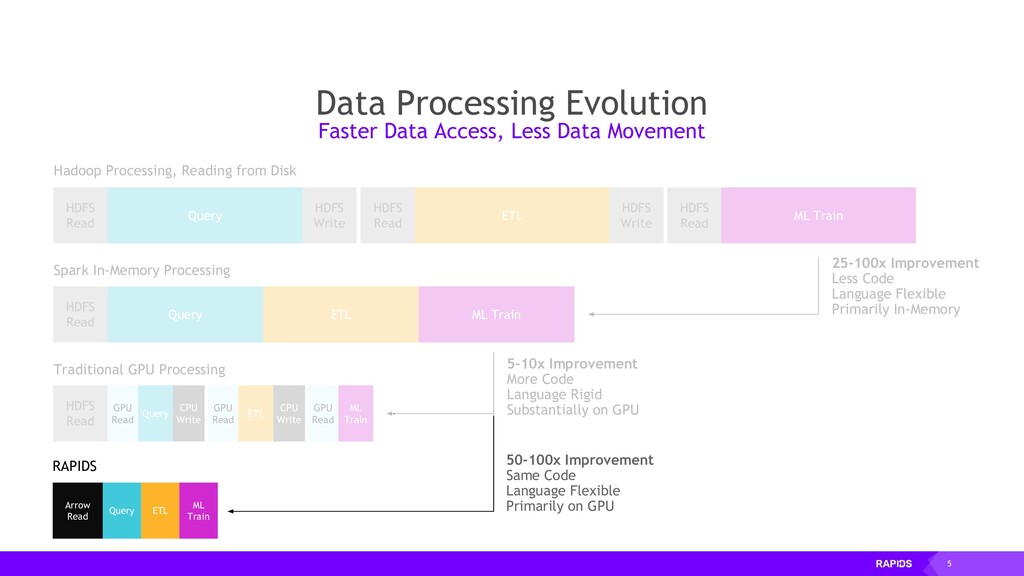
Read HDFS Write HDFS Read HDFS Write HDFS Read Query ETL ML Train HDFS Read Query ETL ML Train HDFS Read GPU Read Query CPU Write GPU Read ETL CPU Write GPU Read ML Train 5-10x Improvement More Code Language Rigid Substantially on GPU Traditional GPU Processing Hadoop Processing, Reading from Disk Spark In-Memory Processing Data Processing Evolution Faster Data Access, Less Data Movement RAPIDS Arrow Read ETL ML Train Query 50-100x Improvement Same Code Language Flexible Primarily on GPU
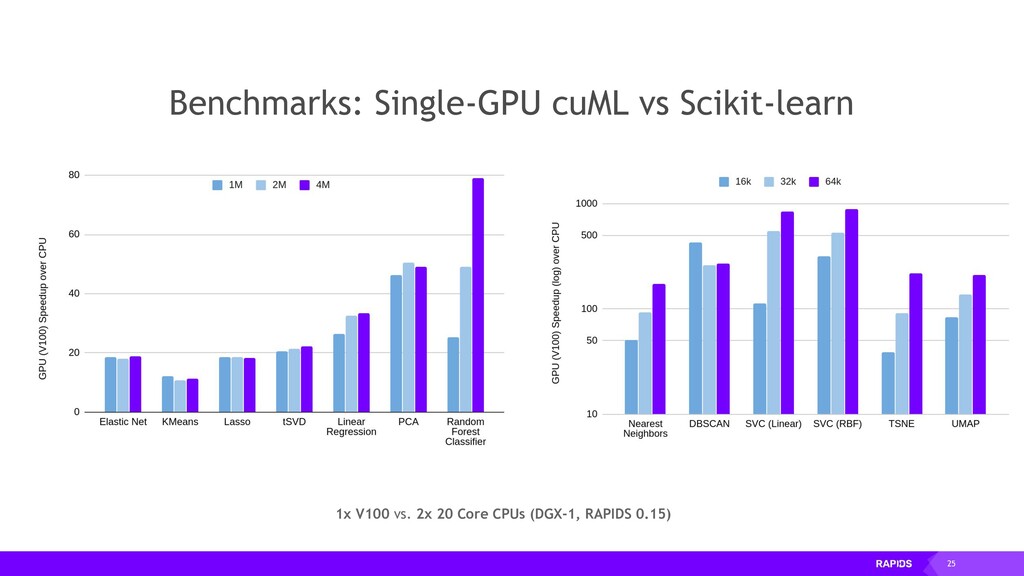
Data Prep) Data Conversion XGBoost Faster Speeds, Real World Benefits Faster Data Access, Less Data Movement cuIO/cuDF – Load and Data Preparation XGBoost Machine Learning End-to-End Benchmark 200GB CSV dataset; Data prep includes joins, variable transformations CPU Cluster Configuration CPU nodes (61 GiB memory, 8 vCPUs, 64-bit platform), Apache Spark RAPIDS Version RAPIDS 0.17 A100 Cluster Configuration 16 A100 GPUs (40GB each)
