SUMO.ai #01で利用
https://sumo-ai.connpass.com/event/356533/
Vision and Languageはコンピュータビジョン分野と自然言語処理分野の融合分野です。
深層学習、特にTransformerベースのアーキテクチャの確立によって、マルチモーダルな生成AIの主流の一つとして現在まで非常に多くの研究が進められています。更に昨今では、Vision-Language-Actionモデルを中心としたEmbodied AIがロボットなどに搭載されたり、そうしたAIによって研究開発そのものをターゲットとしたAI for Scienceの試みが広がったりと、自律社会への端緒が開けつつある状況です。本講演では、こうしたVision and Languageの流れから最近の研究まで、講演者の研究事例を交えつつ概観しています。
{kind=link}
{kind=link}
![2011 2012 2014 電話音声認識のエラー率が 30%程度→20%以下に [Seide+, InterSpeech 2011] 大規模画像分類のエラー率が 25%程度→15%程度に](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_2.jpg){kind=link}
![2011 2012 2014 電話音声認識のエラー率が 30%程度→20%以下に [Seide+, InterSpeech 2011] 大規模画像分類のエラー率が 25%程度→15%程度に](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_3.jpg){kind=link}
![Transformer 任意の個数のベクトルを 形式で変形する技術 Encoder-Decoder [Vaswani+, NIPS 2017]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_4.jpg){kind=link}
![2013 VAE [Kingma+Welling, ICLR’14] 2014 GAN [Goodfellow+, NIPS’14] 2015 DCGAN](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_5.jpg){kind=link}
![基盤モデル ある目的関数のもと 自己教師あり学習された 巨大なモデル メリット:種々のタスクに容易に転用できる [Bommasani+, 2021]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_6.jpg){kind=link}
![基盤モデル ある目的関数のもと 自己教師あり学習された 巨大なモデル メリット:種々のタスクに容易に転用できる [Bommasani+, 2021] Vision and Language](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_7.jpg){kind=link}
