Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIエージェントの隔離技術の徹底比較
Search
kawayu
May 24, 2026
Programming
520
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIエージェントの隔離技術の徹底比較
kawayu
May 24, 2026
More Decks by kawayu
See All by kawayu
メモリウォールを超えて:キャッシュメモリ技術の進歩
kawayu
0
3.6k
Other Decks in Programming
See All in Programming
Claude Team Plan導入・ガイド
tk3fftk
0
220
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
120
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
390
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
540
AIエージェントで 変わるAndroid開発環境
takahirom
2
710
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
霧の中の代数的エフェクト
funnyycat
1
420
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.3k
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
150
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
180
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
140
Featured
See All Featured
Abbi's Birthday
coloredviolet
3
8.8k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Making Projects Easy
brettharned
120
6.7k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Paper Plane (Part 1)
katiecoart
PRO
1
9.8k
Navigating Weather and Climate Data
rabernat
0
400
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The untapped power of vector embeddings
frankvandijk
2
1.8k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Transcript
AIエージェントの 隔離技術の徹底比較 — Container / gVisor / VM・microVM / Linux
on WASM — kawayu_u 開発合宿 2026.5.16-17 @ 鳴子温泉 1
目次 01 危険シナリオ 02 比較軸 03 Container 04 gVisor 05
VM / microVM 06 Linux on WASM 番外編 07 答え合わせ:危険シナリオ × 隔離レベル 08 まとめ 2
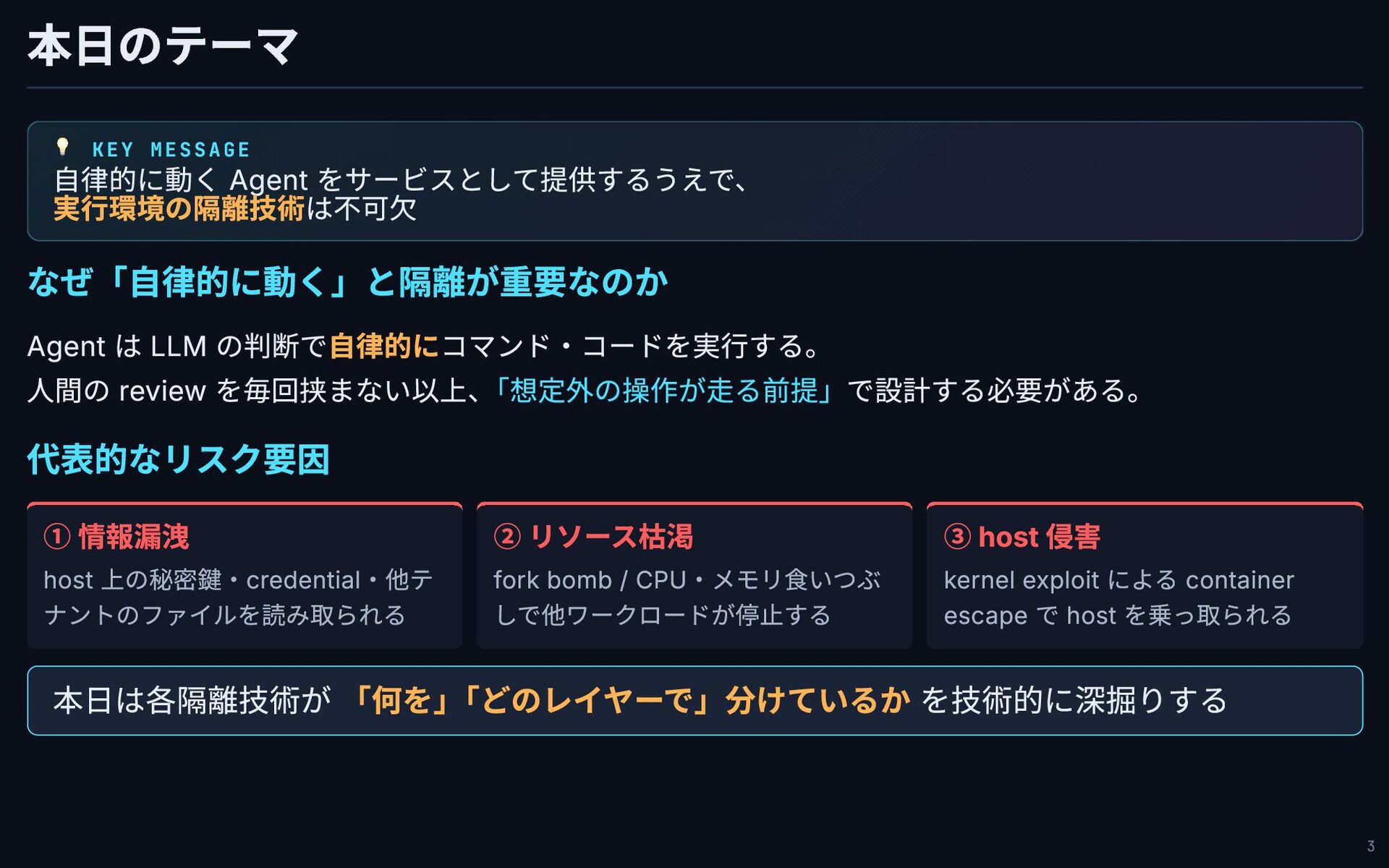
本日のテーマ 💡 KEY MESSAGE 自律的に動く Agent をサービスとして提供するうえで、 実行環境の隔離技術は不可欠 なぜ「自律的に動く」と隔離が重要なのか Agent
は LLM の判断で自律的にコマンド・コードを実行する。 人間の review を毎回挟まない以上、 「想定外の操作が走る前提」で設計する必要がある。 代表的なリスク要因 ① 情報漏洩 host 上の秘密鍵・credential・他テ ナントのファイルを読み取られる ② リソース枯渇 fork bomb / CPU・メモリ食いつぶ しで他ワークロードが停止する ③ host 侵害 kernel exploit による container escape で host を乗っ取られる 本日は各隔離技術が 「何を」 「どのレイヤーで」分けているか を技術的に深掘りする 3
01 危険シナリオ 「Agent が暴走したらどうなるか」を 4 つの具体シナリオで示す。 4
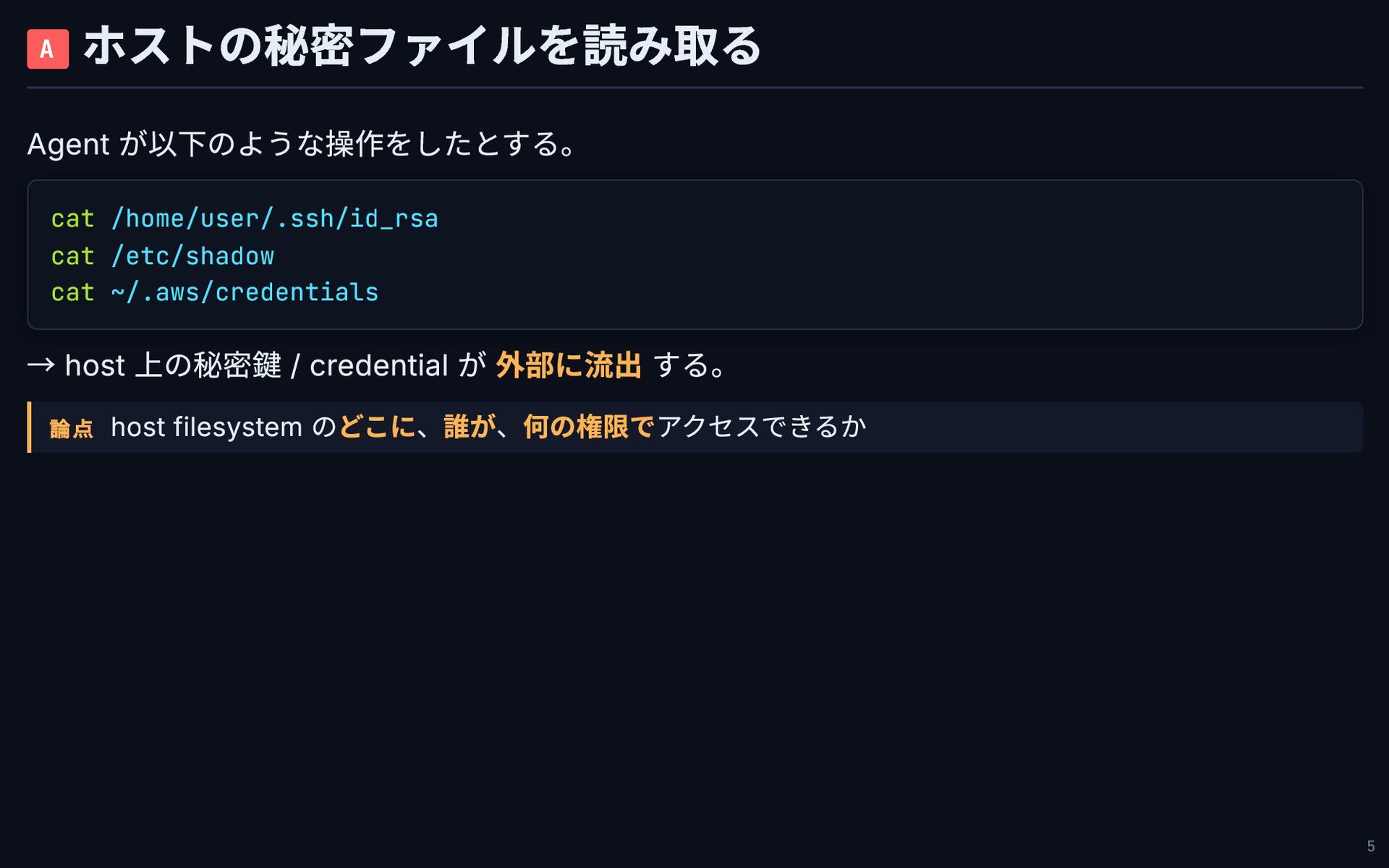
A ホストの秘密ファイルを読み取る Agent が以下のような操作をしたとする。 cat /home/user/.ssh/id_rsa cat /etc/shadow cat ~/.aws/credentials
→ host 上の秘密鍵 / credential が 外部に流出 する。 論点 host filesystem のどこに、誰が、何の権限でアクセスできるか 5
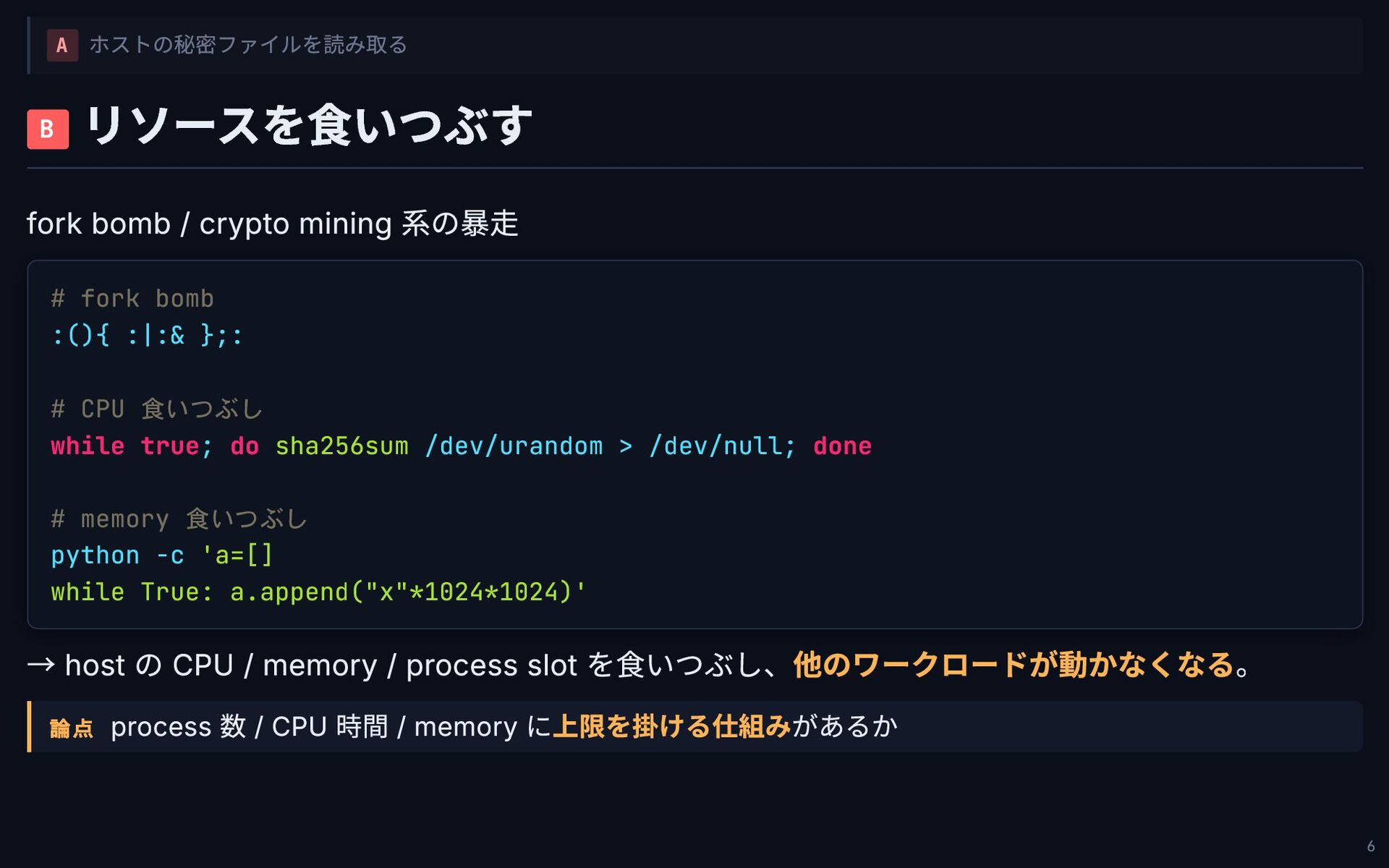
A ホストの秘密ファイルを読み取る B リソースを食いつぶす fork bomb / crypto mining 系の暴走
# fork bomb :(){ :|:& };: # CPU 食いつぶし while true; do sha256sum /dev/urandom > /dev/null; done # memory 食いつぶし python -c 'a=[] while True: a.append("x"*1024*1024)' → host の CPU / memory / process slot を食いつぶし、他のワークロードが動かなくなる。 論点 process 数 / CPU 時間 / memory に上限を掛ける仕組みがあるか 6
A ホストの秘密ファイルを読み取る B リソースを食いつぶす C kernel exploit による container escape
代表例:Dirty Pipe(CVE-2022-0847) Linux kernel 5.8 以降の splice() 周りの bug pipe の flag が初期化されない条件下で、read-only file の page cache に書き込みができる 結果として: /etc/passwd のような read-only file を書き換えできる SUID binary を書き換えて root 権限を得られる container 内から host 上のファイルが書き換えられ、container escape が可能 [ container 内の Agent ] ↓ splice() に bug [ host Linux kernel ] ← 共有しているのでここの bug が直接踏める ↓ host の任意のファイル書き換え → container escape 論点 host kernel をどこまで共有しているか。splice() のような syscall が host kernel に直接届くか 7
