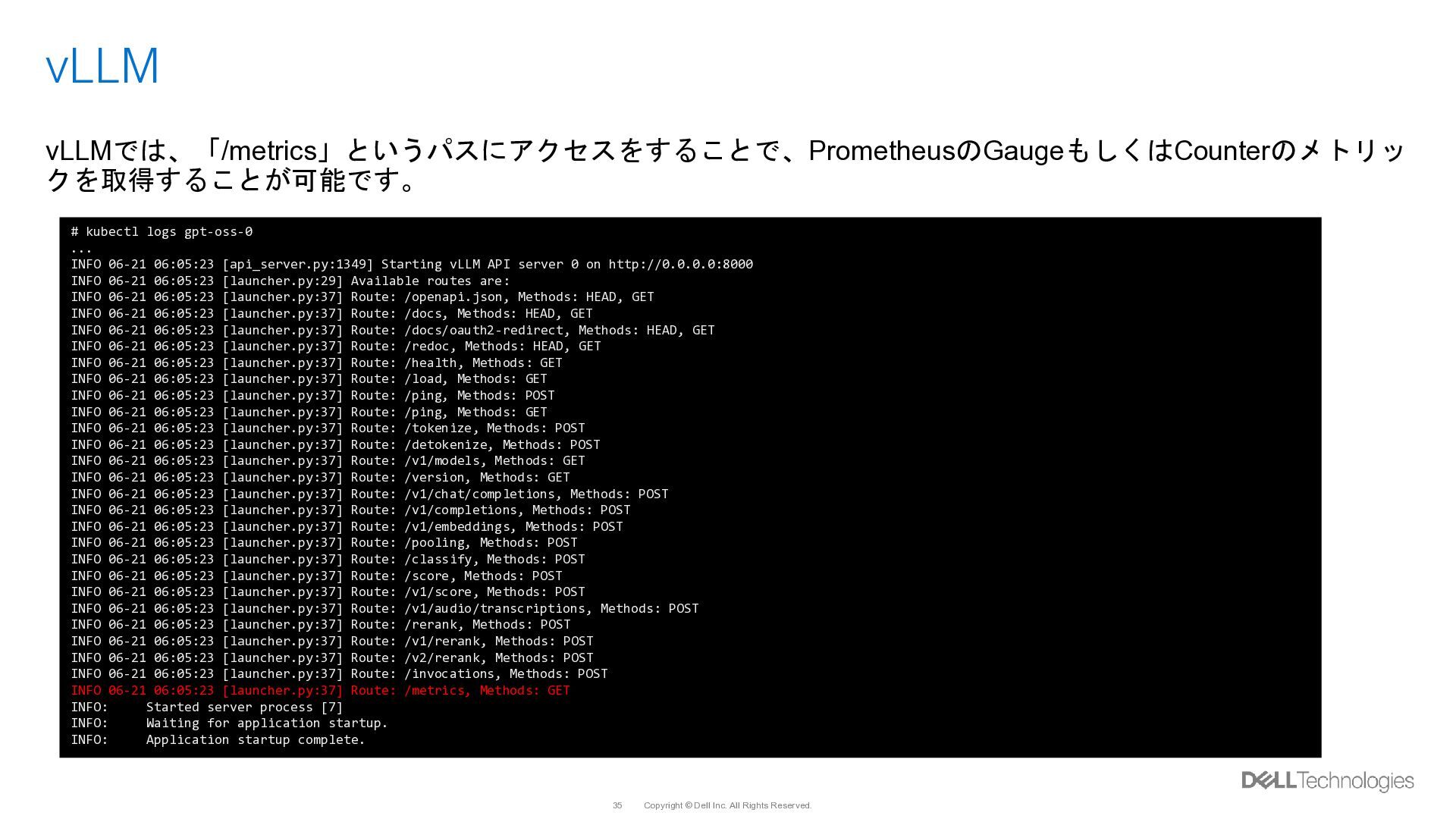
クを取得することが可能です。 # kubectl logs gpt-oss-0 ... INFO 06-21 06:05:23 [api_server.py:1349] Starting vLLM API server 0 on http://0.0.0.0:8000 INFO 06-21 06:05:23 [launcher.py:29] Available routes are: INFO 06-21 06:05:23 [launcher.py:37] Route: /openapi.json, Methods: HEAD, GET INFO 06-21 06:05:23 [launcher.py:37] Route: /docs, Methods: