Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMの気持ちになってRAGのことを考えてみよう
Search
John Smith
November 24, 2024
Technology
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMの気持ちになってRAGのことを考えてみよう
Classmethod AI Talks(CATs) #8 の発表資料です
John Smith
November 24, 2024
More Decks by John Smith
See All by John Smith
Google Cloudで始めるLLM
john_smith
0
1.1k
生成AIのことちゃんと理解していますか?
john_smith
0
1.6k
Other Decks in Technology
See All in Technology
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.8k
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
380
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
620
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.8k
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
640
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
210
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
240
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
250
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
3
2k
AI Driven AI Governance
pict3
0
440
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
Featured
See All Featured
The SEO Collaboration Effect
kristinabergwall1
1
500
Designing for humans not robots
tammielis
254
26k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Testing 201, or: Great Expectations
jmmastey
46
8.2k
The Spectacular Lies of Maps
axbom
PRO
1
860
Technical Leadership for Architectural Decision Making
baasie
3
440
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Marketing to machines
jonoalderson
1
5.6k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Transcript
じょんすみす LLMの気持ちになってRAGのことを考えてみよう ~検索と生成の狭間で~
目次 2 • はじめに • 機械学習とAI • 検索とRAG • まとめ
目次 3 • はじめに • 機械学習とAI • 検索とRAG • まとめ
用語定義: 機械学習, 生成AI, LLM 4 本発表における用語は以下のように定義します。 一般的にそのまま適用されるものではありませんのでご注意ください。 • 機械学習 •
本発表では教師あり学習に限定する • 学習: 与えられたデータの組み合わせ 𝐱, 𝑦 から 𝑦 = 𝑓(𝐱; 𝜃) を求める 𝜃 を決める • 推論: 𝑦が未知の𝐱に対して ො 𝑦 を予測をする • 生成AI • 言語, 画像, 音声など人間がコンテンツとして直接利用可能なものを出力する • 利用する手法自体が機械学習における生成モデルであるかとは関係ないものとする • LLM(Large Language Model) • Transformer及びその発展手法を利用してたモデル • パラメータ数などのモデルの規模や学習時に利用したデータは問わないものとする • 本発表では入力・出力共に自然言語のみを対象とする
本発表で扱うこと・扱わないこと 5 本発表は特定のユースケースに基づく内容ではありません。 特定用途で利用する際に必要となるポイントを洗い出すために解像度を上げます。 扱うこと • 機械学習やLLMが何をしているのか • RAGを構成する要素とそれらがなぜ必要なのか •
利用する際に考えなければならないポイント 扱わないこと • 個別のモデルに関する詳細 • 特定のサービスやライブラリの使い方 • 特定のデータに対する具体的な取扱い方法
目次 6 • はじめに • 機械学習とAI • 検索とRAG • まとめ
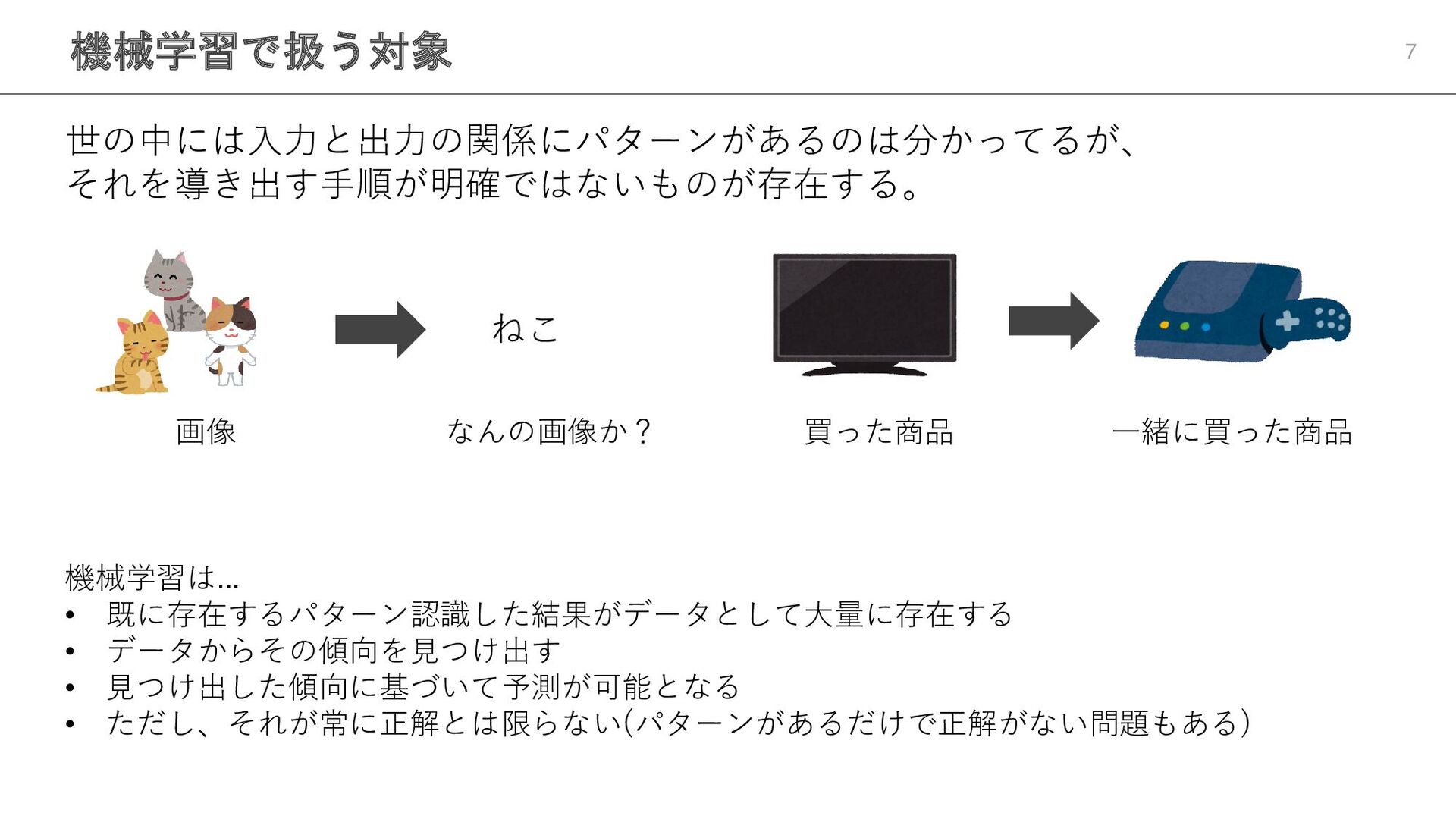
機械学習で扱う対象 7 世の中には入力と出力の関係にパターンがあるのは分かってるが、 それを導き出す手順が明確ではないものが存在する。 ねこ 画像 なんの画像か? 買った商品 一緒に買った商品 機械学習は...
