ウォンテッドリー社内で数回に分けて発表した「文字コードの話」のスライドです。
2026/02/21: まだ埋めきれていない部分、出典の確認・整理が不十分な部分等がありますが、ちょうど文字コードが話題になっているので一旦アップロードしてしまいます。ご指摘歓迎です。
【未適用の修正項目】
・ DEL が想定している媒体は穿孔カードではなく鑽孔テープと思われる
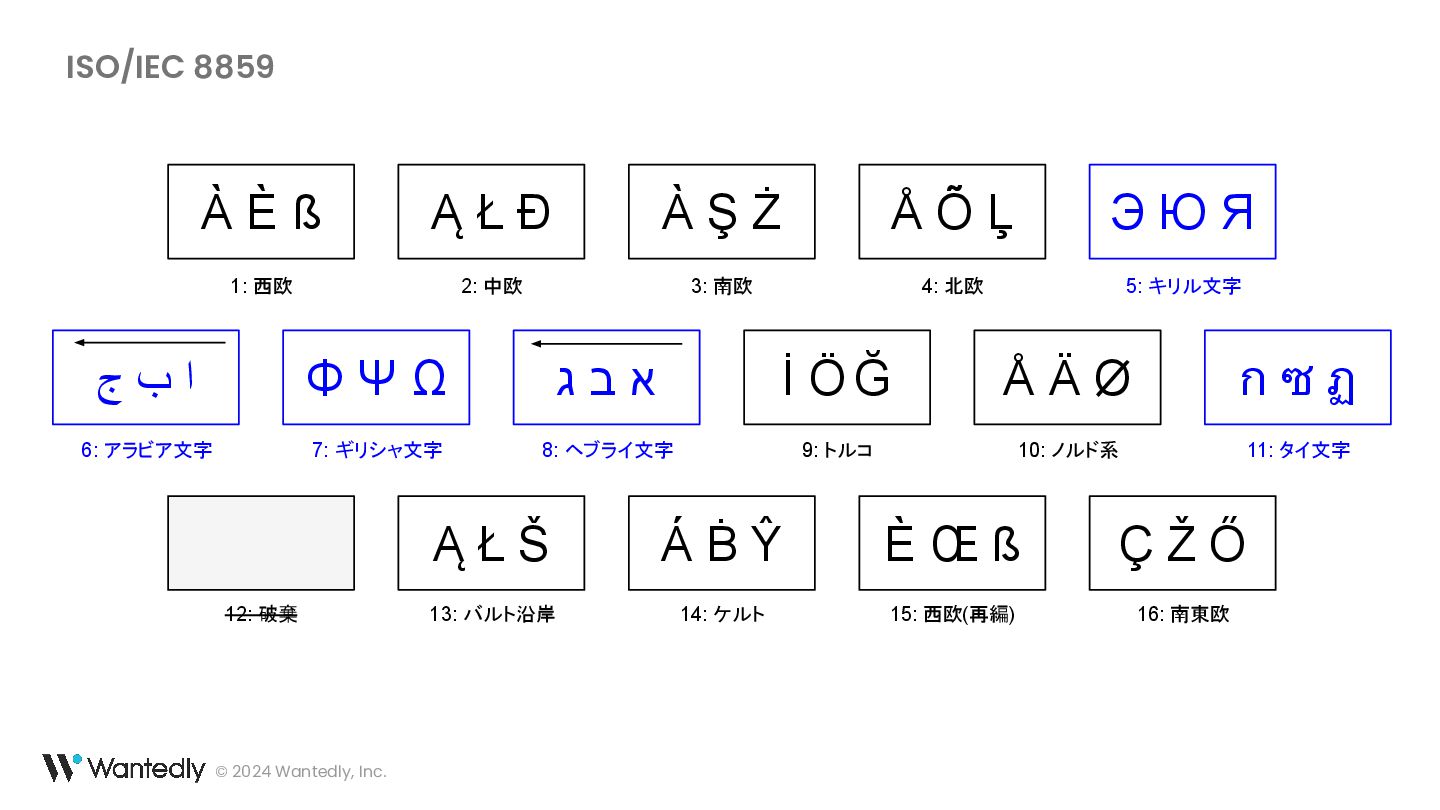
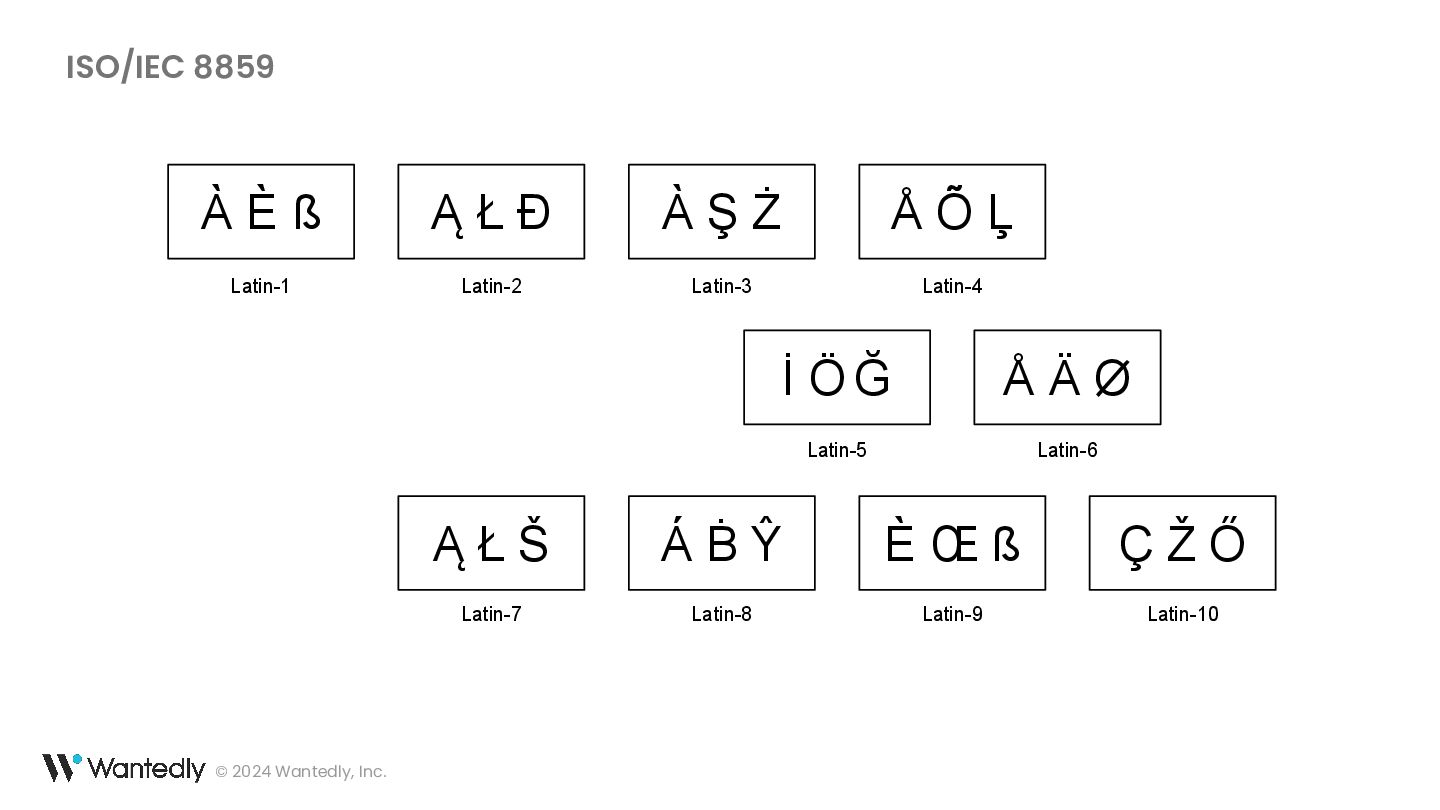
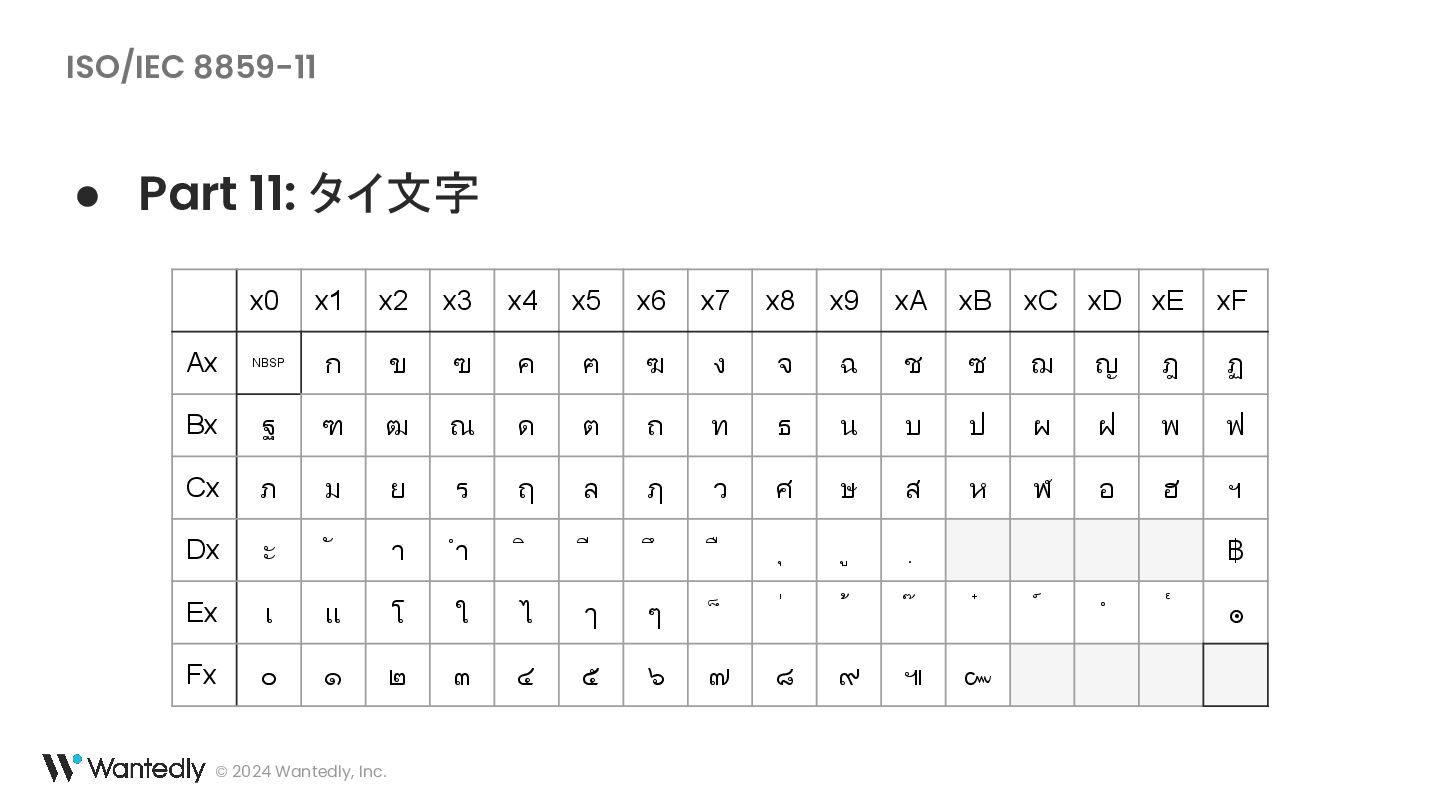
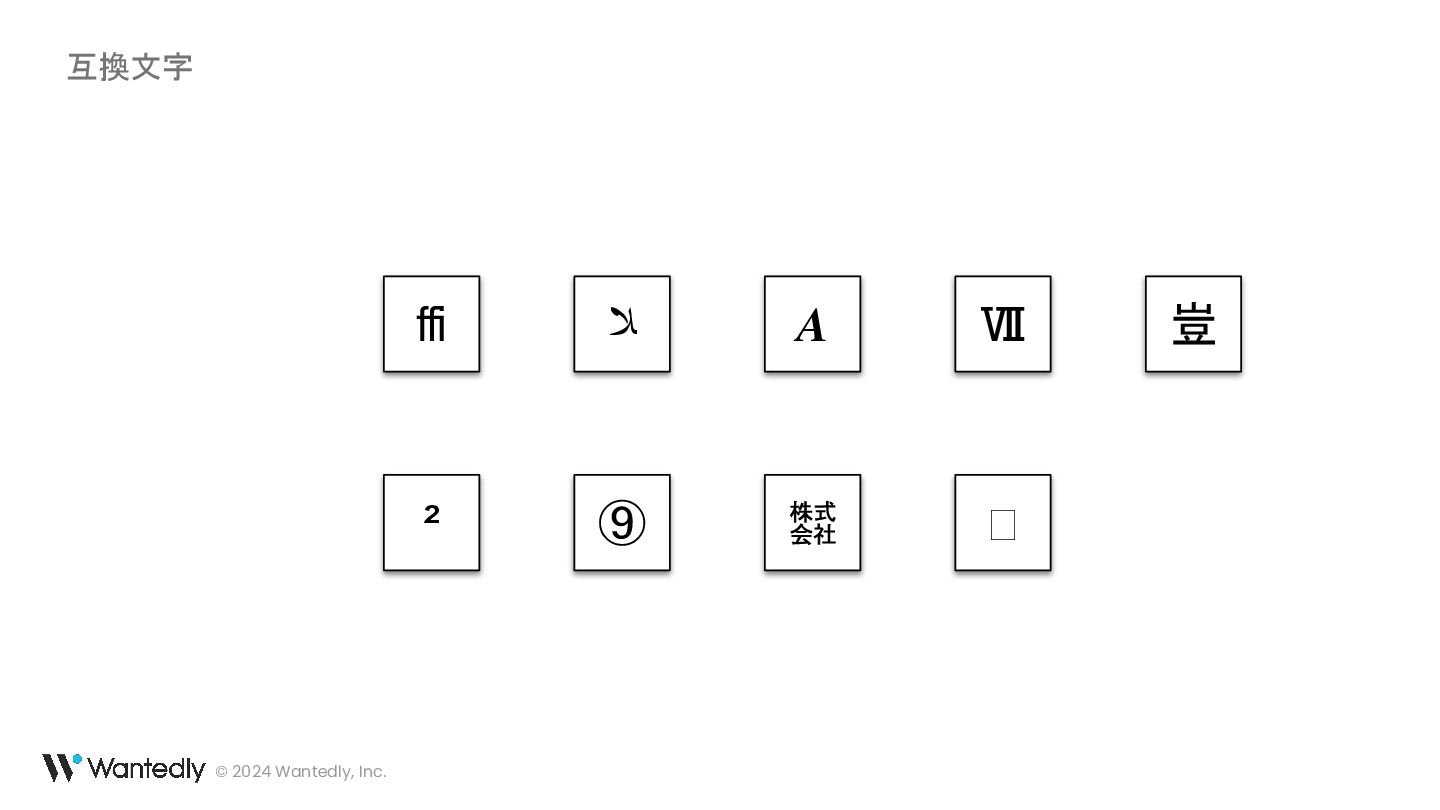
・ ß は ss の合字ではなく sz の合字
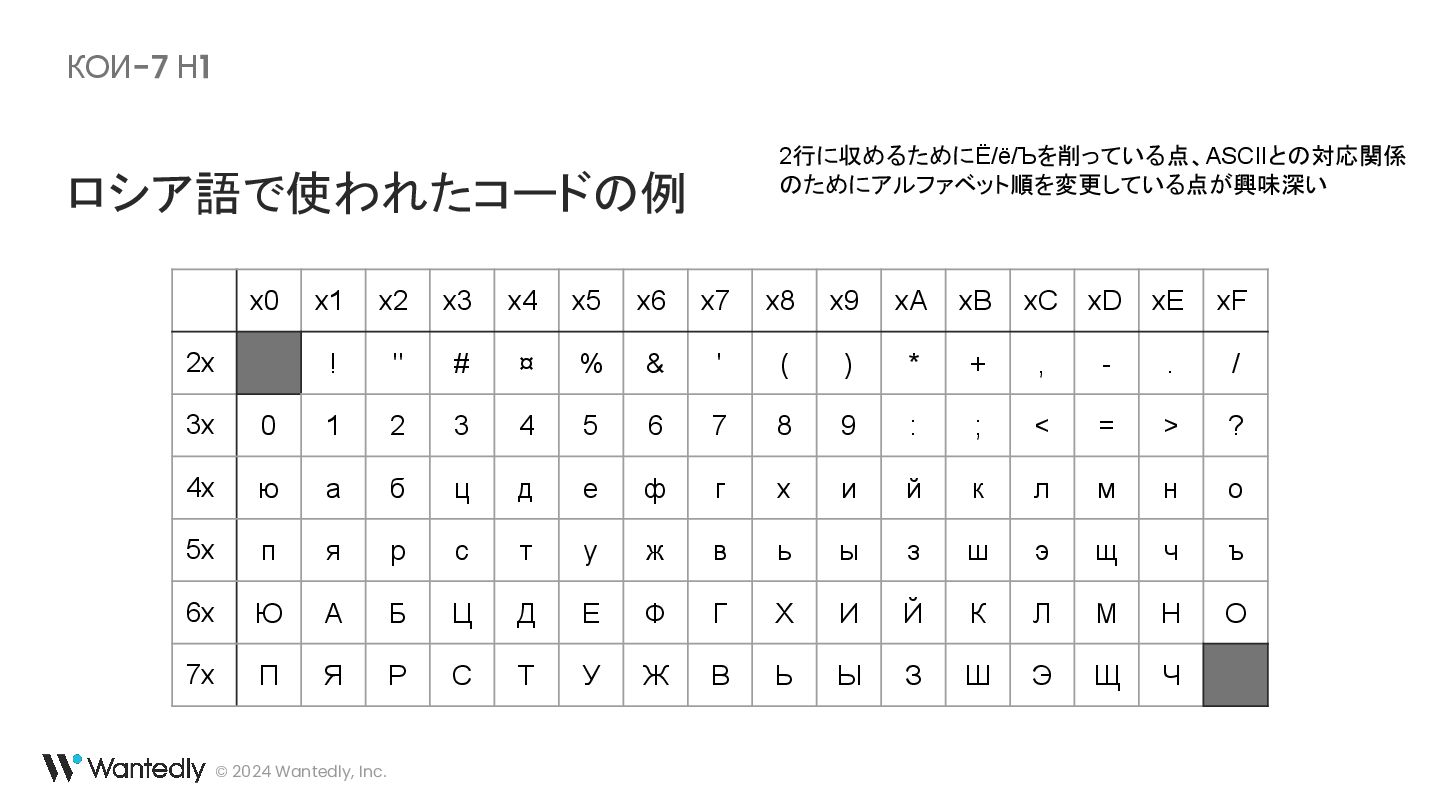
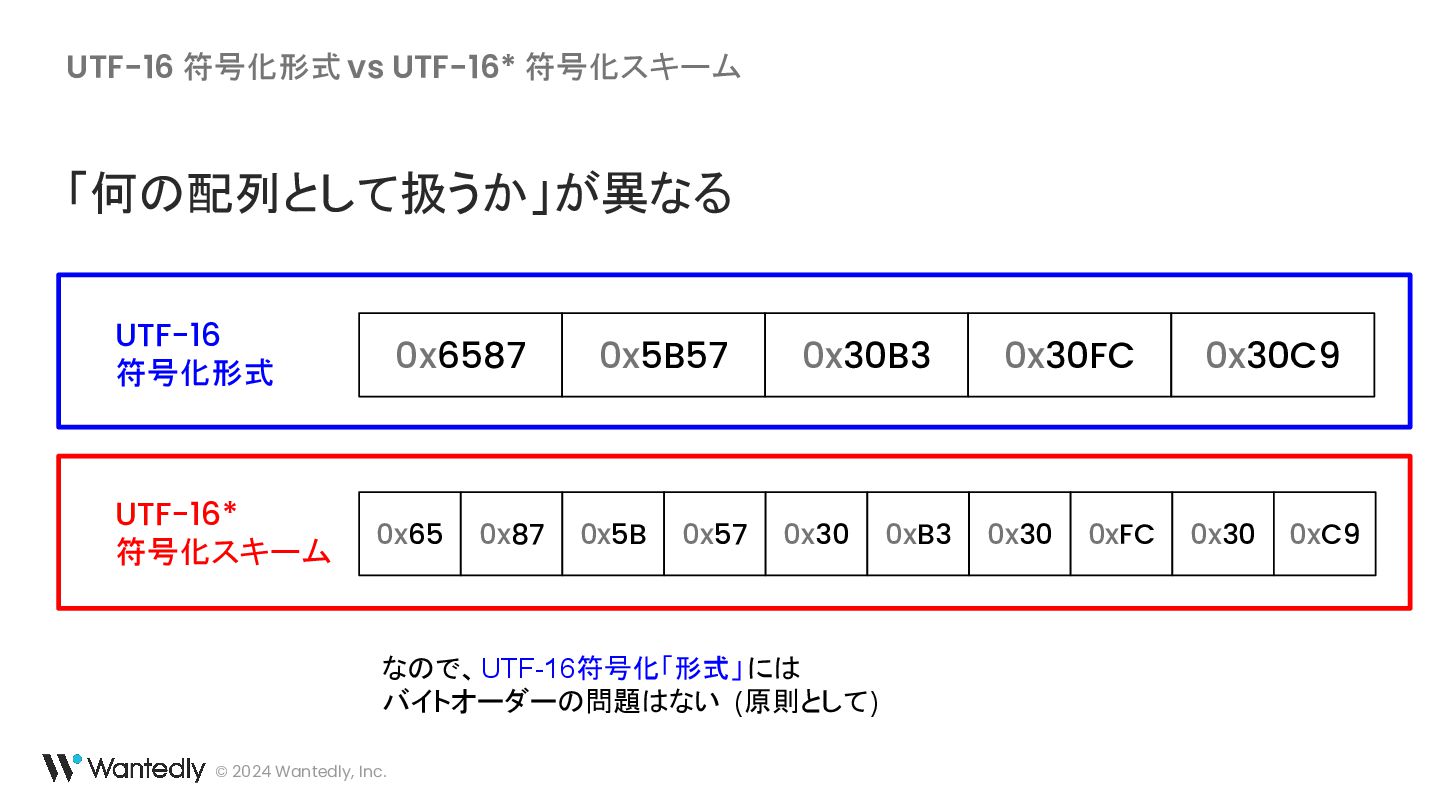
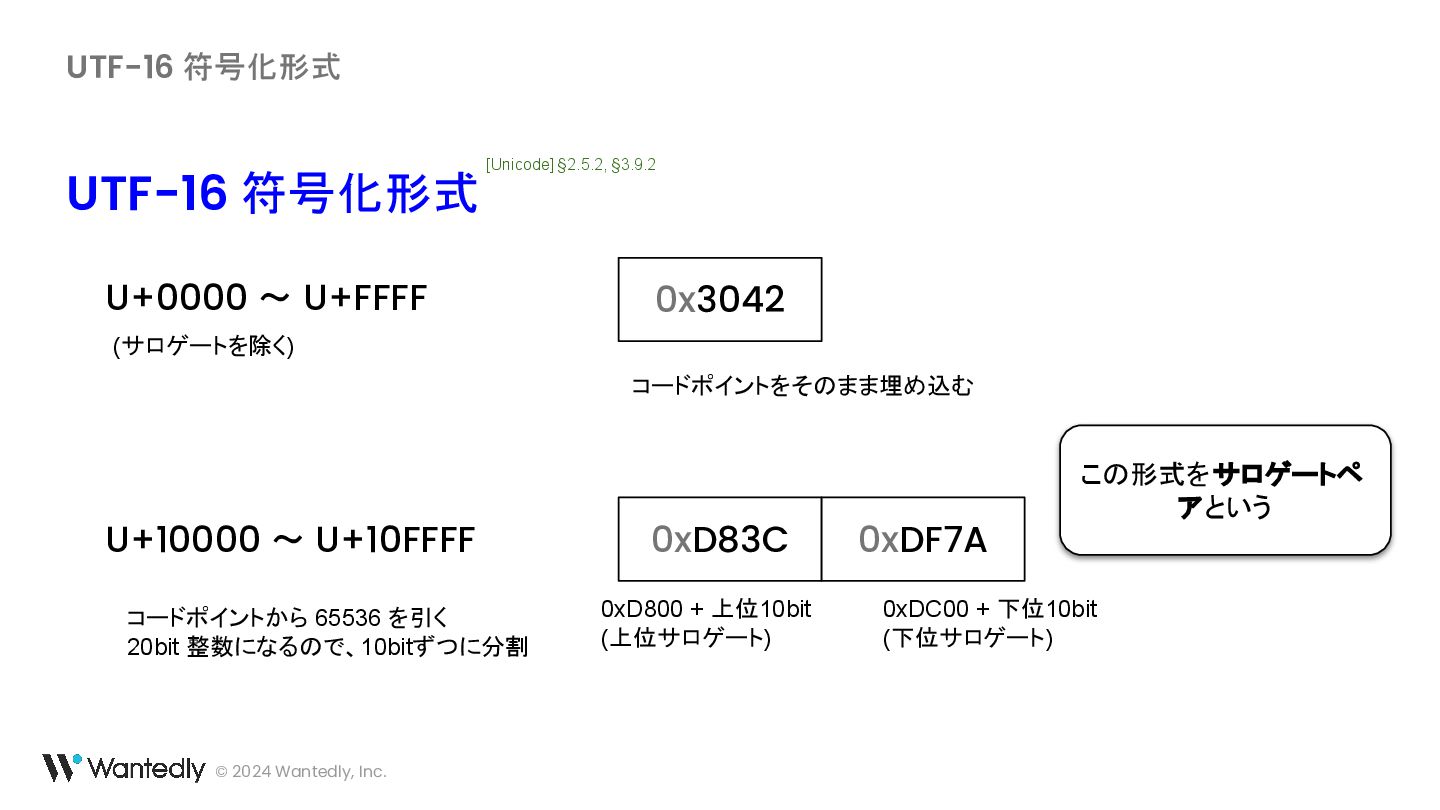
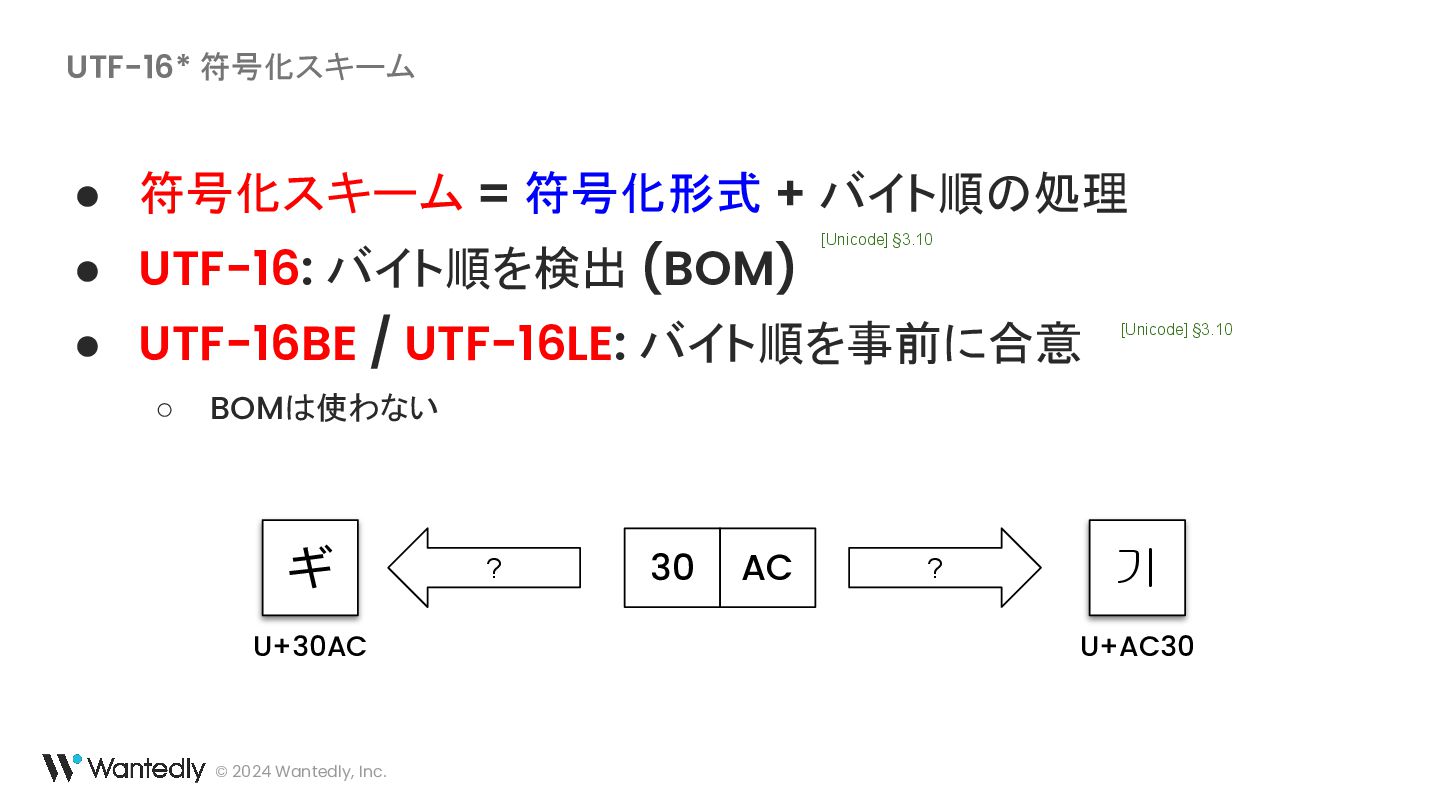
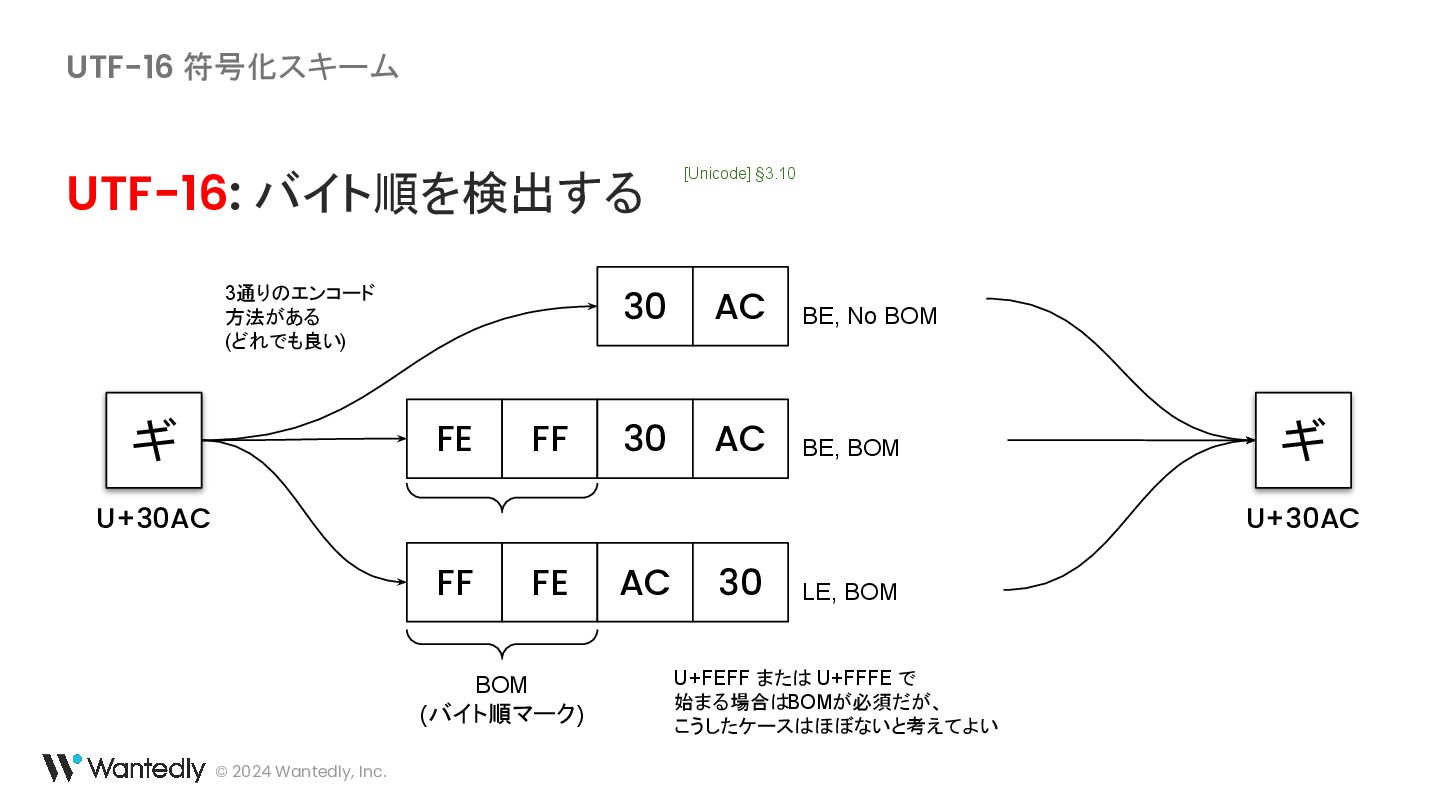
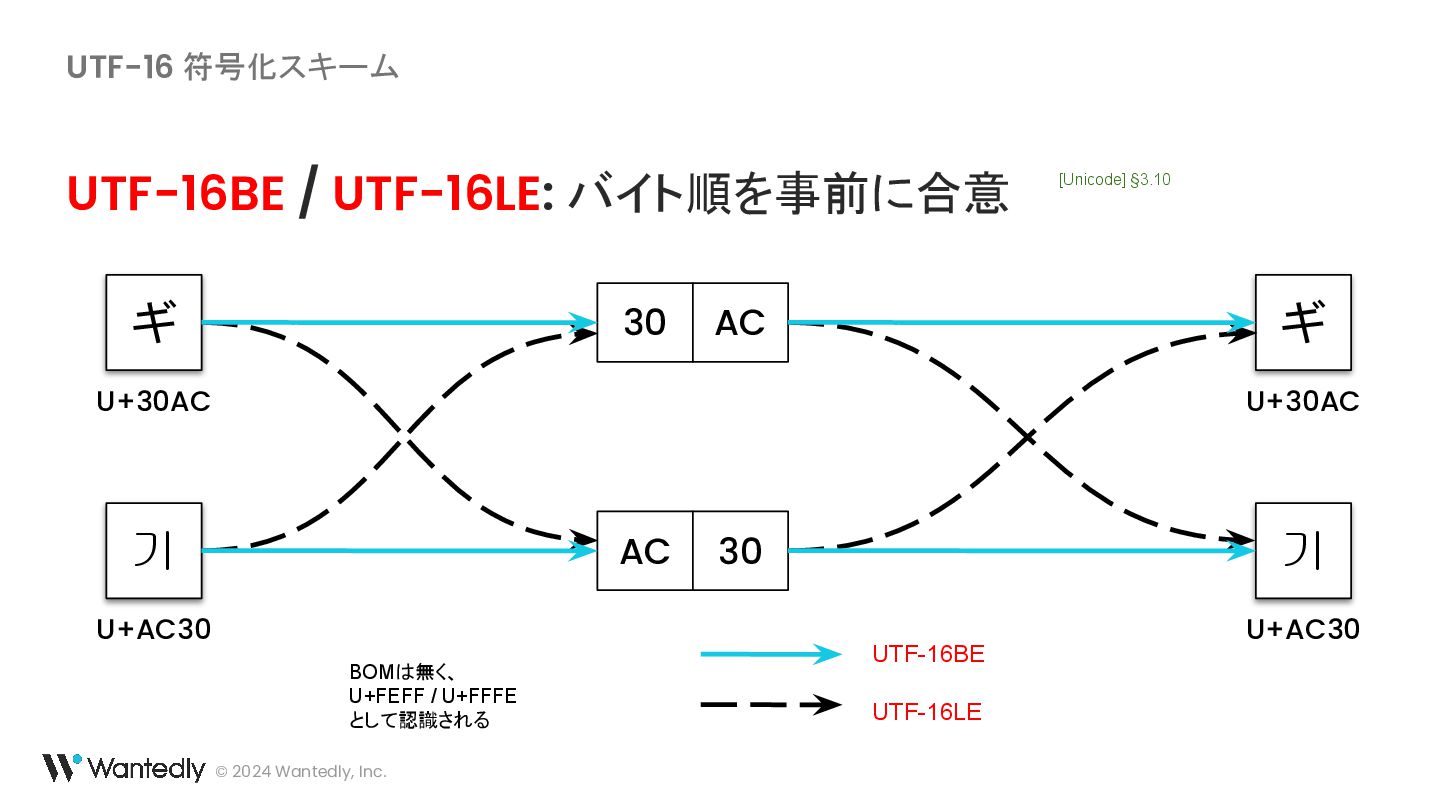
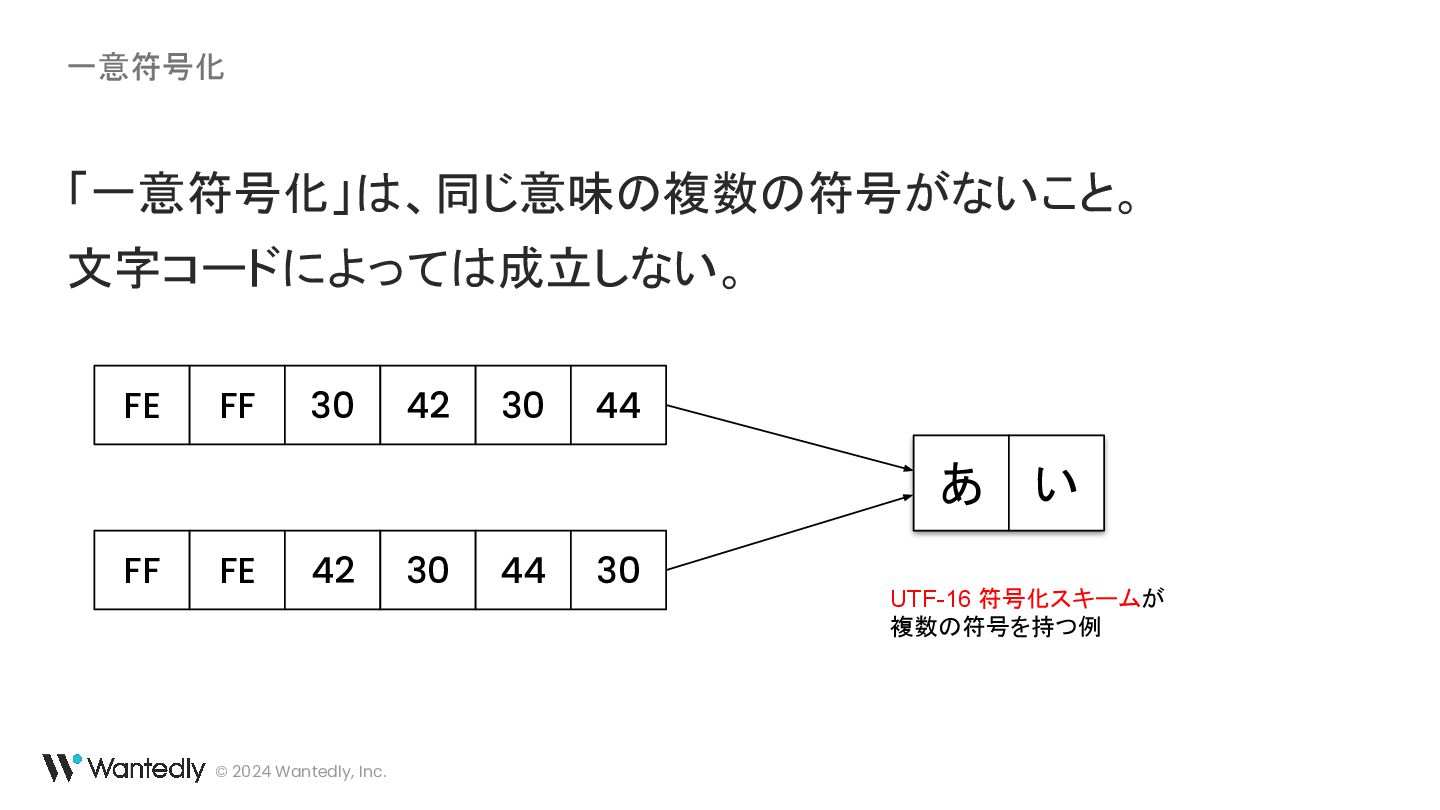
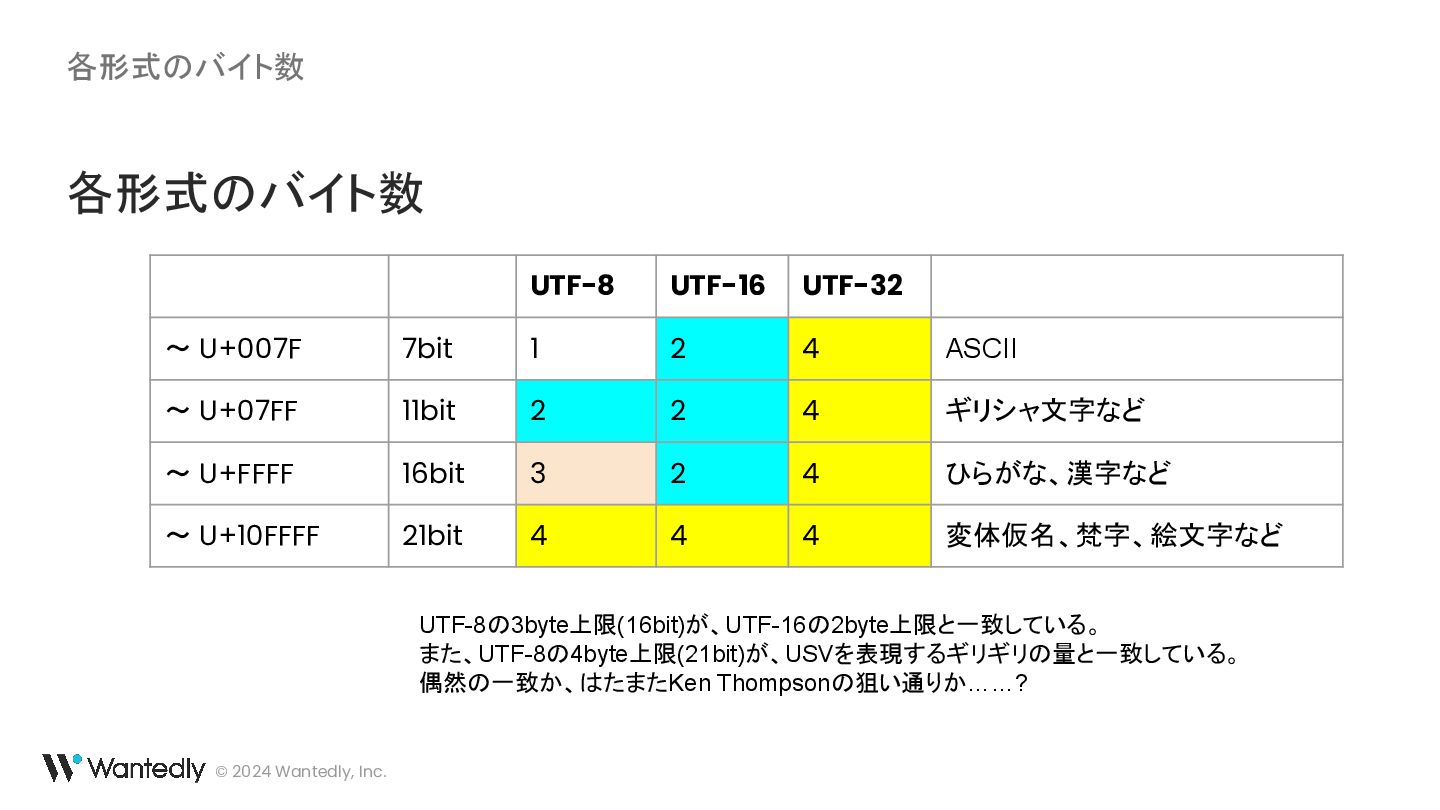
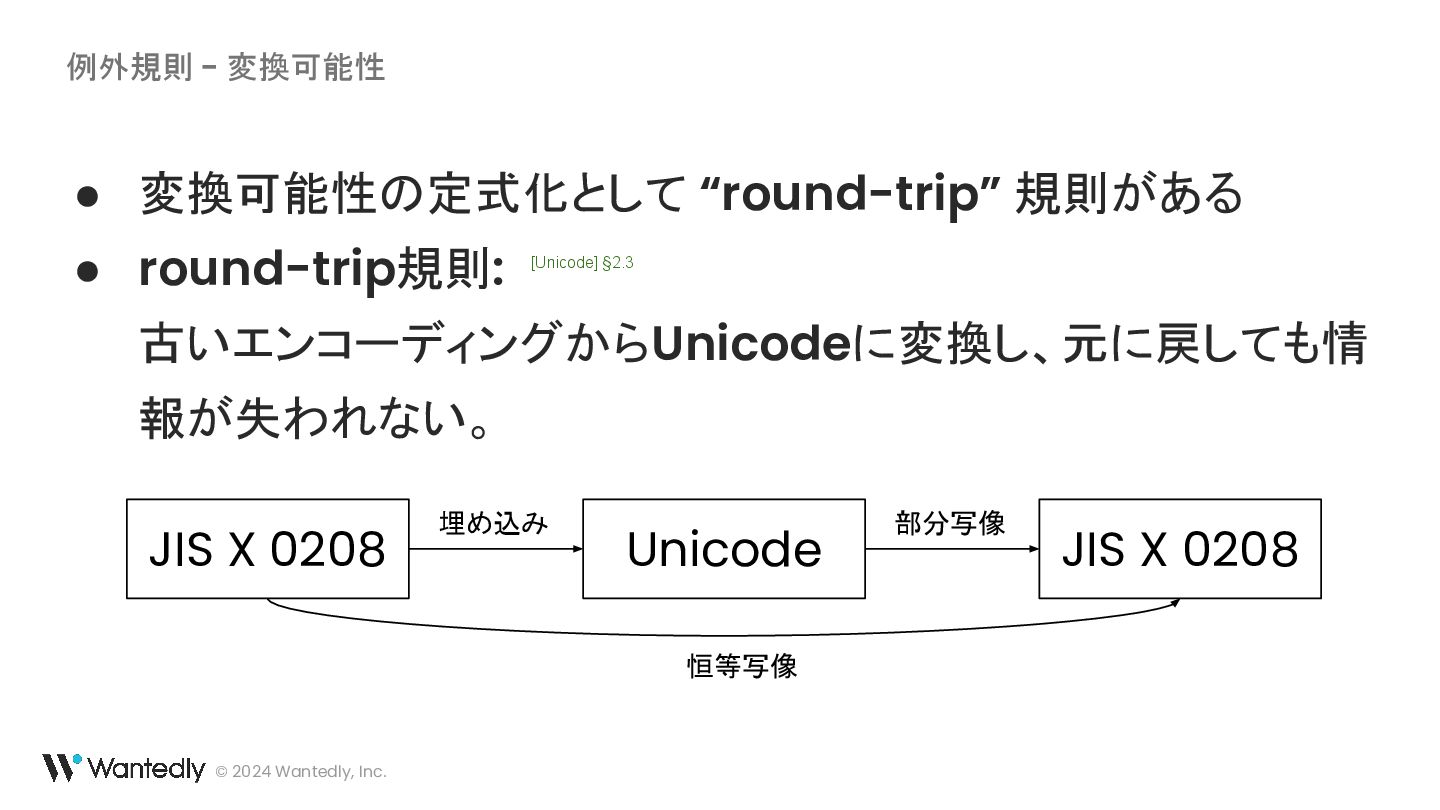
