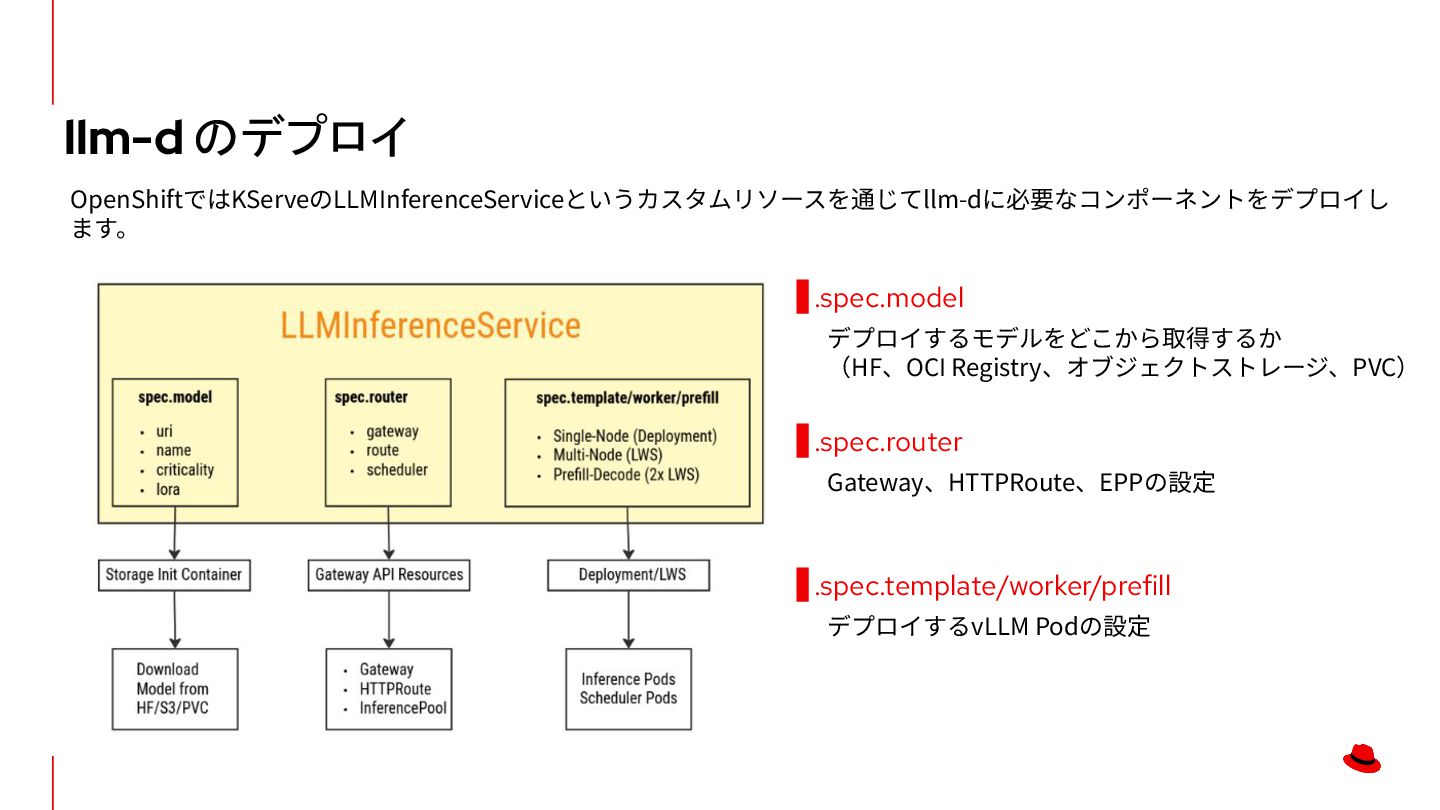
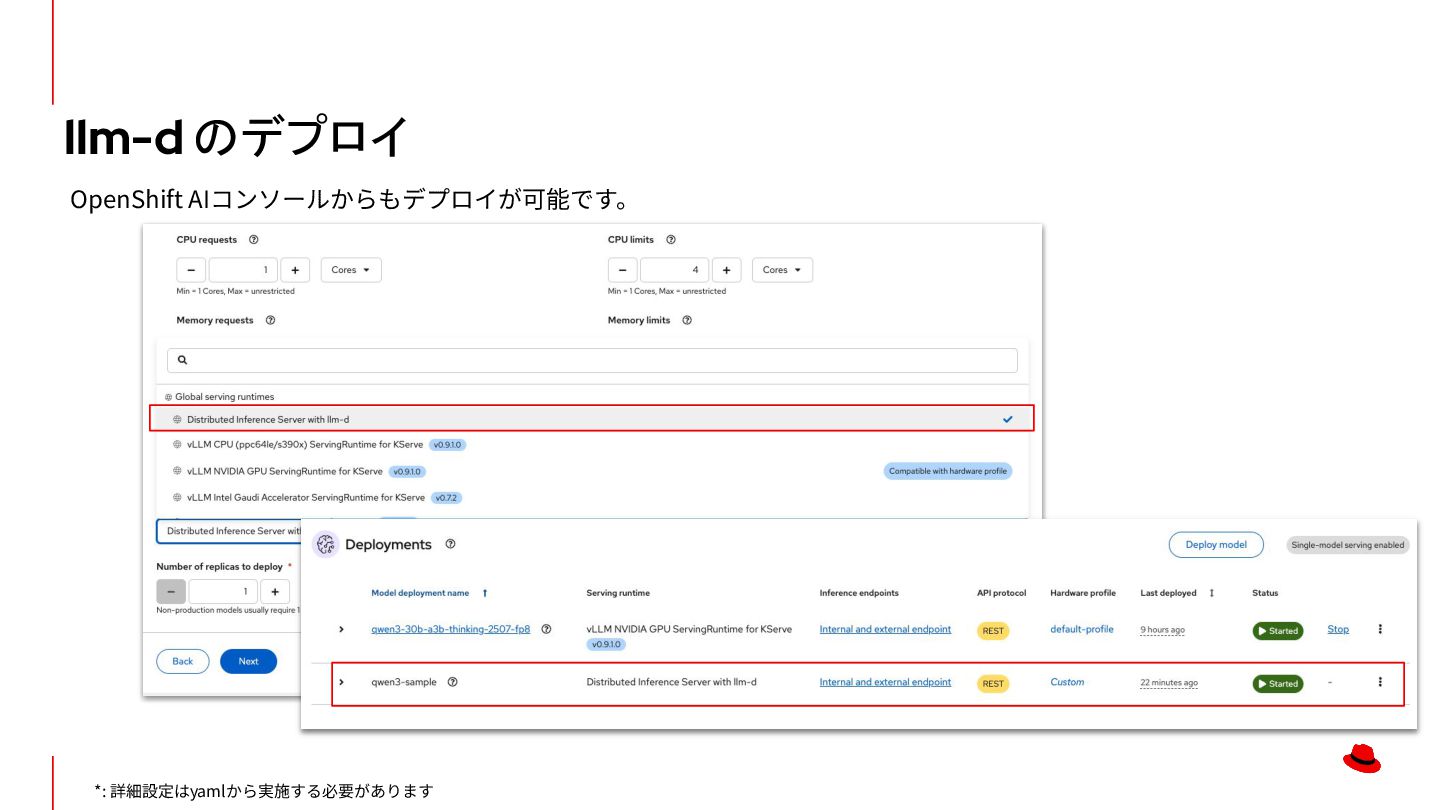
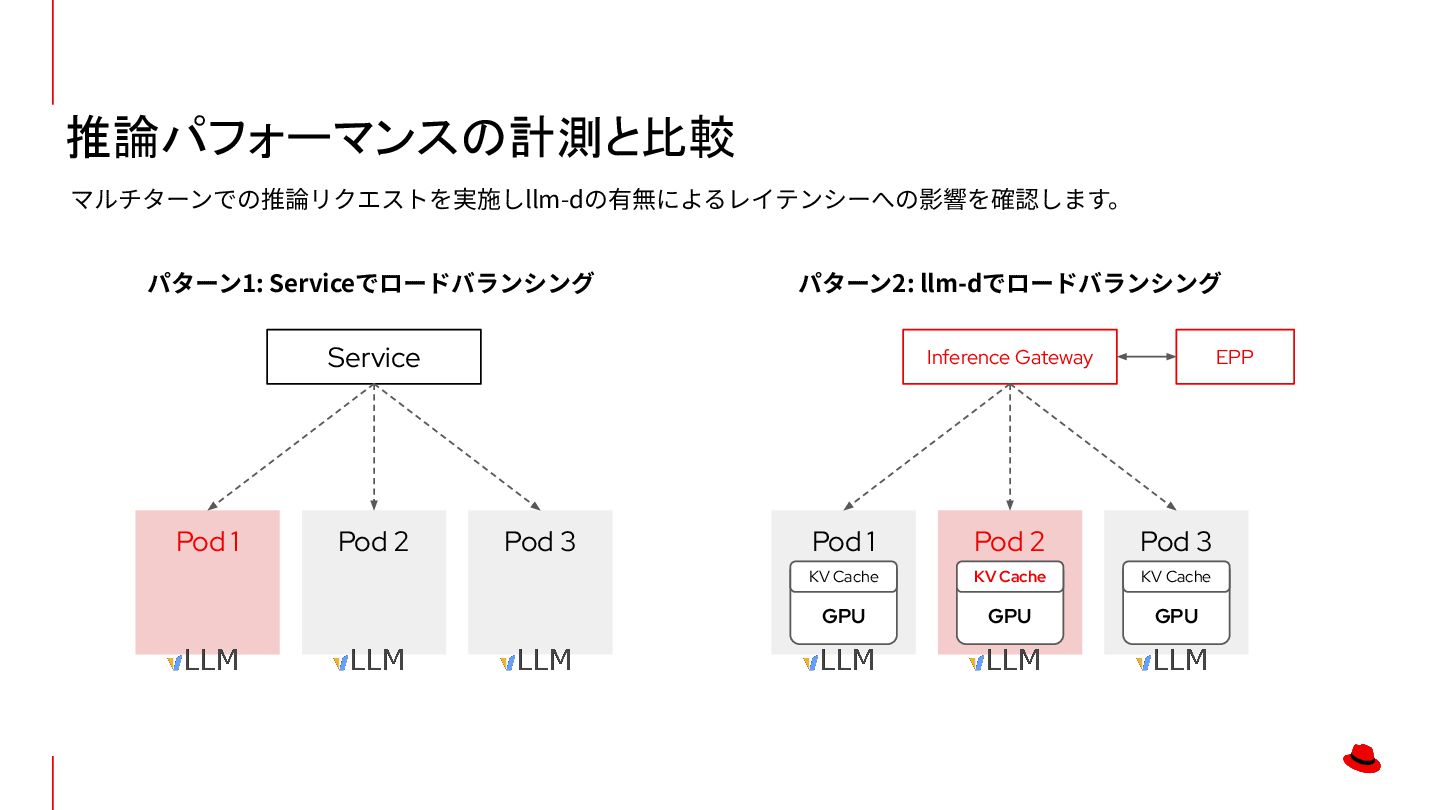
ステートレスな処理 • 汎⽤的なCPUで⾼速に処理可能 LLM推論の課題:推論のロードバランシング Service Pod 1 Pod 2 