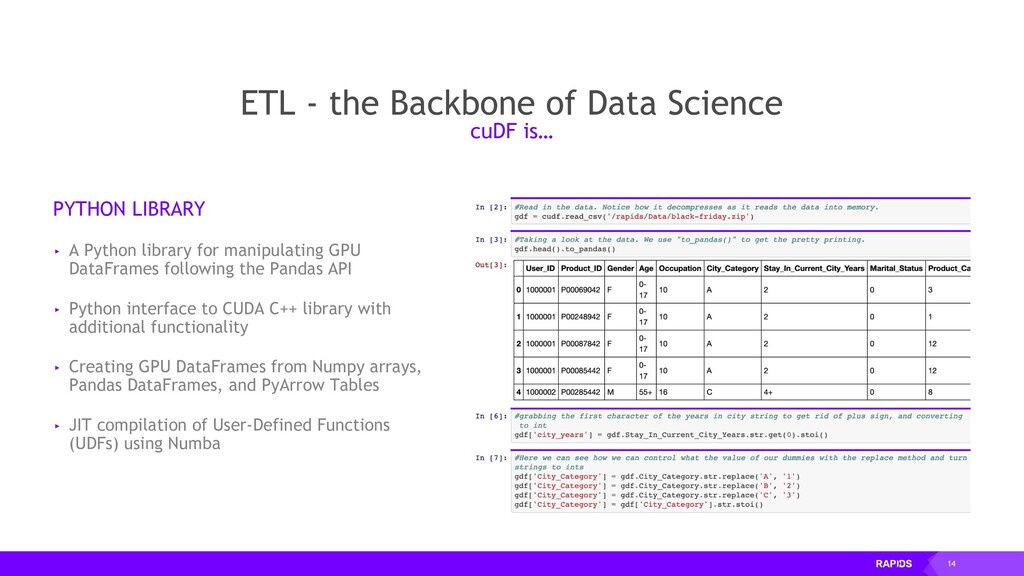
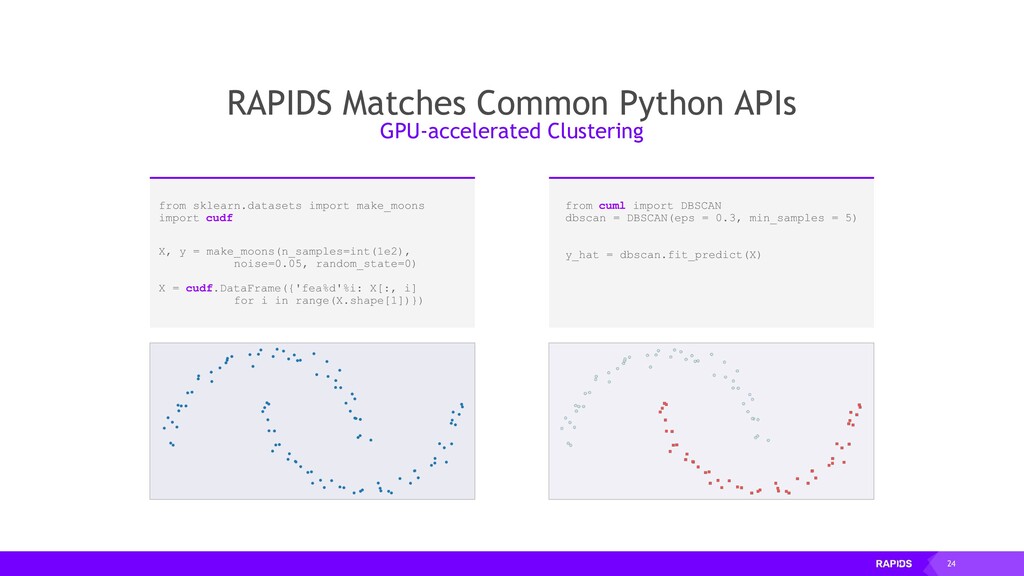
▸ A Python library for manipulating GPU DataFrames following the Pandas API ▸ Python interface to CUDA C++ library with additional functionality ▸ Creating GPU DataFrames from Numpy arrays, Pandas DataFrames, and PyArrow Tables ▸ JIT compilation of User-Defined Functions (UDFs) using Numba cuDF is…
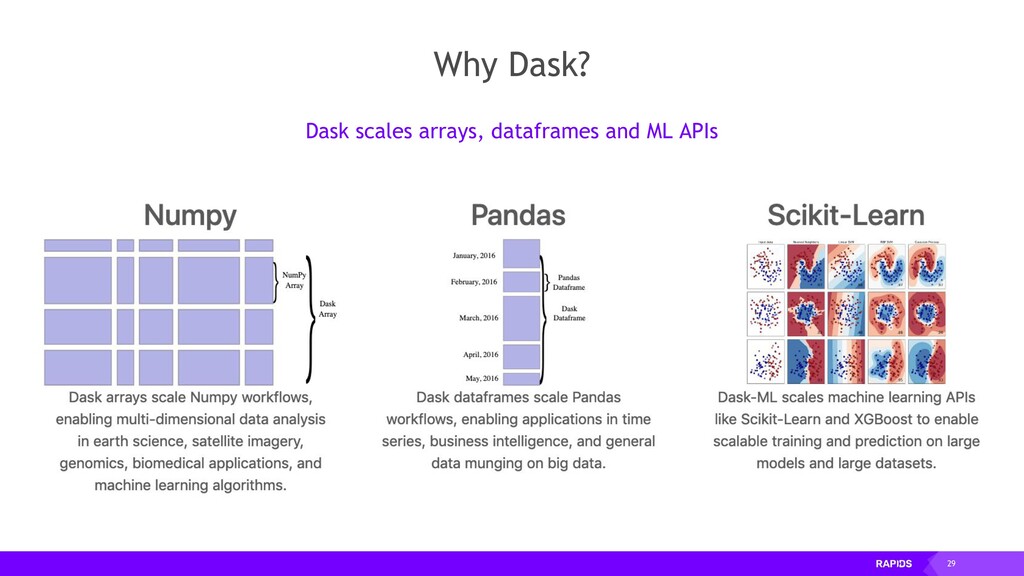
use on a laptop ▸ Scales out to thousand node clusters ▸ Modularly built for acceleration DEPLOYABLE ▸ HPC: SLURM, PBS, LSF, SGE ▸ Cloud: Kubernetes ▸ Hadoop/Spark: Yarn PYDATA NATIVE ▸ Easy Migration: Built on top of NumPy, Pandas Scikit-Learn, etc ▸ Easy Training: With the same API POPULAR ▸ Most Common parallelism framework today in the PyData and SciPy community ▸ Millions of monthly Downloads and Dozens of Integrations NumPy, Pandas, Scikit-Learn, Numba and many more Single CPU core In-memory data PYDATA Multi-core and distributed PyData NumPy -> Dask Array Pandas -> Dask DataFrame Scikit-Learn -> Dask-ML … -> Dask Futures DASK Scale Out / Parallelize
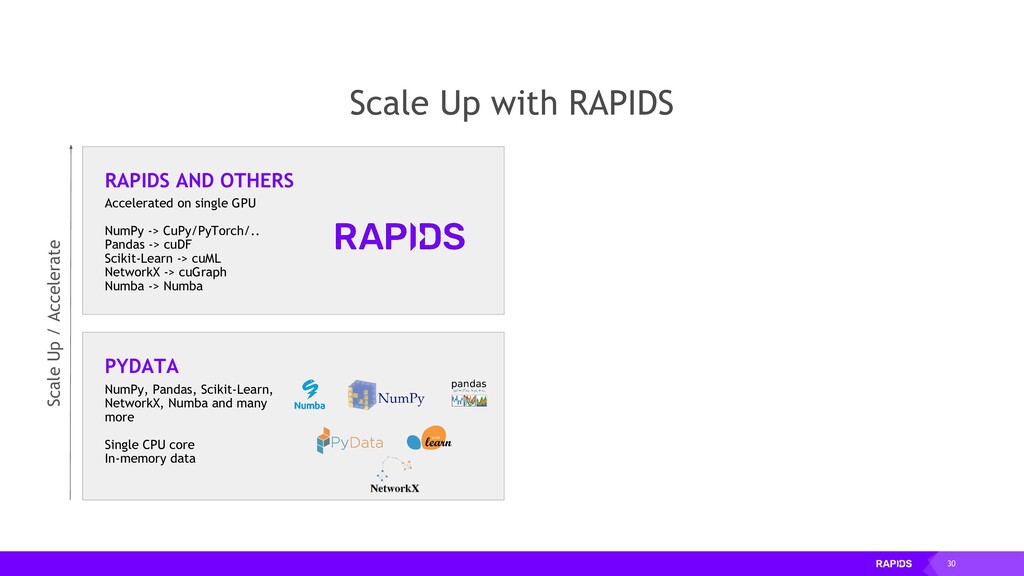
cuDF Scikit-Learn -> cuML NetworkX -> cuGraph Numba -> Numba RAPIDS AND OTHERS NumPy, Pandas, Scikit-Learn, NetworkX, Numba and many more Single CPU core In-memory data PYDATA Scale Up / Accelerate Scale Up with RAPIDS
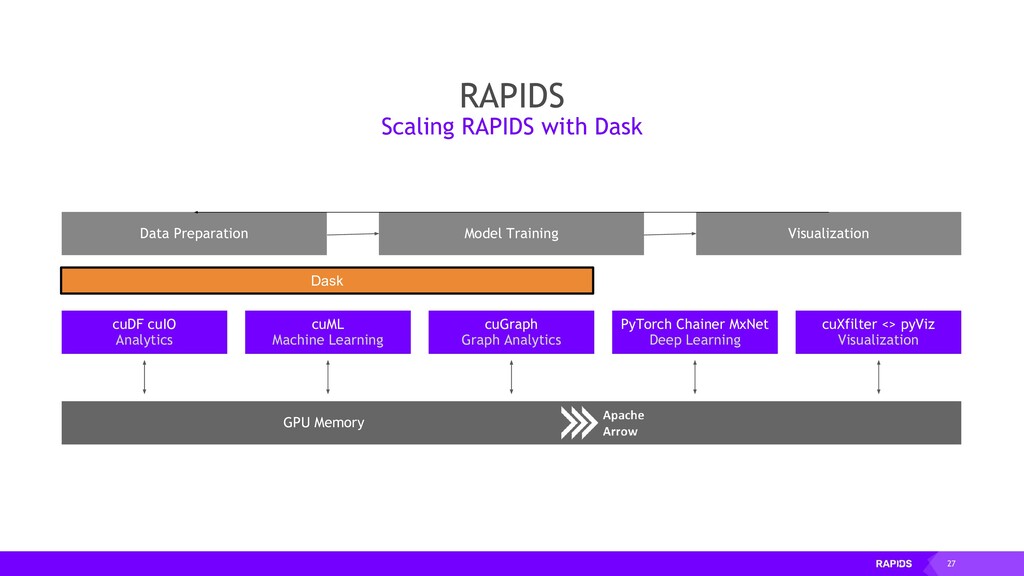
cuDF Scikit-Learn -> cuML NetworkX -> cuGraph Numba -> Numba RAPIDS AND OTHERS Multi-GPU On single Node (DGX) Or across a cluster RAPIDS + DASK WITH OPENUCX NumPy, Pandas, Scikit-Learn, Numba and many more Single CPU core In-memory data PYDATA Multi-core and distributed PyData NumPy -> Dask Array