HEAD, GET INFO 06-21 06:05:23 [launcher.py:37] Route: /docs/oauth2-redirect, Methods: HEAD, GET INFO 06-21 06:05:23 [launcher.py:37] Route: /redoc, Methods: HEAD, GET INFO 06-21 06:05:23 [launcher.py:37] Route: /health, Methods: GET INFO 06-21 06:05:23 [launcher.py:37] Route: /load, Methods: GET INFO 06-21 06:05:23 [launcher.py:37] Route: /ping, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /ping, Methods: GET INFO 06-21 06:05:23 [launcher.py:37] Route: /tokenize, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /detokenize, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/models, Methods: GET INFO 06-21 06:05:23 [launcher.py:37] Route: /version, Methods: GET INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/chat/completions, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/completions, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/embeddings, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /pooling, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /classify, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /score, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/score, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/audio/transcriptions, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /rerank, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v1/rerank, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /v2/rerank, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /invocations, Methods: POST INFO 06-21 06:05:23 [launcher.py:37] Route: /metrics, Methods: GET INFO: Started server process [7] INFO: Waiting for application startup. INFO: Application startup complete.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
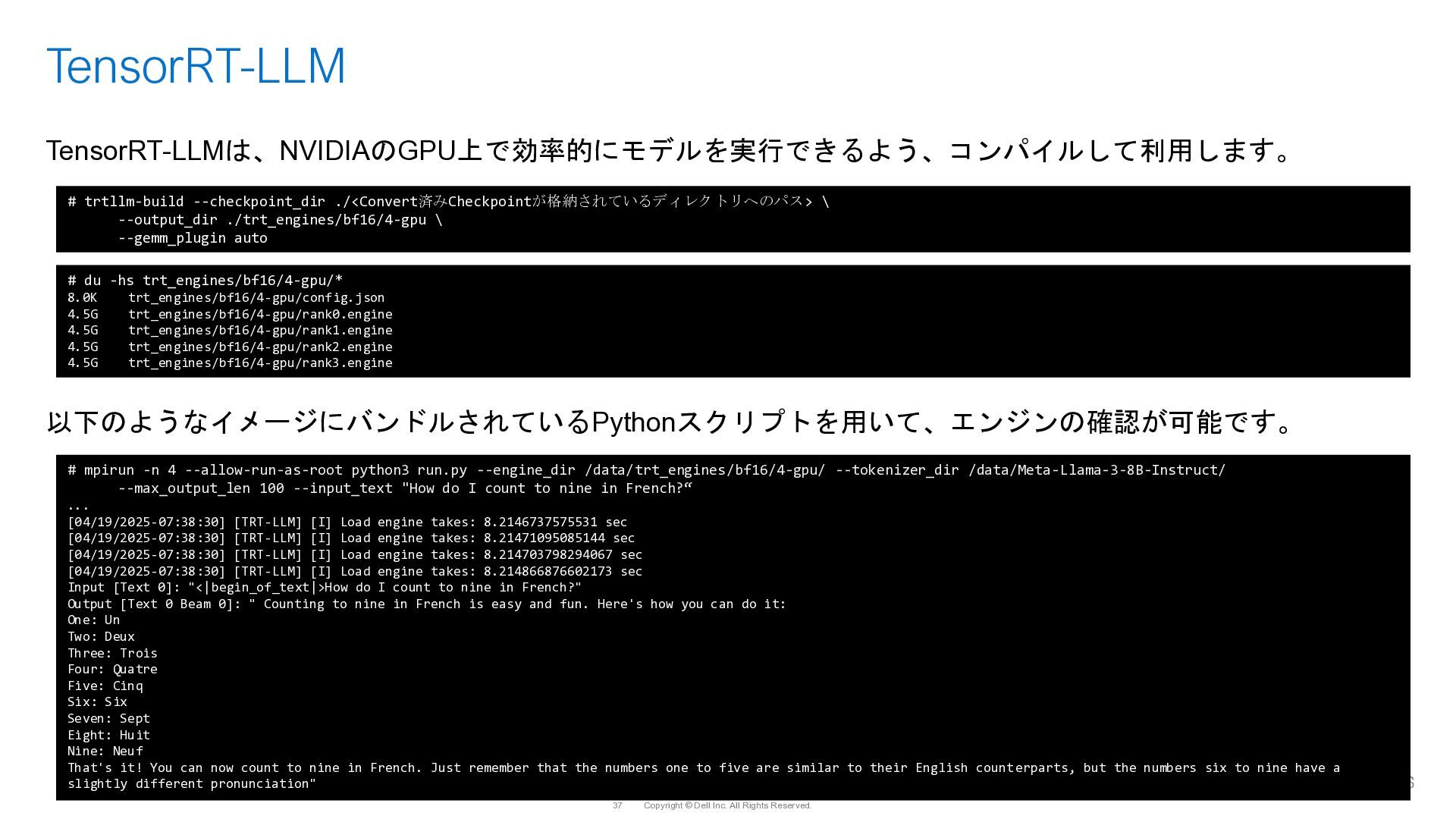{kind=link}
{kind=link}
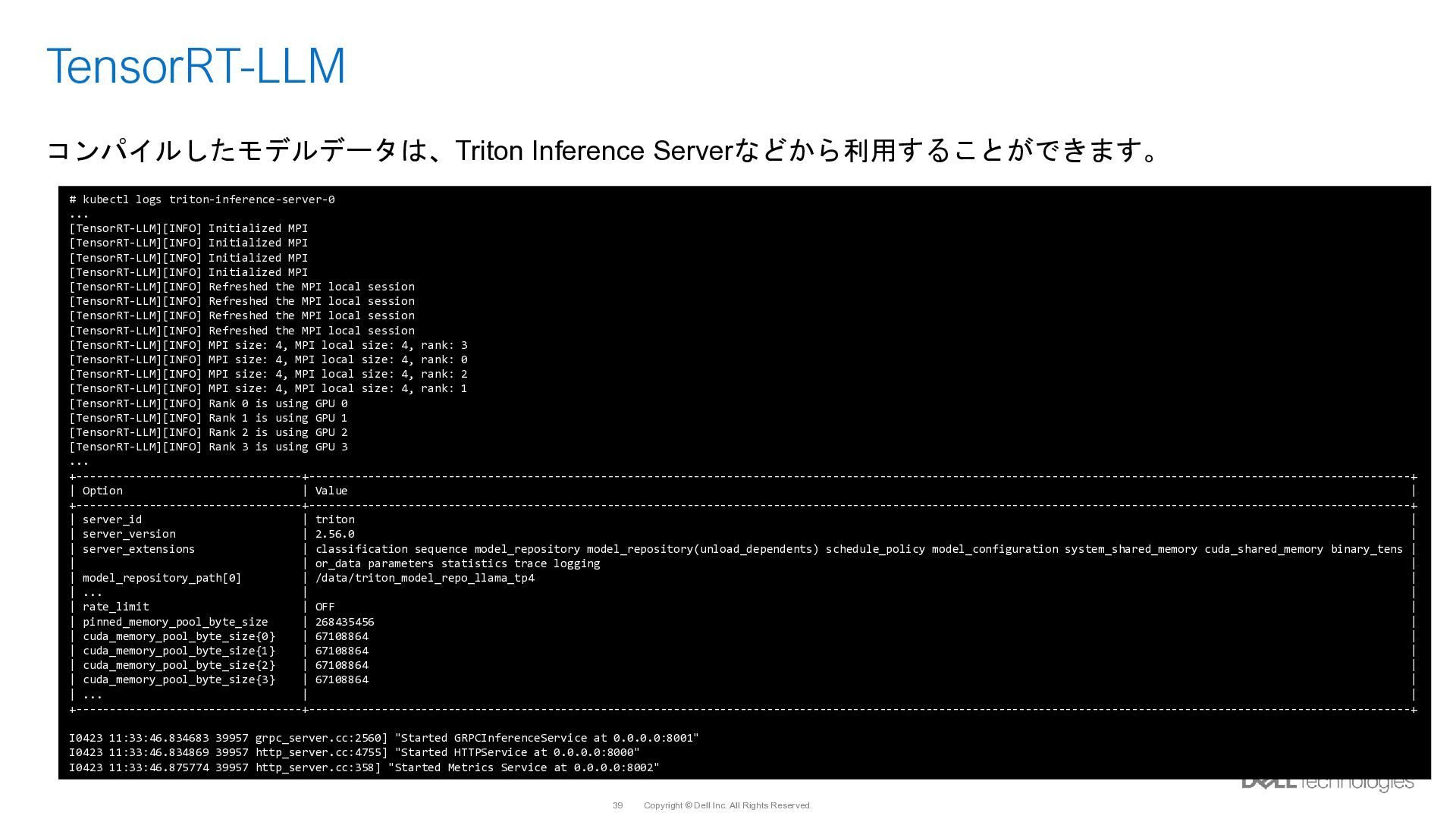{kind=link}
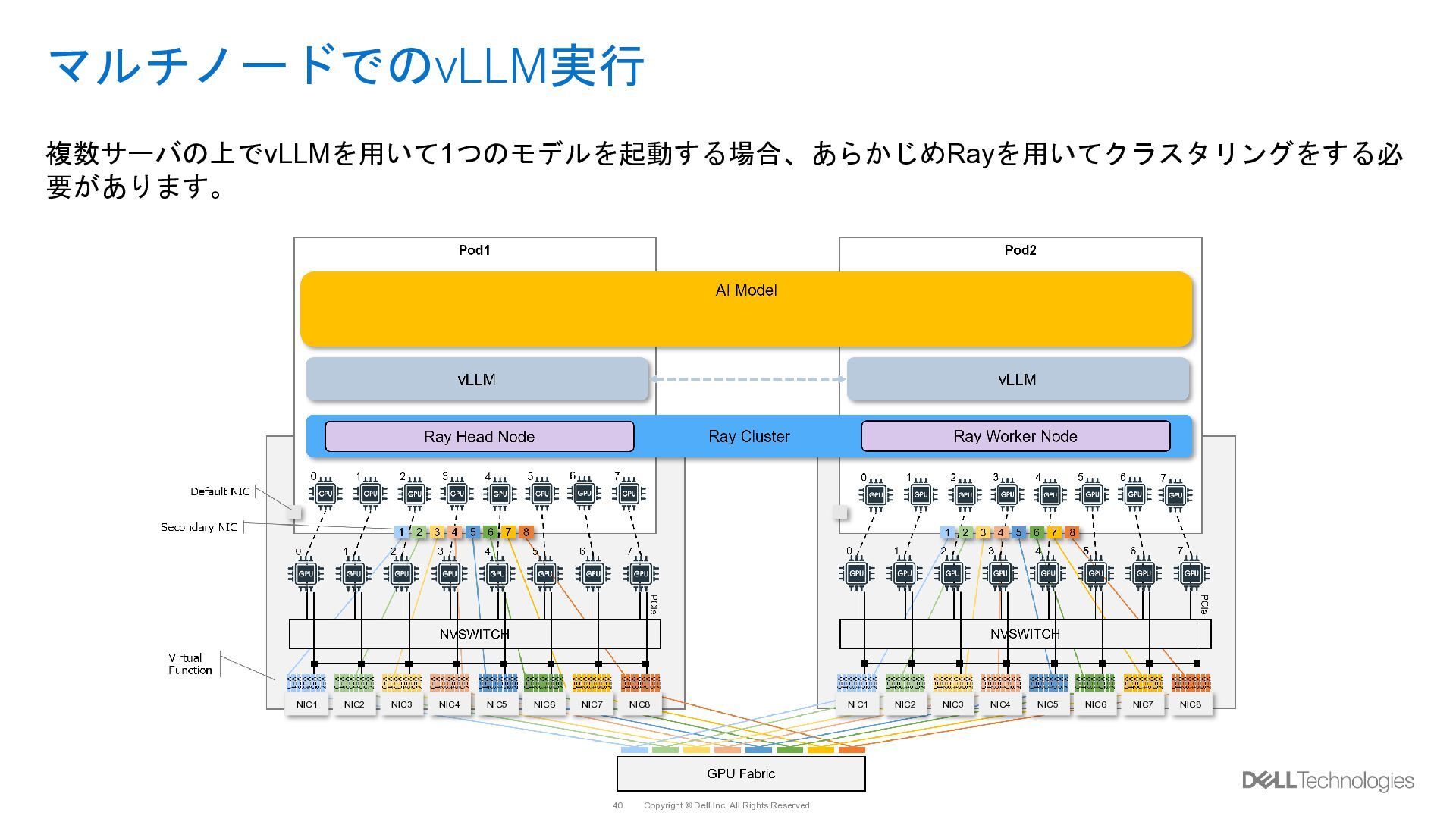{kind=link}
