Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MIRU2025 チュートリアル講演「ロボット基盤モデルの最前線」
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kento Kawaharazuka
July 28, 2025
Research
13k
15
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MIRU2025 チュートリアル講演「ロボット基盤モデルの最前線」
Kento Kawaharazuka
July 28, 2025
More Decks by Kento Kawaharazuka
See All by Kento Kawaharazuka
RSJ2025「オープンハードウェアと学習制御」チュートリアル2025(河原塚)
haraduka
3
780
RSJ2025「基盤モデルの実ロボット応用」チュートリアル2025-1(河原塚)
haraduka
2
1.5k
Data-centric AI勉強会 「ロボットにおけるData-centric AI」
haraduka
1
1.2k
RSJ2024学術ランチョンセミナー「若手・中堅による国際化リーダーシップに向けて」資料 (河原塚)
haraduka
0
680
RSJ2024「基盤モデルの実ロボット応用」チュートリアルA(河原塚)
haraduka
3
1.6k
RSJ2023「基盤モデルの実ロボット応用」チュートリアル1(既存の基盤モデルを実ロボットに応用する方法)
haraduka
5
2.8k
Other Decks in Research
See All in Research
量子コンピュータの紹介
oqtopus
0
360
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.3k
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
250
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
NLP colloquium: AI Safety Survey
kanekomasahiro
0
840
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
正規分布と最適化について
koide3
1
300
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
AIで最適化を解けるか?
mickey_kubo
0
140
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
180
Featured
See All Featured
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
First, design no harm
axbom
PRO
2
1.2k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
My Coaching Mixtape
mlcsv
0
170
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Claude Code のすすめ
schroneko
67
230k
Transcript
1 ロボット基盤モデル研究の最前線 河原塚 健人 東京大学 1 2025.7.29 (13:10-14:40) MIRU2025 チュートリアル講演
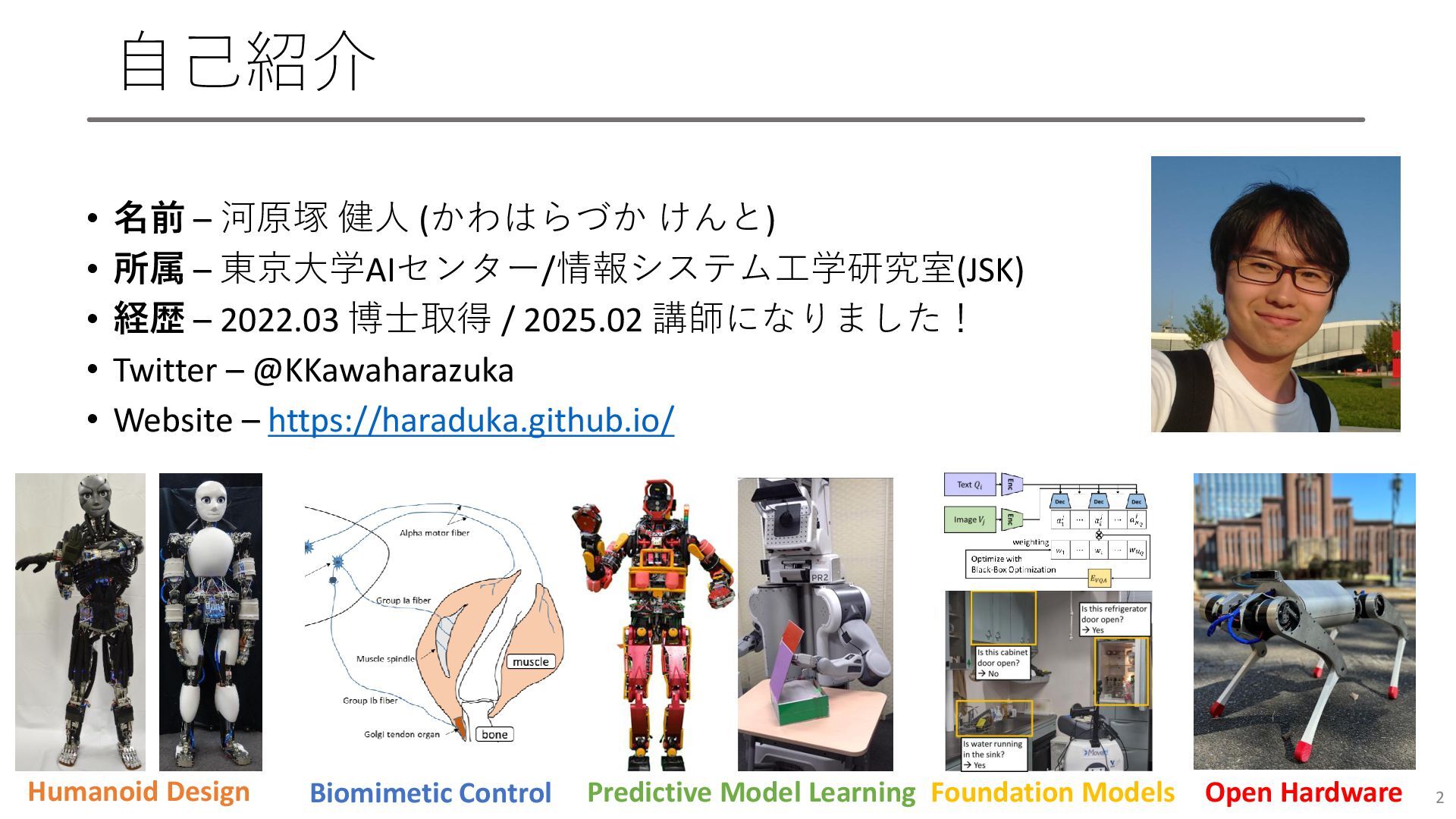
自己紹介 • 名前 – 河原塚 健人 (かわはらづか けんと) • 所属
– 東京大学AIセンター/情報システム工学研究室(JSK) • 経歴 – 2022.03 博士取得 / 2025.02 講師になりました! • Twitter – @KKawaharazuka • Website – https://haraduka.github.io/ 2 Humanoid Design Biomimetic Control Foundation Models Predictive Model Learning Open Hardware
3 Kengoro [Y. Asano+, Humanoids2016] [K. Kozuki+, IROS2016]
4 Kengoro [Y. Asano+, IROS2016] [T. Makabe, K. Kawaharazuka+, Humanoids2018]
[S. Makino, K. Kawaharazuka+, IROS2018] [K. Kawaharazuka+, IROS2017]
5 Musashi [K. Kawaharazuka+, RA-Magazine/ICRA2021]
6 CubiXGo1 [S. Inoue, K. Kawaharazuka+, Advanced Robotics Research, 2025]
7 MEVIUS
なぜ基盤モデルの世界へ? • 2022.07.06 – JSAI2022で話した縁で, 松尾研にお邪魔しCLIPの話を聞く • 2022.08.15 – 頭の片隅にあったCLIPやVQAが可能なモデルの面白さに気付き,
学生とご飯を食べながらブレスト • 2022.09.15 – ICRA2023に, ロボットのための言語による状態認識に関する研究 を2本投稿 • 2022.10.17 – ロボティクスシンポジア2023に料理/パトロール/ナビゲーション の観点から3本の論文を投稿 • 2023.02.20 – 日本ロボット学会でオーガナイズドセッションを企画 • 2023.03.18 – 認知ロボティクス作戦会議で特集号の話が持ち上がる 8 …
これまでの活動 • OS「基盤モデルの実ロボット応用」@日本ロボット学会2023-2025 • 特集号「Real-World Robot Applications of Foundation Models」
@国際論文誌Advanced Robotics 9 RSJ2025は9/2-5 @東京科学大!
Survey Paperを執筆しました! 10
さらに異分野へ 11 NLP2024併設ワークショップ: 大規模言語モデルの実世界応用 MIRU2025チュートリアル ロボット基盤モデルの最前線
基盤モデル×ロボットの二種類の方向性 12 LLMやVLMの活用 ロボット基盤モデル(VLA) SayCan [M. Ahn+, CoRL2022] RT-X [Open
X-Embodiment, ICRA2024]
以下を参照してください 13 チュートリアル1 @日本ロボット学会2023 IEICE先端セミナー 「生成AIの応用」 PRMU研究会 でも招待講演 しました
ですが今回は… 14 LLMやVLMの活用 ロボット基盤モデル(VLA) SayCan [M. Ahn+, CoRL2022] RT-X [Open
X-Embodiment, ICRA2024]
ロボット基盤モデルは何ができているのか 15 RT-1 [Google Research, 2022] https://www.youtube.com/watch?v=UuKAp9a6wMs
ロボット基盤モデルは何ができているのか 16 AutoRT [Google DeepMind, 2024] https://auto-rt.github.io/
ロボット基盤モデルは何ができているのか 17 [Physical Intelligence (π), 2024] https://www.physicalintelligence.company/blog/pi0
ロボット基盤モデルは何ができているのか 18 GR00T N1 [NVIDIA, 2025] https://www.youtube.com/watch?v=m1CH-mgpdYg
ロボット基盤モデルは何ができているのか 19 Helix [Figure, 2025] https://www.figure.ai/news/helix
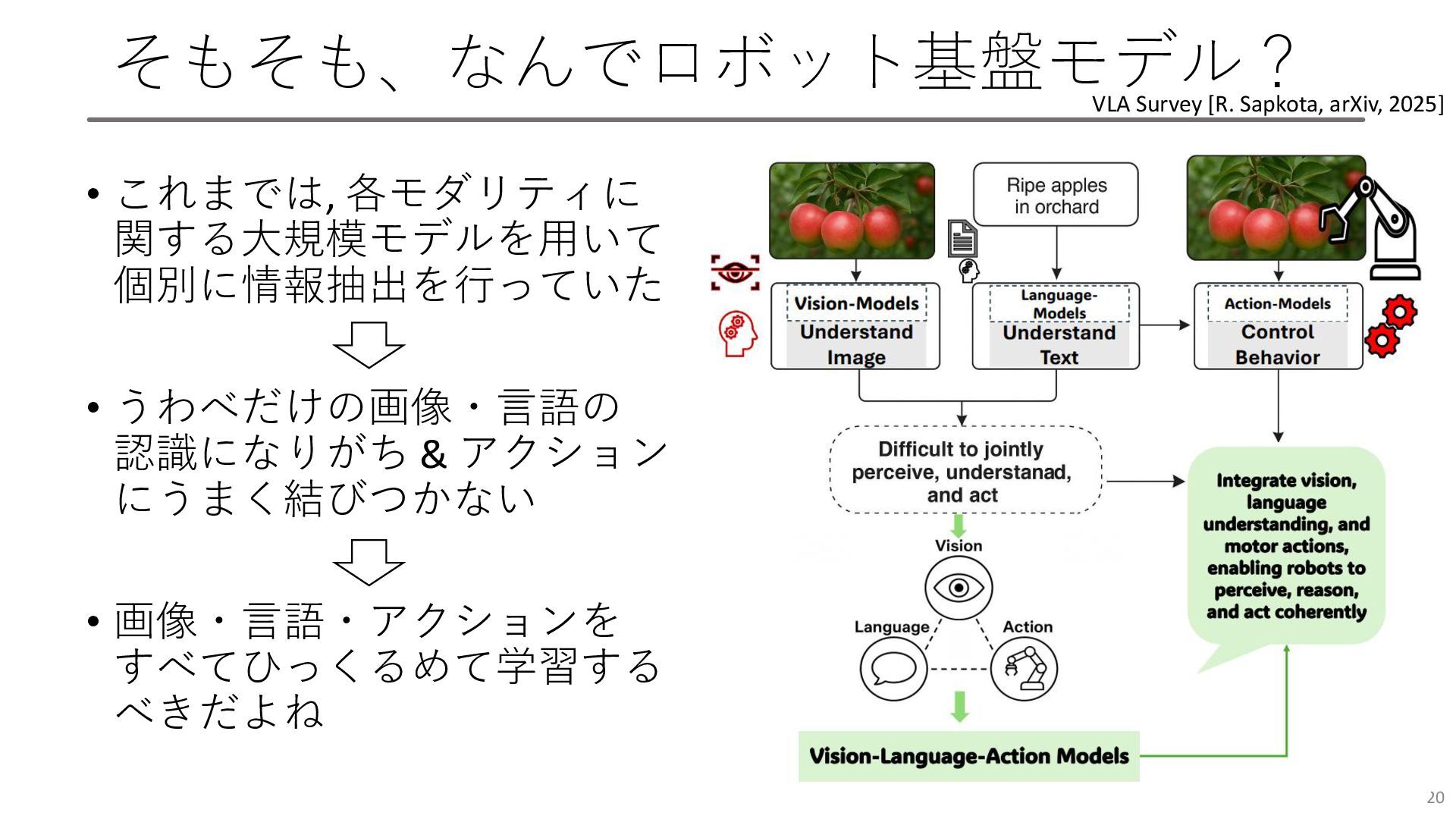
そもそも、なんでロボット基盤モデル? • これまでは, 各モダリティに 関する大規模モデルを用いて 個別に情報抽出を行っていた • うわべだけの画像・言語の 認識になりがち &
アクション にうまく結びつかない • 画像・言語・アクションを すべてひっくるめて学習する べきだよね 20 VLA Survey [R. Sapkota, arXiv, 2025]
そもそも、なんでロボット基盤モデル? 21 SayCan [M. Ahn+, CoRL2022] https://say-can.github.io/
そもそも、なんでロボット基盤モデル? • もし汎用的なロボット基盤モデル(VLA)ができたら • カスタムデータセットを最小化, またはゼロへ • ロボット導入の障壁をゼロへ 22
日本のプレゼンスは? • めっちゃ低いです(ど真ん中の論文はほぼ0) • 基盤モデルのロボット応用はまだ良かった • ロボット基盤モデル(VLA)はGoogleやNVIDIAみたいな 体力のある企業とその周辺が牛耳っている • (私も含め,
みな素人です) • なので, ぜひ追いつきましょう! 23
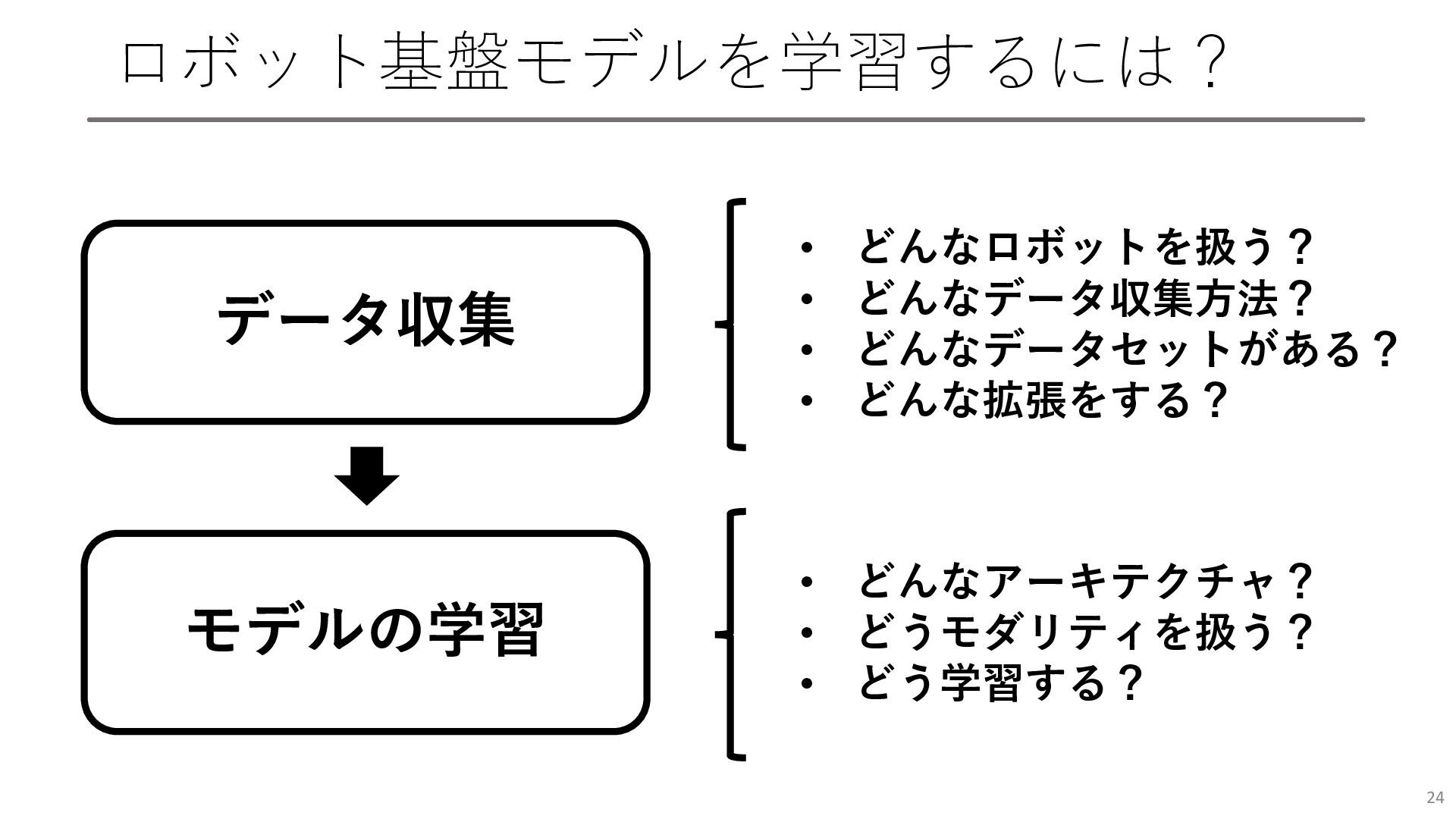
ロボット基盤モデルを学習するには? 24 データ収集 モデルの学習 • どんなロボットを扱う? • どんなデータ収集方法? • どんなデータセットがある?
• どんな拡張をする? • どんなアーキテクチャ? • どうモダリティを扱う? • どう学習する?