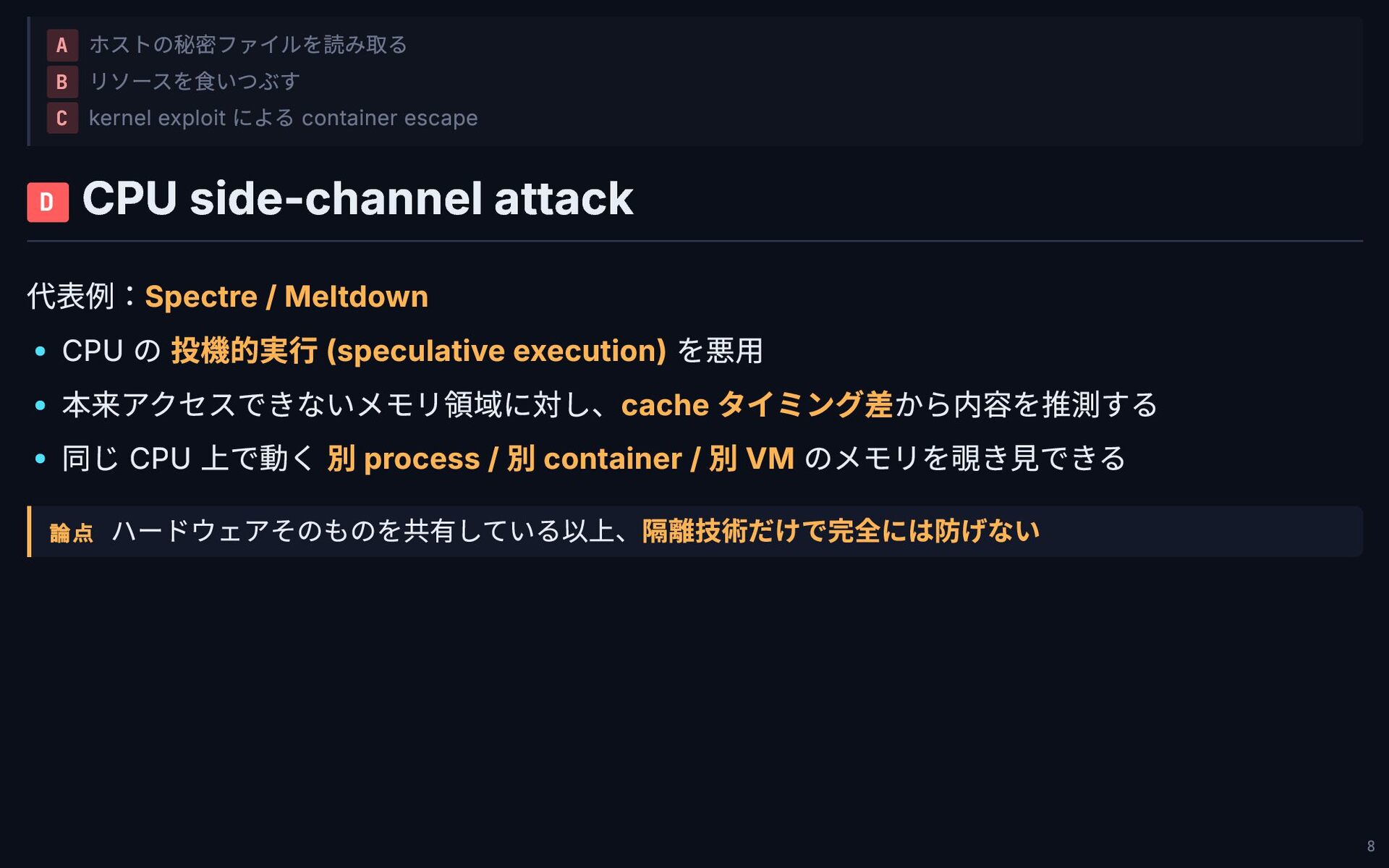
A ホストの秘密ファイルを読み取る B リソースを食いつぶす C kernel exploit による container escape
D CPU side-channel attack 代表例:Spectre / Meltdown CPU の 投機的実行 (speculative execution) を悪用 本来アクセスできないメモリ領域に対し、cache タイミング差から内容を推測する 同じ CPU 上で動く 別 process / 別 container / 別 VM のメモリを覗き見できる 論点 ハードウェアそのものを共有している以上、隔離技術だけで完全には防げない 8
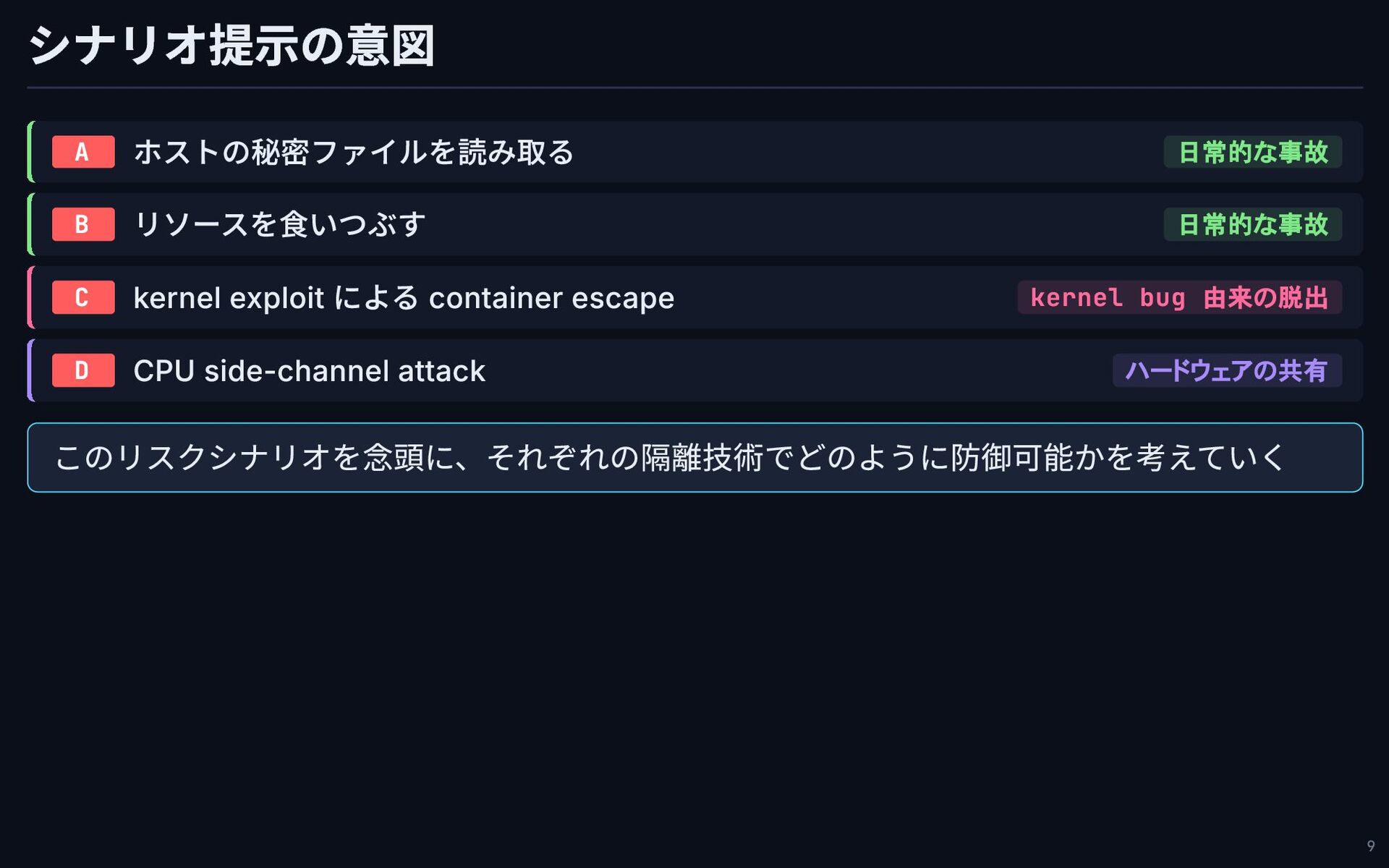
シナリオ提示の意図 A ホストの秘密ファイルを読み取る 日常的な事故 B リソースを食いつぶす 日常的な事故 C kernel exploit
による container escape kernel bug 由来の脱出 D CPU side-channel attack ハードウェアの共有 このリスクシナリオを念頭に、それぞれの隔離技術でどのように防御可能かを考えていく 9
02 比較軸 隔離技術の違いは 「何を分けているか」 と 「どこで境界を作っているか」 で理解できる。 10
8 つの比較軸 観点 見るポイント ファイル隔離 host のファイルに触れるか プロセス隔離 他のプロセスが見えるか ネットワーク隔離
外部通信を制御できるか リソース制御 CPU / memory / pids / io / time を制限できるか syscall 面 host kernel にどれだけ直接触れるか kernel 隔離 host と kernel を共有するか 起動速度 Agent ごとに即時作成できるか (Ephemeral 性) 互換性 普通の Linux アプリがそのまま動くか 11
F I G 0 1 隔離レベルのスペクトル SPECTRUM OF ISOLATION VIEW
+ LIMIT Container 見える世界とリソース量を分け る 境界 = host kernel namespaces(mount/pid/net …) cgroups(cpu/mem/pids/io) 01 SYSCALL SHIM gVisor syscall 面を userspace kernel で吸収 境界 = Sentry runc → runsc に差し替え Sentry + Gofer が常駐 02 KERNEL APART VM / microVM kernel そのものを分ける 境界 = guest kernel Firecracker / Cloud Hypervisor Kata Containers 03 DIFFERENT MODEL Linux on WASM 実行モデル自体を別物にする 境界 = WASM sandbox container2wasm / WebVM / v86 capability-based · WASI ★ 弱い・軽い 番外編 12
03 Container 見える世界を分ける 13
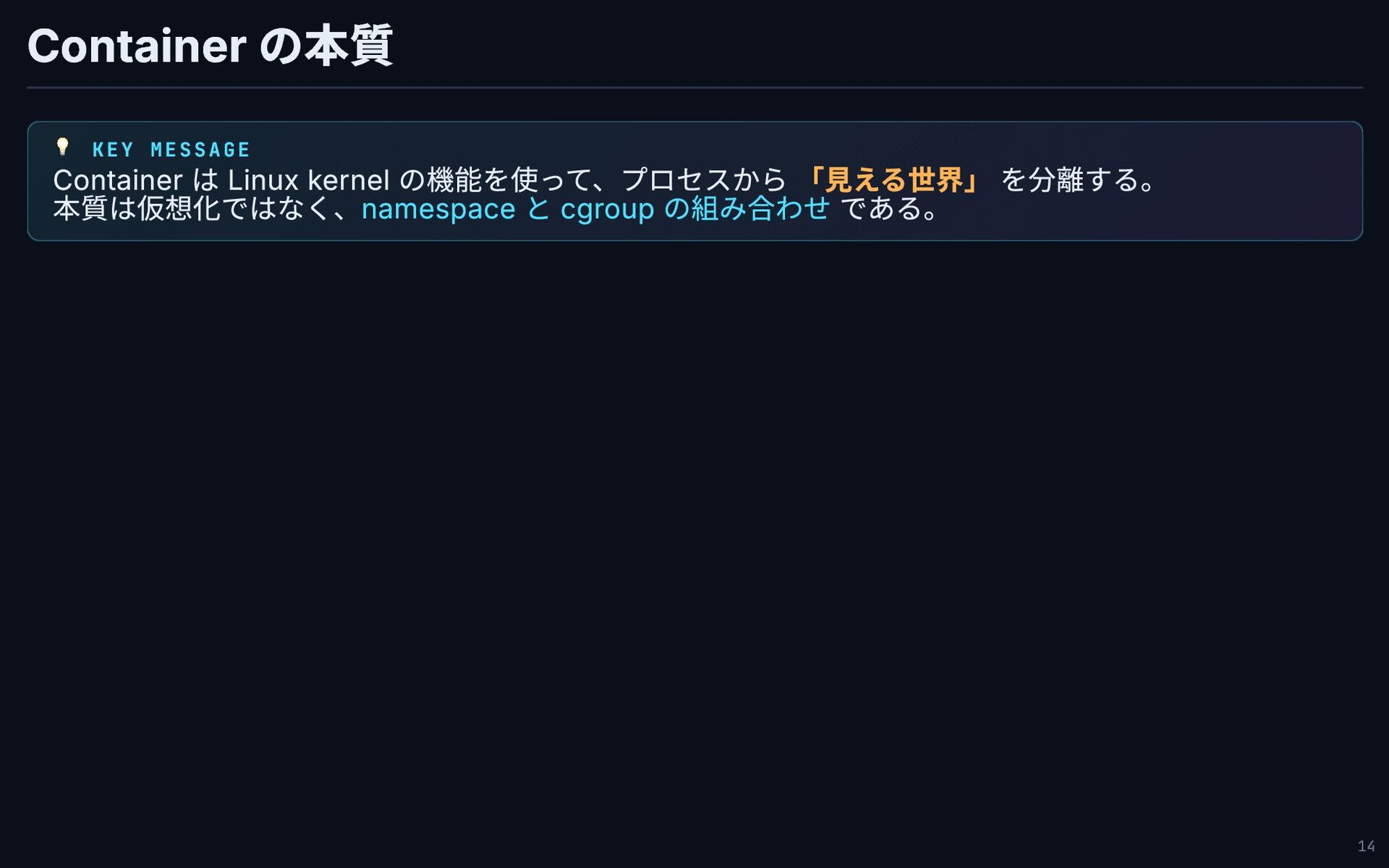
Container の本質 💡 KEY MESSAGE Container は Linux kernel の機能を使って、プロセスから
「見える世界」 を分離する。 本質は仮想化ではなく、namespace と cgroup の組み合わせ である。 14
全体像:containerd → runc → container User / Docker CLI /
kubelet ↓ Docker daemon / kubelet CRI client ↓ containerd image pull、snapshotter / overlayfs による rootfs 準備、OCI config 生成 ↓ containerd-shim-runc-v2 containerd から独立して container task を管理、runc を呼び出す ↓ runc namespaces 作成 / 参加、cgroups 設定、mounts / rootfs 設定、container init process 起動、起動後は基本的に終了 ↓ container process namespaces 内で実行、cgroups に所属、overlayfs 等で構成された rootfs を見 る ↓ syscall host Linux kernel 15
namespaces:見える世界を分ける Linux kernel が提供する「同じリソースを別々の view で見せる」機能群。 namespace 分離する対象 例 mount
filesystem の mount point / 、 /proc 、 /sys を container 専用にする pid プロセス ID 空間 container 内で PID 1 になる net network interface / route / iptables / port container 専用の eth0 / IP / port を持つ ipc System V IPC、POSIX message queue host の IPC が見えない uts hostname / domain name container 内で異なる hostname を持てる user UID / GID マッピング container 内の root を host の非 root にマップ cgroup cgroup hierarchy の見え方 自分が属する cgroup tree しか見えなくする time system clock の見え方(比較的新しい) boot time / clock を別に持てる 16
cgroups (v2):リソースを制限する process のグループに対してリソース上限を設定する kernel 機能。v2 では single hierarchy に統
一。 controller 制限対象 例 cpu CPU 時間 weight / max でクォータ制御 memory RAM / swap memory.max を超えると OOM kill pids プロセス / スレッド数 pids.max で fork bomb 対策 io block I/O 帯域 per-device の read/write 制限 hugetlb huge page 利用上限 17
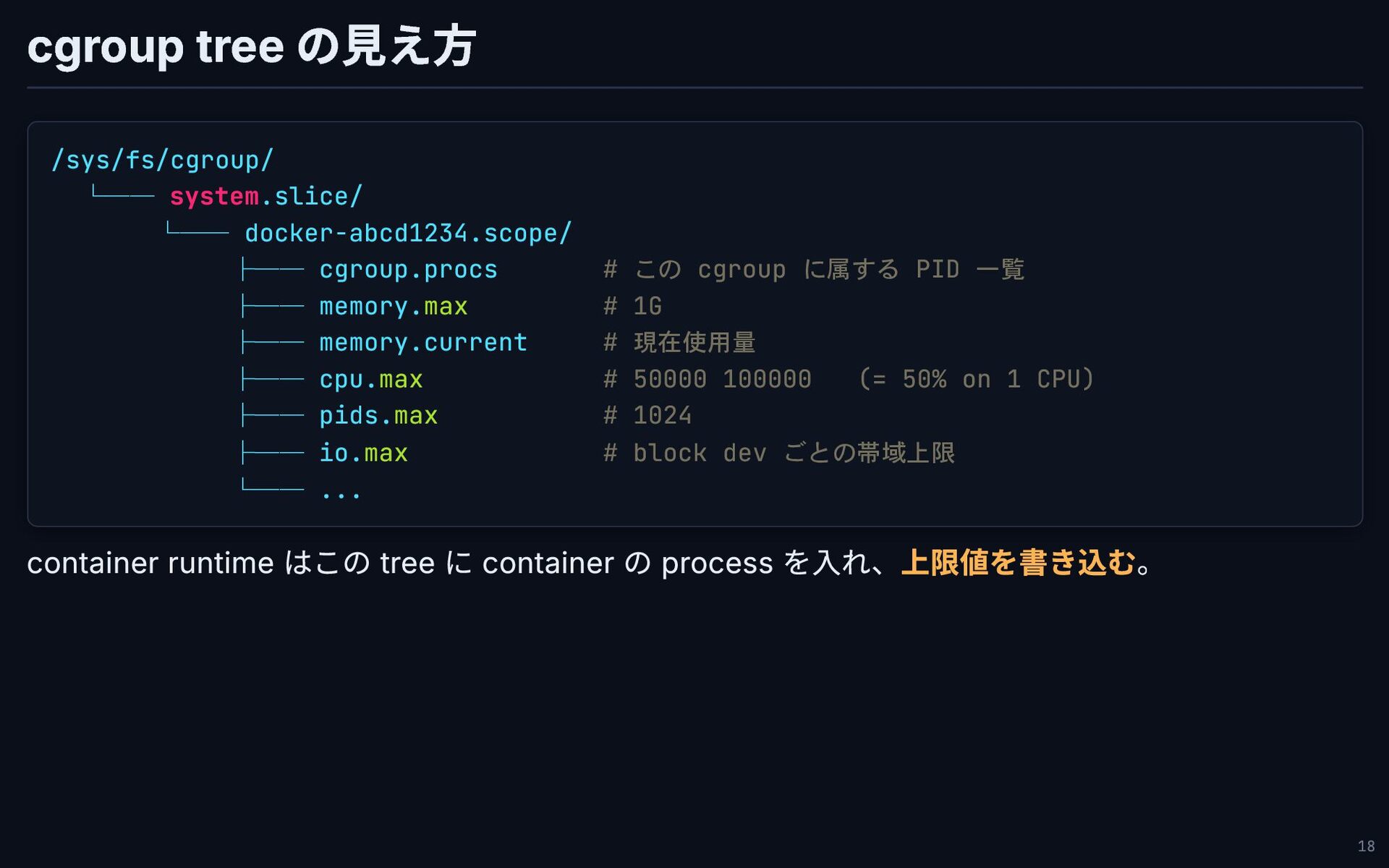
