files publication of my HP http://kapper1224.sakura.ne.jp Gadget Hacking User Group Speaker:Kapper 1.準備 2.ローカルLLMと生成AI 3. llamafile演習 4.llama.cpp,Ollama他 5.その他 OSC名古屋2024 2024年5月25日 Place: 中小企業振興会館 15:00〜15:45 メインテーマ「ガジェット&生成AI」
• HP:http://kapper1224.sakura.ne.jp • Slideshare: http://www.slideshare.net/kapper1224 • Mastodon:https://pawoo.net/@kapper1224/ • Facebook:https://www.facebook.com/kapper1224/ • My nobels:https://ncode.syosetu.com/n7491fi/ • My Togetter:https://togetter.com/id/kapper1224 • My Youtube:http://kapper1224.sakura.ne.jp/Youtube.html • My Hobby:Linux、*BSD、and Mobile Devices • My favorite words:The records are the more important than the experiment. • Test Model:Netwalker、Nokia N900、DynabookAZ、RaspberryPi、Nexus7、Nexus5、Chromebook、GPD-WIN、GPD- Pocket、Macbook、NANOTE、Windows Tablet、SailfishOS、UBPorts、postmarketOS、NetBSD and The others... • Recent my Activity: • Hacking Generative AI (Images and LLM) in a lot of devices. • Hacking Linux on Windows10 Tablet (Intel Atom) and Android