Pod 3 Serviceによるロードバランシング Load Balancer Pod 1 Pod 2 Pod 3 LLMの推論におけるロードバランシング GPU KV Cache GPU KV Cache GPU KV Cache KubernetesのServiceでは推論時のステート(KV Cache)を考慮することができないため、推論の効率が悪化します。 LLMの推論を効率化するためにはLLMの特性に合った新たな仕組みが必要となります。 推論を最適化するための LBの仕組みが必要
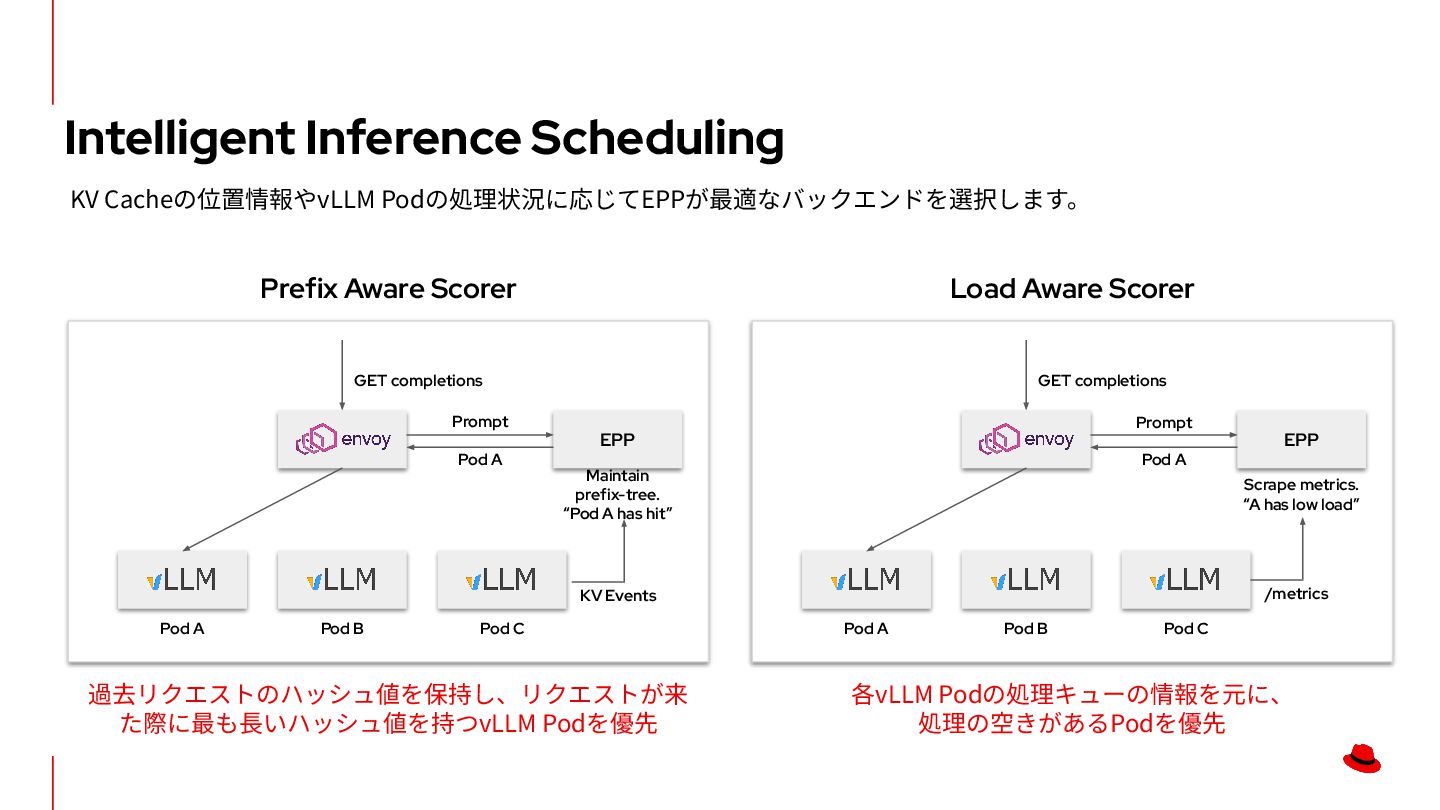
has hit” Prefix Aware Scorer EPP Pod A Pod B Pod C GET completions Load Aware Scorer EPP Pod A Pod