cgroup tree の見え方 /sys/fs/cgroup/ └── system.slice/ └── docker-abcd1234.scope/ ├── cgroup.procs
# この cgroup に属する PID 一覧 ├── memory.max # 1G ├── memory.current # 現在使用量 ├── cpu.max # 50000 100000 (= 50% on 1 CPU) ├── pids.max # 1024 ├── io.max # block dev ごとの帯域上限 └── ... container runtime はこの tree に container の process を入れ、上限値を書き込む。 18
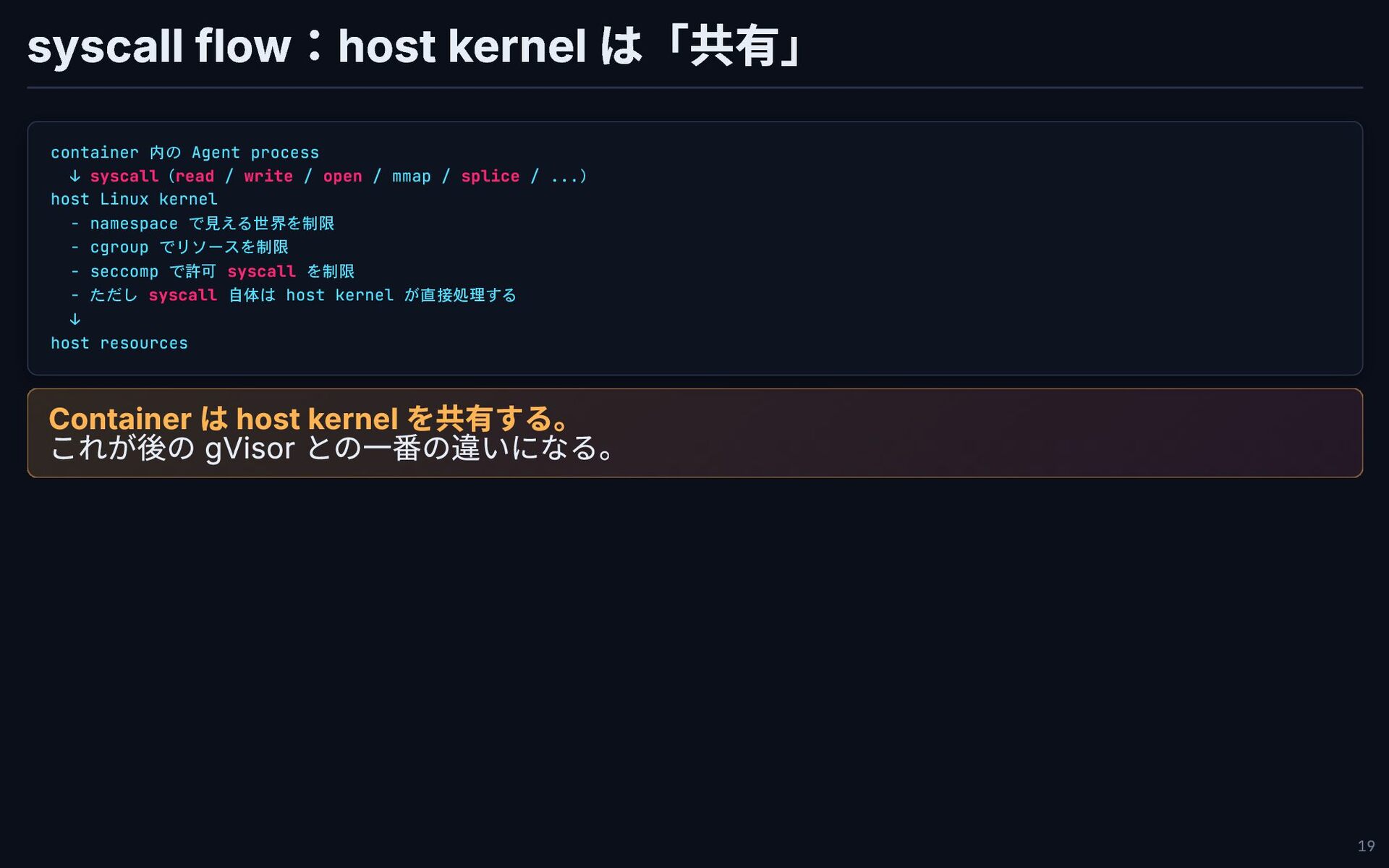
syscall flow:host kernel は「共有」 container 内の Agent process ↓ syscall(read
/ write / open / mmap / splice / ...) host Linux kernel - namespace で見える世界を制限 - cgroup でリソースを制限 - seccomp で許可 syscall を制限 - ただし syscall 自体は host kernel が直接処理する ↓ host resources Container は host kernel を共有する。 これが後の gVisor との一番の違いになる。 19
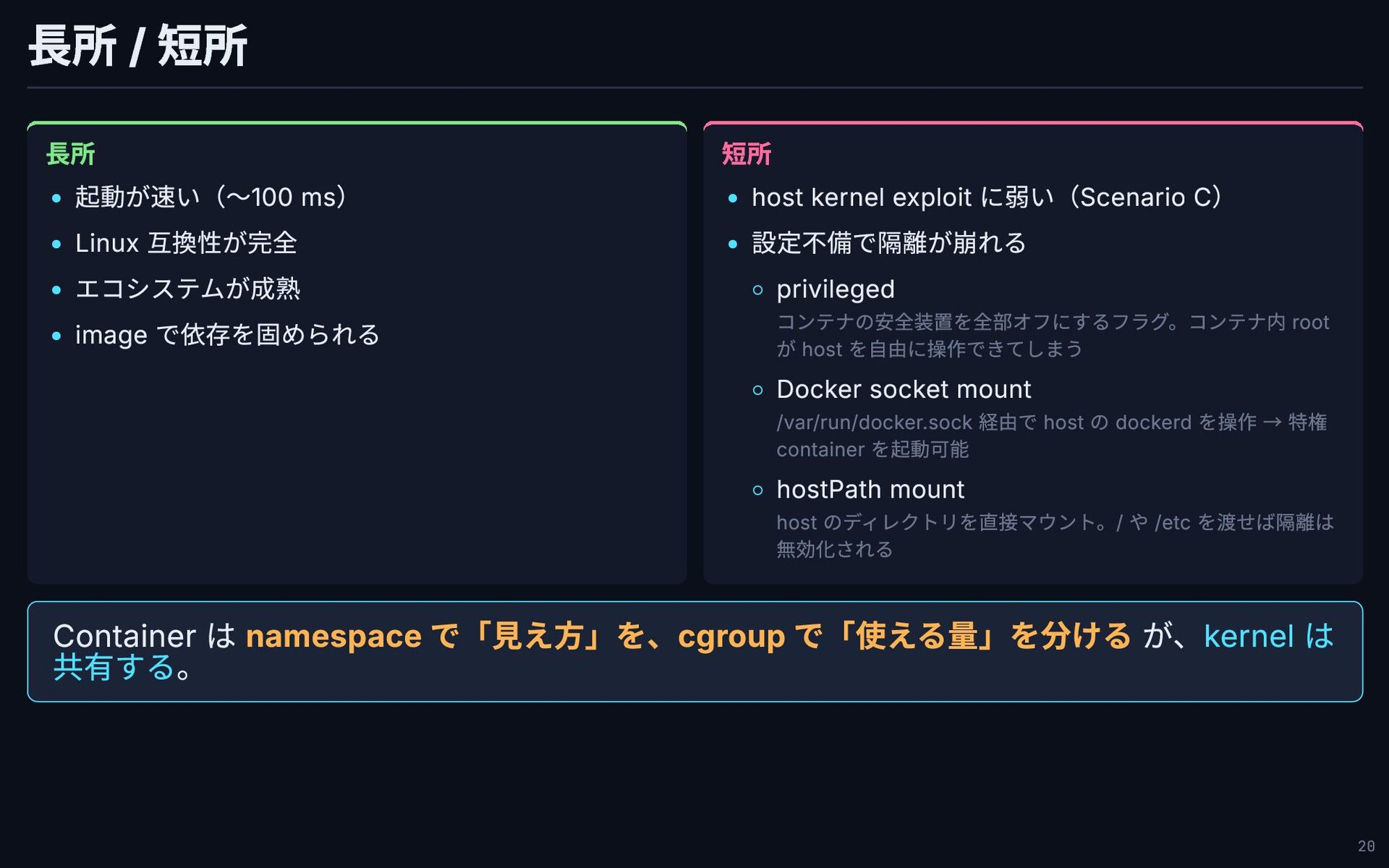
長所 / 短所 長所 起動が速い(〜100 ms) Linux 互換性が完全 エコシステムが成熟 image
で依存を固められる 短所 host kernel exploit に弱い(Scenario C) 設定不備で隔離が崩れる privileged コンテナの安全装置を全部オフにするフラグ。コンテナ内 root が host を自由に操作できてしまう Docker socket mount /var/run/docker.sock 経由で host の dockerd を操作 → 特権 container を起動可能 hostPath mount host のディレクトリを直接マウント。/ や /etc を渡せば隔離は 無効化される Container は namespace で「見え方」を、cgroup で「使える量」を分ける が、kernel は 共有する。 20
04 gVisor host kernel への接触面を減らす 21
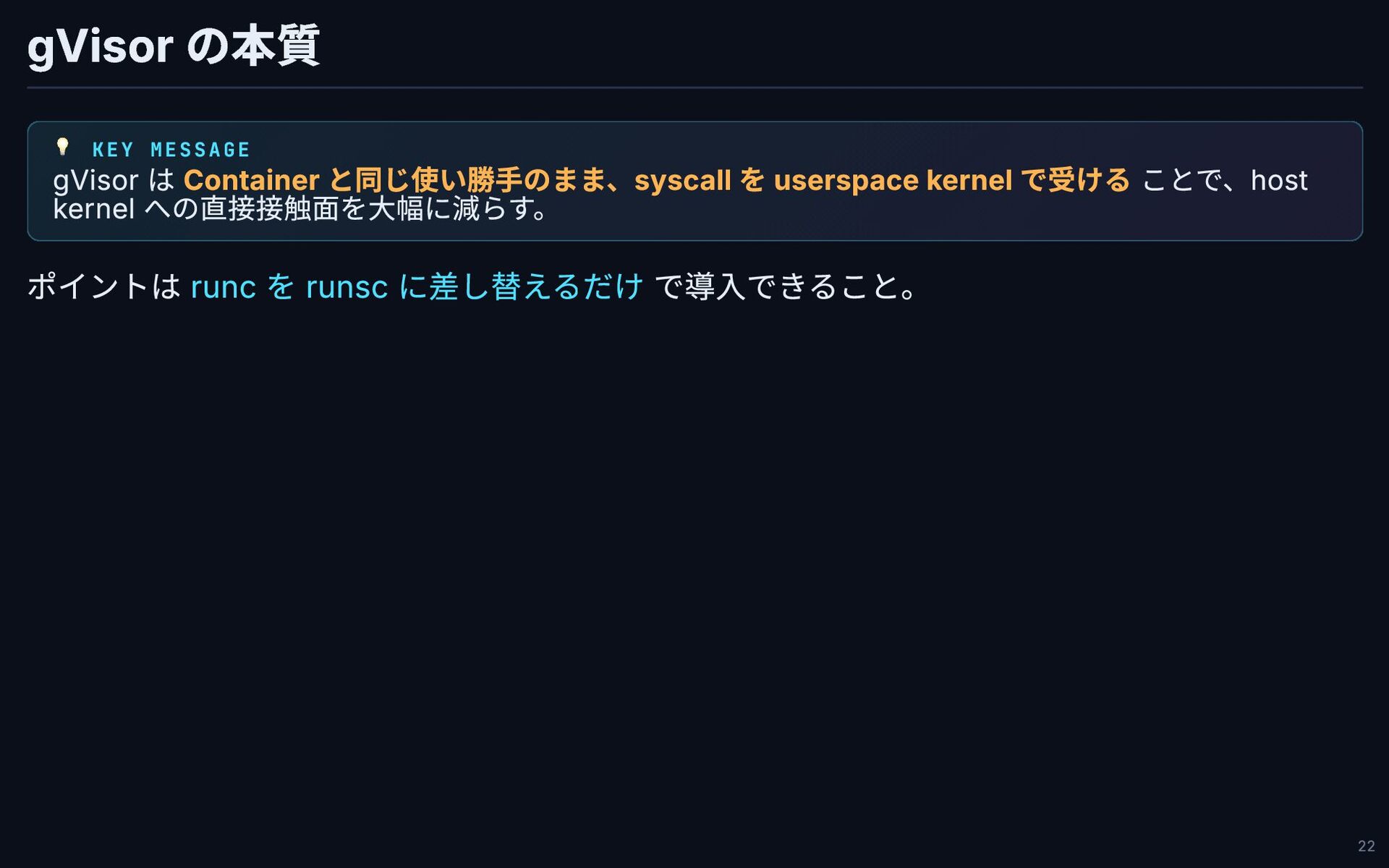
gVisor の本質 💡 KEY MESSAGE gVisor は Container と同じ使い勝手のまま、syscall を
userspace kernel で受ける ことで、host kernel への直接接触面を大幅に減らす。 ポイントは runc を runsc に差し替えるだけ で導入できること。 22
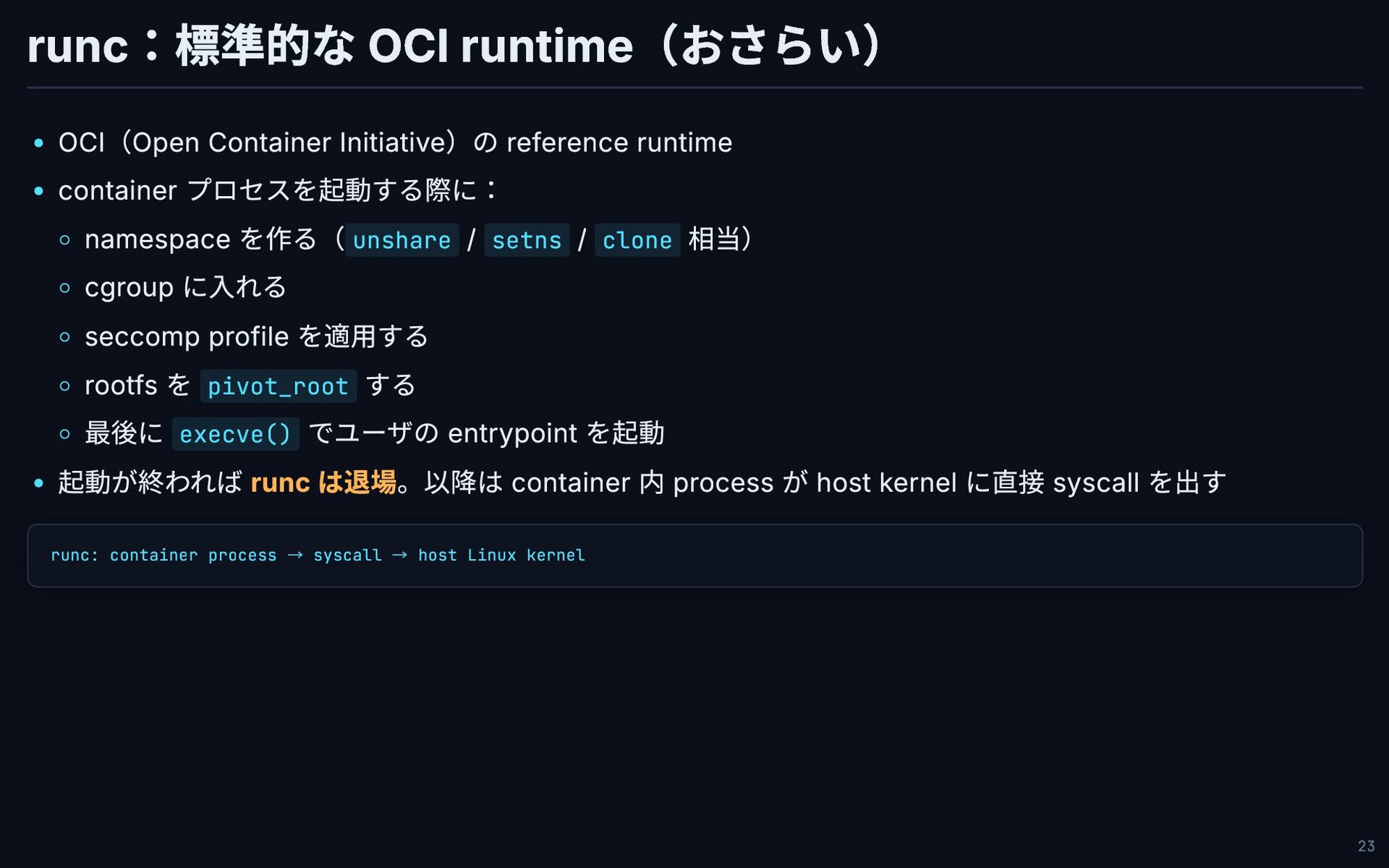
runc:標準的な OCI runtime(おさらい) OCI(Open Container Initiative)の reference runtime container プロセスを起動する際に:
namespace を作る(unshare / setns / clone 相当) cgroup に入れる seccomp profile を適用する rootfs を pivot_root する 最後に execve() でユーザの entrypoint を起動 起動が終われば runc は退場。以降は container 内 process が host kernel に直接 syscall を出す runc: container process → syscall → host Linux kernel 23
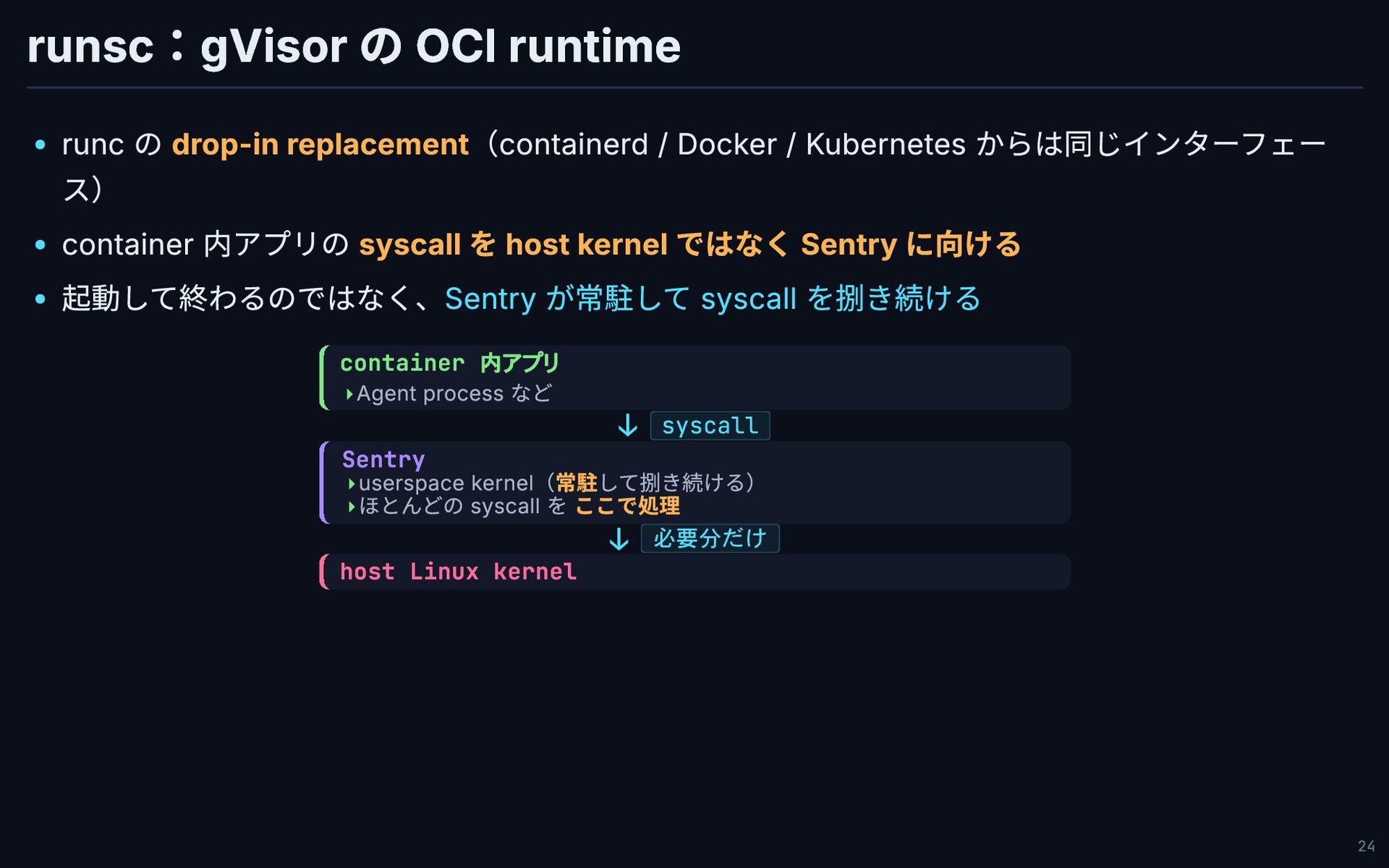
runsc:gVisor の OCI runtime runc の drop-in replacement(containerd / Docker
/ Kubernetes からは同じインターフェー ス) container 内アプリの syscall を host kernel ではなく Sentry に向ける 起動して終わるのではなく、Sentry が常駐して syscall を捌き続ける container 内アプリ ↓ syscall Sentry ↓ 必要分だけ host Linux kernel Agent process など ▸ userspace kernel(常駐して捌き続ける) ▸ ほとんどの syscall を ここで処理 ▸ 24
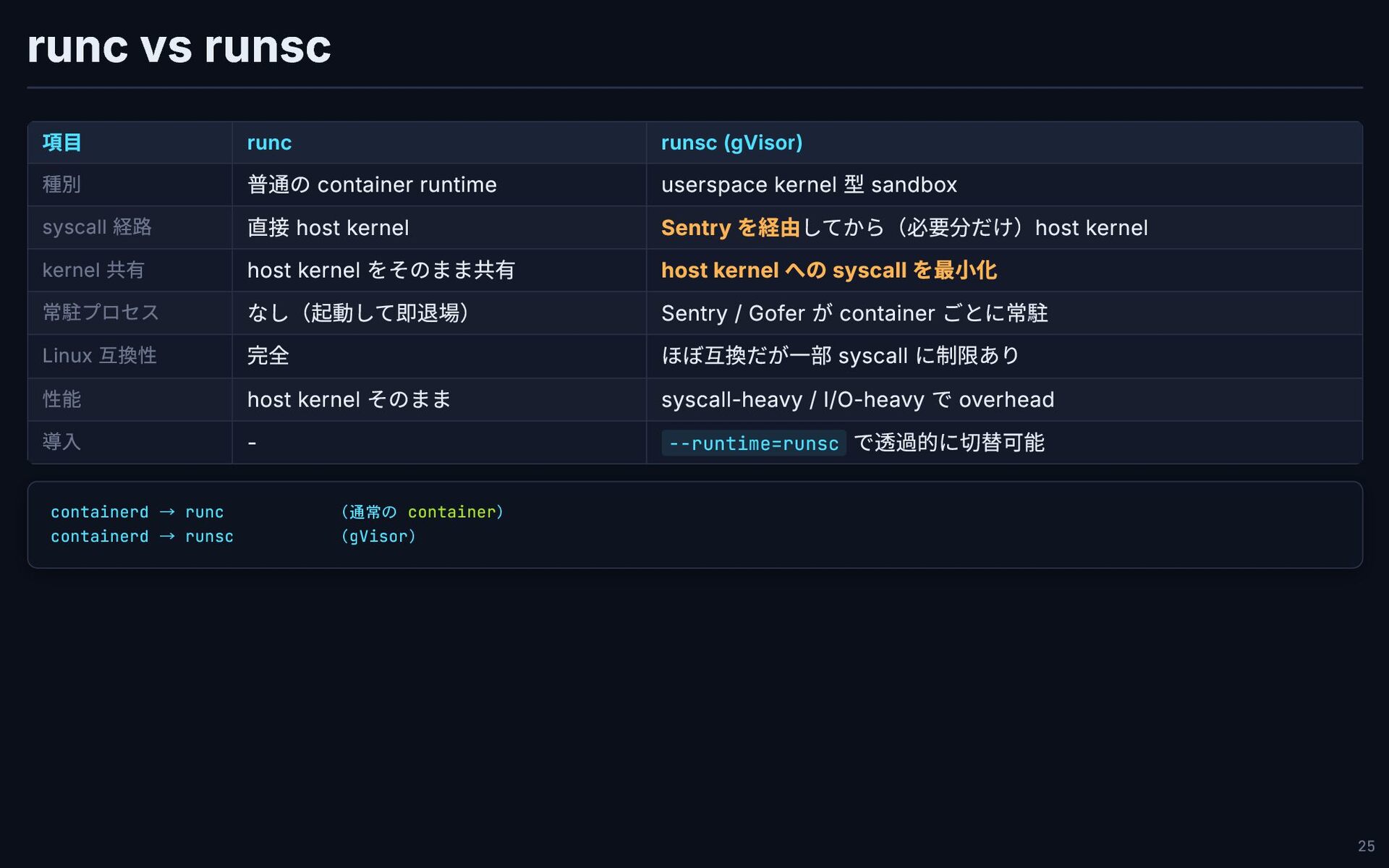
runc vs runsc 項目 runc runsc (gVisor) 種別 普通の container
runtime userspace kernel 型 sandbox syscall 経路 直接 host kernel Sentry を経由してから(必要分だけ)host kernel kernel 共有 host kernel をそのまま共有 host kernel への syscall を最小化 常駐プロセス なし(起動して即退場) Sentry / Gofer が container ごとに常駐 Linux 互換性 完全 ほぼ互換だが一部 syscall に制限あり 性能 host kernel そのまま syscall-heavy / I/O-heavy で overhead 導入 - --runtime=runsc で透過的に切替可能 containerd → runc (通常の container) containerd → runsc (gVisor) 25
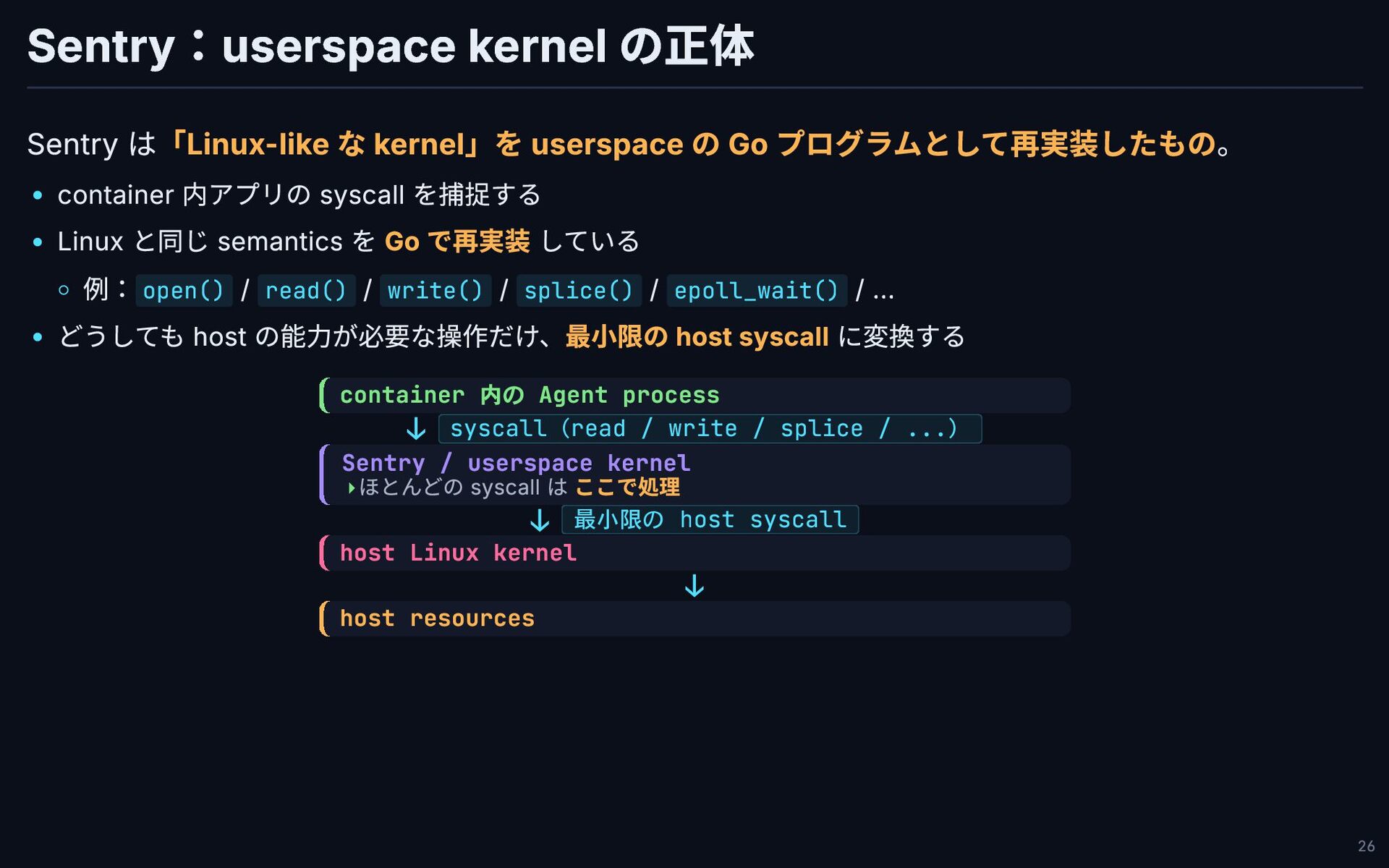
Sentry:userspace kernel の正体 Sentry は「Linux-like な kernel」を userspace の Go
プログラムとして再実装したもの。 container 内アプリの syscall を捕捉する Linux と同じ semantics を Go で再実装 している 例:open() / read() / write() / splice() / epoll_wait() / ... どうしても host の能力が必要な操作だけ、最小限の host syscall に変換する container 内の Agent process ↓ syscall(read / write / splice / ...) Sentry / userspace kernel ↓ 最小限の host syscall host Linux kernel ↓ host resources ほとんどの syscall は ここで処理 ▸ 26
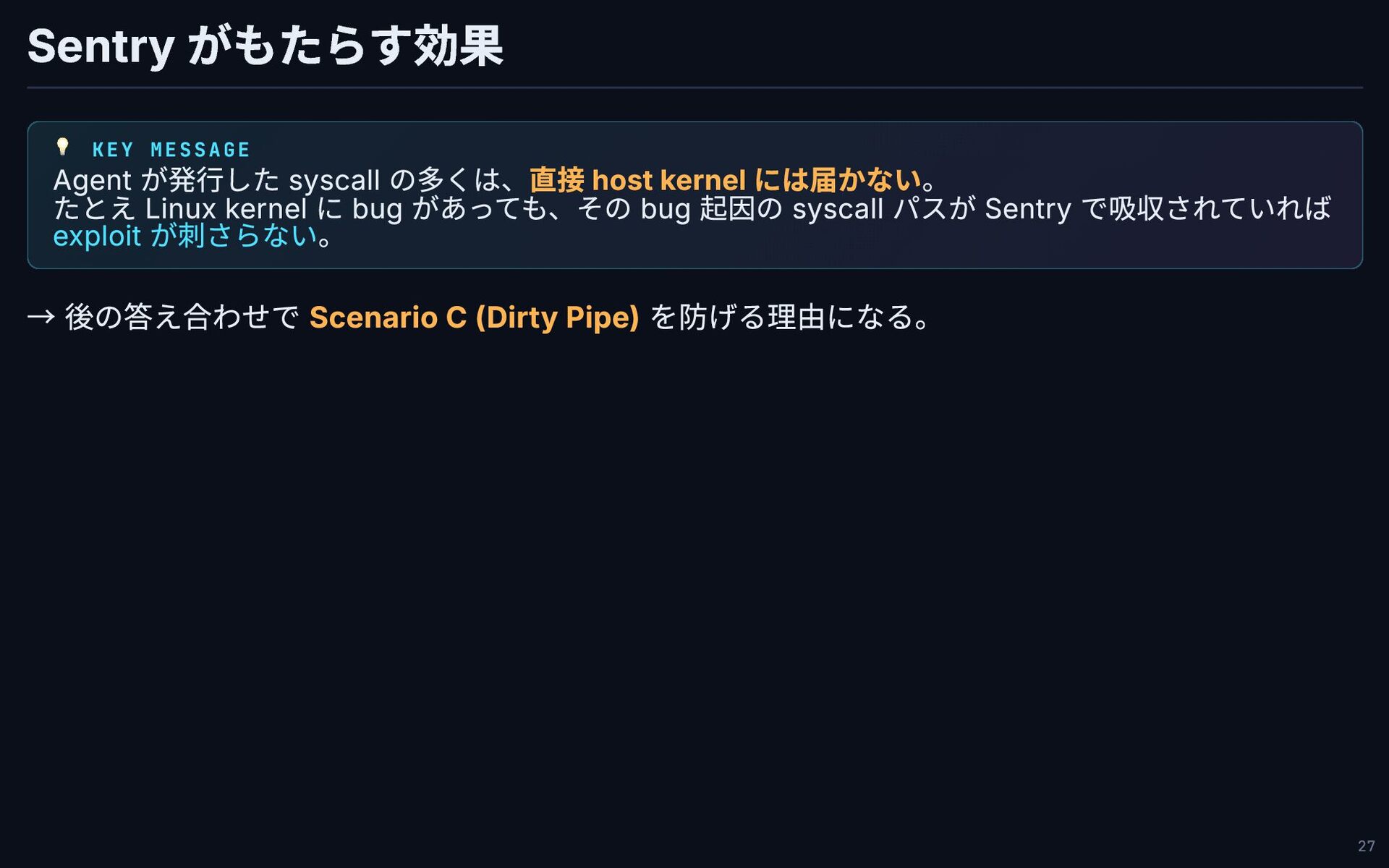
