Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Reth...
Search
小林優斗
June 20, 2026
Research
180
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
小林優斗
June 20, 2026
More Decks by 小林優斗
See All by 小林優斗
ICCV2025参加報告_採択されやすいワークショップの選び方
kobayashi31
0
180
Other Decks in Research
See All in Research
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
280
Fukui Shibiten 39 - AI Art
butchi
0
160
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
240
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
430
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
170
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
Using our influence and power for patient safety
helenbevan
0
380
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
200
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
340
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
200
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
170
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
130
Featured
See All Featured
So, you think you're a good person
axbom
PRO
2
2.1k
BBQ
matthewcrist
89
10k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
480
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
450
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
270
The SEO identity crisis: Don't let AI make you average
varn
0
520
The Cult of Friendly URLs
andyhume
79
7k
The Curse of the Amulet
leimatthew05
2
13k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Transcript
VLMにとって 良いvision encoderとは何か? 小林優斗(名工大 玉木・丁研) 第64回 名古屋CV・PRML勉強会 CVPR2026論文紹介 Rethinking Model
Selection in VLM Through the Lens of Gromov-Wasserstein Distance Muyang Li, Yucheng Liu, Jianbo Ma, Elliot Osborne, Bo Han, Tongliang Liu
本紹介の概要 ◼背景知識の説明 • VLMとは • 標準のアーキテクチャ • Vision Encoder の重要性
◼CVPR2026の論文紹介 • Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance [Li+, CVPR2026] (ハイライト論文)
背景知識:VLMとは ◼一般的なVision-Language Model (VLM) • 画像と言語を統合的に扱うモデル全般 • CLIP, BLIP, LLaVA,
Qwen等 ◼この論文での「VLM」 • 上記の中でもLLMに視覚特徴を入力するもの • MLLM (Multimodal LLM) • LVLM (Large VLM) と呼ばれるモデル LLaVA-1.5 [Liu+, CVPR2024]
