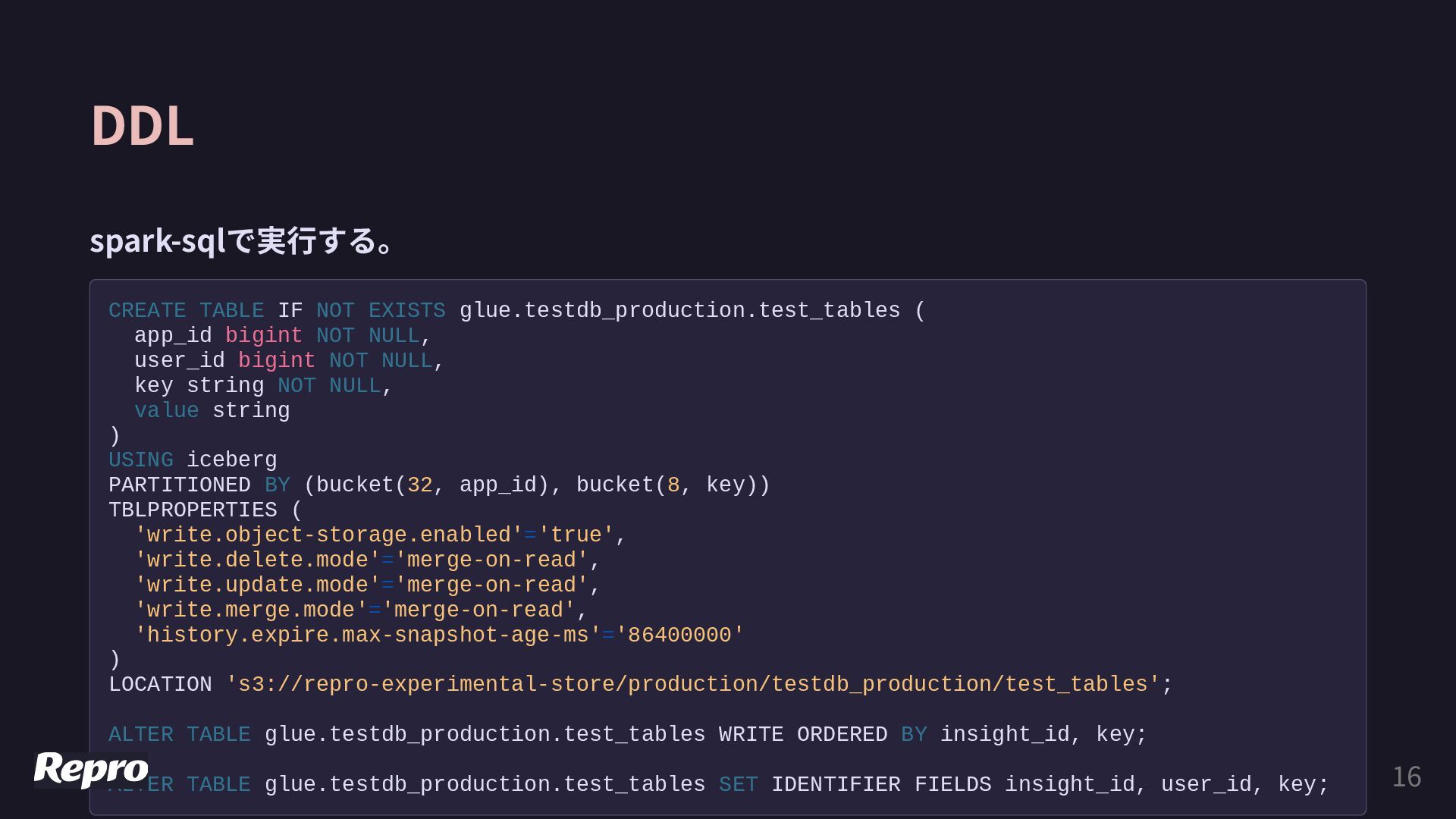
bigint NOT NULL, user_id bigint NOT NULL, key string NOT NULL, value string ) USING iceberg PARTITIONED BY (bucket(32, app_id), bucket(8, key)) TBLPROPERTIES ( 'write.object-storage.enabled'='true', 'write.delete.mode'='merge-on-read', 'write.update.mode'='merge-on-read', 'write.merge.mode'='merge-on-read', 