Sentry がもたらす効果 💡 KEY MESSAGE Agent が発行した syscall の多くは、直接 host
kernel には届かない。 たとえ Linux kernel に bug があっても、その bug 起因の syscall パスが Sentry で吸収されていれば exploit が刺さらない。 → 後の答え合わせで Scenario C (Dirty Pipe) を防げる理由になる。 27
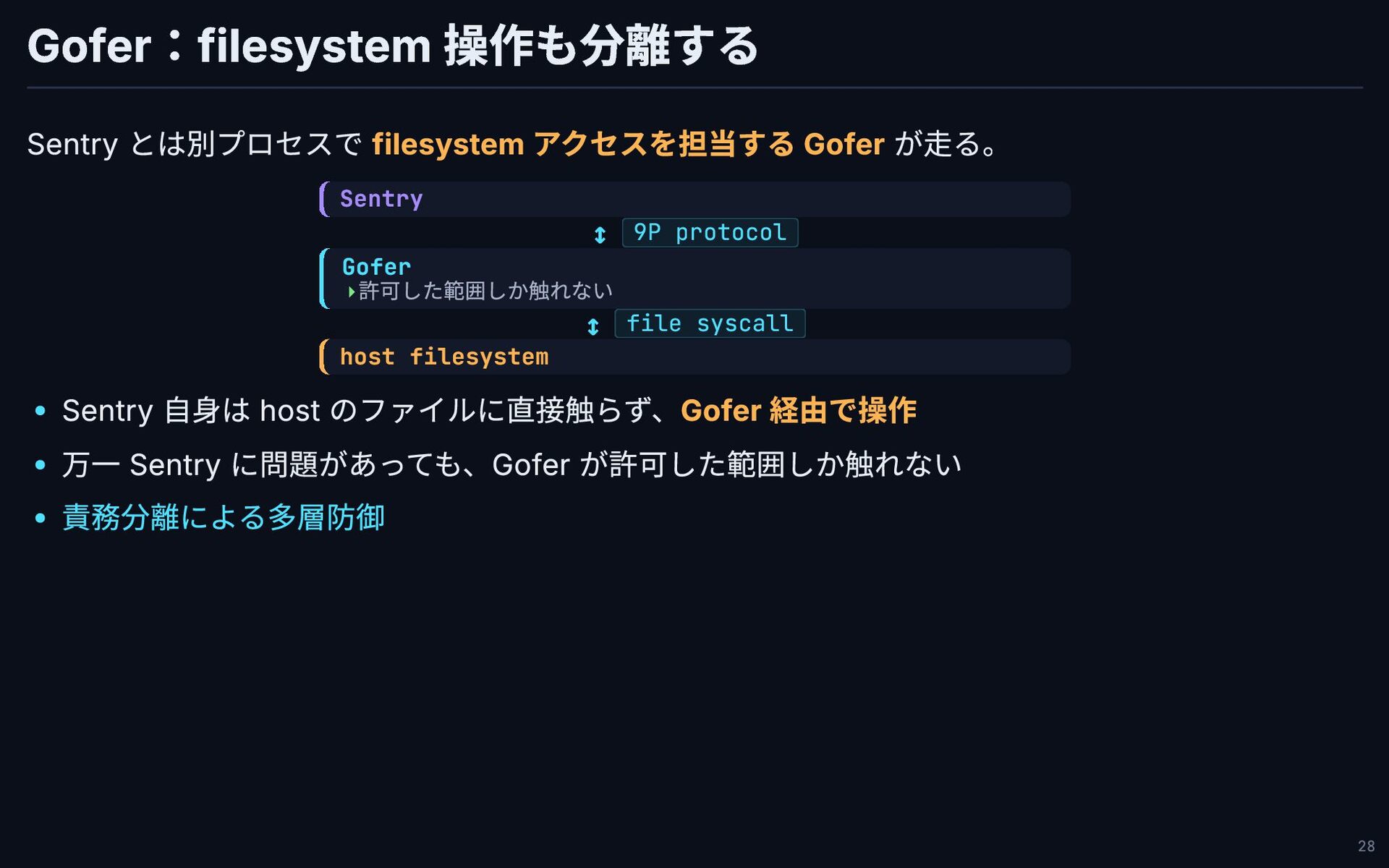
Gofer:filesystem 操作も分離する Sentry とは別プロセスで filesystem アクセスを担当する Gofer が走る。 Sentry ↕
9P protocol Gofer ↕ file syscall host filesystem Sentry 自身は host のファイルに直接触らず、Gofer 経由で操作 万一 Sentry に問題があっても、Gofer が許可した範囲しか触れない 責務分離による多層防御 許可した範囲しか触れない ▸ 28
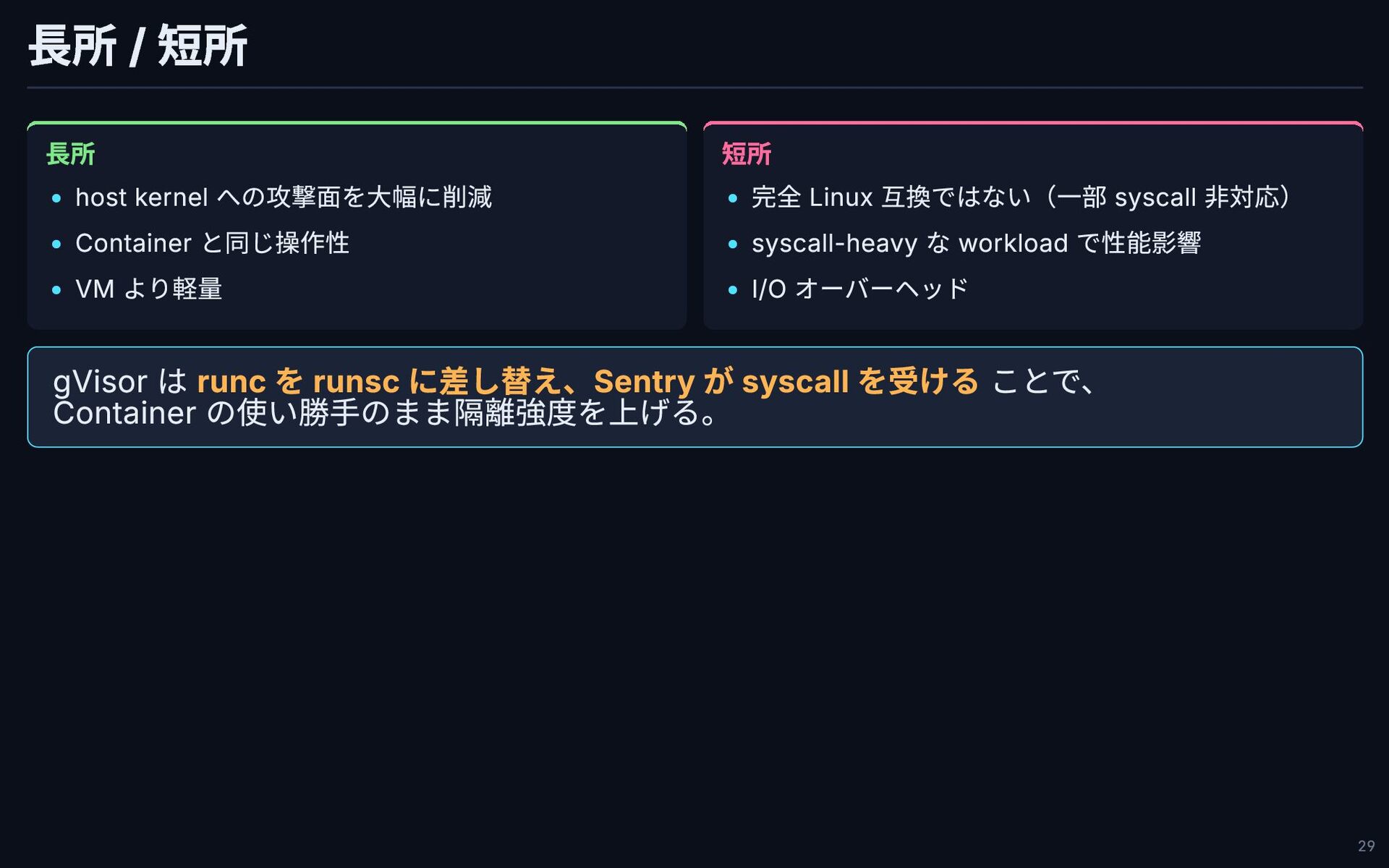
長所 / 短所 長所 host kernel への攻撃面を大幅に削減 Container と同じ操作性 VM
より軽量 短所 完全 Linux 互換ではない(一部 syscall 非対応) syscall-heavy な workload で性能影響 I/O オーバーヘッド gVisor は runc を runsc に差し替え、Sentry が syscall を受ける ことで、 Container の使い勝手のまま隔離強度を上げる。 29
05 VM / microVM kernel ごと分ける 30
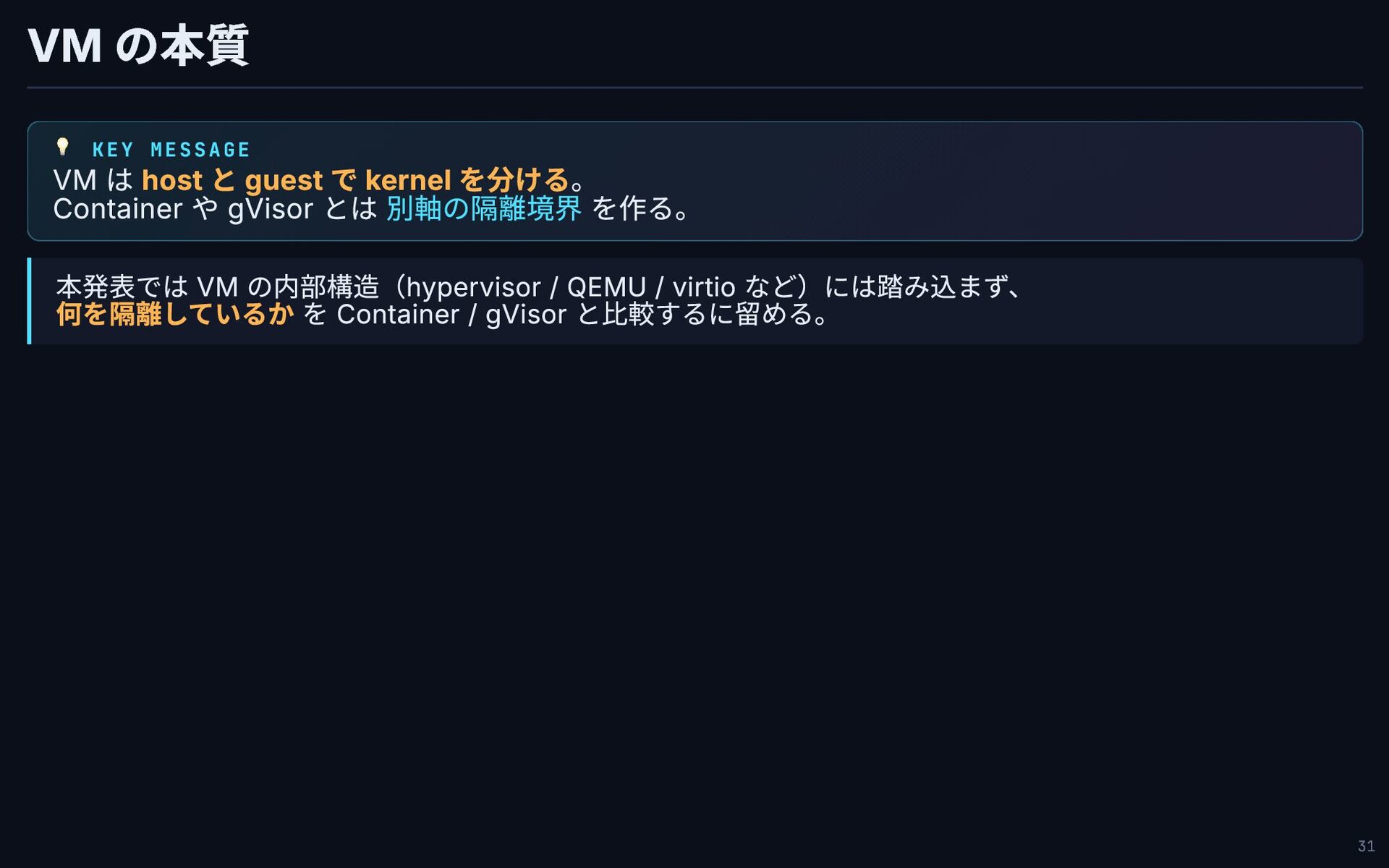
VM の本質 💡 KEY MESSAGE VM は host と guest
で kernel を分ける。 Container や gVisor とは 別軸の隔離境界 を作る。 本発表では VM の内部構造(hypervisor / QEMU / virtio など)には踏み込まず、 何を隔離しているか を Container / gVisor と比較するに留める。 31
F I G 0 5 syscall flow 比較 — その
syscall、どの kernel に届く? CONTAINER · gVISOR · VM ★ KEY QUESTION Agent が発行した syscall は、最終的に どの kernel が処理するのか? ── Container: host kernel / gVisor: Sentry / VM: guest kernel Container RUNC · NS + CGROUP ↓ syscall read / write / splice / mmap … ← 境界がここまでしかない ↓ RISK kernel bug を直接踏める (Dirty Pipe) Agent process container 内 host Linux kernel namespace / cgroup / seccomp で 制限はかかるが、syscall は直接届く host resources gVisor RUNSC · USERSPACE KERNEL ↓ syscall アプリは「普通の Linux 上」と思っている ← 境界 = Sentry ↓ 必要な最小限の syscall allowlist · seccomp で多層防御 ↓ SHIM host への接触面を最小化 Agent process container 内 Sentry (userspace kernel) Go で再実装。大半をここで処理 host Linux kernel 面が小さく、bug を踏みにくい host resources VM / microVM GUEST KERNEL + HYPERVISOR ↓ syscall ← 境界 = guest kernel ↓ 仮想ハードウェア操作 virtio / hypercall … ↓ ↓ APART kernel そのものを分ける Agent process guest 内 guest Linux kernel guest 専用 kernel。host とは別物 VMM / hypervisor Firecracker / KVM / … host Linux kernel host resources 32
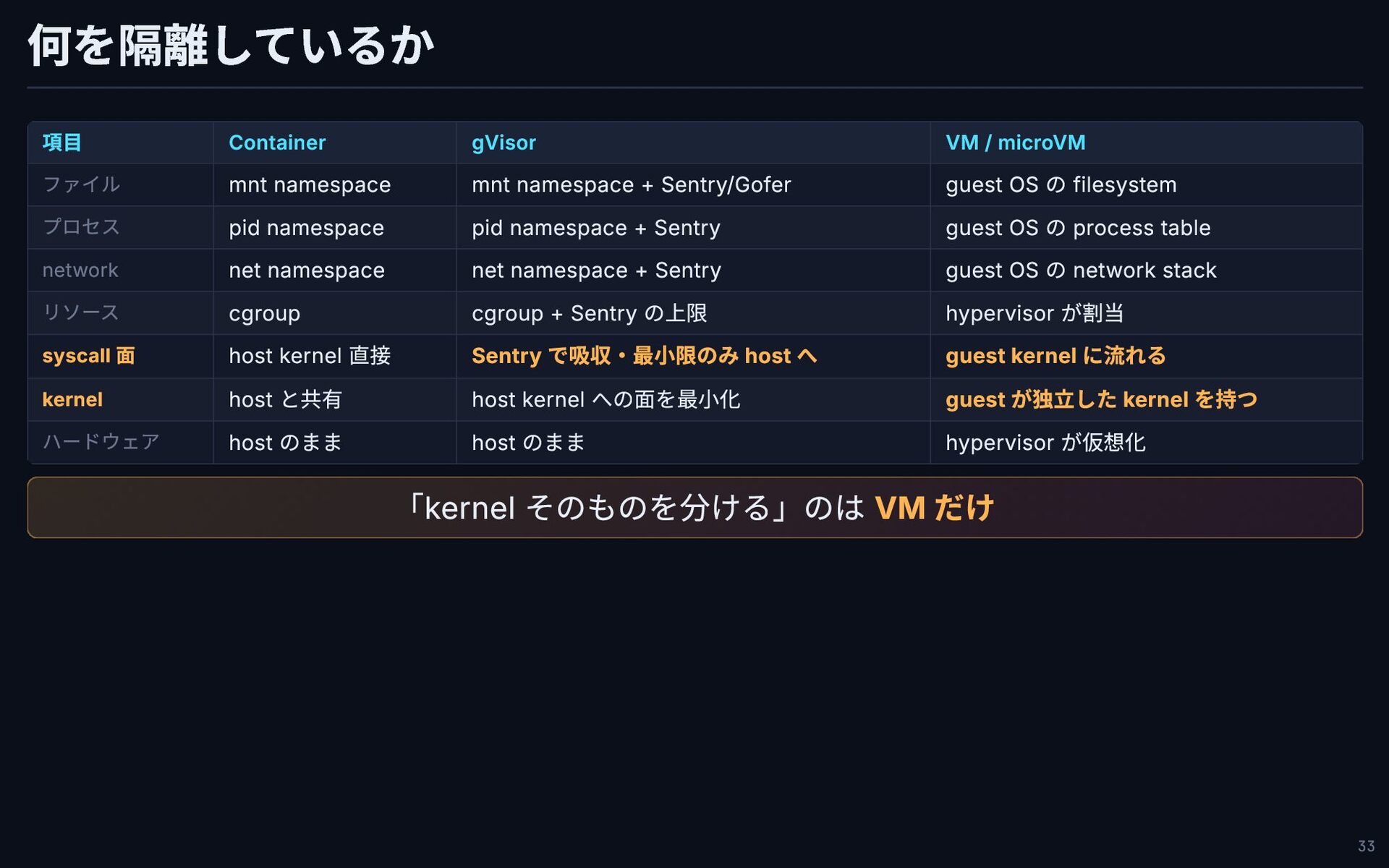
何を隔離しているか 項目 Container gVisor VM / microVM ファイル mnt namespace
mnt namespace + Sentry/Gofer guest OS の filesystem プロセス pid namespace pid namespace + Sentry guest OS の process table network net namespace net namespace + Sentry guest OS の network stack リソース cgroup cgroup + Sentry の上限 hypervisor が割当 syscall 面 host kernel 直接 Sentry で吸収・最小限のみ host へ guest kernel に流れる kernel host と共有 host kernel への面を最小化 guest が独立した kernel を持つ ハードウェア host のまま host のまま hypervisor が仮想化 「kernel そのものを分ける」のは VM だけ 33
microVM 汎用 VM から不要な device emulation を削ぎ落とした 軽量 VM 実装。
Firecracker(AWS Lambda / Fargate):起動 ~125 ms Cloud Hypervisor Kata Containers:OCI 互換、見た目は container・中身は軽量 VM Container 並の起動速度と、VM 並の隔離境界を 両立する設計。 34
長所 / 短所 / まとめ 長所 kernel ごと分離するため、最も強固な隔離境界 guest kernel