背景知識:MLLMの標準アーキテクチャ ◼3段階の構造 • LLM • Alignment Module / projector /
connector • Vision Encoder ◼2段階の学習 1. Alignment Moduleのみ事前学習 2. モデル全体のファインチューニング LLaVA-1.5 [Liu+, CVPR2024] Vision Encoder Alignment Module LLM Vision Encoder Alignment Module LLM
背景知識:MLLMにおけるVision Encoderの重要性 ◼CLIPエンコーダの課題が指摘されている • 詳細な視覚理解能力の不足 MMVP [Shengbang+, CVPR2024] (カウント) (方向)
Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein
Distance Muyang Li, Yucheng Liu, Jianbo Ma, Elliot Osborne, Bo Han, Tongliang Liu CVPR2026
概要 ◼背景 • どのVision Encoderを選択するべきか明確な基準の分析不足 • MLLM全体でファインチューンするまでどのくらい性能が出るか分からない • コストが高い ◼主張
• 重要なのはVision Encoderの単体性能よりLLMとの“相性・適合性” • モデルのサイズ・画像分類のZero-shot性能 ◼貢献 • Vision EncoderとLLMの各表現について構造的類似性を“相性”の概念として提案 • その代理指標としてGW距離 を使う “トレーニング不要の選択指標” を提案 • 重い学習をすることなくMLLMの性能の良し悪しを予測できる
表現空間の構造の類似性が手がかりでは? ◼アイデア • Vision EncoderとLLM内部の表現空間の構造が類似していれば容易にアライン でき,より良い共同理解が働くのでは(学習後の性能が高いのでは) • 「表現分布間の距離」的なものが指標になりそう ◼どんな分布間距離指標がいい? •
