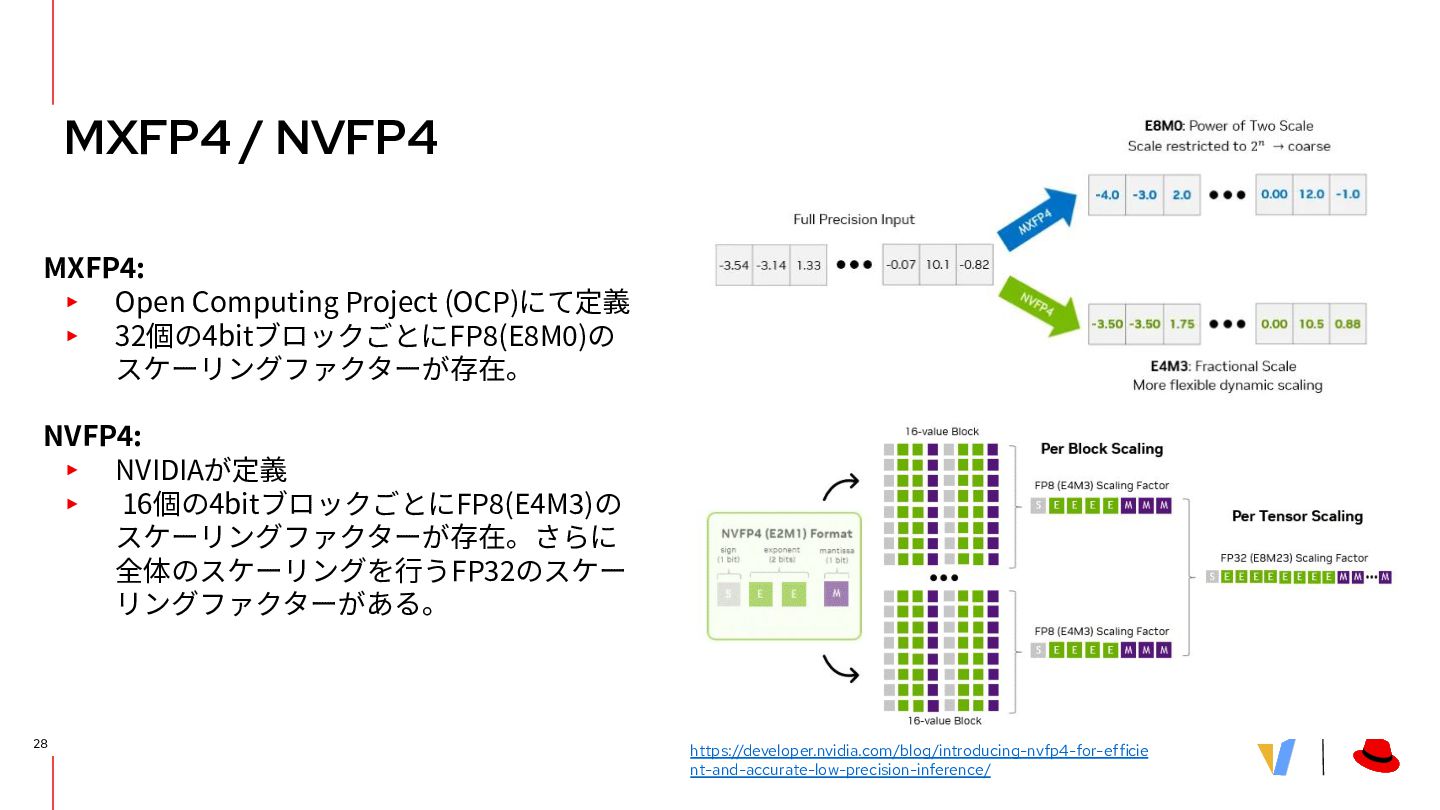
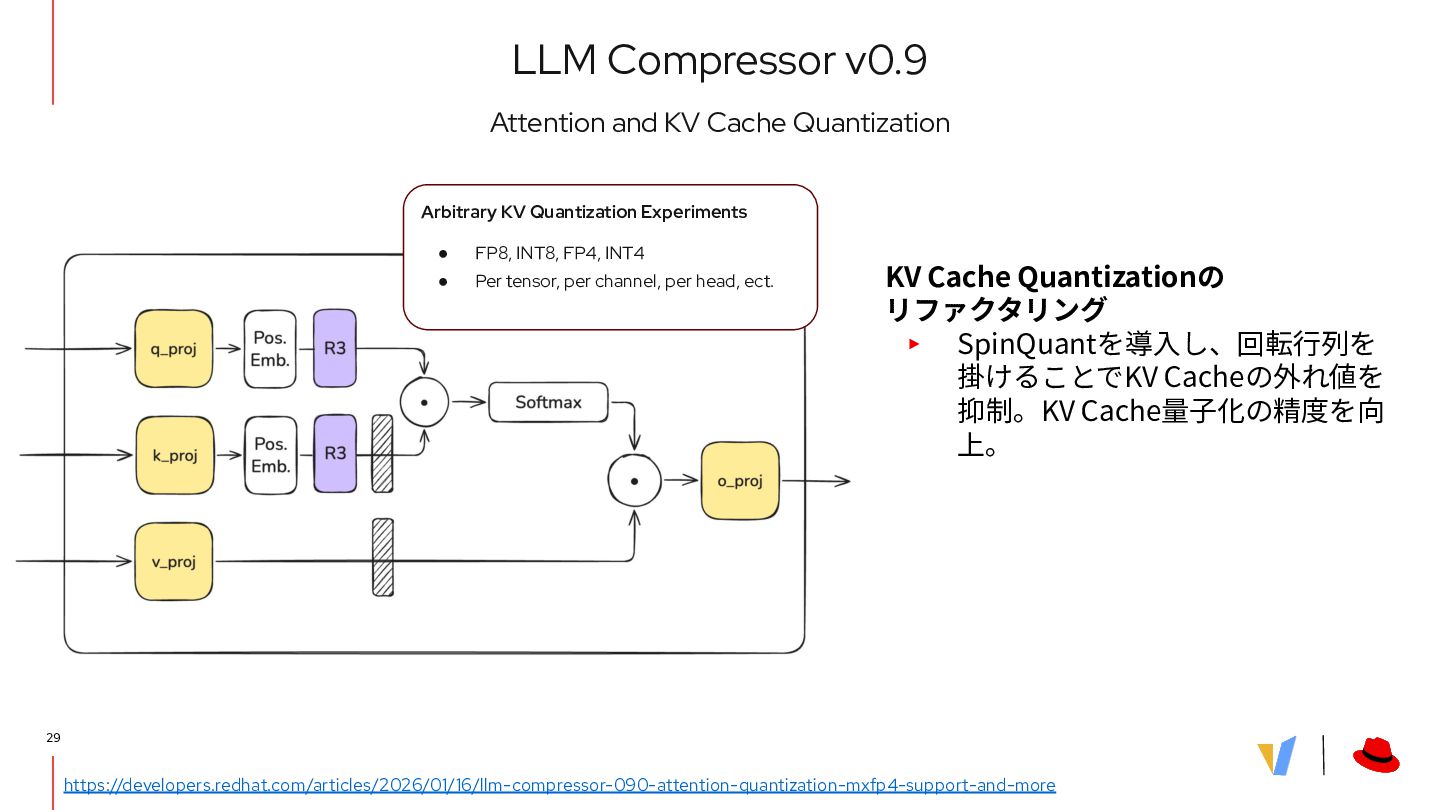
最新の量子化アルゴリズムをサポートし、モデルサ イズを削減しつつ、デグレーションを抑止 ▪ GPTQ, AWQ, Smooth Quant, Spin Quant, AutoRound ▪ INT8, FP8, INT4, NVFP4, MXFP4(experimental) ▪ Weight Quantization, Activation Quantization, KV Cache Quantization • vLLMでの実行に最適化されたSafetensor形式の 拡張フォーマット • HF AutoModelとのシームレスな統合 Optimize fine-tune models for inference LLM Compressor
{kind=link}
{kind=link}
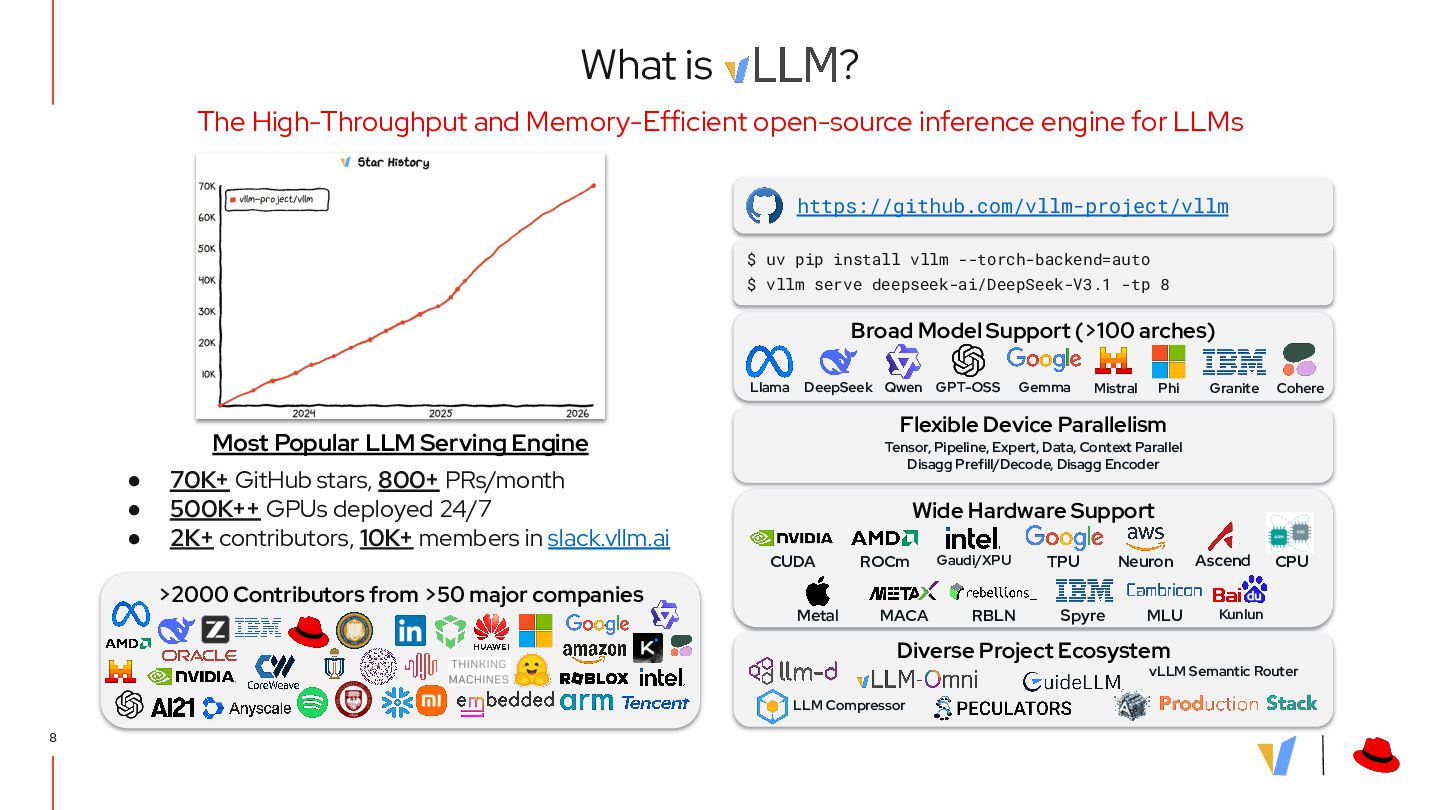{kind=link}
