You Need”, NeurIPS, 2024. - Brown et al., “Language models are few-shot learners”, NeurIPS, 2020 - Wenzek et al., “Extracting high quality monolingual datasets from web crawl data”, LREC, 2020 - Zhang et al., “Tinyllama: An open-source small language model”, arXiv preprint, 2024 - Jiang et al, “Mistral 7B”, arXiv preprint, 2023 参考⽂献
{kind=link}
{kind=link}
{kind=link}
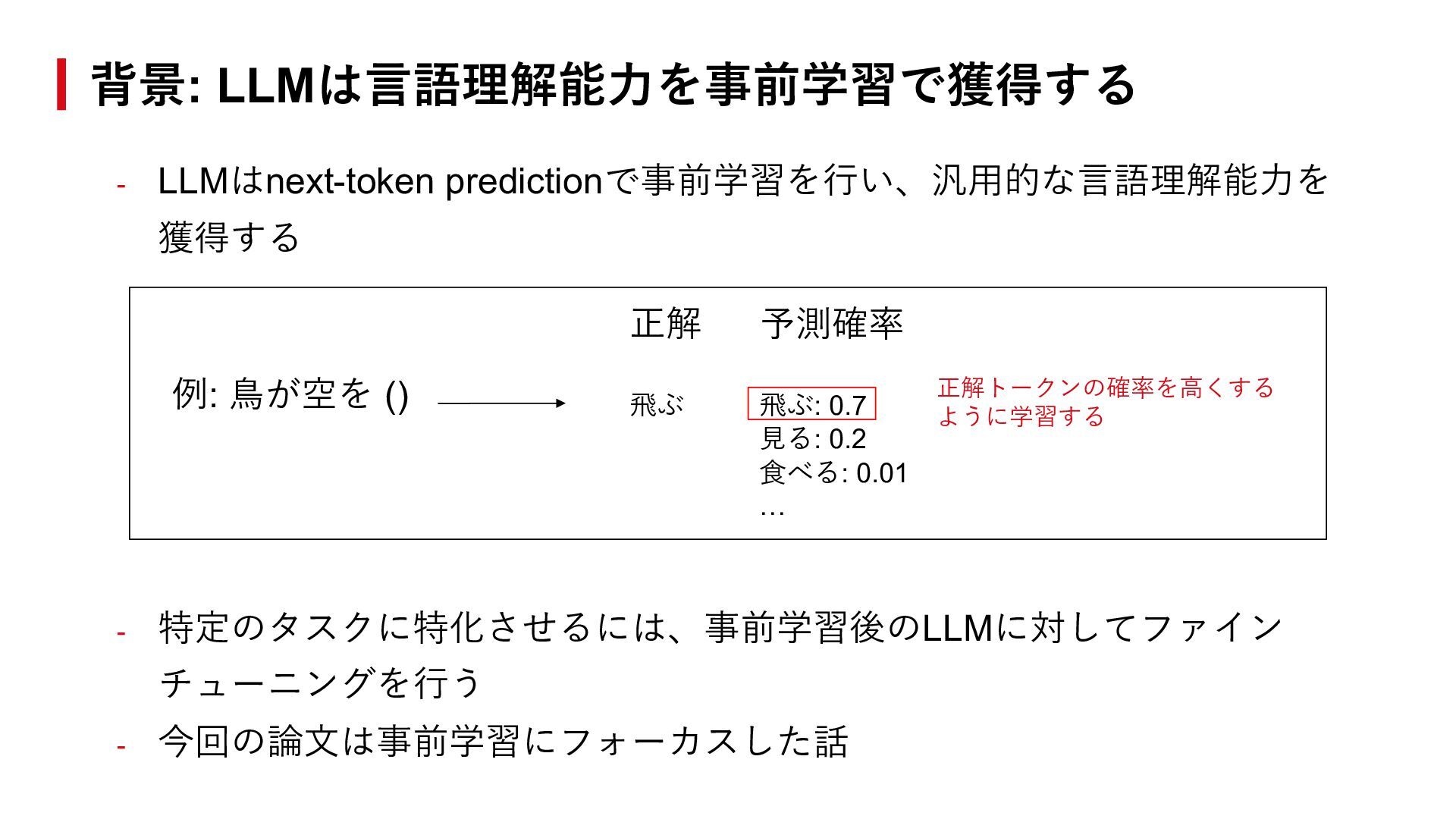{kind=link}
{kind=link}
{kind=link}
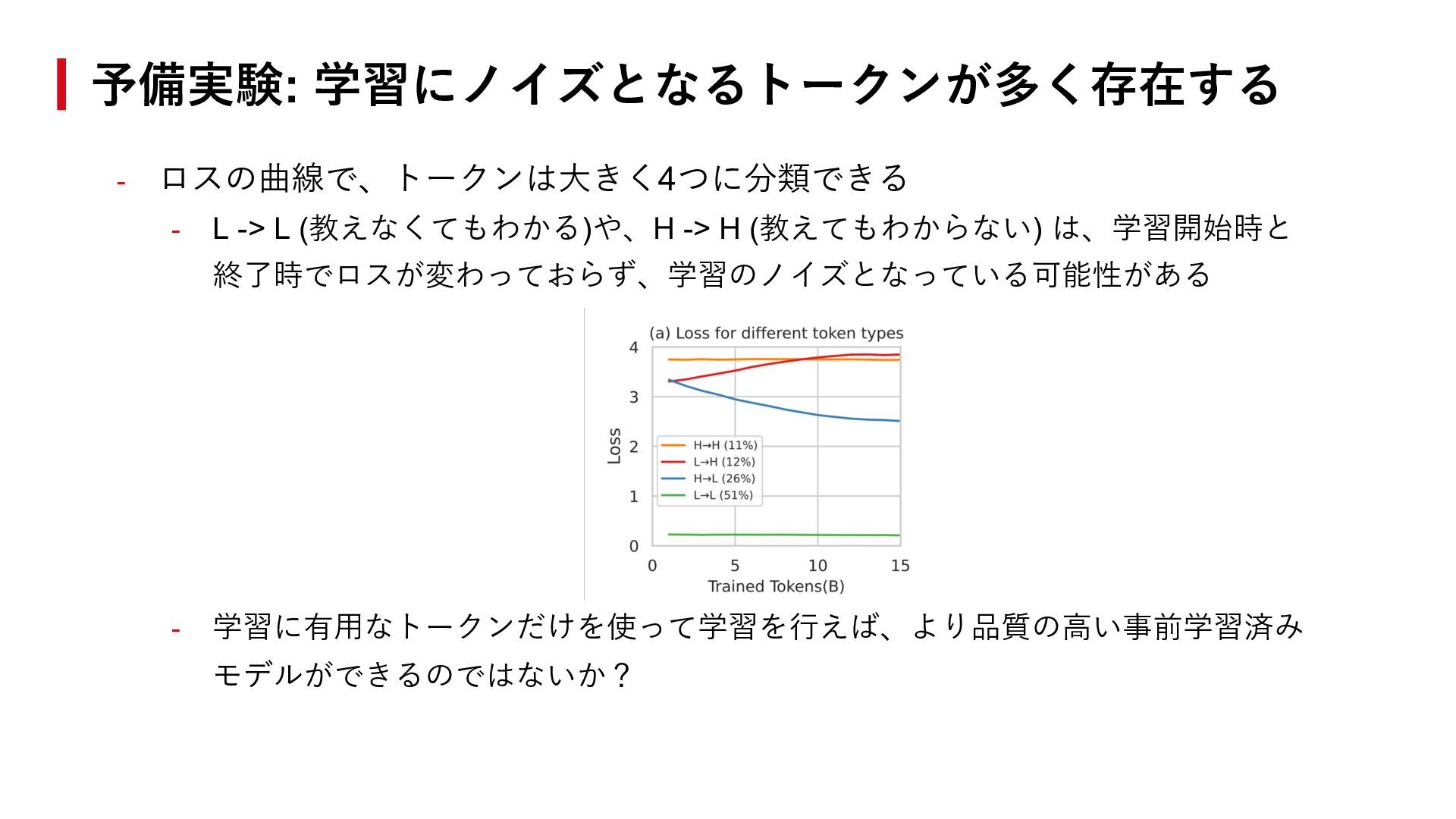{kind=link}