• 既に存在するパターン認識した結果がデータとして大量に存在する • データからその傾向を見つけ出す • 見つけ出した傾向に基づいて予測が可能となる • ただし、それが常に正解とは限らない(パターンがあるだけで正解がない問題もある)
機械学習で扱う対象 8 パターン認識をするにあたってどの程度、特定の要素に特化したものなのか 一般的・普遍的な内容であるのかを確認しておく必要がある。 広く世の中全般 特定のドメイン 一般的な会話、雑談など 特定の業界・業種のみで伝わる専門用語知識 組織内の用語や独自フローに紐づくもの 組織内でも特定の部署などに限定される内容
• 上の方ほど、特定の要素に基づくものでデータは少ないが知っておく範囲も限定しやすい • 下の方に行くほど、普遍的な要素を取り込む必要が生じてパターンを見つけづらくなる
機械学習で扱う対象 9 例) レコメンドやパーソナライズで以下のケースを考えてみよう。 • 初対面の人に「何かオススメない?」と聞かれる • 初対面だが食事の話をしているときに「何かオススメない?」と聞かれる • 初対面だが自社の製品の話をしているときに「何かオススメない?」と聞かれる
• 既に何度か使ってもらってるリピーターに「何かオススメない?」と聞かれる • よく知っている友人に「何かオススメない?」と聞かれる → 相手のことをよりよく知っている方が特化したレコメンドが可能 → 対象を絞ることでも判断範囲を狭めて特化したレコメンドが可能
機械学習で扱う対象 10 例) レコメンドやパーソナライズで以下のケースを考えてみよう。 • 初対面の人に「何かオススメない?」と聞かれる • 初対面だが食事の話をしているときに「何かオススメない?」と聞かれる • 初対面だが自社の製品の話をしているときに「何かオススメない?」と聞かれる
• 既に何度か使ってもらってるリピーターに「何かオススメない?」と聞かれる • よく知っている友人に「何かオススメない?」と聞かれる 別な視点で見ると、初対面でも共通の話題が無くても会話はできている → 会話という行為そのものには同一言語話者どうしてあれば常に成立する普遍的なパターンがある
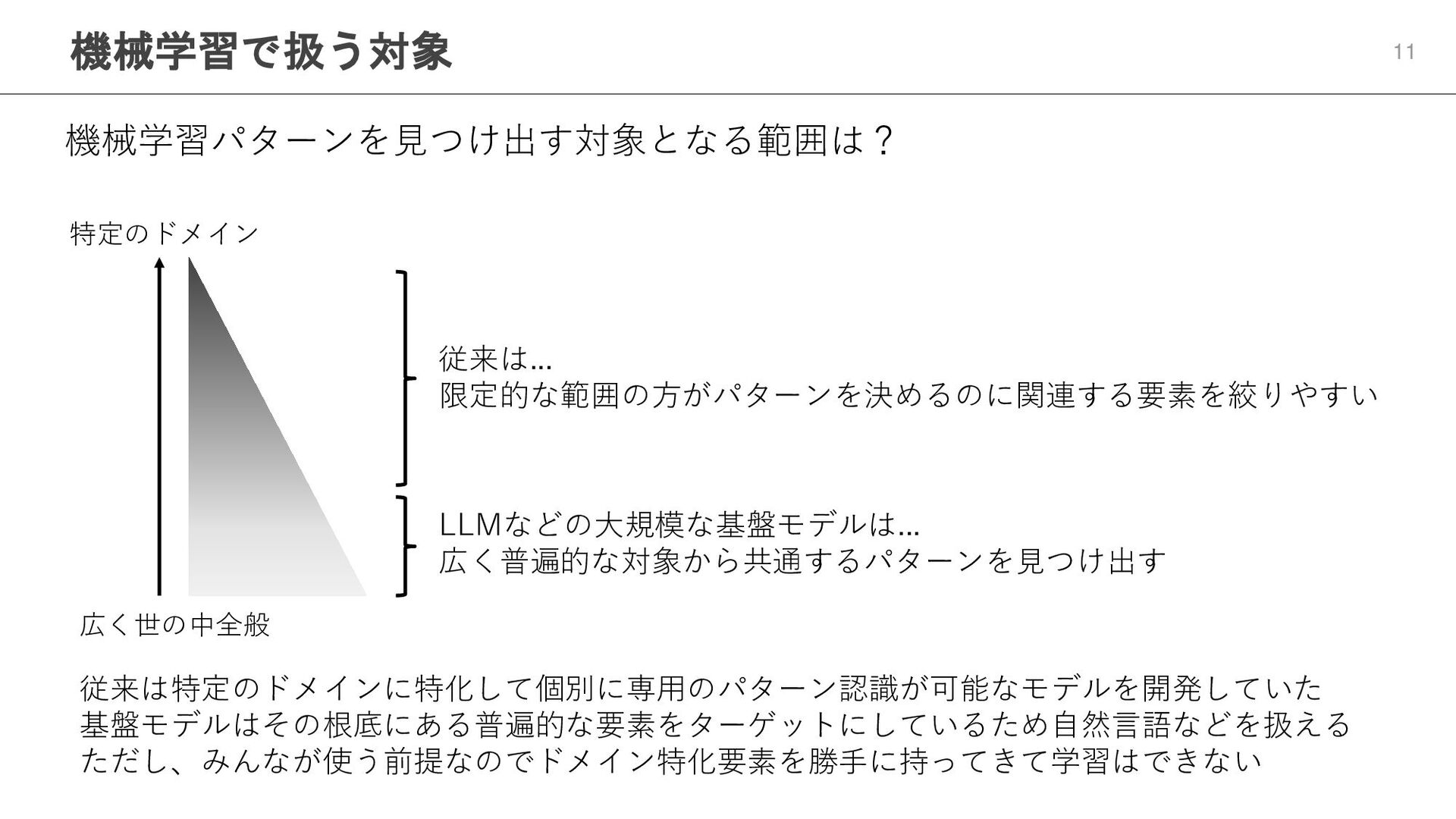
機械学習で扱う対象 11 機械学習パターンを見つけ出す対象となる範囲は? 広く世の中全般 特定のドメイン 従来は... 限定的な範囲の方がパターンを決めるのに関連する要素を絞りやすい LLMなどの大規模な基盤モデルは... 広く普遍的な対象から共通するパターンを見つけ出す 従来は特定のドメインに特化して個別に専用のパターン認識が可能なモデルを開発していた
基盤モデルはその根底にある普遍的な要素をターゲットにしているため自然言語などを扱える ただし、みんなが使う前提なのでドメイン特化要素を勝手に持ってきて学習はできない
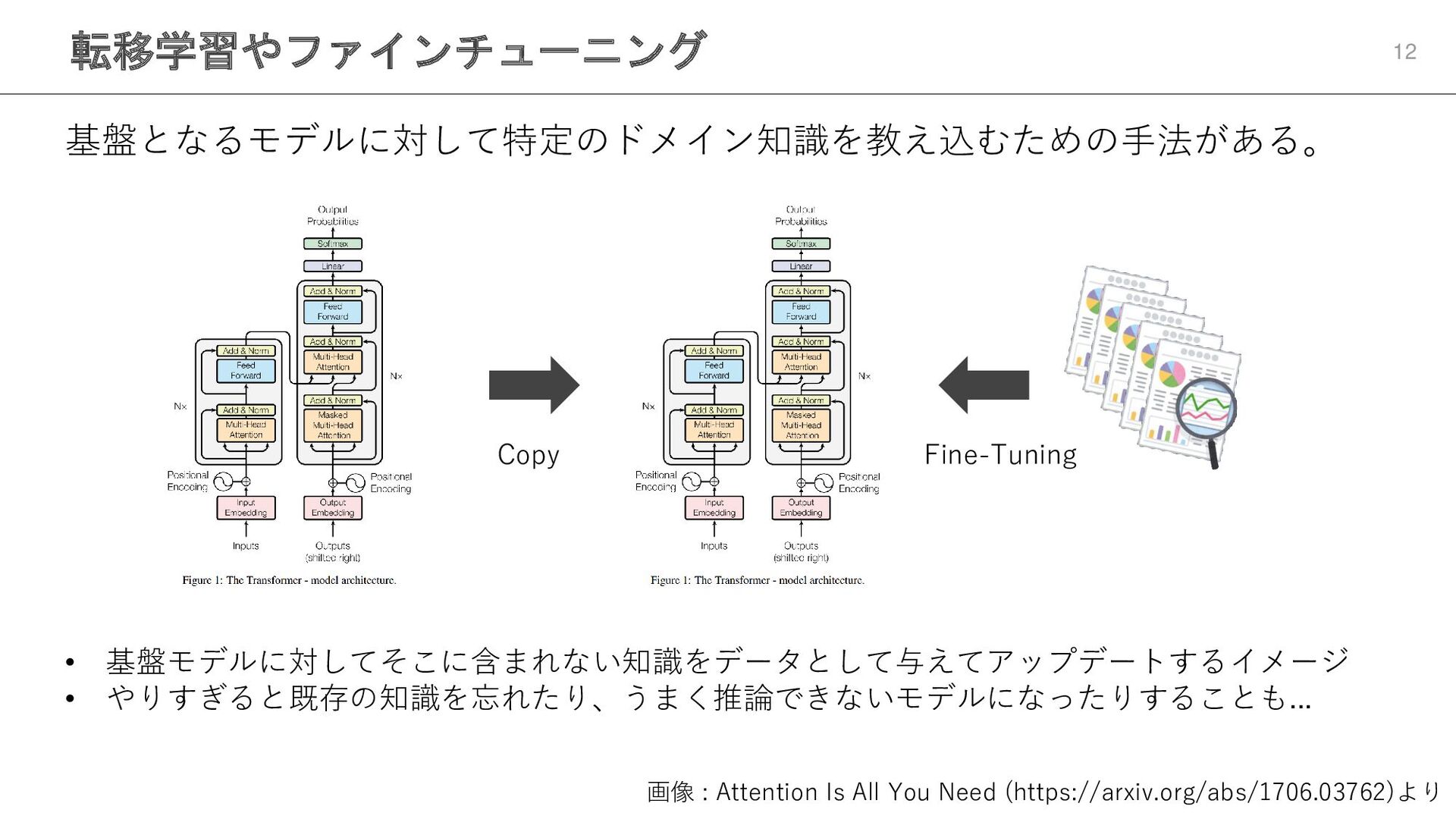
転移学習やファインチューニング 12 基盤となるモデルに対して特定のドメイン知識を教え込むための手法がある。 画像 : Attention Is All You Need
(https://arxiv.org/abs/1706.03762)より Copy Fine-Tuning • 基盤モデルに対してそこに含まれない知識をデータとして与えてアップデートするイメージ • やりすぎると既存の知識を忘れたり、うまく推論できないモデルになったりすることも...