{kind=link}
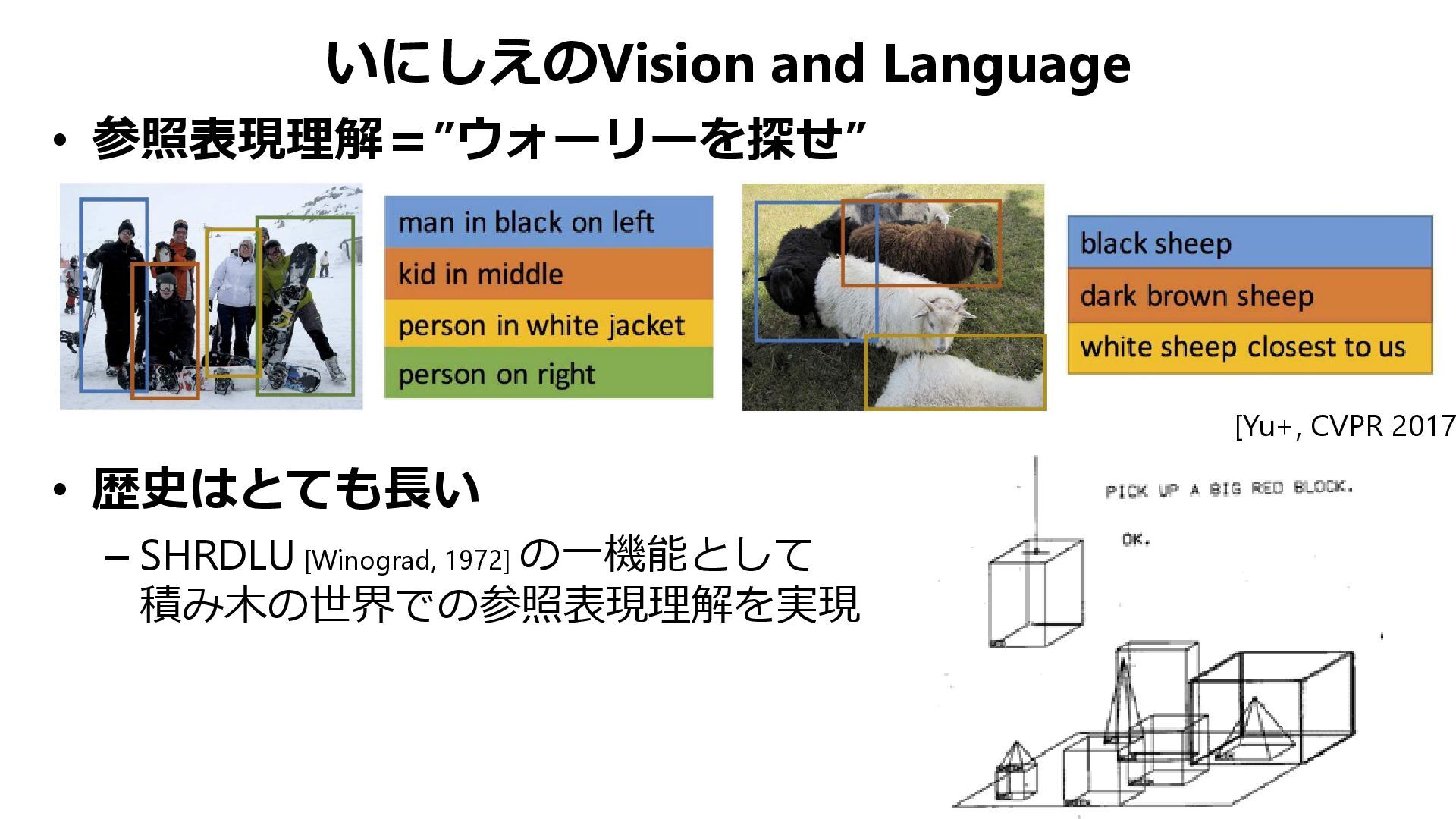{kind=link}
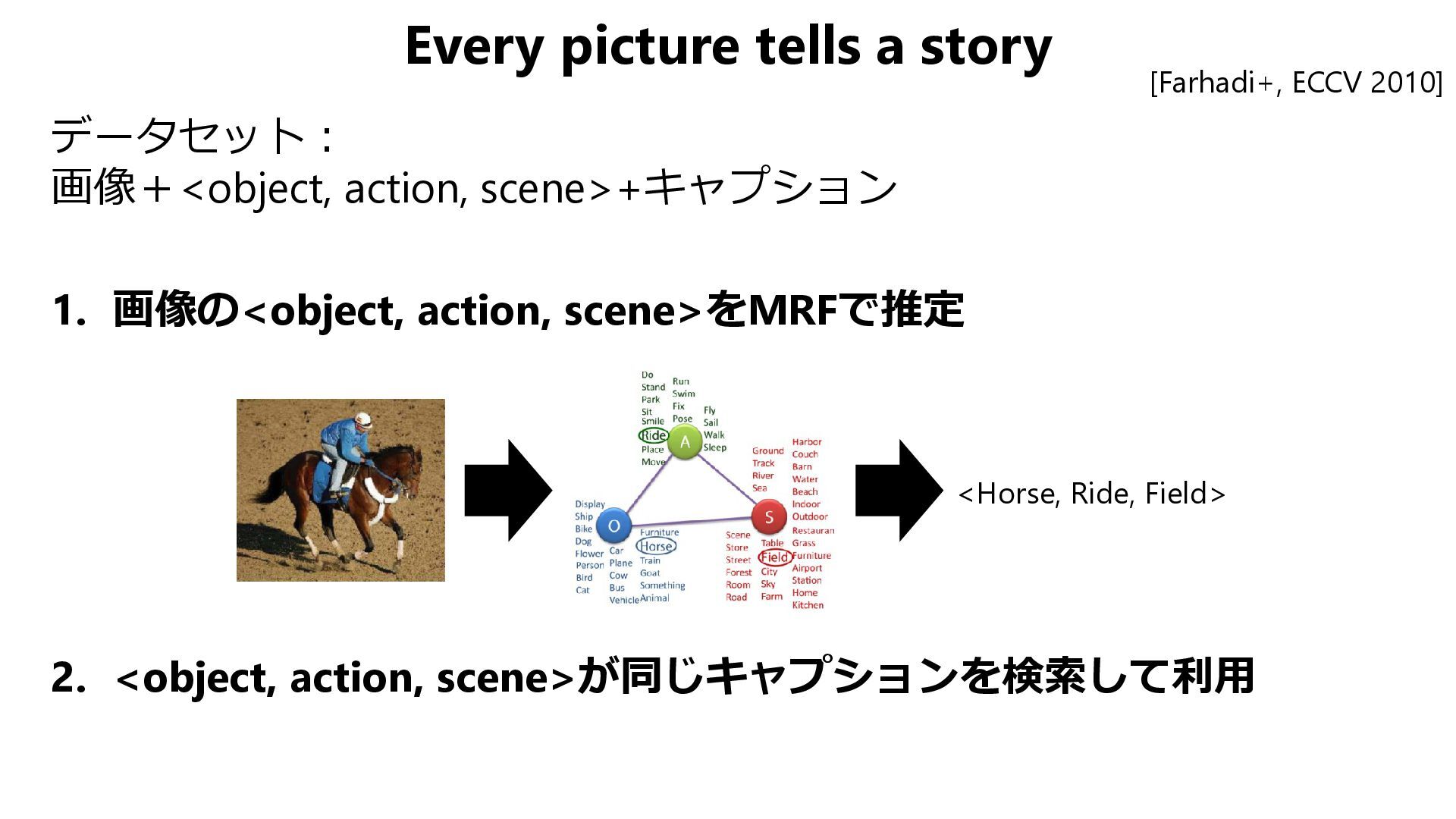{kind=link}
{kind=link}
![マルチキーフレーズ推定アプローチ 当時の問題=使用候補であるフレーズの精度が悪い キーフレーズを独立なラベルとして扱うと… マルチキーフレーズの推定=一般画像認識 文生成は[Ushiku+, ACM MM 2011]と同じ [Ushiku+, ACM](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_12.jpg){kind=link}
{kind=link}
![Visual Question Answering (VQA) 最初はユーザインタフェース分野で注目 • VizWiz [Bigham+, UIST 2010]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_14.jpg){kind=link}
![Visual Question Answering (VQA) 最初はユーザインタフェース分野で注目 • VizWiz [Bigham+, UIST 2010]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_15.jpg){kind=link}