{kind=link}
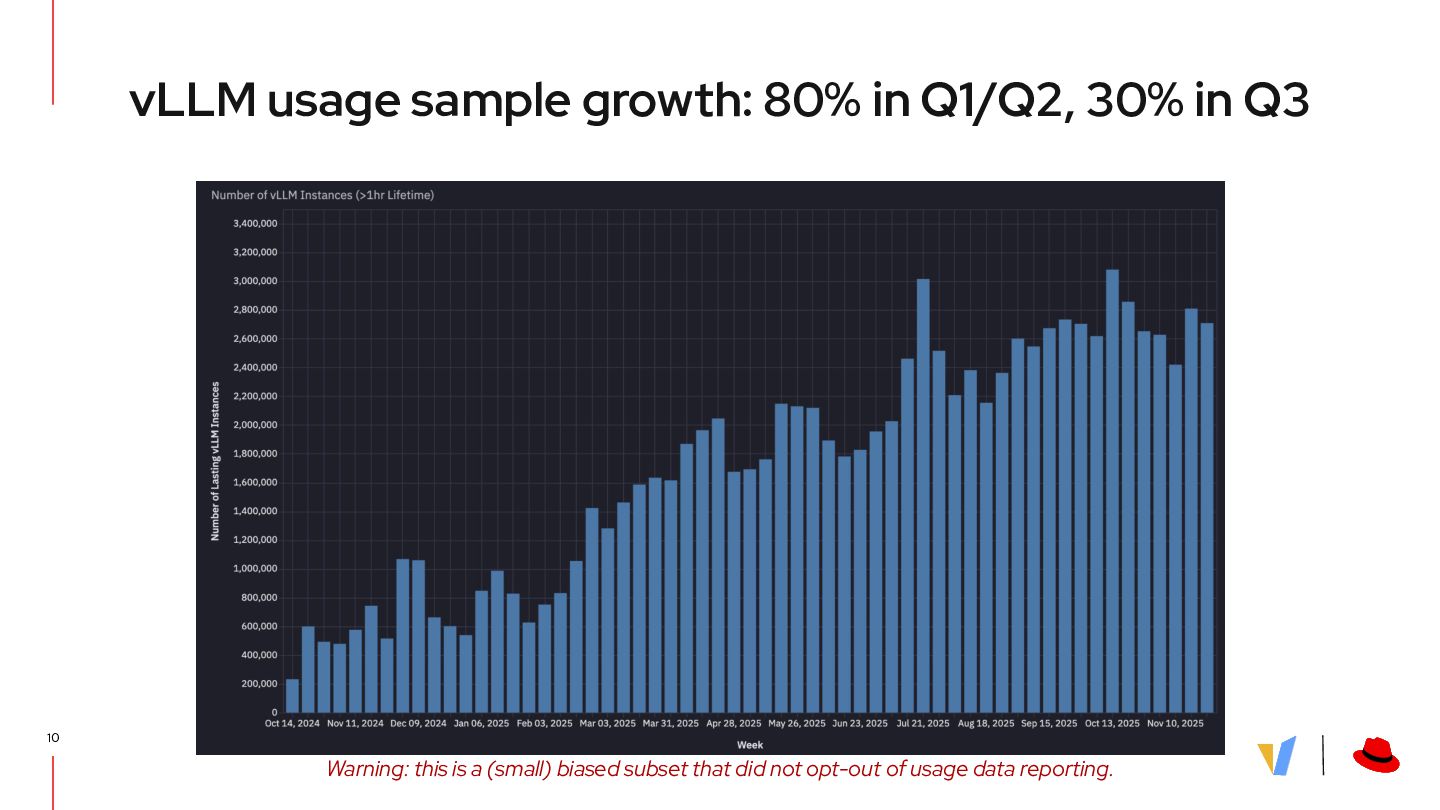{kind=link}
{kind=link}
{kind=link}
{kind=link}
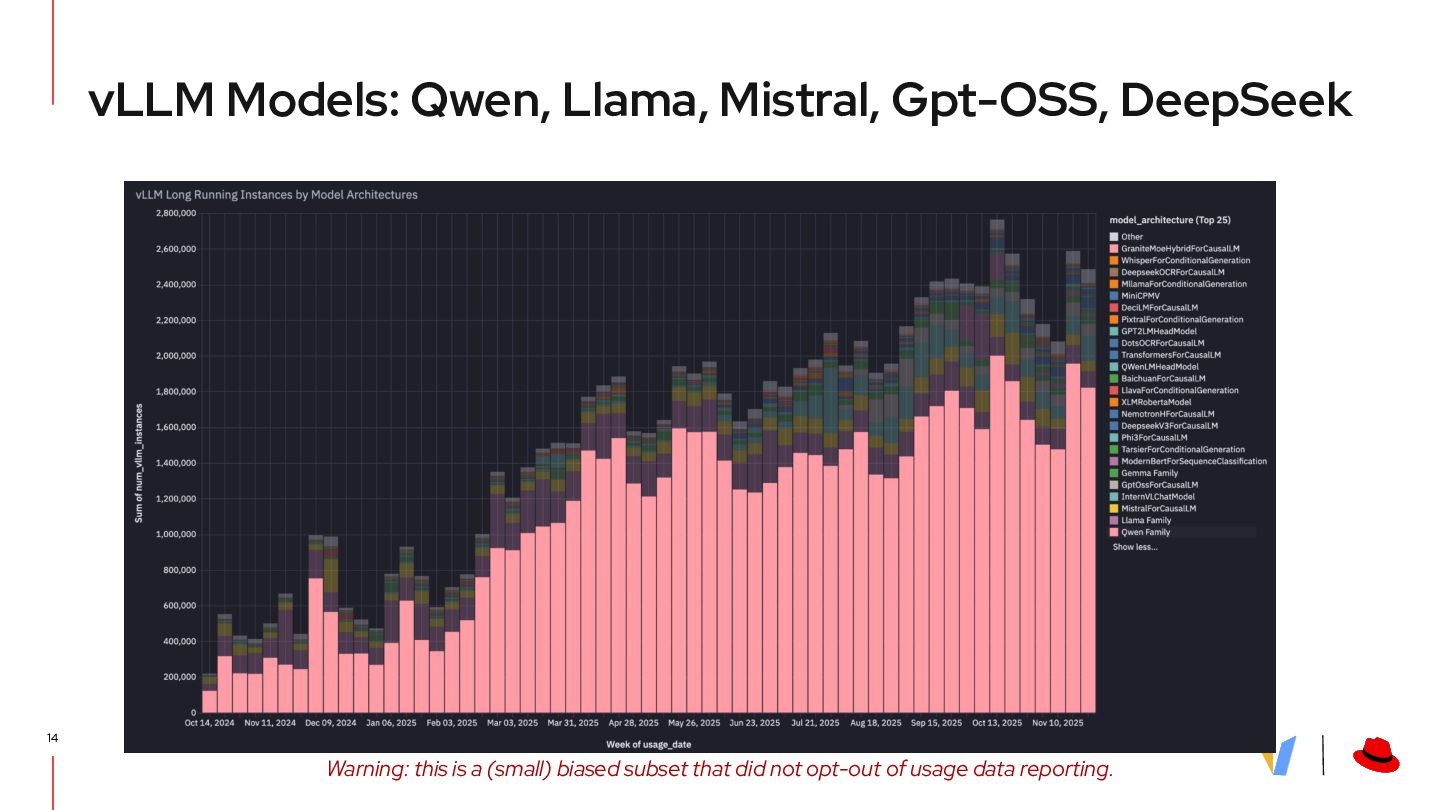