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 25
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 26
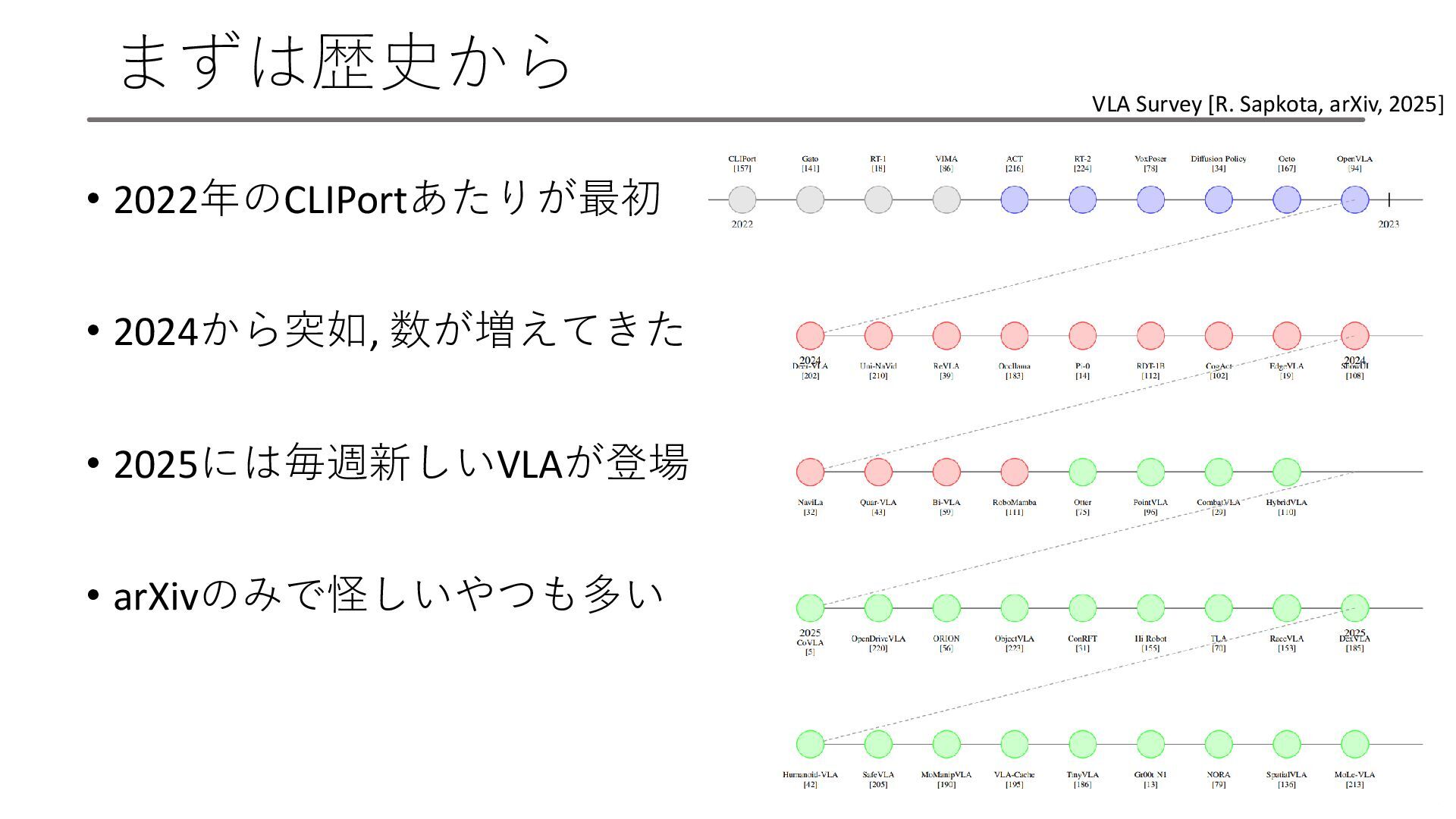
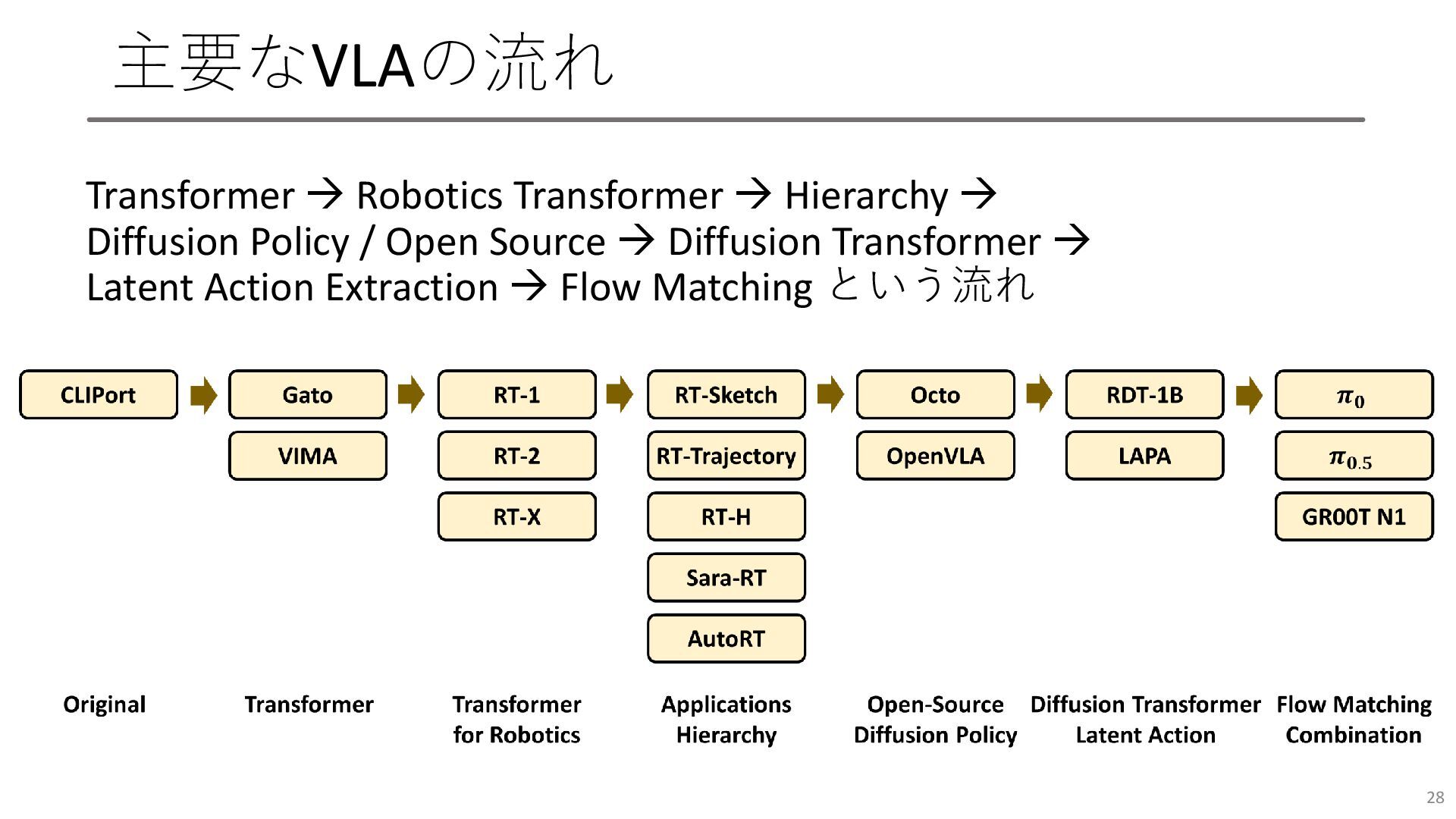
まずは歴史から • 2022年のCLIPortあたりが最初 • 2024から突如, 数が増えてきた • 2025には毎週新しいVLAが登場 • arXivのみで怪しいやつも多い
27 VLA Survey [R. Sapkota, arXiv, 2025]
主要なVLAの流れ Transformer Robotics Transformer Hierarchy Diffusion Policy
/ Open Source Diffusion Transformer Latent Action Extraction Flow Matching という流れ 28
CLIPort 29 [M. Shridhar, CoRL2021] • End-to-EndなVLAとしては最も原始的なモデル • CLIPによる言語情報と視覚情報の抽出 •
Pick and Placeに特化したTransporter Networkとの結合 • RGB-D画像と言語情報からどの物体をどこに置くべきかを生成 • CNN/MLP構成では多様なモダリティの扱い/スケーラビリティに限界
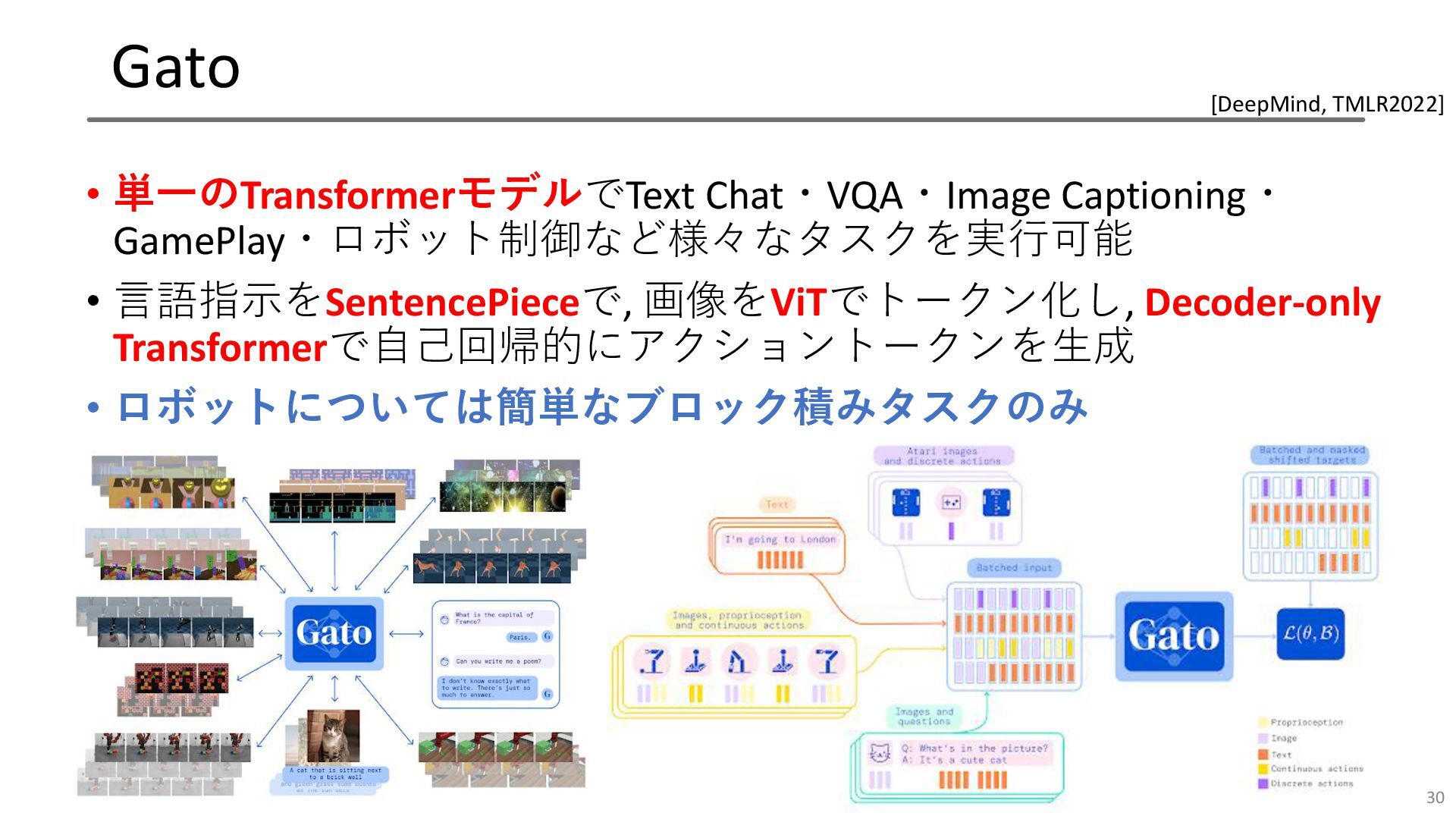
Gato • 単一のTransformerモデルでText Chat・VQA・Image Captioning・ GamePlay・ロボット制御など様々なタスクを実行可能 • 言語指示をSentencePieceで, 画像をViTでトークン化し, Decoder-only
Transformerで自己回帰的にアクショントークンを生成 • ロボットについては簡単なブロック積みタスクのみ 30 [DeepMind, TMLR2022]
VIMA 31 [Y. Jiang+, ICML2023] • ゴール画像やテキストを含む多様なタスク指示が可能な Encoder-Decoder型のTransformer • Mask
R-CNNで物体検出, 各物体画像をViTで, 言語指示はT5エンコーダ でトークン化, バウンディングボックス情報もトークン化 • 多様なロボットタスクが可能だがシミュレーションのみでの試行
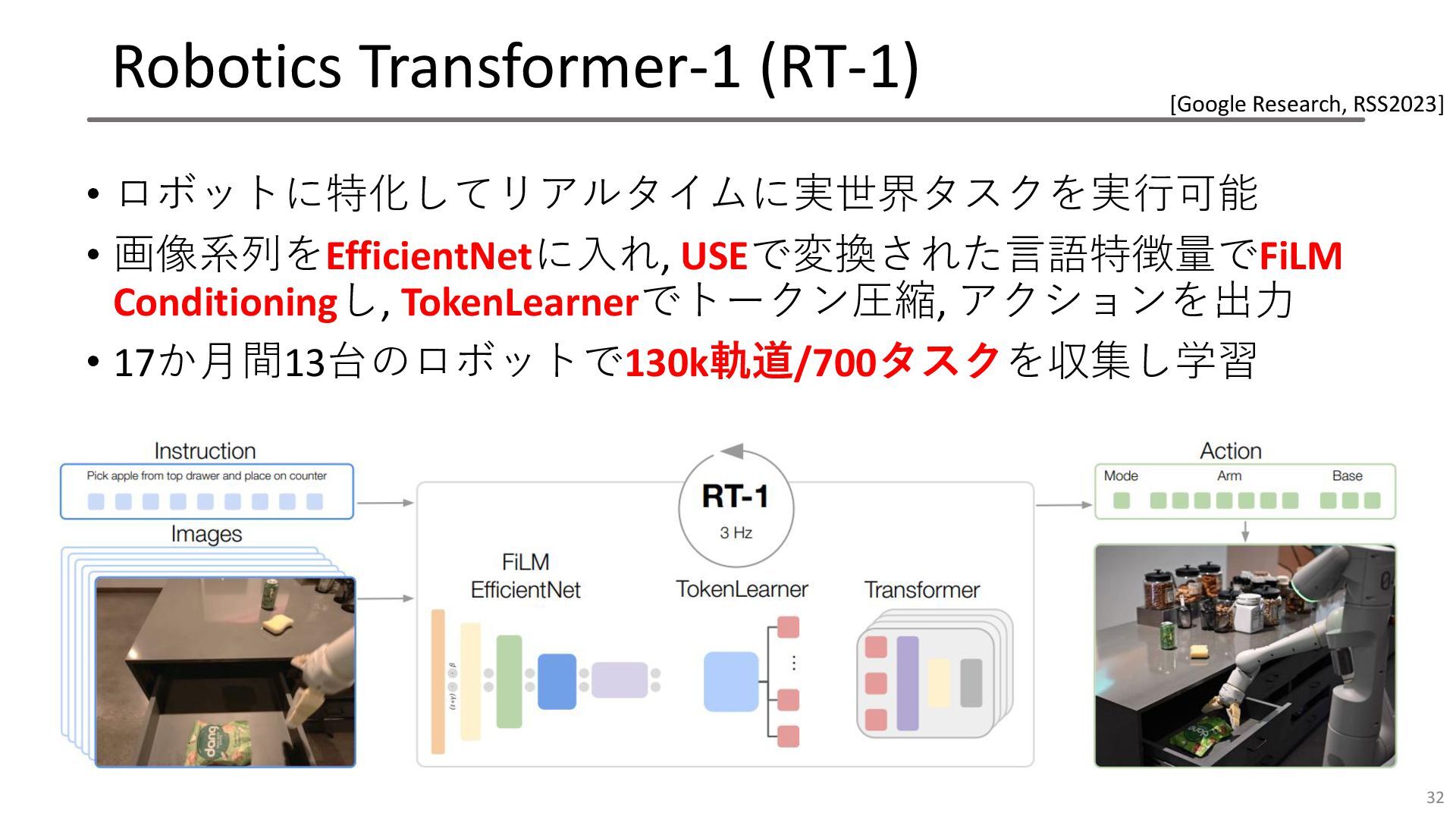
Robotics Transformer-1 (RT-1) • ロボットに特化してリアルタイムに実世界タスクを実行可能 • 画像系列をEfficientNetに入れ, USEで変換された言語特徴量でFiLM Conditioningし, TokenLearnerでトークン圧縮,
アクションを出力 • 17か月間13台のロボットで130k軌道/700タスクを収集し学習 32 [Google Research, RSS2023]
RT-2 • 大規模なウェブデータで学習されたVLMであるPaLM-E/PaLI-Xを バックボーンとすることで未知環境への汎化性能を向上 • RT-1由来のデータとインターネットスケールの視覚言語タスクの 両者を用いてVLMをFine Tuning • VLMをバックボーンとしたVLAという考え方が一般的に
33 [Google DeepMind, CoRL2023]
RT-X • 単一の身体だけでなく, 多様な身体性を持つロボットデータを同時 に使い学習することでRT-1/RT-2の性能を向上可能 • 21機関/173人の著者による22ロボットの60データセットの整備 34 [Open X-Embodiment,
ICRA2024]
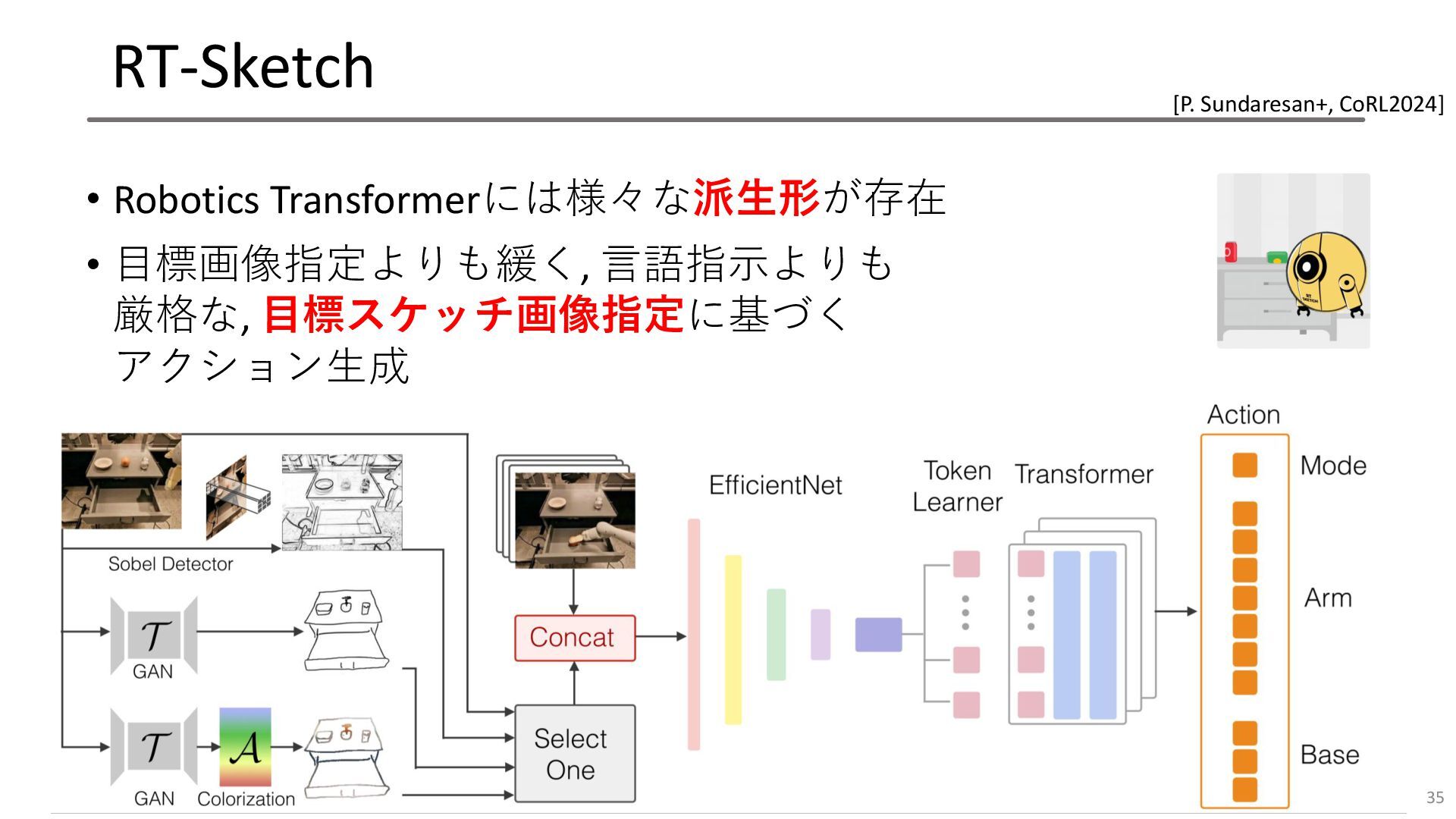
RT-Sketch • Robotics Transformerには様々な派生形が存在 • 目標画像指定よりも緩く, 言語指示よりも 厳格な, 目標スケッチ画像指定に基づく アクション生成
35 [P. Sundaresan+, CoRL2024]
RT-Trajectory • 手先の軌道を入力としたアクション生成を行う • この他にも自動データ収集のAutoRTや速度向上に向けたSARA-RTなど 36 [J. Gu+, ICLR2024]
RT-H • 中間表現であるlanguage motionを予測する高レベルポリシーと language motionからactionを予測する低レベルポリシーの階層構造 • プロンプトの変化により単一モデルで両ポリシーを学習させる • 学習が容易かつ人間の介入に対応可能.