・ UTF-16 の例示に使われている「ギ」「기」に対応するバイト列は 30 AC ではなく 30 AE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
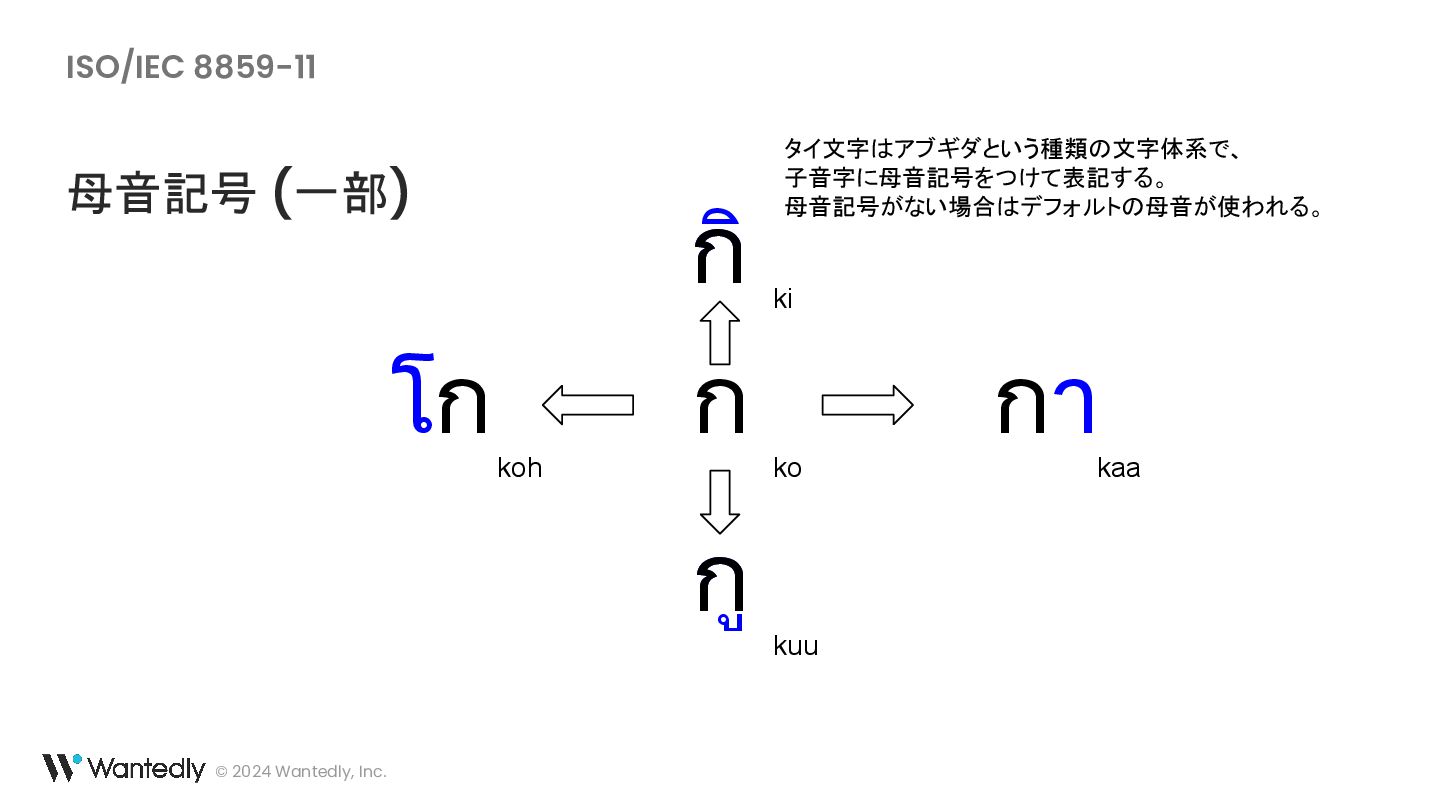{kind=link}
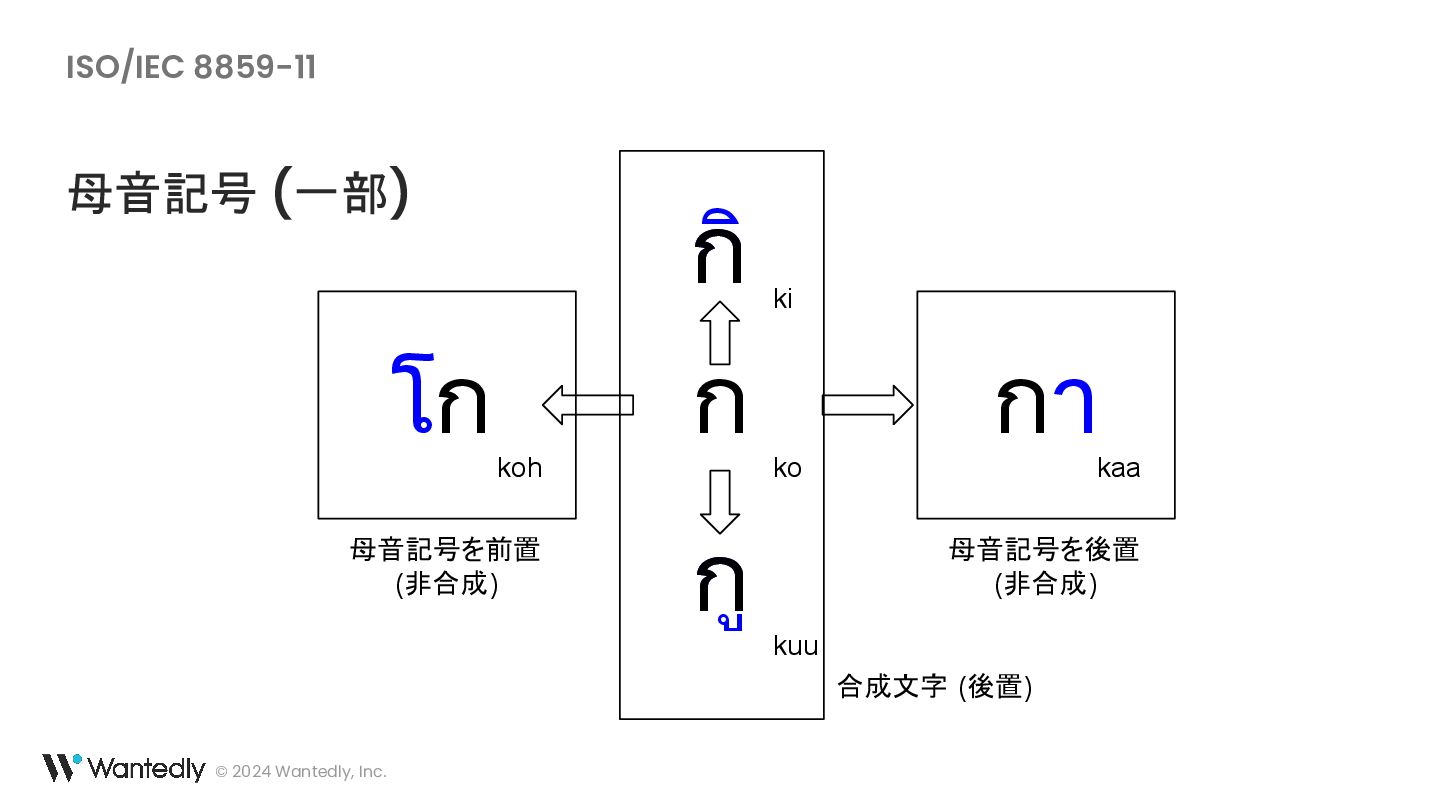{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
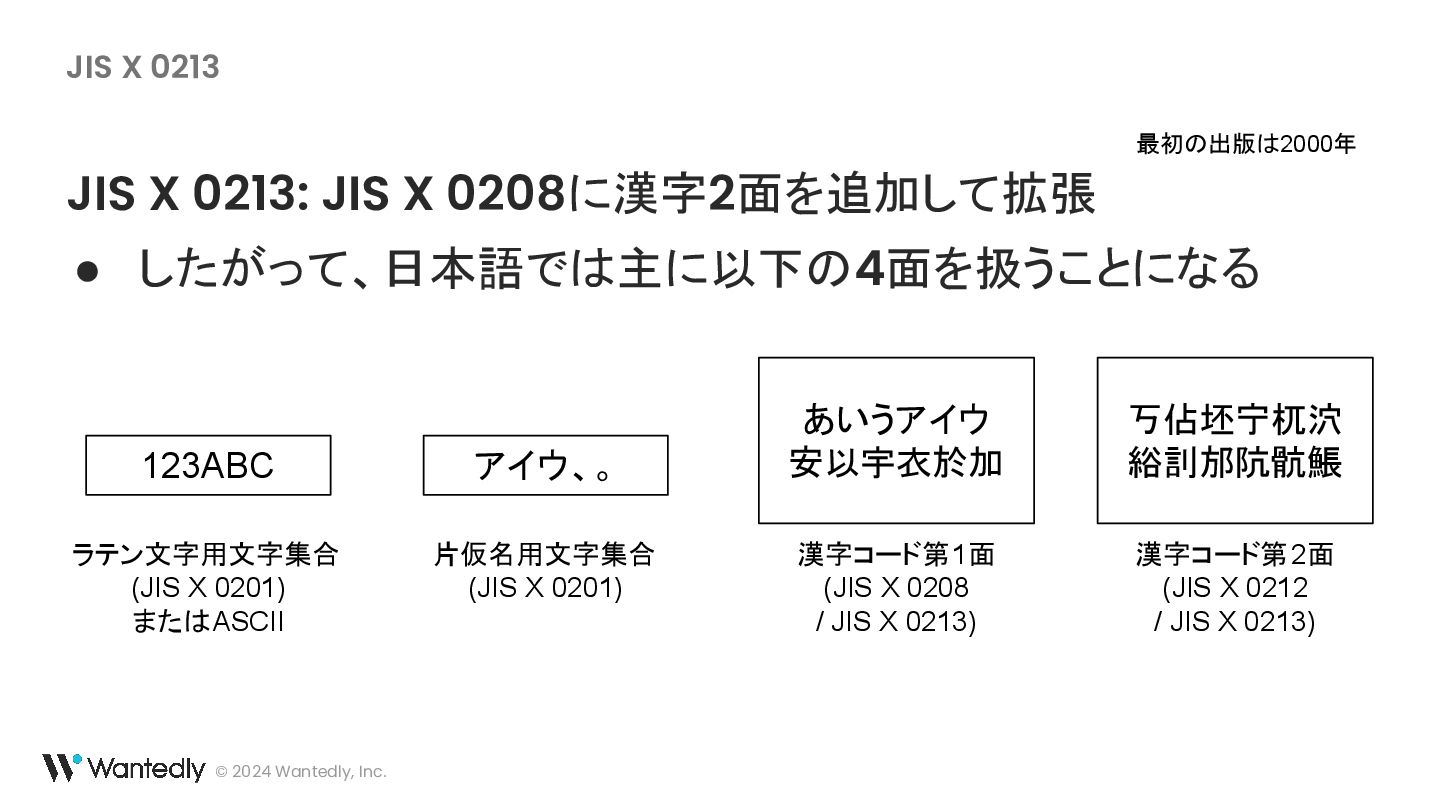{kind=link}
{kind=link}
{kind=link}
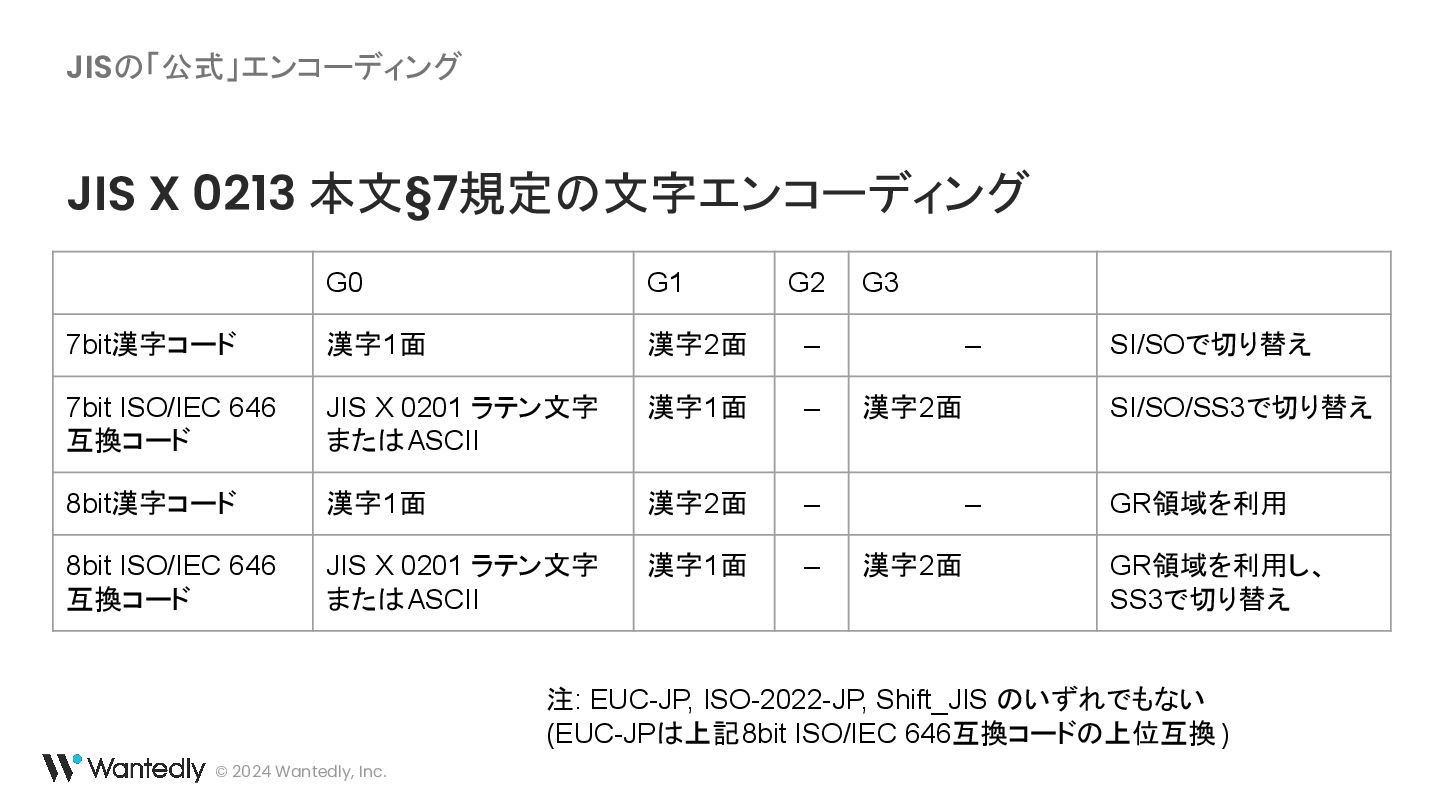{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
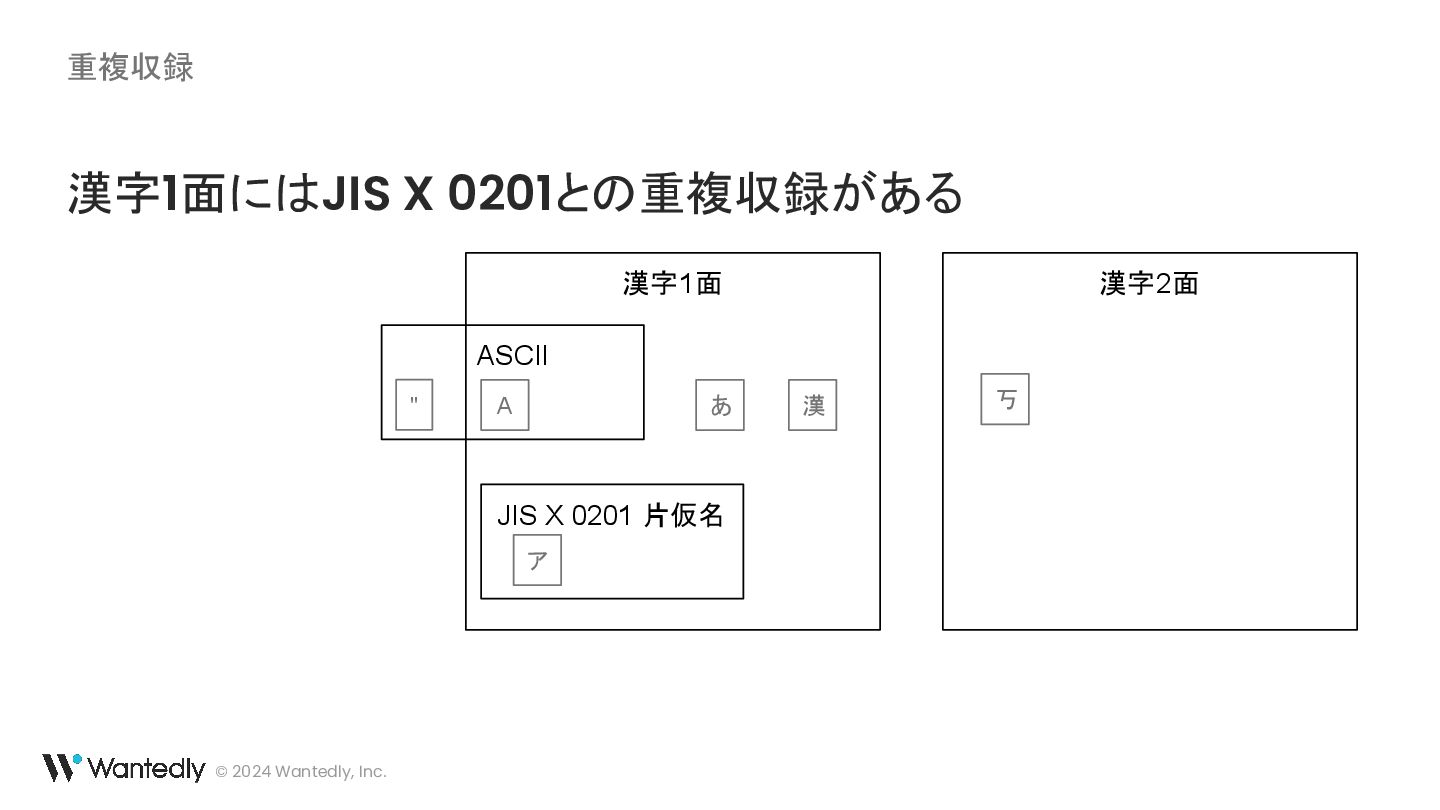{kind=link}
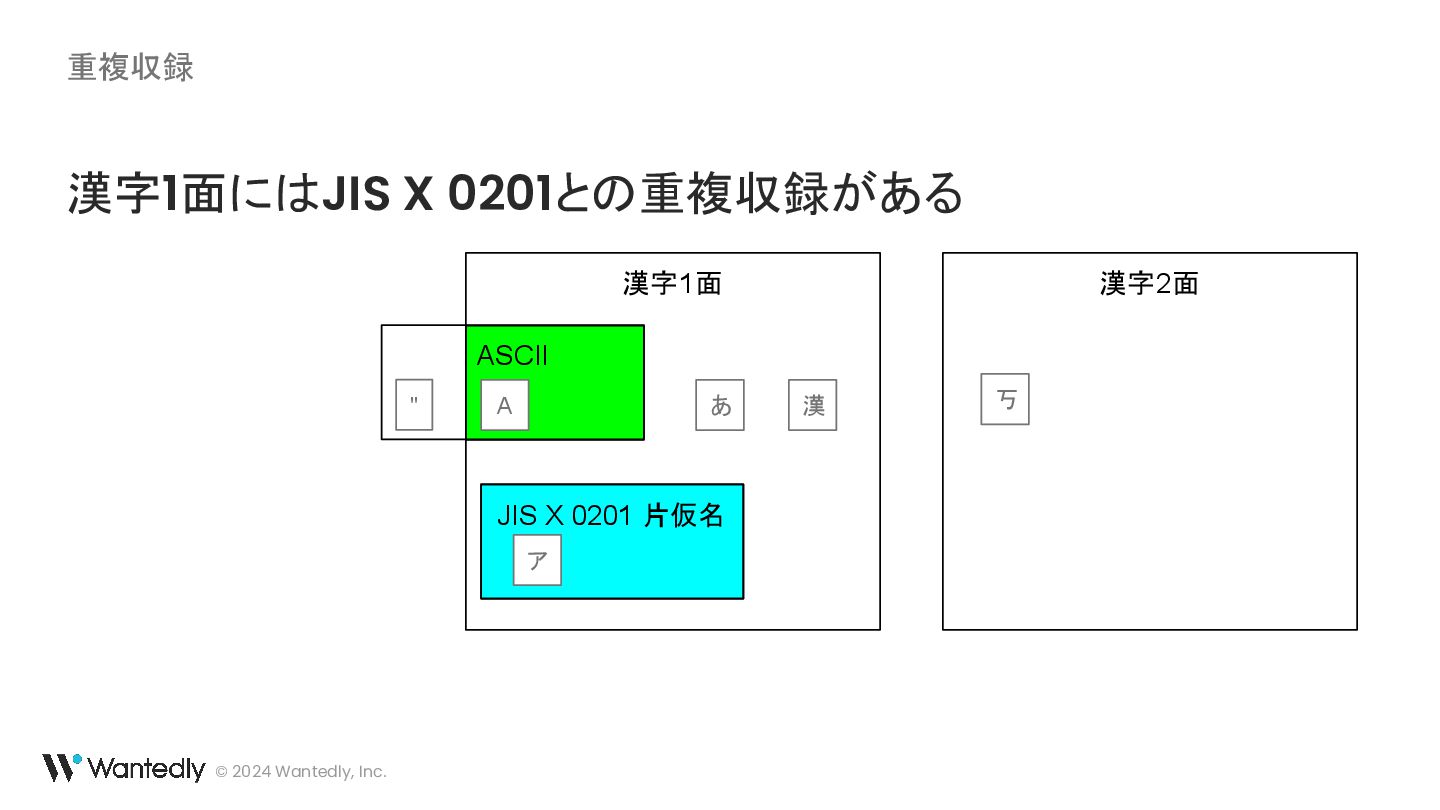{kind=link}
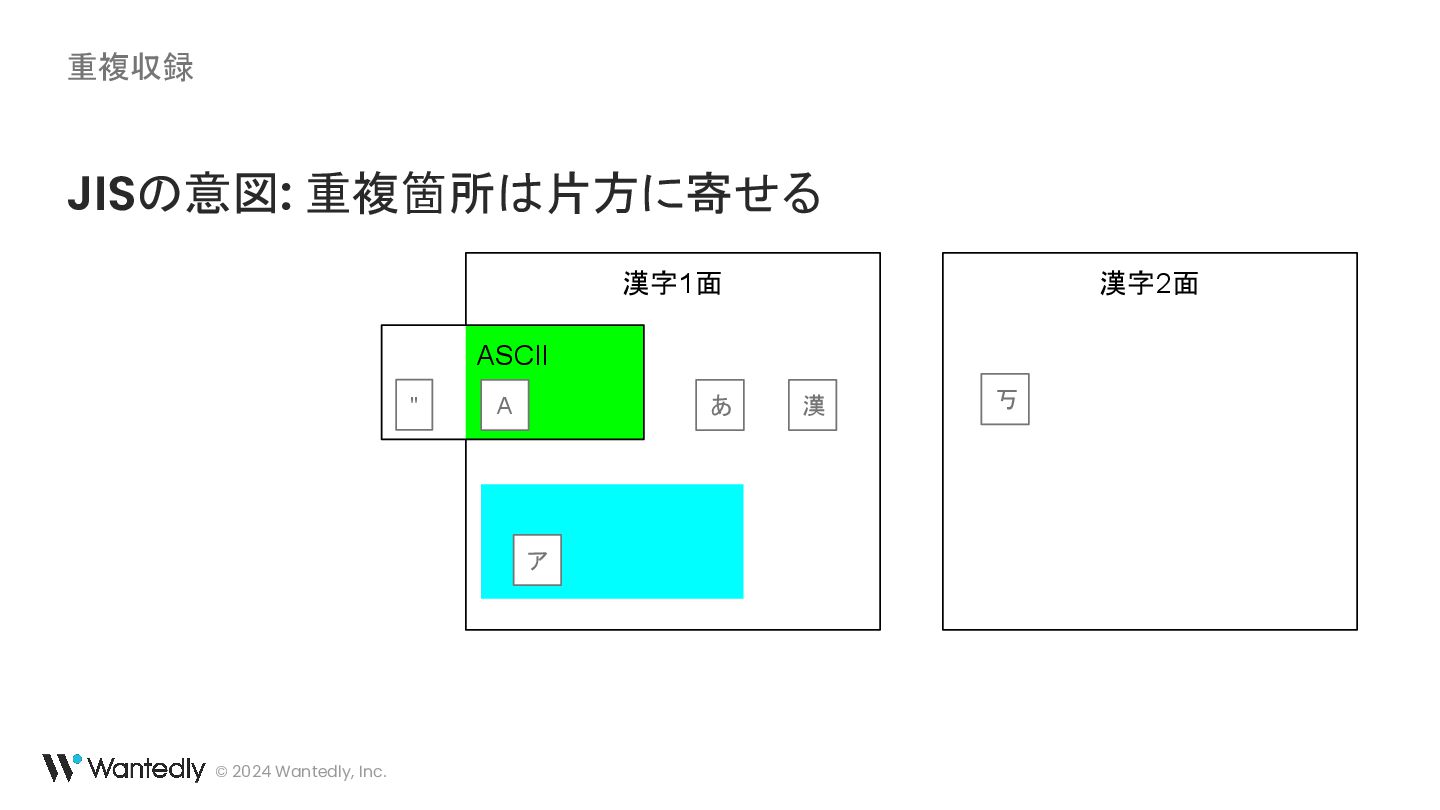{kind=link}
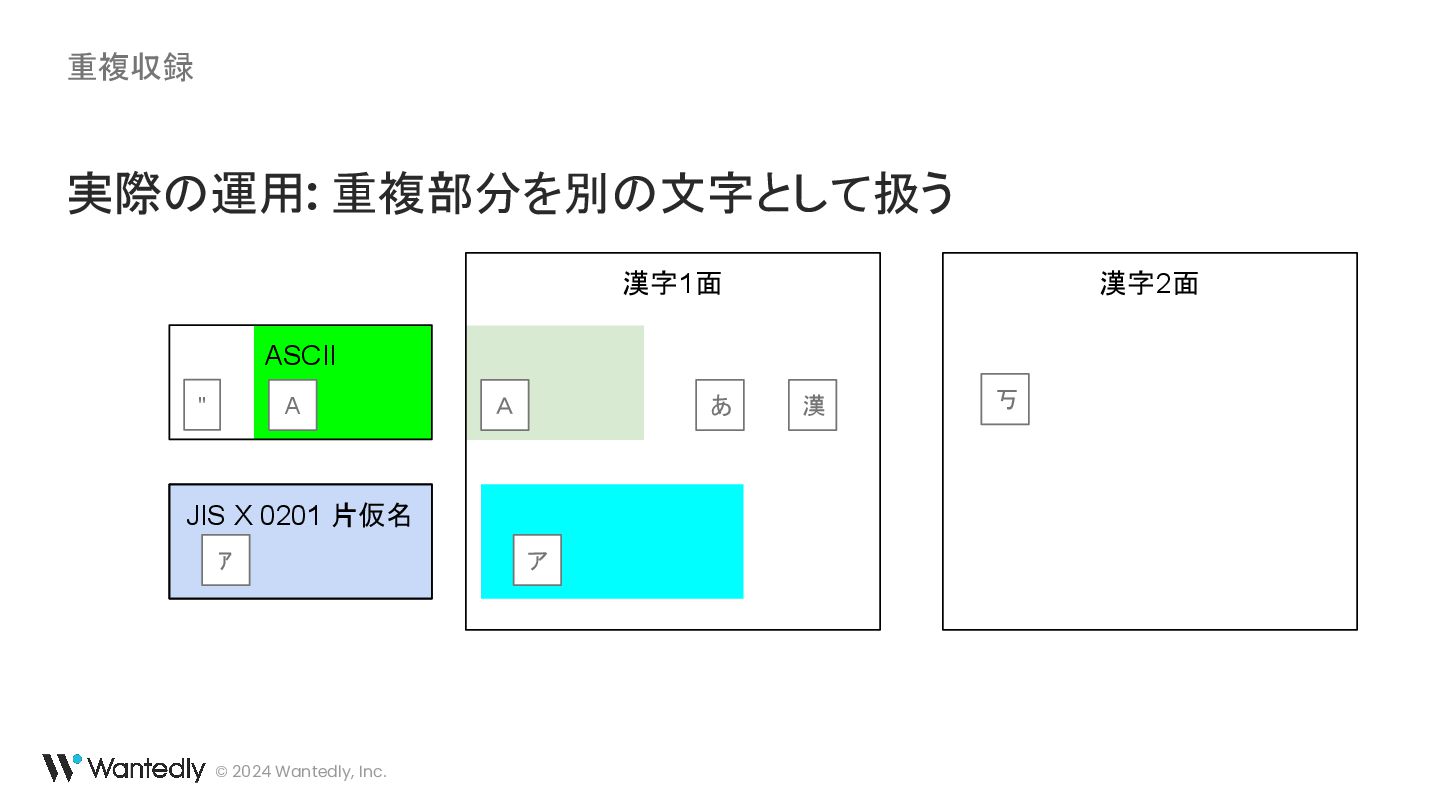{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
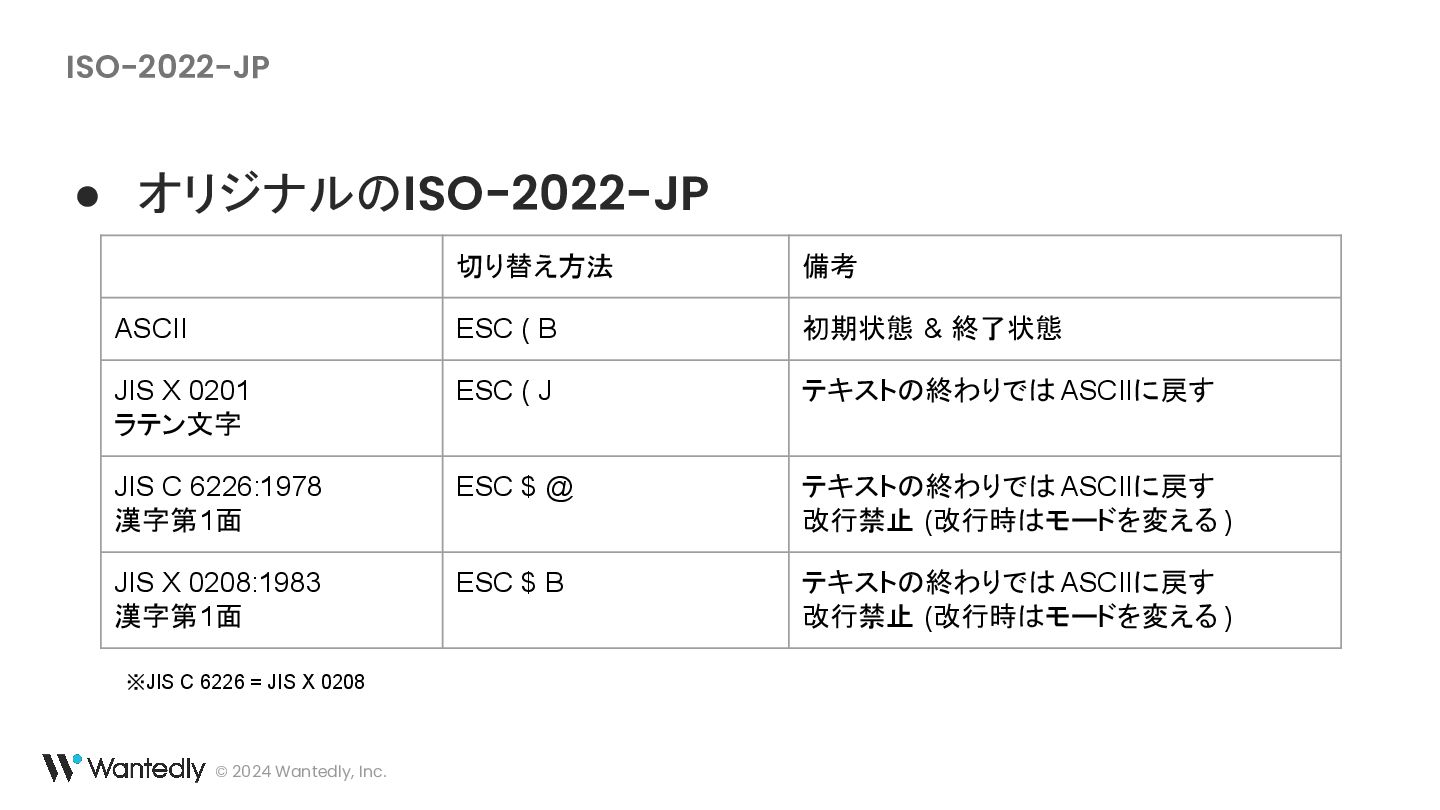{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