{kind=link}
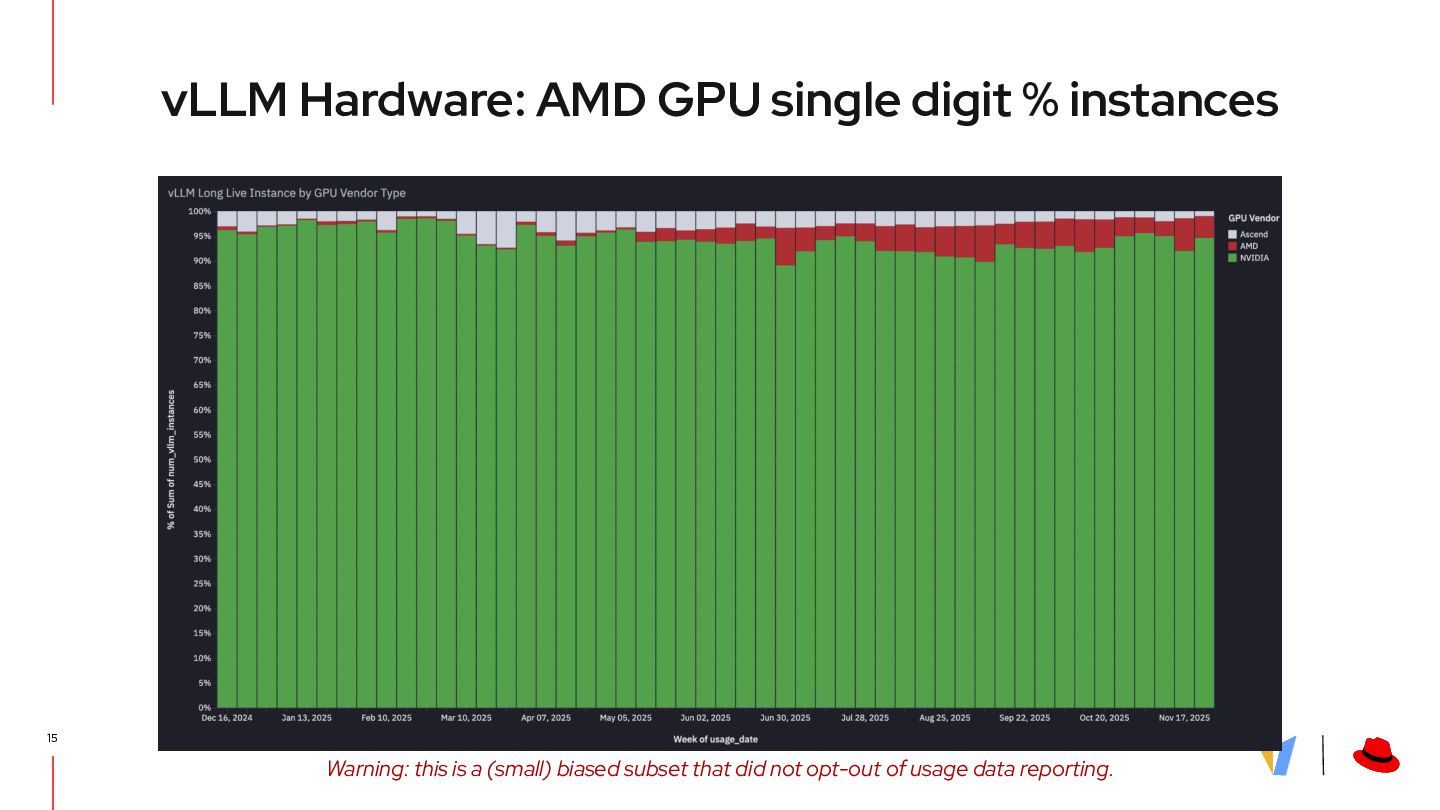{kind=link}
{kind=link}
{kind=link}