その後階層構造が人気に 37 [S. Belkhale, RSS2024]
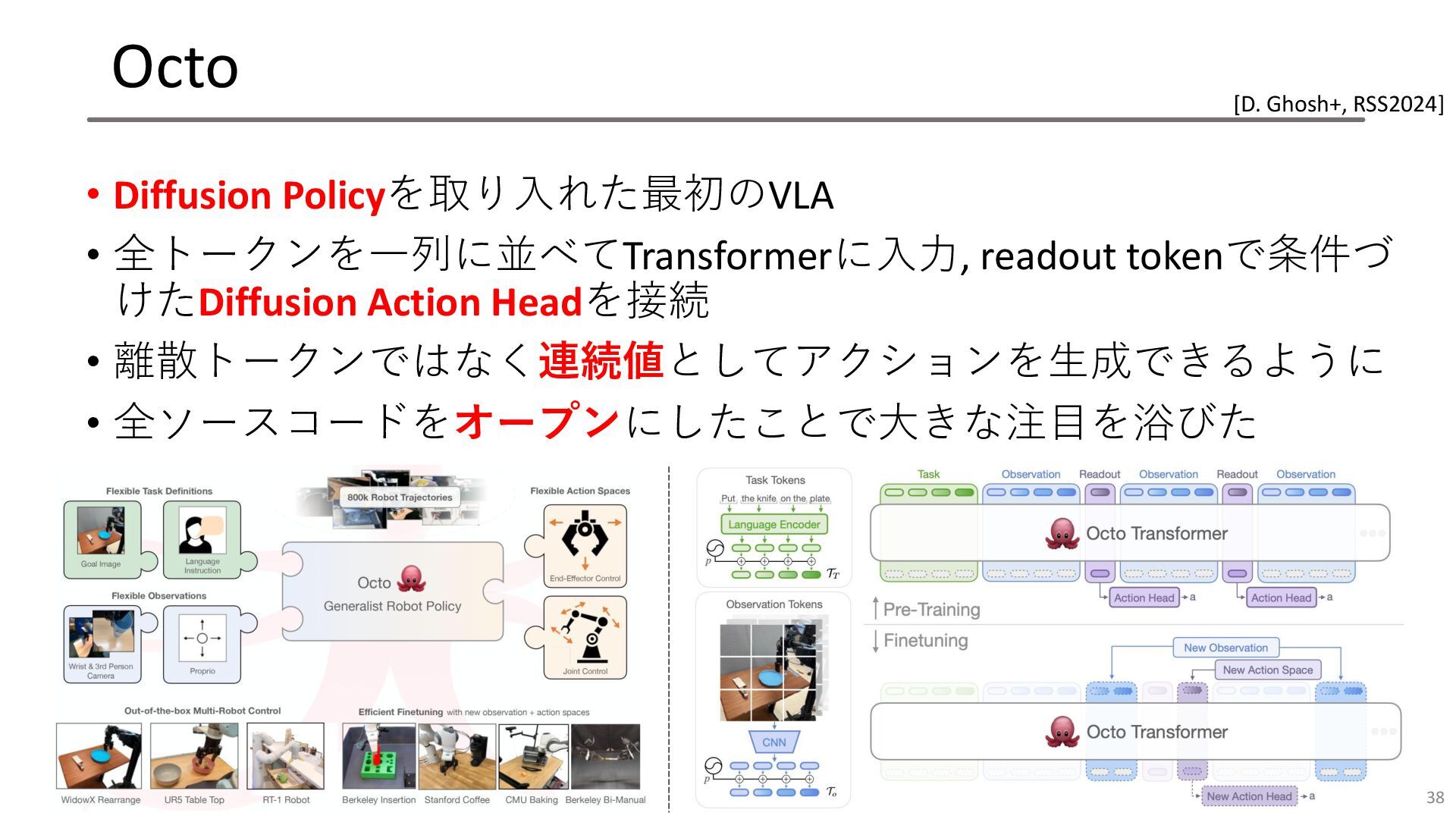
Octo • Diffusion Policyを取り入れた最初のVLA • 全トークンを一列に並べてTransformerに入力, readout tokenで条件づ けたDiffusion Action
Headを接続 • 離散トークンではなく連続値としてアクションを生成できるように • 全ソースコードをオープンにしたことで大きな注目を浴びた 38 [D. Ghosh+, RSS2024]
OpenVLA • Octoと同様にオープンソースとして公開 • 画像入力をDINOv2とSigLIPにより変換して入力する, LLaMA 2を ベースとしたPrismatic VLMをバックボーンとして使用 •
RT-Xのデータセットを用いてfull fine-tuningし, RT-2やOctoより高い性能 • OpenVLA/Prismatic VLMがベースのモデルとして頻繁に用いられる 39 [M. J. Kim+, CoRL2024]
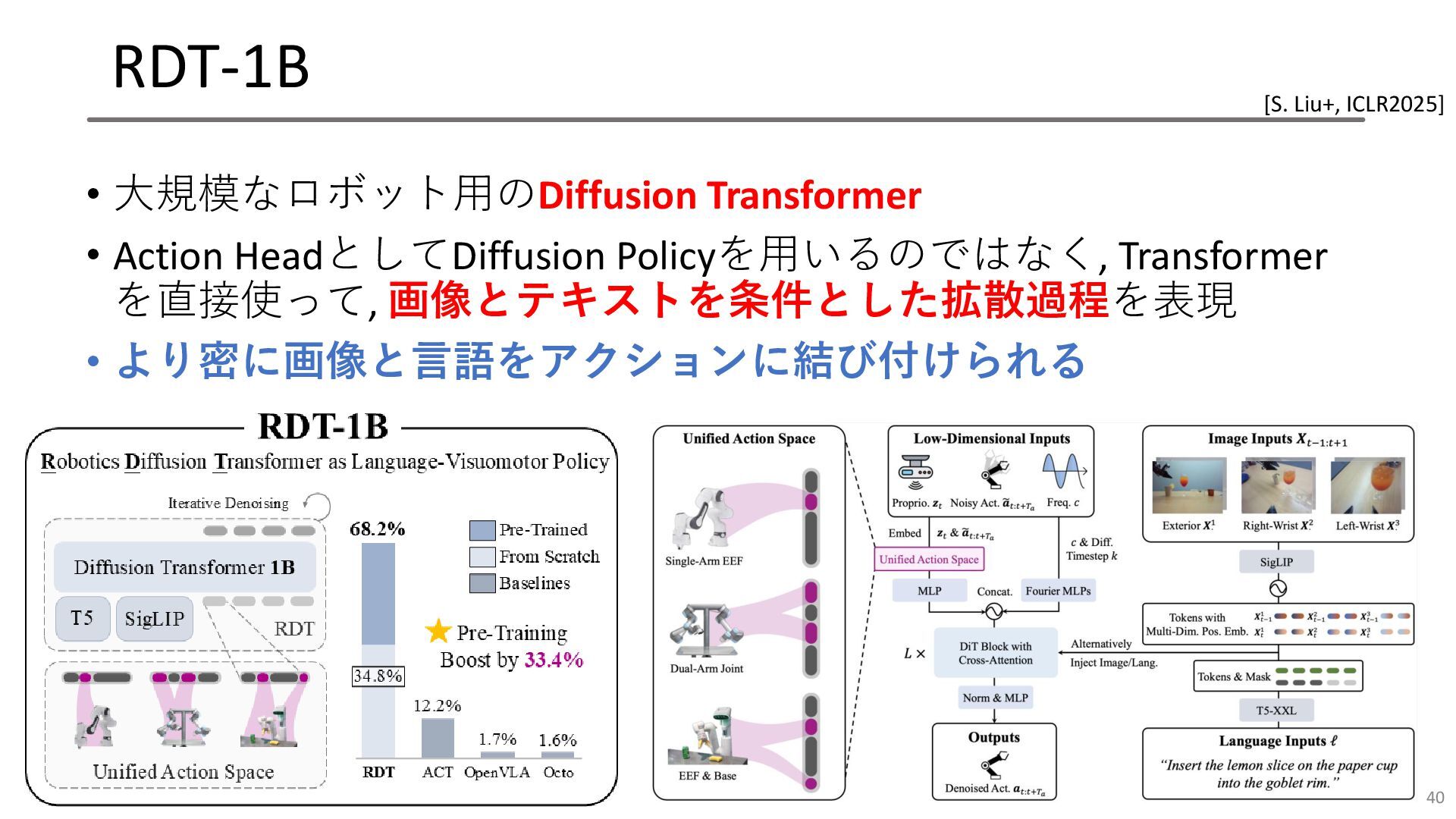
RDT-1B • 大規模なロボット用のDiffusion Transformer • Action HeadとしてDiffusion Policyを用いるのではなく, Transformer を直接使って,
画像とテキストを条件とした拡散過程を表現 • より密に画像と言語をアクションに結び付けられる 40 [S. Liu+, ICLR2025]
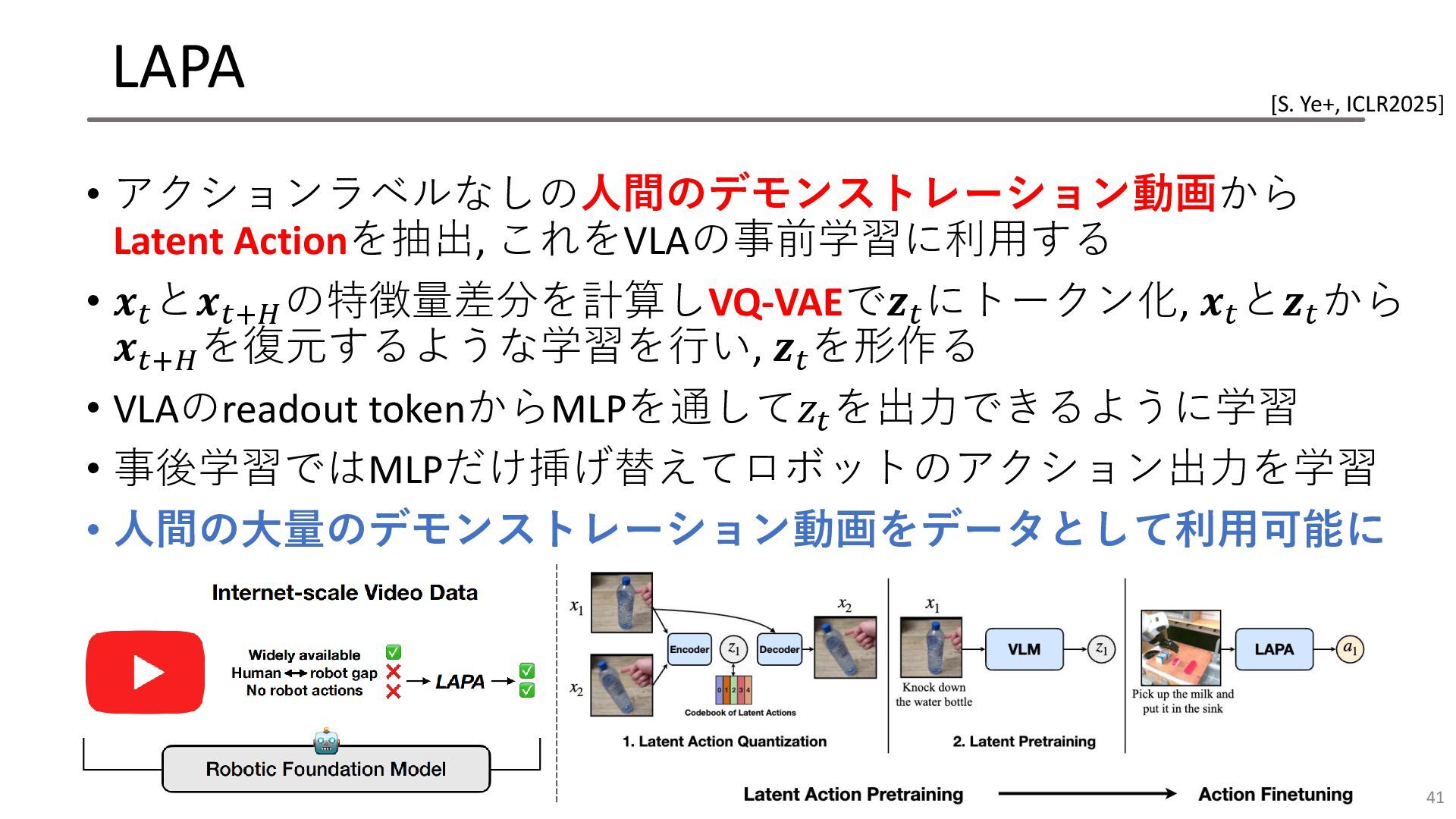
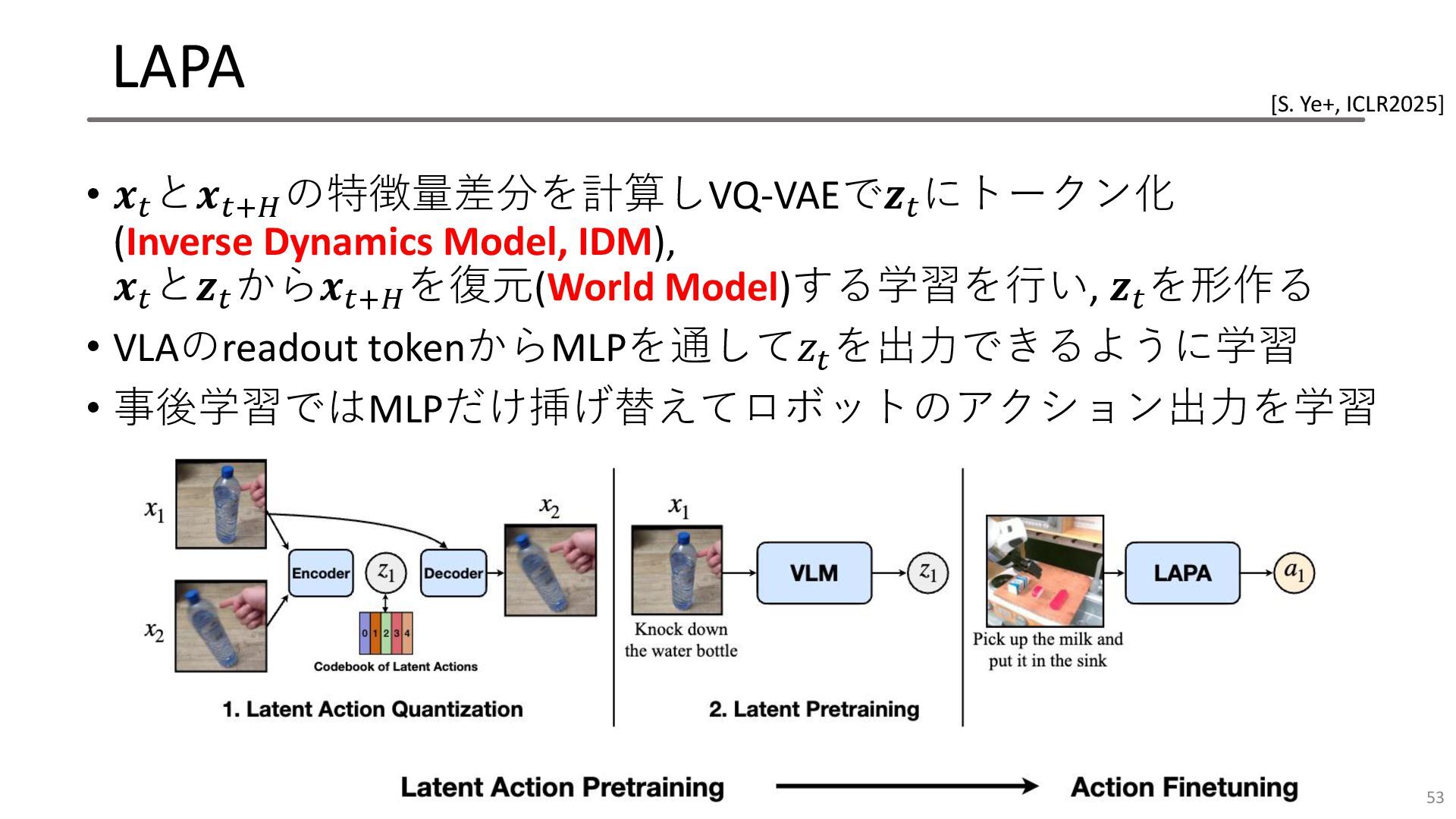
LAPA • アクションラベルなしの人間のデモンストレーション動画から Latent Actionを抽出, これをVLAの事前学習に利用する • 𝒙𝑡 と𝒙𝑡+𝐻 の特徴量差分を計算しVQ-VAEで𝒛𝑡
にトークン化, 𝒙𝑡 と𝒛𝑡 から 𝒙𝑡+𝐻 を復元するような学習を行い, 𝒛𝑡 を形作る • VLAのreadout tokenからMLPを通して𝑧𝑡 を出力できるように学習 • 事後学習ではMLPだけ挿げ替えてロボットのアクション出力を学習 • 人間の大量のデモンストレーション動画をデータとして利用可能に 41 [S. Ye+, ICLR2025]
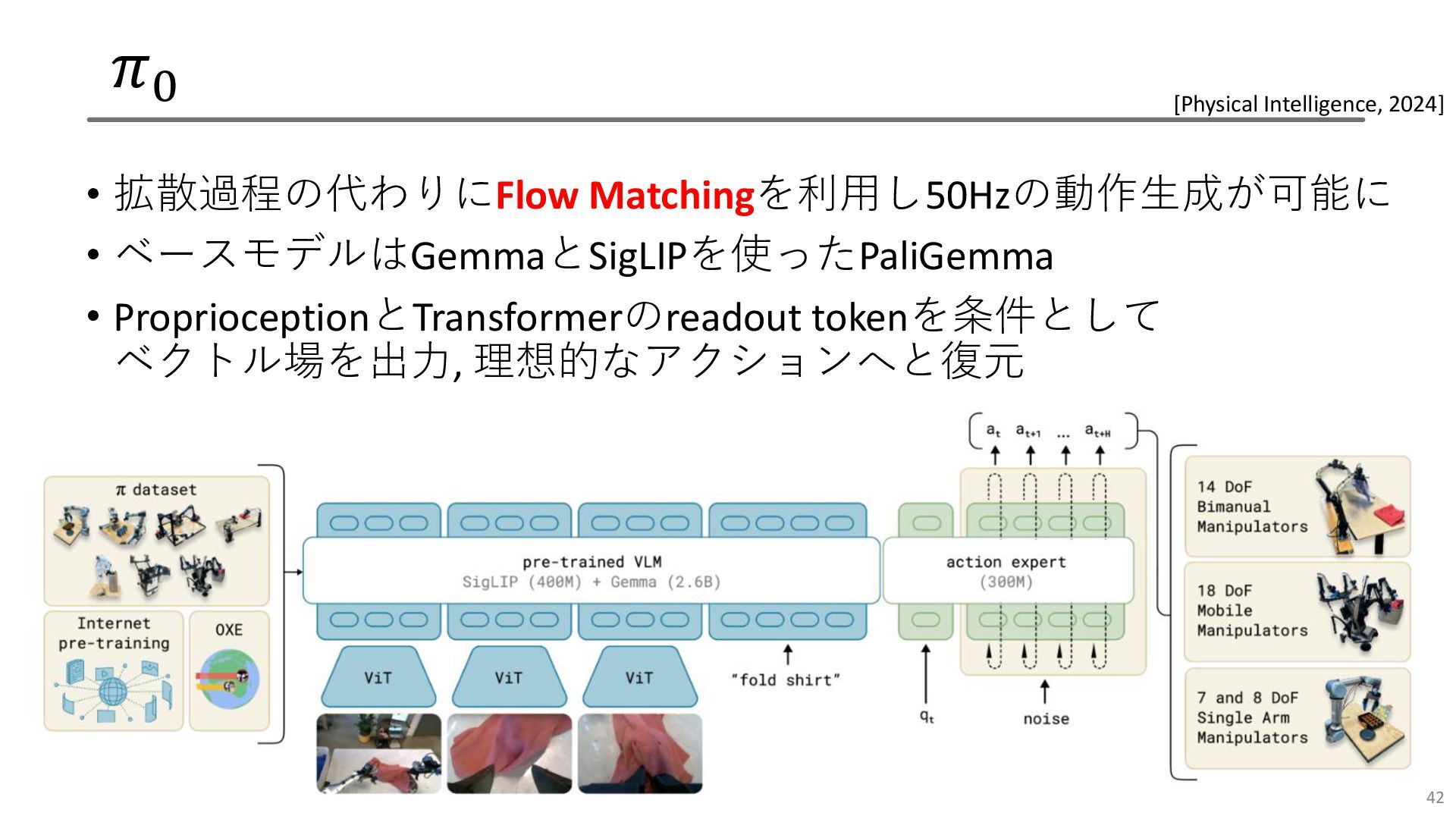
𝜋0 • 拡散過程の代わりにFlow Matchingを利用し50Hzの動作生成が可能に • ベースモデルはGemmaとSigLIPを使ったPaliGemma • ProprioceptionとTransformerのreadout tokenを条件として ベクトル場を出力,
理想的なアクションへと復元 42 [Physical Intelligence, 2024]
𝜋0 43 [Physical Intelligence (π), 2024] https://www.physicalintelligence.company/blog/pi0