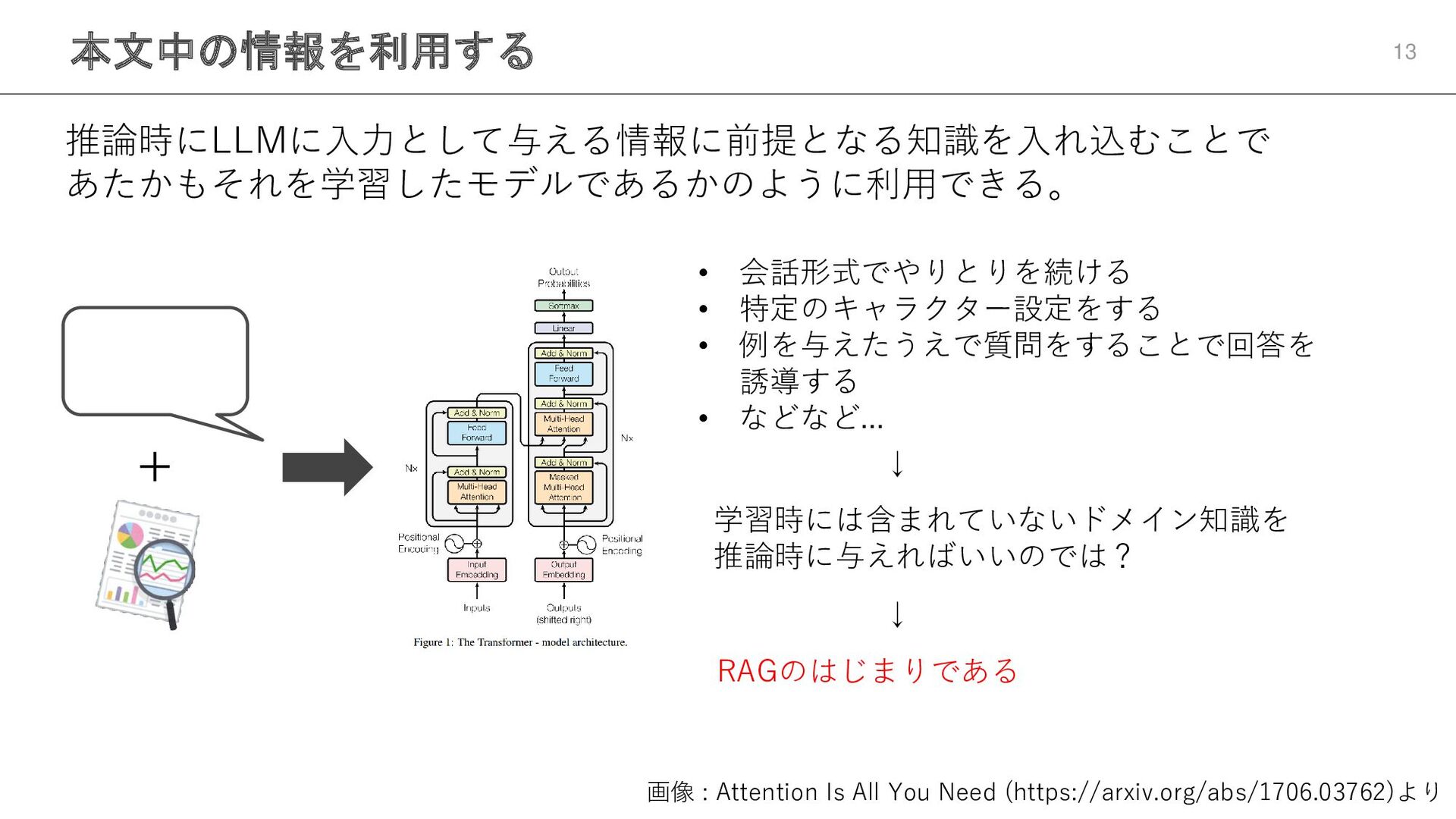
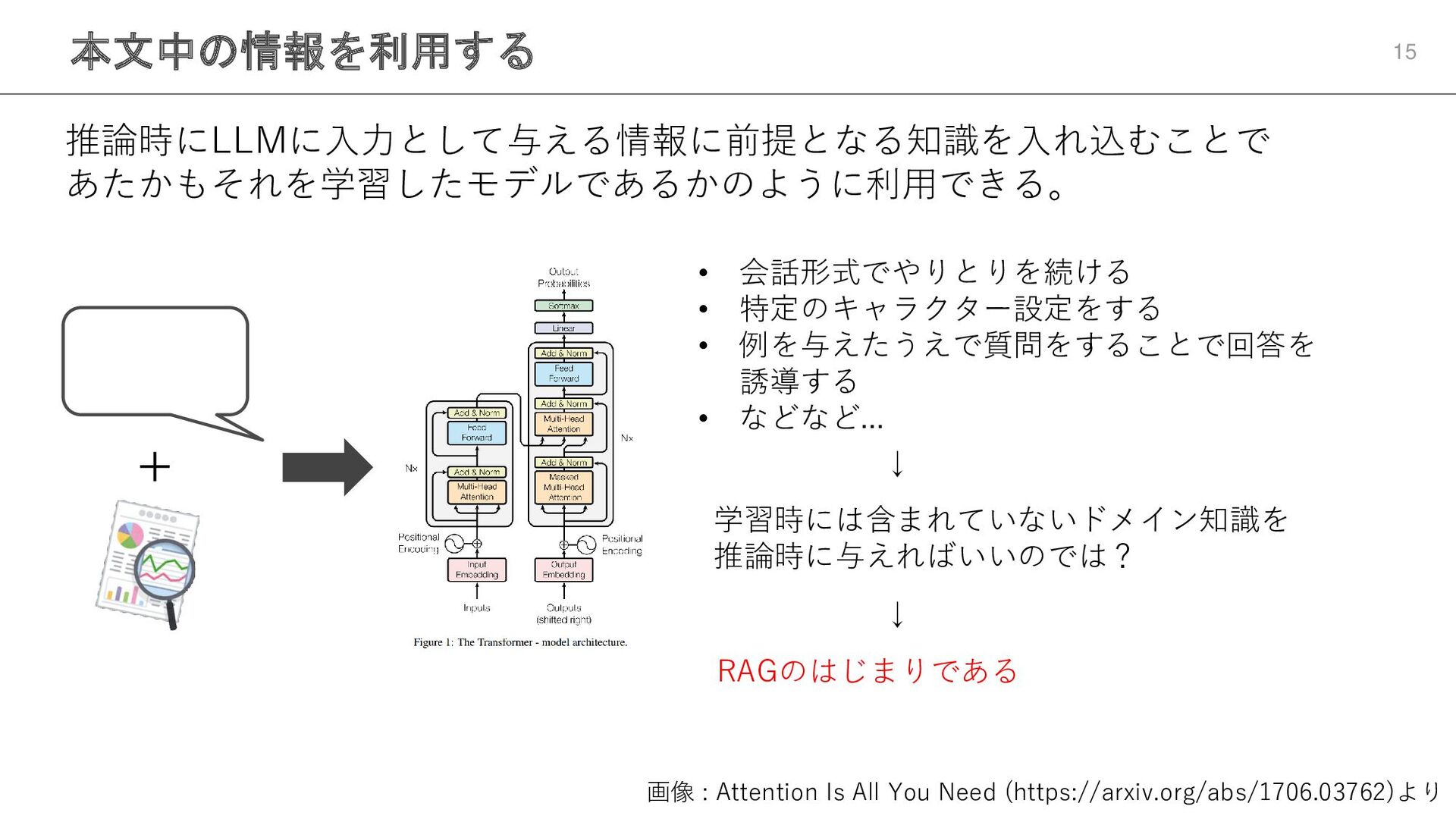
本文中の情報を利用する 13 推論時にLLMに入力として与える情報に前提となる知識を入れ込むことで あたかもそれを学習したモデルであるかのように利用できる。 画像 : Attention Is All You
Need (https://arxiv.org/abs/1706.03762)より • 会話形式でやりとりを続ける • 特定のキャラクター設定をする • 例を与えたうえで質問をすることで回答を 誘導する • などなど... + ↓ 学習時には含まれていないドメイン知識を 推論時に与えればいいのでは? ↓ RAGのはじまりである
目次 14 • はじめに • 機械学習とAI • 検索とRAG • まとめ
