Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
IVRyにおけるNLP活用と NLP2025の関連論文紹介
Search
keisuke-osone
April 13, 2025
Technology
400
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
IVRyにおけるNLP活用と NLP2025の関連論文紹介
NLP2025 参加報告会 presented by Money Forward Labでの発表資料です
keisuke-osone
April 13, 2025
More Decks by keisuke-osone
See All by keisuke-osone
GENDAとIVRy、急成長スタートアップがDatabricksを採用した理由 Data + AI World Tour 2025
keisukeosone
1
3.1k
AI・データサイエンス 組織のアンチパターン とその対応ケースの事例紹介 ~LIFULL AI Hub 100 ミニッツ #4 「データ組織のマネジメント」~
keisukeosone
2
1k
Other Decks in Technology
See All in Technology
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
160
オートマトンと字句解析でRoslynを読む
tomokusaba
0
110
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
380
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
180
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
160
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
4
1k
QA・ソフトウェアテスト研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
3
1.5k
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.2k
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
キャリアLT会#3
beli68
2
280
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
140
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
170
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
First, design no harm
axbom
PRO
2
1.2k
Embracing the Ebb and Flow
colly
88
5.1k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
A Soul's Torment
seathinner
6
3.1k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Odyssey Design
rkendrick25
PRO
2
730
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
IVRyにおけるNLP活⽤と NLP2025の関連論⽂紹介 ~NLP2025 参加報告会 presented by Money Forward Lab~ 株式会社IVRy(アイブリー)
VP of Data ⼤曽根 圭輔 2025/4/11
⾃⼰紹介 ▪ 学⽣時代: 筑波⼤学⼤学院で博⼠(⼯学) 第⼆次ブームの終焉あたりにゲームAIの研究 ▪ 2012年: 株式会社サイバード データ分析部⾨⽴ち上げ等を担当 ▪
2015年: 株式会社Gunosy ニュース記事配信アルゴリムの改善およびグノシー事業責任者 ▪ 2022年: 株式会社アダコテック 製造業向け外観検査プロダクトのエンジニアリングマネージャー ▪ 2024年: 株式会社IVRy BizDev(事業開発)として参画 ⼤曽根 圭輔 2
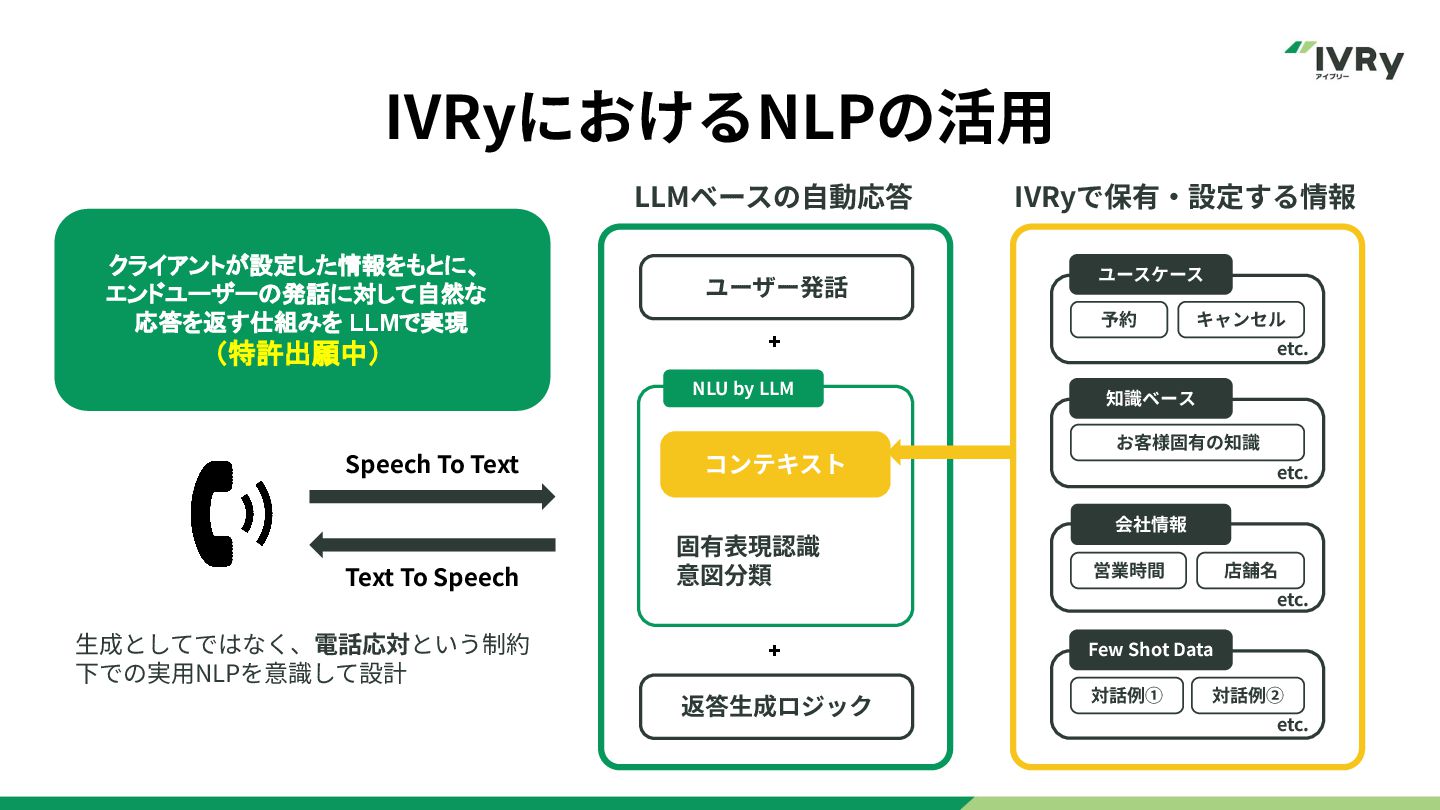
IVRyにおけるNLPの活⽤ 3 Speech To Text Text To Speech IVRyで保有‧設定する情報 LLMベースの⾃動応答
⽣成としてではなく、電話応対という制約 下での実⽤NLPを意識して設計 + ユーザー発話 固有表現認識 意図分類 コンテキスト 返答⽣成ロジック + ユースケース Few Shot Data 予約 キャンセル etc. 知識ベース etc. etc. お客様固有の知識 会社情報 etc. 営業時間 店舗名 対話例① 対話例② NLU by LLM クライアントが設定した情報をもとに、 エンドユーザーの発話に対して自然な 応答を返す仕組みを LLMで実現 (特許出願中)
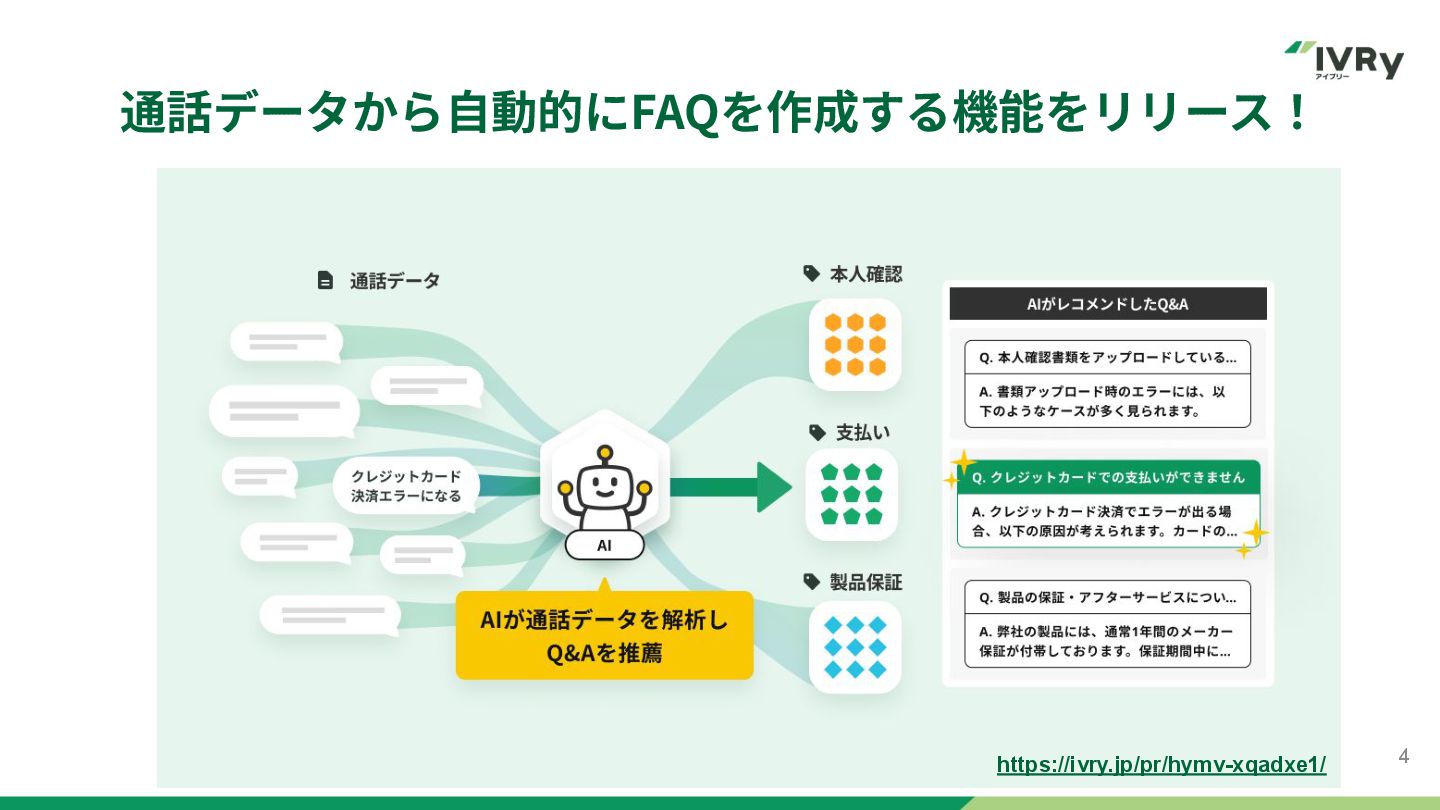
通話データから⾃動的にFAQを作成する機能をリリース! 4 https://ivry.jp/pr/hymv-xqadxe1/
5 関連する論⽂紹介
選んだ理由 • 潜在トピックの発⾒とFAQ候補の抽出タスクは似ているため選定 概要 • 希少‧難治性疾患患者が新型コロナウイルス感染症の流⾏期間中に経験した困難の⾃由記述 テキストを対象に、⼤規模⾔語モデル(LLM)を活⽤して質的データ分析を⾃動化する⼿法 を提案‧検証 6 質的研究の⾃動化:患者⾃由記述テキストからの潜在的トピックの発⾒
