:LLMコンペなどの エンジニアリング要素が強いコンペ Kaggle:@isakatsuyoshi GitHub:@Isaka-code Qiita :@Isaka-code X :@AInebosuke Opinions are my own. I just came here as a Kaggler. 2 LLM + DCAI Tabular + DCAI LLM + 🎅 LLM + ⛳ LLM + DCAI LLM + DCAI ※DCAI(Data-Centric AI):データ を起点にAIの性能を高めるアプローチ 一緒にチームを組んでくださった皆様 ありがとうございました!
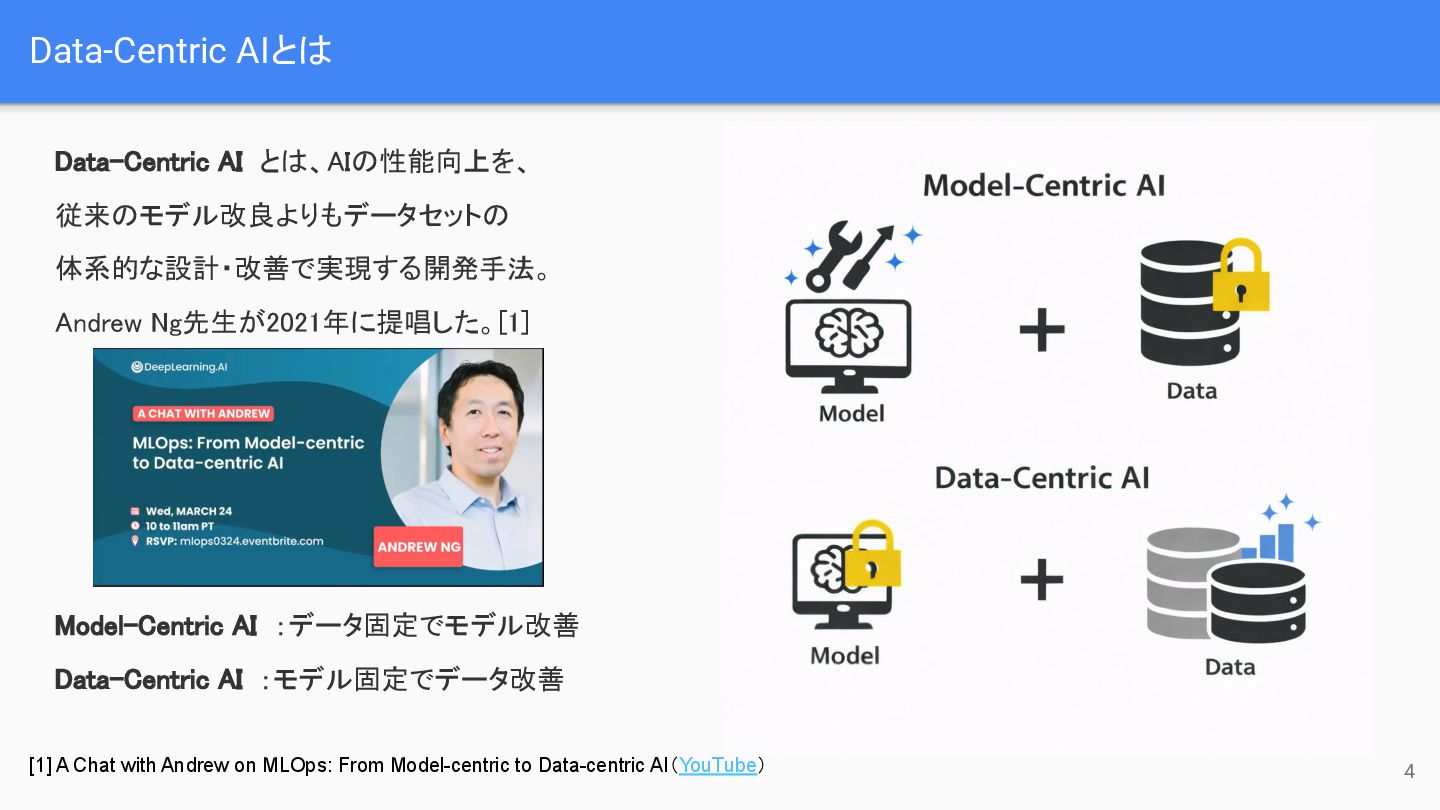
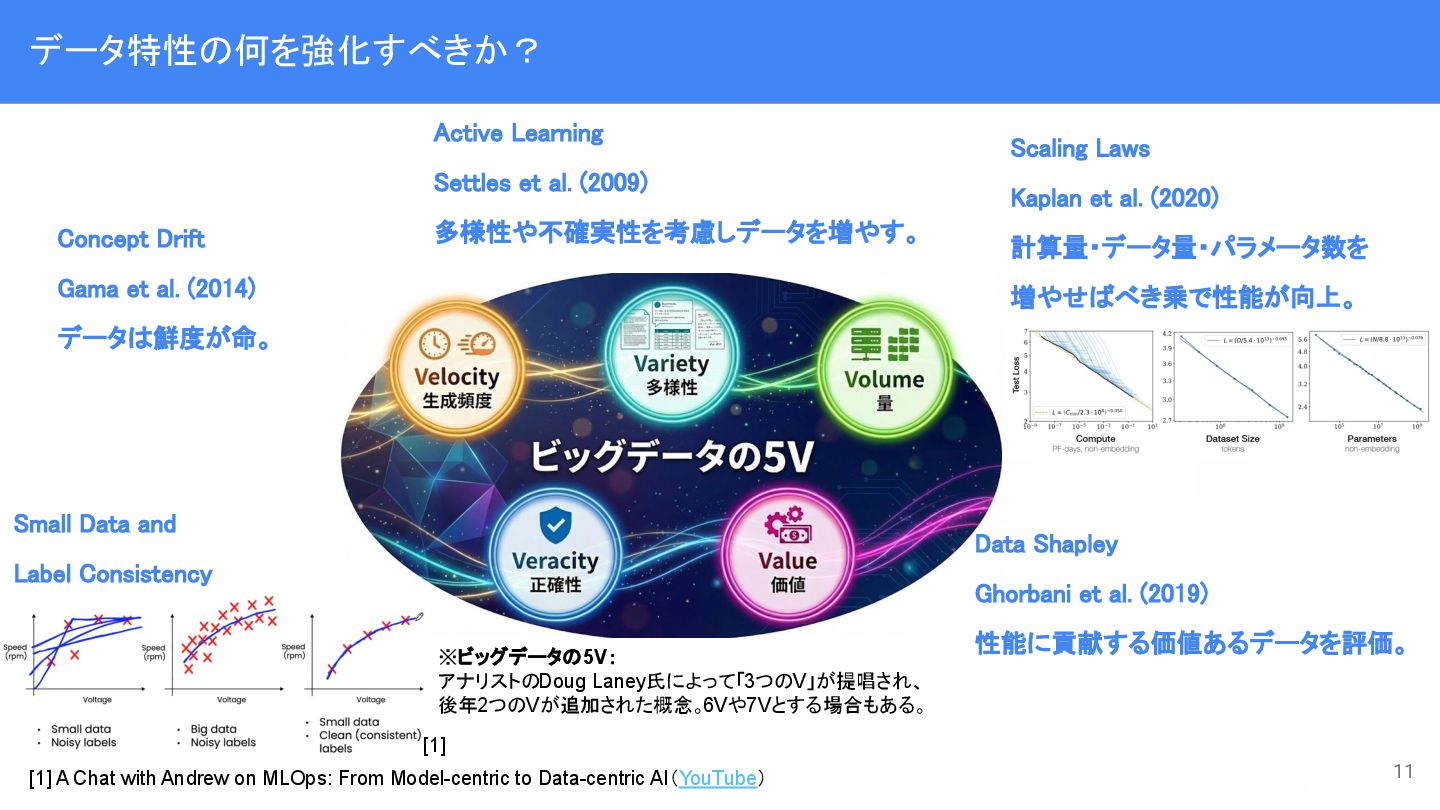