本文中の情報を利用する 15 推論時にLLMに入力として与える情報に前提となる知識を入れ込むことで あたかもそれを学習したモデルであるかのように利用できる。 画像 : Attention Is All You
Need (https://arxiv.org/abs/1706.03762)より • 会話形式でやりとりを続ける • 特定のキャラクター設定をする • 例を与えたうえで質問をすることで回答を 誘導する • などなど... + ↓ 学習時には含まれていないドメイン知識を 推論時に与えればいいのでは? ↓ RAGのはじまりである
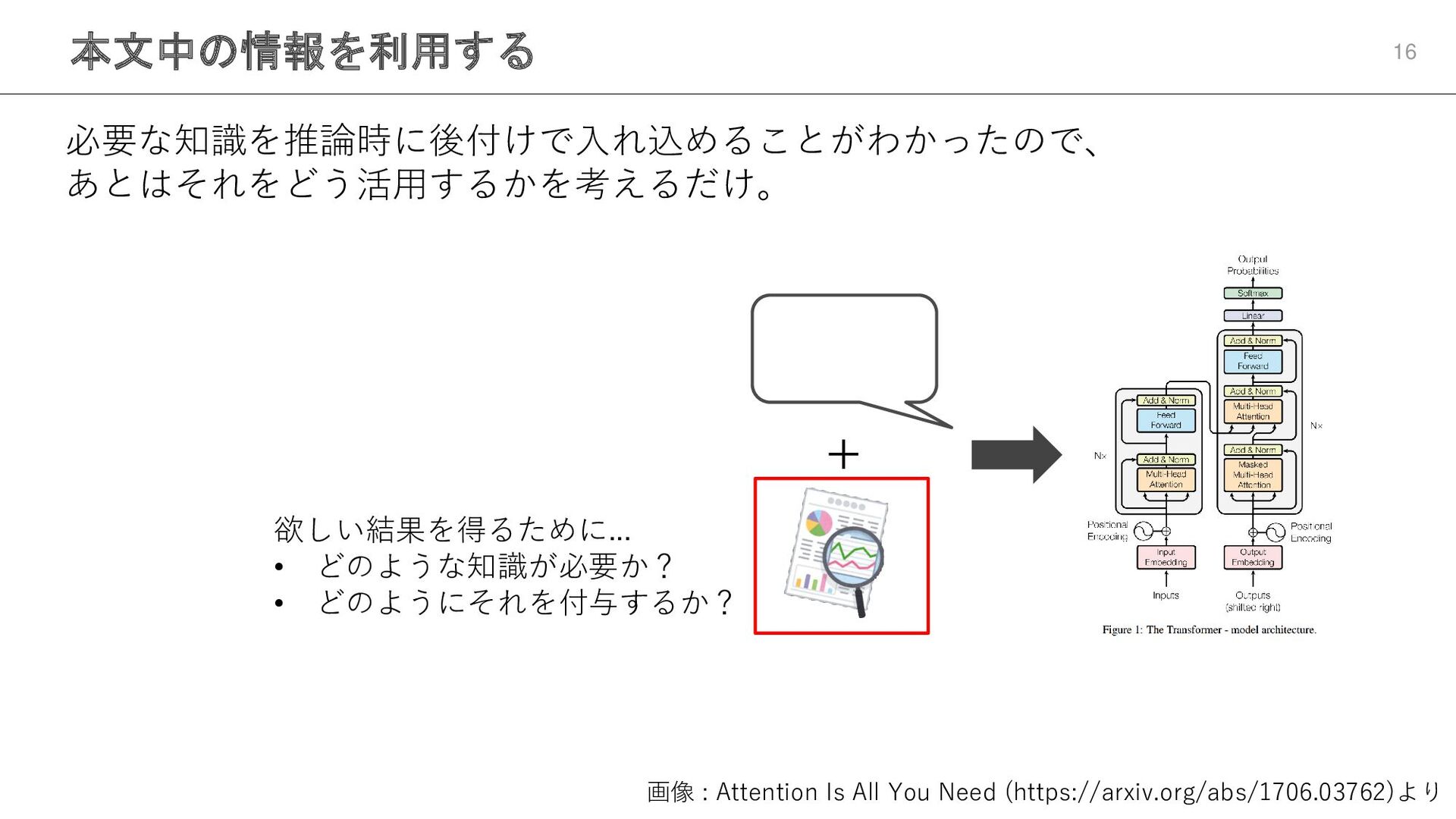
本文中の情報を利用する 16 必要な知識を推論時に後付けで入れ込めることがわかったので、 あとはそれをどう活用するかを考えるだけ。 画像 : Attention Is All You
Need (https://arxiv.org/abs/1706.03762)より + 欲しい結果を得るために... • どのような知識が必要か? • どのようにそれを付与するか?
