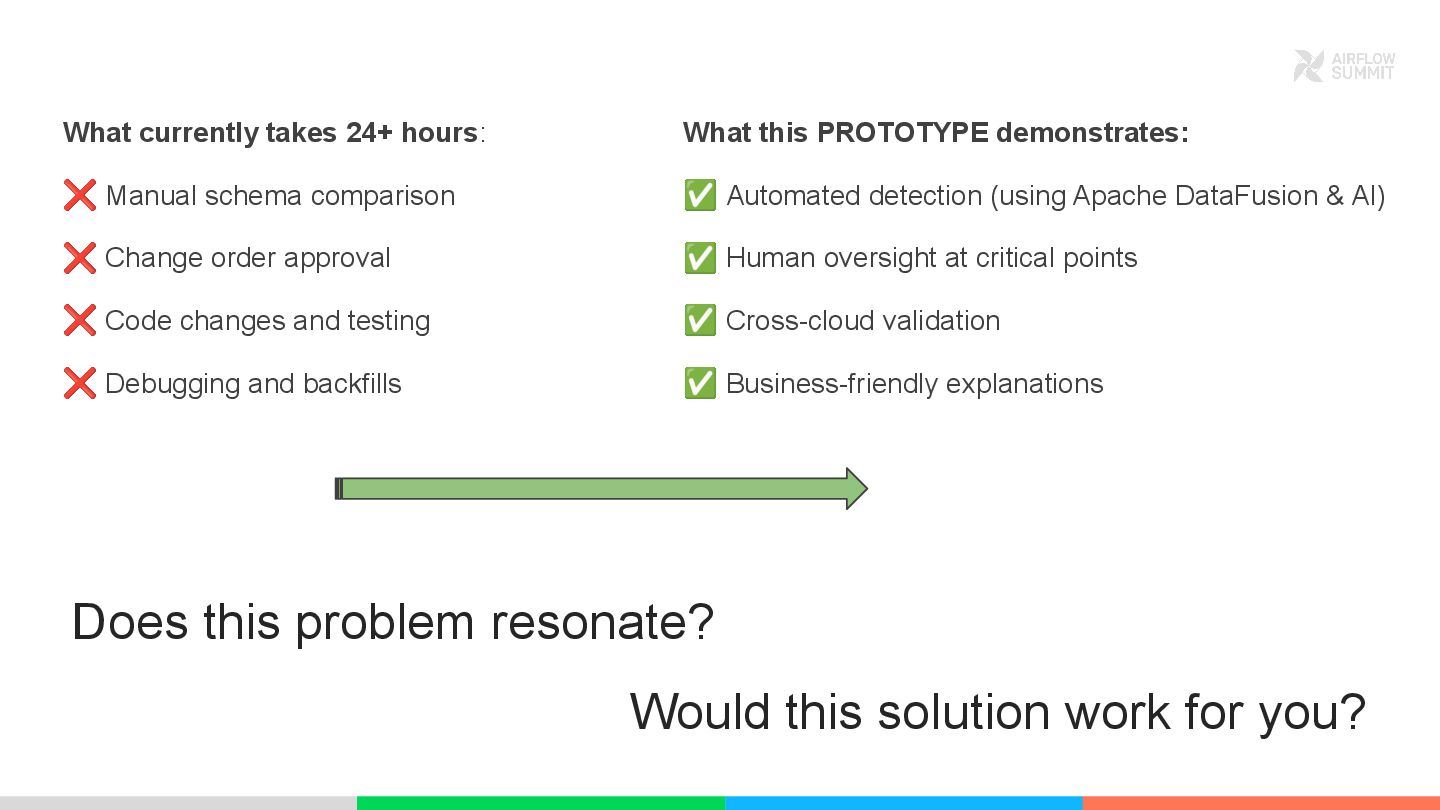
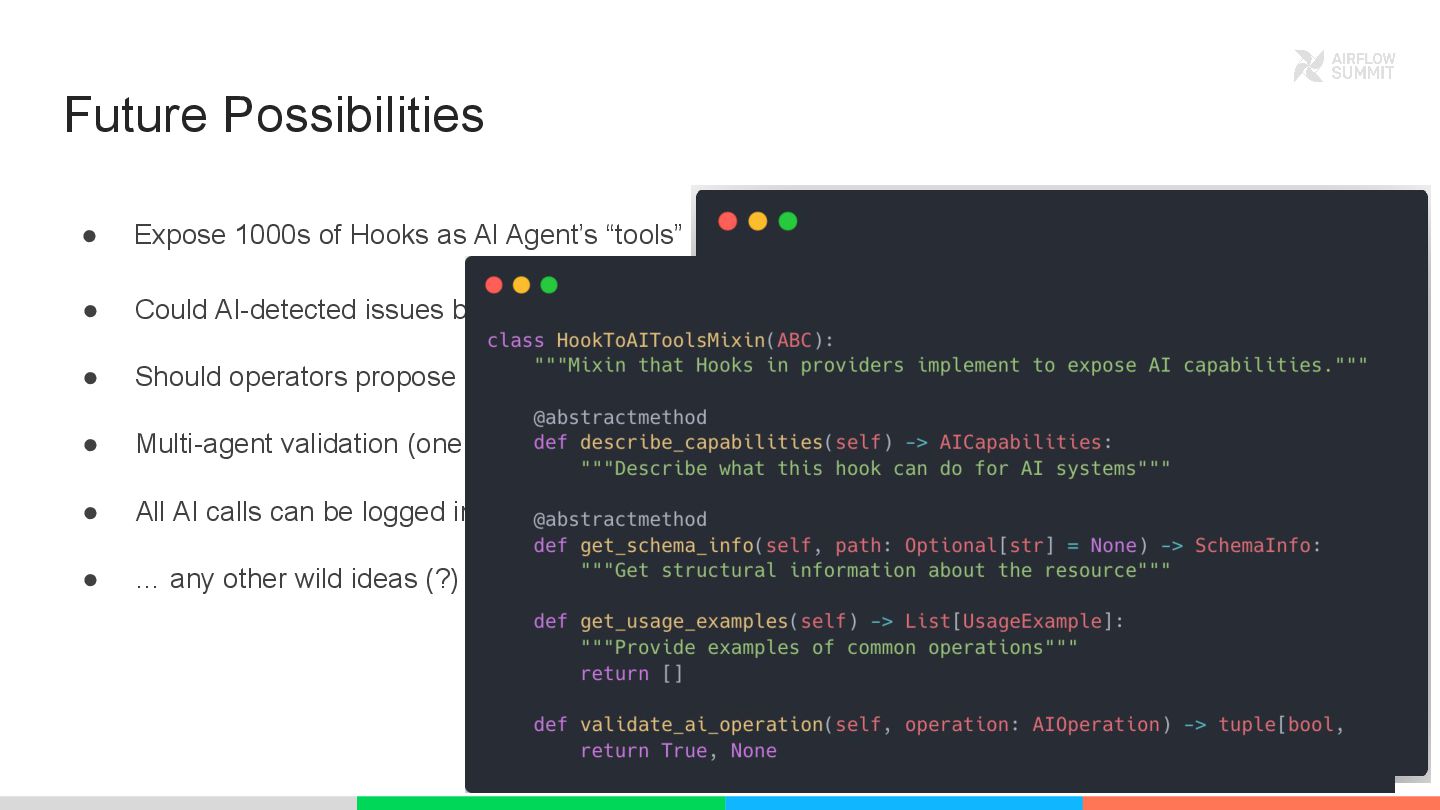
What if your Airflow tasks could understand natural language AND adapt to schema changes automatically, while maintaining the deterministic, observable workflows we rely on? This talk introduces practical patterns for AI-native orchestration that preserve Airflow’s strengths while adding intelligence where it matters most.