同じ空間で比べる距離指標は使えない • 例 • KLダイバージェンス • Wasserstein距離 • Vision EncoderとLLMは次元が異なる • 距離や類似度の物差しがない 異なる空間にある2つの分布の構造 の類似度を評価したい…
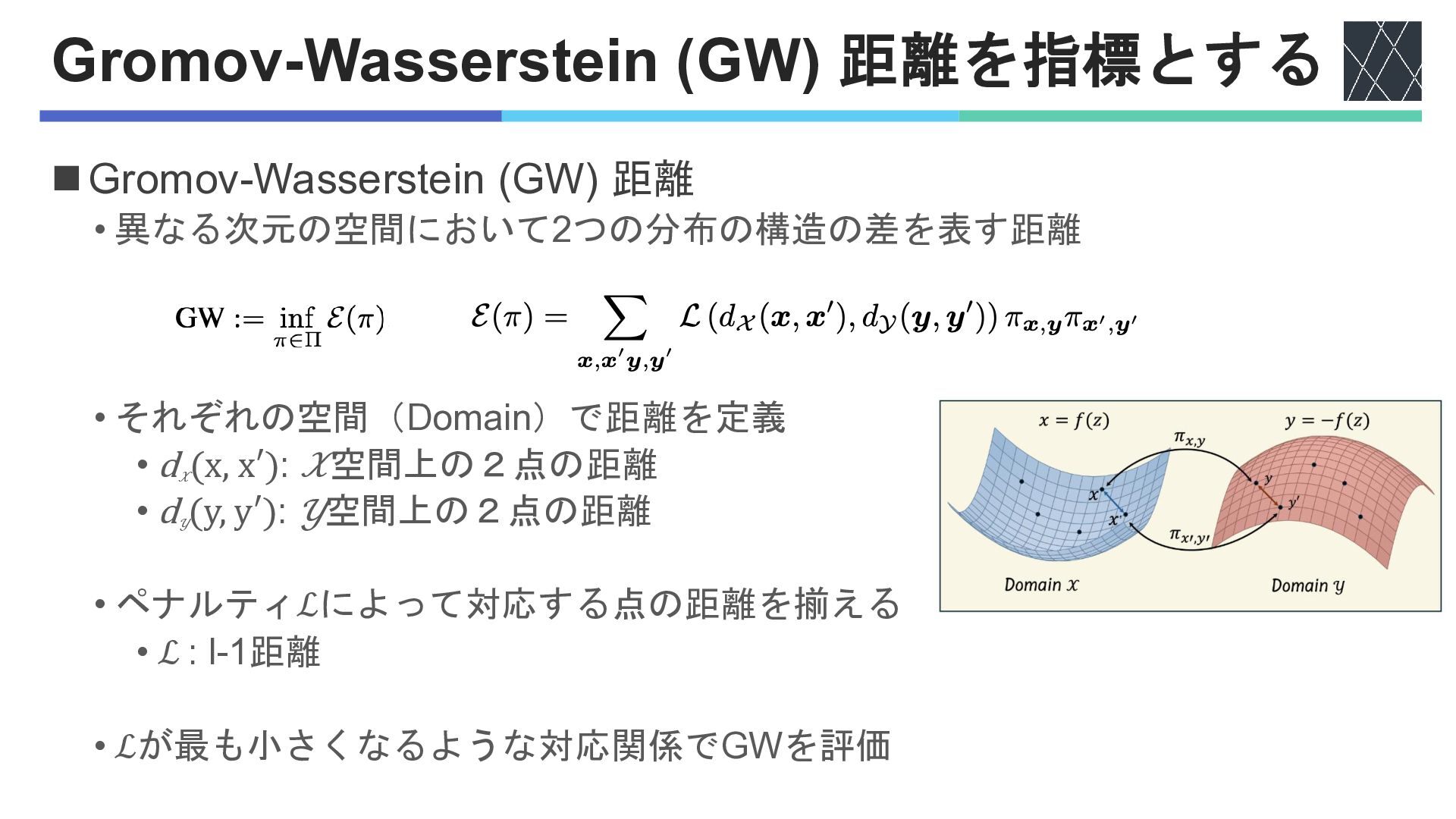
Gromov-Wasserstein (GW) 距離を指標とする ◼Gromov-Wasserstein (GW) 距離 • 異なる次元の空間において2つの分布の構造の差を表す距離 • それぞれの空間(Domain)で距離を定義
• d 𝒳 (x, x′): 𝒳空間上の2点の距離 • d 𝒴 (y, y′): 𝒴空間上の2点の距離 • ペナルティℒによって対応する点の距離を揃える • ℒ : l-1距離 • ℒが最も小さくなるような対応関係でGWを評価
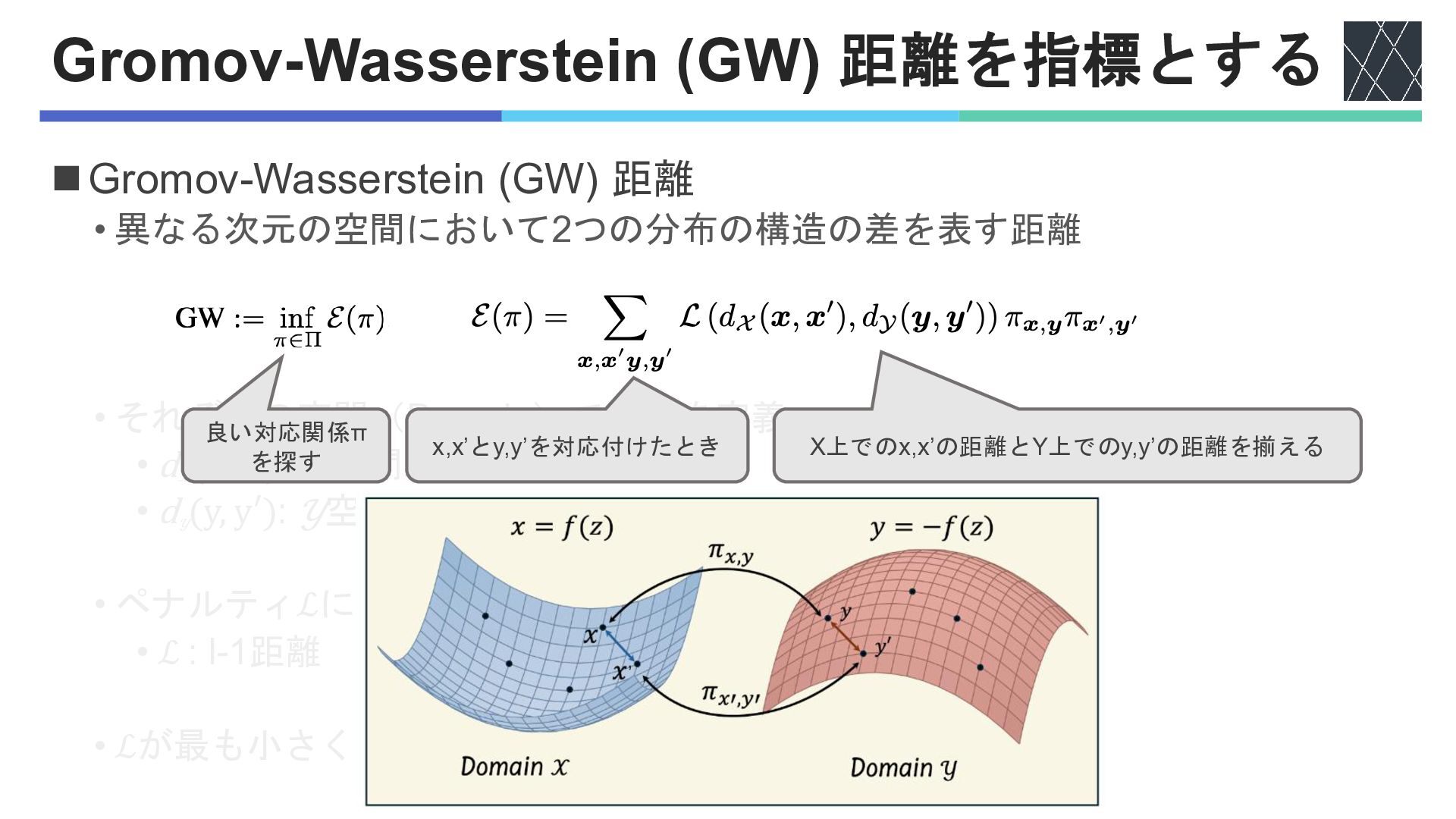
Gromov-Wasserstein (GW) 距離を指標とする ◼Gromov-Wasserstein (GW) 距離 • 異なる次元の空間において2つの分布の構造の差を表す距離 • それぞれの空間(Domain)で距離を定義
• d 𝒳 (x, x′): 𝒳空間上の2点の距離 • d 𝒴 (y, y′): 𝒴空間上の2点の距離 • ペナルティℒによって対応する点の距離を揃える • ℒ : l-1距離 • ℒが最も小さくなるような対応関係でGWを評価 良い対応関係π を探す X上でのx,x’の距離とY上でのy,y’の距離を揃える x,x’とy,y’を対応付けたとき
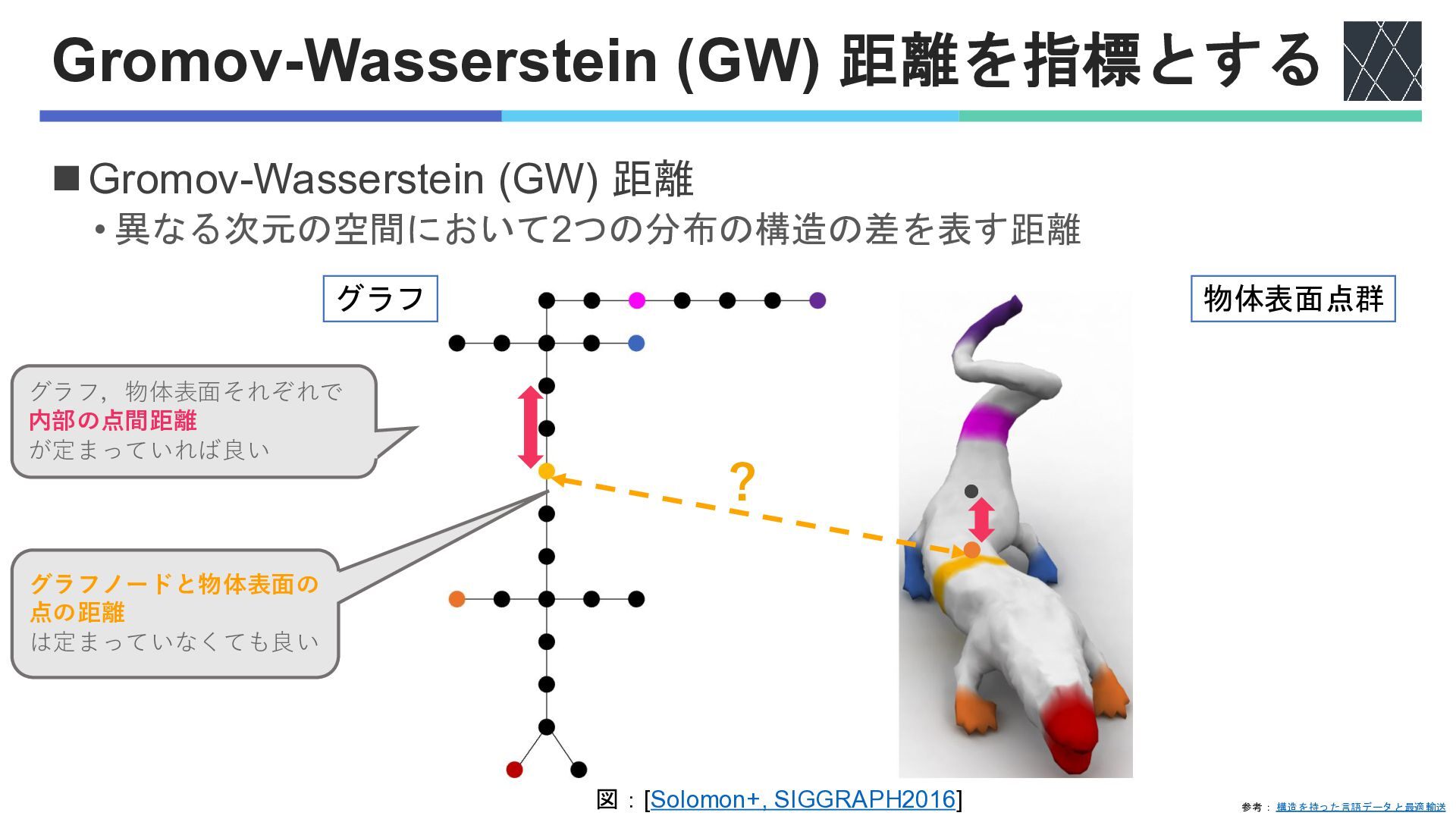
Gromov-Wasserstein (GW) 距離を指標とする ◼Gromov-Wasserstein (GW) 距離 • 異なる次元の空間において2つの分布の構造の差を表す距離 • それぞれの空間(Domain)で距離を定義
• d 𝒳 (x, x′): 𝒳空間上の2点の距離 • d 𝒴 (y, y′): 𝒴空間上の2点の距離 • ペナルティℒによって対応する点の距離を揃える • ℒ : l-1距離 • ℒが最も小さくなるような対応関係でGWを評価 良い対応関係π を探す X上でのx,x’の距離とY上でのy,y’の距離を揃える 物体表面点群 参考: 構造を持った言語データと最適輸送 x,x’とy,y’を対応付けたとき 図:[Solomon+, SIGGRAPH2016] ? グラフノードと物体表面の 点の距離 は定まっていなくても良い グラフ,物体表面それぞれで 内部の点間距離 が定まっていれば良い グラフ