Andrew Ng先生が2021年に提唱した。[1] Model-Centric AI :データ固定でモデル改善 Data-Centric AI :モデル固定でデータ改善 4 [1] A Chat with Andrew on MLOps: From Model-centric to Data-centric AI(YouTube)
計算量・データ量・パラメータ数を 増やせばべき乗で性能が向上。 Data Shapley Ghorbani et al. (2019) 性能に貢献する価値あるデータを評価。 Concept Drift Gama et al. (2014) データは鮮度が命。 ※ビッグデータの5V: アナリストのDoug Laney氏によって「3つのV」が提唱され、 後年2つのVが追加された概念。 6Vや7Vとする場合もある。 [1] A Chat with Andrew on MLOps: From Model-centric to Data-centric AI(YouTube) [1] Small Data and Label Consistency Active Learning Settles et al. (2009) 多様性や不確実性を考慮しデータを増やす。
といったデータ拡張が可能なことがある。 ルールベースによるデータ拡張は、計算コストが軽量なため、 推論時にも適用可能 (Test Time Augmentation;TTA ) Kaggle - LLM Science Exam (LLMを活用して科学の多肢選択問題を解くコンペ) - 選択肢をシャッフルしTTAを行うことは自然な発想。ただし、それだけ推論時間が伸びてしまう。5位チーム は、{context} {Q} {A B C D E} {B C D E A} … {E A B C D} のように、全ての パターンをconcatすることで、推論を1回に減らし、Position Biasも緩和した。