B Pod C GET completions Prompt 過去リクエストのハッシュ値を保持し、リクエストが来 た際に最も⻑いハッシュ値を持つvLLM Podを優先 Scrape metrics. “A has low load” 各vLLM Podの処理キューの情報を元に、 処理の空きがあるPodを優先 Pod A Prompt Pod A /metrics KV Events
provider of enterprise open source software solutions. Award-winning support, training, and consulting services make Red Hat a trusted adviser to the Fortune 500. Thank you
{kind=link}
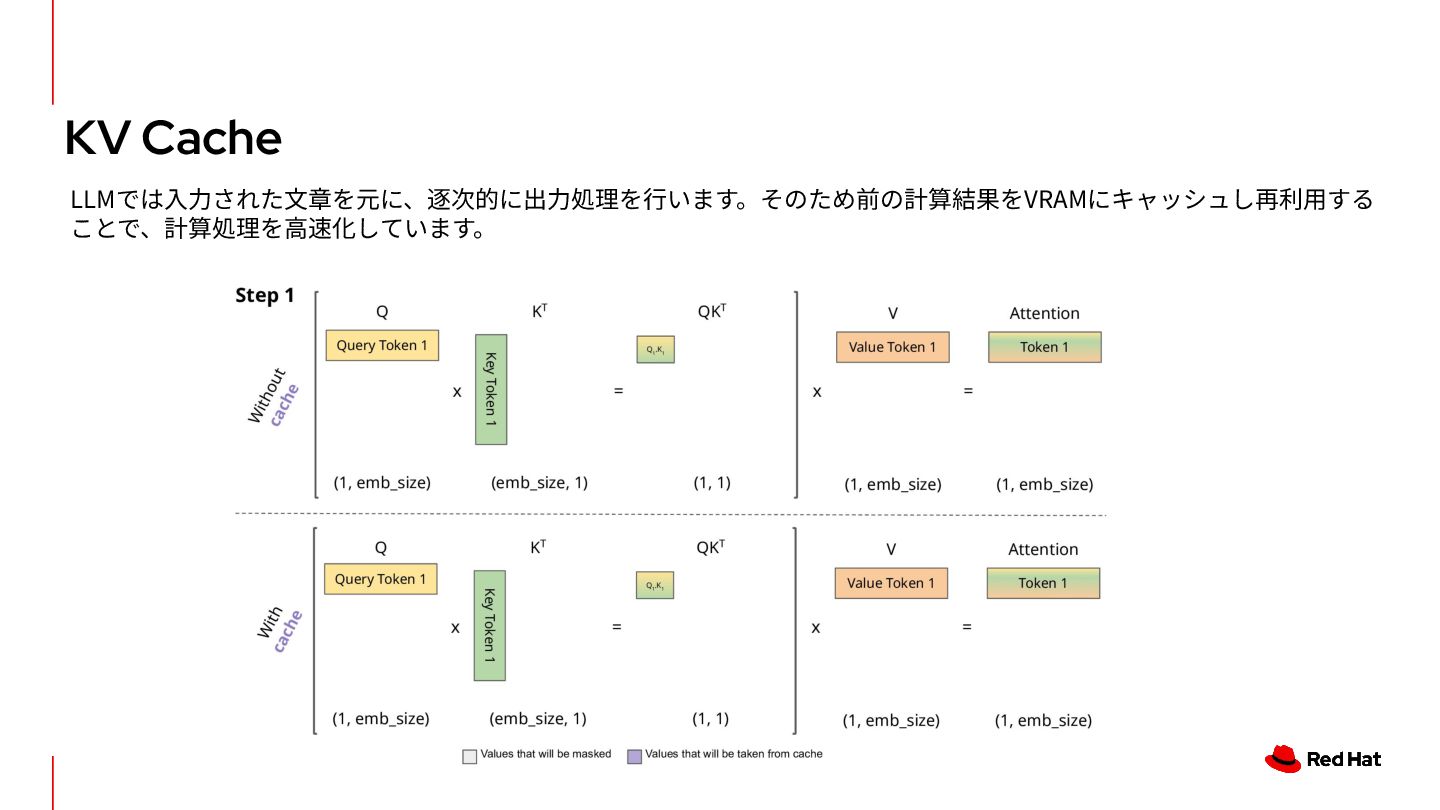{kind=link}
{kind=link}
{kind=link}
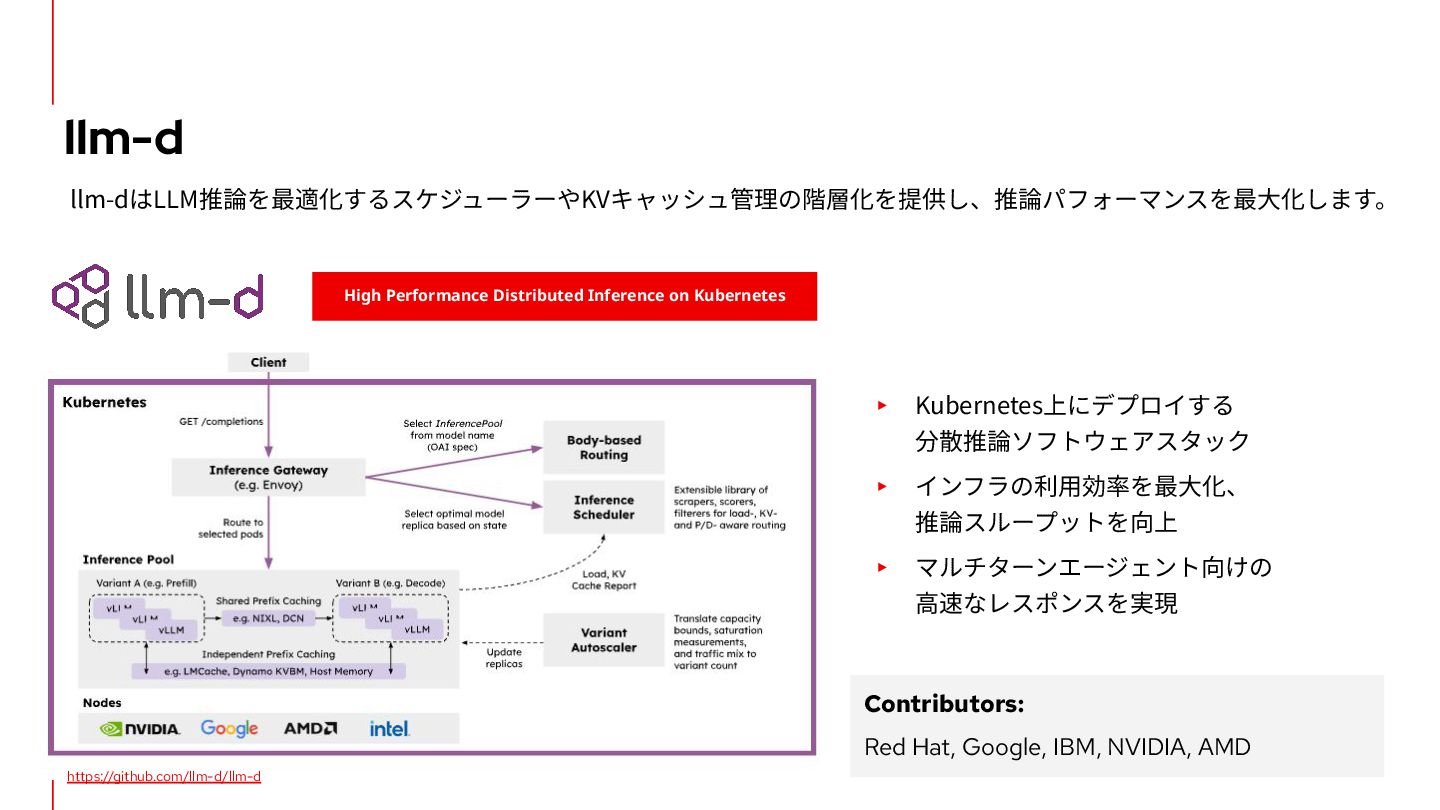{kind=link}
{kind=link}
{kind=link}
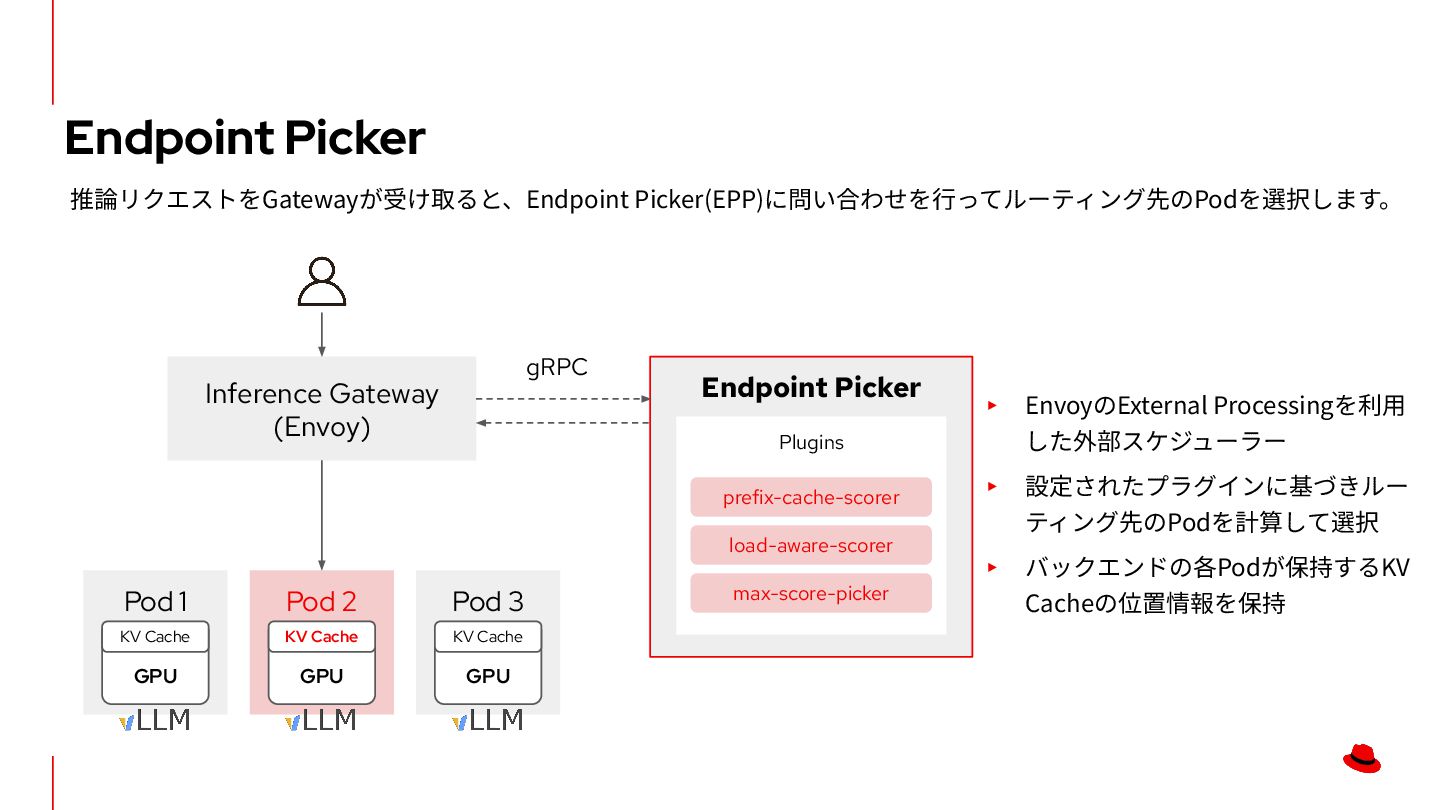{kind=link}