各空間で定義した距離のスケール合わせ ◼d 𝒳 , d 𝒴 は(それぞれの定義によって)スケールが異なる • ℒを求める前に揃える必要がある ◼Median-ratio
matching • 2つの距離の中央値のスケールが合うようにどちらかを定数倍
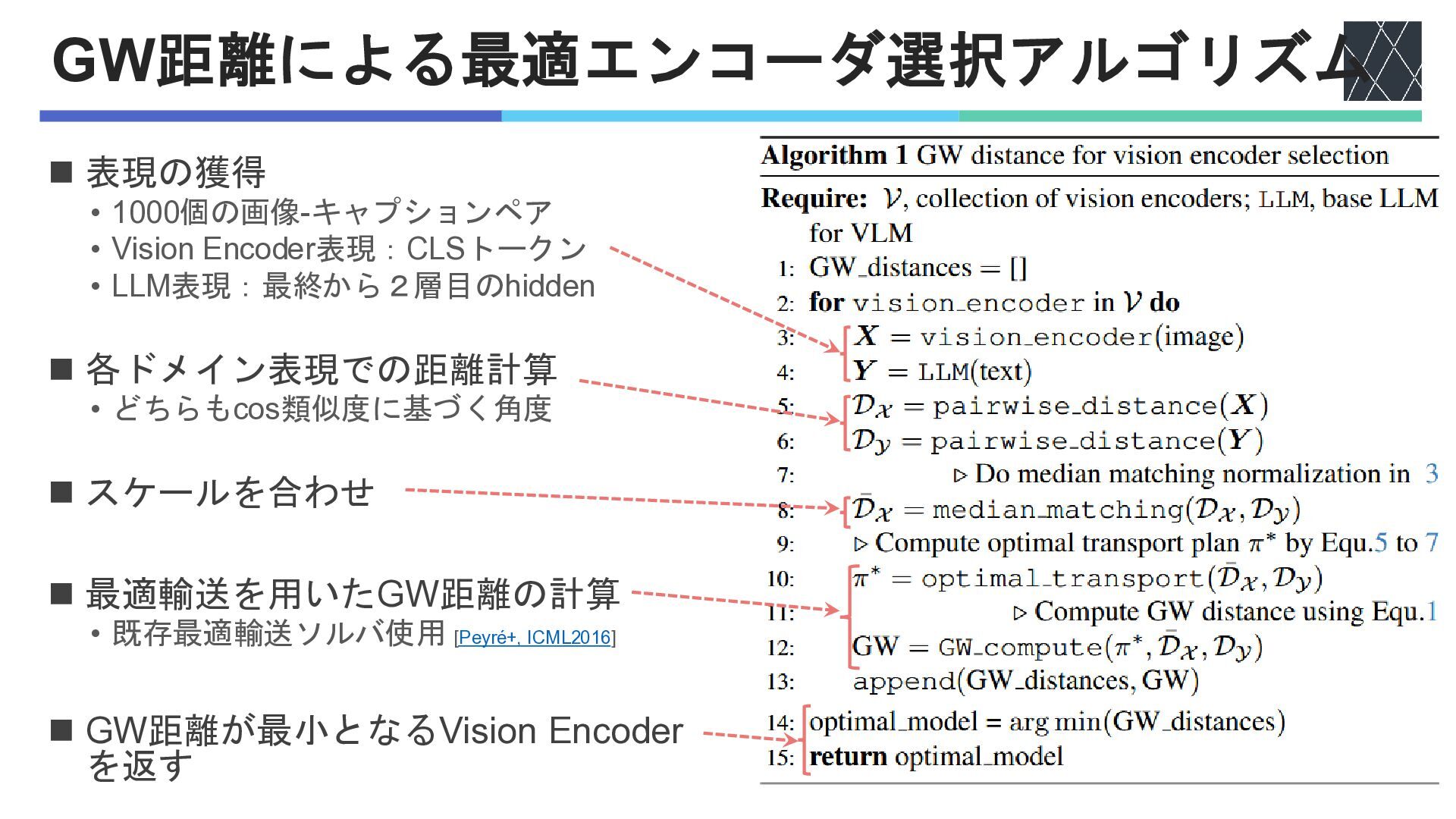
GW距離による最適エンコーダ選択アルゴリズム ◼ 表現の獲得 • 1000個の画像-キャプションペア • Vision Encoder表現:CLSトークン • LLM表現:最終から2層目のhidden
◼ 各ドメイン表現での距離計算 • どちらもcos類似度に基づく角度 ◼ スケールを合わせ ◼ 最適輸送を用いたGW距離の計算 • 既存最適輸送ソルバ使用 [Peyré+, ICML2016] ◼ GW距離が最小となるVision Encoder を返す
実験結果 ◼GW距離はエンコーダプールから最適なエンコーダを選べるか • 既存のエンコーダ選択指標と比較 • RSA [Kriegeskorte+, Neurosci2008], • CCA
[Morcos+, NeurIPS2018], • MutualNN [Huh+, ICML2024] • 選択されたエンコーダを用いた複数ベンチマーク評価 の平均値 • 正しい選択なら値がOptimalと同じになる ◼結果 • 異なるLLM・プールにおいて最適なエンコーダを選択 Qwen-2.5-7B-Instruct [Yang+, arXiv2024] Llama-3.1-8B-Instruct [Grattafiori+, arXiv2024] Worst = 最悪エンコーダでの性能 Optimal = 最適エンコーダでの性能 プール1 プール2 プール1 プール2
実験結果 ◼最終性能との相関は他の指標よりも高い • エンコーダのゼロショット性能 • エンコーダのパラメータ数 • RSA [Kriegeskorte+, Neurosci2008],
