are designed as highly capable reasoners, with configurable thinking modes. • Extended Multimodalities: Processes Text, Image with variable aspect ratio and resolution support (all models), Video, and Audio (featured natively on the E2B and E4B models). • Increased Context Window: Small models feature a 128K context window, while the medium models support 256K. • Enhanced Coding & Agentic Capabilities: Achieves notable improvements in coding benchmarks alongside built-in function-calling support, powering highly capable autonomous agents. • Native System Prompt Support: Gemma 4 introduces built-in support for the system role, enabling more structured and controllable conversations. https://ai.google.dev/gemma/docs/core 5
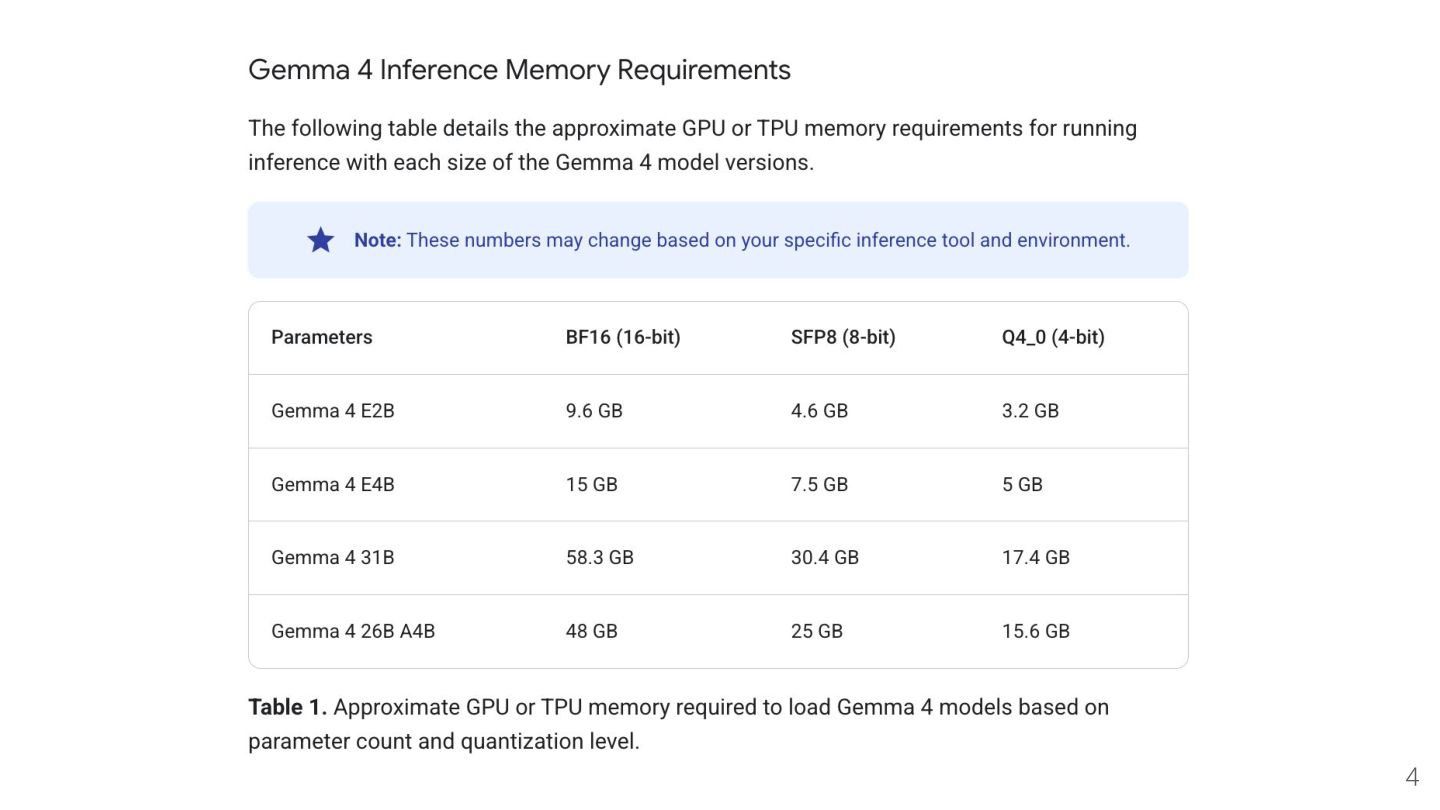