exploit があっても host へは hypervisor escape が必要 Linux 互換性が完全(syscall を絞らない) workload ごとに kernel version / config を自由に 選べる microVM なら起動 ~125 ms と container 並み 短所 Container や gVisor より image / network / storage の設計が複雑 guest OS が独立しているため OCI layer の image はそのまま使 えず rootfs を別途用意。network は virtio-net、storage は virtio-blk など仮想ハードウェアとして再構築する必要がある 高密度起動には設計が必要 VM ごとに guest kernel・専用メモリ・ディスクを持つので、 container 並みの密度で並べると host 資源を圧迫。KSM やページ 共有、microVM などの最適化が前提になる 監視 / debug のしかたが container と異なる host から guest 内部のプロセスや /proc は直接見えない。guest agent・hypervisor 側メトリクス・シリアルコンソール経由のログ 収集など、container とは別系統の観測手段が必要 Container / gVisor よりコストが高くなりやすい VM は kernel ごと分ける。 kernel 共有を前提とした攻撃シナリオを 最も明確に防げる。 35
06 Linux on WASM (番外編)実行モデルそのものを変える 36
Linux on WASM の位置づけ 💡 KEY MESSAGE WebAssembly 上で Linux
を動かす発想は 隔離レベルとしては理論的に非常に強い が、 課題が多く、現状は番外編的な位置づけ。 37
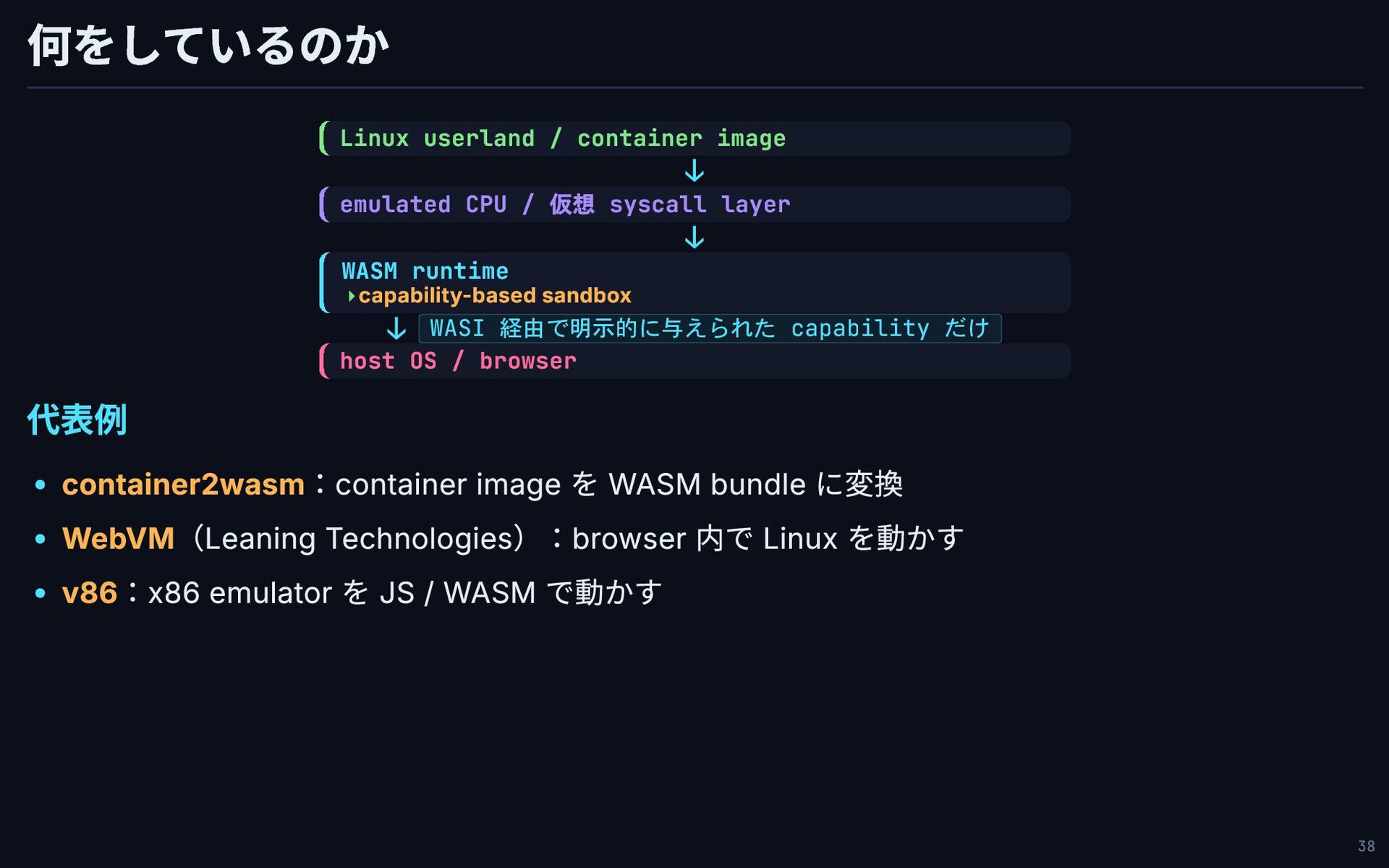
何をしているのか Linux userland / container image ↓ emulated CPU /
仮想 syscall layer ↓ WASM runtime ↓ WASI 経由で明示的に与えられた capability だけ host OS / browser 代表例 container2wasm:container image を WASM bundle に変換 WebVM(Leaning Technologies):browser 内で Linux を動かす v86:x86 emulator を JS / WASM で動かす capability-based sandbox ▸ 38
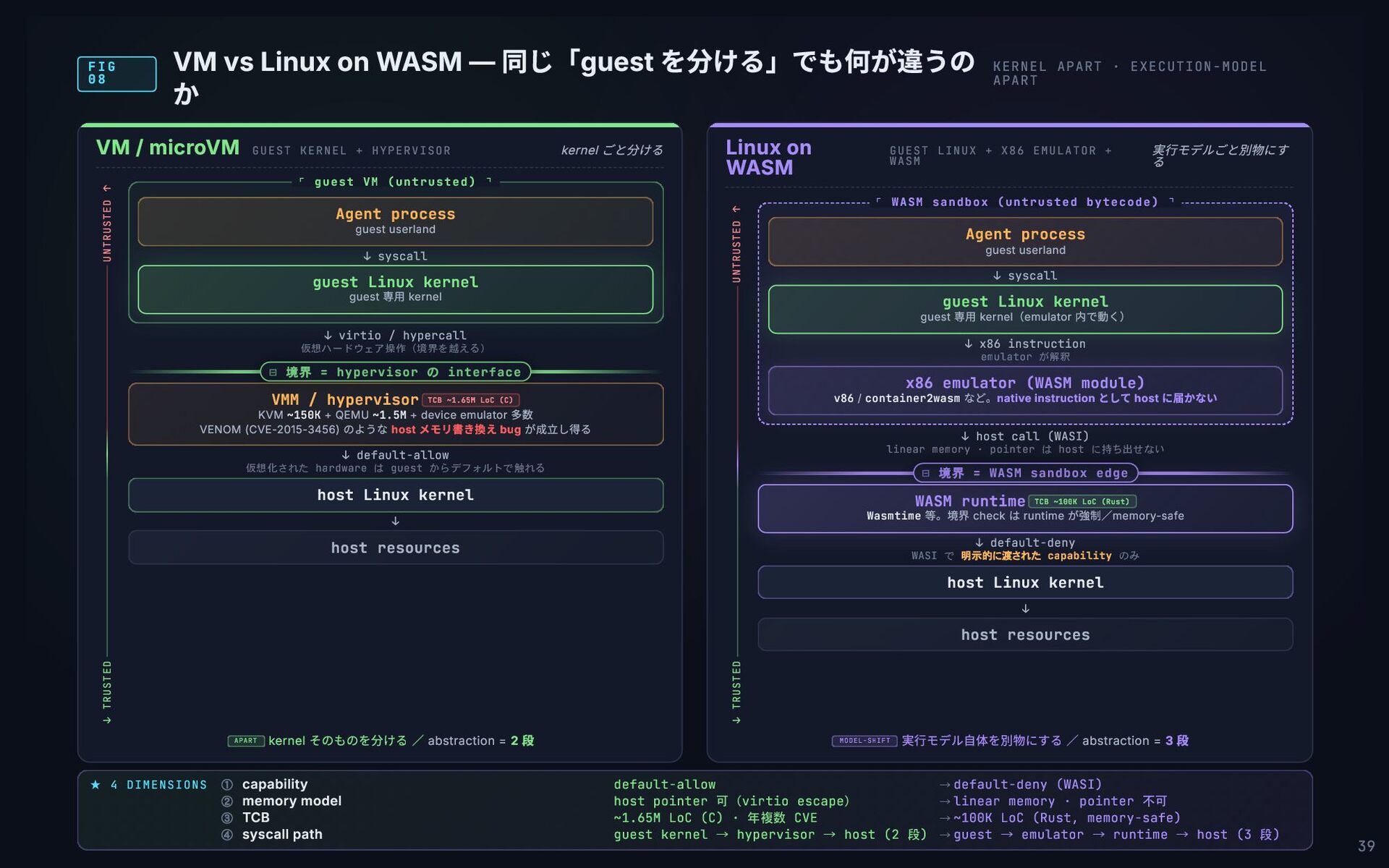
F I G 0 8 VM vs Linux on WASM
— 同じ「guest を分ける」でも何が違うの か KERNEL APART · EXECUTION-MODEL APART ★ 4 DIMENSIONS ① capability default-allow → default-deny (WASI) ② memory model host pointer 可(virtio escape) → linear memory · pointer 不可 ③ TCB ~1.65M LoC (C) · 年複数 CVE → ~100K LoC (Rust, memory-safe) ④ syscall path guest kernel → hypervisor → host (2 段) → guest → emulator → runtime → host (3 段) VM / microVM GUEST KERNEL + HYPERVISOR kernel ごと分ける ↓ virtio / hypercall 仮想ハードウェア操作(境界を越える) ↓ default-allow 仮想化された hardware は guest からデフォルトで触れる ↓ APART kernel そのものを分ける / abstraction = 2 段 ↓ syscall ⌜ guest VM (untrusted) ⌝ Agent process guest userland guest Linux kernel guest 専用 kernel 境界 = hypervisor の interface ⊟ VMM / hypervisor TCB ~1.65M LoC (C) KVM ~150K + QEMU ~1.5M + device emulator 多数 VENOM (CVE-2015-3456) のような host メモリ書き換え bug が成立し得る host Linux kernel host resources Linux on WASM GUEST LINUX + X86 EMULATOR + WASM 実行モデルごと別物にす る ↓ host call (WASI) linear memory · pointer は host に持ち出せない ↓ default-deny WASI で 明示的に渡された capability のみ ↓ MODEL-SHIFT 実行モデル自体を別物にする / abstraction = 3 段 ↓ syscall ↓ x86 instruction emulator が解釈 ⌜ WASM sandbox (untrusted bytecode) ⌝ Agent process guest userland guest Linux kernel guest 専用 kernel(emulator 内で動く) x86 emulator (WASM module) v86 / container2wasm など。native instruction として host に届かない 境界 = WASM sandbox edge ⊟ WASM runtime TCB ~100K LoC (Rust) Wasmtime 等。境界 check は runtime が強制/memory-safe host Linux kernel host resources UNTRUSTED ↑ ↓ TRUSTED UNTRUSTED ↑ ↓ TRUSTED 39
なぜ強い隔離になり得るか WASM runtime は capability-based:host への access は明示的に与えられたものだけ 中で動く Linux
は emulated CPU 上で動くので、host kernel と一切共有しない 配布 1 ファイル(.wasm )で済むので Ephemeral 性も高い 40
課題(だから番外編) 性能 emulation overhead が大きい 互換性 WASI が POSIX を完全カバーしていない
一部 syscall・I/O に制約 成熟度 production 採用例が少ない debug / 監視のエコシステムが弱い ユースケース browser 完結 / 教育 / 配布性重視のときに限定的 41
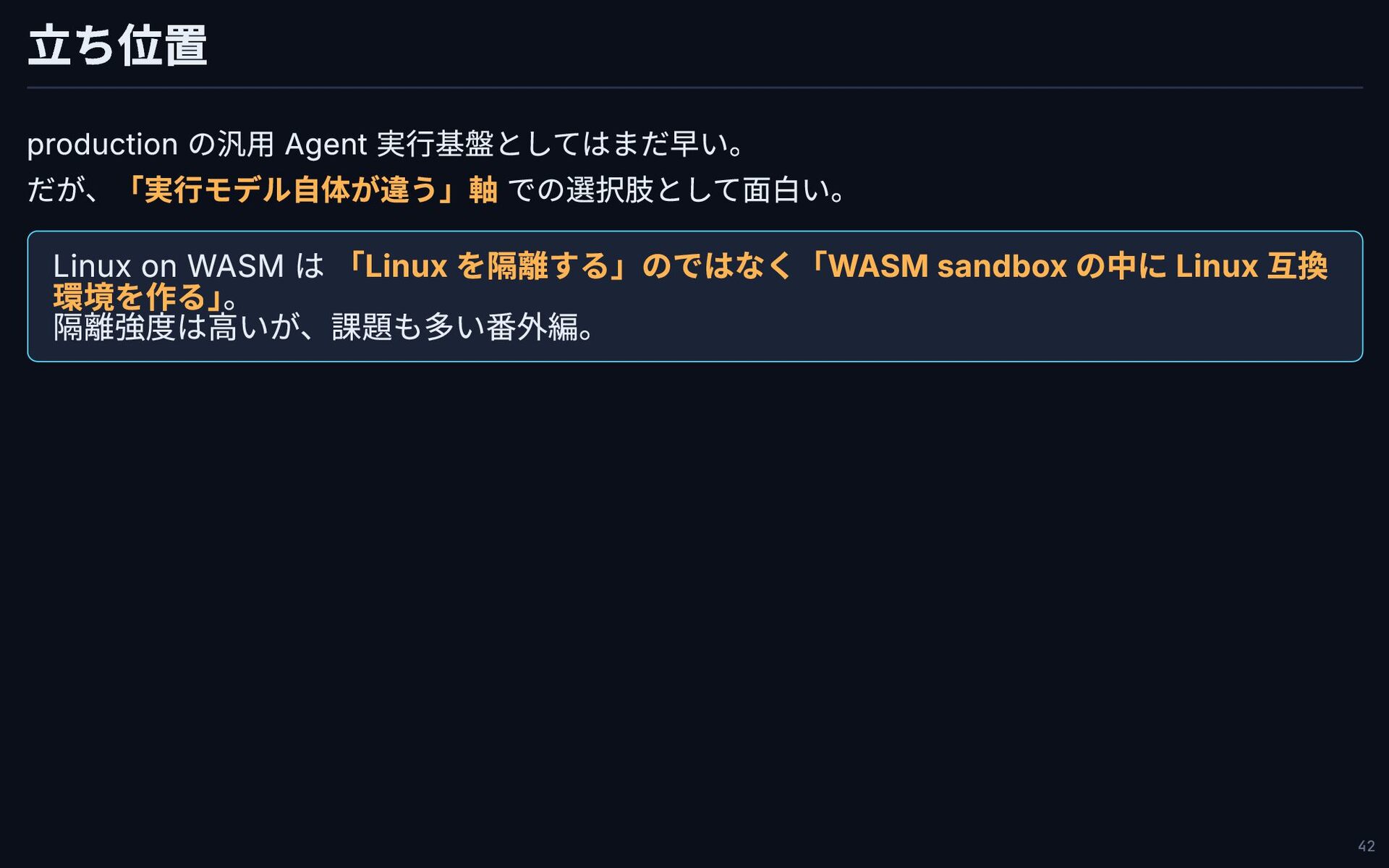
立ち位置 production の汎用 Agent 実行基盤としてはまだ早い。 だが、「実行モデル自体が違う」軸 での選択肢として面白い。 Linux on WASM
は 「Linux を隔離する」のではなく「WASM sandbox の中に Linux 互換 環境を作る」 。 隔離強度は高いが、課題も多い番外編。 42
07 答え合わせ 危険シナリオ × 隔離レベル (Dirty Pipe 深掘り含む) 43
F I G 0 7 答え合わせ — 危険シナリオ × 隔離レベル