• CCA [Morcos+, NeurIPS2018], • MutualNN [Huh+, ICML2024] ピアソン 相関係数 スピアマン順位 相関係数 決定係数
本論文のまとめ ◼背景 • どのVision Encoderを選択するべきか明確な基準の分析不足 • MLLM全体でファインチューンするまでどのくらい性能が出るか分からない • コストが高い ◼MLLMにおけるエンコーダとLLMの「相性」を定量化した
• Gromov-Wasserstein (GW) 距離による表現空間の構造的類似度で定義 ◼他の指標よりも高い相関で性能を予測できた • これに従えば学習しなくても性能の良いMLLMが作れる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景知識:MLLMにおけるVision Encoderの重要性 ◼CLIPエンコーダの課題が指摘されている • 詳細な視覚理解能力の不足 MMVP [Shengbang+, CVPR2024] (カウント) (方向)](https://files.speakerdeck.com/presentations/a4d3bf562c0d487c9465f5cbad9ccae7/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験結果 ◼GW距離はエンコーダプールから最適なエンコーダを選べるか • 既存のエンコーダ選択指標と比較 • RSA [Kriegeskorte+, Neurosci2008], • CCA](https://files.speakerdeck.com/presentations/a4d3bf562c0d487c9465f5cbad9ccae7/slide_13.jpg){kind=link}
![実験結果 ◼最終性能との相関は他の指標よりも高い • エンコーダのゼロショット性能 • エンコーダのパラメータ数 • RSA [Kriegeskorte+, Neurosci2008],](https://files.speakerdeck.com/presentations/a4d3bf562c0d487c9465f5cbad9ccae7/slide_14.jpg){kind=link}
{kind=link}