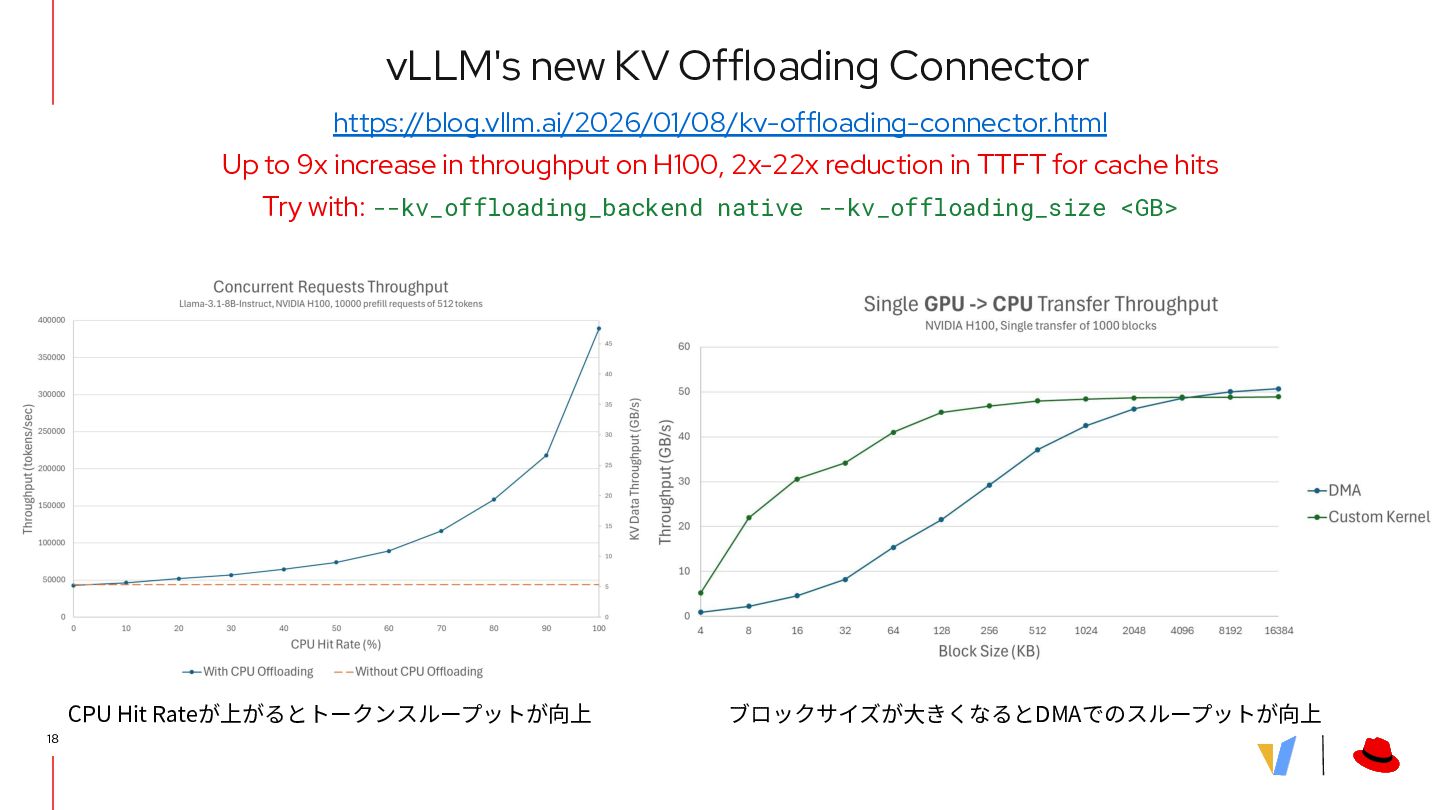{kind=link}
{kind=link}
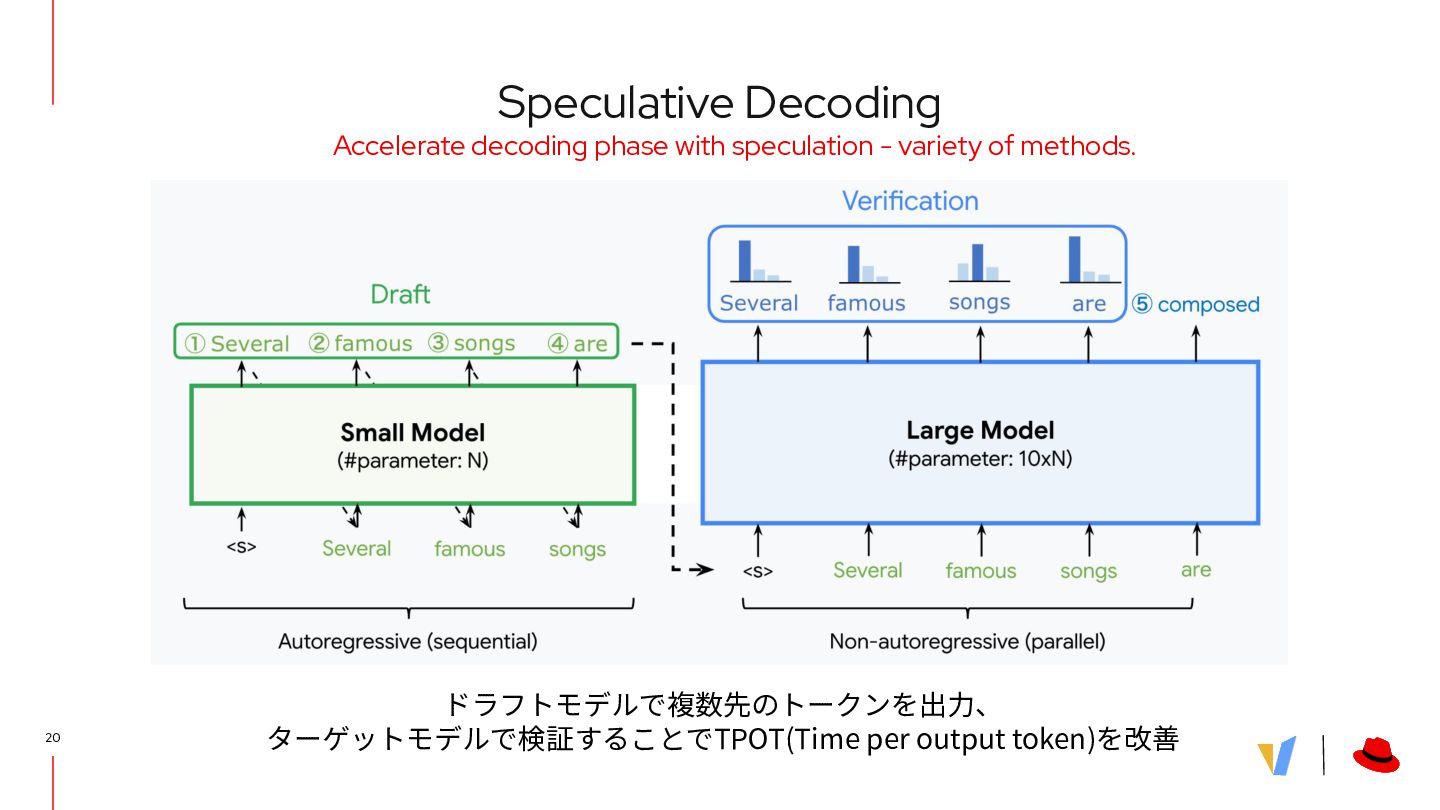{kind=link}
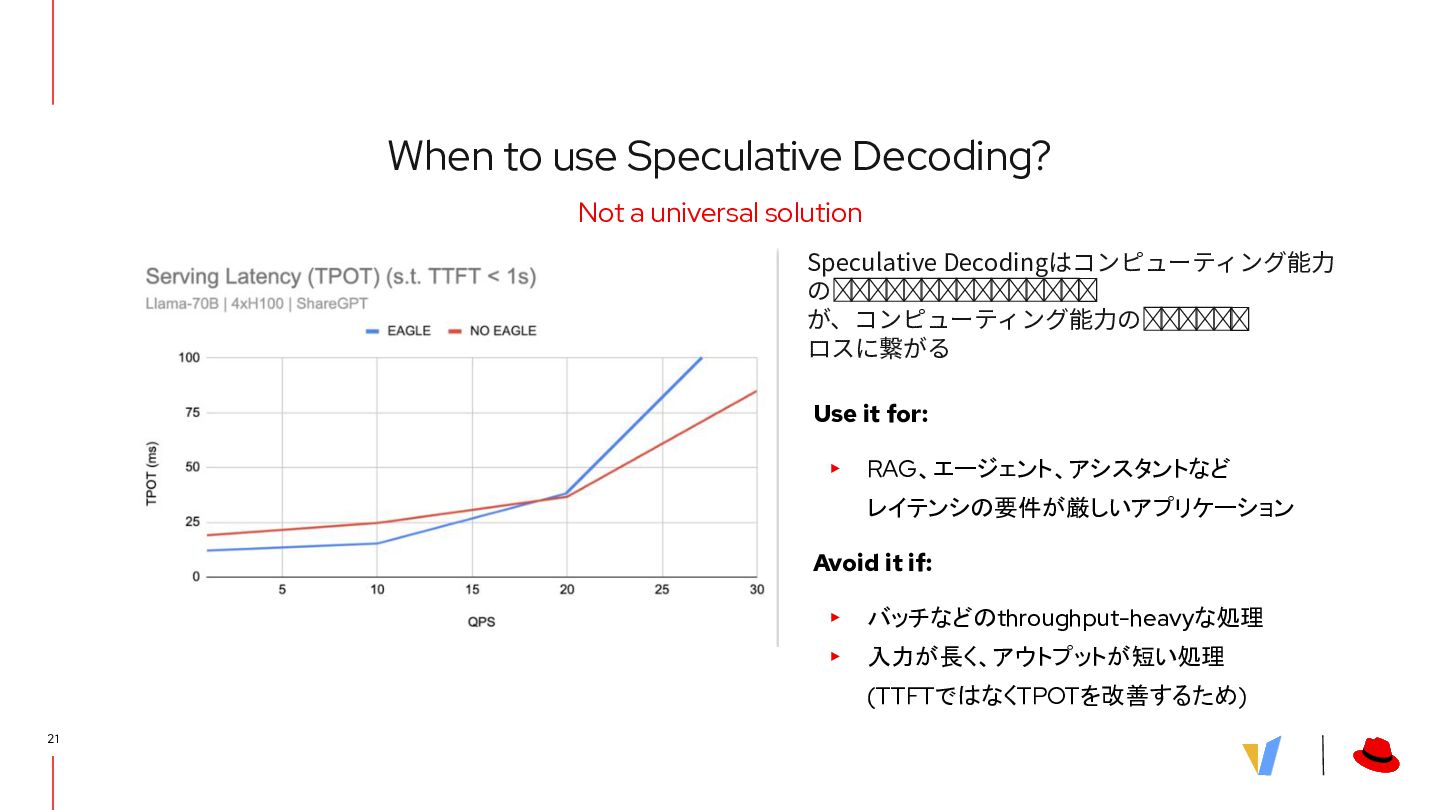