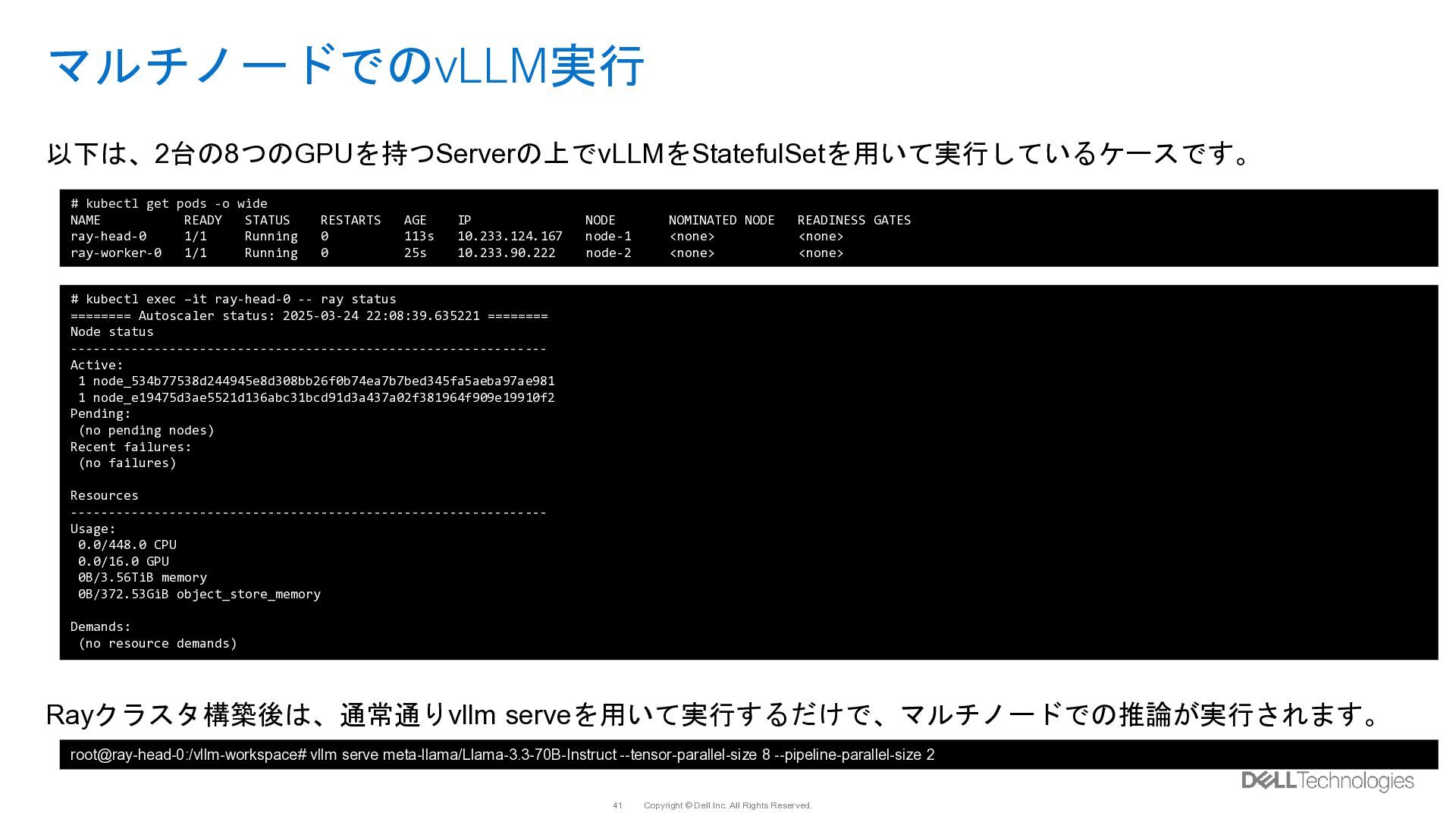{kind=link}
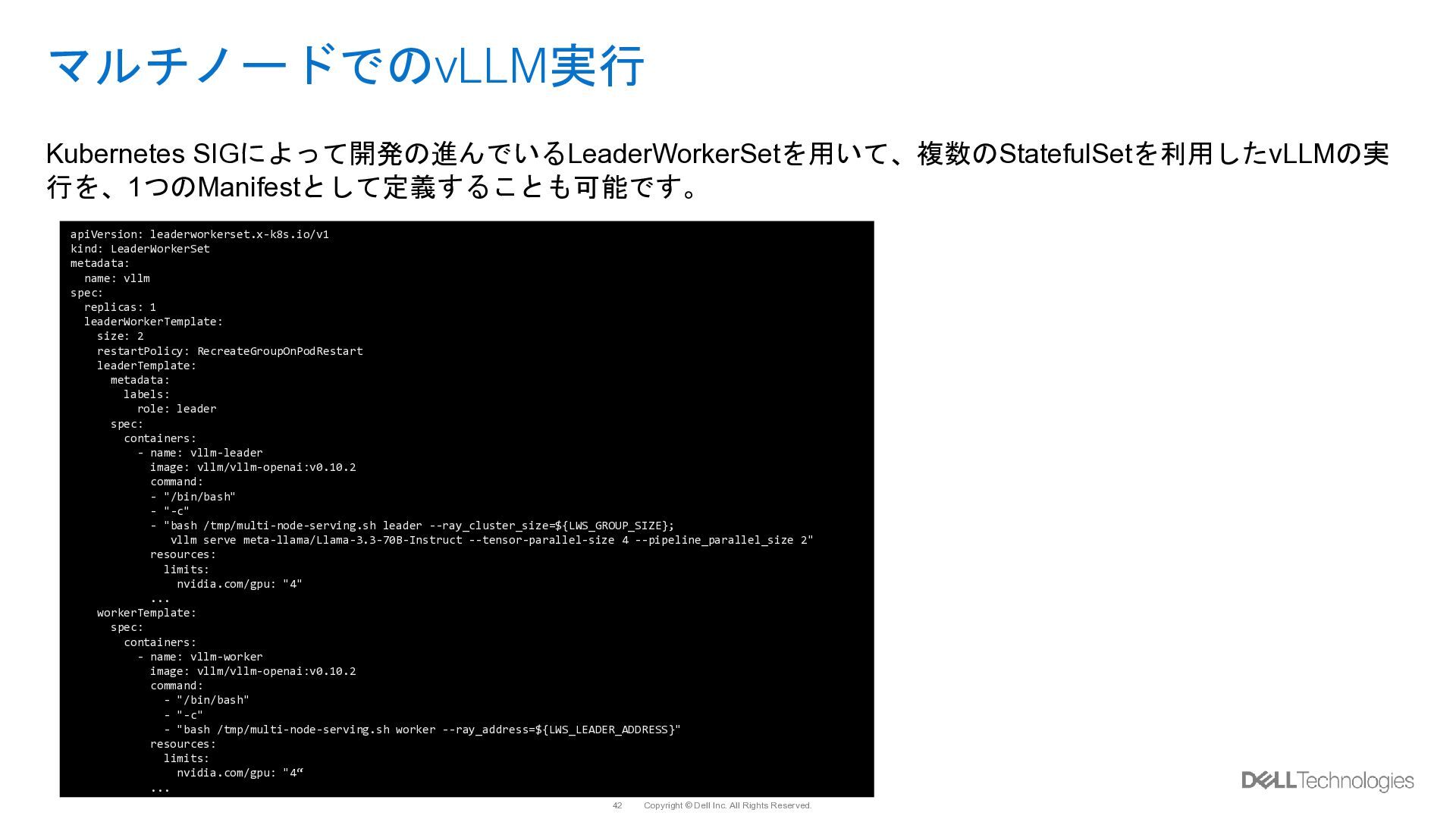{kind=link}
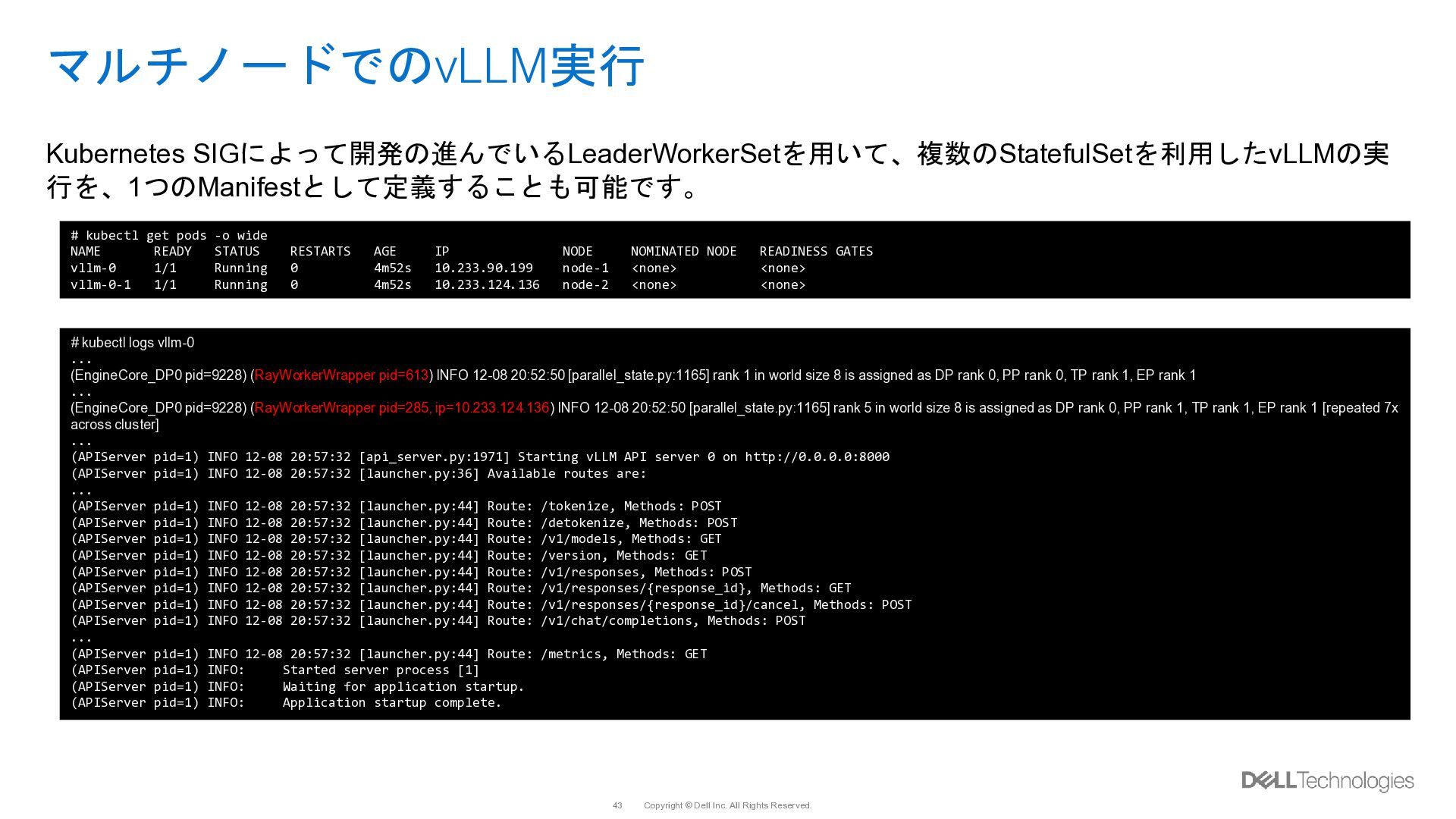{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
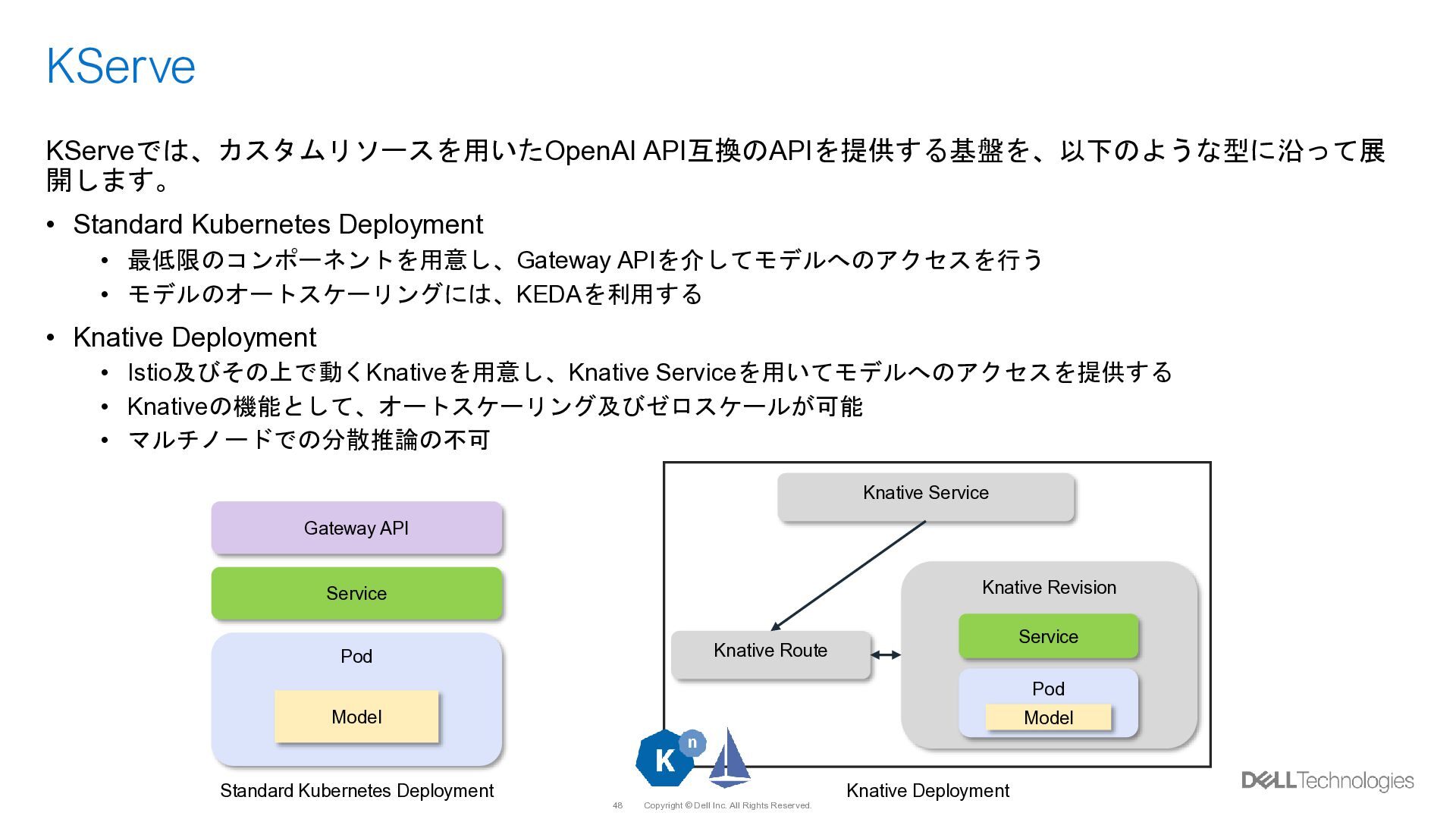{kind=link}
{kind=link}
{kind=link}
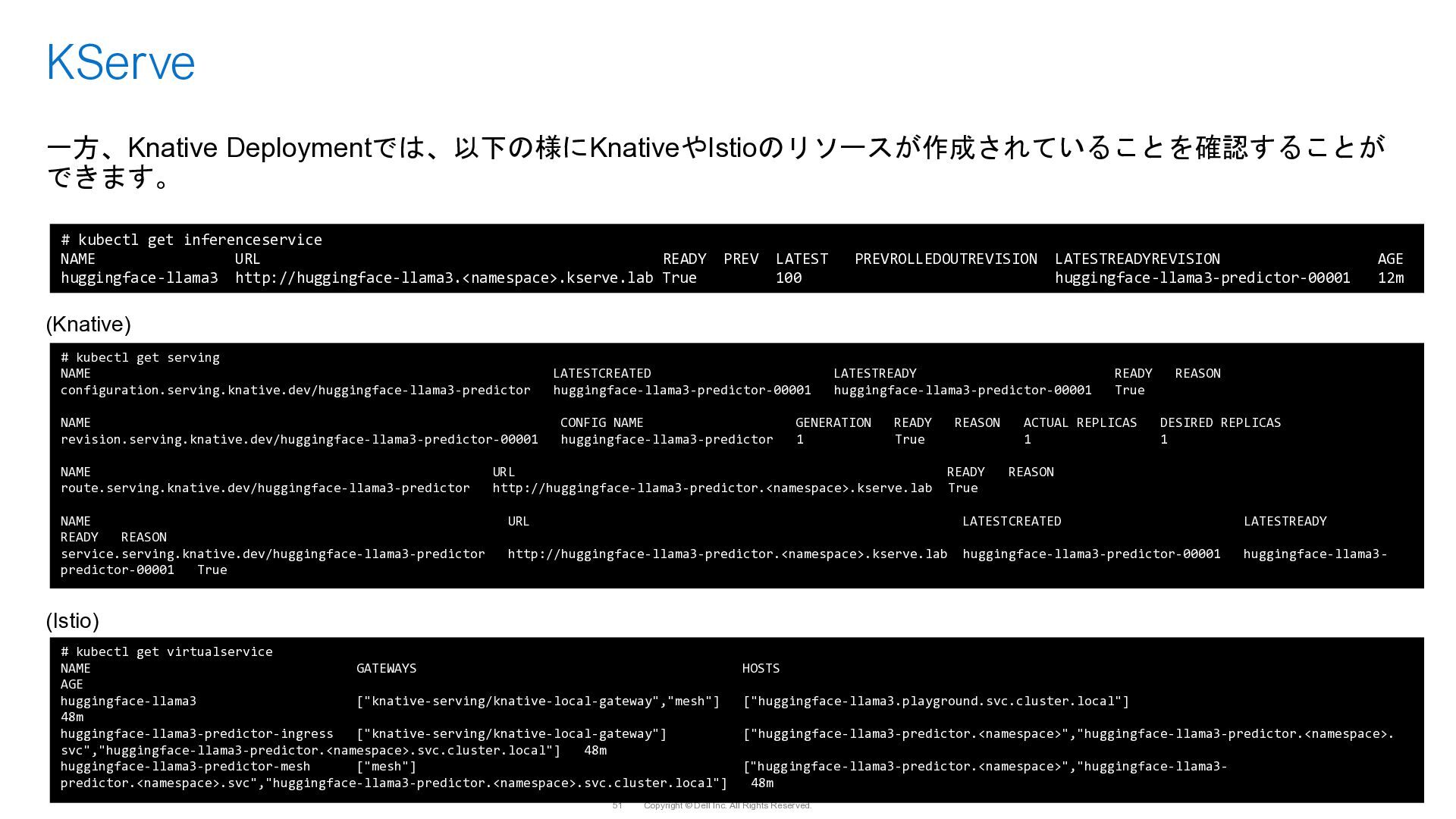{kind=link}
