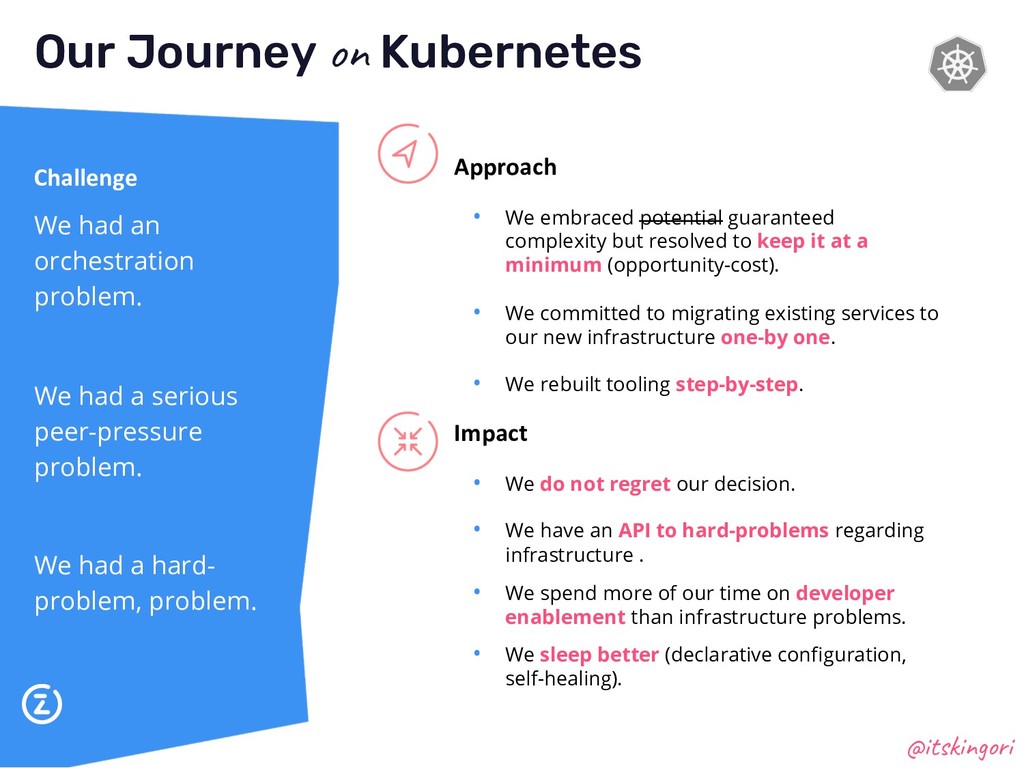
We made the decision in late 2015 to move all our applications to containerised environments managed by Kubernetes. It took roughly 3 years to complete that migration. During that journey we learnt a lot about containerisation, distributed systems, complicated migrations and automation of systems managing over 85 developers. This talk was about sharing some of the key principles and ideas that guided us. It touched lightly on Kubernetes from a technical point of view and focused on sharing key ideas.
Links:
• Conference: DevOpsDays 2019 (Cape Town) - Full Talk
• Program: https://devopsdays.org/events/2019-cape-town/program/
• Video: https://youtu.be/sHZVD0fmVWg
PS: I'd recommend you watch the talk with speed set to 1.5x. I really need to work on my speed. 🙈
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}