Smartphone. • Hacking NetBSD and OpenBSD on UEFI and Windows Tablet. • I have over 200 Windows Tablet and 120 ARM Android, and test it now. • 後、最近小説家になろうで異世界で製造業と産業革命の小説書いていますなう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
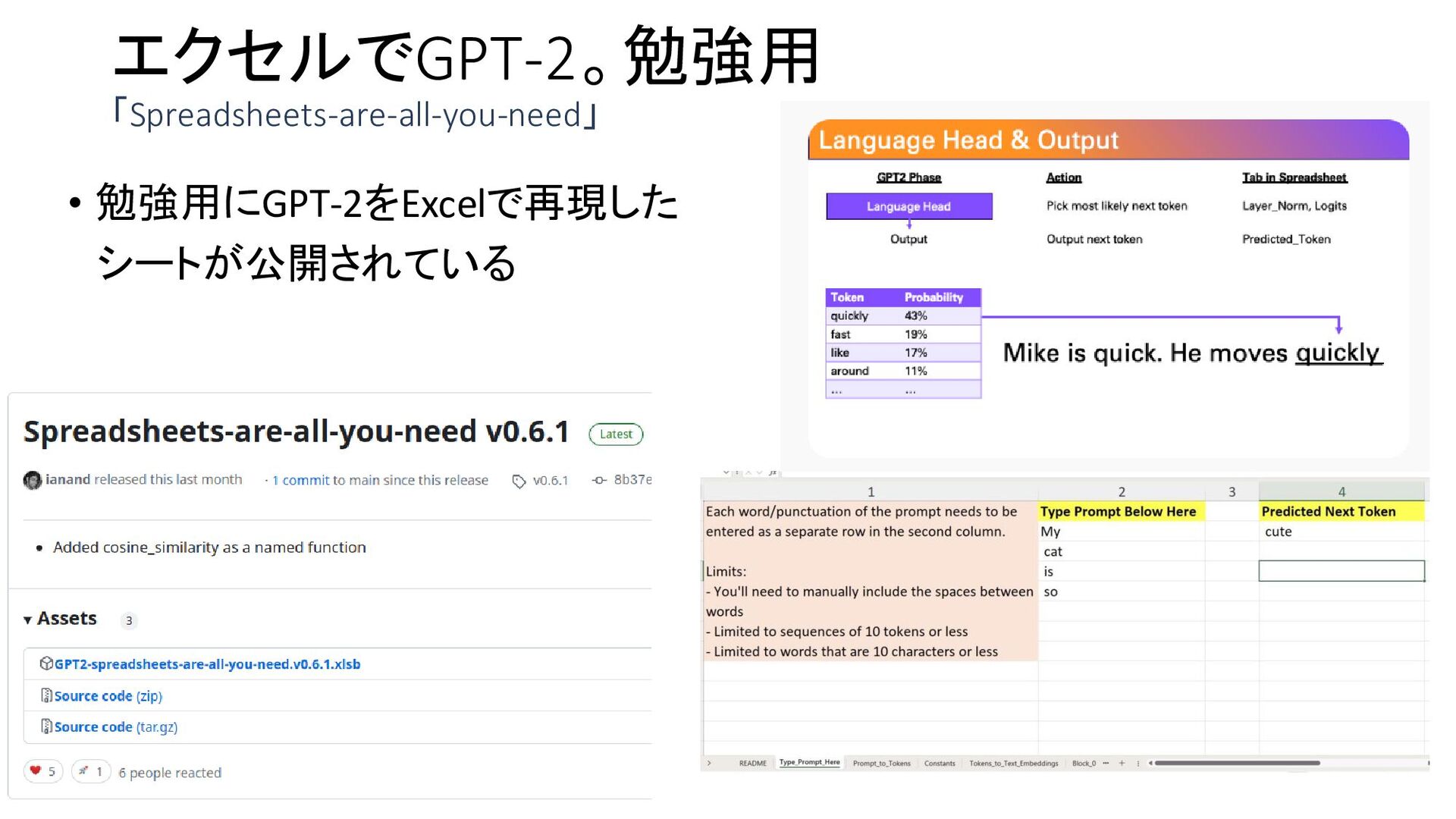{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
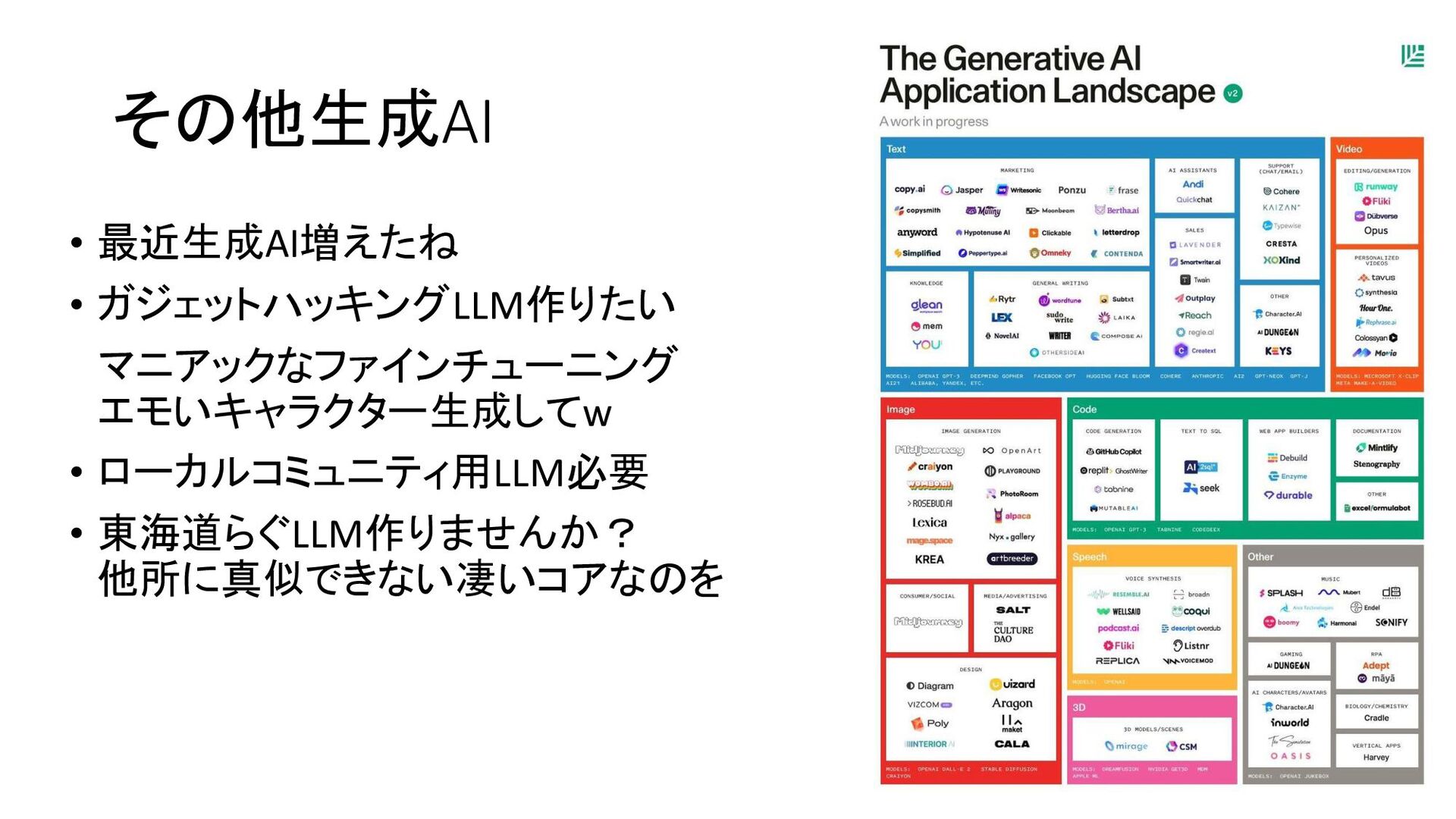
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
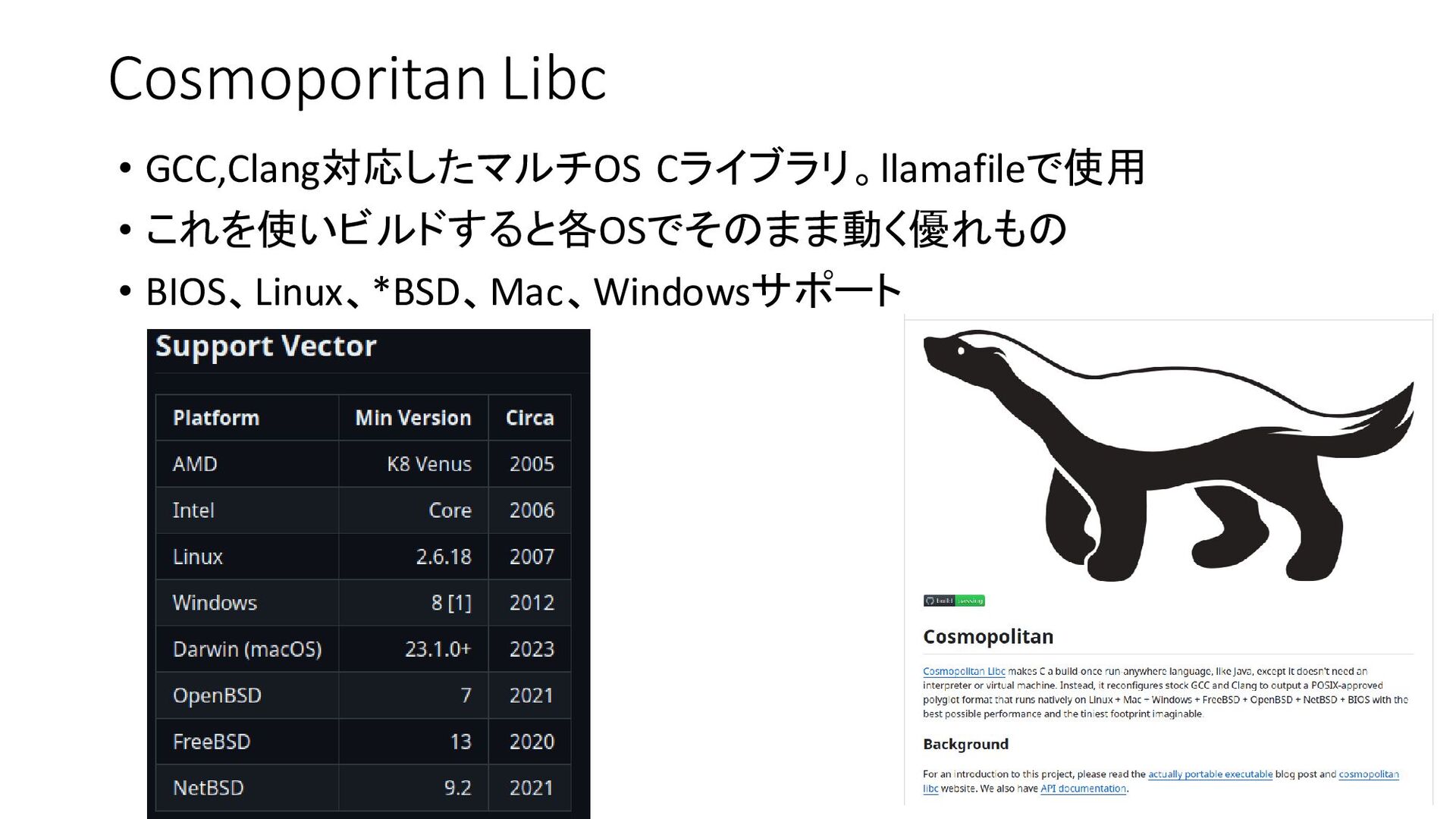{kind=link}
{kind=link}
{kind=link}