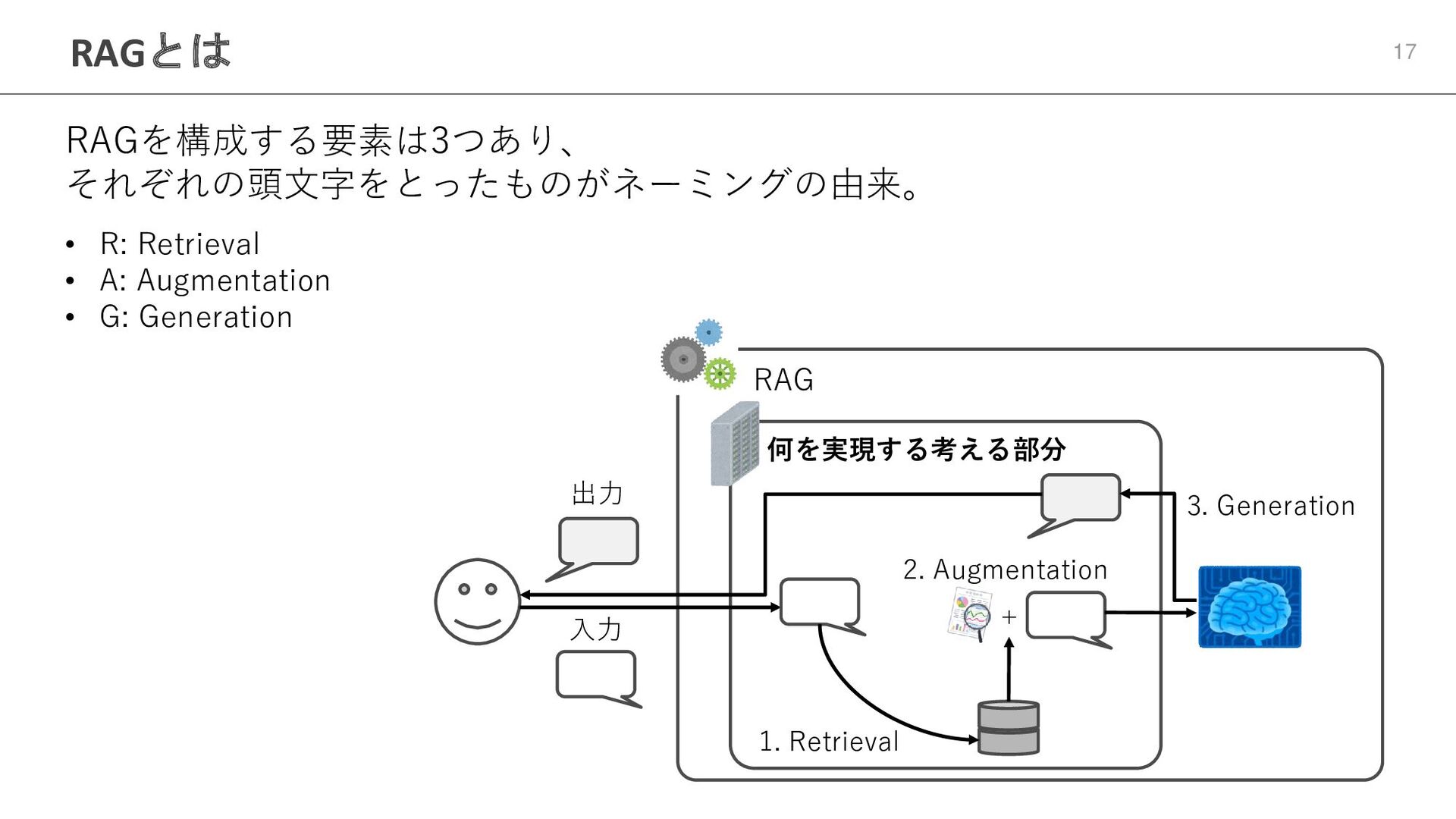
RAGとは 17 RAGを構成する要素は3つあり、 それぞれの頭文字をとったものがネーミングの由来。 • R: Retrieval • A: Augmentation
• G: Generation RAG 何を実現する考える部分 入力 1. Retrieval + 2. Augmentation 3. Generation 出力
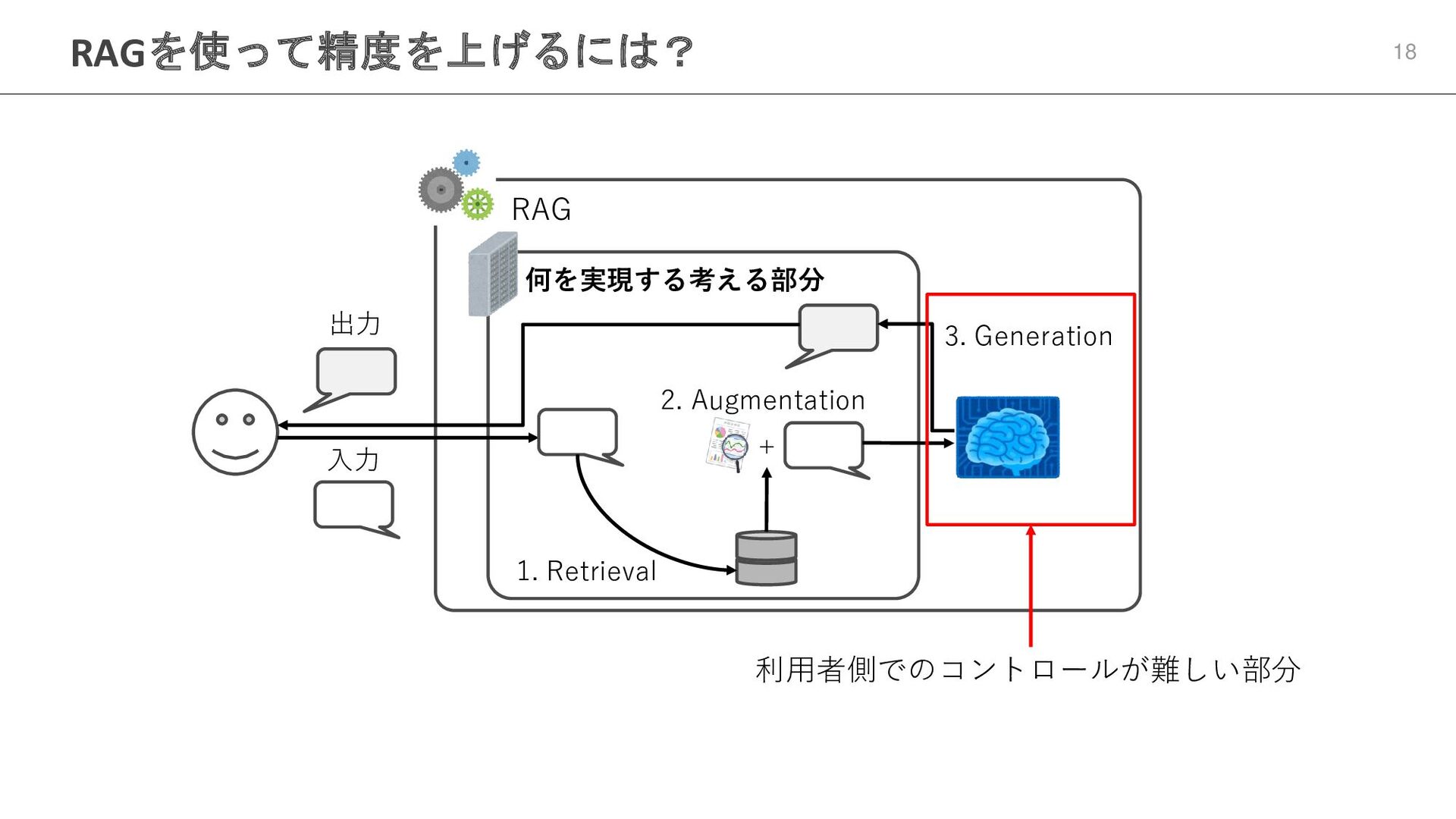
RAGを使って精度を上げるには? 18 RAG 何を実現する考える部分 入力 1. Retrieval + 2. Augmentation
3. Generation 出力 利用者側でのコントロールが難しい部分
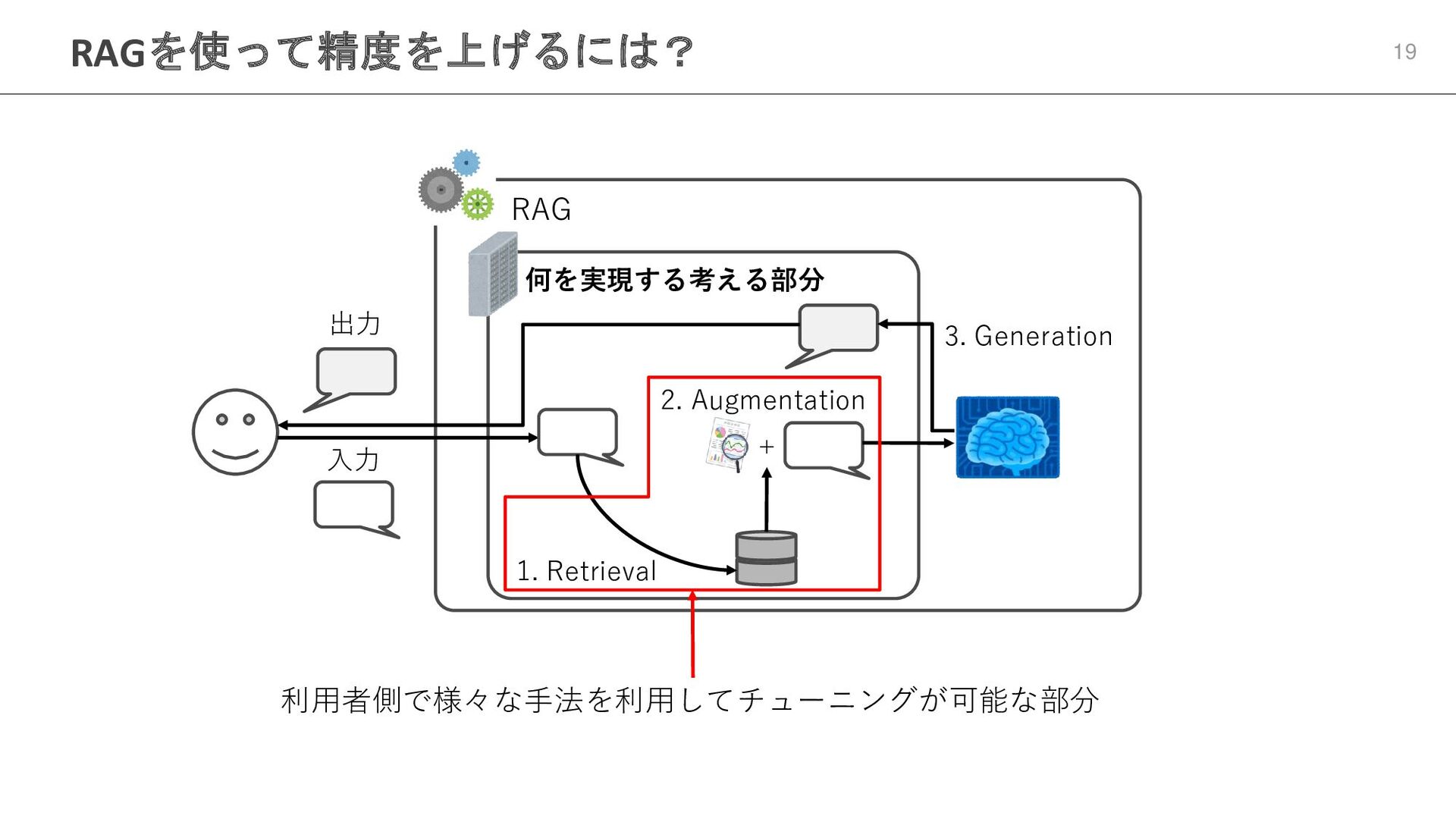
RAGを使って精度を上げるには? 19 RAG 何を実現する考える部分 入力 1. Retrieval + 2. Augmentation
3. Generation 出力 利用者側で様々な手法を利用してチューニングが可能な部分
RAGの精度を上げるためには? 20 RAGでは検索が重要だと言われる所以はここに モデルそのものをコントロールするには... • 2024年11月現在、独自モデルを作るコストは非常に高い • 一方で既存のサービスの挙動はユーザ側では完全にコントロールできない • そもそも、LLM自体が生成される結果を完全にコントロールするものではない