橋本 清⽃, 清⽔ 聖司, ⼯藤 紀⼦ (NAIST), ⽮⽥ 竣太郎 (筑波⼤), 若宮 翔⼦ (NAIST), 江 本 駿, ⻄村 由希⼦ (ASrid), 荒牧 英治 (NAIST) 論文URL: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/P6-1.pdf
質的研究の⾃動化:患者⾃由記述テキストからの潜在的トピックの発⾒ 7 タグ⽣成の流れ • タグ⽣成(TagGen) ◦ ⾃由記述テキストから、LLMによって困難の内容を20⽂字以内で要約する「タグ」を ⽣成。既存タグに分類できるものはそのまま、できないものは新規タグを⽣成 • タグ統合(TagInteg)
◦ 意味的に類似するタグ同⼠をLLMにより統合。統合基準には「意味的類似度スコア (0〜100)」を使⽤ ◦ 作成された新たなタグリストに対し再分類も⾏い、出⼒の⼀貫性と冗⻑性削減を実 現。 実験 • データ:特定⾮営利活動法⼈ ASrid が収集した110名からの813件の⾃由記述テキスト • 評価:813件中251件に⼈⼿でタグを付け、LLMによるタグ付けと⽐較 • 使⽤モデル:Gemma2:27b-instruct-fp16
質的研究の⾃動化:患者⾃由記述テキストからの潜在的トピックの発⾒ 8 結果 • ⼈⼿での付与との⽐較 ◦ ARI (Adjusted Rand Index)
は 4 回⽬の試⾏で最⾼値を記録 ◦ 提案⼿法により⽣成されたタグと正解ラベル付きデータとある程度⼀致 ▪ F1 スコア 0.5151,Cohen’s Kappa 0.4592 • 全データに対しても「感染予防対策」「通院期間の延⻑」「衛⽣⽤品不⾜」など、社会背景 を反映する内容も多く含まれていた。 感想 • 統合の過程で階層が得られるため、通話の構造化のヒントにもなる可能性あり • 今回の試⾏の最適値は4となったが対象の構造によってどう変わるかは興味
選んだ理由 • IVRyの対話タスクにおいても研究背景と同様の課題がある。 ◦ コスト⾯で⼈⼿での評価が難しい 概要 • ⽂⽣成タスクの「評価者」としてLLMの活⽤が注⽬されており、⾼コストな⼈⼿評価の代替 ⼿段として期待 •
⼤規模映画字幕コーパスであるOpenSubtitlesから作成した⽇本語発話‒応答ペア集合から抽 出した対話データセットに対してLLMで対話品質を評価 ⼤規模⾔語モデルを⽤いた対話品質評価に関する調査 ⾚間 怜奈, 鈴⽊ 潤 (東北⼤/理研) 9 論文URL: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/D8-4.pdf
実験 • OpenSubtitlesから獲得した対話データには対話として許容できない低品質な発話‒応答ペアが含 まれる(映画のデータなのでそれはそう) ◦ 対話データに対して良い-悪い * スコア、スコア-テキスト、テキストの6種類で評価 ▪ 良い-悪いのそれぞれで「5」、「5:強く同意する」、「強く同意する」