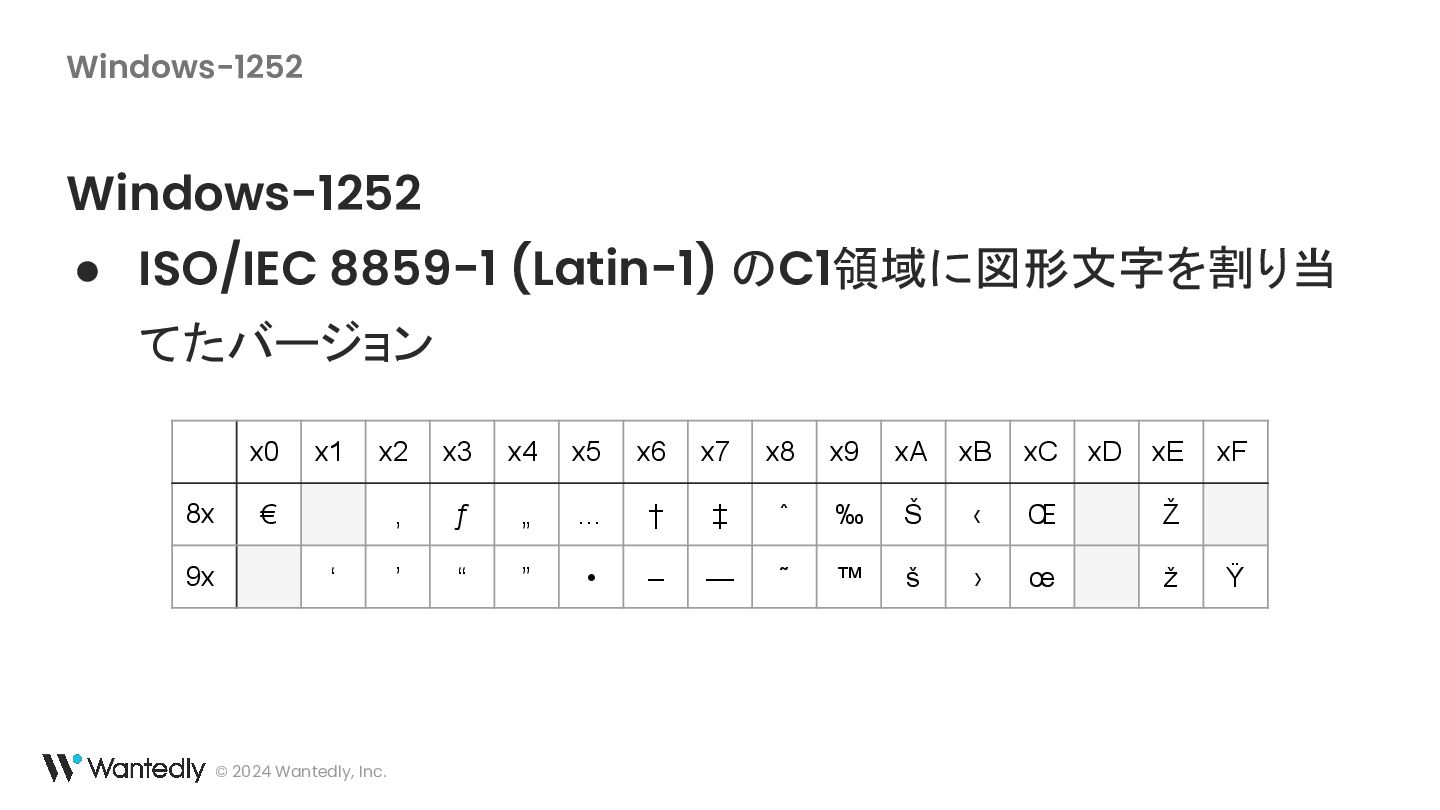{kind=link}
{kind=link}
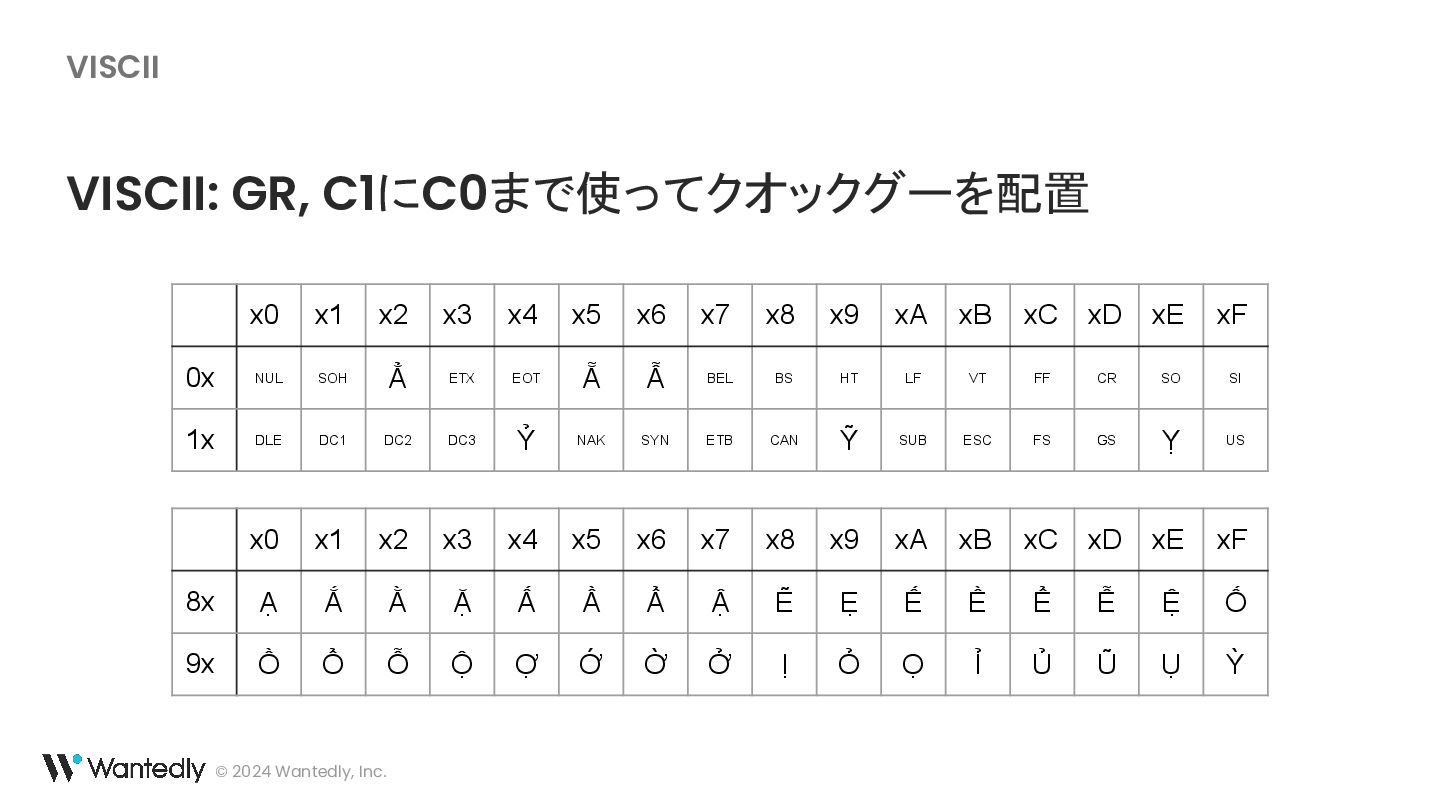{kind=link}
{kind=link}
{kind=link}
{kind=link}
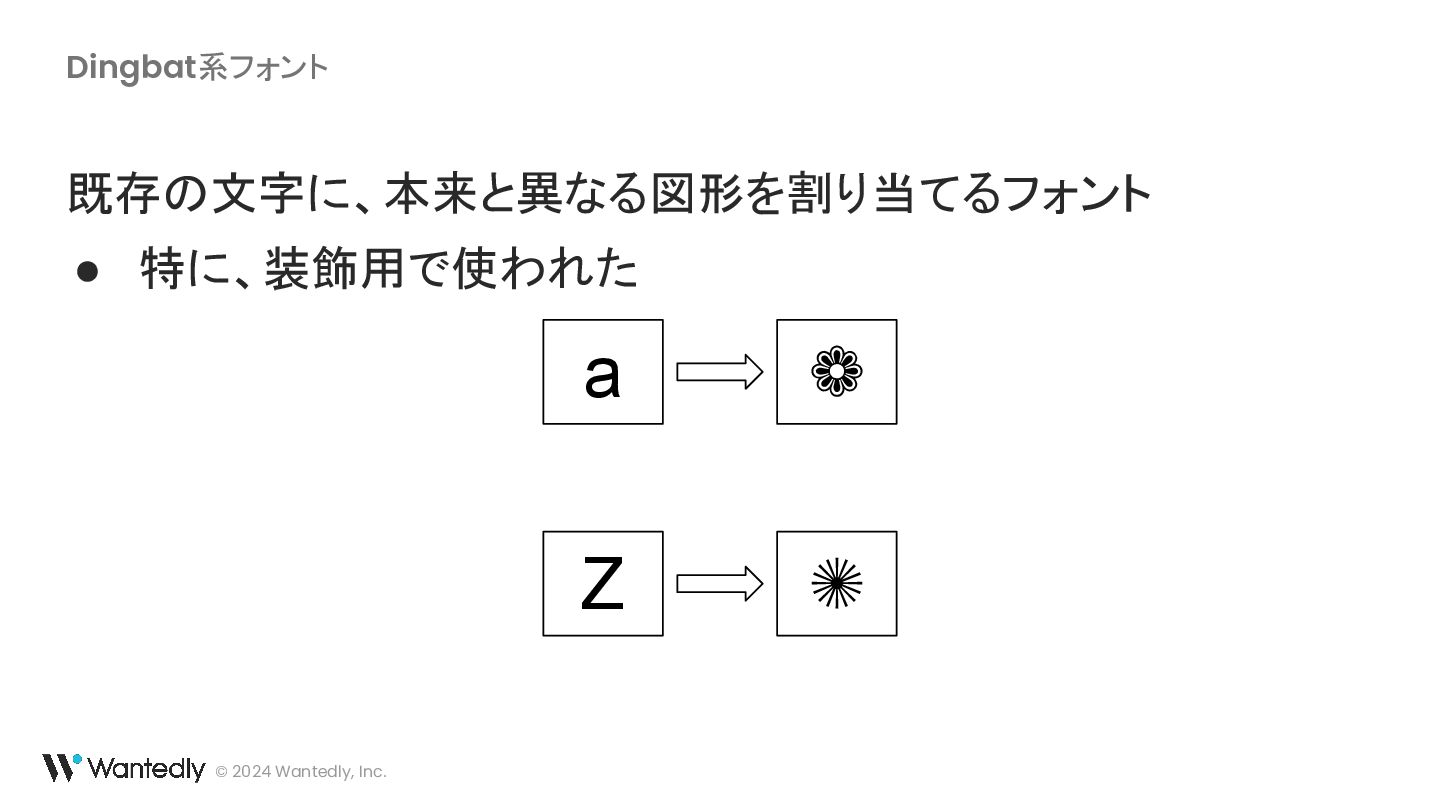{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
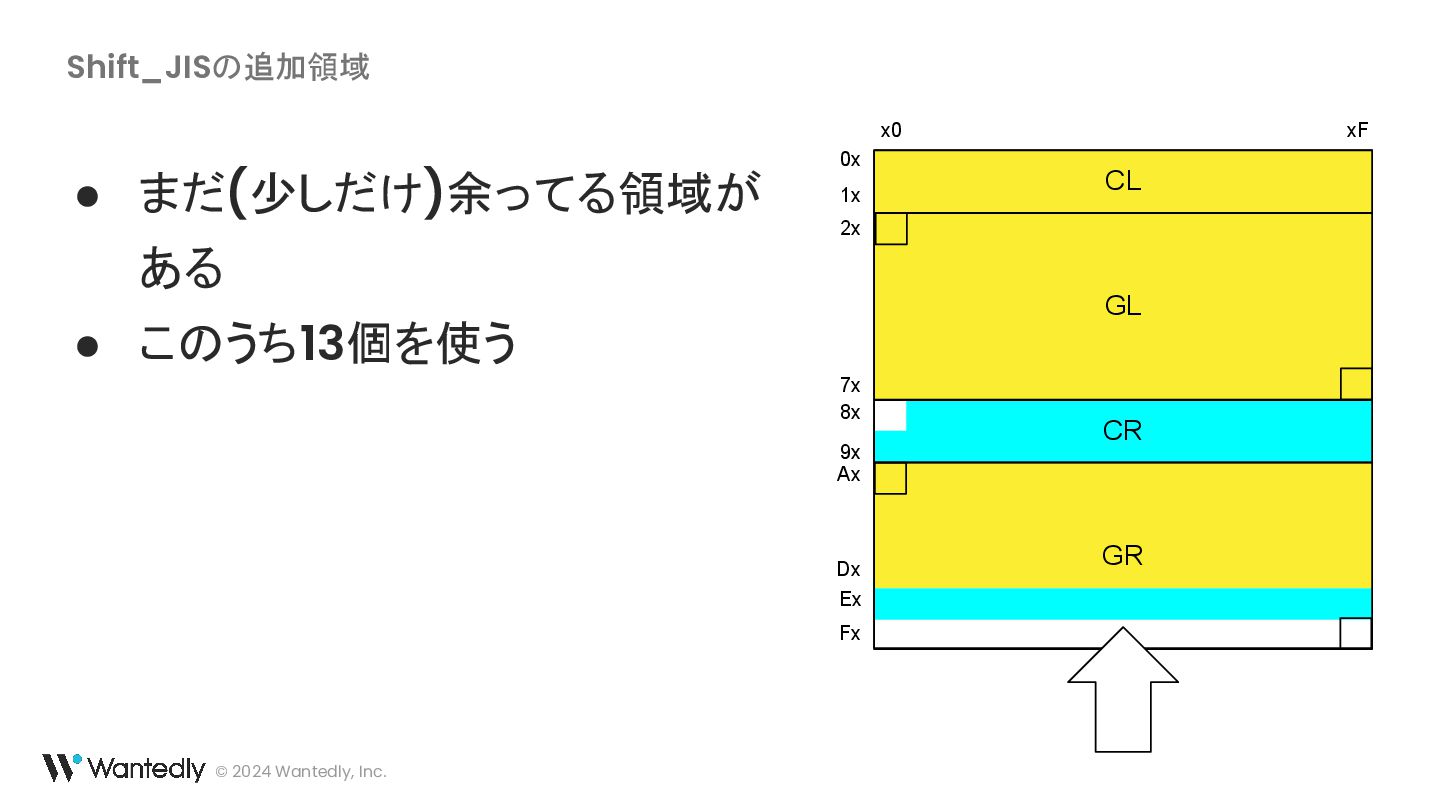{kind=link}
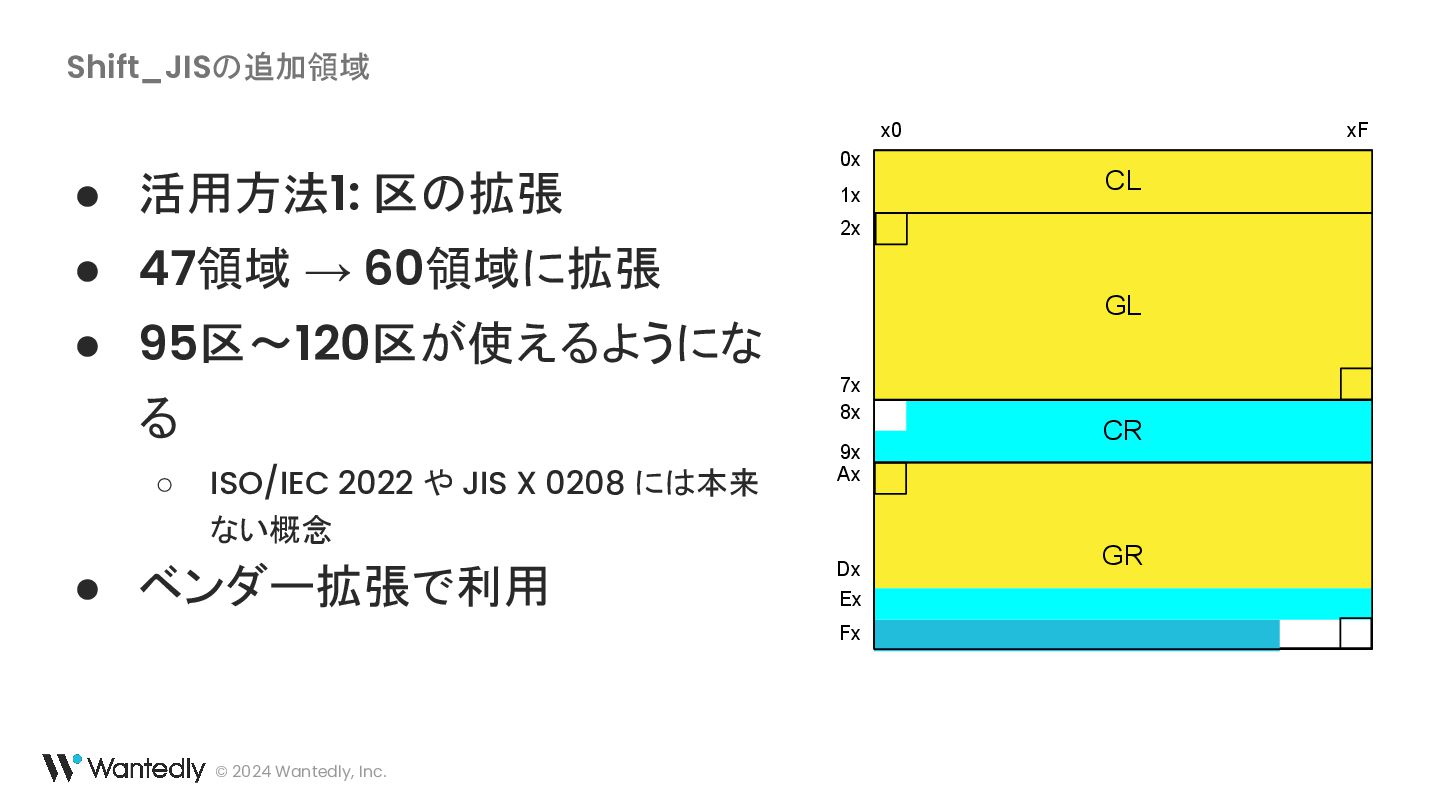{kind=link}
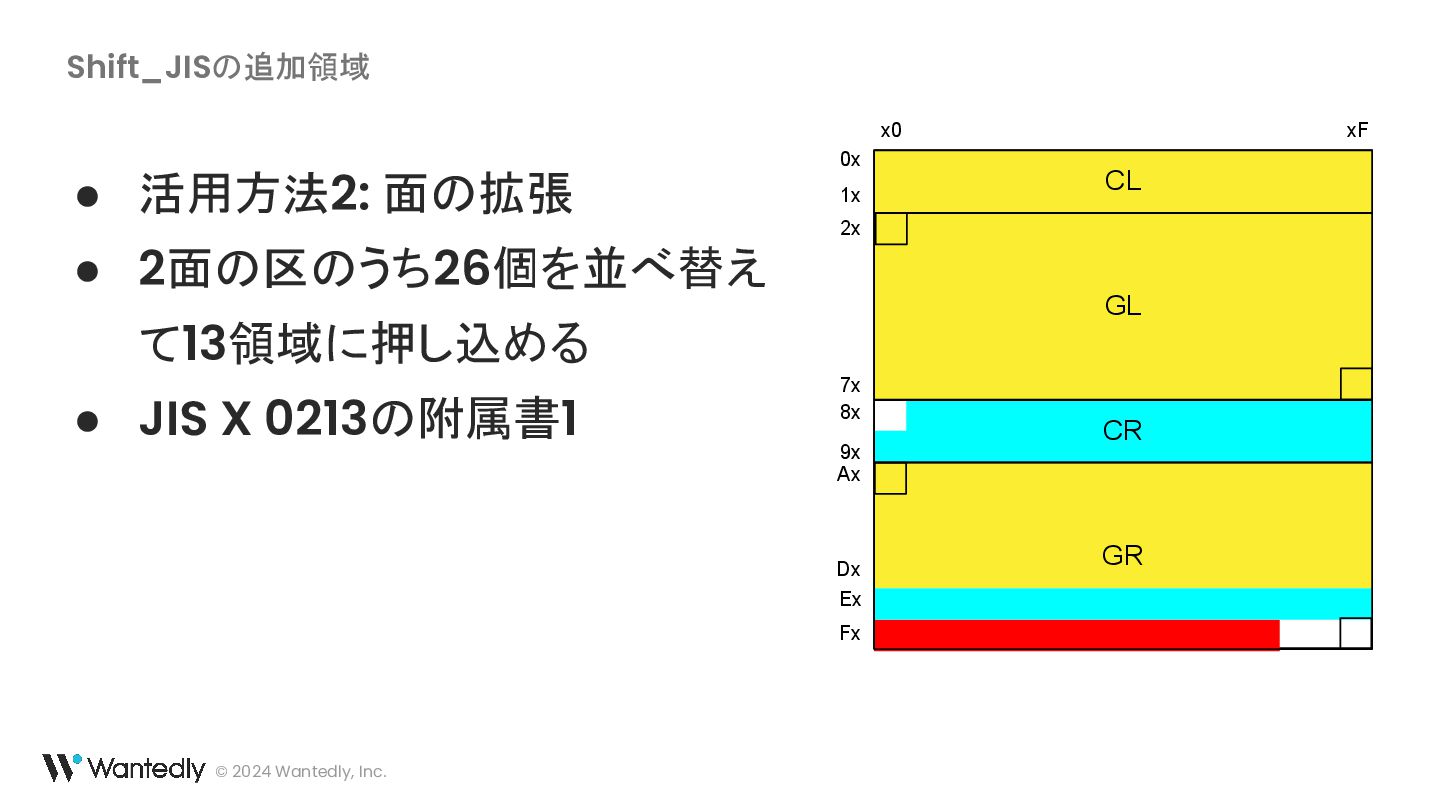{kind=link}
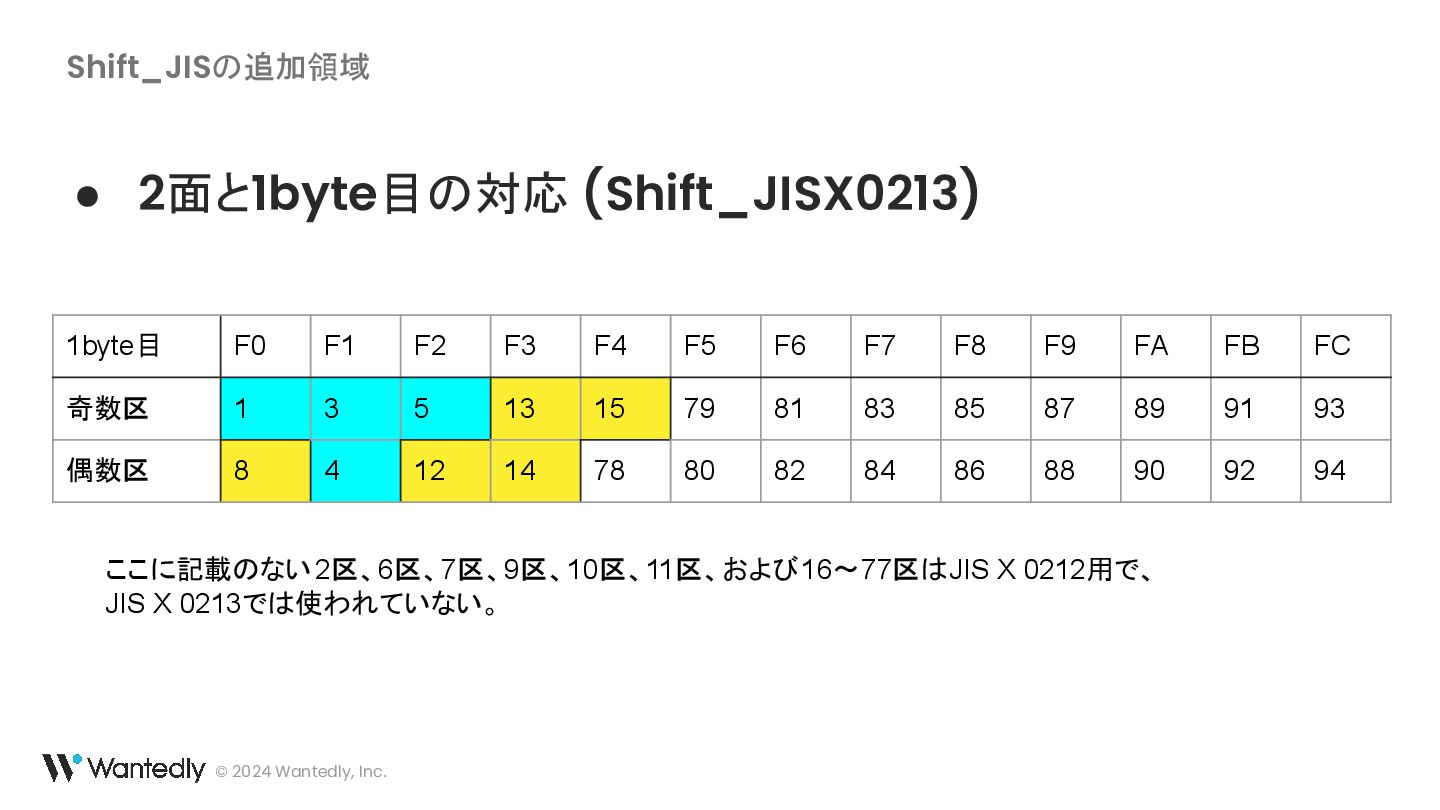{kind=link}
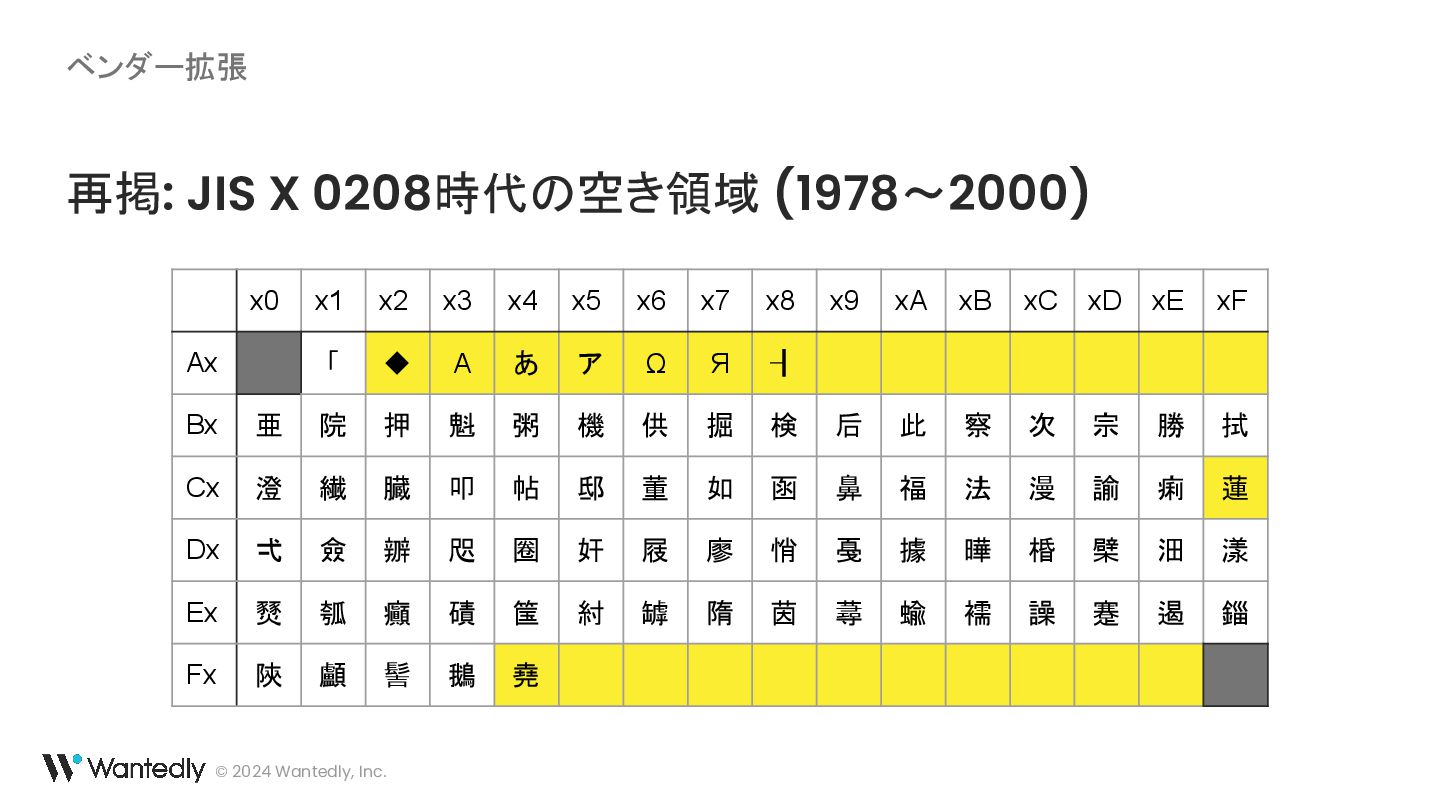{kind=link}
{kind=link}
{kind=link}
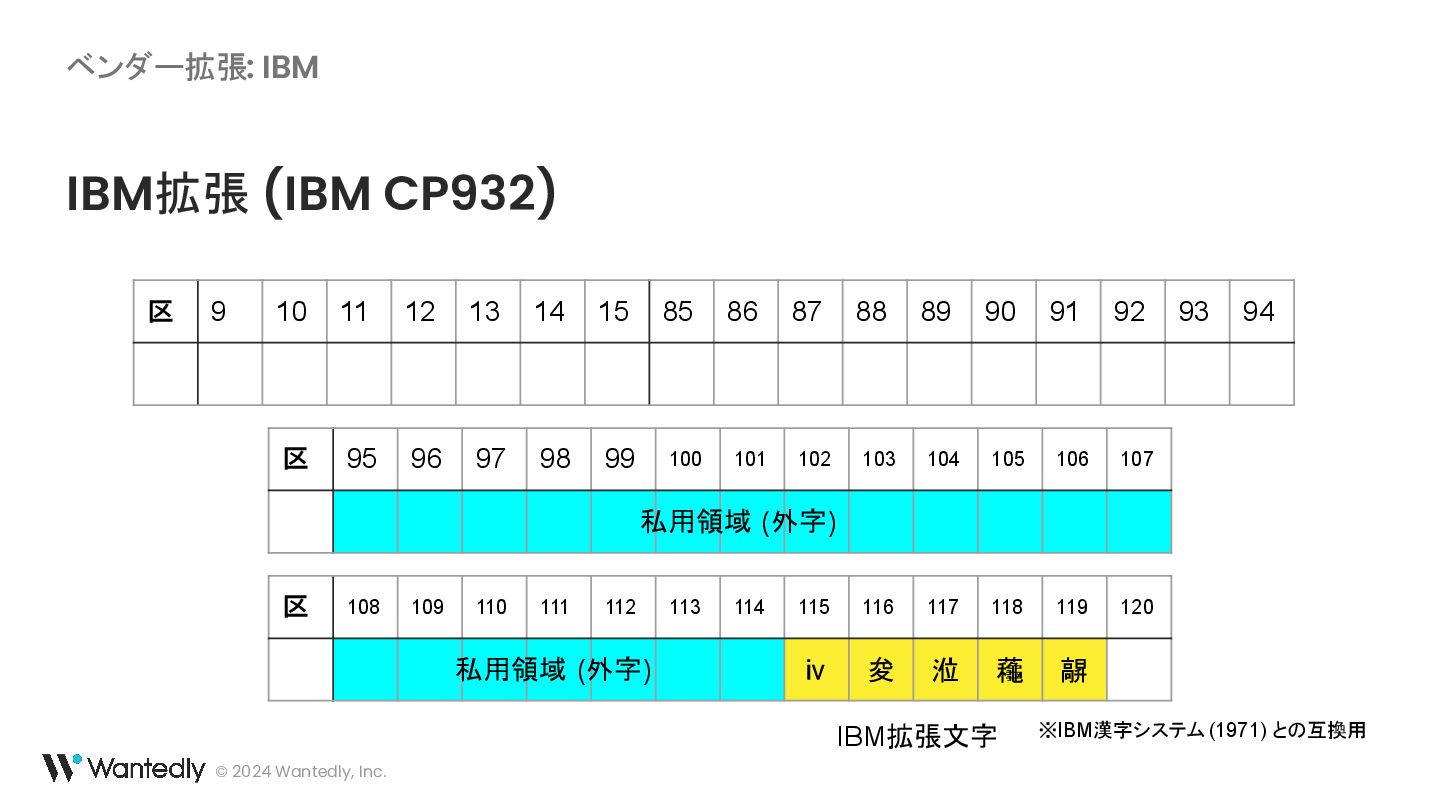{kind=link}
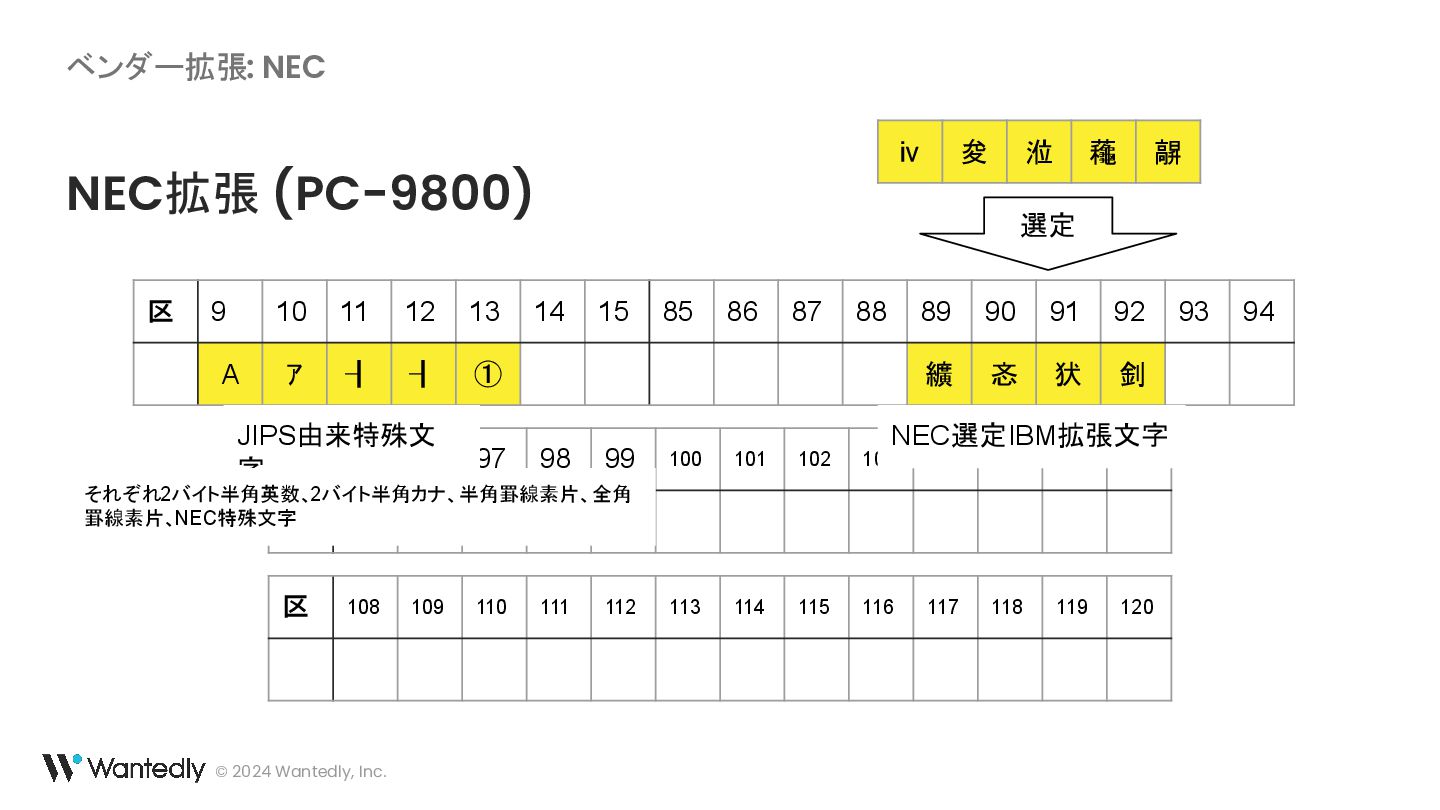{kind=link}
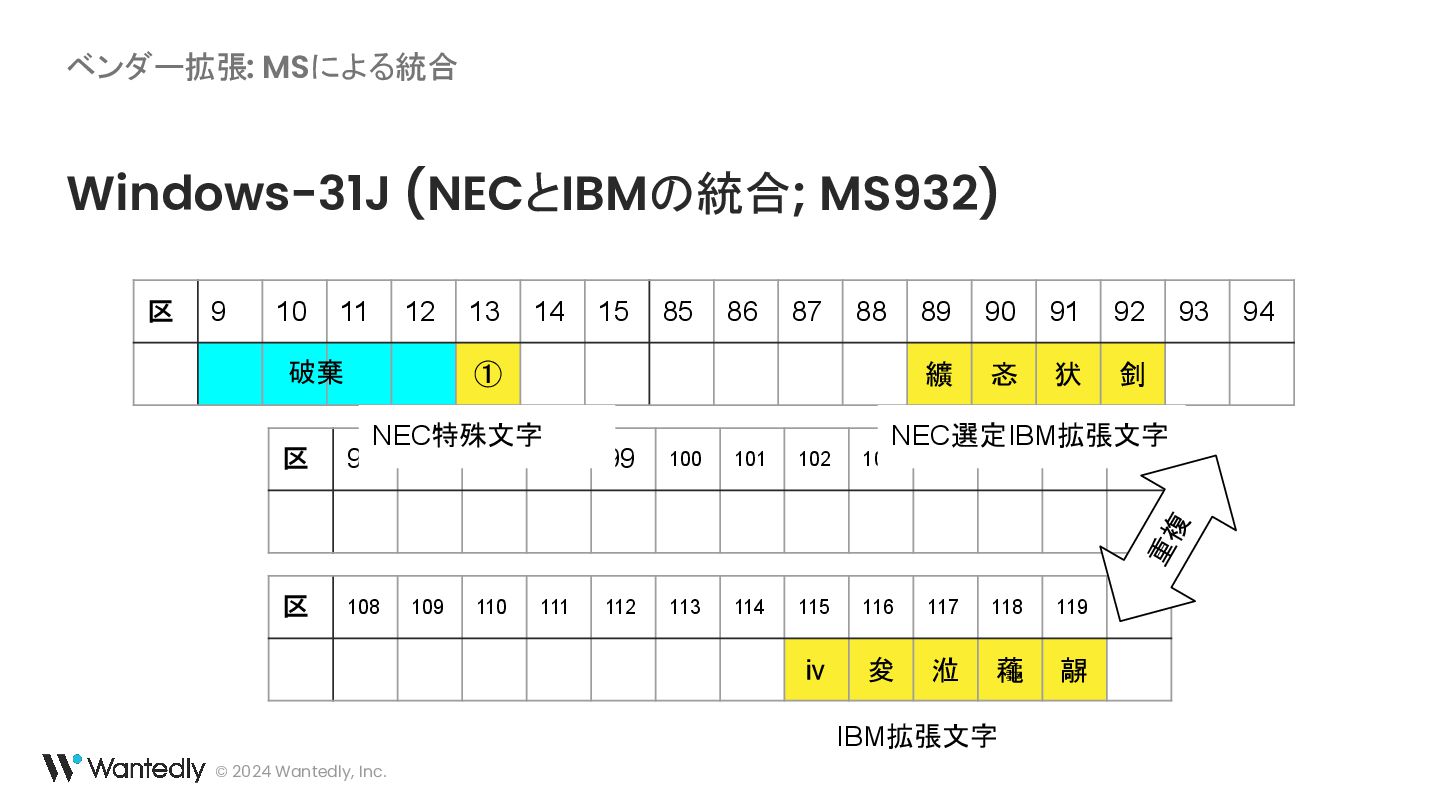{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