Pandas -> Dask DataFrame Scikit-Learn -> Dask-ML … -> Dask Futures DASK Scale Up / Accelerate Scale Out / Parallelize Scale Out with RAPIDS + Dask with OpenUCX
Graph analytics ▸ Compatible with NetworkX, SciPy and CuPy cuSpatial ▸ Spatial Analytics ▸ Point-in-polygon and distance calculations cuSignal ▸ Signal processing NVTabular ▸ ETL library for recommender systems A Bigger, Better, Stronger Ecosystem for All CLX/cyBERT ▸ Cyber log acceleration ▸ Utilizes NLP and transformer architectures for cybersecurity tasks Data vizualization ▸ Cuxfilter and Plotly Dash ▸ Part of the pyViz community BlazingSQL ▸ GPU accelerated SQL engine built on top of RAPIDS Streamz ▸ Distributed stream processing
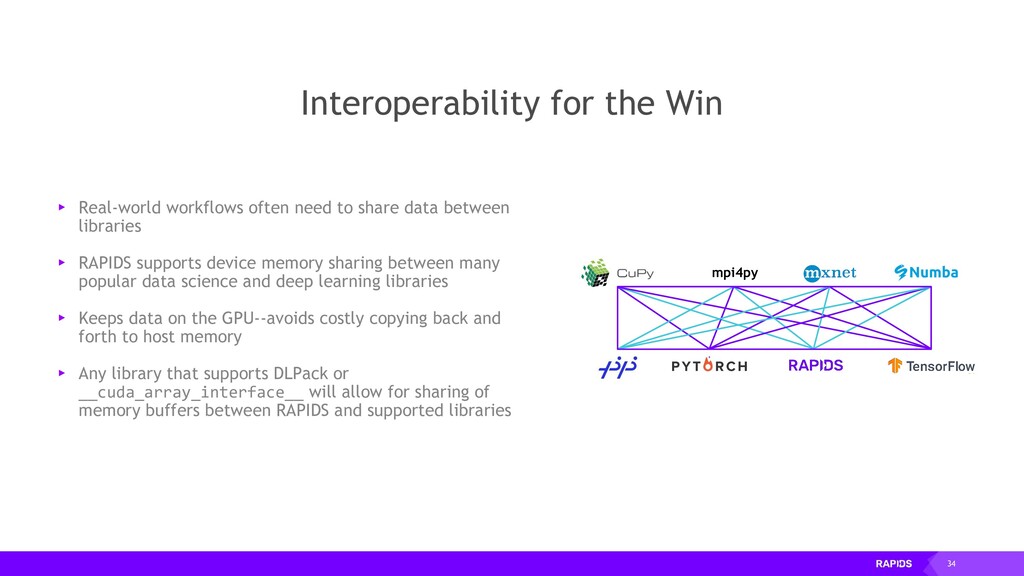
need to share data between libraries ▸ RAPIDS supports device memory sharing between many popular data science and deep learning libraries ▸ Keeps data on