[2] [1] Li, Hou, Che (2021) Data Augmentation Approaches in Natural Language Processing: A Survey. arXiv:2110.01852. [2] https://www.kaggle.com/competitions/kaggle-llm-science-exam/writeups/preferred-chattykids-5th-place-solution-llama-2-70 スポーツデータ [1] ルールベースによるparaphrasingの例 ボードゲームデータ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
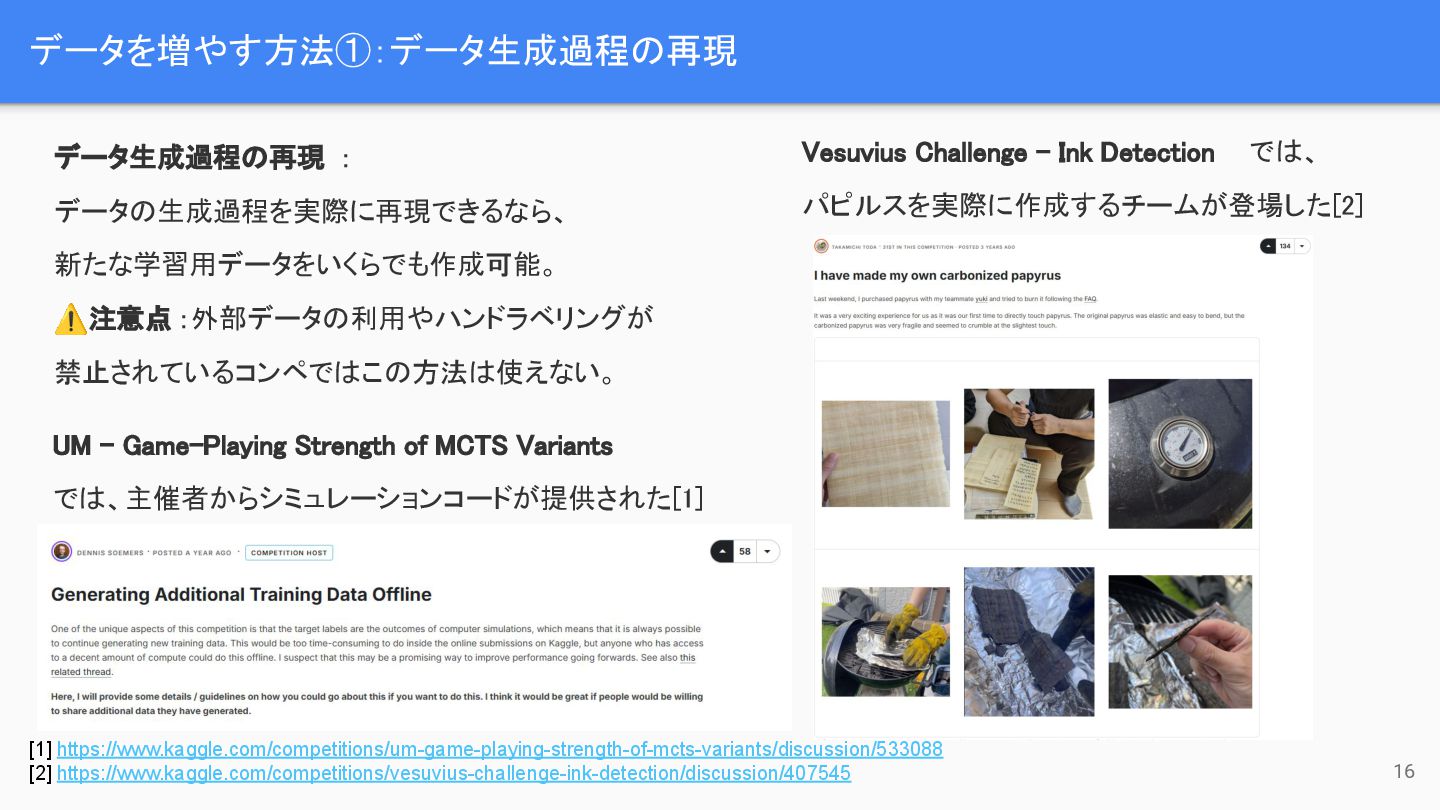
{kind=link}
{kind=link}