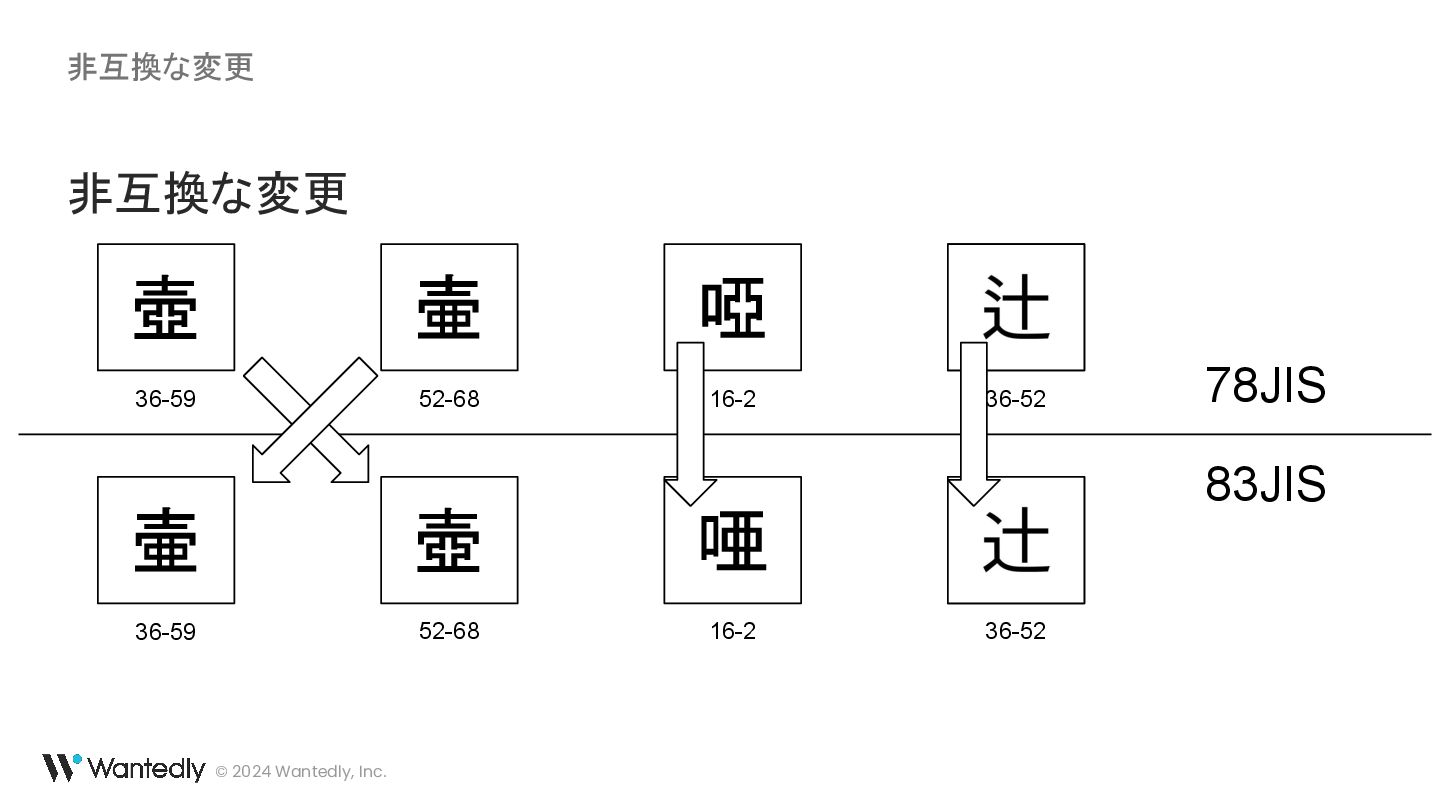{kind=link}
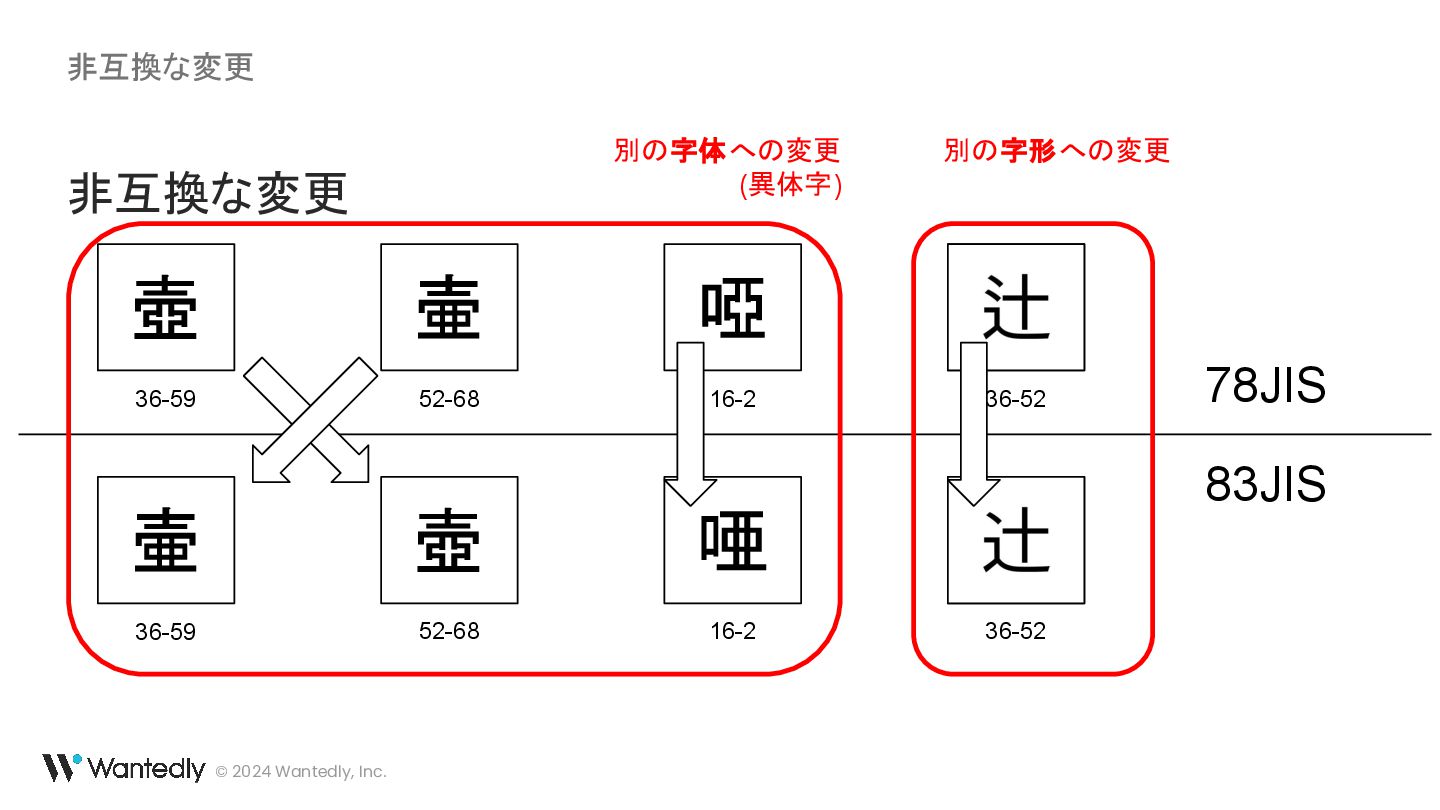{kind=link}
{kind=link}
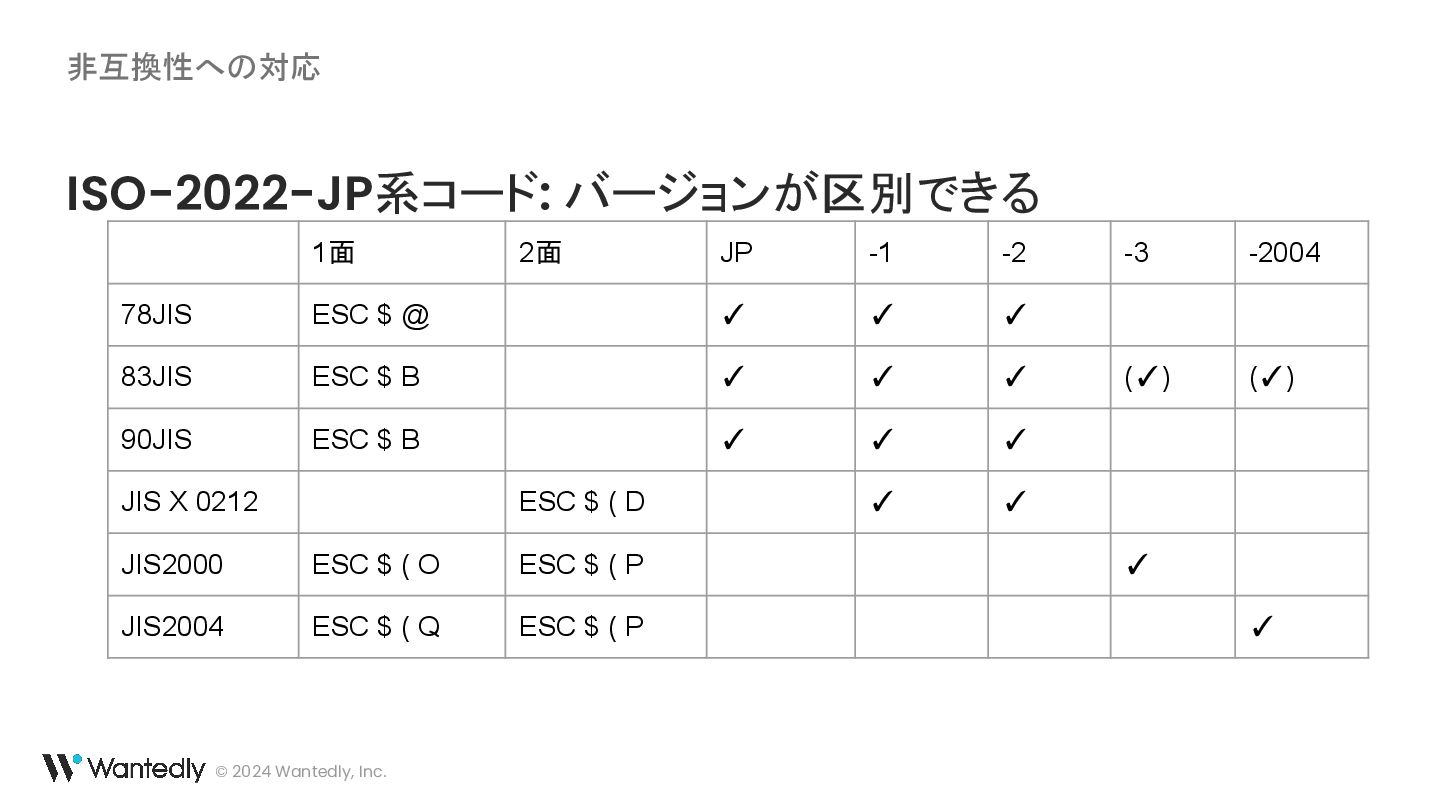{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
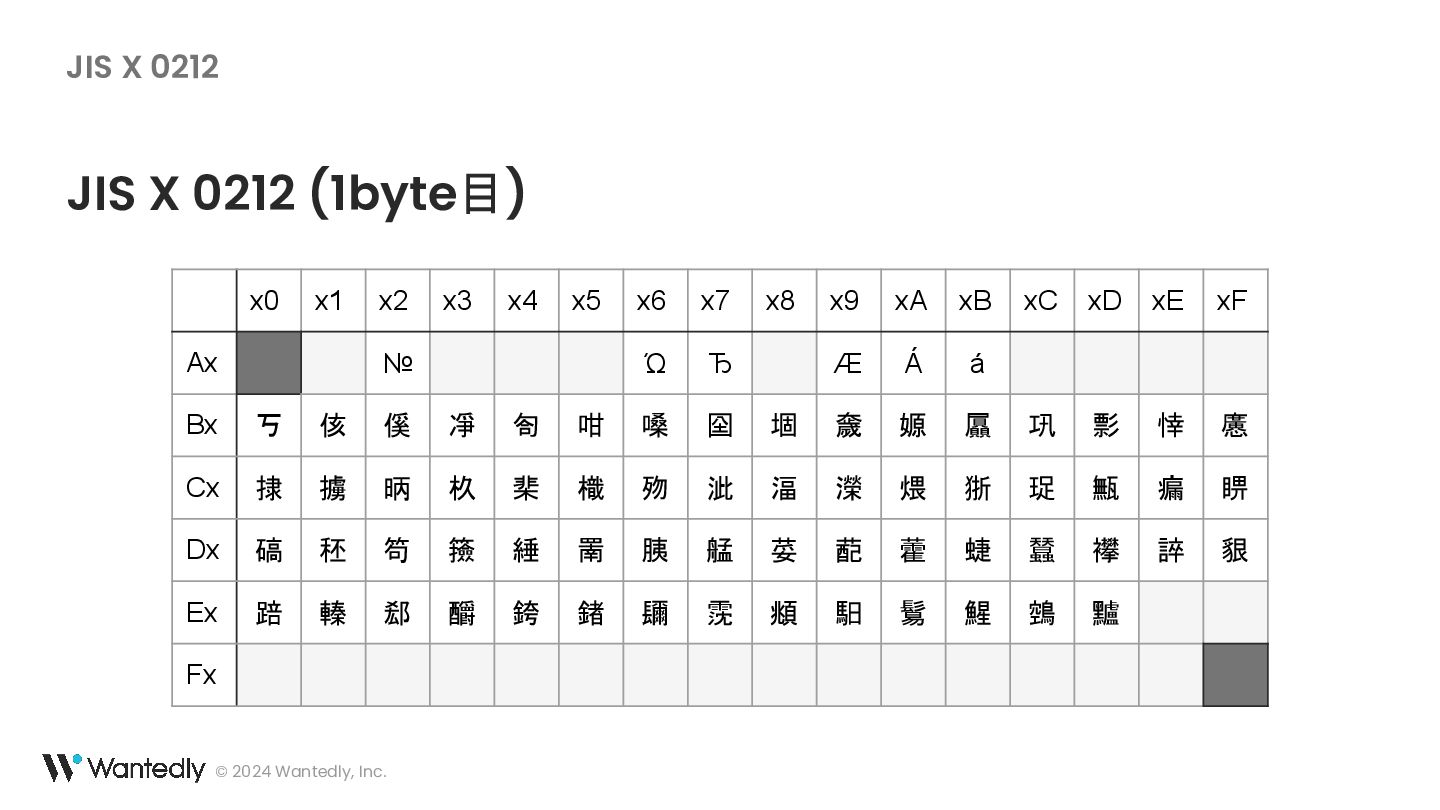{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
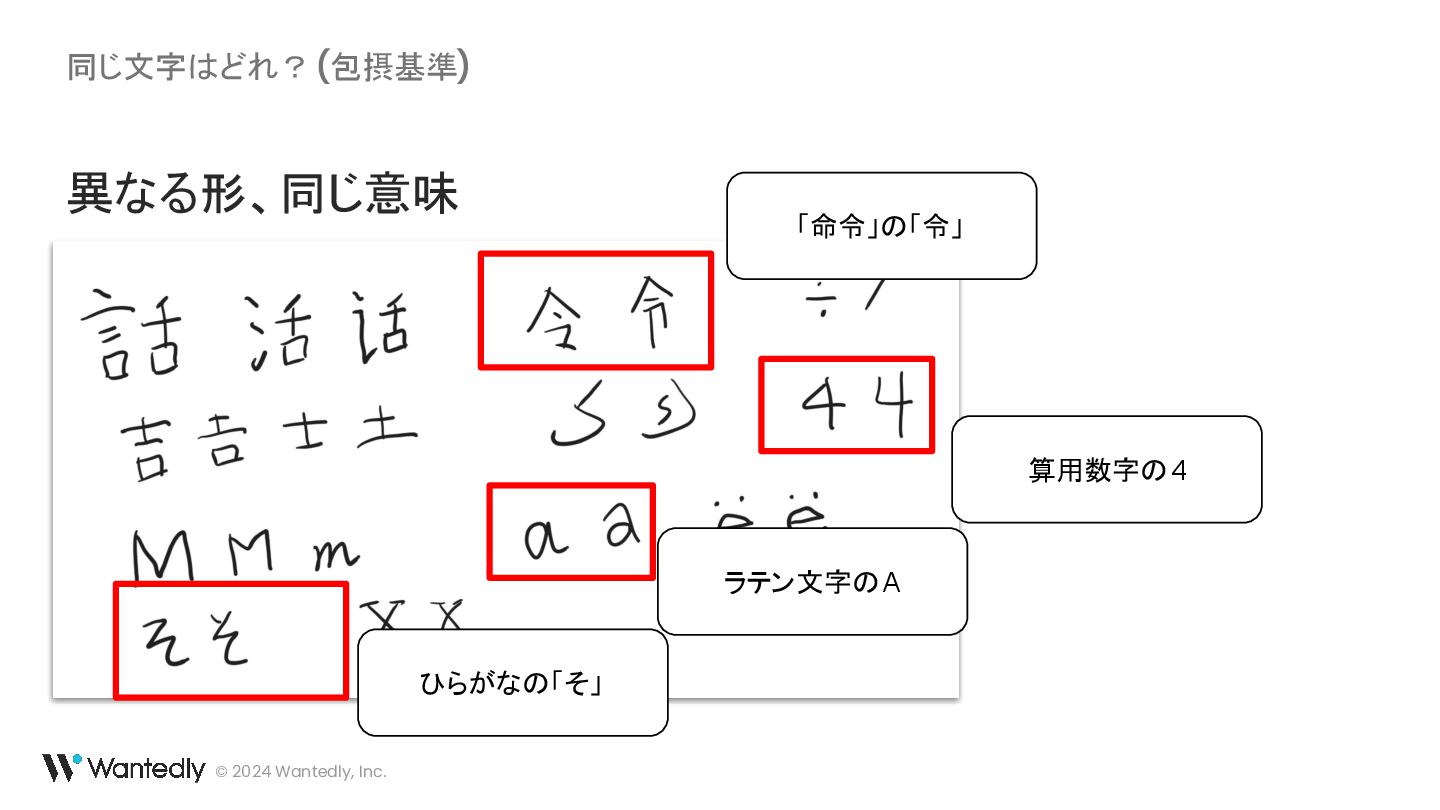{kind=link}
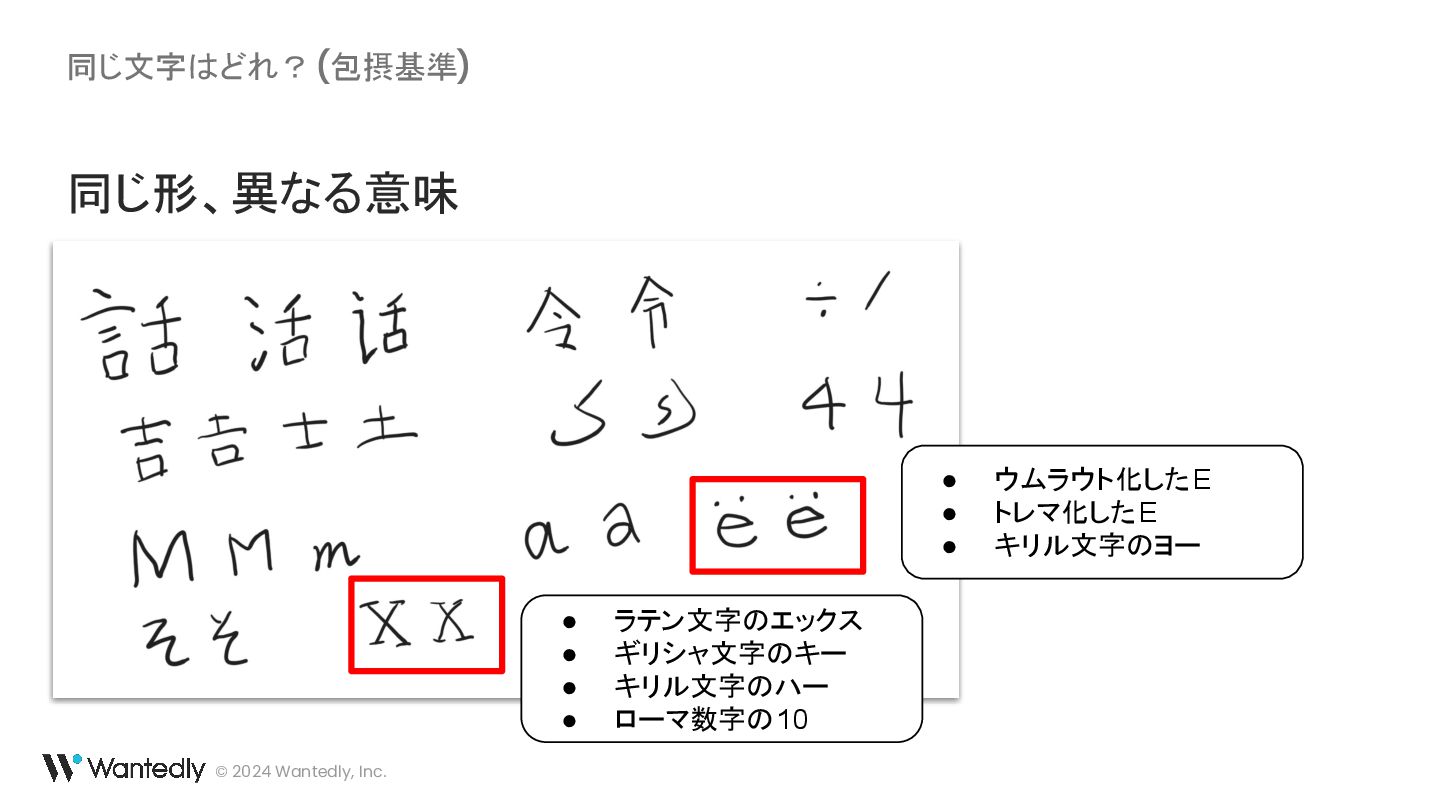{kind=link}
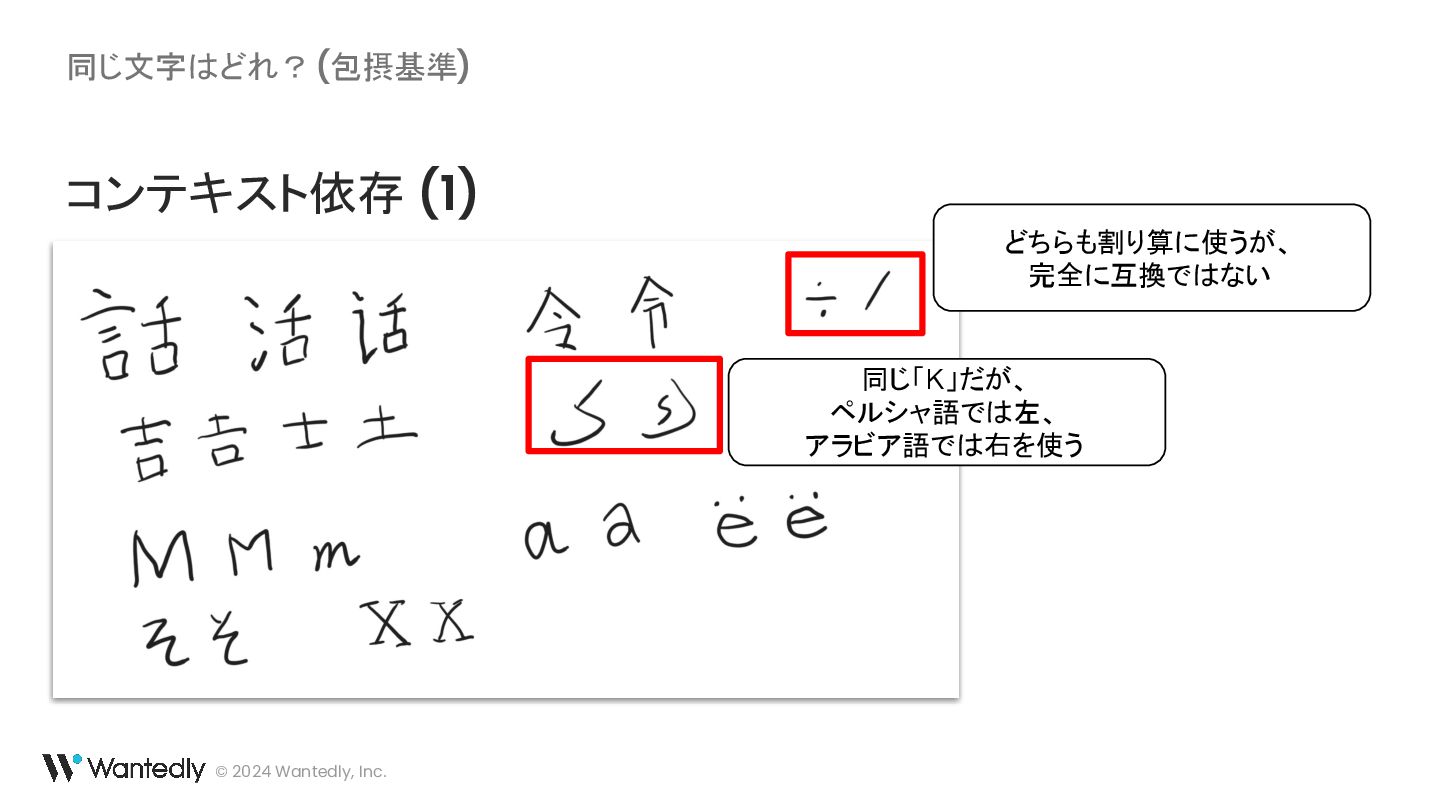{kind=link}
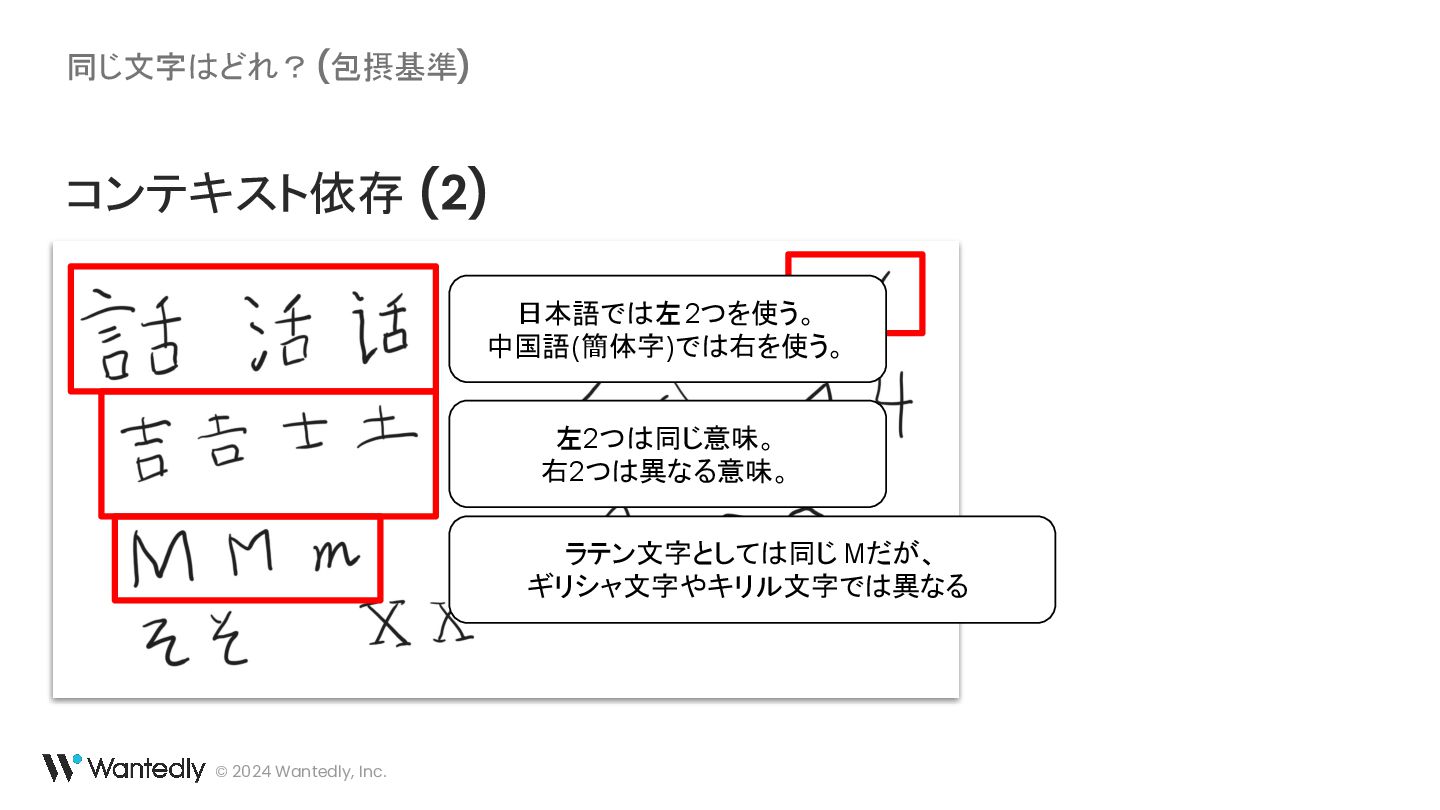{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
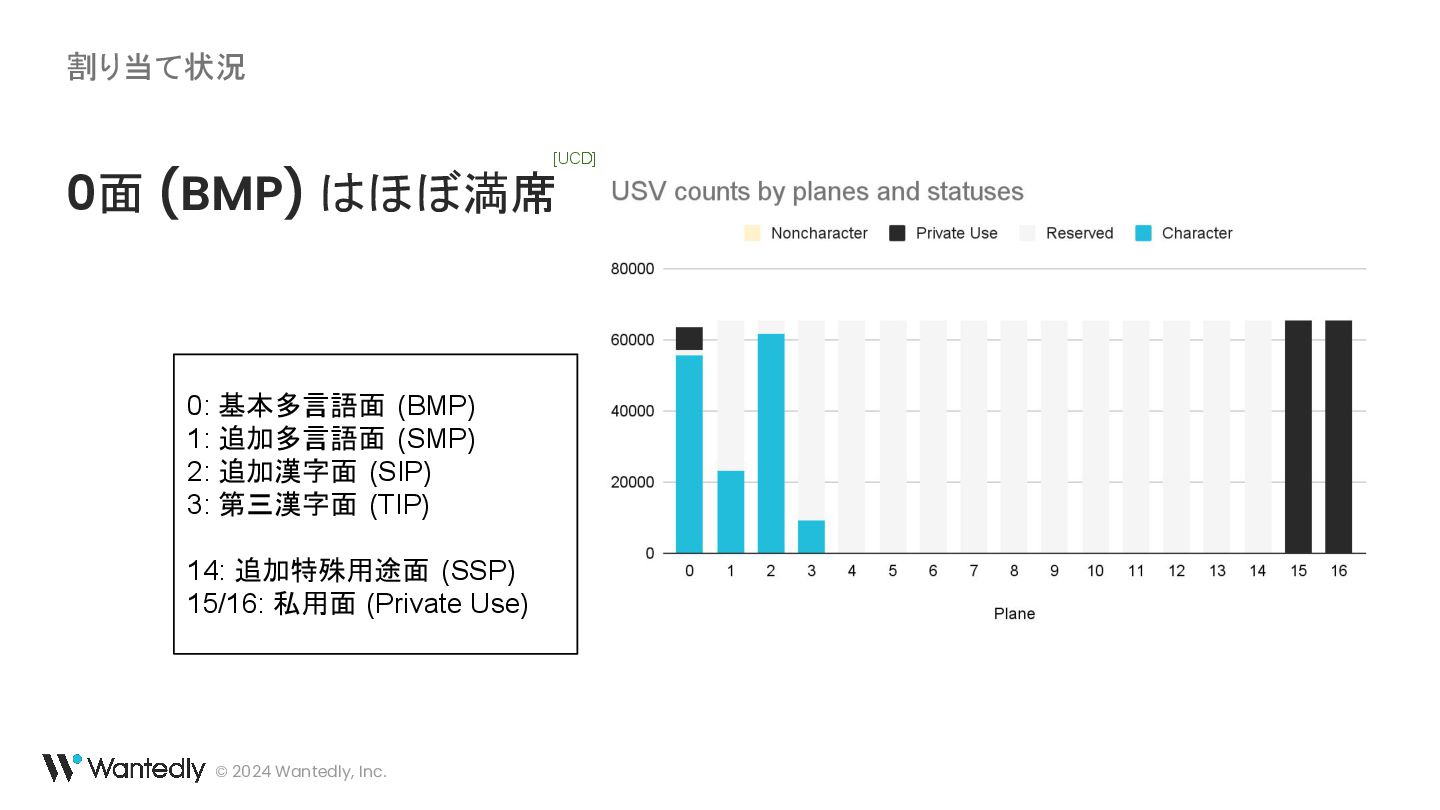
![© 2024 Wantedly, Inc. 割り当て状況 約14%が割り当て済み[UCD]](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_247.jpg){kind=link}
{kind=link}
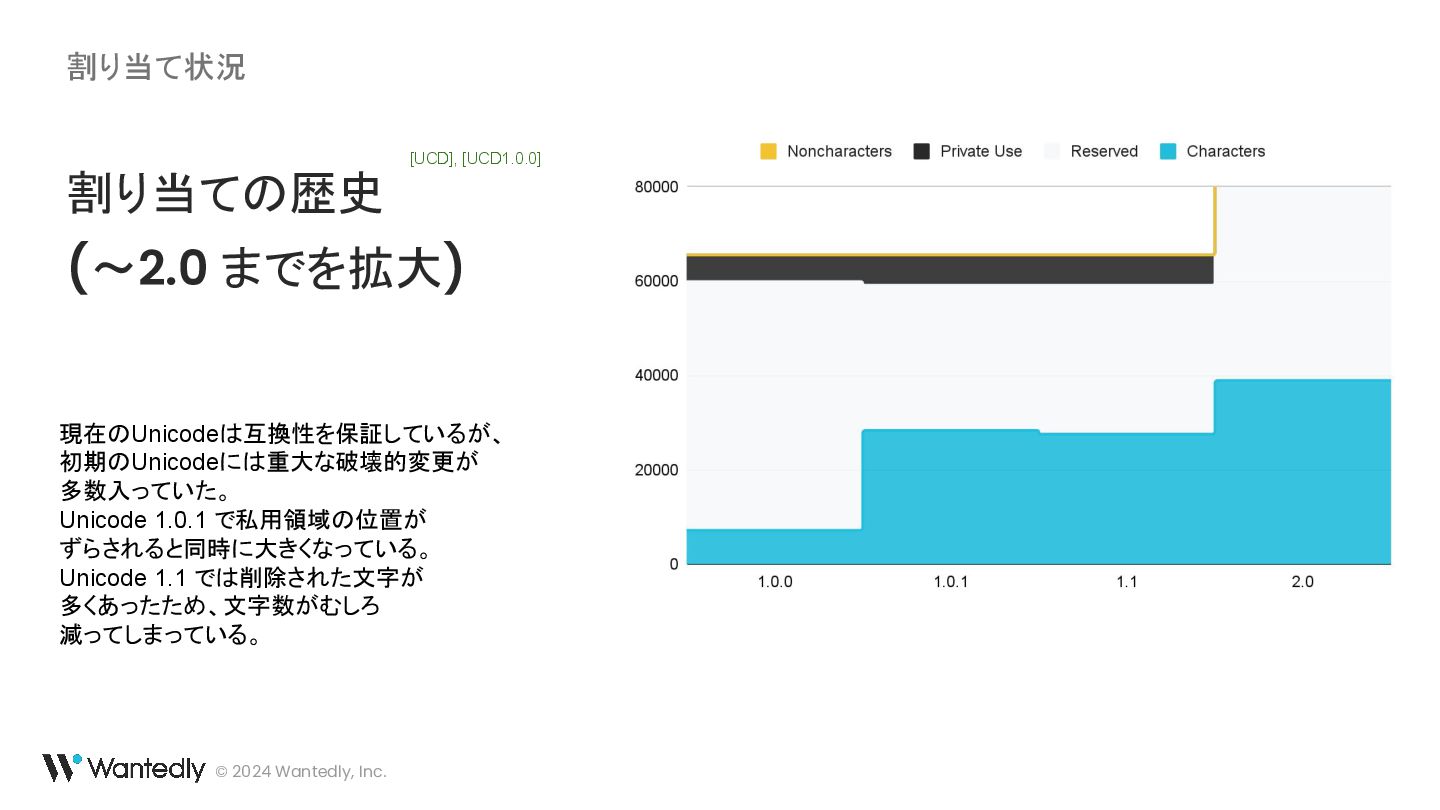