検索の部分に関しては... • その気になればユーザ側で作りこみが可能 • 手法やそれを実装したライブラリ、それらの組み合わせなどの選択肢も広い • 検証段階で試せる要素が非常に多い領域といえる
RAGの精度を上げるためには? 21 RAGでは検索が重要だと言われる所以はここに モデルそのものをコントロールするには... • 2024年11月現在、独自モデルを作るコストは非常に高い • 一方で既存のサービスの挙動はユーザ側では完全にコントロールできない • そもそも、LLM自体が生成される結果を完全にコントロールするものではない
検索の部分に関しては... • その気になればユーザ側で作りこみが可能 • 手法やそれを実装したライブラリ、それらの組み合わせなどの選択肢も広い • 検証段階で試せる要素が非常に多い領域といえる そもそもRAGというものが必要になった経緯を考えると • 聞きたい問題に対する専門的な知識を与えるために利用している • 検索で得られた結果に正解が含まれてさえいればLLMは正確な回答を返せる → 検索の精度を上げていこう!という流れになる
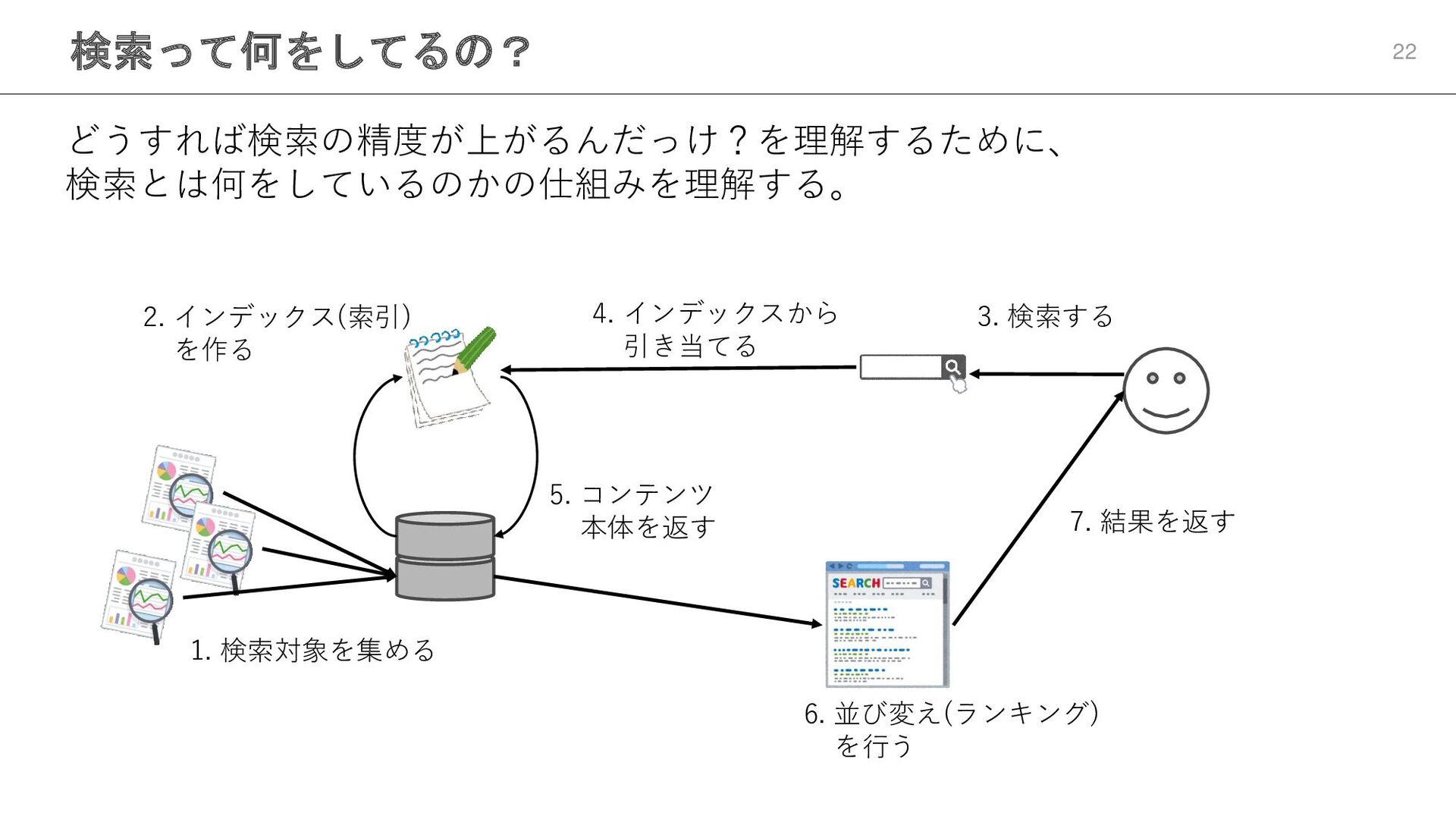
検索って何をしてるの? 22 どうすれば検索の精度が上がるんだっけ?を理解するために、 検索とは何をしているのかの仕組みを理解する。 1. 検索対象を集める 2. インデックス(索引) を作る 3.