![Kaggle Winning Formula by ケロッピ先生(hengck23さん) 12 [1] [1] https://www.kaggle.com/competitions/neurips-open-polymer-prediction-2025/discussion/587564#3241637 NeurIPS](https://files.speakerdeck.com/presentations/78813c8a6b4b4a658453f66bc0463563/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
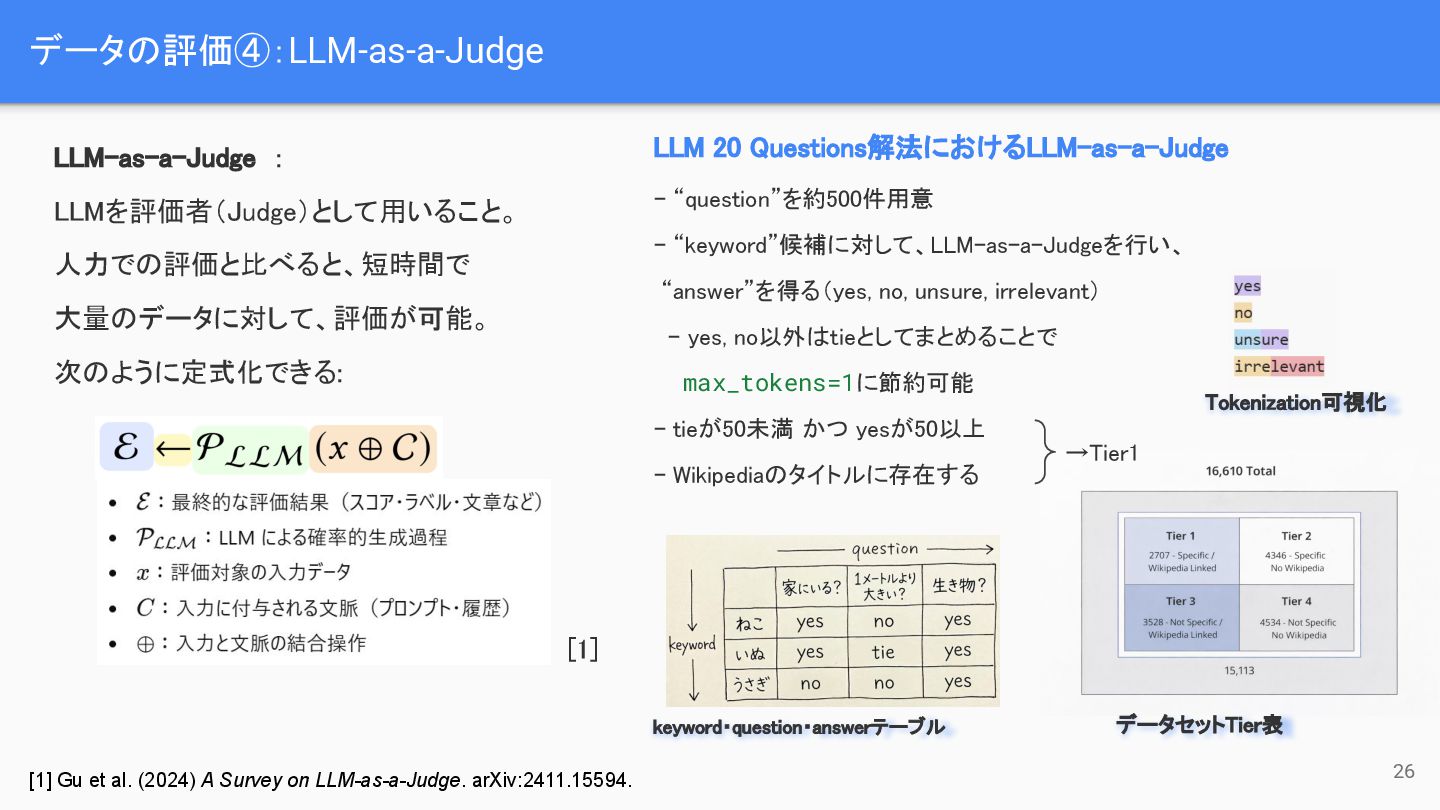{kind=link}
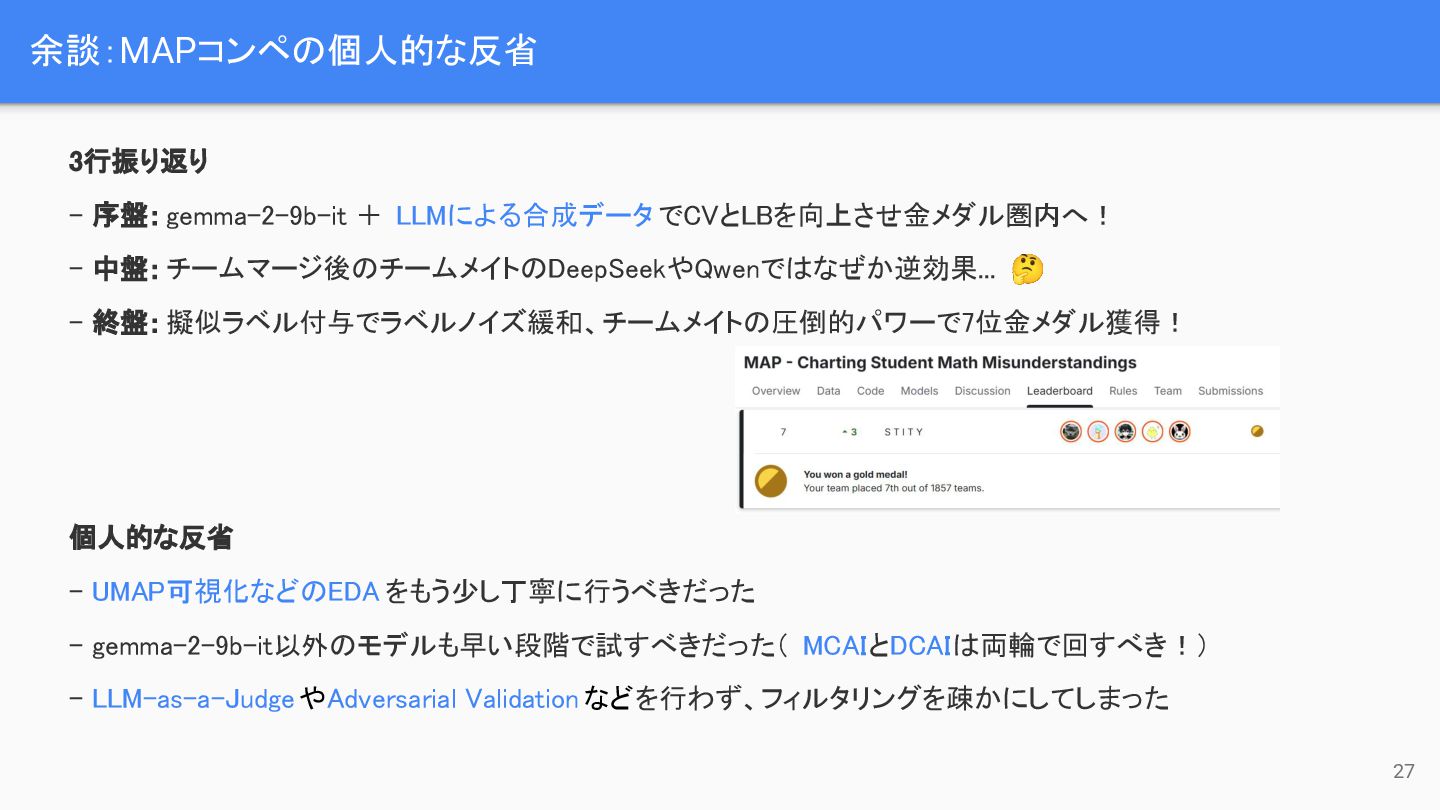{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}