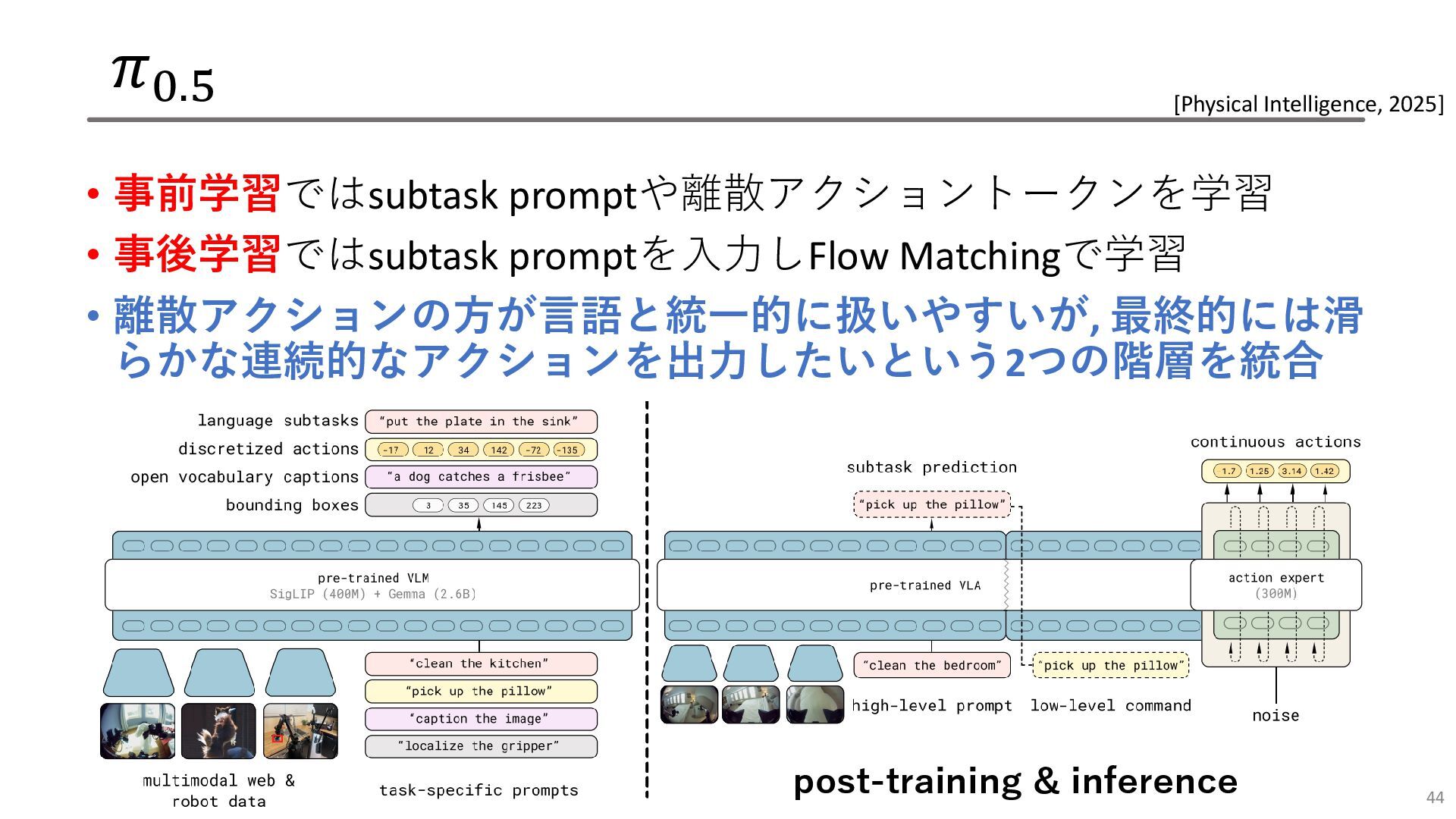
𝜋0.5 • 事前学習ではsubtask promptや離散アクショントークンを学習 • 事後学習ではsubtask promptを入力しFlow Matchingで学習 • 離散アクションの方が言語と統一的に扱いやすいが,
最終的には滑 らかな連続的なアクションを出力したいという2つの階層を統合 44 [Physical Intelligence, 2025] post-training & inference
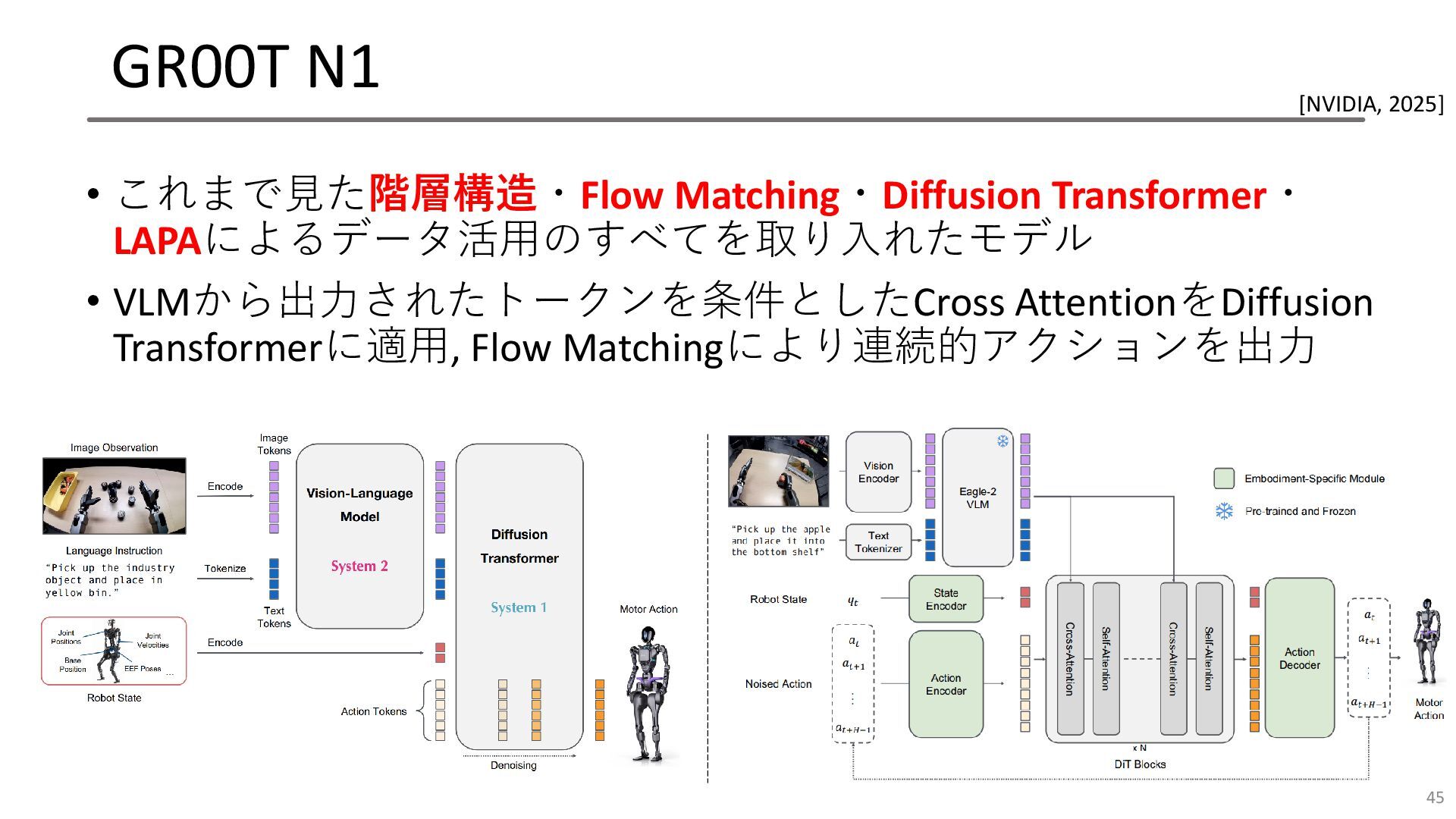
GR00T N1 • これまで見た階層構造・Flow Matching・Diffusion Transformer・ LAPAによるデータ活用のすべてを取り入れたモデル • VLMから出力されたトークンを条件としたCross AttentionをDiffusion
Transformerに適用, Flow Matchingにより連続的アクションを出力 45 [NVIDIA, 2025]
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 46
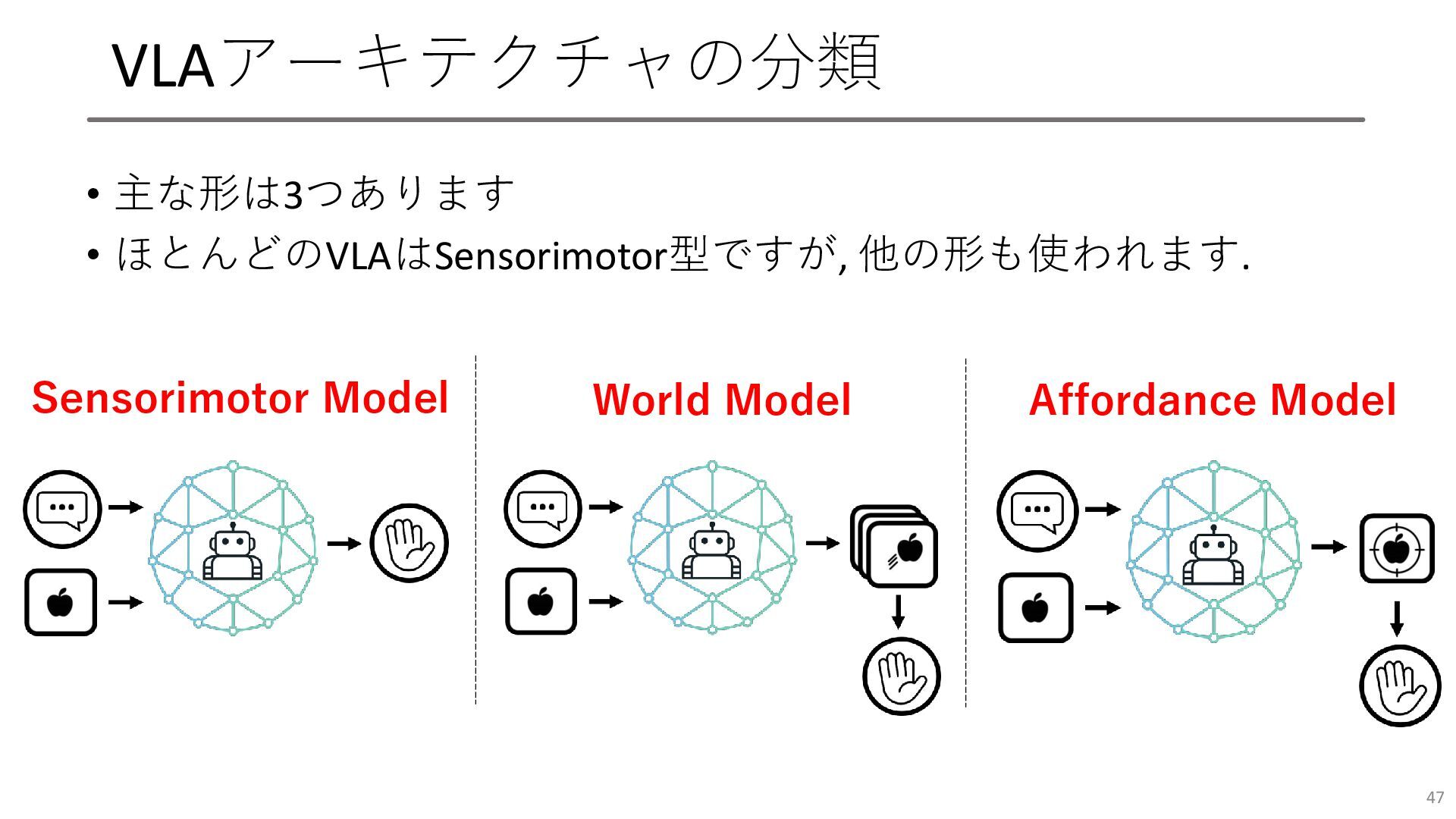
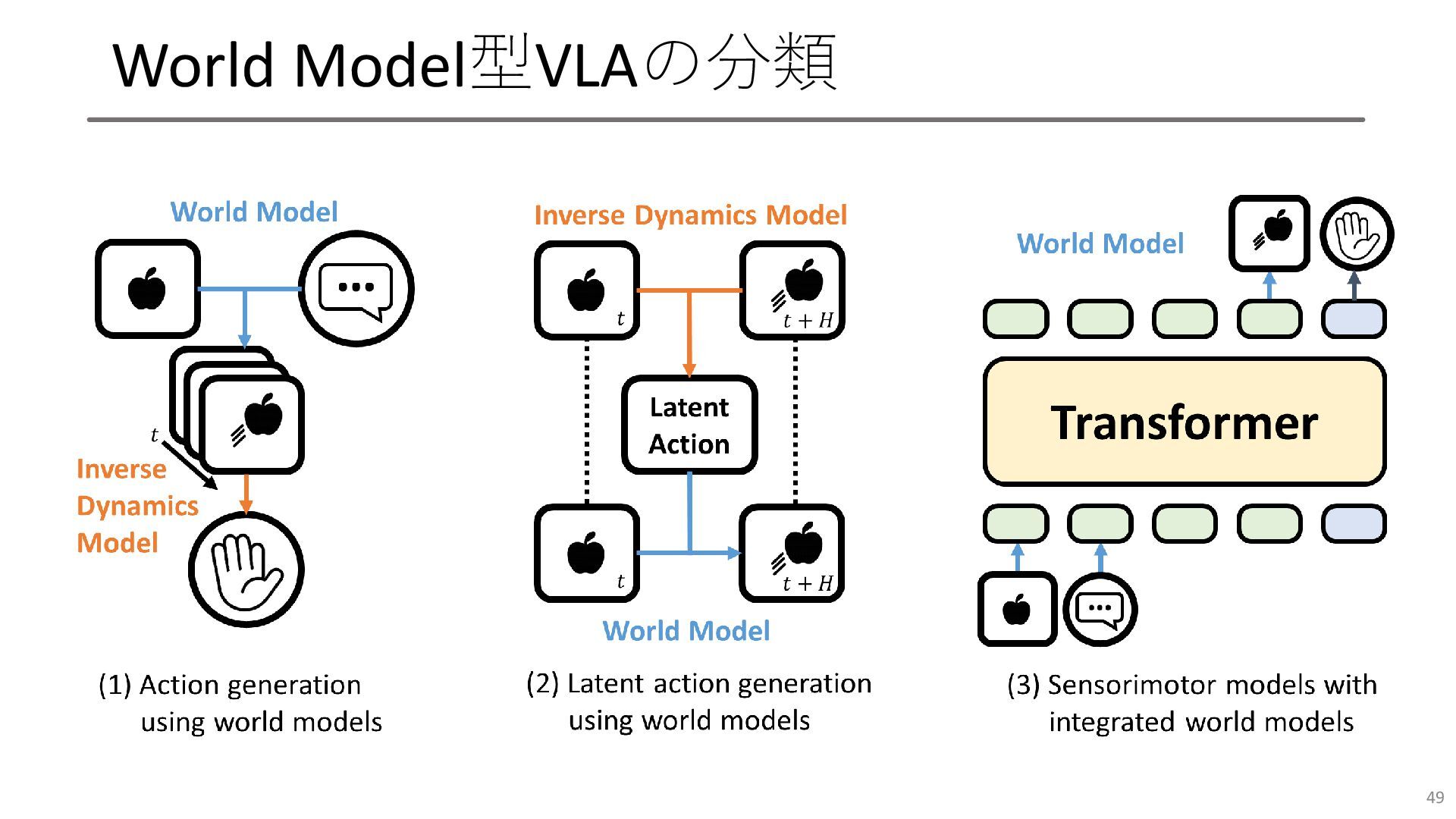
VLAアーキテクチャの分類 • 主な形は3つあります • ほとんどのVLAはSensorimotor型ですが, 他の形も使われます. 47 Sensorimotor Model World
Model Affordance Model
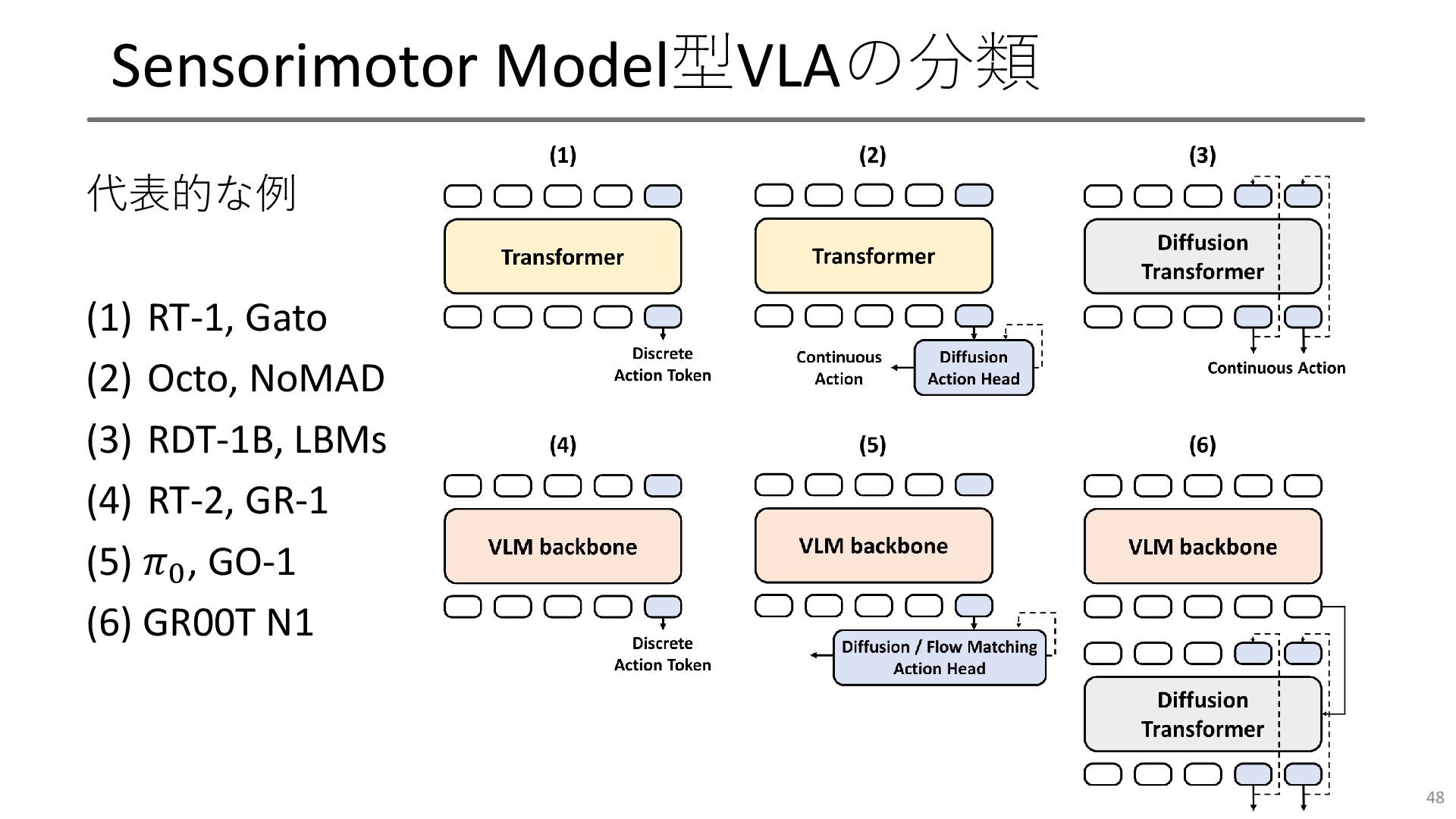
Sensorimotor Model型VLAの分類 代表的な例 (1) RT-1, Gato (2) Octo, NoMAD (3)
RDT-1B, LBMs (4) RT-2, GR-1 (5) 𝜋0 , GO-1 (6) GR00T N1 48
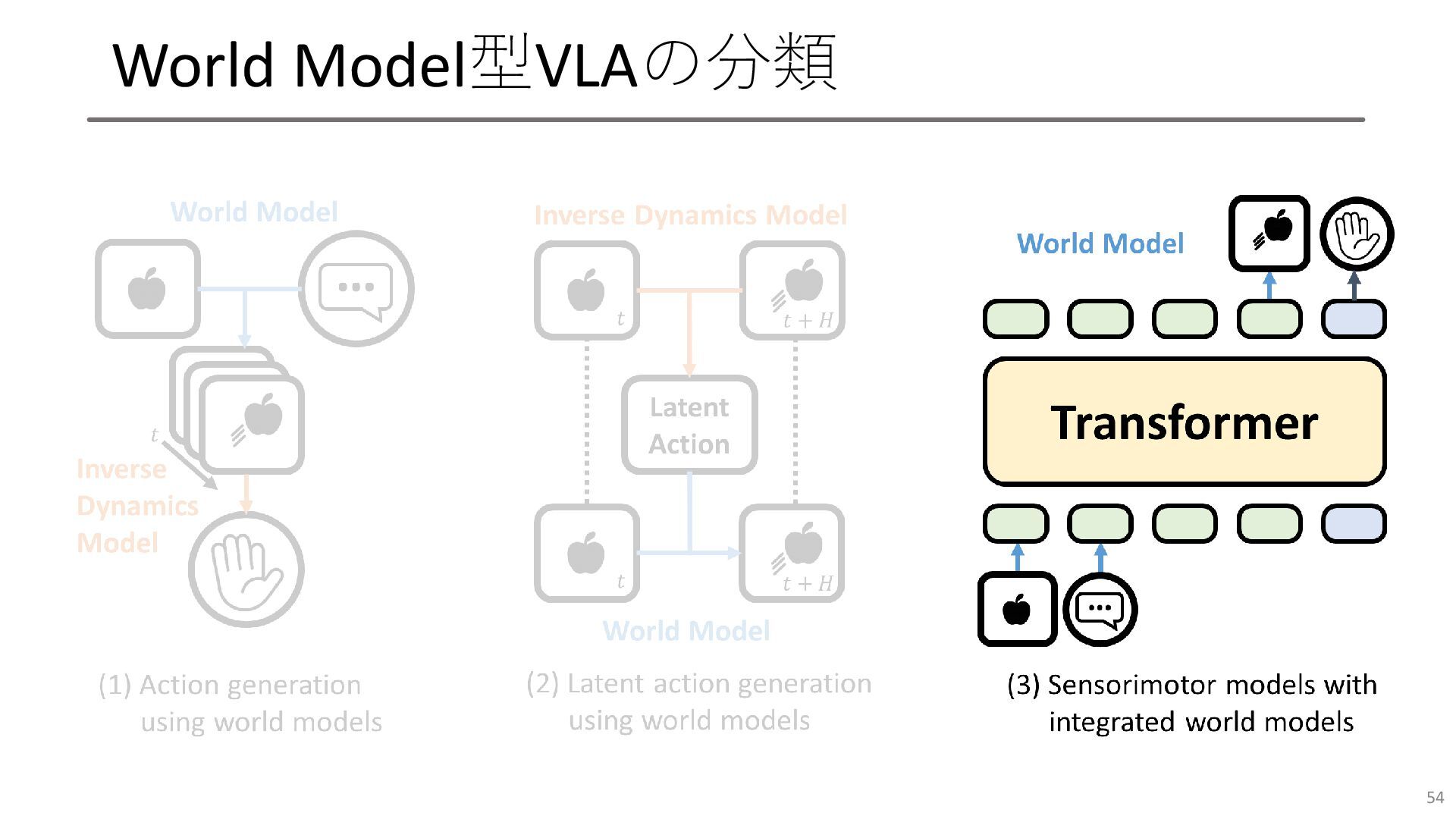
World Model型VLAの分類 49
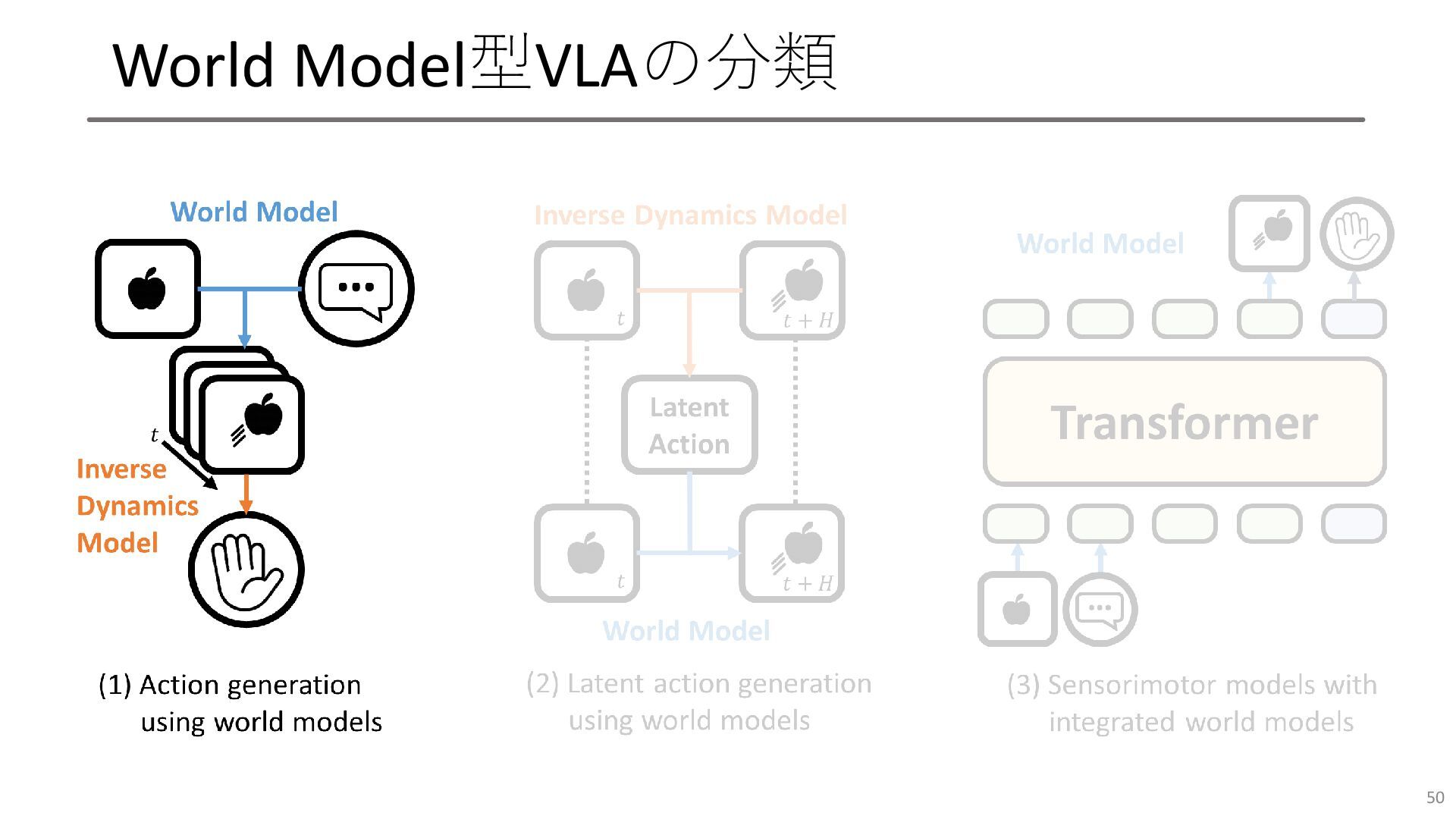
World Model型VLAの分類 50
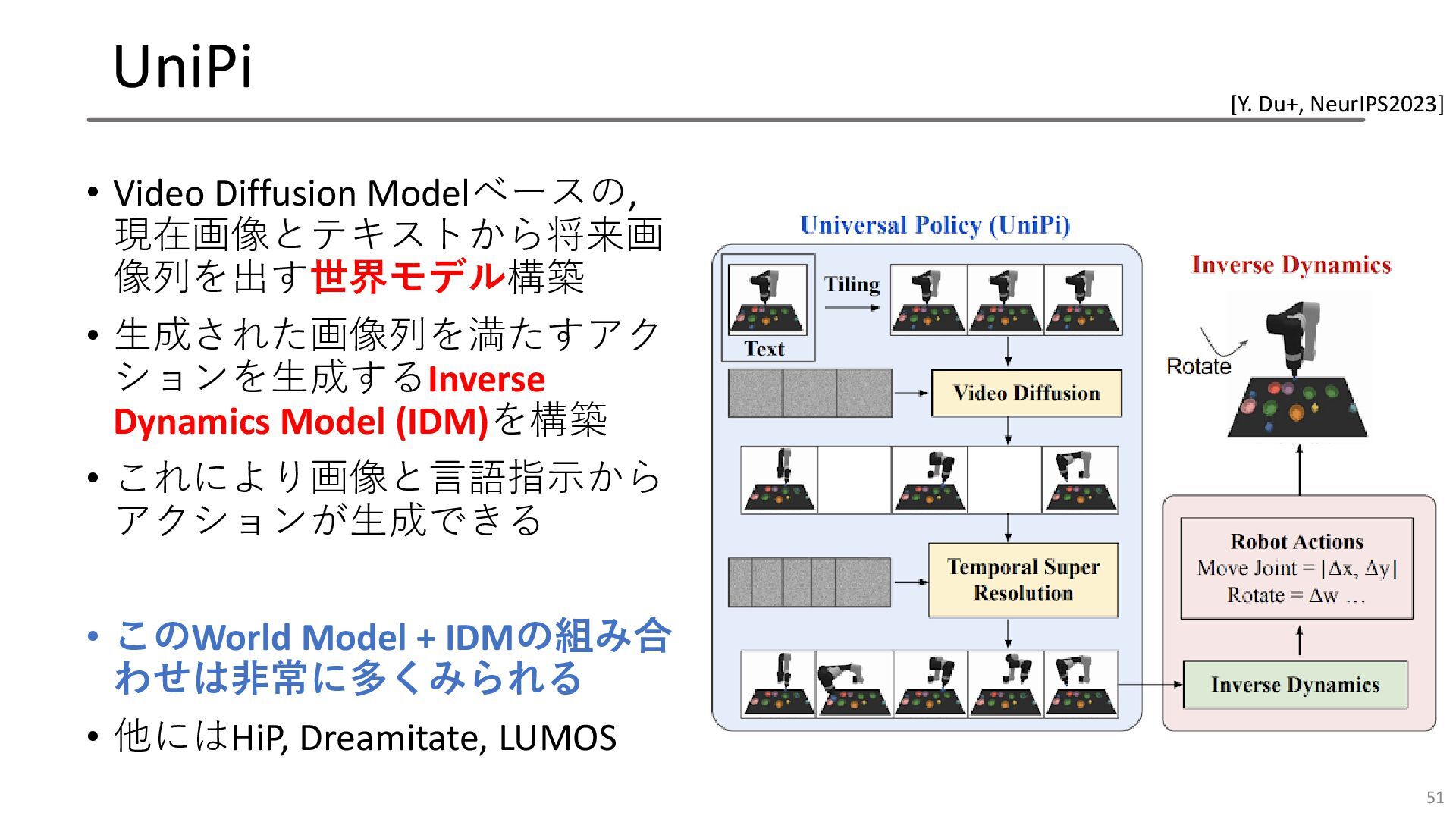
UniPi • Video Diffusion Modelベースの, 現在画像とテキストから将来画 像列を出す世界モデル構築 • 生成された画像列を満たすアク ションを生成するInverse
Dynamics Model (IDM)を構築 • これにより画像と言語指示から アクションが生成できる • このWorld Model + IDMの組み合 わせは非常に多くみられる • 他にはHiP, Dreamitate, LUMOS 51 [Y. Du+, NeurIPS2023]