検索する 4. インデックスから 引き当てる 5. コンテンツ 本体を返す 6. 並び変え(ランキング) を行う 7. 結果を返す
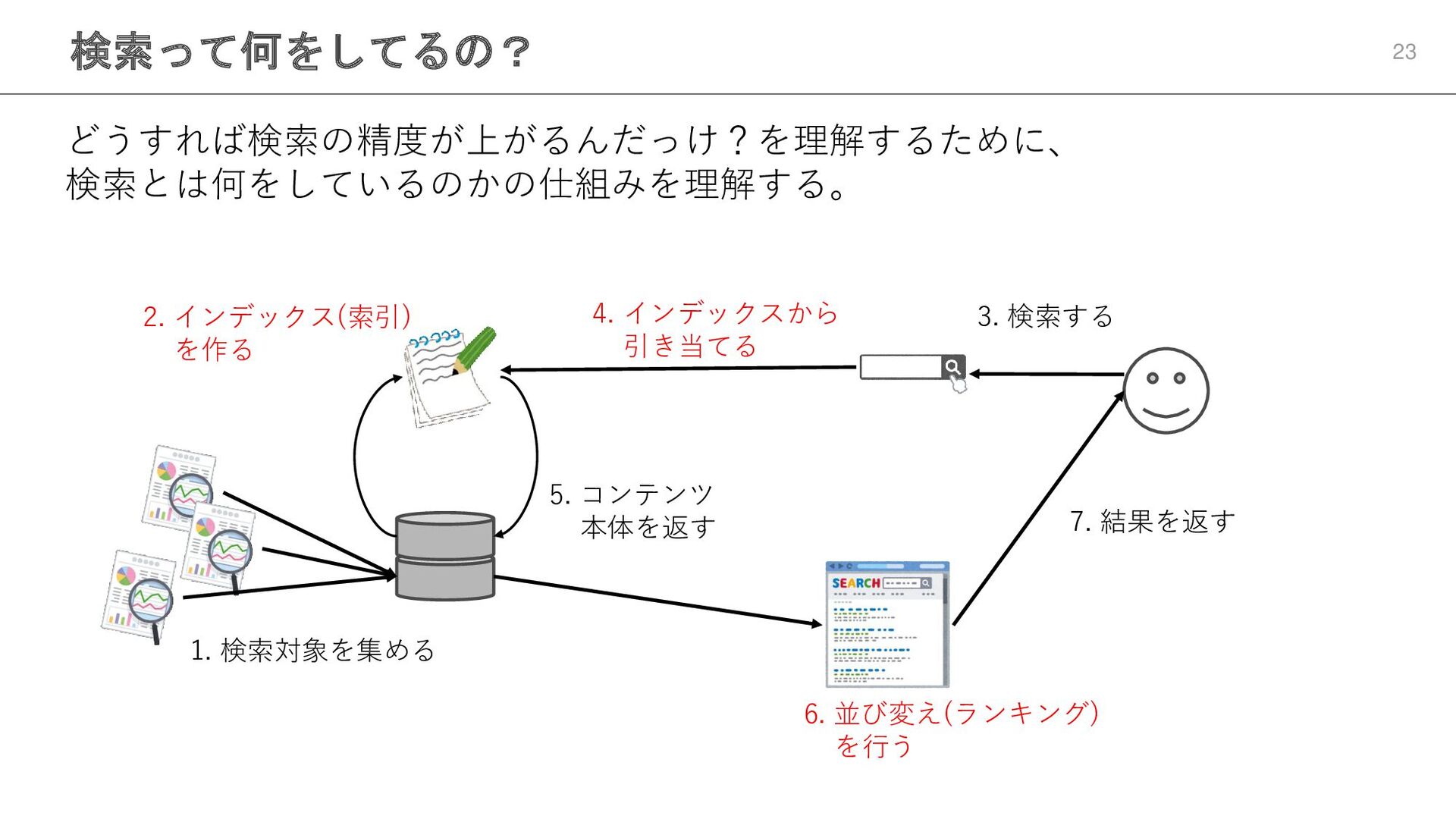
検索って何をしてるの? 23 どうすれば検索の精度が上がるんだっけ?を理解するために、 検索とは何をしているのかの仕組みを理解する。 1. 検索対象を集める 2. インデックス(索引) を作る 3.