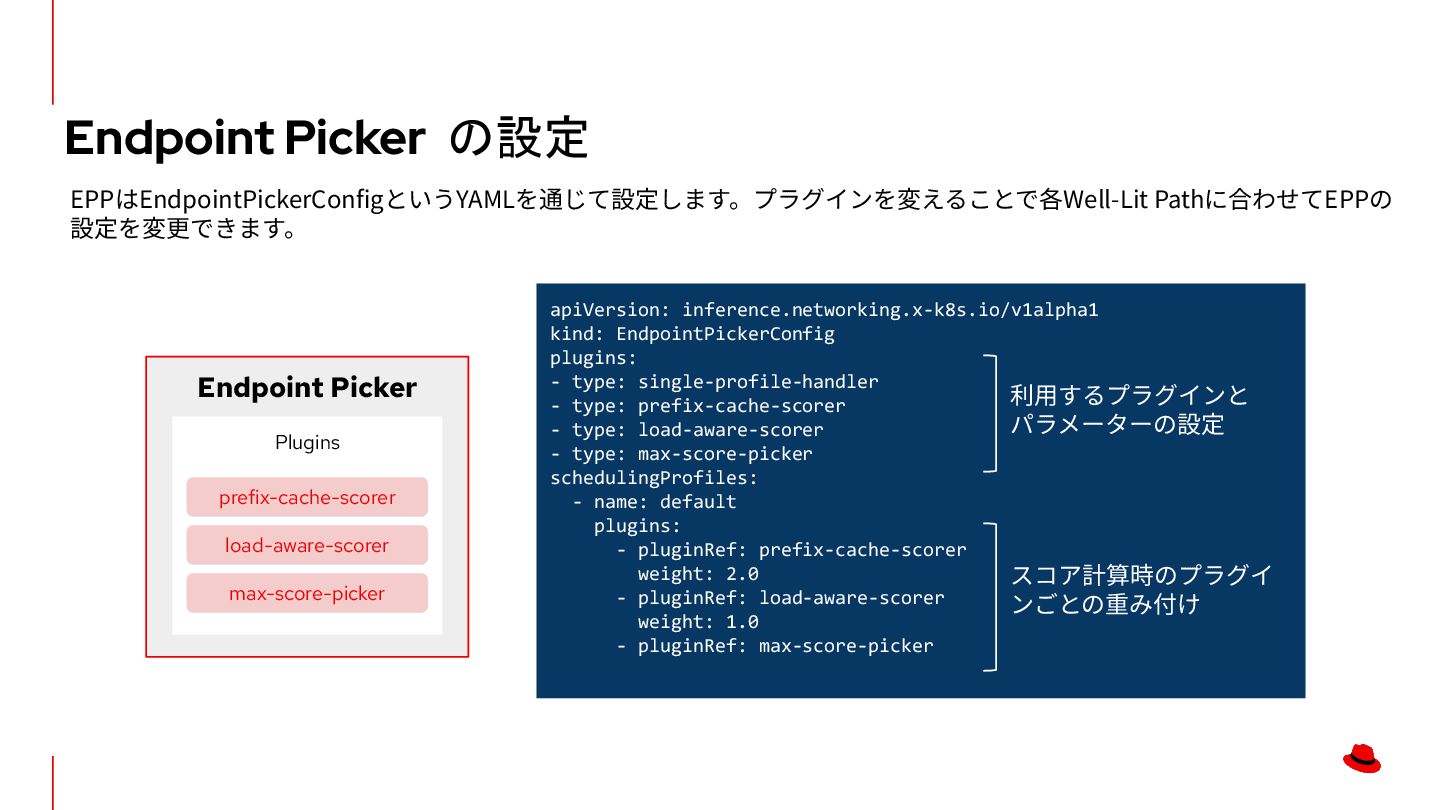{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
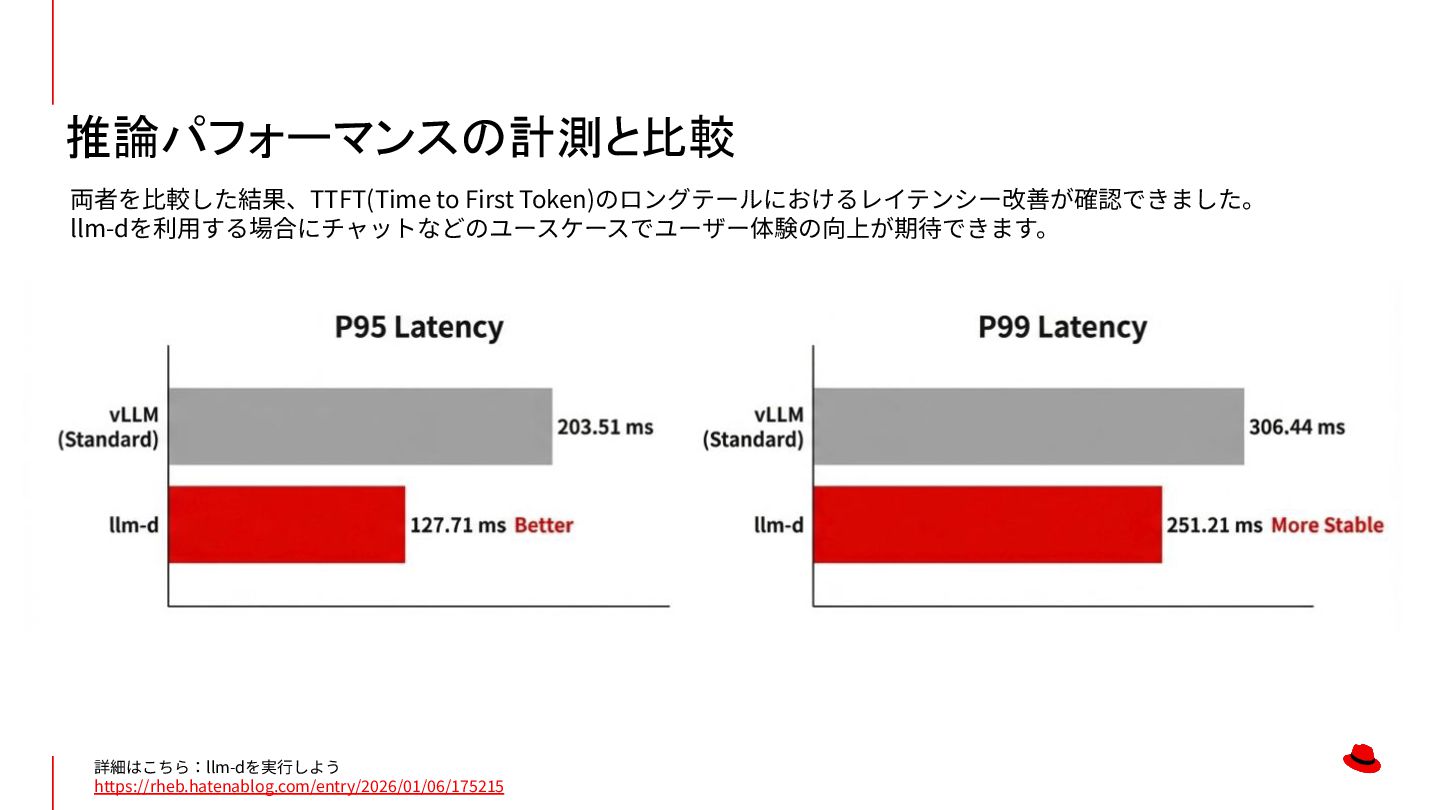
![推論パフォーマンスの計測と比較 推論機能を強化するllm-d https://www.netone.co.jp/media/detail/20260121-01/ TTFT (ms) [p99] TTFT (ms) [p90] ITL](https://files.speakerdeck.com/presentations/d43d11f67bc34b1fa76a92547d16bd3c/slide_14.jpg){kind=link}
{kind=link}
{kind=link}