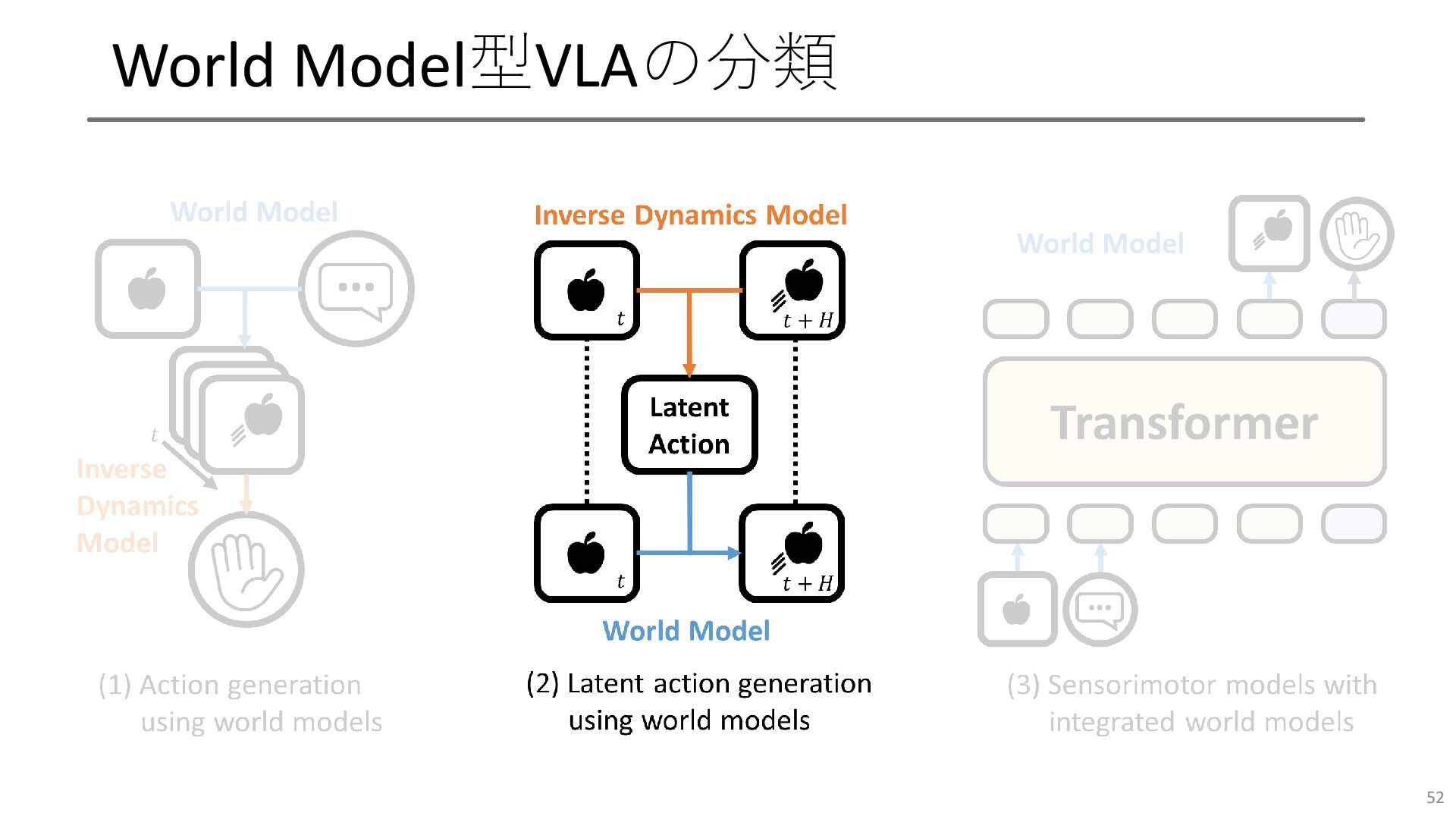
World Model型VLAの分類 52
LAPA • 𝒙𝑡 と𝒙𝑡+𝐻 の特徴量差分を計算しVQ-VAEで𝒛𝑡 にトークン化 (Inverse Dynamics Model, IDM),
𝒙𝑡 と𝒛𝑡 から𝒙𝑡+𝐻 を復元(World Model)する学習を行い, 𝒛𝑡 を形作る • VLAのreadout tokenからMLPを通して𝑧𝑡 を出力できるように学習 • 事後学習ではMLPだけ挿げ替えてロボットのアクション出力を学習 53 [S. Ye+, ICLR2025]
World Model型VLAの分類 54
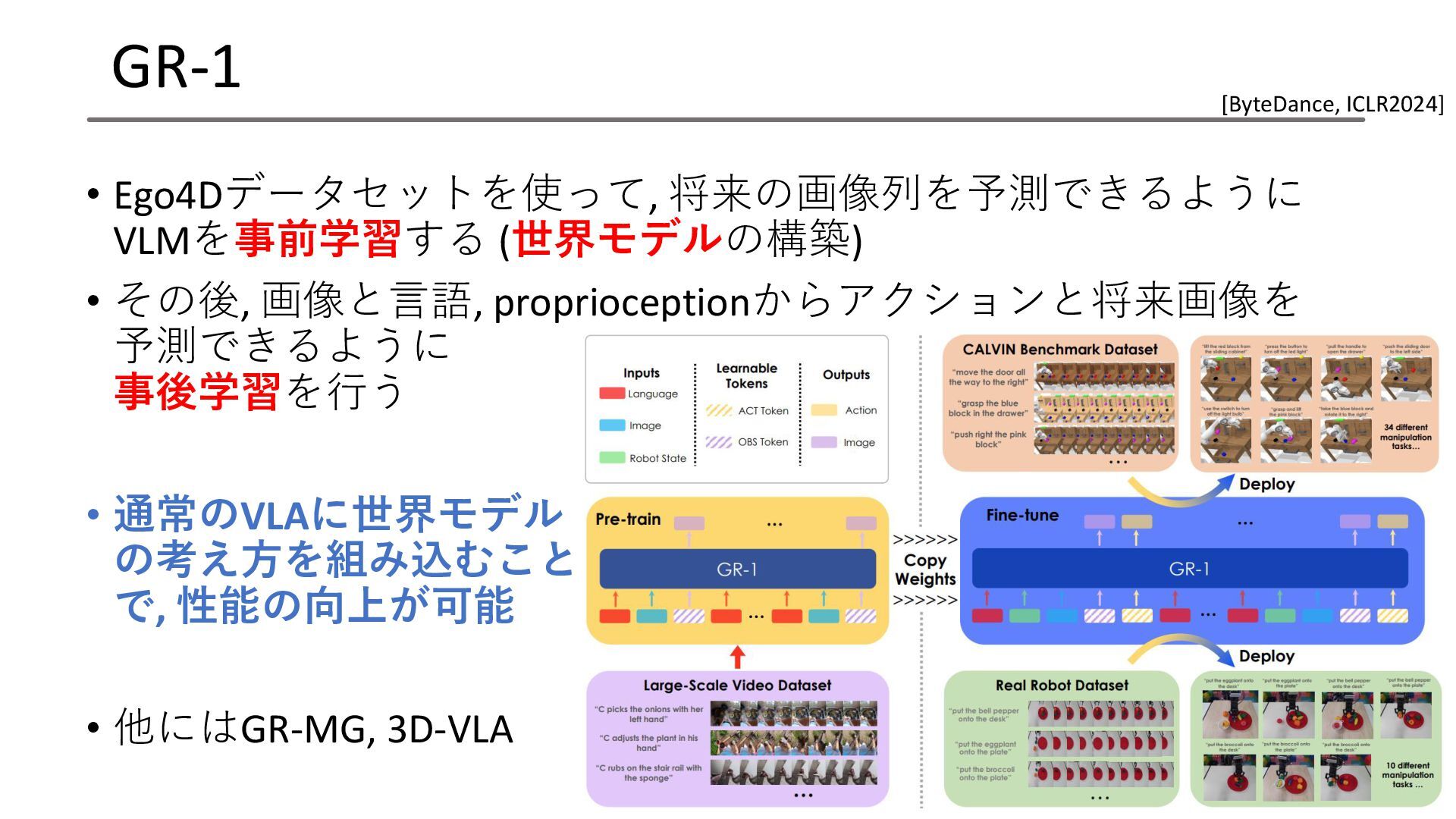
GR-1 • Ego4Dデータセットを使って, 将来の画像列を予測できるように VLMを事前学習する (世界モデルの構築) • その後, 画像と言語, proprioceptionからアクションと将来画像を
予測できるように 事後学習を行う • 通常のVLAに世界モデル の考え方を組み込むこと で, 性能の向上が可能 • 他にはGR-MG, 3D-VLA 55 [ByteDance, ICLR2024]
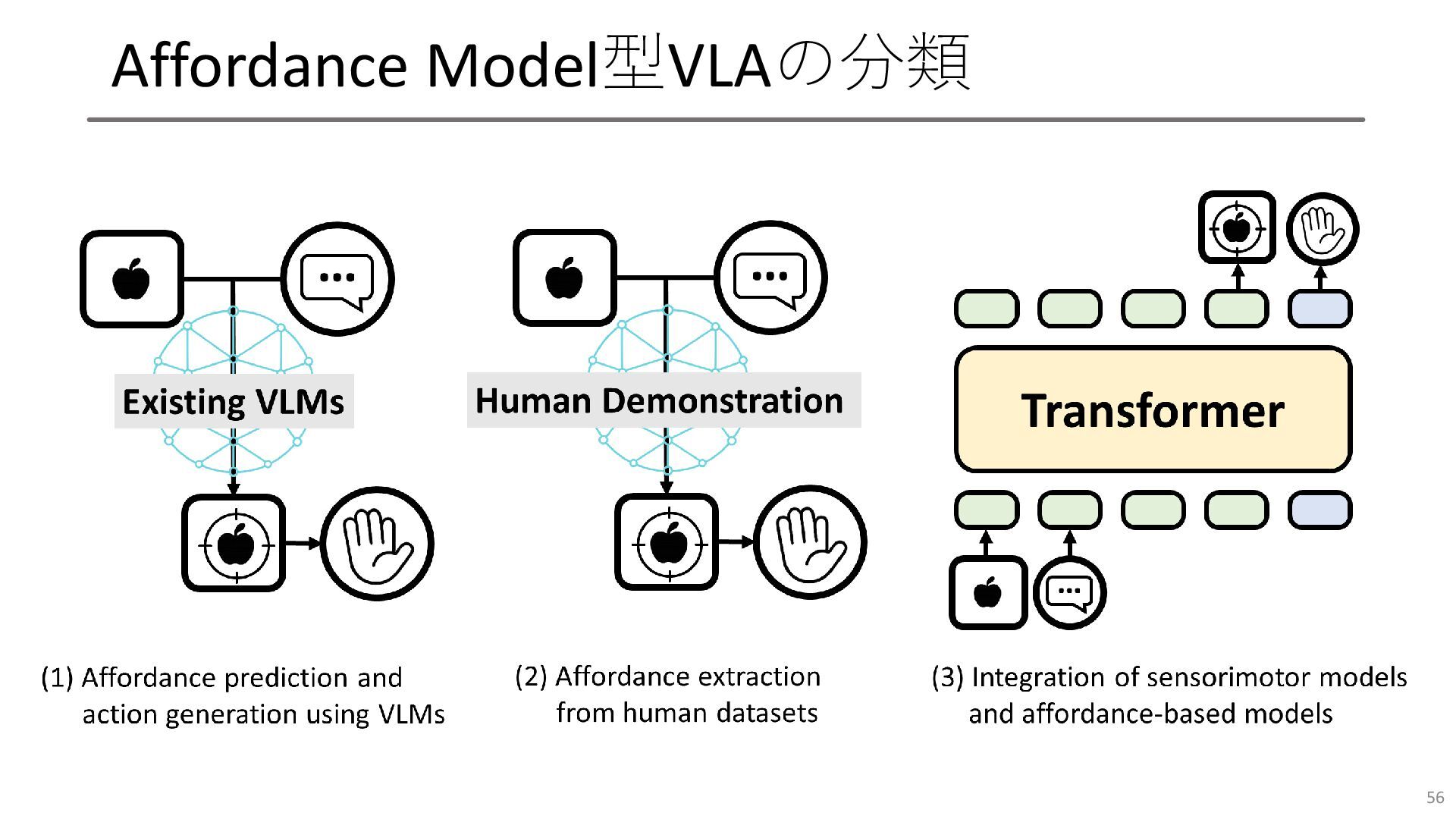
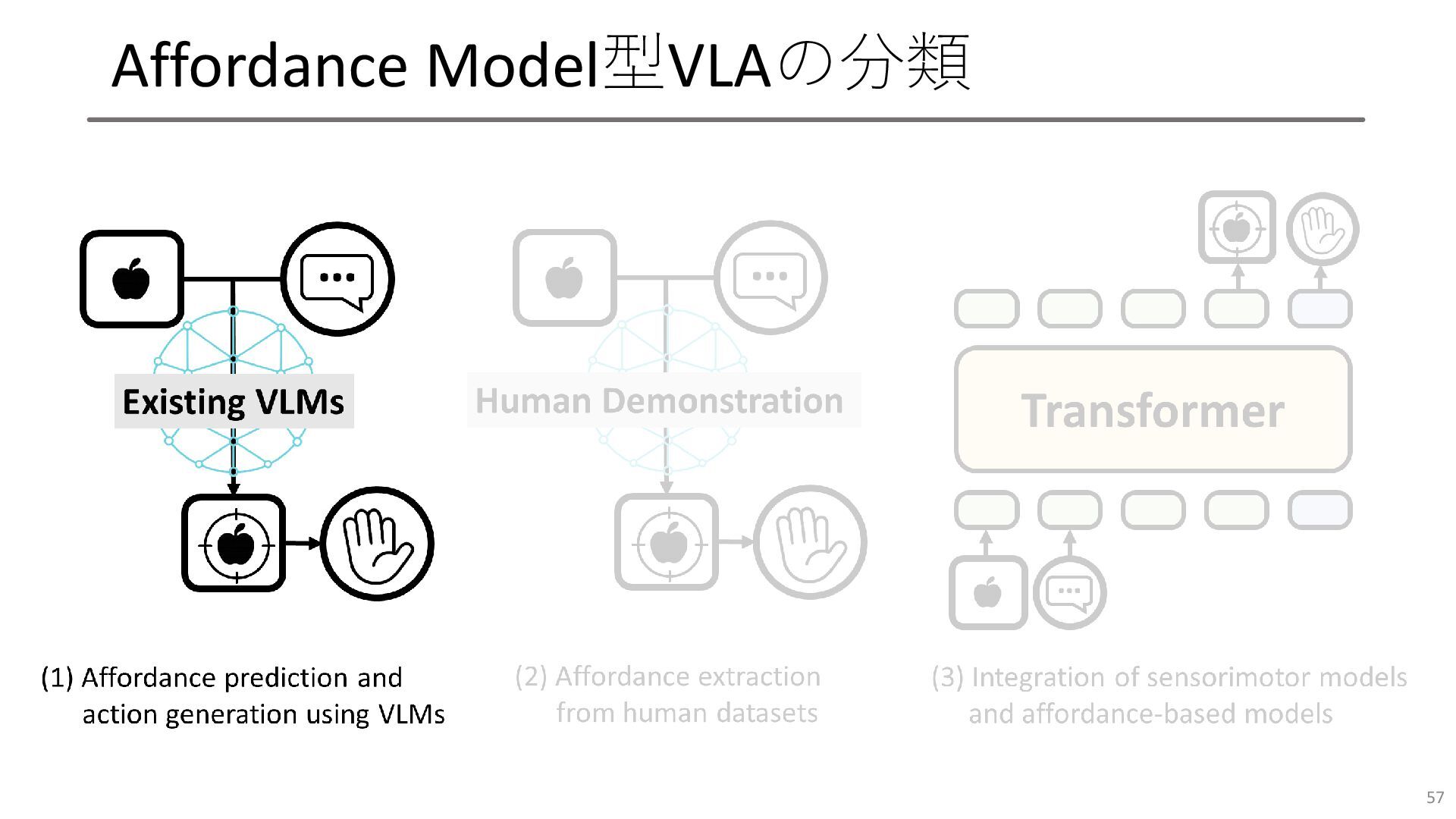
Affordance Model型VLAの分類 56
Affordance Model型VLAの分類 57
VoxPoser • 既存のVLMとLLMにより, どこに手を伸ばすべきか(Affordance Map), どこに気を付けるべきか (Constraint Map)を構築し, この情報をも とにモデル予測制御を実行してマニピュレーション
• 既存のVLM/LLMに含まれる常識/アフォーダンスを利用できる 58 [W. Huang+, CoRL2023]
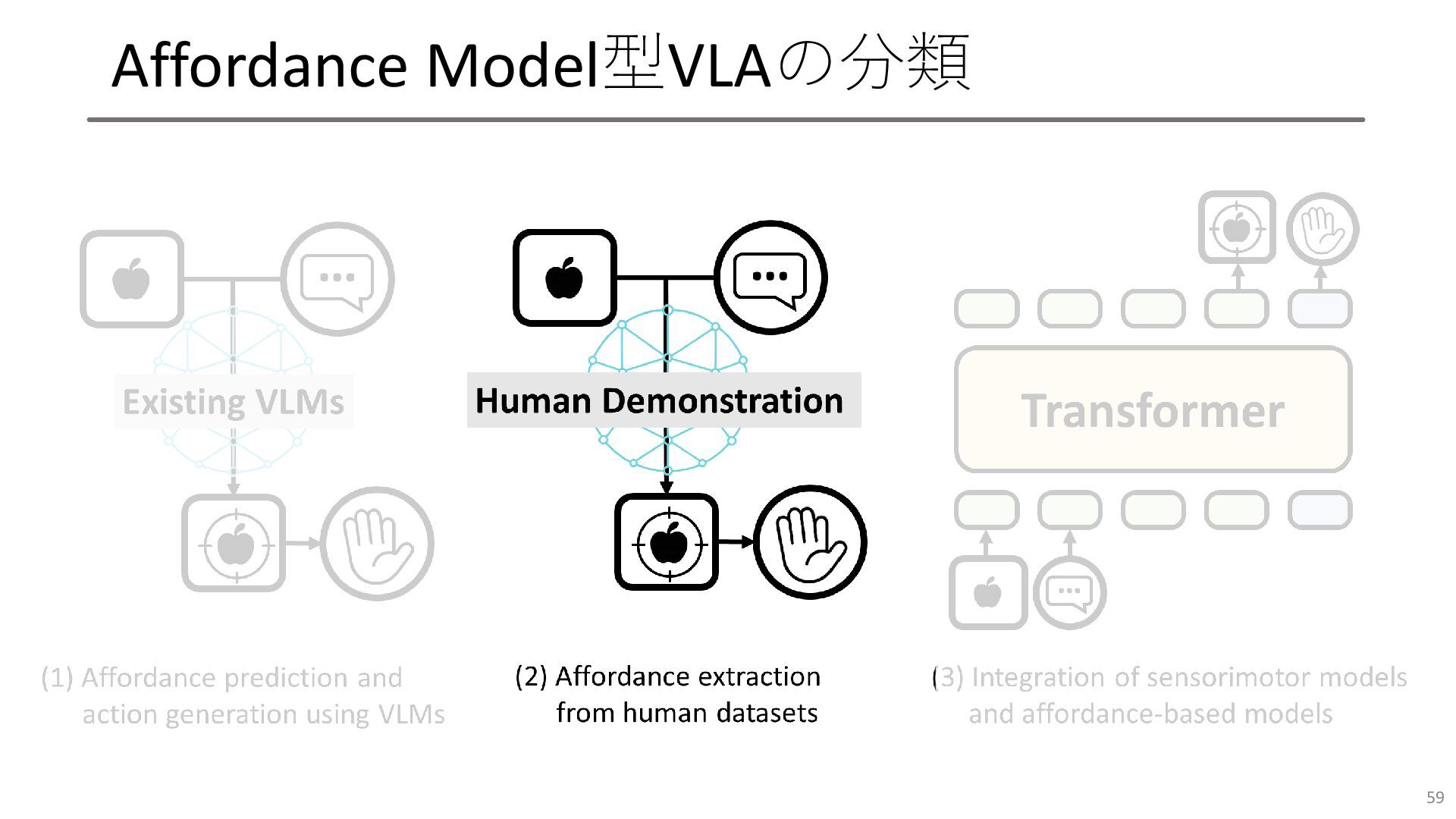
Affordance Model型VLAの分類 59
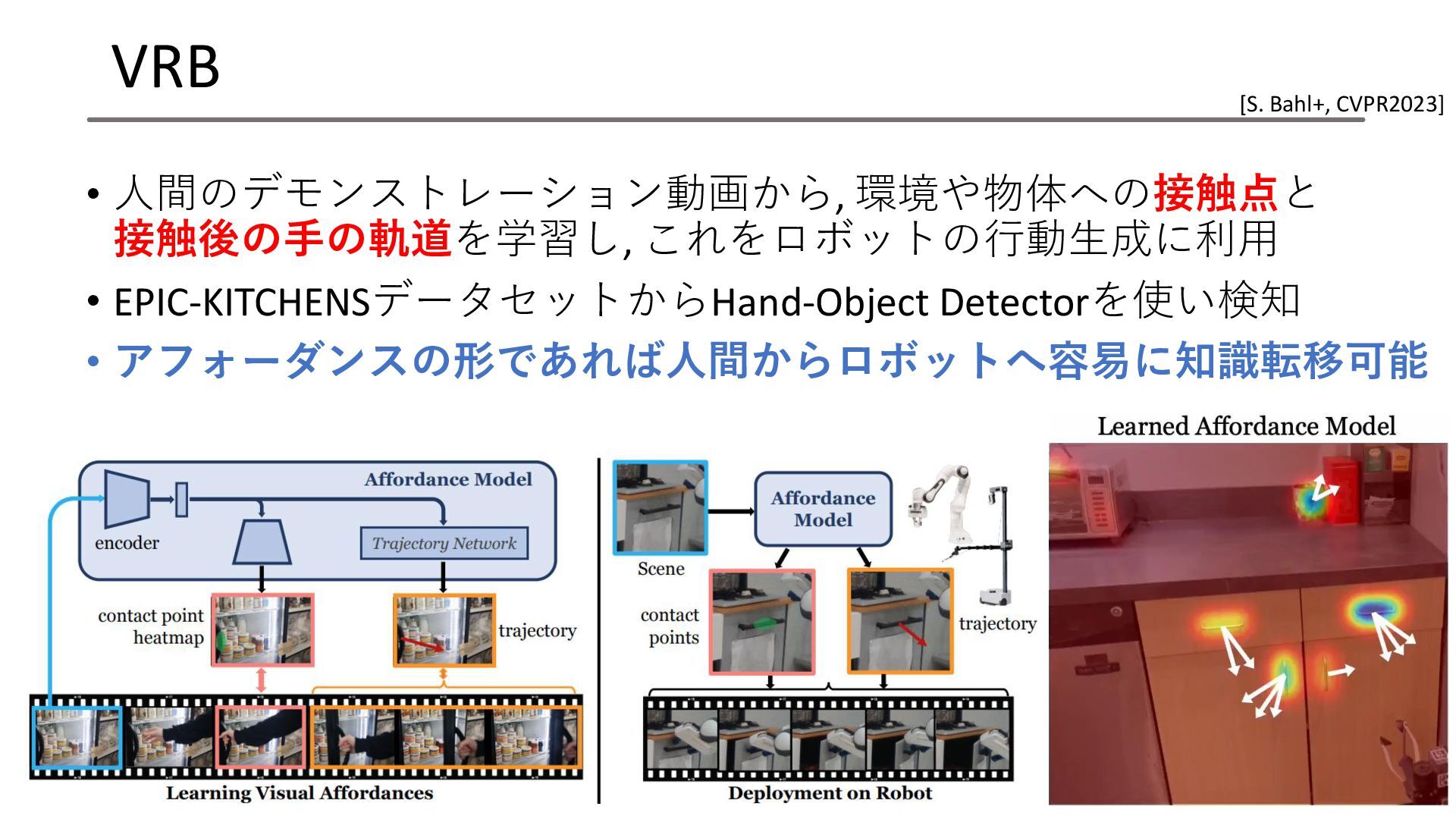
VRB • 人間のデモンストレーション動画から, 環境や物体への接触点と 接触後の手の軌道を学習し, これをロボットの行動生成に利用 • EPIC-KITCHENSデータセットからHand-Object Detectorを使い検知 •
アフォーダンスの形であれば人間からロボットへ容易に知識転移可能 60 [S. Bahl+, CVPR2023]
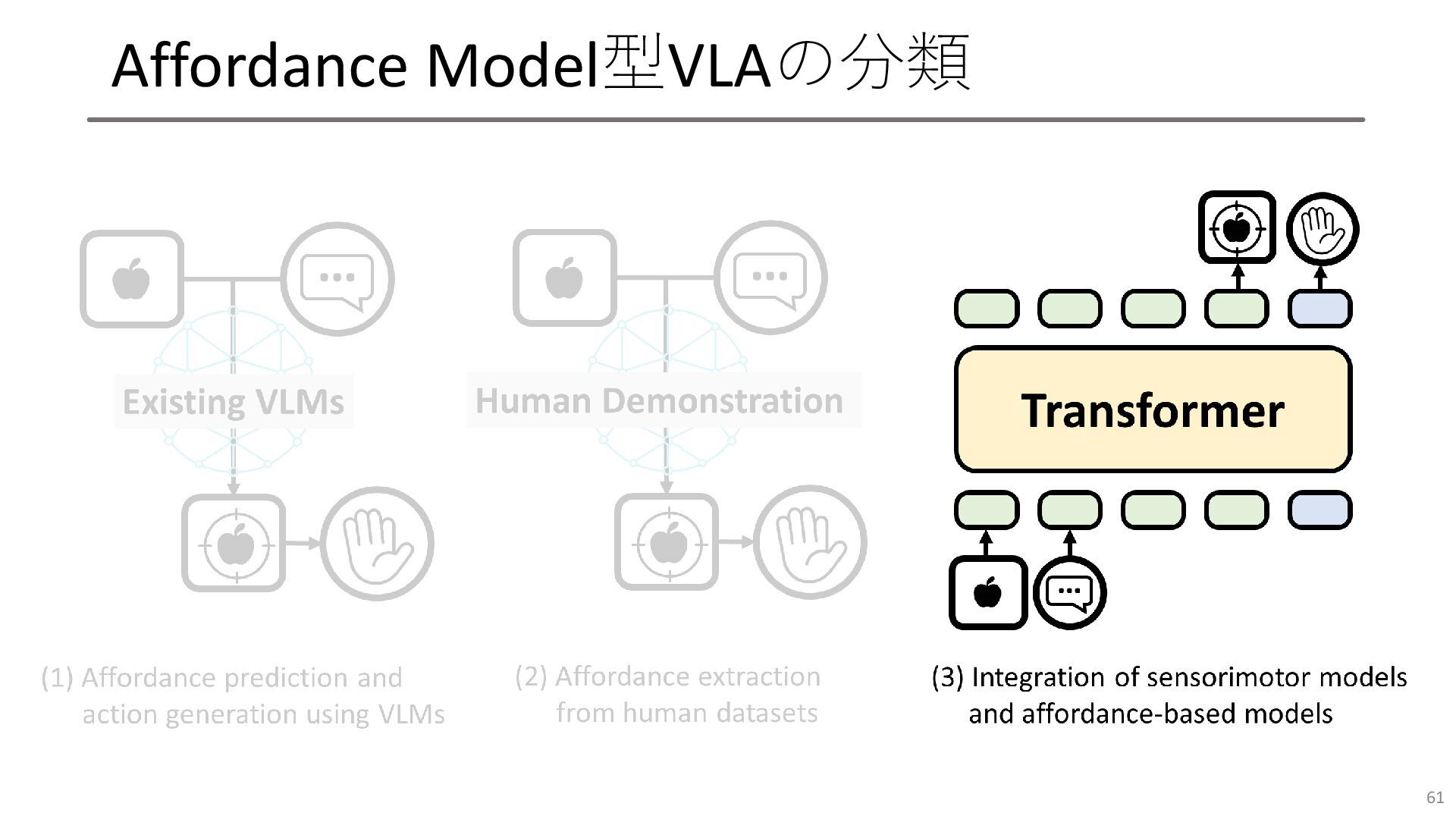
Affordance Model型VLAの分類 61
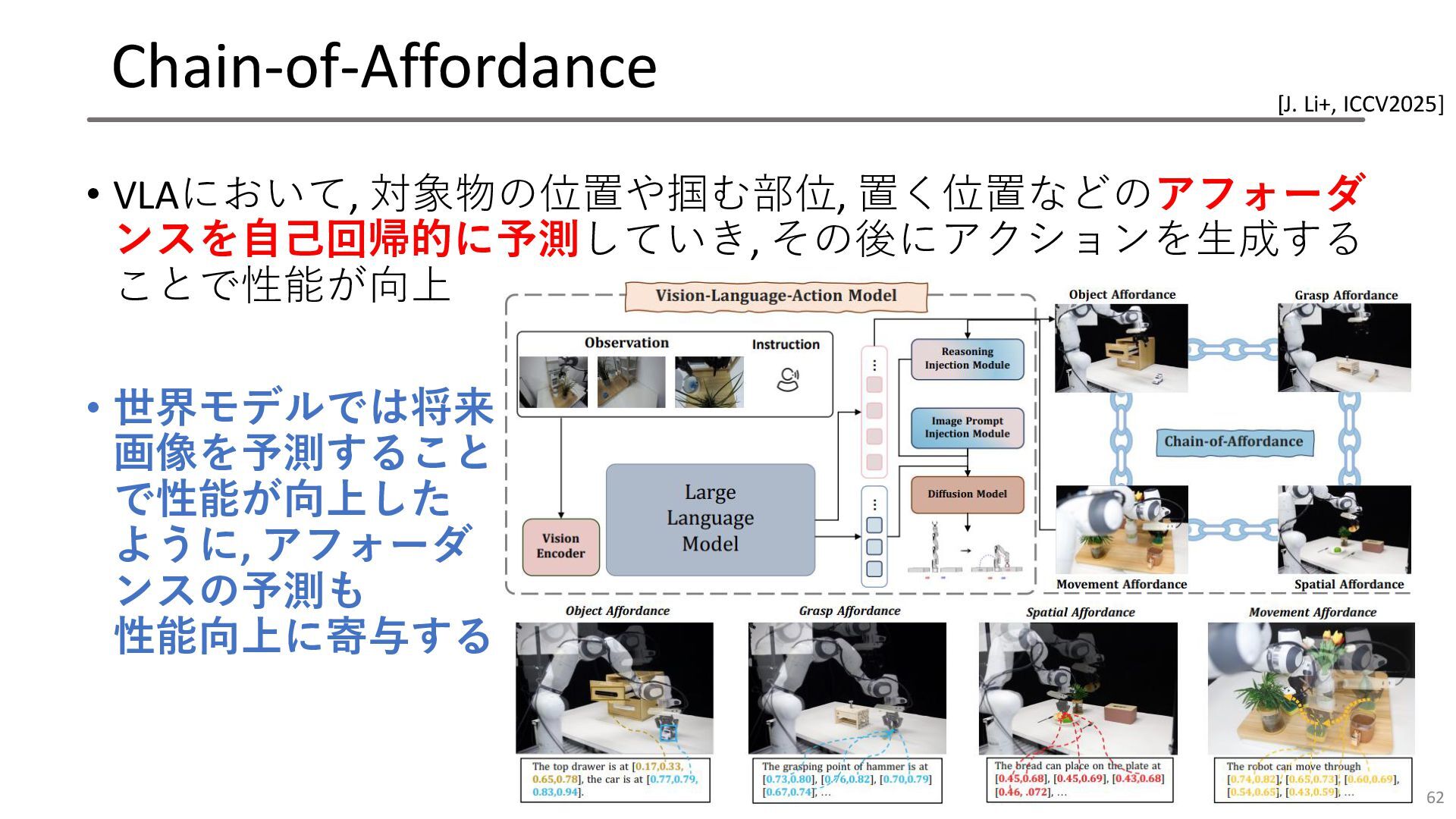
Chain-of-Affordance • VLAにおいて, 対象物の位置や掴む部位, 置く位置などのアフォーダ ンスを自己回帰的に予測していき, その後にアクションを生成する ことで性能が向上 • 世界モデルでは将来