SCENARIO × ISOLATION ▸ READING A, B はどのレベルでも防げる / C こそ 「kernel 共有 vs kernel 分離」 の決定的な差 ★ / D は隔離技術だけでは 完全には防げない領域 ◦ 防げる △ 一部 / 条件付き × 防げない SCENARIO 危険シナリオ 「Agent が暴走したら?」 CONTAINER Container ns + cgroup · host kernel 共有 SYSCALL SHIM gVisor runsc · Sentry / Gofer KERNEL APART VM / microVM guest kernel + hypervisor DIFFERENT MODEL Linux on WASM capability sandbox A host の秘密ファイル読み取り /etc/shadow / .ssh/id_rsa / .aws/credentials ◦ mount ns で host fs が見えな い ※ hostPath mount があれば崩れ る ◦ Gofer が許可した範囲のみ より明示的 ◦ guest OS の独立した filesystem を持つ ◦ capability-based 明示権限のみアクセス B fork bomb / リソース枯渇 CPU / memory / process slot ◦ cgroup の pids.max / memory.max / cpu.max ◦ Sentry 内で完結 + host 側 cgroup も効く ◦ hypervisor の 割当範囲に閉じる ◦ WASM runtime が execution 上限を持つ C kernel exploit による container escape 代表例:Dirty Pipe (CVE-2022-0847) · splice() ★ KEY DIFFERENTIATOR × host kernel をそのまま使う container escape まで行く △〜◦ splice() は Sentry が独自実 装 bug を直接踏まない ◦ syscall は guest kernel 処理 host kernel に届かない ◦ emulated CPU 上 host kernel と一切共有しない D CPU side-channel attack 代表例:Spectre / Meltdown(投機的実行) × 同じ CPU を共有 原理的に防げない × 同じ CPU を共有 原理的に防げない △ hypervisor mitigation かなり緩和、ただし完全ではな い △〜◦ emulation 系では 原理上影響が薄い場面あり 44
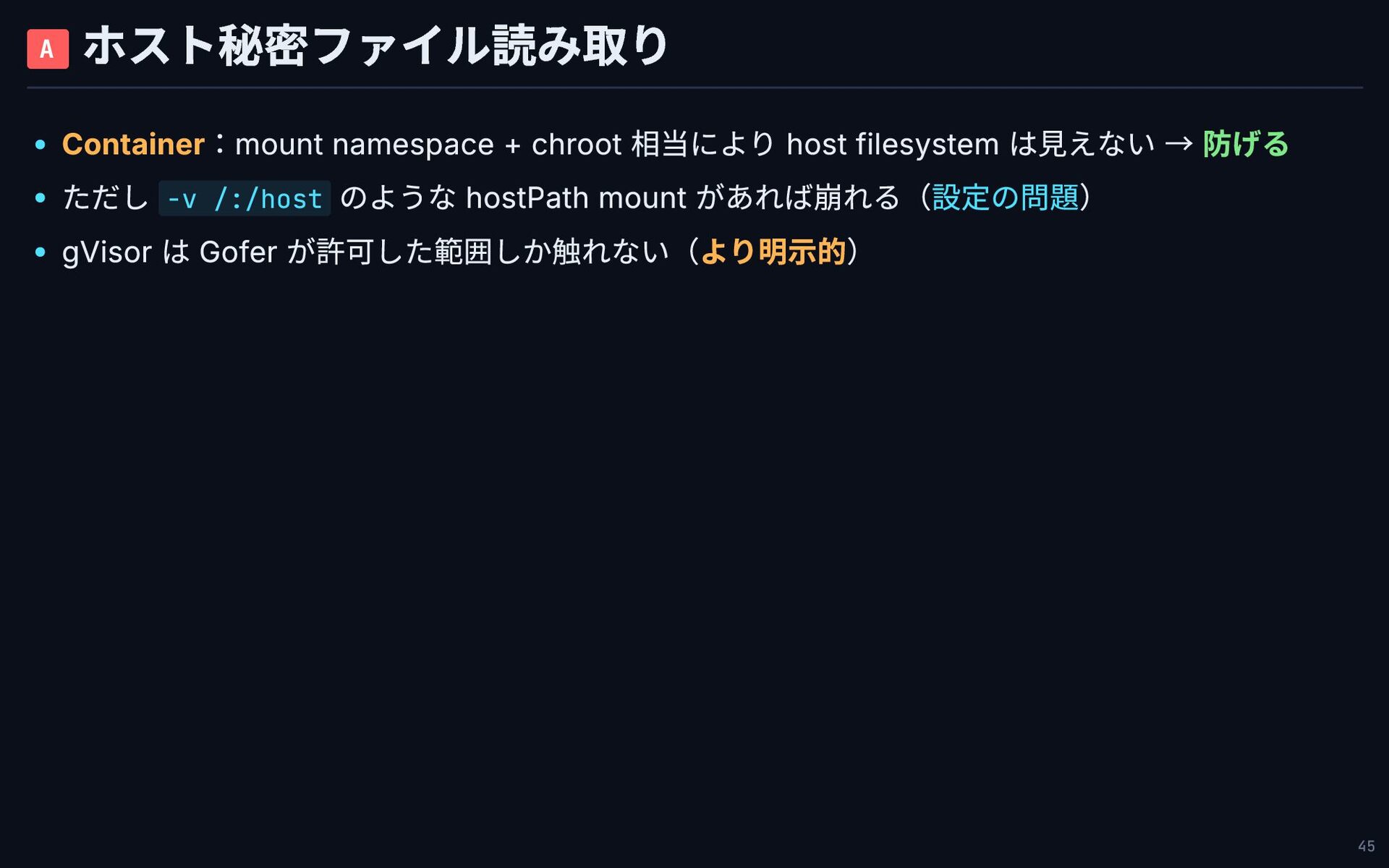
A ホスト秘密ファイル読み取り Container:mount namespace + chroot 相当により host filesystem は見えない
→ 防げる ただし -v /:/host のような hostPath mount があれば崩れる(設定の問題) gVisor は Gofer が許可した範囲しか触れない(より明示的) 45
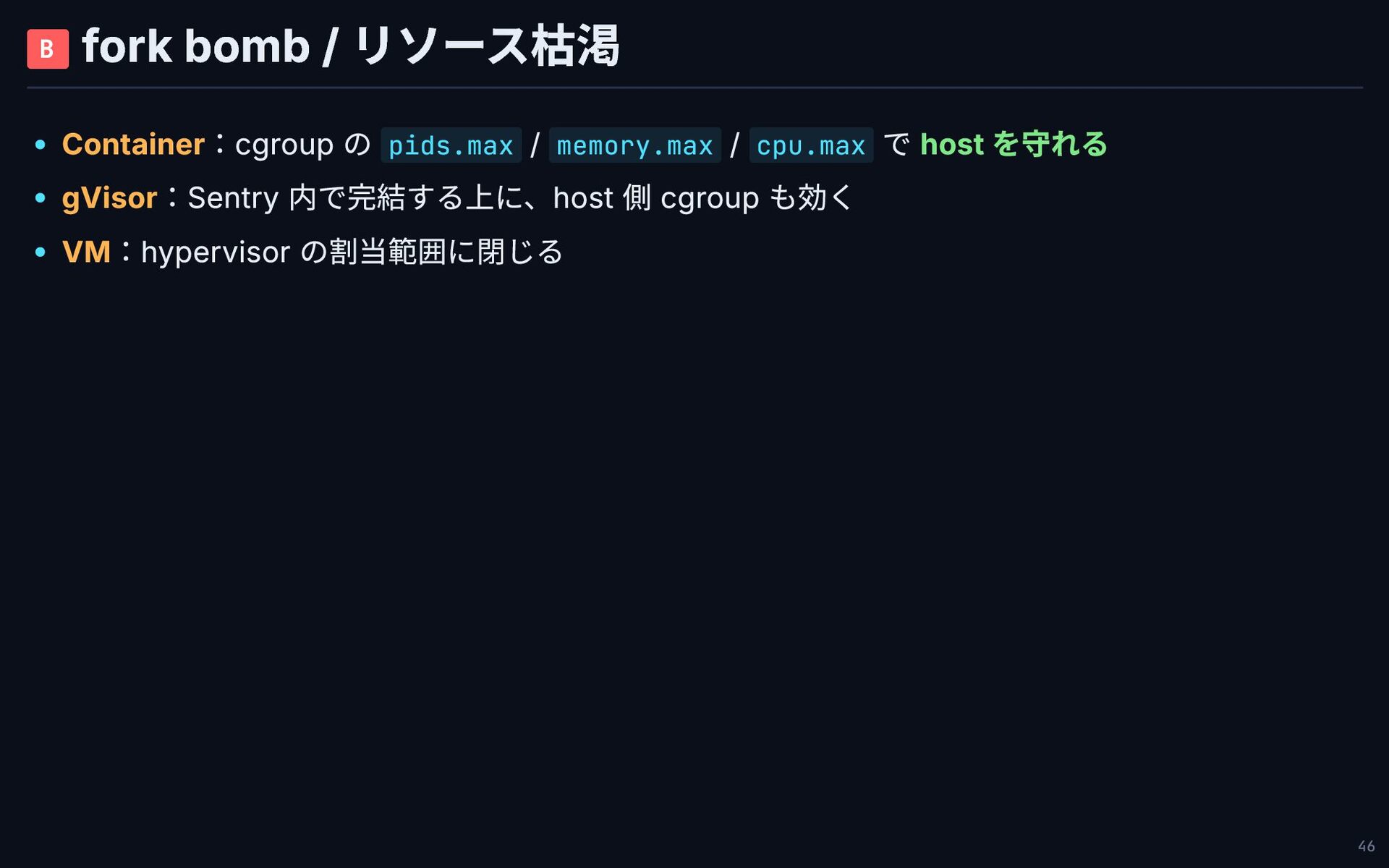
B fork bomb / リソース枯渇 Container:cgroup の pids.max / memory.max
/ cpu.max で host を守れる gVisor:Sentry 内で完結する上に、host 側 cgroup も効く VM:hypervisor の割当範囲に閉じる 46
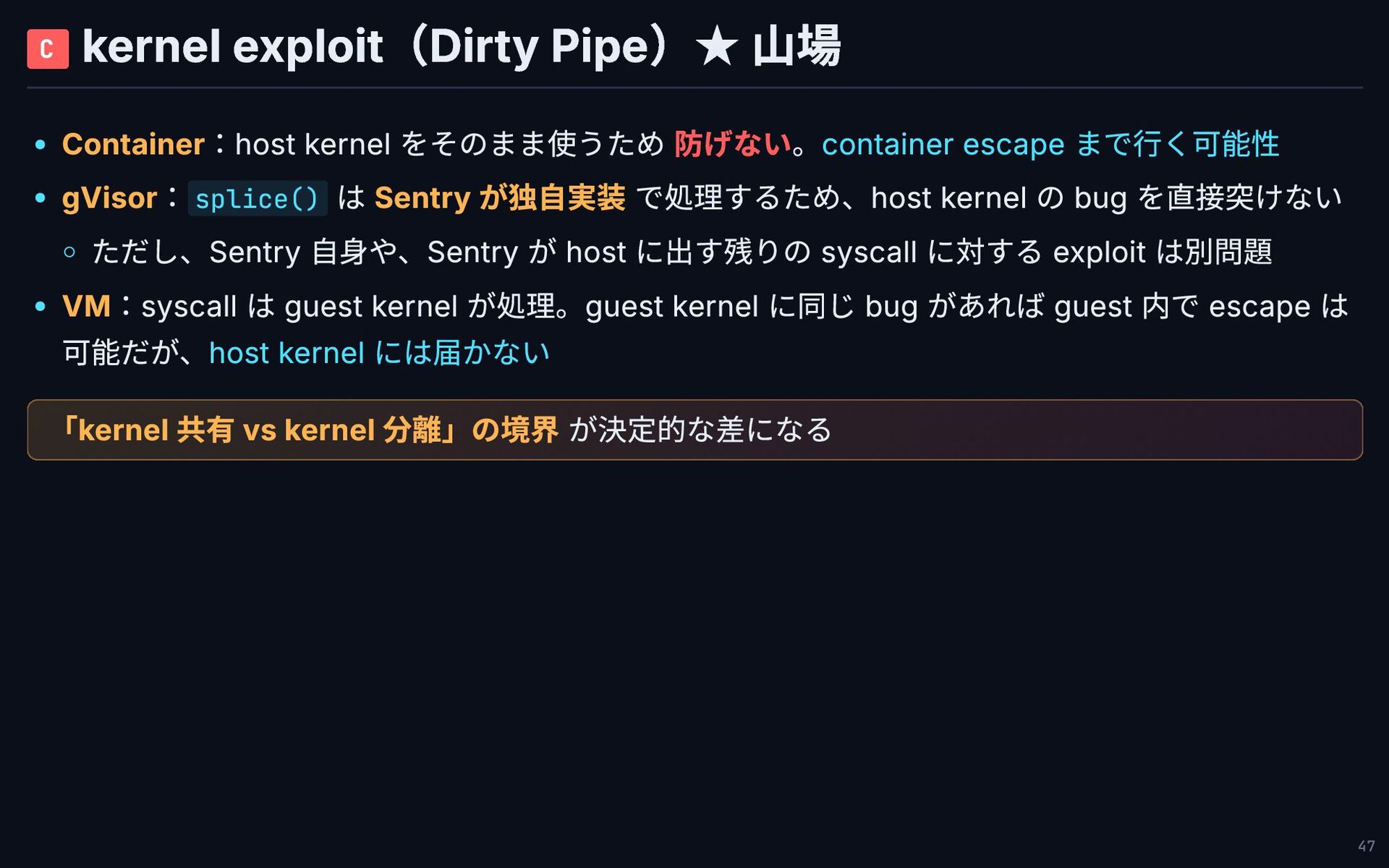
C kernel exploit(Dirty Pipe)★ 山場 Container:host kernel をそのまま使うため 防げない。container escape
まで行く可能性 gVisor:splice() は Sentry が独自実装 で処理するため、host kernel の bug を直接突けない ただし、Sentry 自身や、Sentry が host に出す残りの syscall に対する exploit は別問題 VM:syscall は guest kernel が処理。guest kernel に同じ bug があれば guest 内で escape は 可能だが、host kernel には届かない 「kernel 共有 vs kernel 分離」の境界 が決定的な差になる 47
D CPU side-channel(Spectre / Meltdown) Container / gVisor:同じ CPU を共有する以上、原理的に防げない
VM:hypervisor の mitigation でかなり緩和できるが、完全ではない(VM 間でも残り得る) WASM 系:実行モデル次第(特に emulation 系)で原理上影響を受けにくい場面がある 48
07.5 Dirty Pipe 「kernel 共有」の決定的な差を syscall path で追う 49
Dirty Pipe — 何が起きる脆弱性か 2022 年 3 月、Max Kellermann が公開(CVE-2022-0847)
影響範囲:Linux kernel 5.8 〜 5.16.10(5.16.11 / 5.15.25 / 5.10.102 などで patch) 「splice() 経由で read-only ファイルの page cache を書き換えできてしまう」 bug 結果として: /etc/passwd を書き換えて任意ユーザの認証を通す SUID binary を改変 し、次回実行時に root 権限で攻撃コードが走る container 内 root から host 上のファイルを書き換え → container escape 「権限のないファイルが書き換えられる」は Unix の基本前提を破壊する 強烈な bug。 50
なぜ Container では防げないのか Container の隔離は namespace / cgroup / seccomp
/ capabilities の組み合わせ。 いずれも「syscall を最終的に処理するのは host kernel」という前提は崩していない。 container 内の Agent process ↓ ただの普通の syscall host Linux kernel namespace fd / mount point が見える範囲か ✓ 通る cgroup リソース量 ✓ 通る seccomp syscall 番号の allowlist (splice / write は通常許可) ✓ 通る DAC / capabilities 自分の pipe への write ✓ 通る ★ ここまで通った後の処理 ★ copy_page_to_iter_pipe() ← bug があるのはここ pipe_write() ← CAN_MERGE 残留を踏む ↓ host 上の任意ファイルの page cache が書き換わる splice(file_fd, ..., pipe_fd, ...); ▸ write(pipe_fd, payload, ...); ▸ 51