![ビジュアル質問応答 [Fukui+, EMNLP 2016]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_16.jpg){kind=link}
![ビジュアル質問応答 [Fukui+, EMNLP 2016] ①マルチモーダル理解 入力:ビジュアルデータ+テキストデータ → 出力:認識結果](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
![キャプションからの画像生成 [Ramesh+, 2021] An illustration of a baby hedgehog in](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_20.jpg){kind=link}
![キャプションからの画像生成 [Ramesh+, 2021] An illustration of a baby hedgehog in](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_21.jpg){kind=link}
![テキストによる画像編集 [Dong+, ICCV 2017]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_22.jpg){kind=link}
![テキストによる画像編集 [Dong+, ICCV 2017] ④Image+Text2Image 入力:ビジュアルデータ+テキストデータ → 出力:テキストデータ](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![手前味噌タイム:作業記録動画像からマニュアル自動生成 [Nishimura+, MTA 2023] (a) Cut the pork in half](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![20世紀:AIで科学研究を駆動する先駆者 • DENDRAL[Feigenbaum+, 1971] – 質量スペクトルから化学構造を推定するシステム – 第2次AIブームにおけるエキスパートシステムのさきがけ • PROSPECTOR[Hart+,](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_30.jpg){kind=link}
![2000年代:実世界でのデータ取得 Adam=酵母遺伝学実験の自動化 →新規遺伝子の同定 [King+, Science 2009] 力学的カオス系の実験データを取得 →既知の法則(保存則)を再発見 [Schmidtz+Lipson, Science](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_31.jpg){kind=link}