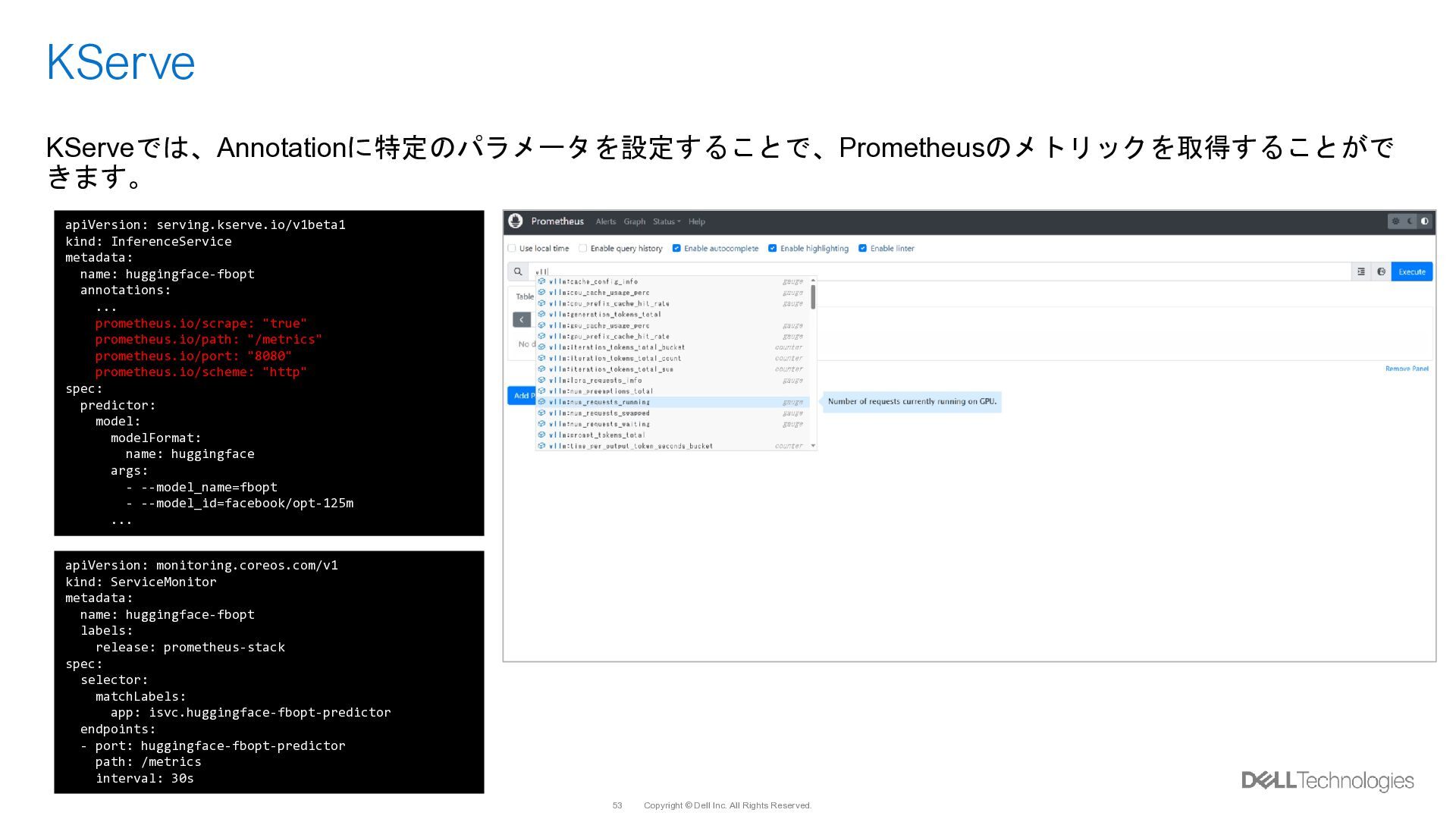{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
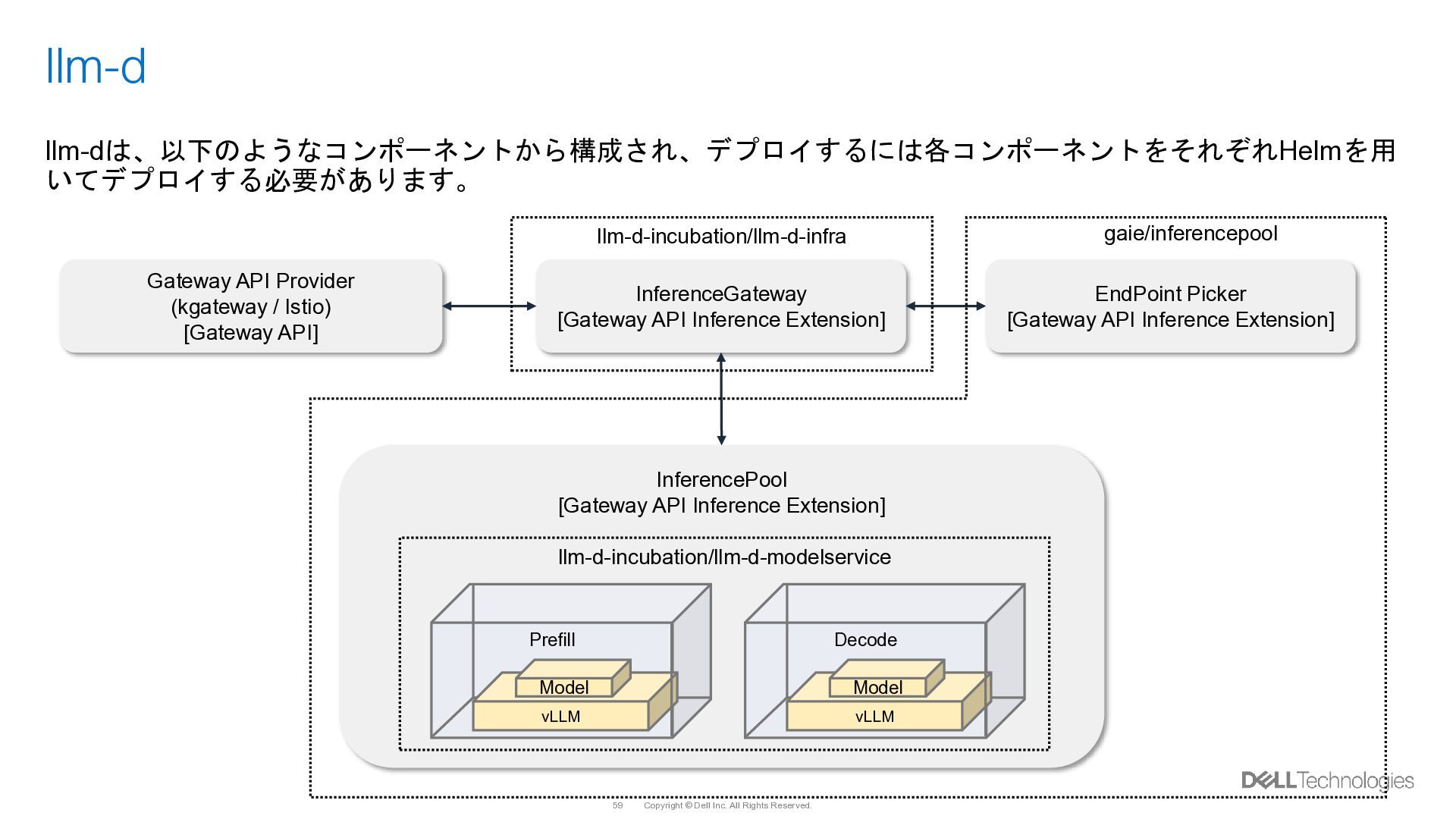{kind=link}
{kind=link}
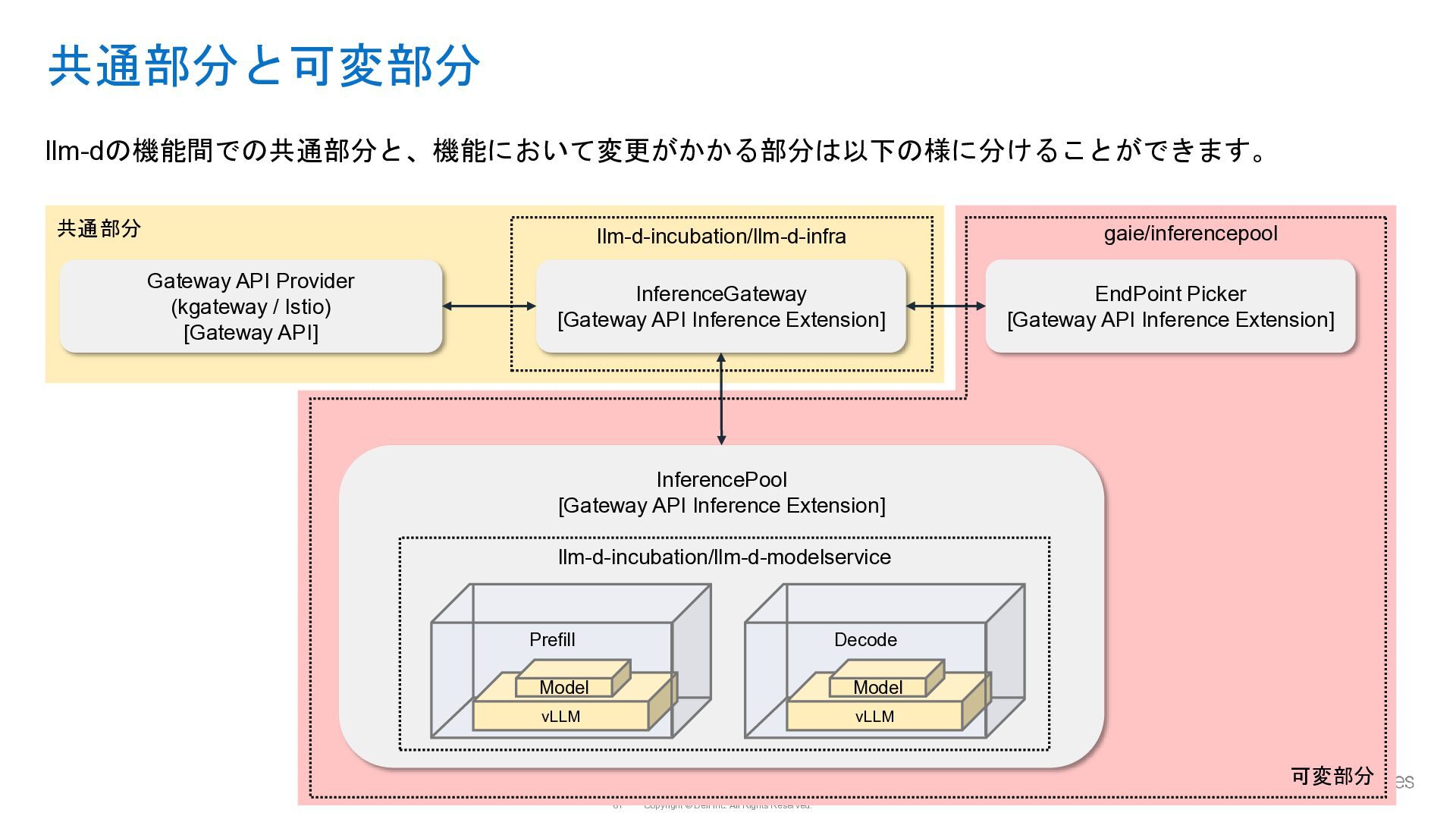{kind=link}
{kind=link}
{kind=link}
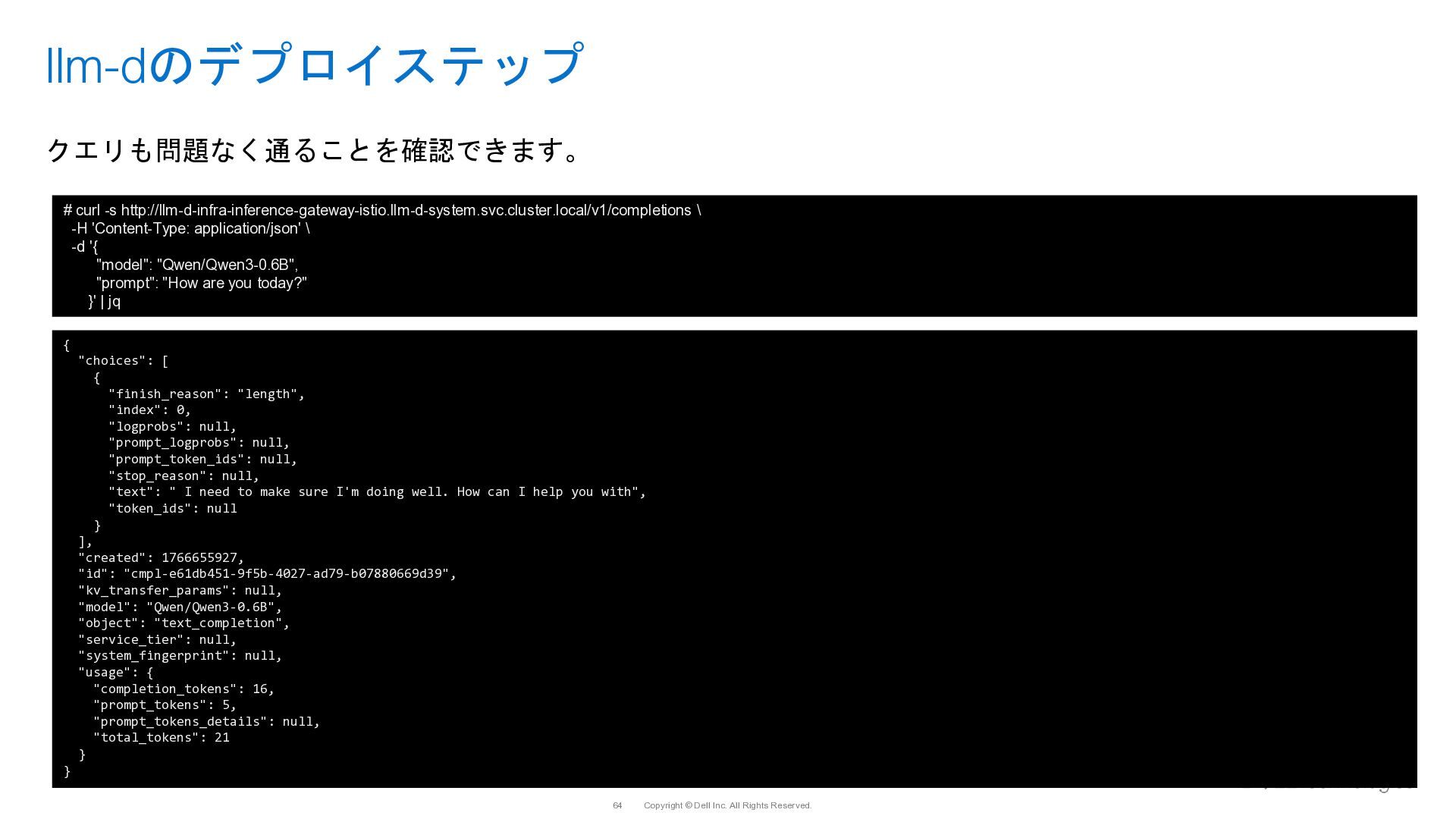{kind=link}
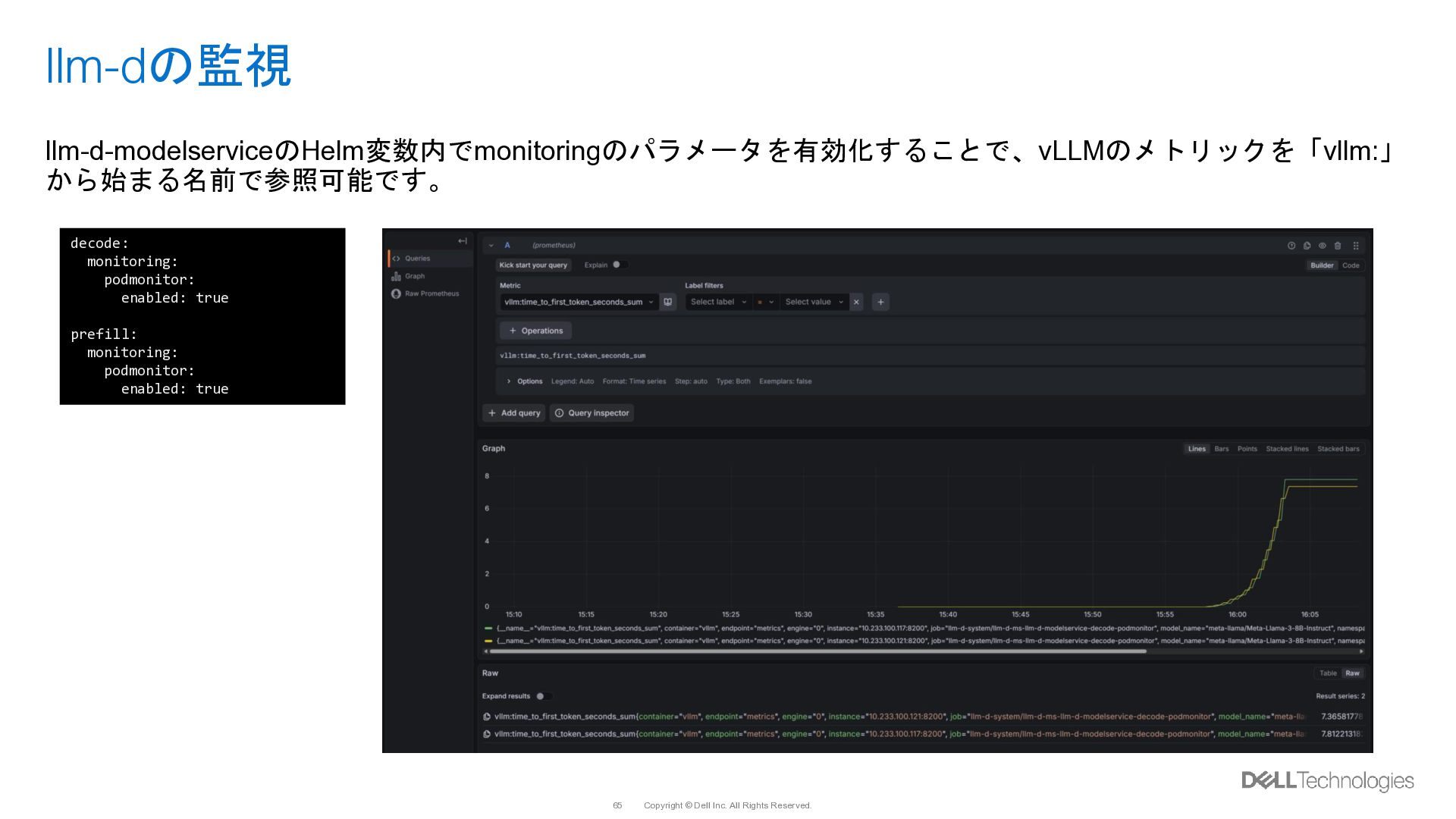{kind=link}
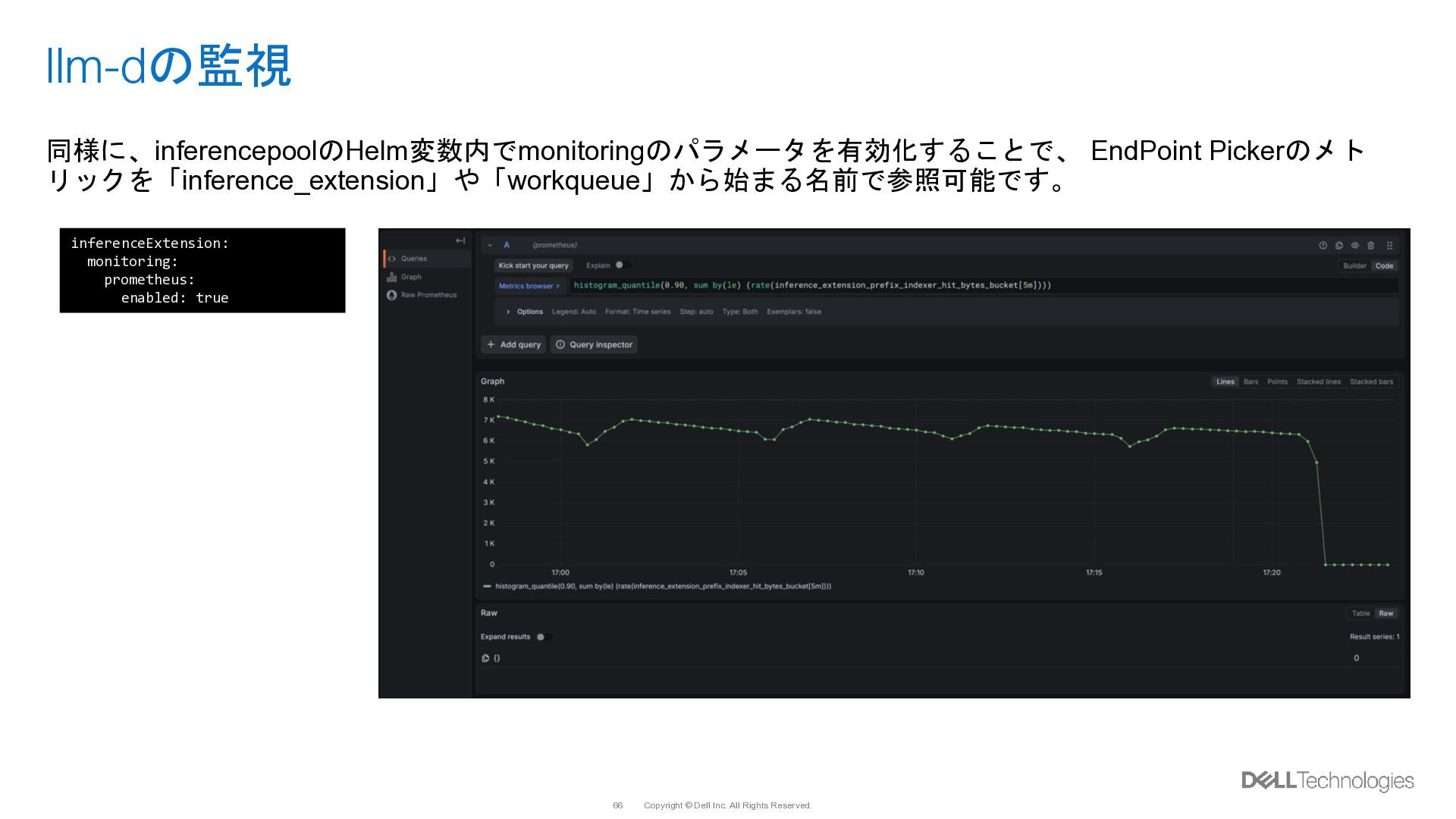{kind=link}
{kind=link}