(E2B and E4B): The "E" stands for "effective" parameters. The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but only used for quick lookups, which is why the total memory required to load static weights is higher than the effective parameter count suggests. • The MoE Architecture (26B A4B): The 26B is a Mixture of Experts model. While it only activates 4 billion parameters per token during generation, all 26 billion parameters must be loaded into memory to maintain fast routing and inference speeds. This is why its baseline memory requirement is much closer to a dense 26B model than a 4B model. • Base Weights Only: The estimates in the preceding table only account for the memory required to load the static model weights. They don't include the additional VRAM needed for supporting software or the context window. • Context Window (KV Cache): Memory consumption will increase dynamically based on the total number of tokens in your prompt and the generated response. Larger context windows require significantly more VRAM on top of the base model weights. • Fine-Tuning Overhead: Memory requirements for fine-tuning Gemma models are drastically higher than for standard inference. Your exact footprint will depend heavily on the development framework, batch size, and whether you are using full-precision tuning versus a Parameter-Efficient Fine-Tuning (PEFT) method like Low-Rank Adaptation (LoRA). https://ai.google.dev/gemma/docs/core 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
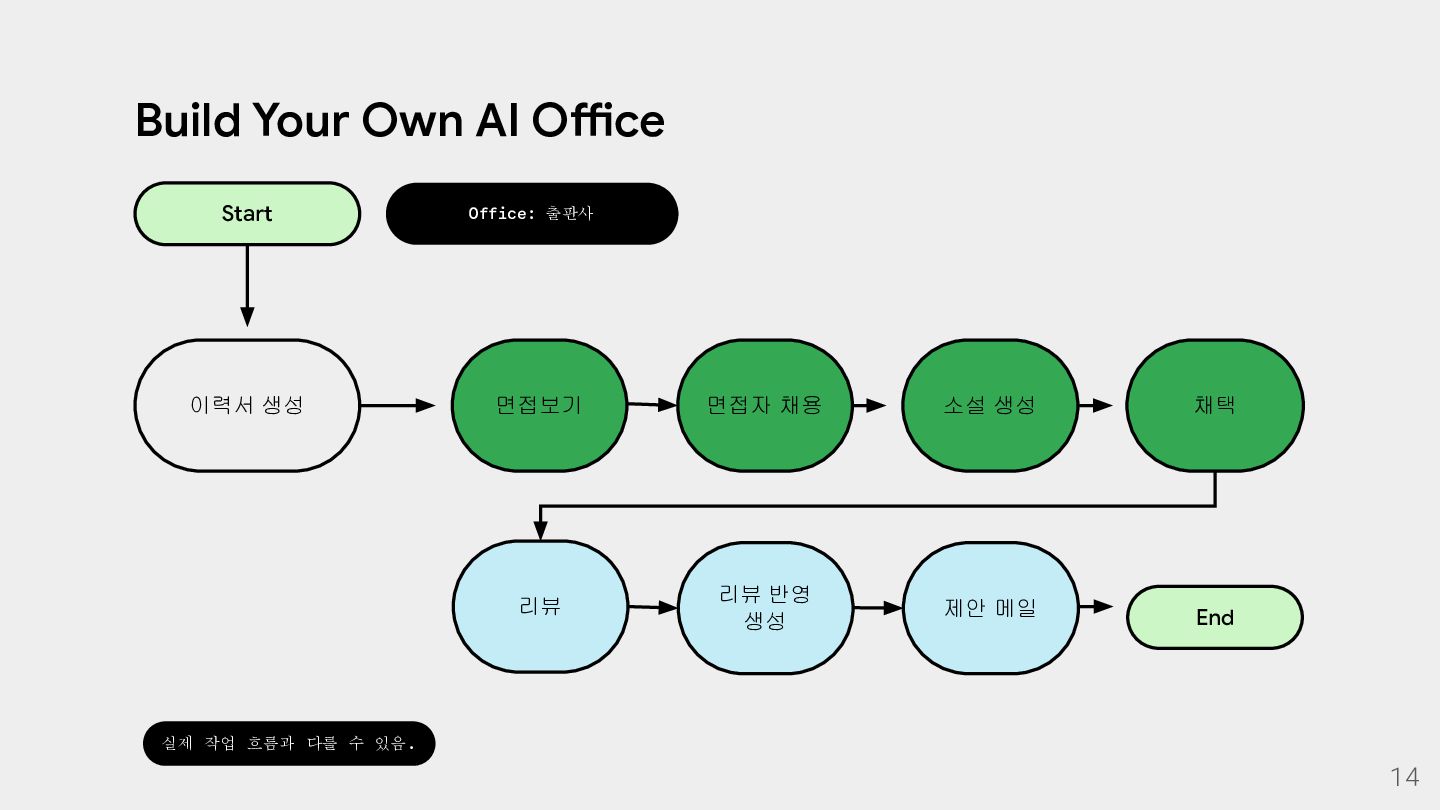{kind=link}
{kind=link}
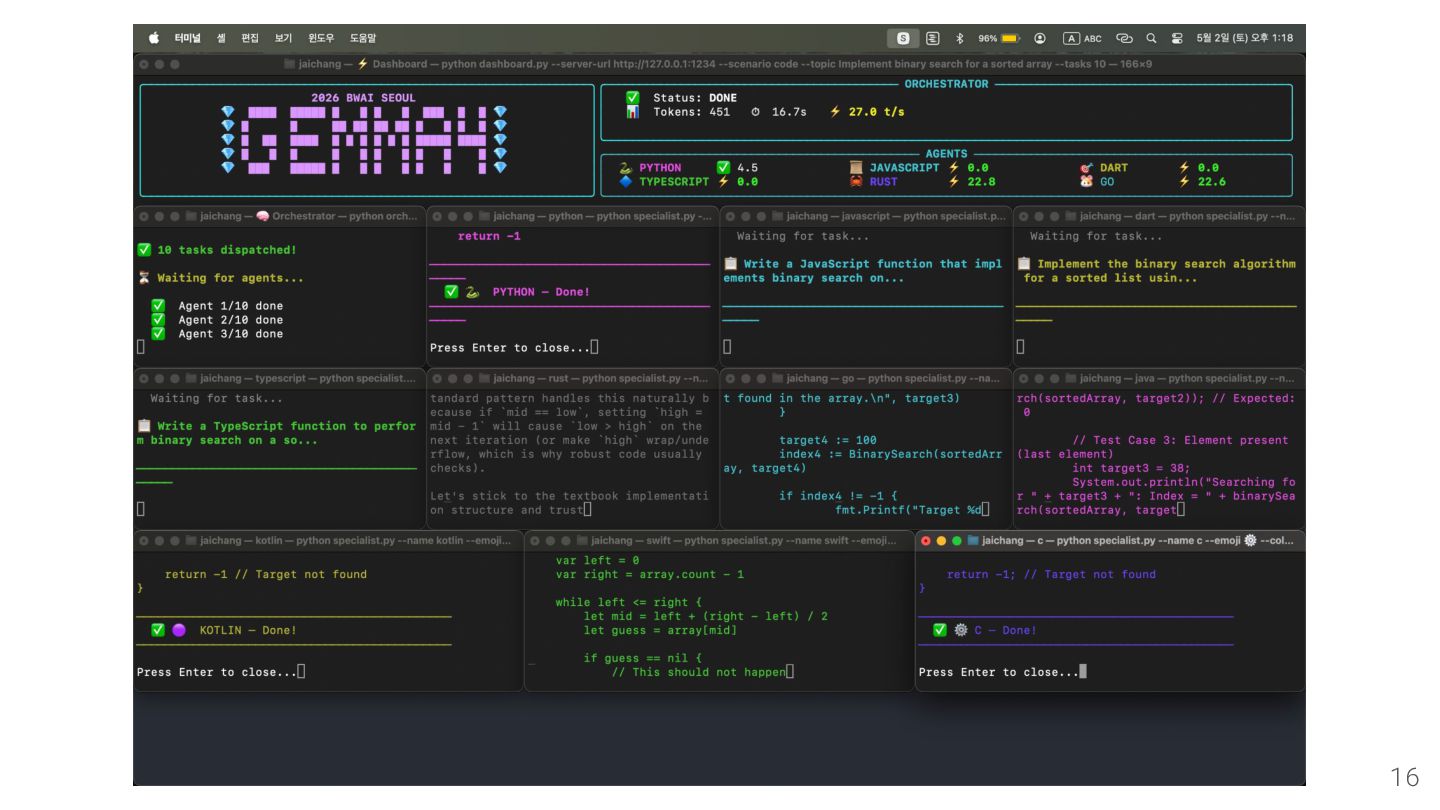{kind=link}
{kind=link}
{kind=link}