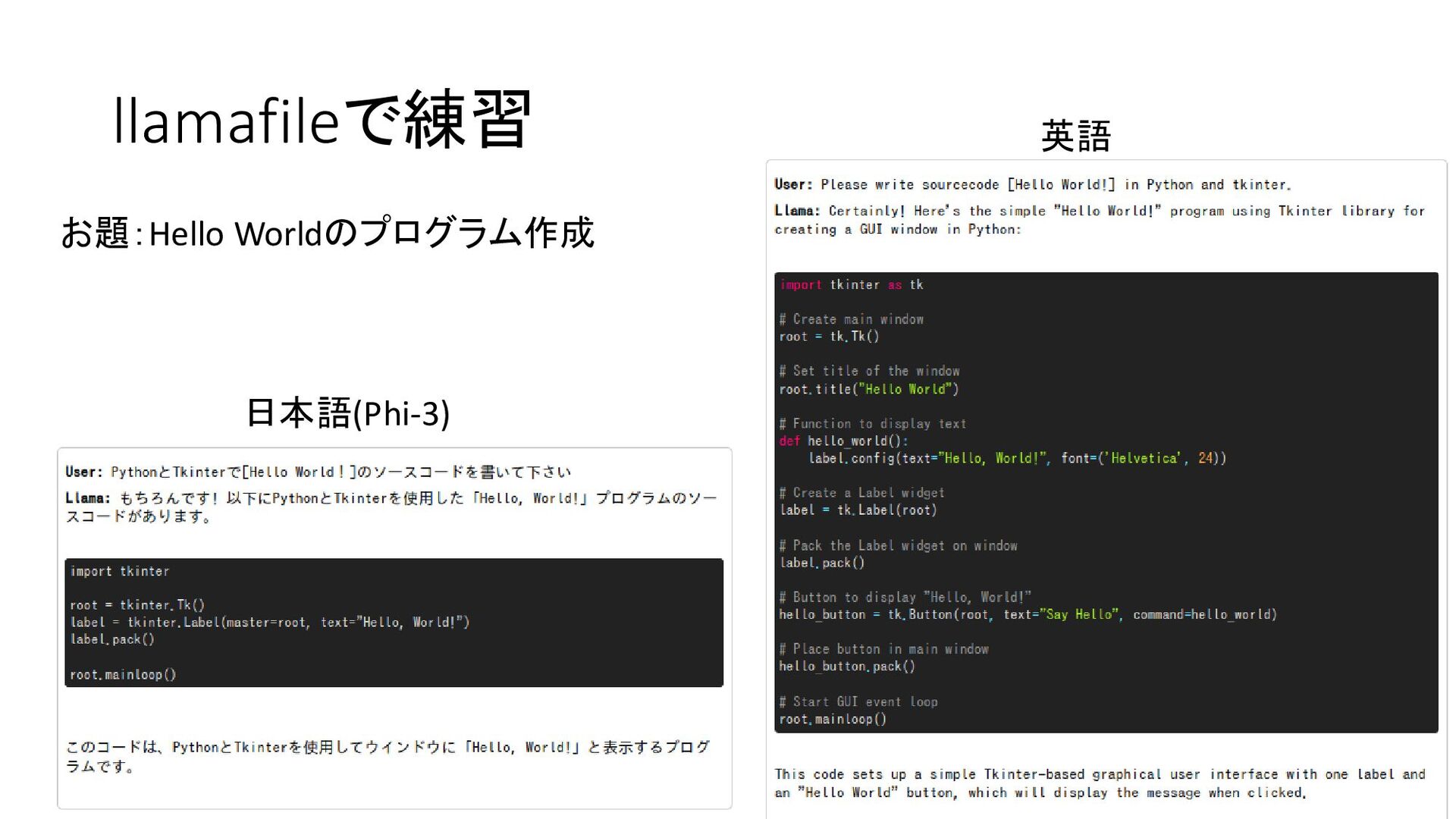
![llamafileで練習 ③こんな画面が出てくるので一番下の 入力欄に英語で質問 例) Please write sourcecode [Hello World!] in](https://files.speakerdeck.com/presentations/9bab177a428b485487e73ef900e63132/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