画像を予測すること で性能が向上した ように, アフォーダ ンスの予測も 性能向上に寄与する 62 [J. Li+, ICCV2025]
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 63
どんなロボットが使われている? 主なロボットは? • マニピュレータ • ハンド/グリッパ • 台車型ロボット • 四脚ロボット
• ヒューマノイドロボット 64
マニピュレータ 65 Franka Emika Panda WidowX-250 KUKA LBR iiwa 14
SO-101 特徴的なVLA – Shake-VLA / RoboNurse-VLA
ハンド・グリッパ 66 Robotiq 2F-85 Shadow Hand Inspire Robots RH65 LEAP
Hand 特徴的なVLA – GraspVLA / DexGraspVLA
モバイルロボット 67 Google Robot Hello Stretch AgiBot G1 DJI Tello
特徴的なVLA – MobilityVLA / UAV-VLA
四脚ロボット 68 Boston Dynamics Spot Unitree Go2 ANYMAL 特徴的なVLA –
NaVILA / CrossFormer
ヒューマノイドロボット 69 Unitree G1 Unitree H1 Booster T1 Fourier GR-1
特徴的なVLA – Humanoid-VLA / LeVERB
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 70
データ収集方法 データ収集には3種類の方法がある • ロボットのテレオペレーション デバイスによりロボットを人間が操作する • 代理デバイスによるデモンストレーション収集 ロボットの一部や専用デバイスで収集(ロボットは必要ない)
• 人間の動作データ収集 カメラで人間の動作を収集する 71
ALOHA • 言わずと知れたデータ収集プラットフォームのスタンダード • リーダ (2×WidowX-250)とフォロワ(2×ViperX-300)による4腕構成 • ユニラテラル制御により人間のデモンストレーションを収集 • ALOHAと同時にAction
Chunking Transformer (ACT)が提案された 72 [T. Z. Zhao, RSS2023]
Mobile ALOHA 73 [Z. Fu+, CoRL2024] • ALOHAと台車型ロボットが合体し, マニピュレーションだけでなく, ナビゲーションのデータ収集・学習ができるように
• ALOHAのデータとco-trainingすることで性能アップ
Open-Television 74 [X. Cheng+, CoRL2024] • Apple Vision Proを使った手首・指・頭の姿勢推定をヒューマノイド に反映しテレオペレーション
• Active Visionの有効性検証