検索する 4. インデックスから 引き当てる 5. コンテンツ 本体を返す 6. 並び変え(ランキング) を行う 7. 結果を返す
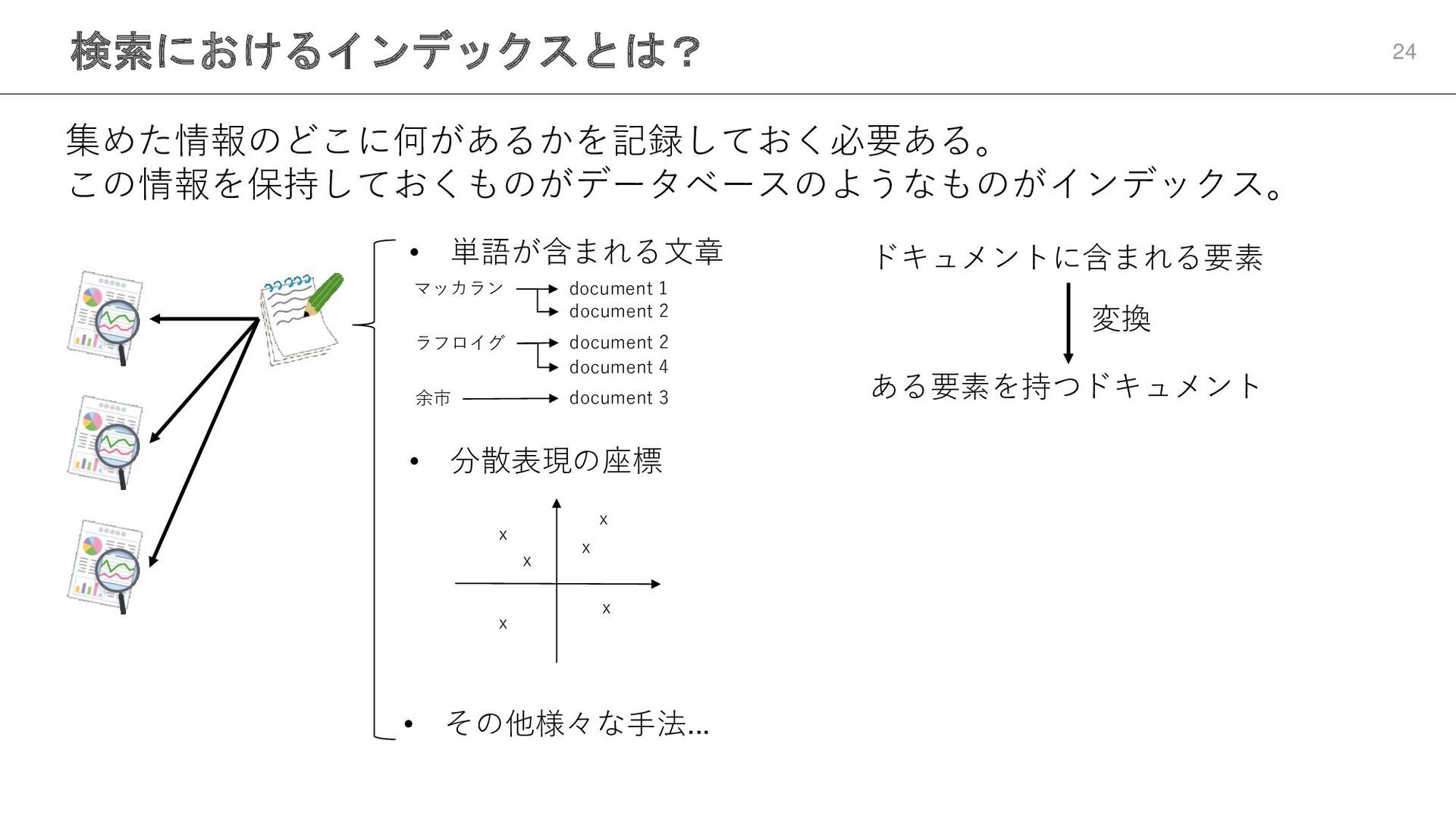
検索におけるインデックスとは? 24 集めた情報のどこに何があるかを記録しておく必要ある。 この情報を保持しておくものがデータベースのようなものがインデックス。 マッカラン document 1 ラフロイグ 余市 document
2 document 2 document 4 document 3 x x x x x x • 単語が含まれる文章 • 分散表現の座標 • その他様々な手法... ドキュメントに含まれる要素 変換 ある要素を持つドキュメント
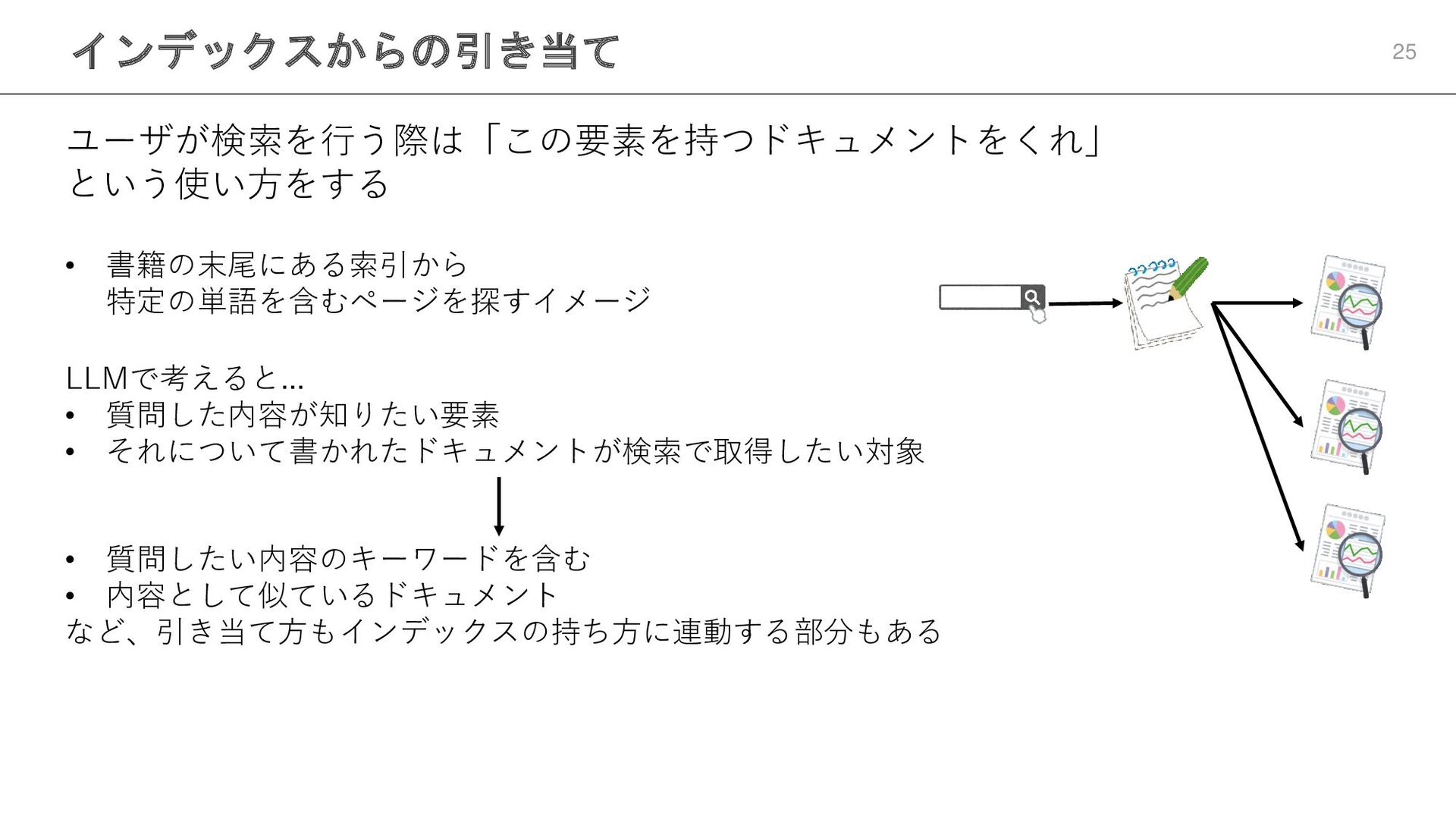
インデックスからの引き当て 25 ユーザが検索を行う際は「この要素を持つドキュメントをくれ」 という使い方をする • 書籍の末尾にある索引から 特定の単語を含むページを探すイメージ LLMで考えると... • 質問した内容が知りたい要素
• それについて書かれたドキュメントが検索で取得したい対象 • 質問したい内容のキーワードを含む • 内容として似ているドキュメント など、引き当て方もインデックスの持ち方に連動する部分もある
ランキングをするって? 26 引き当てた情報のうち検索したかった内容に近いもの順に並べ替える。 これによってできること • 関連度の高いものが上に来てるようにする • 閾値を設けて関連度の低い情報は対象から外す LLMで考えると... •
トークン数の制限の範囲内で • 回答に必要な情報をそこに含める という、重要な役割を持つことになる
ここまで把握しておけば 27 こういった話がどういうことか理解できるようになる。 https://www.anthropic.com/news/contextual-retrieval
発展して考える 28 RAGを含むLLMをブラックボックスのAIとして一塊で扱うのではなく どういった流れで処理が実現されているかを知ると何が嬉しいか? • 「うまくいかない!」「精度が上がらない!」となった際にどこに問題がありそうかを 調査したり、どう改善すれば良さそうかの目星をつけれる • 他の要素を組み込みたいとなったときにどこに何を差し込むことでそれが実現 できそうかを考えやすい
• LLMの用途全般に対してどのように活用できそうかを考える際にもヒントになる • 詳しい人っぽさを醸し出せる
目次 29 • はじめに • 機械学習とAI • 検索とRAG • まとめ
まとめ 30 ✓ 機械学習とは何者でAIとどう関連するのか ✓ LLMにとって学習時に無かった情報をどう扱うのか ✓ RAGと検索の関連性ってどうなてってるのか ✓ 詳しい人になれた気がする
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}