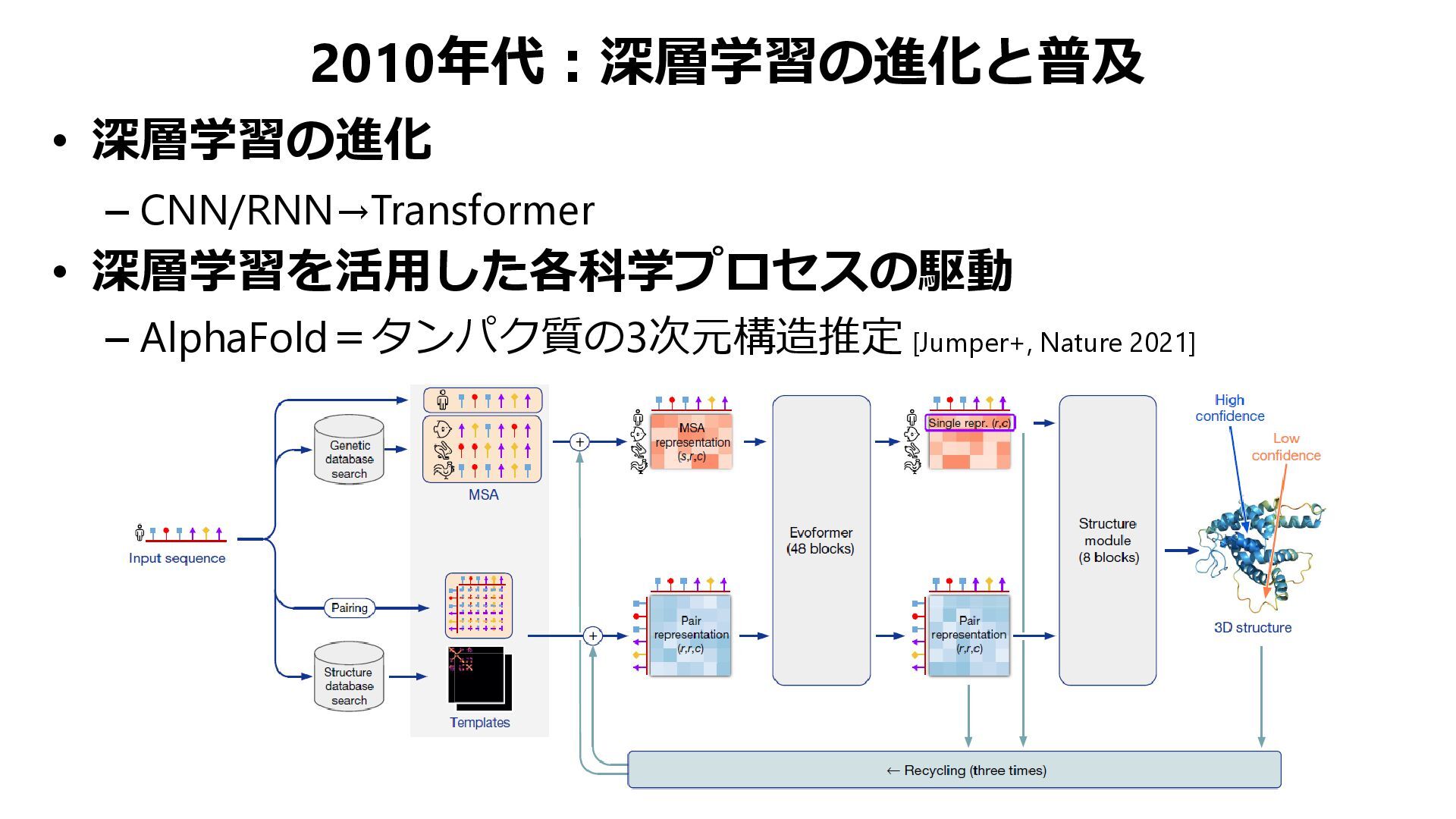{kind=link}
![2020年代:サイバーフィジカルでのエージェントの進化 Mobile robot chemistが光触媒の 活性を自律的に改善 [Burger+, Nature 2020] LabDroid「まほろ」が再生医療用の 細胞レシピを自律的に改善](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_33.jpg){kind=link}
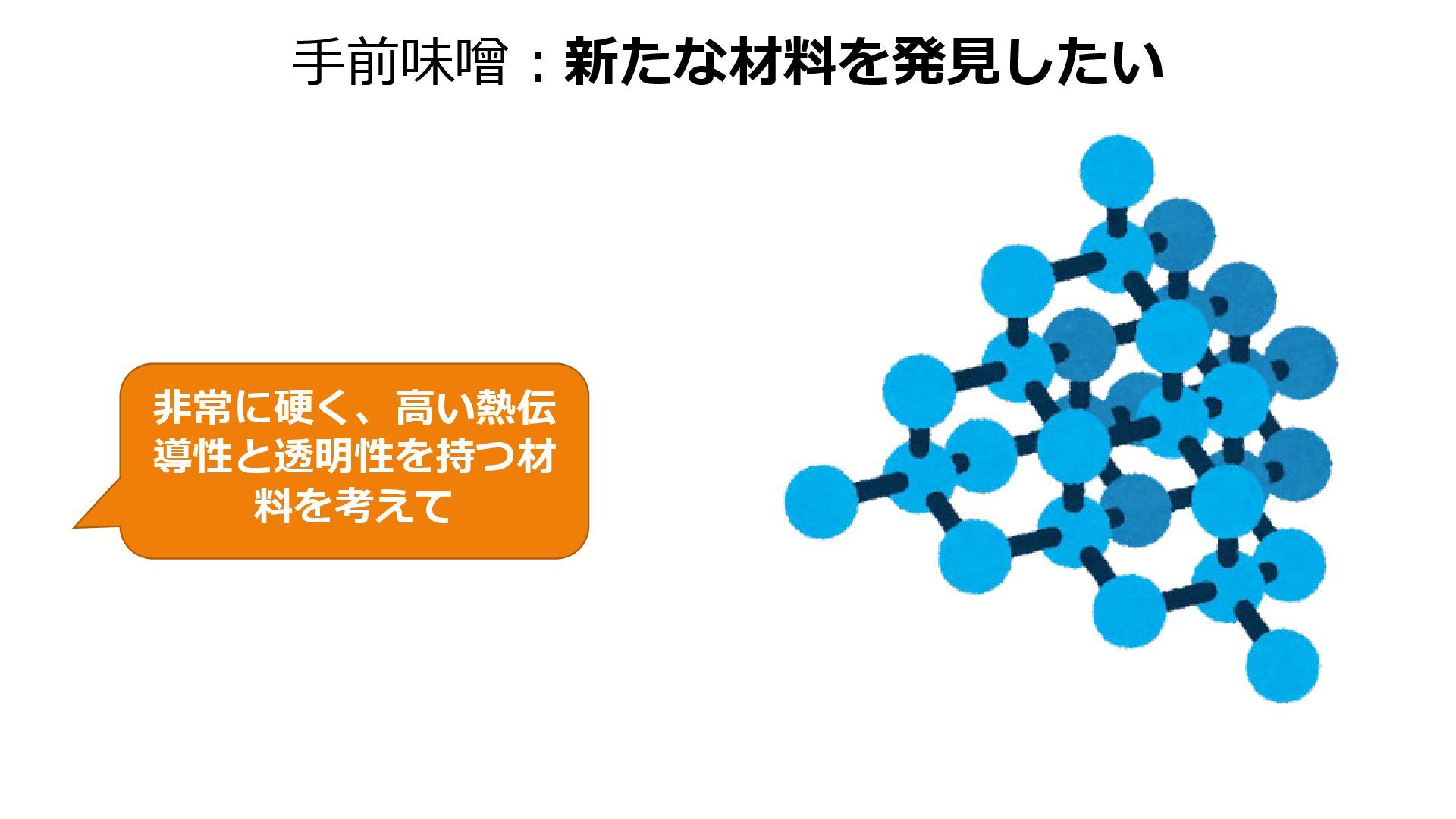{kind=link}
![新材料発見=検索/生成 新規結晶の生成 [Chiba+, Comm. Mat. 2023] 検索による再発見 [Suzuki+, MLST 2022]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_35.jpg){kind=link}
![新材料の物性を予測するには ここでは材料=結晶構造 例: 転移学習による超高格子熱伝導材料の熱伝導率 推定[Ju+, Phys. Rev. Materials’21] • 手動特徴量設計+機械学習](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_36.jpg){kind=link}
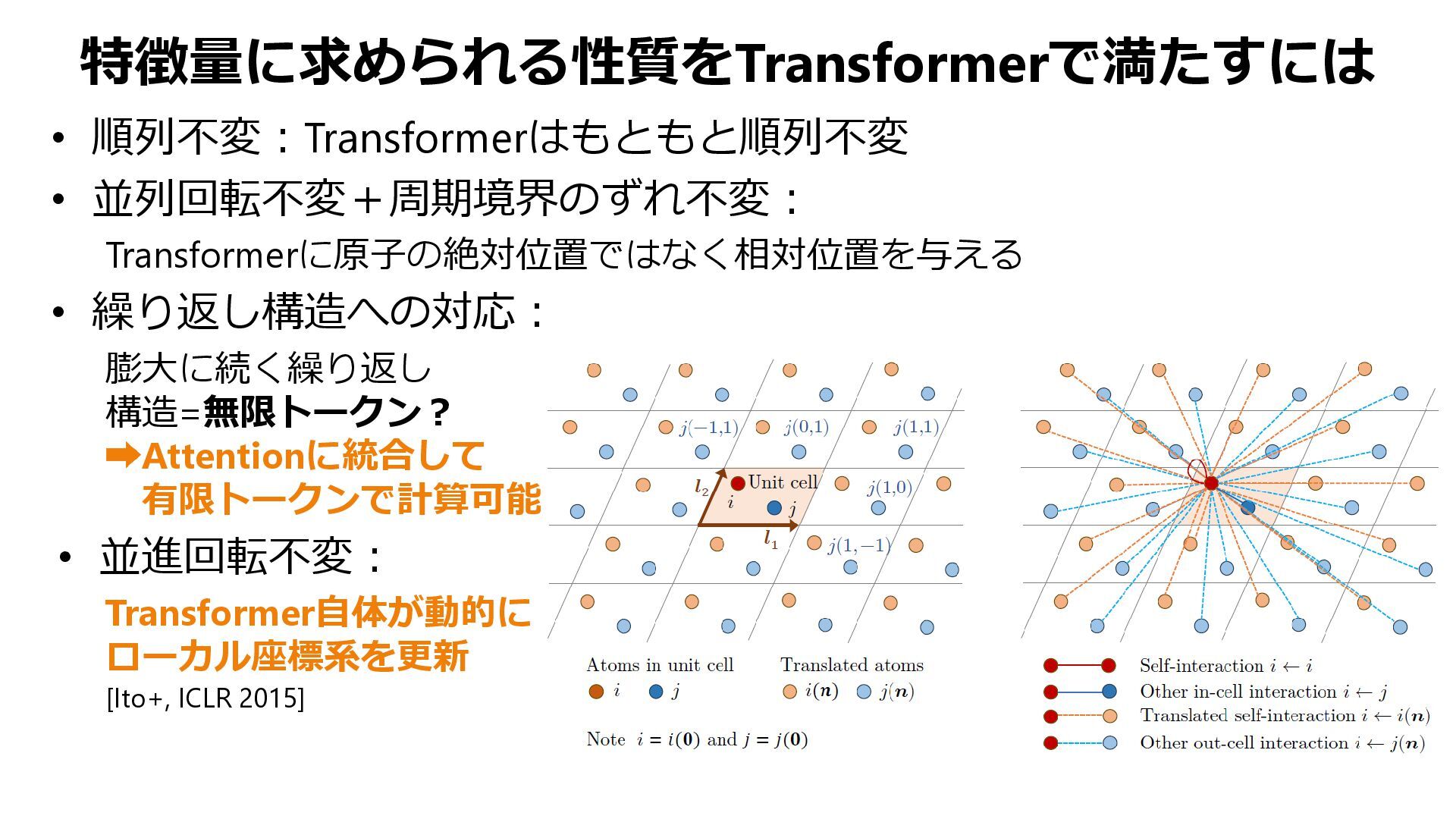{kind=link}
{kind=link}