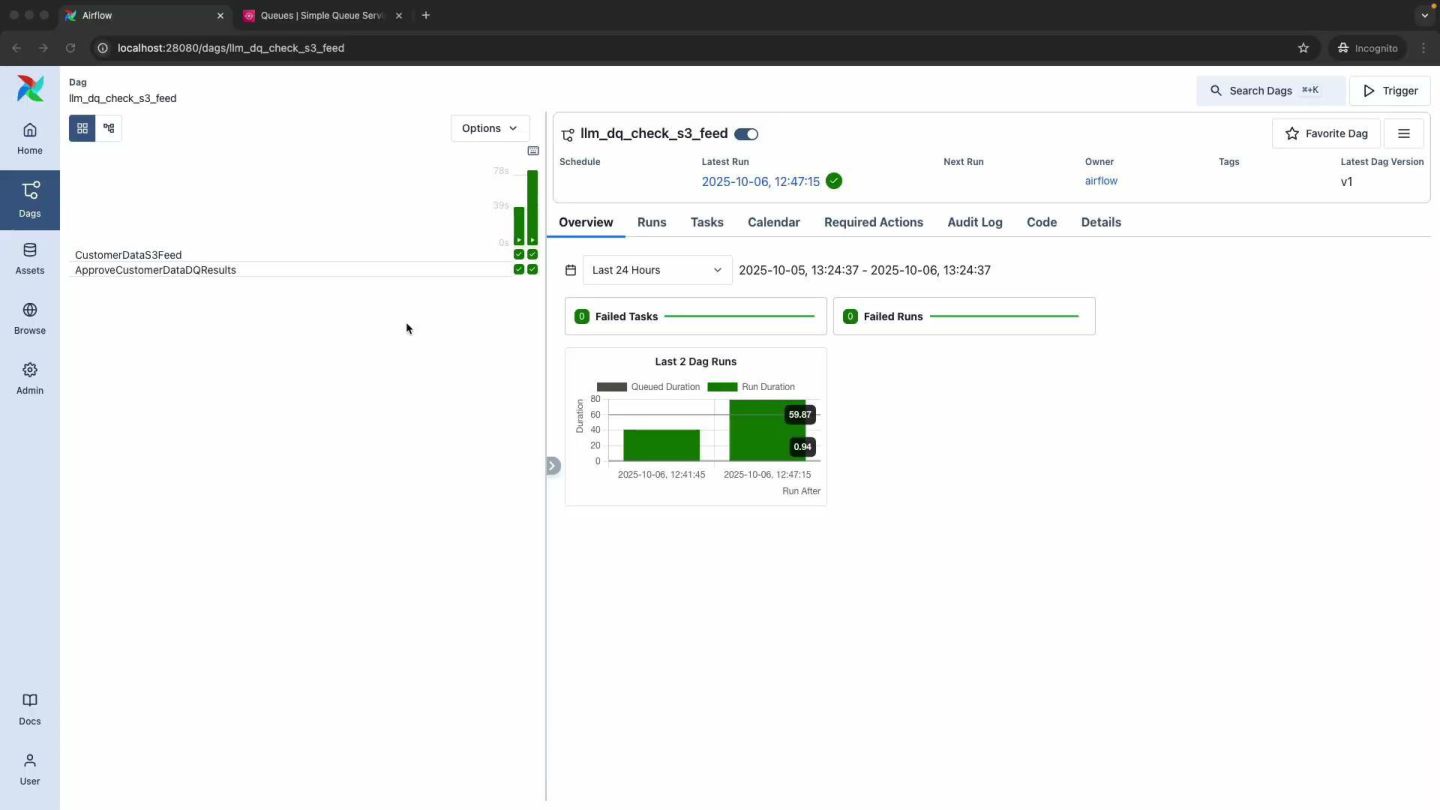
Through a real-world example, we’ll demonstrate AI-powered tasks that detect schema drift across multi-cloud systems and perform context-aware data quality checks that go beyond simple validation—understanding business rules, detecting anomalies, and generating validation queries from prompts like “check data quality across regions.” All within static DAG structures you can test and debug normally.
We’ll show how AI becomes a first-class citizen by combining Airflow’s features, assets for schema context, Human-in-the-Loop for approvals, and AssetWatchers for automated triggers, with engines such as Apache DataFusion for high-performance query execution and support for cross-cloud data processing with unified access to multiple storage formats. These patterns apply directly to schema validation and similar cases where natural language can simplify complex operations.