the GPU--avoids costly copying back and forth to host memory ▸ Any library that supports DLPack or __cuda_array_interface__ will allow for sharing of memory buffers between RAPIDS and supported libraries
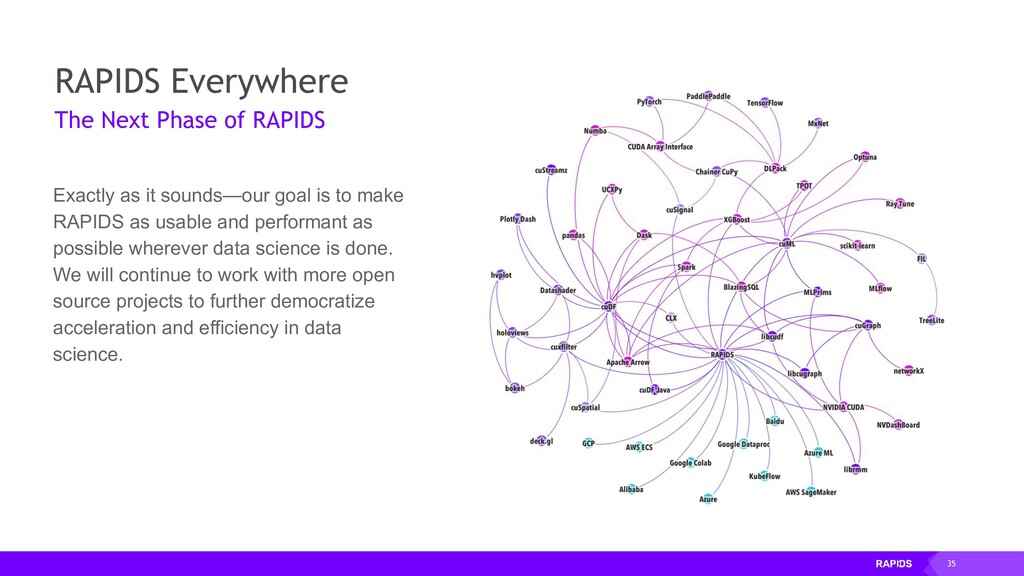
as usable and performant as possible wherever data science is done. We will continue to work with more open source projects to further democratize acceleration and efficiency in data science. RAPIDS Everywhere The Next Phase of RAPIDS
cloud specific machine instances Support for Enterprise and HPC Orchestration Layers Cloud Dataproc Azure Machine Learning Deploy RAPIDS Everywhere Focused on Robust Functionality, Deployment, and User Experience
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Jacob Tomlinson @_jacobtomlinson [email protected]](https://files.speakerdeck.com/presentations/707f07b1f9d94c2597484ffa9356bb61/slide_40.jpg){kind=link}