UMI • カメラがついたハンド型デバイスでデータ収集 • Visual SLAMから手の軌道を取得, これをもとにポリシーを学習 • ロボットが同じデバイスを持ち, そのポリシーをもとにタスク実行
75 [C. Chi+, RSS2024]
Project Aria 76 [Meta, arXiv, 2023] • コンパクトなスマートグラスにより, 人間の一人称視点からの行動 を記録,
これをVLAの事前学習に利用する • Ego-Exo4D, HOT3D, HD EPIC, Aria Everyday Activitiesなど, 多様なデータセットが公開されている
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 77
データセット データセットには主に3種類のカテゴリがある • Human Egocentric Data • Simulation Data •
Real Robot Data 78 ここだけ話します
QT-Opt • 実ロボットによる580,000の物体把持試行データセット • RGB画像入力に基づくスケーラブルなオフポリシー深層強化学習 • 4か月にわたり7台のKUKA LBR iiwaアームを800時間稼働させた 79
[J. Li+, CoRL2018]
BridgeData V2 80 [H. Walke+, CoRL2023] • 実世界の大規模・多様なタスクのデータセット • WidowX-250/24種類の環境/13のスキルの60,000軌道データ
• クラウドソーシングで全軌道に自然言語アノテーション
RT-X • 21の研究機関, 34の研究室, 173人の著者による超大規模データセット • 22種類のロボットにより527のスキルを含む60のデータセット, 1.4M 軌道のデータをRLDSフォーマットにより公開(QT-OPTやBridgeも含む) •
多様な身体性の学習により単一の身体学習よりVLAの精度が向上 81 [Open X-Embodiment, ICRA2024]
DROID 82 • 13機関・18台の共通プラットフォームにより564環境・86タスク・ 350時間の76,000軌道データを収集し公開 • Franka Emika Panda +
Robotiq 2F-85 Gripper + 2×ZED2 + ZED Mini • Oculus Quest 2による6DOFマニピュレーション [A. Khazatsky+, RSS2024]
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 83
データ拡張 • ロボットにおけるデータ拡張は かなり難しい • 通常の画像処理であれば, 画像の 拡大縮小・クロップ・平行移動な どが可能だが, ロボットには身体性
があり, 身体とカメラの位置関係に は意味がある • 拡散モデルを用いたテクスチャな どの変化が行われる 84 Imgaug, A. Jung+
GenAug 85 • 画像を拡散モデルで大量に拡張して学習に利用 • 背景の変化, distractorの追加, 現在物体のテクスチャ変化, 別物体の配置によりロバスト性を大きく向上 [Z.