{kind=link}
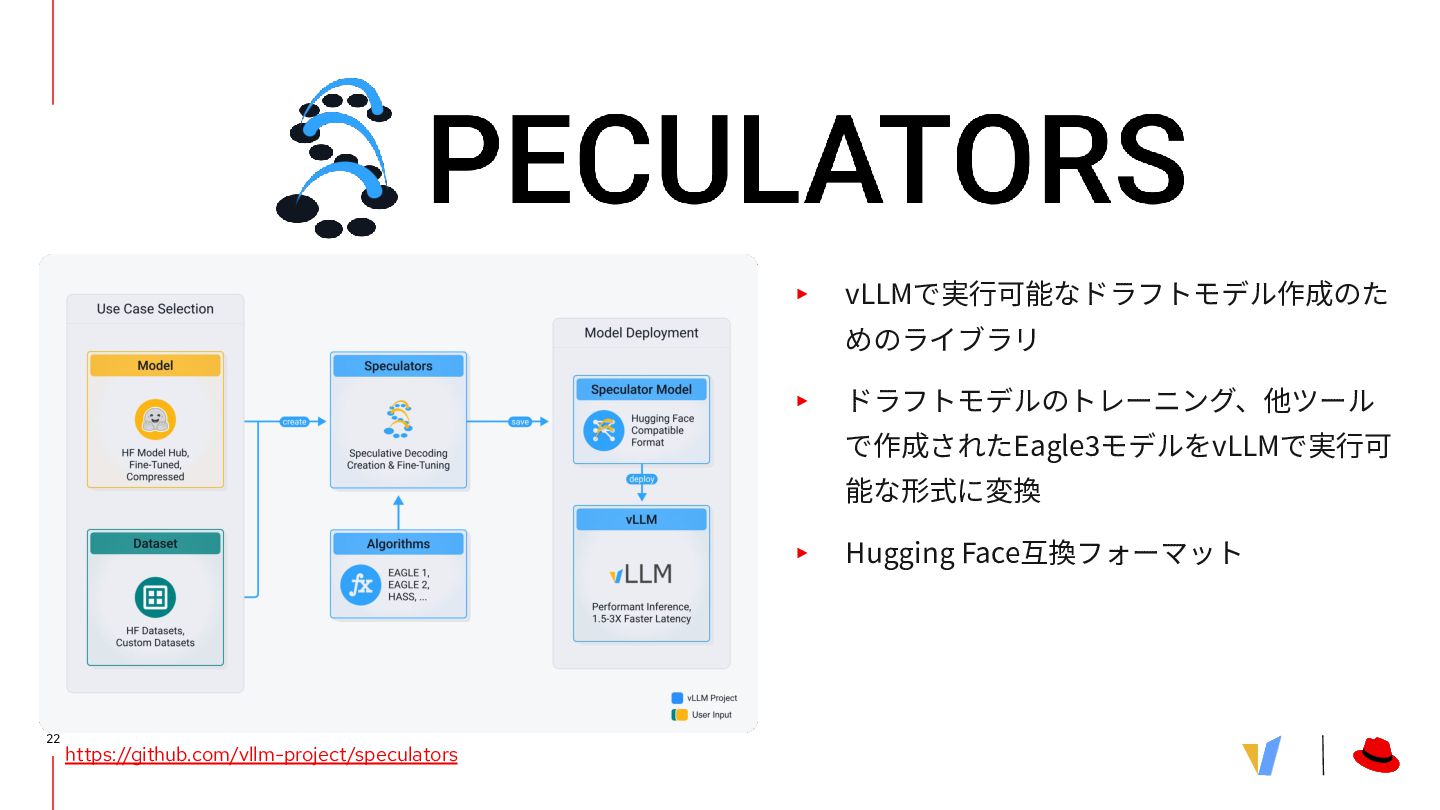{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}