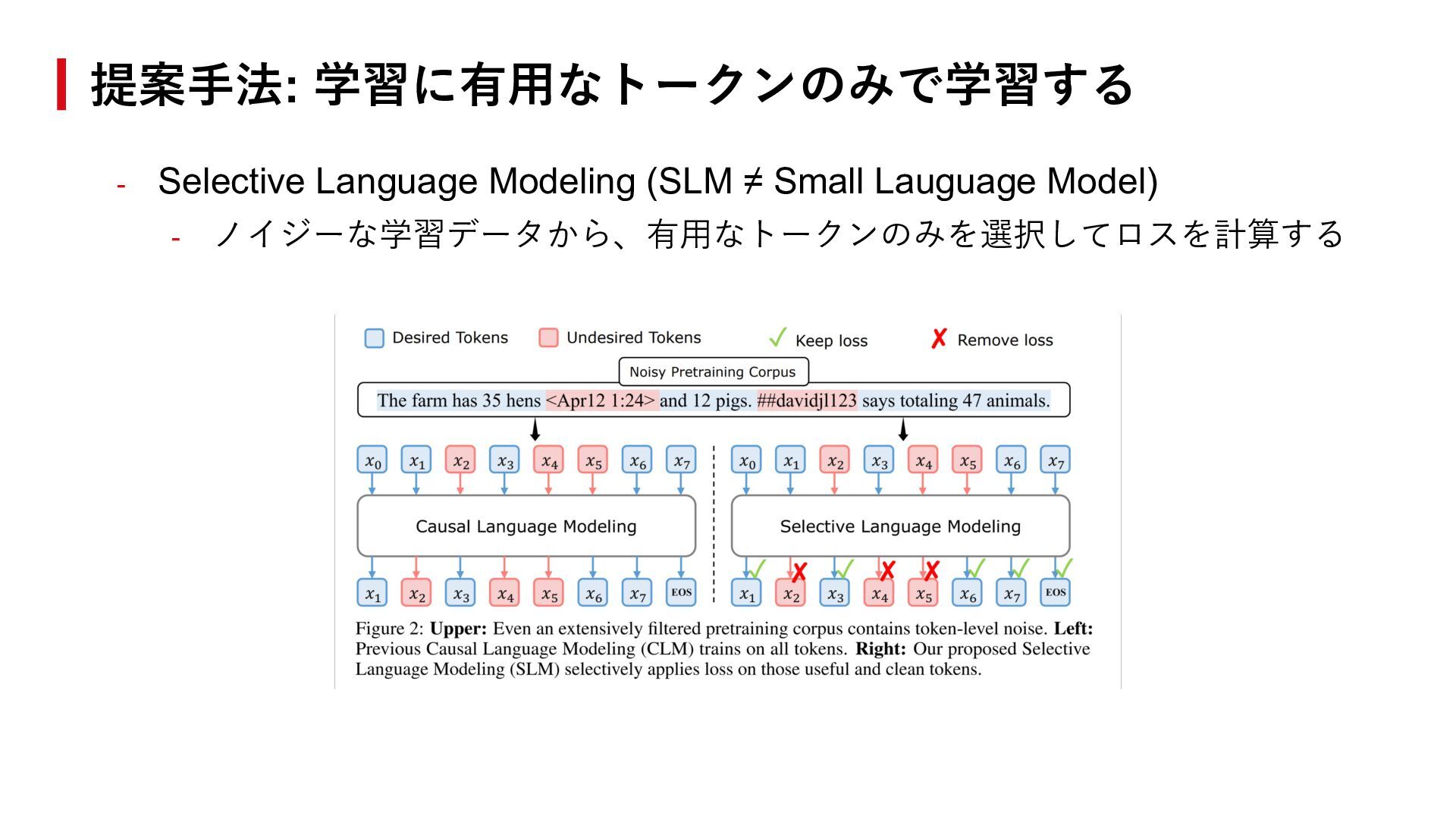{kind=link}
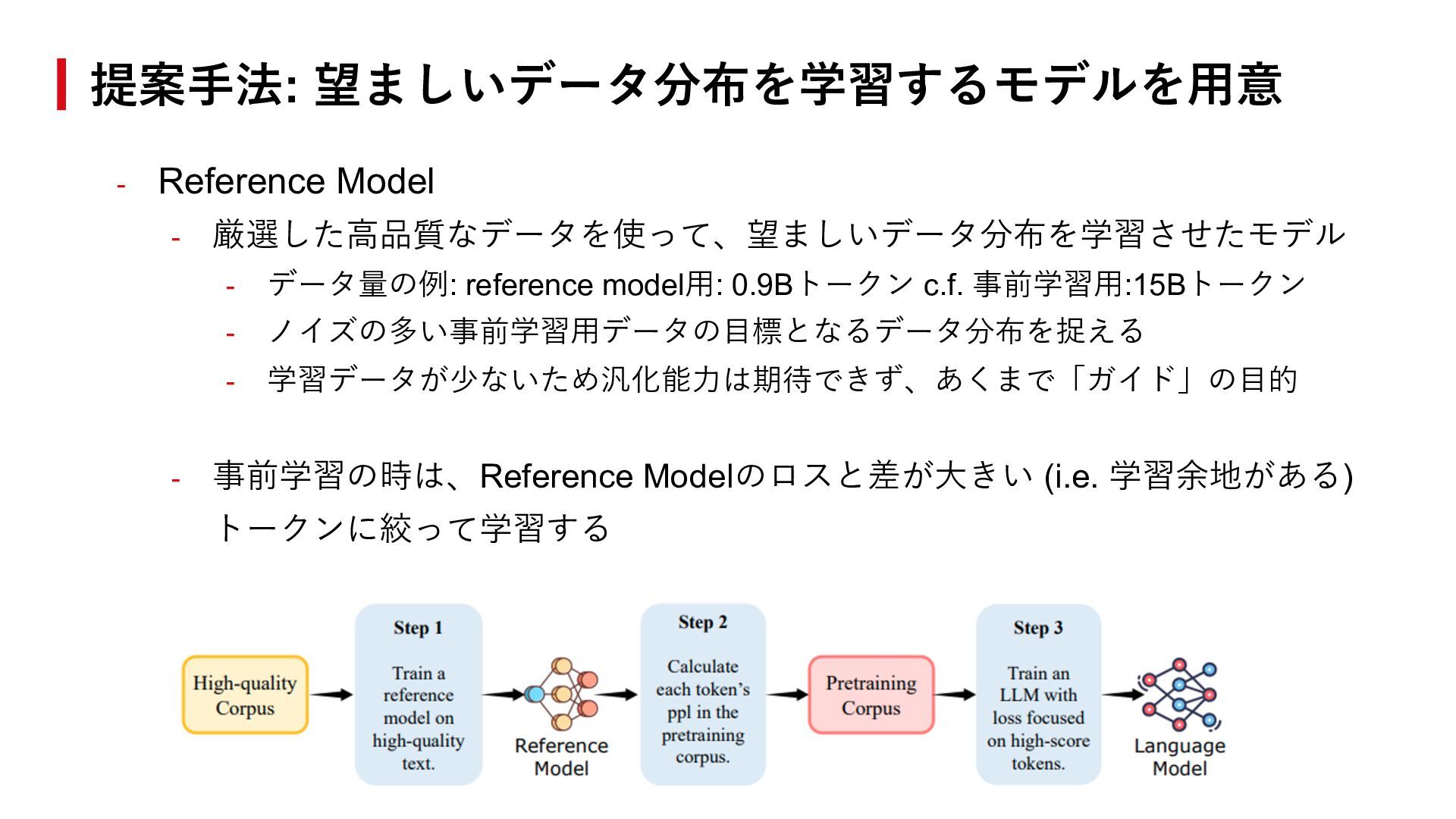{kind=link}
{kind=link}
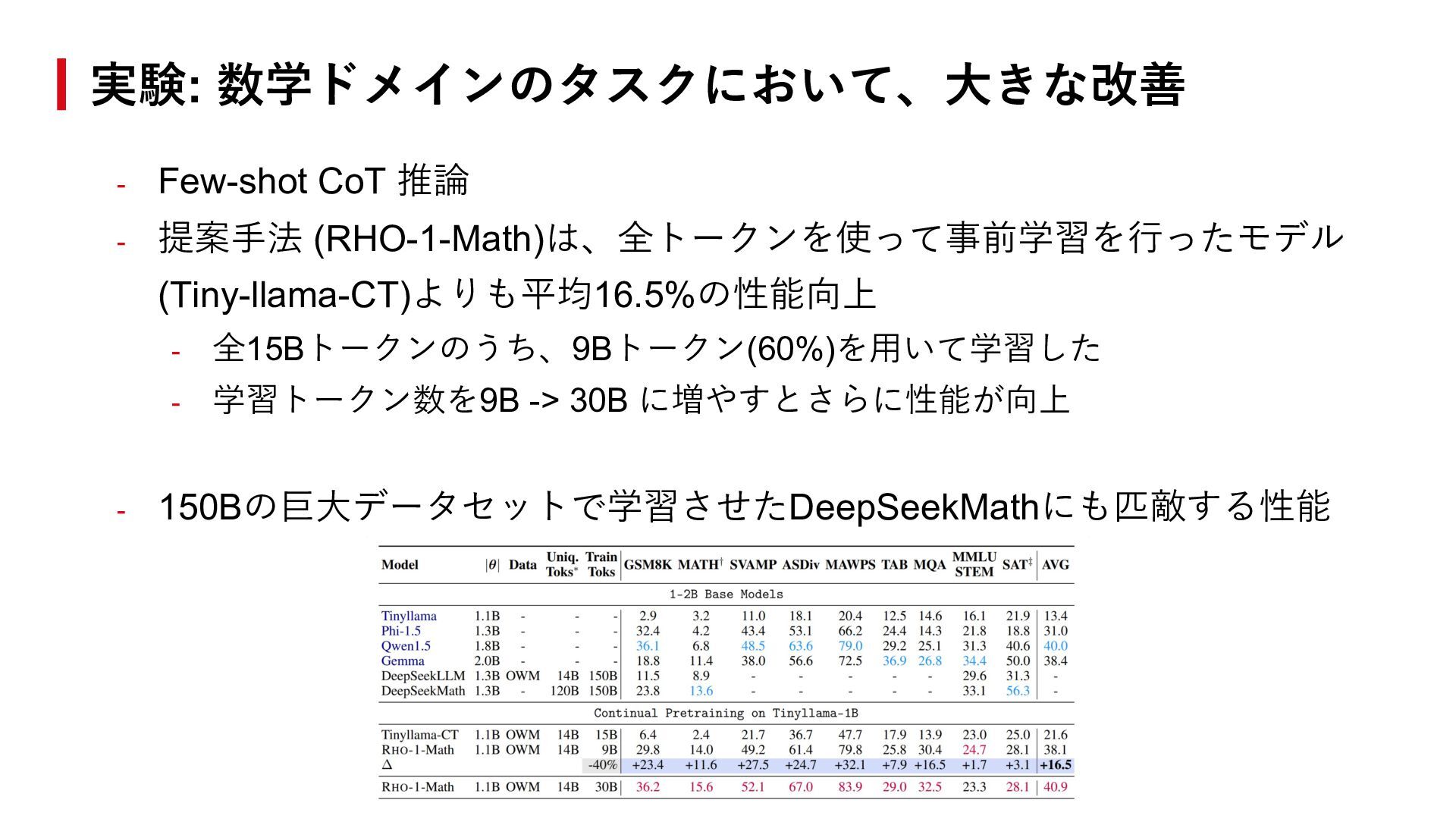
![- モデル - Tiny-llama-1B [Zhang et al., 2024]、トークン使⽤率: 60% -](https://files.speakerdeck.com/presentations/7d4813dfa4054368b90e3e0a9b2c3ab3/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}