Container の隔離機構ごとの「届かなさ」 namespace:「何が見えるか」を分けるだけで、kernel の処理ロジックは制御しない cgroup:「どれだけ使えるか」の話。bug とは無関係 seccomp:splice() を deny すれば理論的には止まるが、正常アプリも壊す対症療法
capabilities:落としても、bug は capability check を通った 後の コードにある bug は Linux kernel の pipe 実装そのものにある。 host process でも container process でも、同じ pipe_write() のコードが実行される。 → namespace を 100 個重ねても、同じコードを通す限り踏める。 Scenario A は「設定が正しければ Container でも防げる」種類。 Scenario C は「設定をどう頑張っても kernel bug 起因なので防げない」種類。そこが本質的に違う。 52
なぜ gVisor では防げるのか gVisor では container 内アプリの syscall を まず
Sentry が受ける。 container 内の Agent process ↓ Sentry が syscall を奪取(ptrace / KVM / systrap) Sentry(Go で書かれた userspace kernel) ↓ host kernel に出るのは「ページを確保したい」など最小限の operation host Linux kernel 💡 KEY MESSAGE bug があるコードは Linux kernel の pipe 実装。Sentry は同じ semantics を別実装している。 同じ bug は別実装に自動的にはコピーされない。 だから構造的に防げた。 splice(...) ; write(...) ▸ splice() / pipe / write() を Sentry が Go で独自実装 ▸ Sentry 内部の pipe 実装には PIPE_BUF_FLAG_CAN_MERGE 残留バグは存在しない(コ ードが別物) ▸ そもそも copy_page_to_iter_pipe() を通らない ▸ bug があるコードパスを「通る理由がない」 ▸ 53
08 まとめ 54
Take-away Container 「Linux の見え方」を namespace と cgroup で分け る。境界は host
kernel。 gVisor 「host kernel への syscall 面」 を Sentry で減らす(runc → runsc ) 。 VM / microVM kernel そのもの を分ける。 guest kernel が syscall を全部受 ける。 Linux on WASM 実行モデル を別物にする(番外 編) 。OS 隔離とは違う発想の sandbox。 F I G 0 1 隔離レベルのスペクトル(再掲) SPECTRUM OF ISOLATION VIEW + LIMIT Container 見える世界とリソース量を分ける 境界 = host kernel SYSCALL SHIM gVisor syscall 面を userspace kernel で吸収 境界 = Sentry KERNEL APART VM / microVM kernel そのものを分ける 境界 = guest kernel DIFFERENT MODEL Linux on WASM 実行モデル自体を別物にする 境界 = WASM sandbox 弱い・軽い 番外編 55
最終メッセージ 💡 KEY MESSAGE そのAgent の syscall は、 最終的にどの kernel
に届くのか? この問いを軸に考えると、Container / gVisor / VM / Linux on WASM の違いが そのまま アーキテクチャの違い として整理できる。 56
09 参考資料 References 57
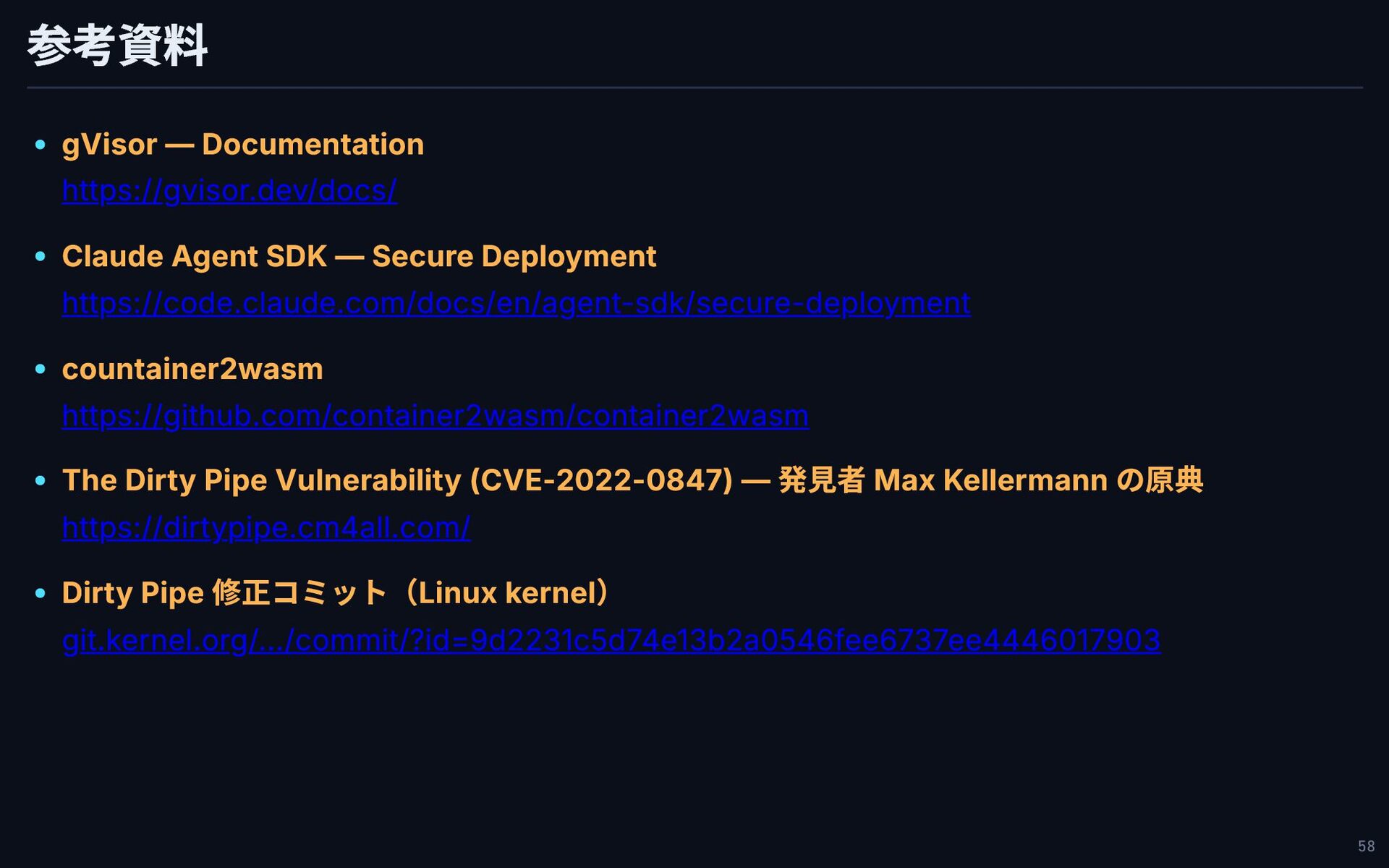
参考資料 gVisor — Documentation Claude Agent SDK — Secure Deployment
countainer2wasm The Dirty Pipe Vulnerability (CVE-2022-0847) — 発見者 Max Kellermann の原典 Dirty Pipe 修正コミット(Linux kernel) https://gvisor.dev/docs/ https://code.claude.com/docs/en/agent-sdk/secure-deployment https://github.com/container2wasm/container2wasm https://dirtypipe.cm4all.com/ git.kernel.org/.../commit/?id=9d2231c5d74e13b2a0546fee6737ee4446017903 58
A コンテナ技術の深堀り 本編から省いた詳細 59
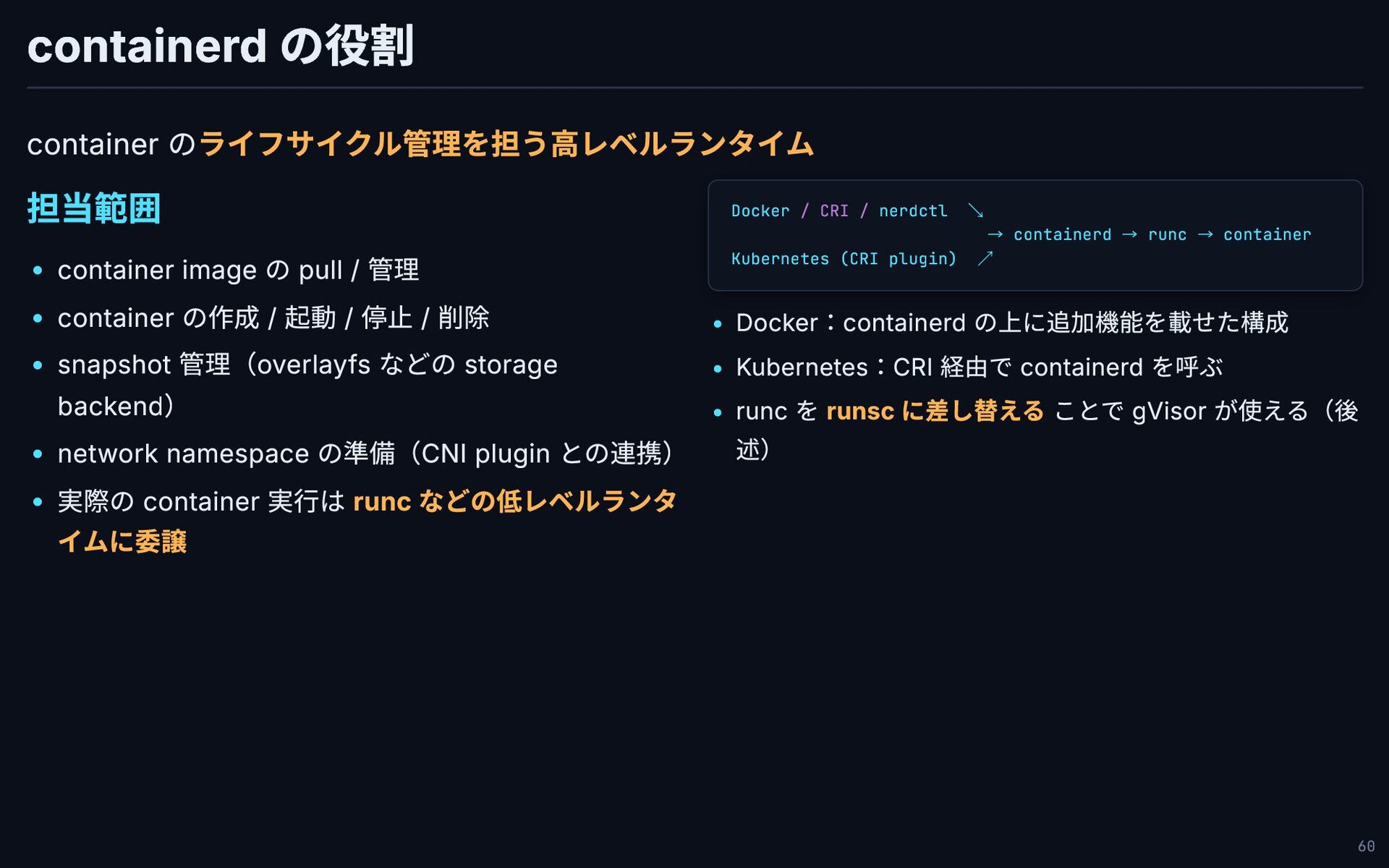
containerd の役割 container のライフサイクル管理を担う高レベルランタイム 担当範囲 container image の pull /
管理 container の作成 / 起動 / 停止 / 削除 snapshot 管理(overlayfs などの storage backend) network namespace の準備(CNI plugin との連携) 実際の container 実行は runc などの低レベルランタ イムに委譲 Docker / CRI / nerdctl ↘ → containerd → runc → container Kubernetes (CRI plugin) ↗ Docker:containerd の上に追加機能を載せた構成 Kubernetes:CRI 経由で containerd を呼ぶ runc を runsc に差し替える ことで gVisor が使える(後 述) 60
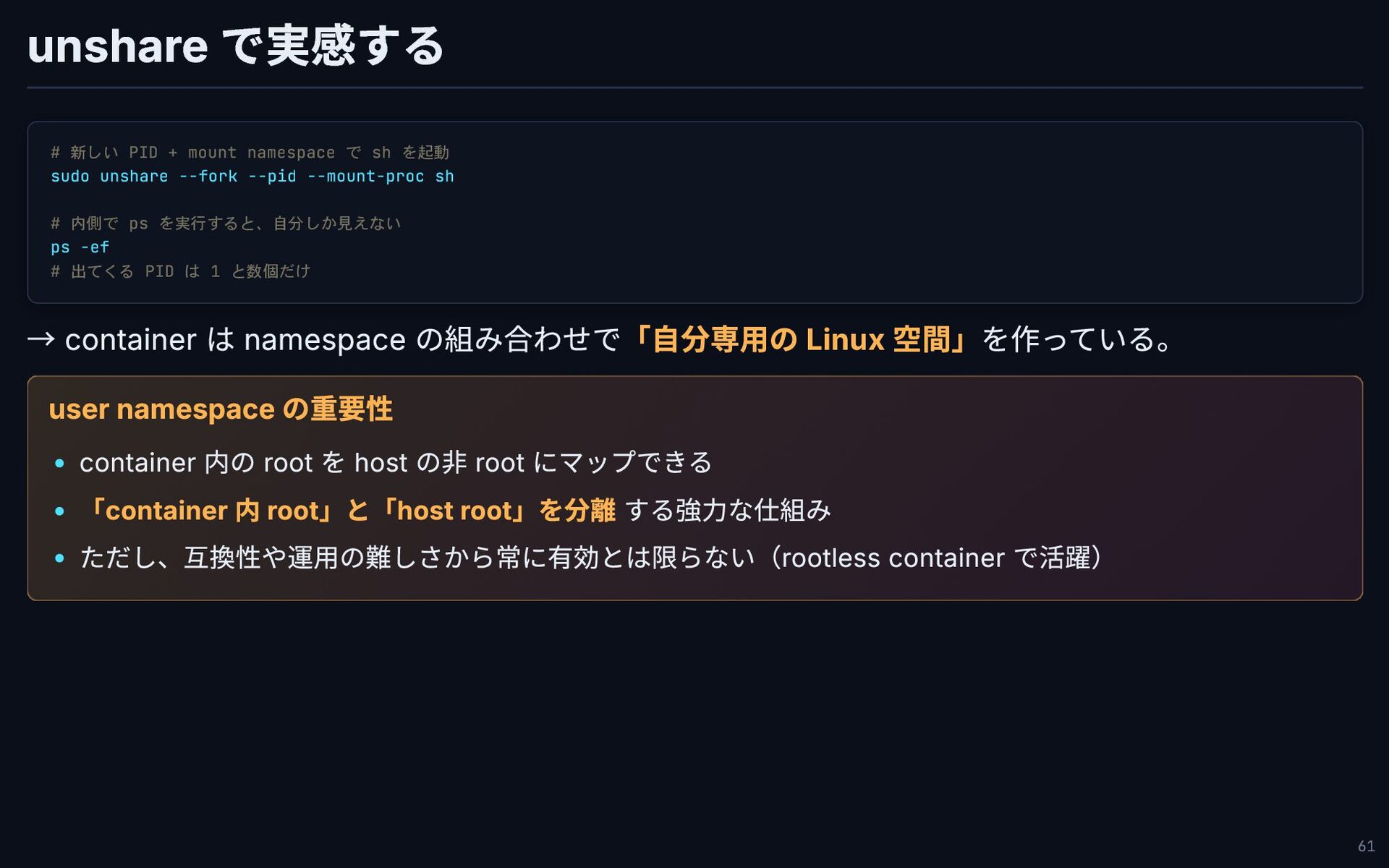
unshare で実感する # 新しい PID + mount namespace で sh
を起動 sudo unshare --fork --pid --mount-proc sh # 内側で ps を実行すると、自分しか見えない ps -ef # 出てくる PID は 1 と数個だけ → container は namespace の組み合わせで「自分専用の Linux 空間」を作っている。 user namespace の重要性 container 内の root を host の非 root にマップできる 「container 内 root」と「host root」を分離 する強力な仕組み ただし、互換性や運用の難しさから常に有効とは限らない(rootless container で活躍) 61