![© 2024 Wantedly, Inc. 割り当て状況 割り当ての歴史 [UCD], [UCD1.0.0]](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_249.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
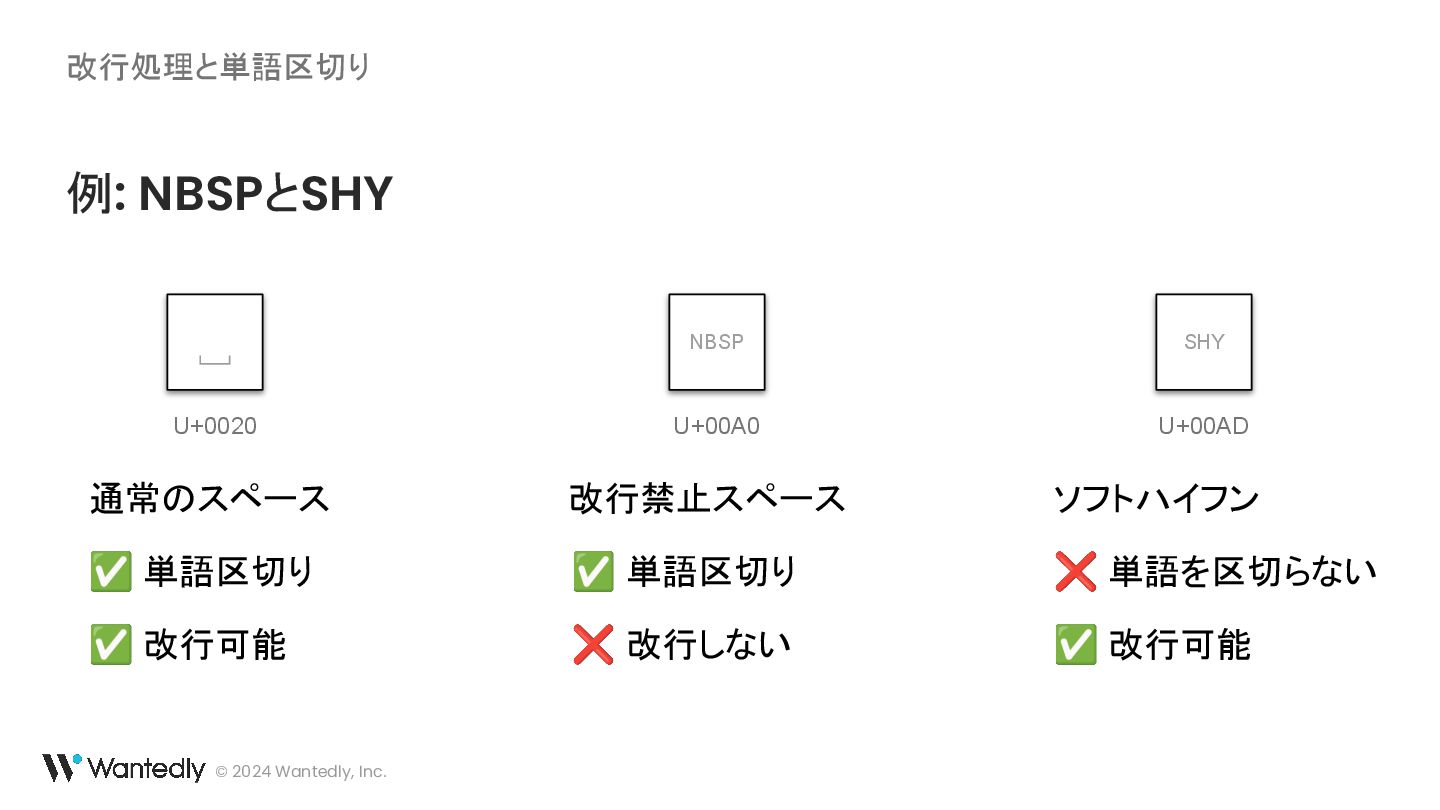{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
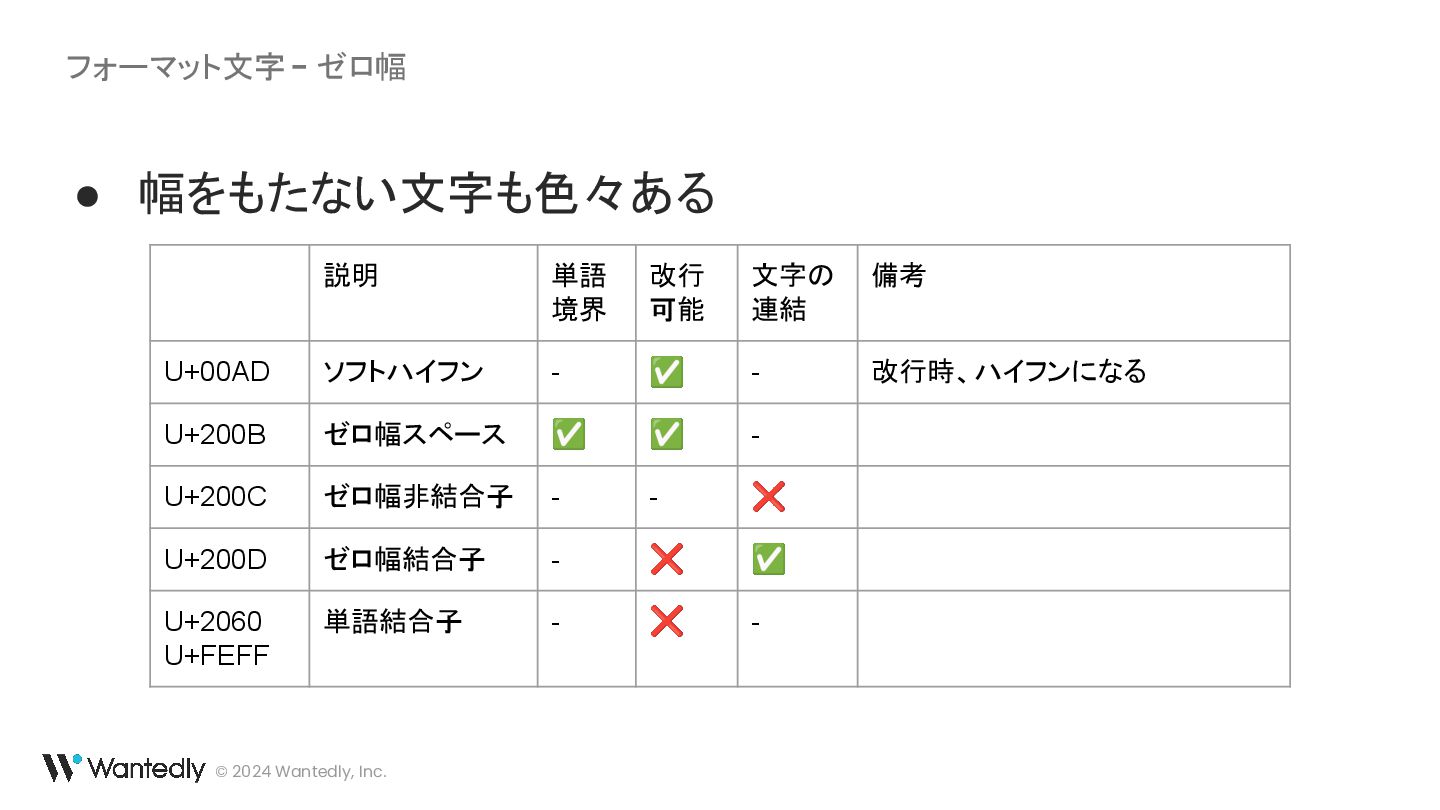{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
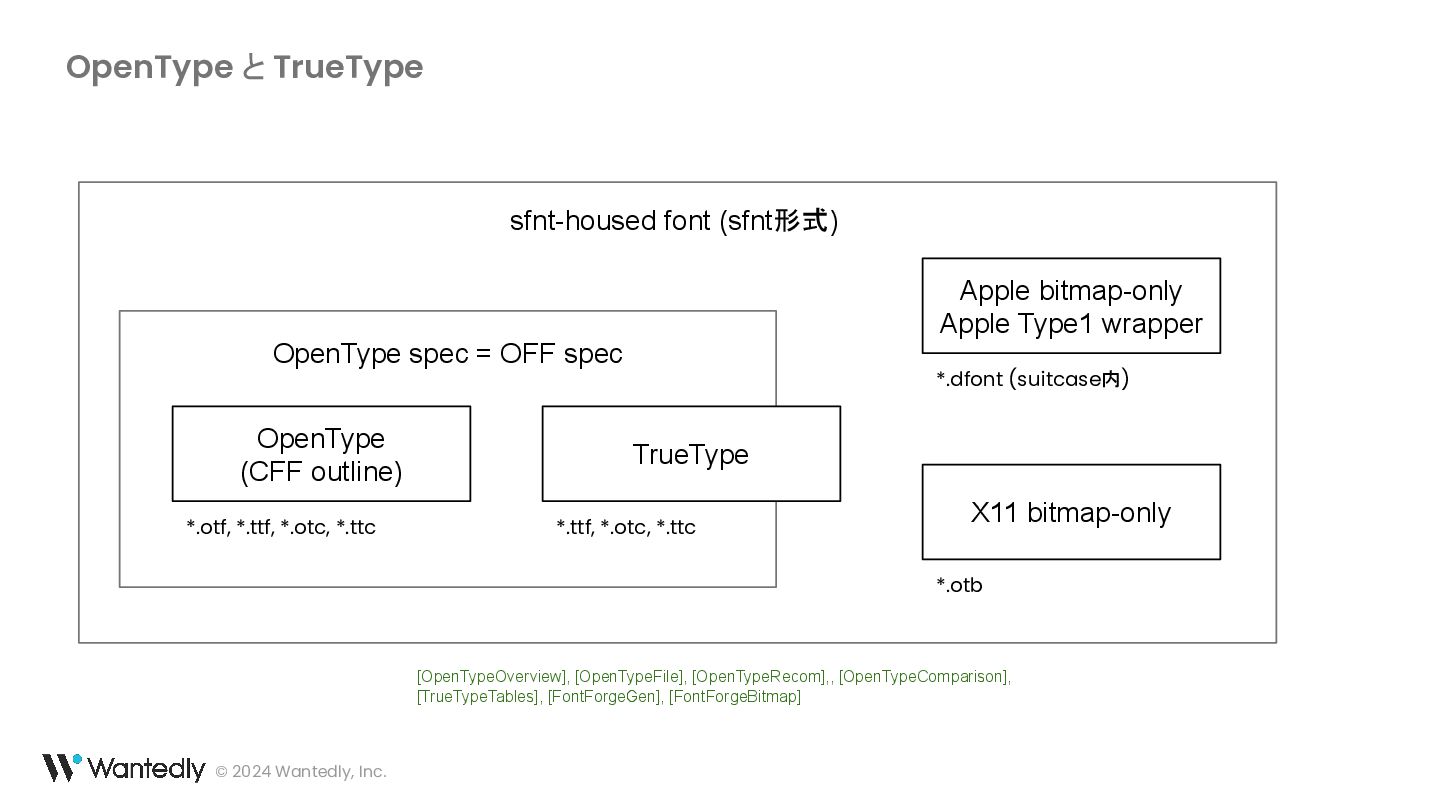{kind=link}
{kind=link}
{kind=link}
{kind=link}
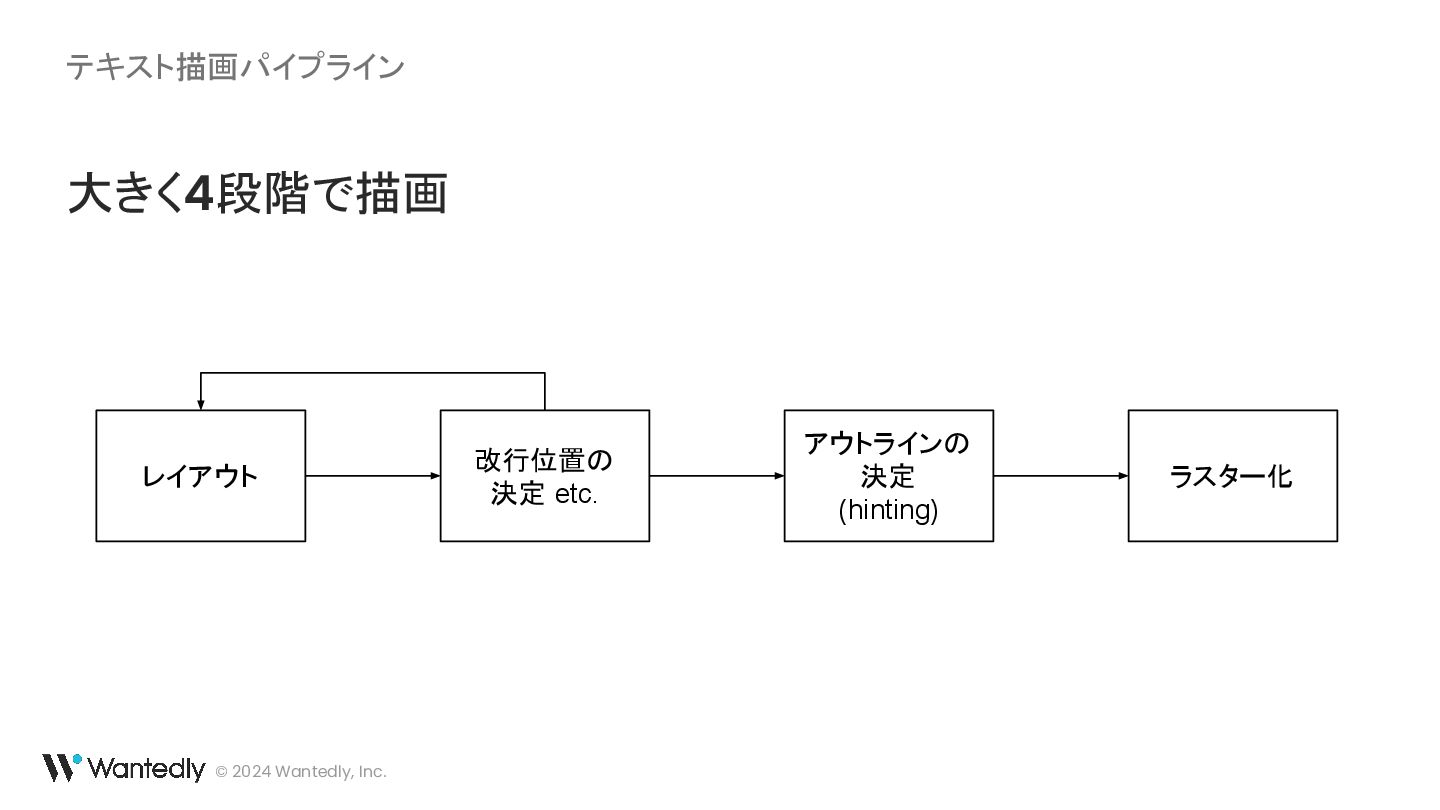{kind=link}
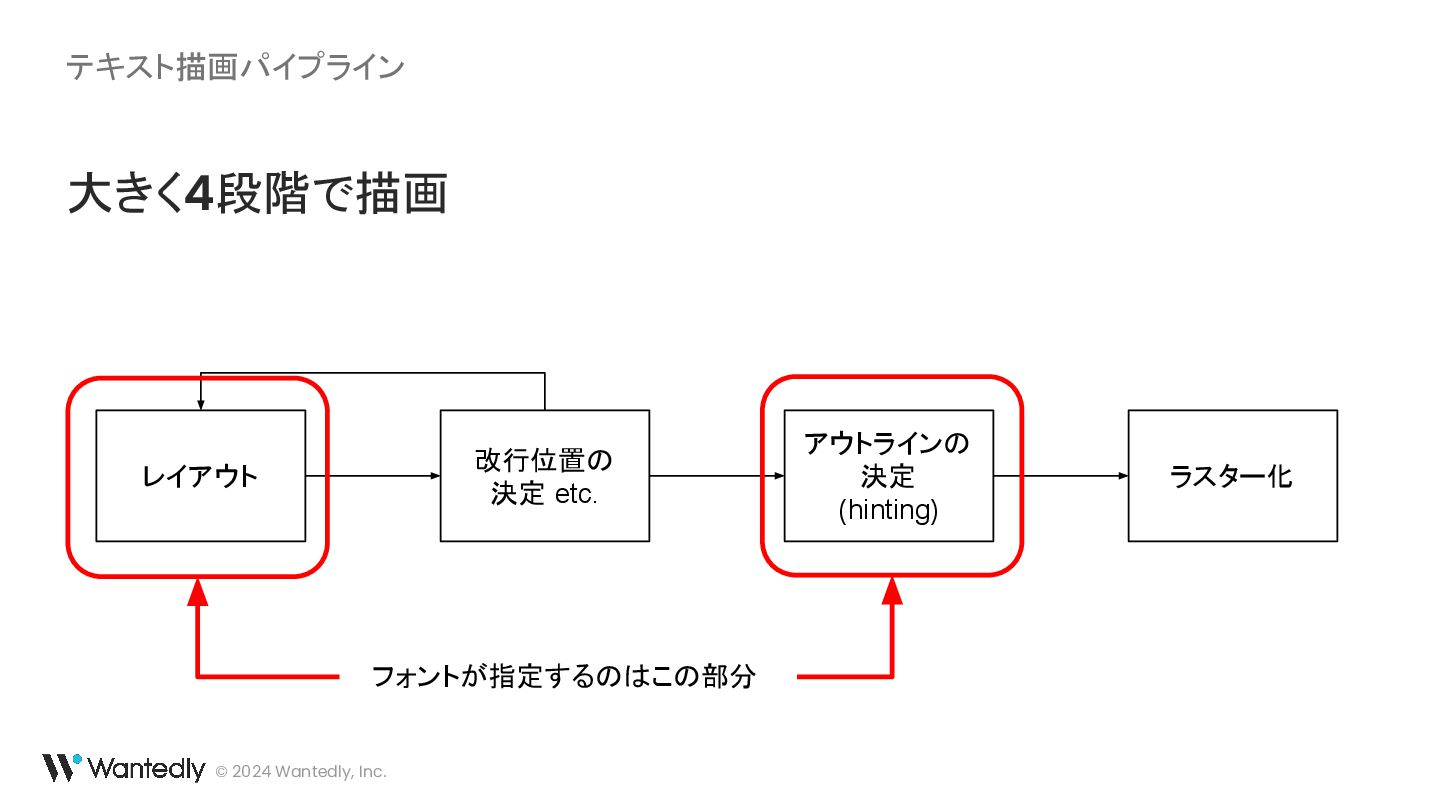{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
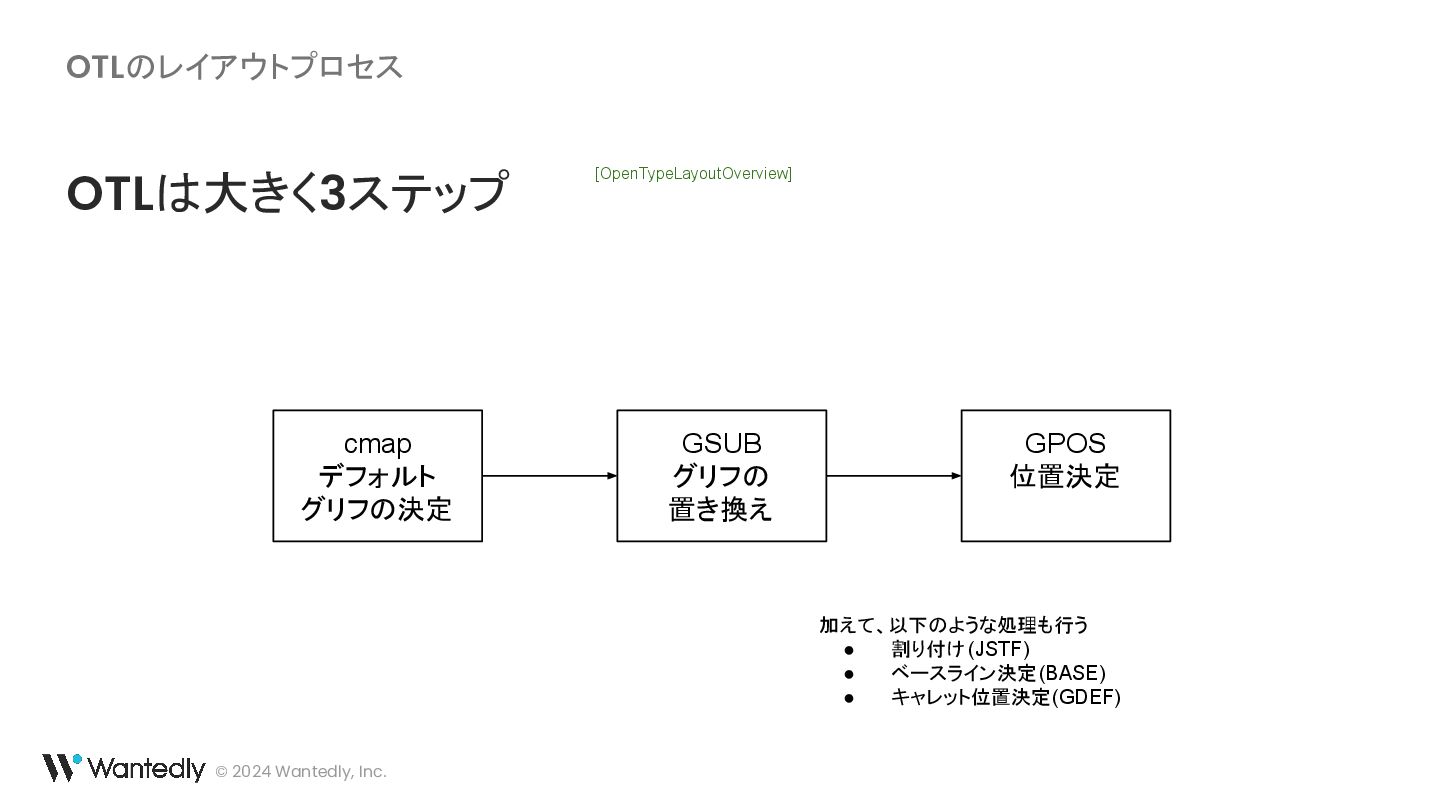{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2024 Wantedly, Inc. 文献 – 第1部その1 [Heide2009] Punched-Card Systems](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_483.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第2部その1 [ISO-IR] International Register](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_484.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その1 [Unicode] The Unicode®](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_485.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その2 [UAX#14] Unicode® Standard](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_486.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その3 [UAX#44] Unicode® Standard](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_487.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その4 [UTS#18] Unicode® Technical](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_488.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その4 [UTS#6] Unicode® Technical](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_489.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その5 [RFC2152] RFC 2152](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_490.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その6 [ISO10646] ISO/IEC 10646:2020](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_491.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その7 [ECMA262] ECMA-262 ECMAScript®](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_492.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その8 [BitesizeTypography3] Fonts and](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_493.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その9 [OpenTypeFAQ] OpenType overview](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_494.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その10 [OpenType] OpenType specification](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_495.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その11 [TrueType] Fonts -](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_496.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その12 [FontForgeGen] Generate Font](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_497.jpg){kind=link}
![© 2024 Wantedly, Inc. 文献 – 第3部その13 [RFC8081] RFC 8081](https://files.speakerdeck.com/presentations/caaaeffac5f04f4c9254b742b9b36fb3/slide_498.jpg){kind=link}