◦ その評価の根拠(判断理由)も合わせて出⼒ 結果 • 「品質の良さを、スコアとテキストの両⽅で回答する」設定で相関は⼈での評価と最⼤に • 「⼤きい数字は “良い” 状態を表す」というバイアスを持っている可能性があることがわかった 感想 • LLMでの評価と⾔っても⼯夫の幅は⼤きい。対話データの評価も⼈⼿評価のデータセットと組み 合わせて検証していく必要性あり(実データの応答率など組み合わせるとより良い?) ⼤規模⾔語モデルを⽤いた対話品質評価に関する調査 10
場所表現の地理的曖昧性を解消するための質問内容⽣成 清⽔ 美緒奈, 林 純⼦, 久⽥ 祥平, 若宮 翔⼦, 荒牧
英治, ⼤内 啓樹 (NAIST) 選んだ理由 • 対話において位置情報を抽出する必要がある場合にランドマークなどを使い対話的に場所を 特定するケースがあるため選定 概要 • 地名や施設名などの場所表現が複数の地理的解釈を持つ(例:「⽇本橋」は東京にも⼤阪に もある)という問題に対し、ユーザに追加情報を尋ねる質問内容を⾃動⽣成することで、位 置の特定を⽀援する⽅法を提案 • 曖昧な地名に対し、候補地点を絞り込むために有効なランドマークを抽出し、それを使った 質問を⾃動で⽣成 論文URL: https://www.anlp.jp/proceedings/annual_meeting/2025/pdf_dir/E3-2.pdf
実験 • GoogleのStreetViewの情報から対話的に⽬的地(⼆つのカフェ(店舗 A,店舗 B))を識別する ために有⽤なランドマークを抽出する実験 ◦ 店舗の位置情報(緯度‧経度)、周辺のストリートビュー画像(東⻄南北)、半径内のラン ドマーク名とカテゴリ 結果
• F1スコアで0.48 ◦ カテゴリの曖昧さ(例:"shop" と "amenity" の区別が困難) ◦ 過剰な推測による誤判断(ランドマークがないケースでも何かを選んでしまう) 感想 • 通話でもランドマークの特定などをAI対話で解けると⾯⽩いなと感じた。実際の対話のデータ セット使いながら評価をしたい。 場所表現の地理的曖昧性を解消するための質問内容⽣成
13 まとめと今後の展望
まとめと今後の展望 • IVRyは対話型⾳声AI SaaSの会社で⾃動応答の機能を開発している ◦ 先⽇リリースした通話データからFAQを作成する機能などの実務に関わる論⽂を紹介 ▪ 質的研究の⾃動化:患者⾃由記述テキストからの潜在的トピックの発⾒ ▪ ⼤規模⾔語モデルを⽤いた対話品質評価に関する調査
▪ 場所表現の地理的曖昧性を解消するための質問内容⽣成 • IVRyとしてNLPに参加してみて ◦ 実績を積んできた先⼈たちと⽐較してまだまだIVRyの認知は低い ▪ 研究‧発表でどんどん存在感を増さないといけない ▪ それが採⽤にもつながるしプロダクトの価値につながるのでどんどんアウトプッ トしていきたい
We are Hiring! 今⽇話してない観点についても 発信していますので是⾮! (Note)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}