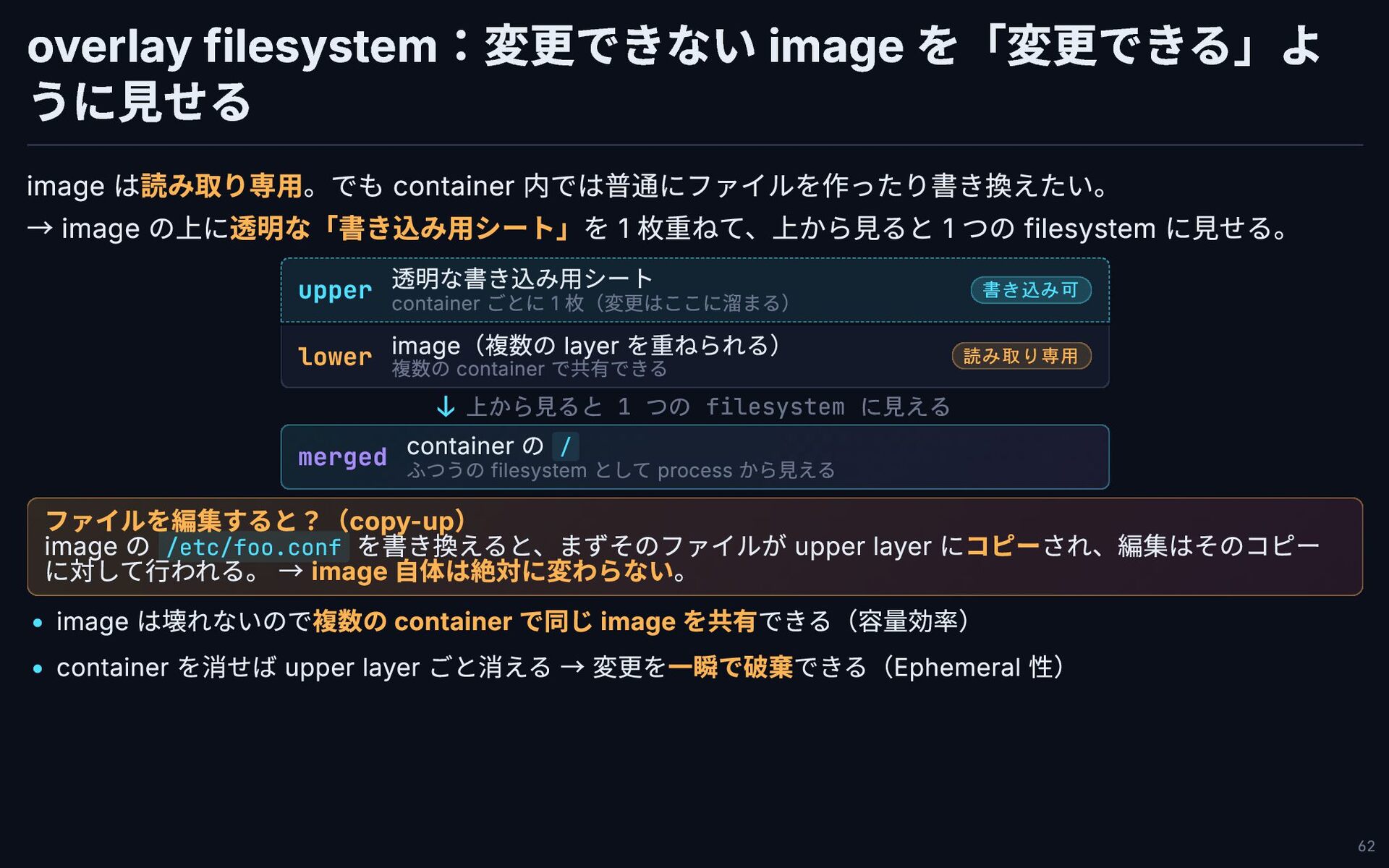
overlay filesystem:変更できない image を「変更できる」よ うに見せる image は読み取り専用。でも container 内では普通にファイルを作ったり書き換えたい。 →
image の上に透明な「書き込み用シート」を 1 枚重ねて、上から見ると 1 つの filesystem に見せる。 upper 透明な書き込み用シート container ごとに 1 枚(変更はここに溜まる) 書き込み可 ↓ 上から見ると 1 つの filesystem に見える merged container の / ふつうの filesystem として process から見える ファイルを編集すると?(copy-up) image の /etc/foo.conf を書き換えると、まずそのファイルが upper layer にコピーされ、編集はそのコピー に対して行われる。 → image 自体は絶対に変わらない。 image は壊れないので複数の container で同じ image を共有できる(容量効率) container を消せば upper layer ごと消える → 変更を一瞬で破棄できる(Ephemeral 性) lower image(複数の layer を重ねられる) 複数の container で共有できる 読み取り専用 62
B Dirty Pipe 深掘り(補足) 本編から省いた詳細 63
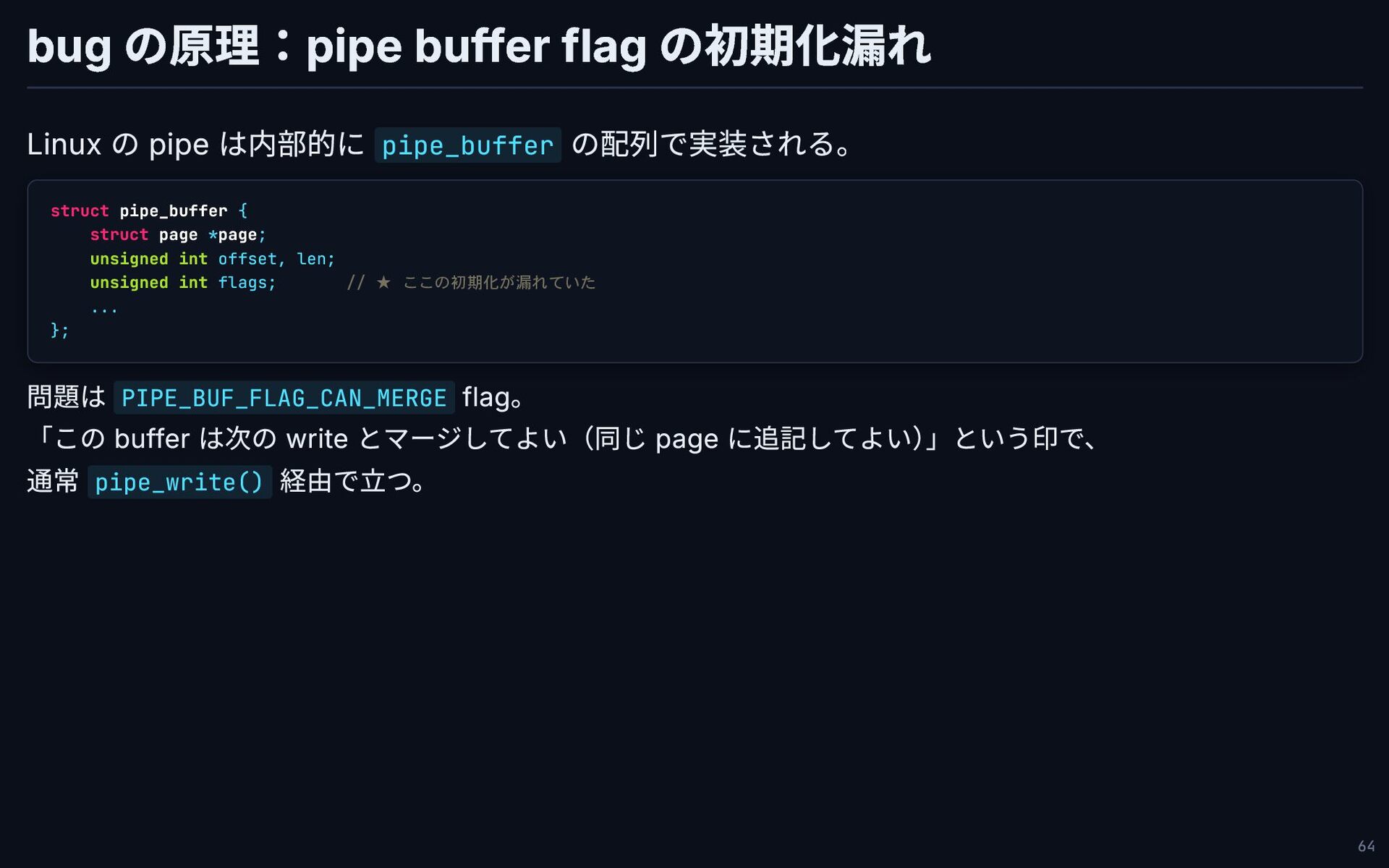
bug の原理:pipe buffer flag の初期化漏れ Linux の pipe は内部的に pipe_buffer
の配列で実装される。 struct pipe_buffer { struct page *page; unsigned int offset, len; unsigned int flags; // ★ ここの初期化が漏れていた ... }; 問題は PIPE_BUF_FLAG_CAN_MERGE flag。 「この buffer は次の write とマージしてよい(同じ page に追記してよい) 」という印で、 通常 pipe_write() 経由で立つ。 64
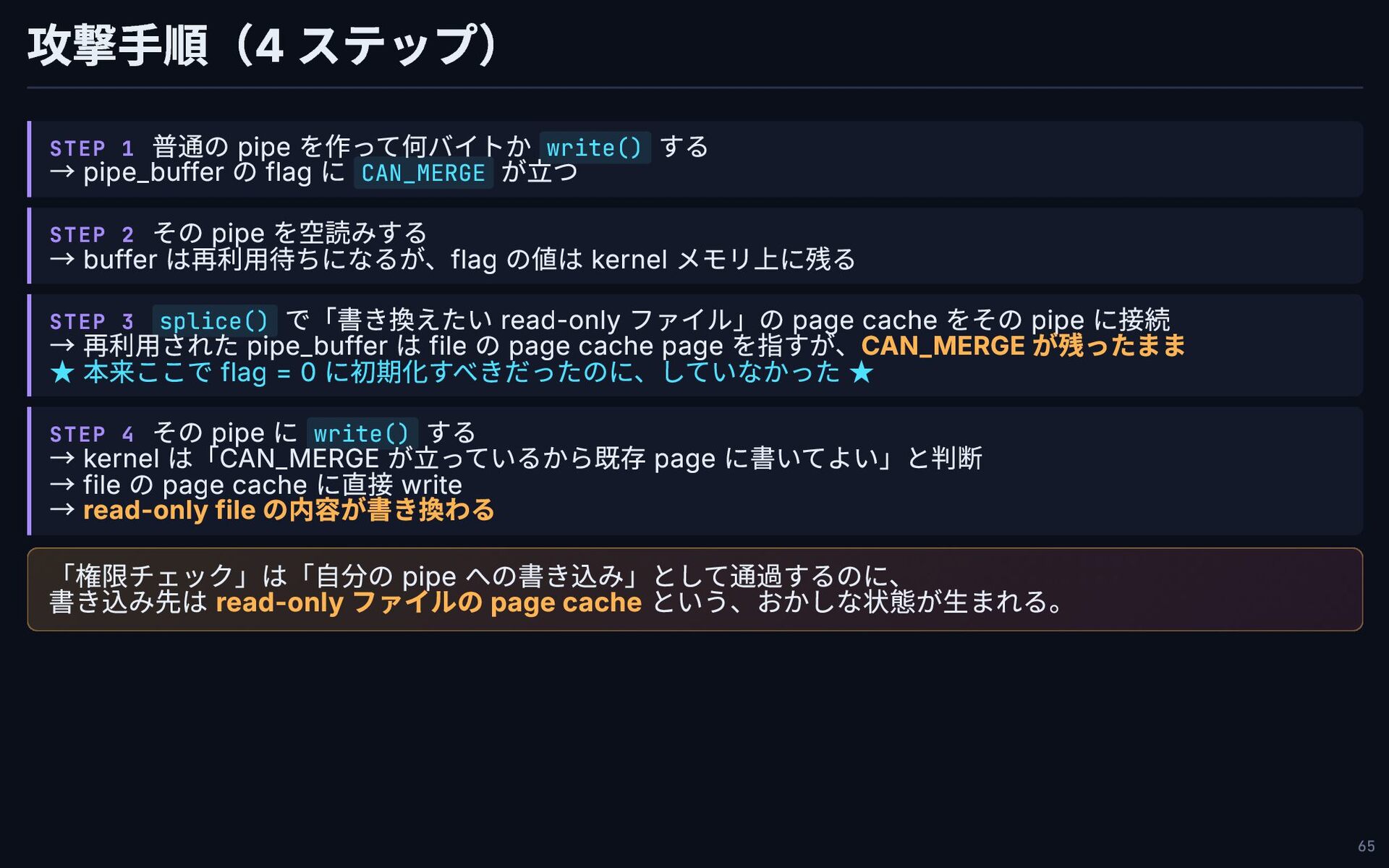
攻撃手順(4 ステップ) STEP 1 普通の pipe を作って何バイトか write() する →
pipe_buffer の flag に CAN_MERGE が立つ STEP 2 その pipe を空読みする → buffer は再利用待ちになるが、flag の値は kernel メモリ上に残る STEP 3 splice() で「書き換えたい read-only ファイル」の page cache をその pipe に接続 → 再利用された pipe_buffer は file の page cache page を指すが、CAN_MERGE が残ったまま ★ 本来ここで flag = 0 に初期化すべきだったのに、していなかった ★ STEP 4 その pipe に write() する → kernel は「CAN_MERGE が立っているから既存 page に書いてよい」と判断 → file の page cache に直接 write → read-only file の内容が書き換わる 「権限チェック」は「自分の pipe への書き込み」として通過するのに、 書き込み先は read-only ファイルの page cache という、おかしな状態が生まれる。 65
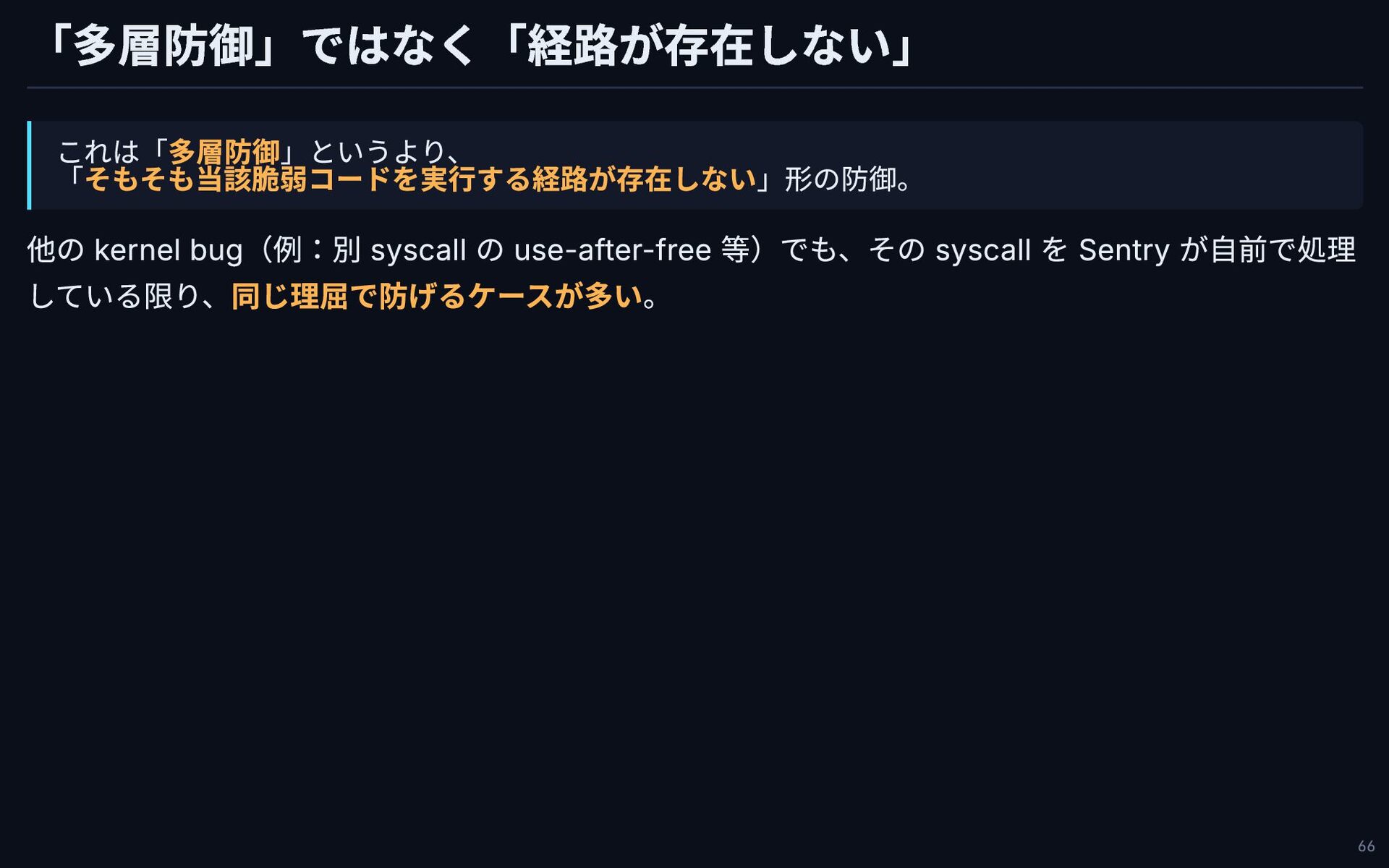
「多層防御」ではなく「経路が存在しない」 これは「多層防御」というより、 「そもそも当該脆弱コードを実行する経路が存在しない」形の防御。 他の kernel bug(例:別 syscall の use-after-free 等)でも、その
syscall を Sentry が自前で処理 している限り、同じ理屈で防げるケースが多い。 66
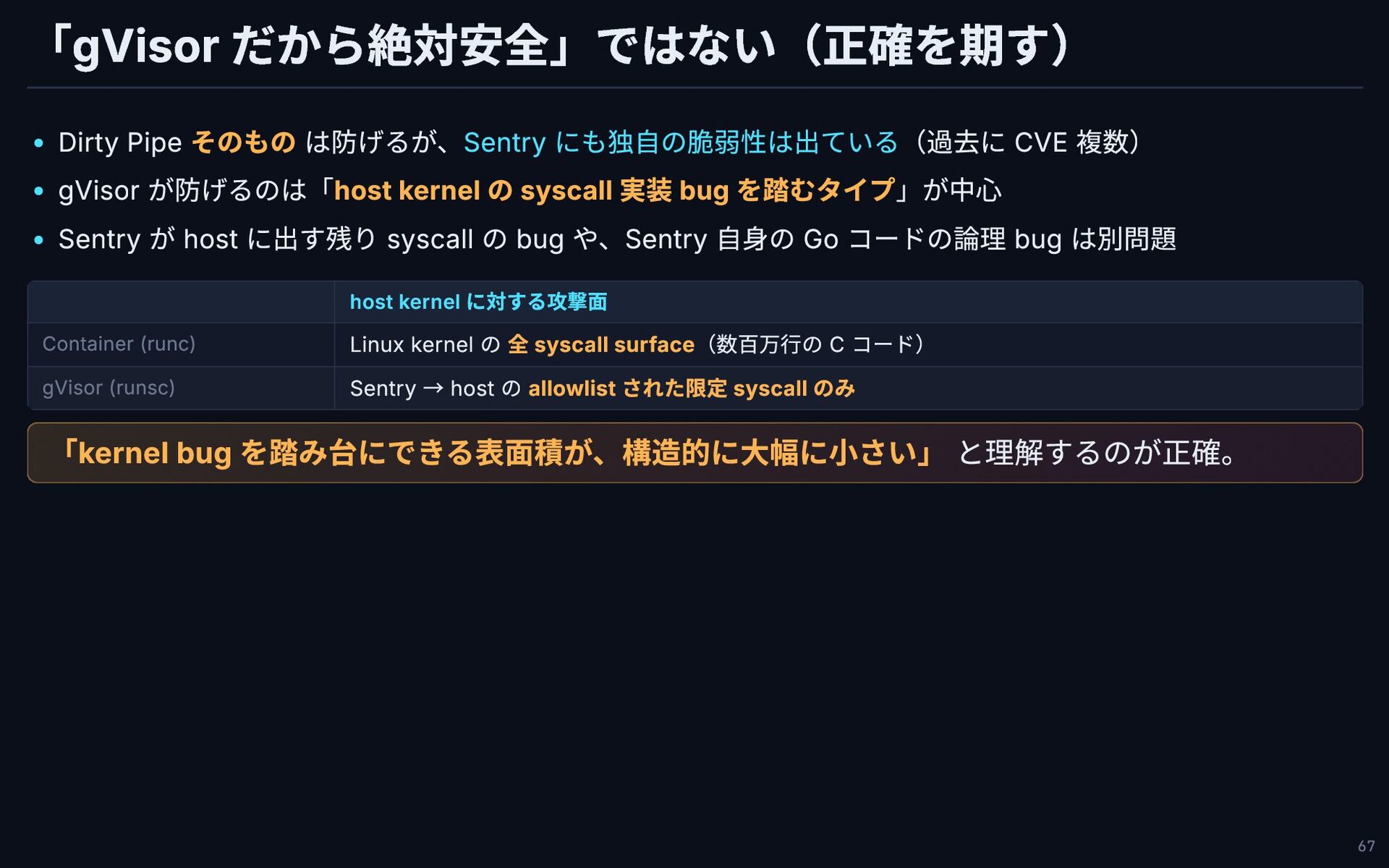
「gVisor だから絶対安全」ではない(正確を期す) Dirty Pipe そのもの は防げるが、Sentry にも独自の脆弱性は出ている(過去に CVE 複数) gVisor
が防げるのは「host kernel の syscall 実装 bug を踏むタイプ」が中心 Sentry が host に出す残り syscall の bug や、Sentry 自身の Go コードの論理 bug は別問題 host kernel に対する攻撃面 Container (runc) Linux kernel の 全 syscall surface(数百万行の C コード) gVisor (runsc) Sentry → host の allowlist された限定 syscall のみ 「kernel bug を踏み台にできる表面積が、構造的に大幅に小さい」 と理解するのが正確。 67
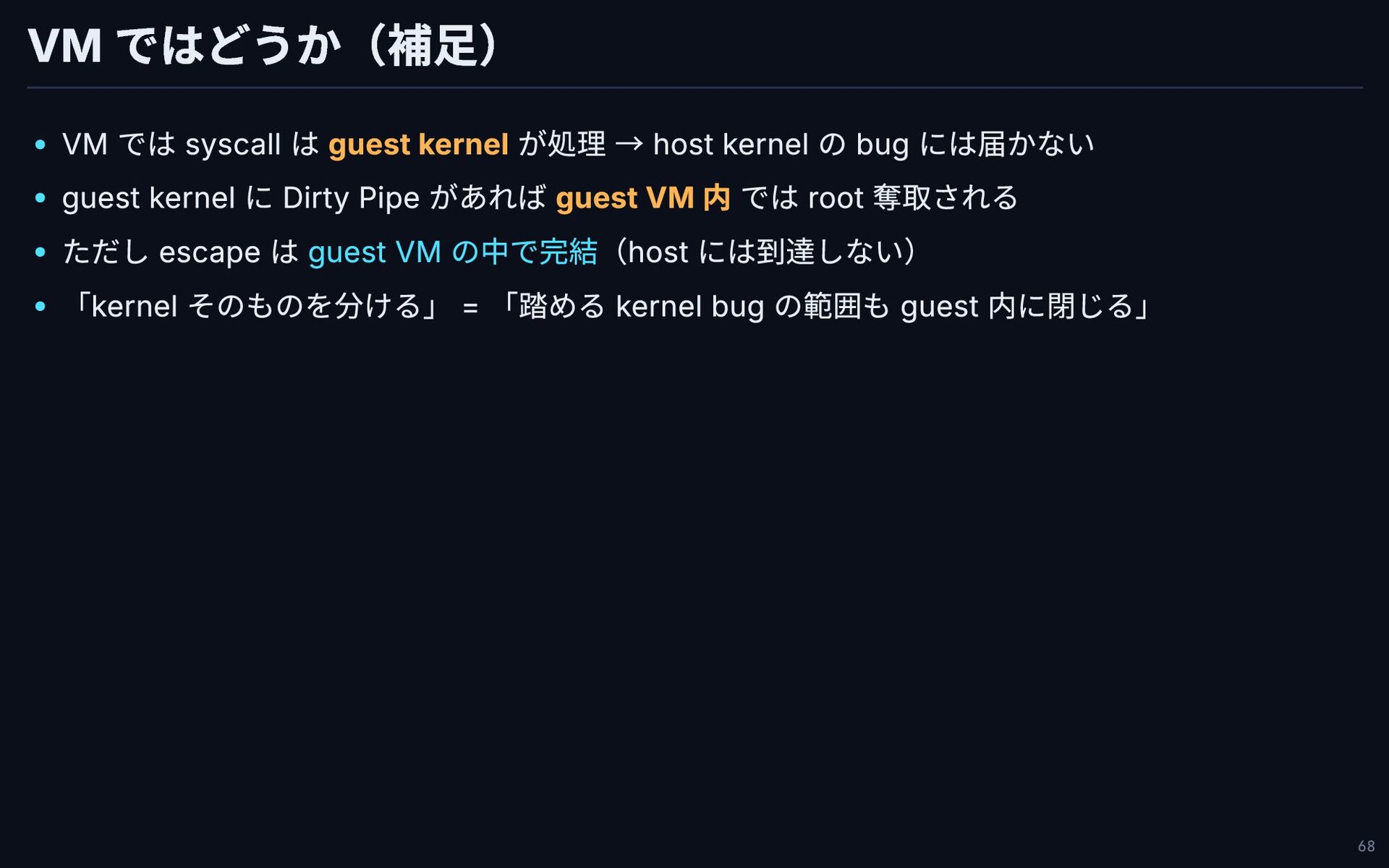
VM ではどうか(補足) VM では syscall は guest kernel が処理 →
host kernel の bug には届かない guest kernel に Dirty Pipe があれば guest VM 内 では root 奪取される ただし escape は guest VM の中で完結(host には到達しない) 「kernel そのものを分ける」 = 「踏める kernel bug の範囲も guest 内に閉じる」 68
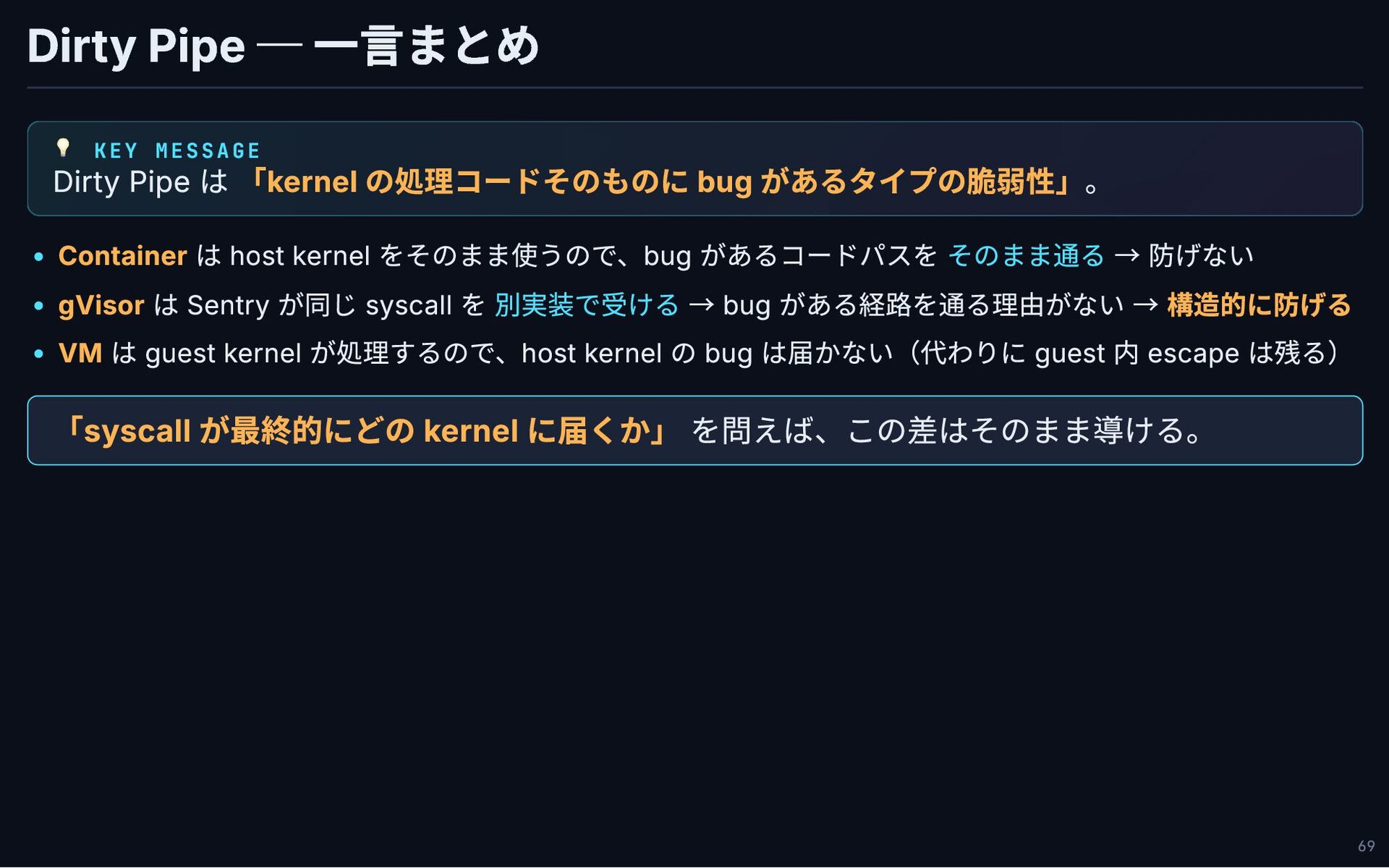
Dirty Pipe ─ 一言まとめ 💡 KEY MESSAGE Dirty Pipe は
「kernel の処理コードそのものに bug があるタイプの脆弱性」。 Container は host kernel をそのまま使うので、bug があるコードパスを そのまま通る → 防げない gVisor は Sentry が同じ syscall を 別実装で受ける → bug がある経路を通る理由がない → 構造的に防げる VM は guest kernel が処理するので、host kernel の bug は届かない(代わりに guest 内 escape は残る) 「syscall が最終的にどの kernel に届くか」 を問えば、この差はそのまま導ける。 69
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}