Chen+, RSS2023]
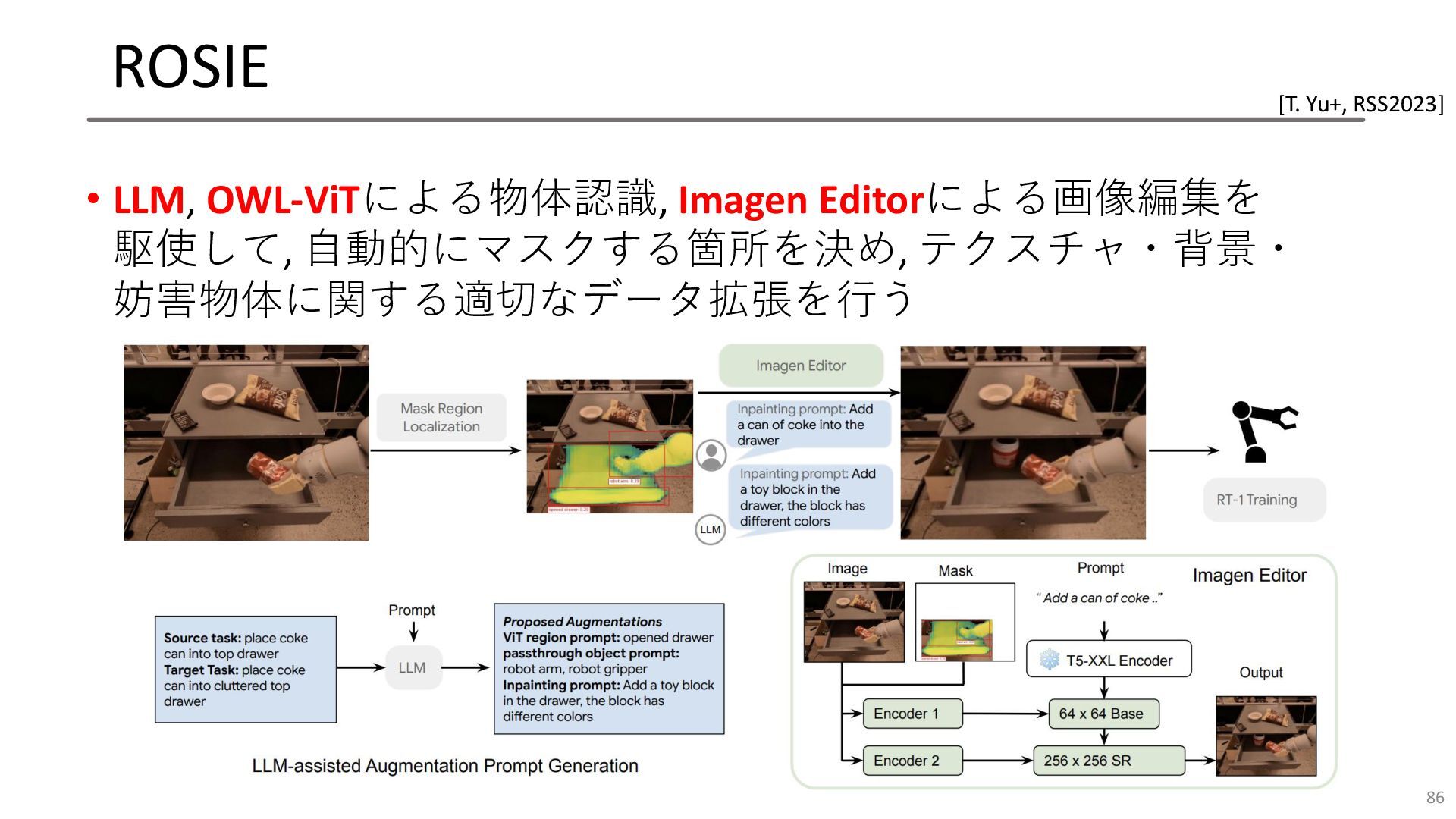
ROSIE • LLM, OWL-ViTによる物体認識, Imagen Editorによる画像編集を 駆使して, 自動的にマスクする箇所を決め, テクスチャ・背景・ 妨害物体に関する適切なデータ拡張を行う
86 [T. Yu+, RSS2023]
ROSIE 87 [T. Yu+, RSS2023]
DIAL 88 • 少量のアノテーションから軌道と言語の間のCLIPをFine-Tuning • CLIPを用いて, LLMで増やした大量の言語指示例のうち, 類似度の 高い言語指示top-Kを得て, データを増やしてVLAの学習に利用
[T. Xiao+, RSS2023]
データ拡張ってどうなの? • 最近は研究自体かなり少ない • 拡張するよりも現実世界のデータの方が綺麗 • 非常にリッチな実世界のデータセットが公開されるようになった • CLIP, SigLIP,
DINOv2のような優秀な特徴量抽出モジュールが増えた 89
今日のチュートリアルの流れ Vision-Language-Actionモデルの • 歴史 • アーキテクチャ • ロボット • データ収集
• データセット • データ拡張 • ベンチマーク 90
VLAのベンチマーク • VLAの評価指標は与えられたタスクの成功率の場合がほとんど • これを各機関のロボット実機で評価・比較することはほぼ不可能 • ほとんどのベンチマークはシミュレーション上で構築されています 91 AI2-THOR RLBench
COLOSSEUM CALVIN SIMPLER RoboArena ManiSkill ManiSkill 2 ManiSkill 3 ManiSkill-HAB robosuite robomimic RoboCasa LIBERO Habitat Habitat 2.0 Habitat 3.0 Meta-World
CALVIN 92 [O. Mees+, RA-L, 2022] • 自然言語に従った長期的なロボット操作タスクの公開ベンチマーク • 7自由度ロボットアーム(Franka
Emika Panda)による34の基本タスク • 見た目や配置の異なるA/B/C/D 4つの環境をPyBulletで構築 • 固定と手首のRGB-D画像, 触覚画像が得られる
LIBERO • CALVINと同様に頻繁に用いられる言語操作タスクのベンチマーク • MuJoCoを使ったRobosuiteがベース + Franka Emika Panda •
130のタスクを含む4つのカテゴリを備え, それぞれ問う知識が異なる • LIBERO-SPATIAL: 空間知識 • 同一物体の異なる配置 • LIBERO-OBJECT: 物体知識 • 異なる物体を扱う • LIBERO-GOAL: 動作知識 • 同じ状況/ゴールのみ異なる • LIBERO-100: 複合タスク 93 [B. Liu+, NeurIPS2023]
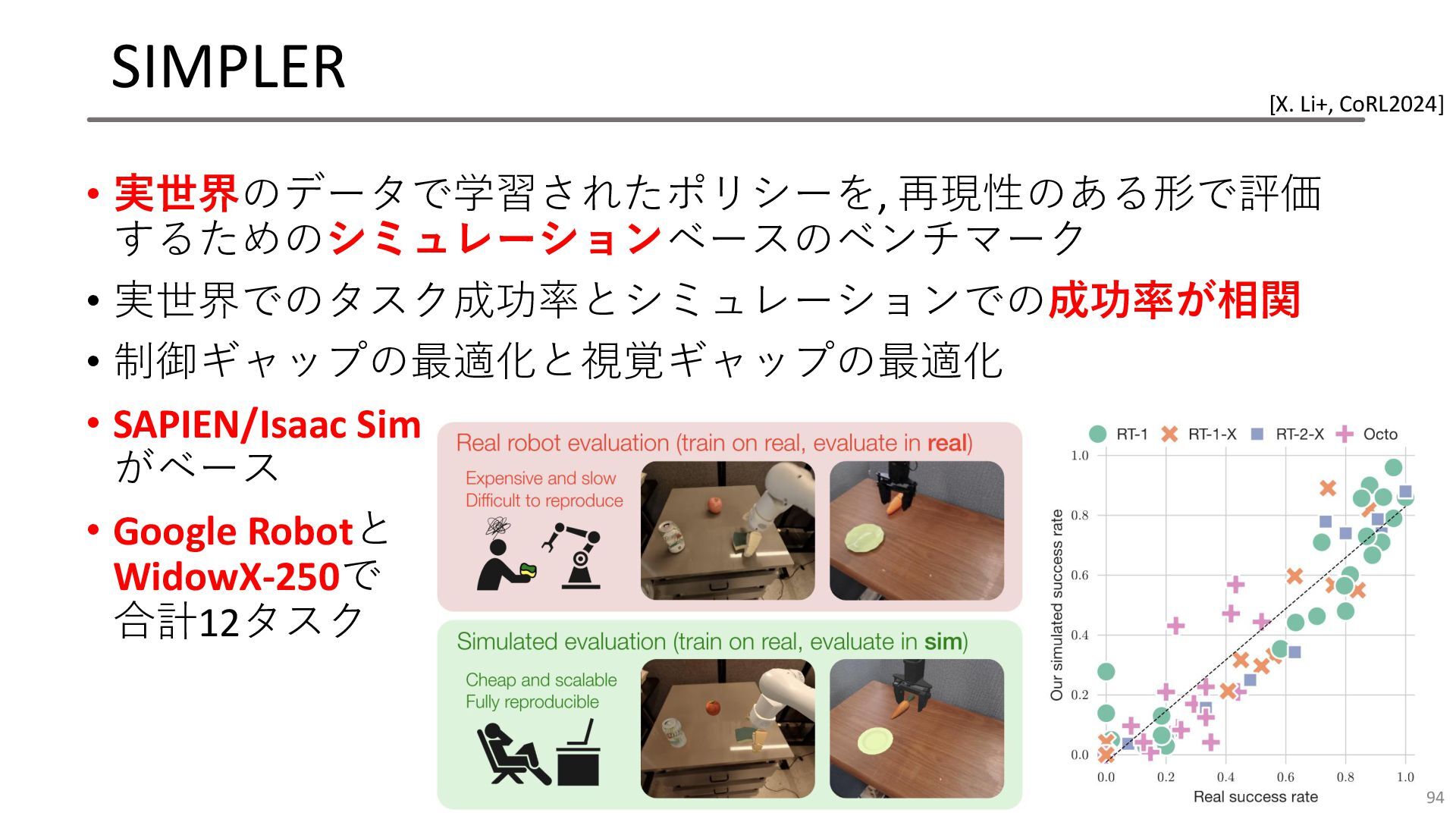
SIMPLER • 実世界のデータで学習されたポリシーを, 再現性のある形で評価 するためのシミュレーションベースのベンチマーク • 実世界でのタスク成功率とシミュレーションでの成功率が相関 • 制御ギャップの最適化と視覚ギャップの最適化 •
SAPIEN/Isaac Sim がベース • Google Robotと WidowX-250で 合計12タスク 94 [X. Li+, CoRL2024]
RoboArena • VLAの現実世界での性能評価を, 大規模かつ公平・信頼性を持って 行うための分散評価フレームワーク • 各拠点(7大学)でDROIDプラットフォームを用意, 任意のタスク・ 環境でA/Bテストを実施し, グローバルなランキングを生成
95 [P. Atreya+, arXiv, 2025]
まとめ • なぜロボット基盤モデル(VLA)なのか? • VLAの歴史 •VLAのアーキテクチャ • VLAで扱うロボット • VLAのためのデータ収集
• VLAにおけるデータセット • VLAのデータ拡張 •VLAの評価 96
RTシリーズについて •Data-centric AI本で! • 第5章 ロボットデータ • はじめに • RTシリーズの概要
• 多様なロボット • ロボットにおけるデータ収集 • データセット • データ拡張 • おわりに 97
基盤モデル全般について • ロボットと基盤モデルがどう融合する のか, その全体像を理解いただけます • 8/29発売予定!予約してね! 98
99 Thank You!
{kind=link}
{kind=link}
![3 Kengoro [Y. Asano+, Humanoids2016] [K. Kozuki+, IROS2016]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_2.jpg){kind=link}
![4 Kengoro [Y. Asano+, IROS2016] [T. Makabe, K. Kawaharazuka+, Humanoids2018]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_3.jpg){kind=link}
![5 Musashi [K. Kawaharazuka+, RA-Magazine/ICRA2021]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_4.jpg){kind=link}
![6 CubiXGo1 [S. Inoue, K. Kawaharazuka+, Advanced Robotics Research, 2025]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![基盤モデル×ロボットの二種類の方向性 12 LLMやVLMの活用 ロボット基盤モデル(VLA) SayCan [M. Ahn+, CoRL2022] RT-X [Open](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_11.jpg){kind=link}
{kind=link}
![ですが今回は… 14 LLMやVLMの活用 ロボット基盤モデル(VLA) SayCan [M. Ahn+, CoRL2022] RT-X [Open](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_13.jpg){kind=link}
![ロボット基盤モデルは何ができているのか 15 RT-1 [Google Research, 2022] https://www.youtube.com/watch?v=UuKAp9a6wMs](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_14.jpg){kind=link}
![ロボット基盤モデルは何ができているのか 16 AutoRT [Google DeepMind, 2024] https://auto-rt.github.io/](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_15.jpg){kind=link}
![ロボット基盤モデルは何ができているのか 17 [Physical Intelligence (π), 2024] https://www.physicalintelligence.company/blog/pi0](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_16.jpg){kind=link}
![ロボット基盤モデルは何ができているのか 18 GR00T N1 [NVIDIA, 2025] https://www.youtube.com/watch?v=m1CH-mgpdYg](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_17.jpg){kind=link}
![ロボット基盤モデルは何ができているのか 19 Helix [Figure, 2025] https://www.figure.ai/news/helix](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_18.jpg){kind=link}
{kind=link}
![そもそも、なんでロボット基盤モデル? 21 SayCan [M. Ahn+, CoRL2022] https://say-can.github.io/](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CLIPort 29 [M. Shridhar, CoRL2021] • End-to-EndなVLAとしては最も原始的なモデル • CLIPによる言語情報と視覚情報の抽出 •](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_28.jpg){kind=link}
{kind=link}
![VIMA 31 [Y. Jiang+, ICML2023] • ゴール画像やテキストを含む多様なタスク指示が可能な Encoder-Decoder型のTransformer • Mask](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RT-Trajectory • 手先の軌道を入力としたアクション生成を行う • この他にも自動データ収集のAutoRTや速度向上に向けたSARA-RTなど 36 [J. Gu+, ICLR2024]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![𝜋0 43 [Physical Intelligence (π), 2024] https://www.physicalintelligence.company/blog/pi0](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mobile ALOHA 73 [Z. Fu+, CoRL2024] • ALOHAと台車型ロボットが合体し, マニピュレーションだけでなく, ナビゲーションのデータ収集・学習ができるように](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_72.jpg){kind=link}
![Open-Television 74 [X. Cheng+, CoRL2024] • Apple Vision Proを使った手首・指・頭の姿勢推定をヒューマノイド に反映しテレオペレーション](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_73.jpg){kind=link}
{kind=link}
![Project Aria 76 [Meta, arXiv, 2023] • コンパクトなスマートグラスにより, 人間の一人称視点からの行動 を記録,](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![BridgeData V2 80 [H. Walke+, CoRL2023] • 実世界の大規模・多様なタスクのデータセット • WidowX-250/24種類の環境/13のスキルの60,000軌道データ](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_79.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ROSIE 87 [T. Yu+, RSS2023]](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_86.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CALVIN 92 [O. Mees+, RA-L, 2022] • 自然言語に従った長期的なロボット操作タスクの公開ベンチマーク • 7自由度ロボットアーム(Franka](https://files.speakerdeck.com/presentations/11acec1a4f1747b68cd1ef2cccee890f/slide_91.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}