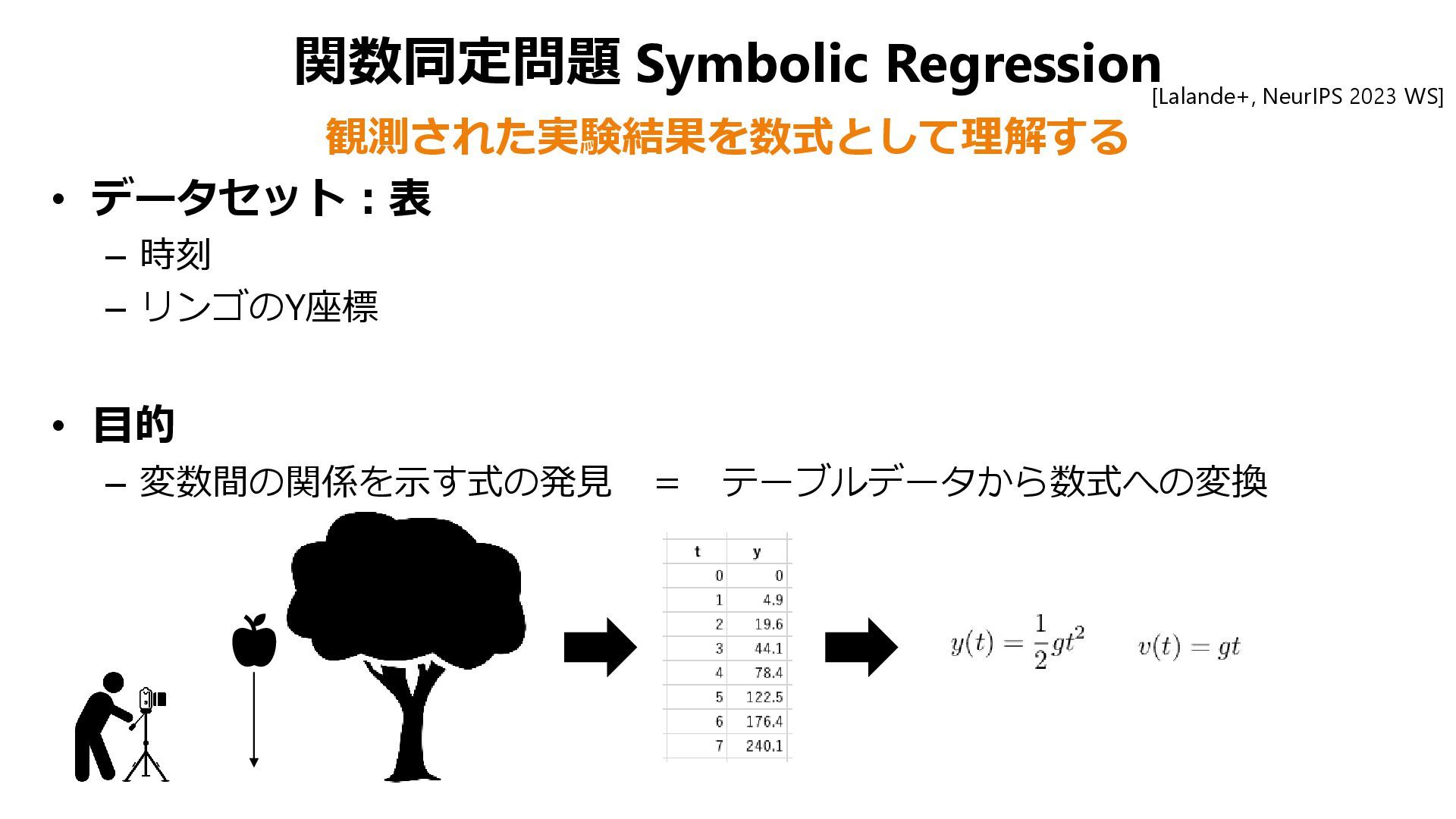{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Kadokawa+, IROS 2023]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_43.jpg){kind=link}
![44 [Nakajima+, IROS 2023]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_44.jpg){kind=link}
![[Yotsumoto+, Digital Discovery 2024][Nakajima+, Digital Discovery 2024]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_45.jpg){kind=link}
{kind=link}
![Physical Intelligence/Embodied AIの時代 [Black+, 2024]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_47.jpg){kind=link}
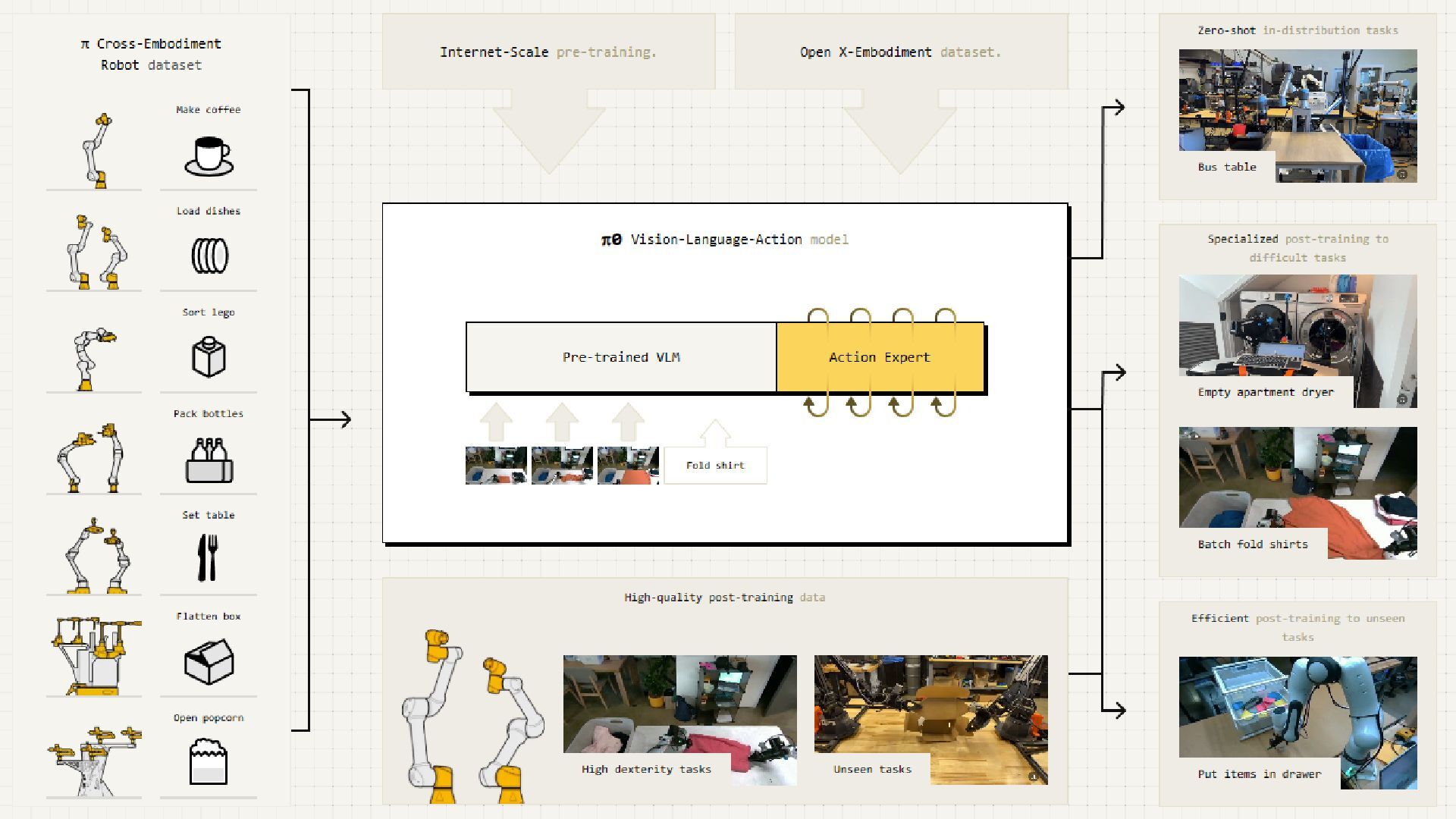{kind=link}
![Vision-and-Language Navigation (VNL) 対話行為が移動とナビゲーション [Anderson+, ICCV 2017]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_49.jpg){kind=link}
![EmbodiedQA 質問応答のために探索が必要な問題 著者自らがその後、階層的な方策を獲得するA3Cベースの強化学習を提 案 [Das+, CoRL 2018] [Das+, CVPR 2018]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_50.jpg){kind=link}
![基盤モデルとの接続(SayCan) [Ahn+, 2022]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_51.jpg){kind=link}
![データセットのコモディティ化 [Open X-Embodiment Collaboration, 2023]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_52.jpg){kind=link}
{kind=link}
![[Shirai+, ICRA 2024]](https://files.speakerdeck.com/presentations/4e39e4ad86674ae19fb73e33112598b9/slide_54.jpg){kind=link}
{kind=link}
{kind=link}