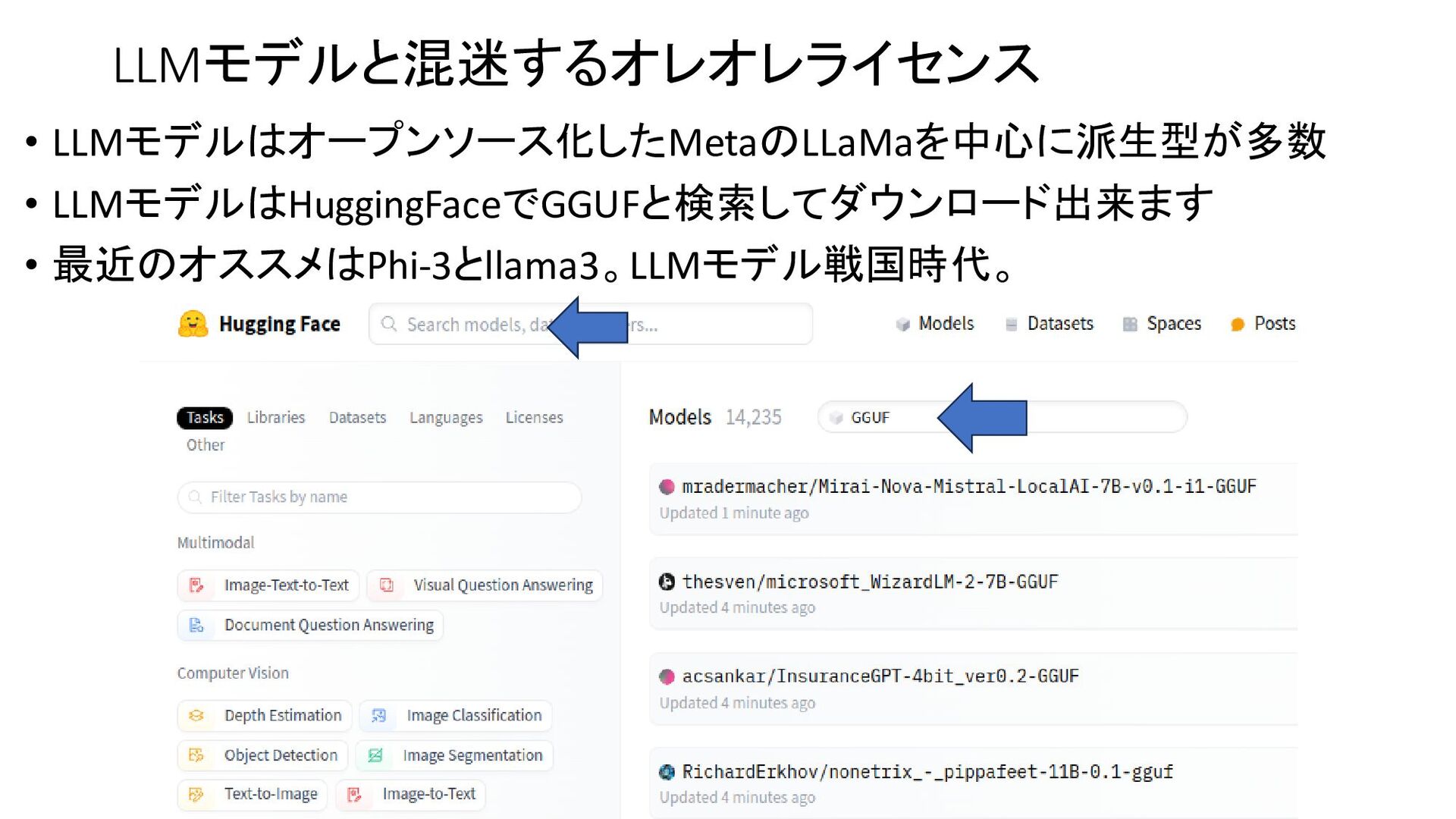{kind=link}
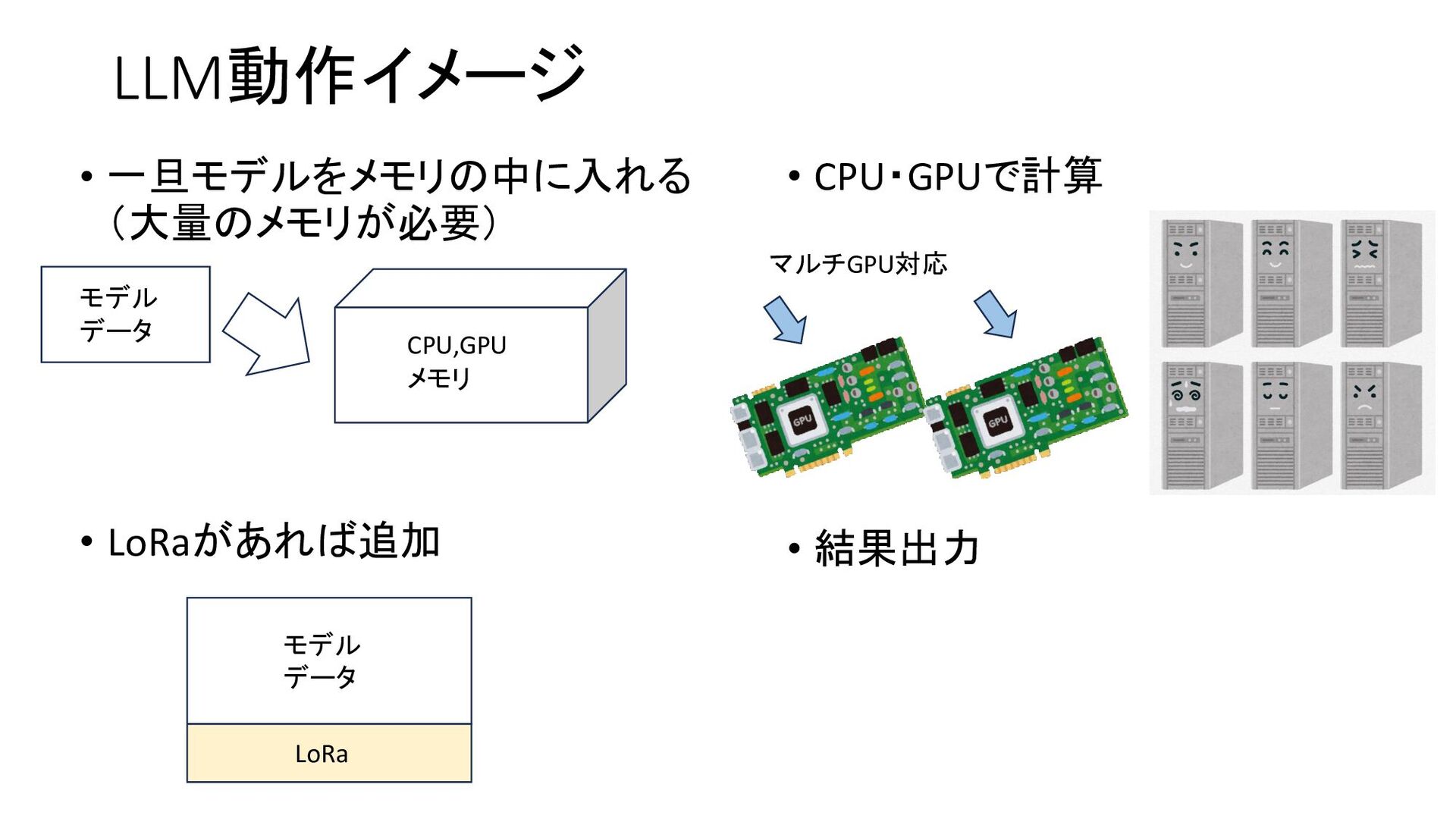{kind=link}
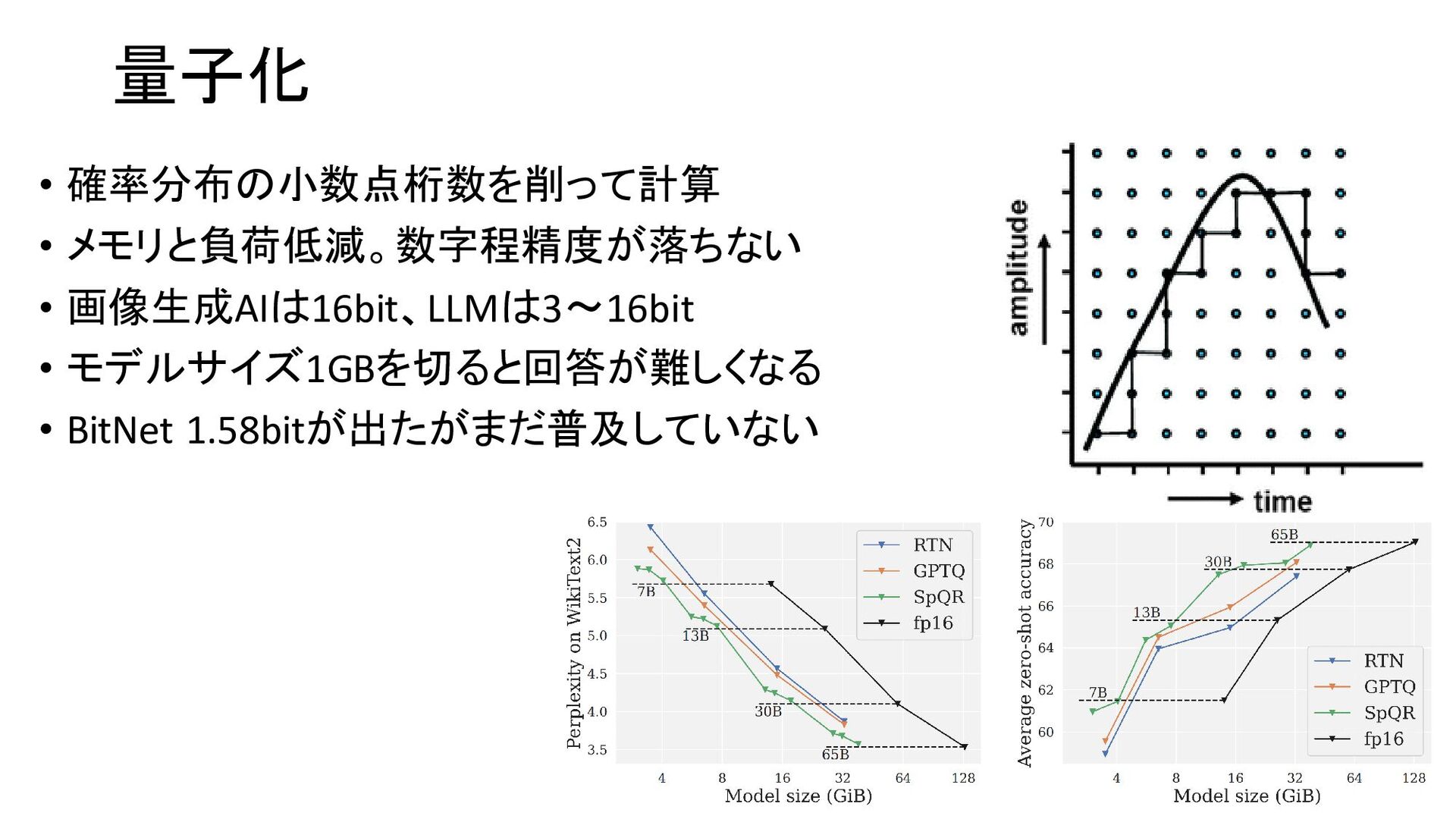{kind=link}
{kind=link}
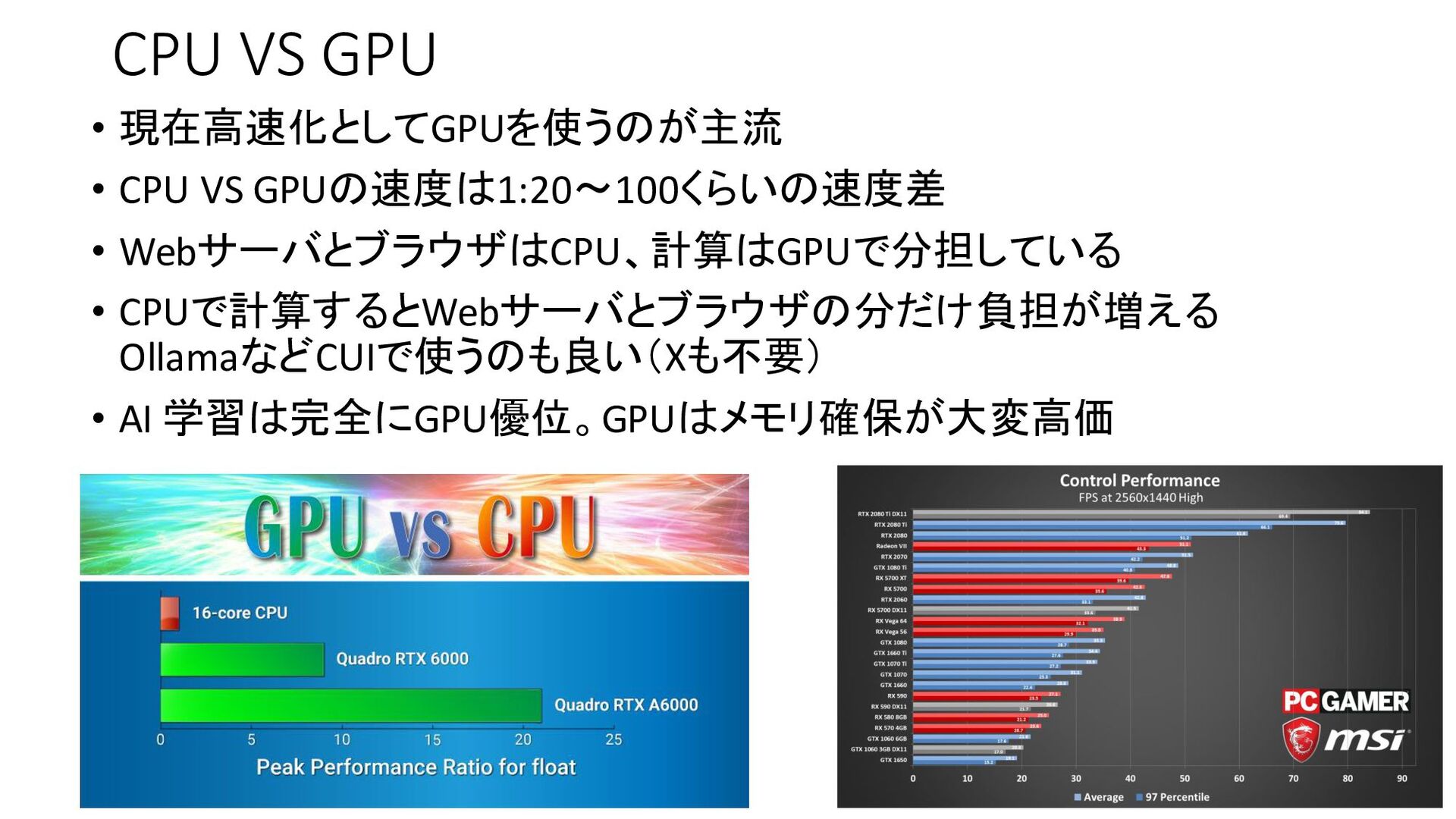{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}