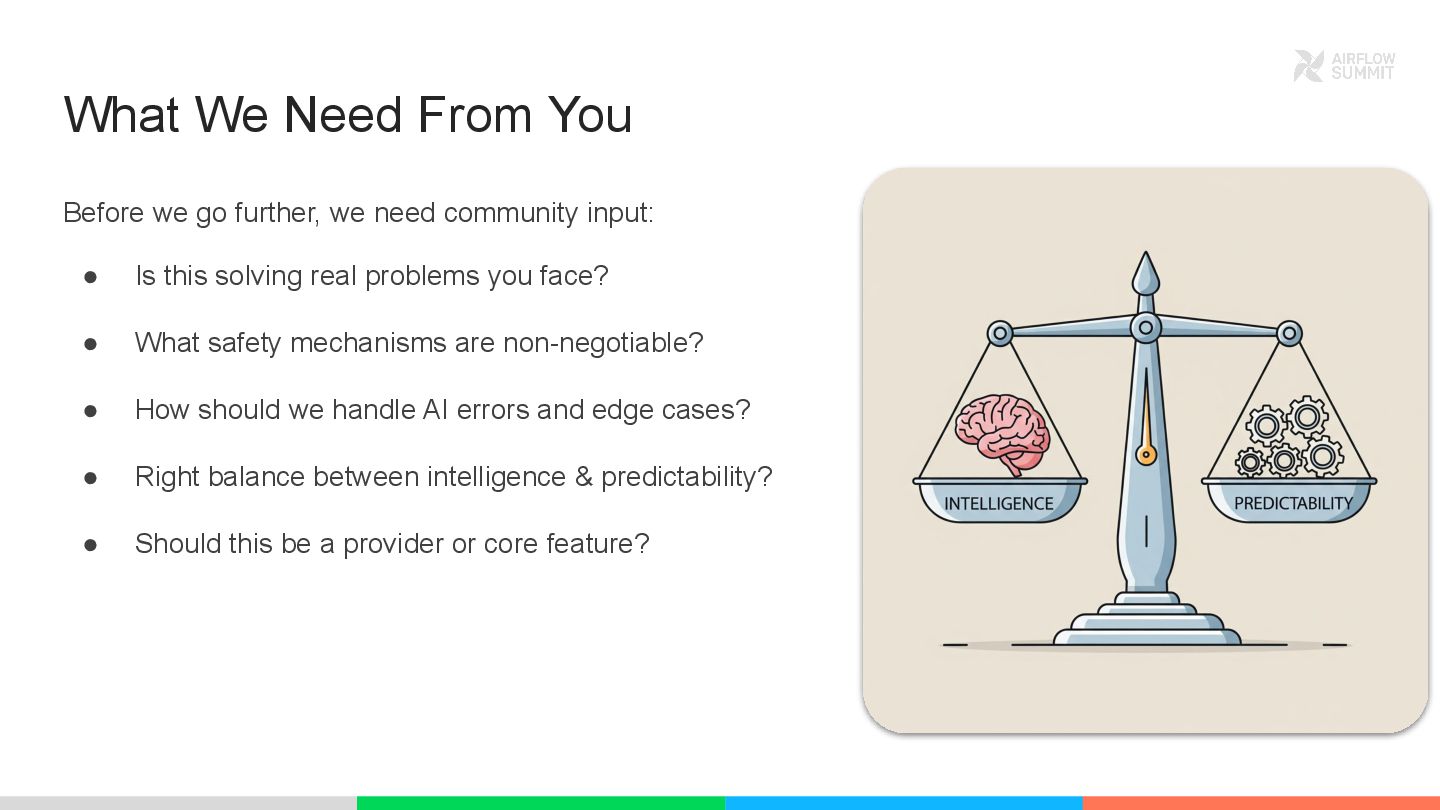
This isn’t about bolting AI onto Airflow. It’s about evolving how we build workflows, from brittle rules to intelligent adaptation, while keeping everything testable, auditable, and production-ready.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![How to get involved? 💬 Mailing list: [email protected] (AIP coming](https://files.speakerdeck.com/presentations/59aac4d25011458484ef39f7c87b74cd/slide_23.jpg){kind=link}
{kind=link}
{kind=link}