'history.expire.max-snapshot-age-ms'='86400000' ) LOCATION 's3://repro-experimental-store/production/testdb_production/test_tables'; ALTER TABLE glue.testdb_production.test_tables WRITE ORDERED BY insight_id, key; ALTER TABLE glue.testdb_production.test_tables SET IDENTIFIER FIELDS insight_id, user_id, key; 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
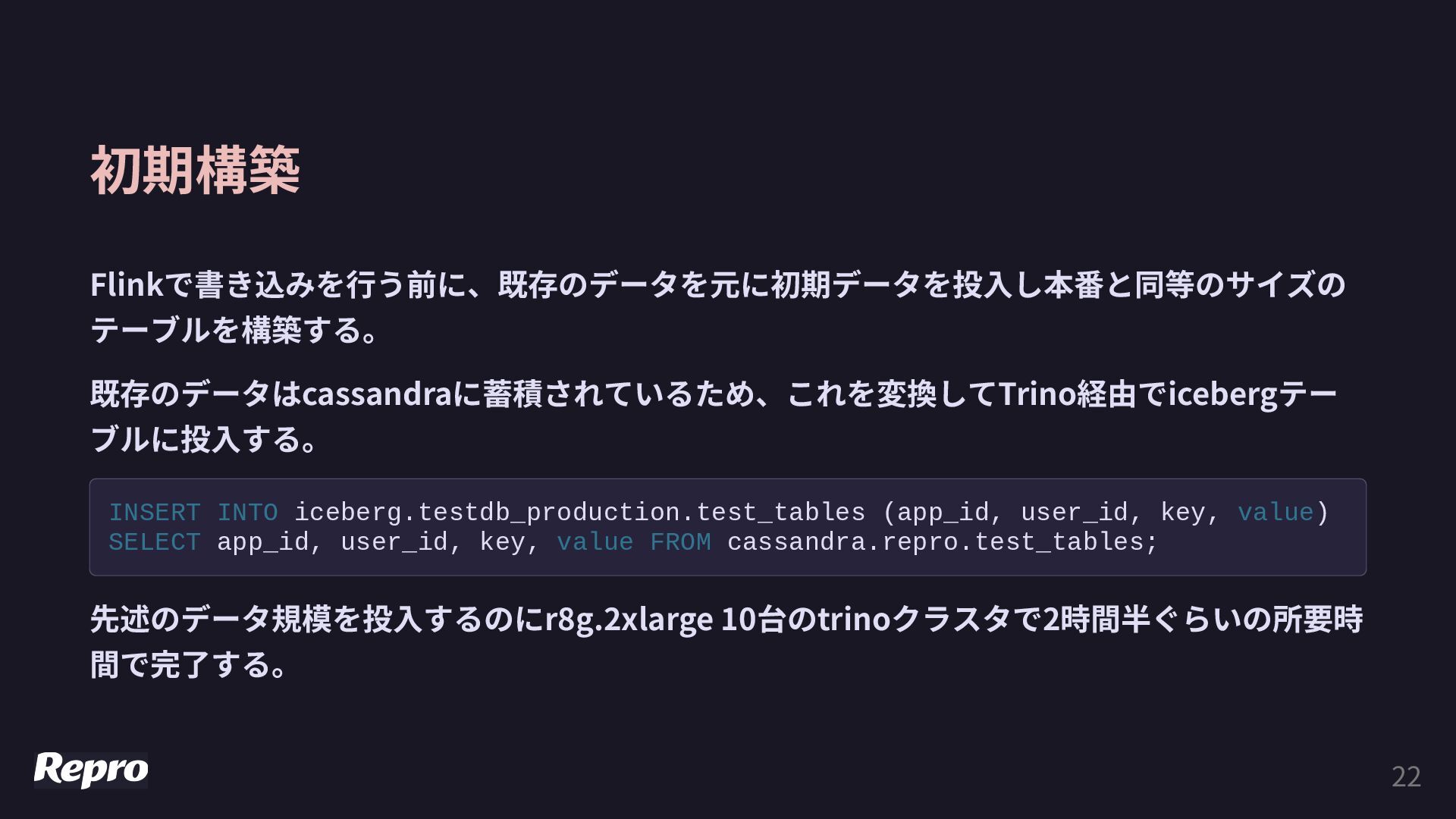{kind=link}
{kind=link}
{kind=link}
{kind=link}
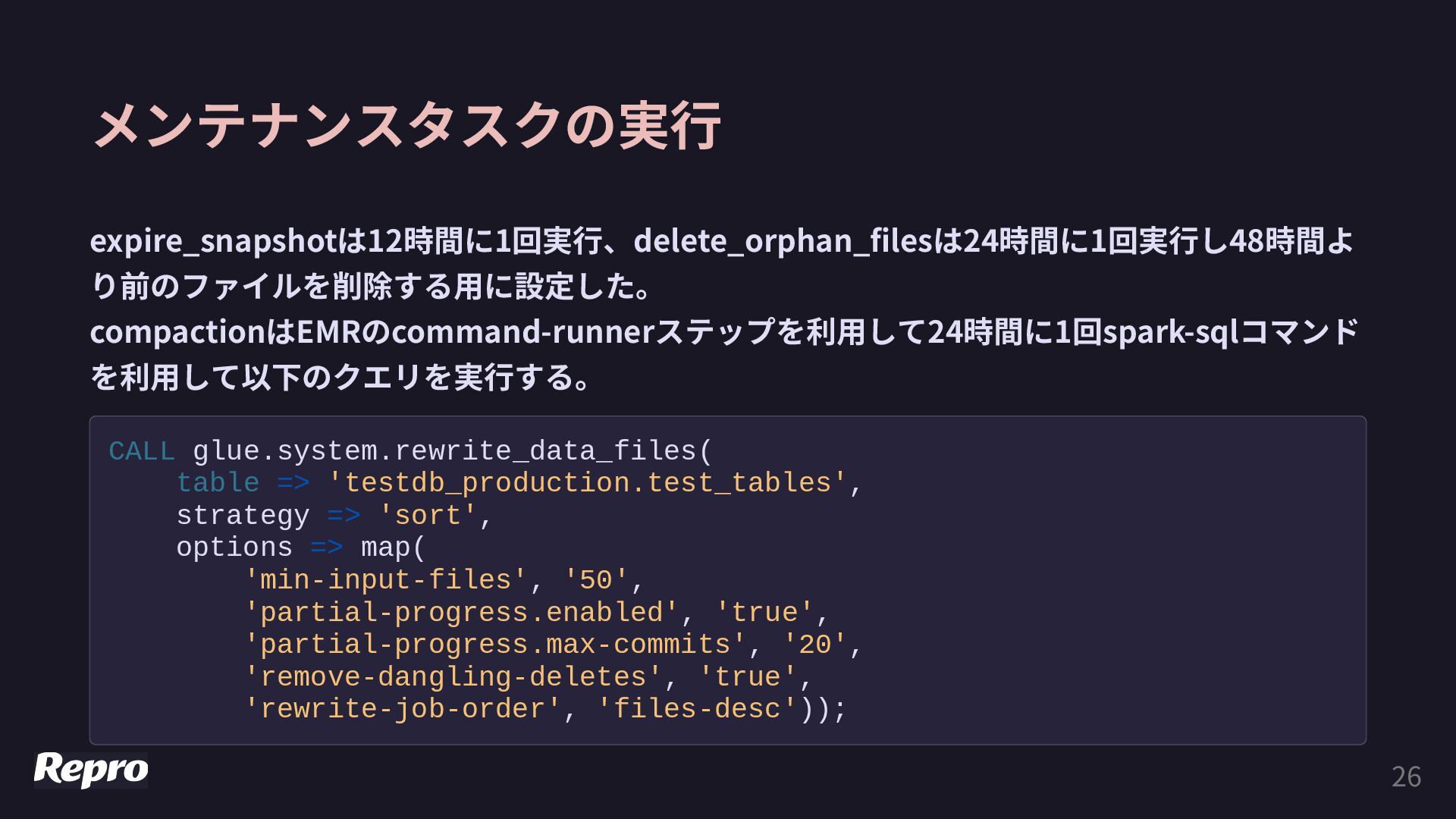{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![現在、本番導⼊に向けて作業中 • [x] 必要なインフラのコード化 • [x] メトリック取得とアラートモニタの整備 • [ ]](https://files.speakerdeck.com/presentations/468c4310bb5c43fb8786dc46fd996dc0/slide_31.jpg){kind=link}
{kind=link}
{kind=link}