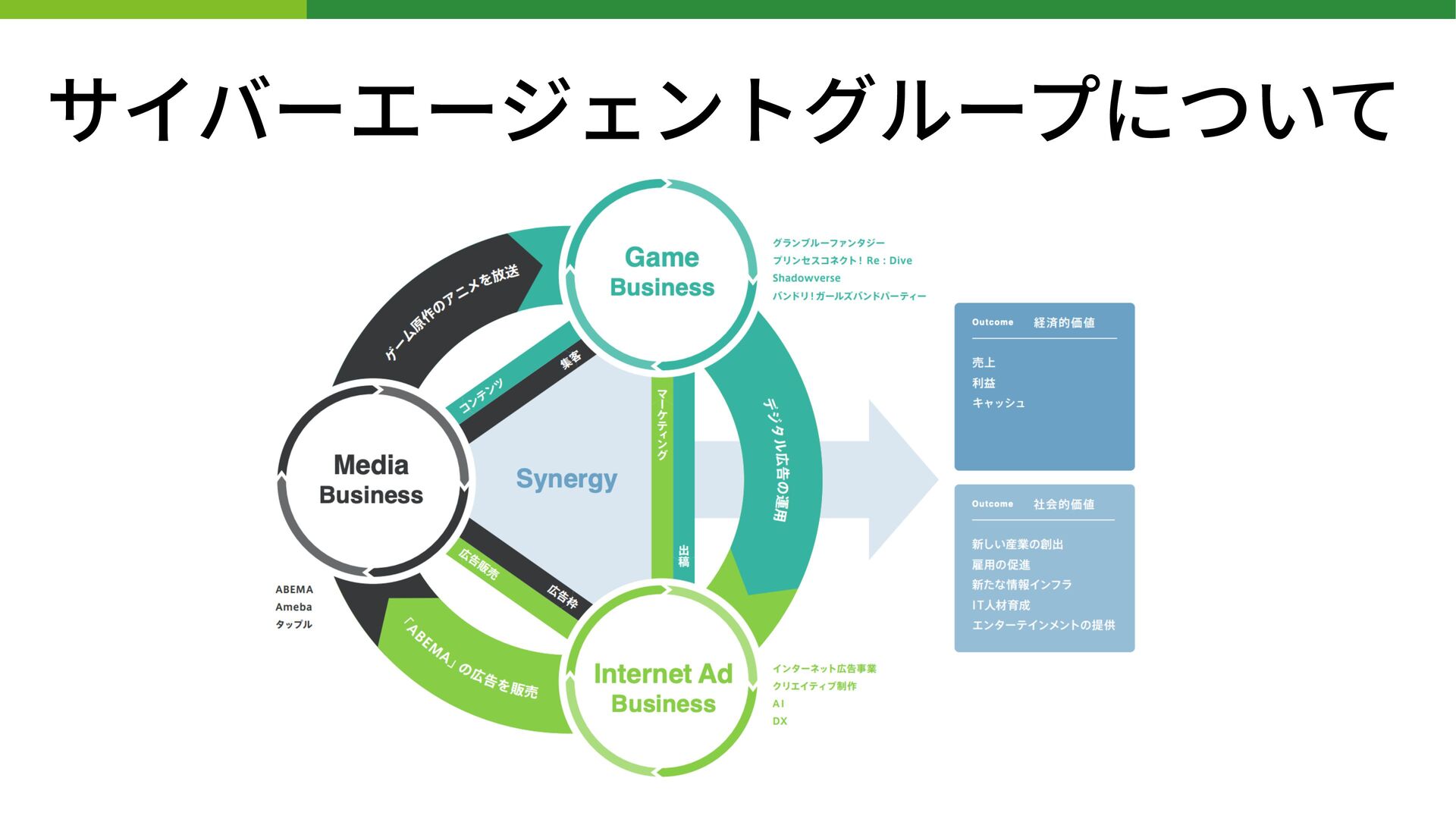
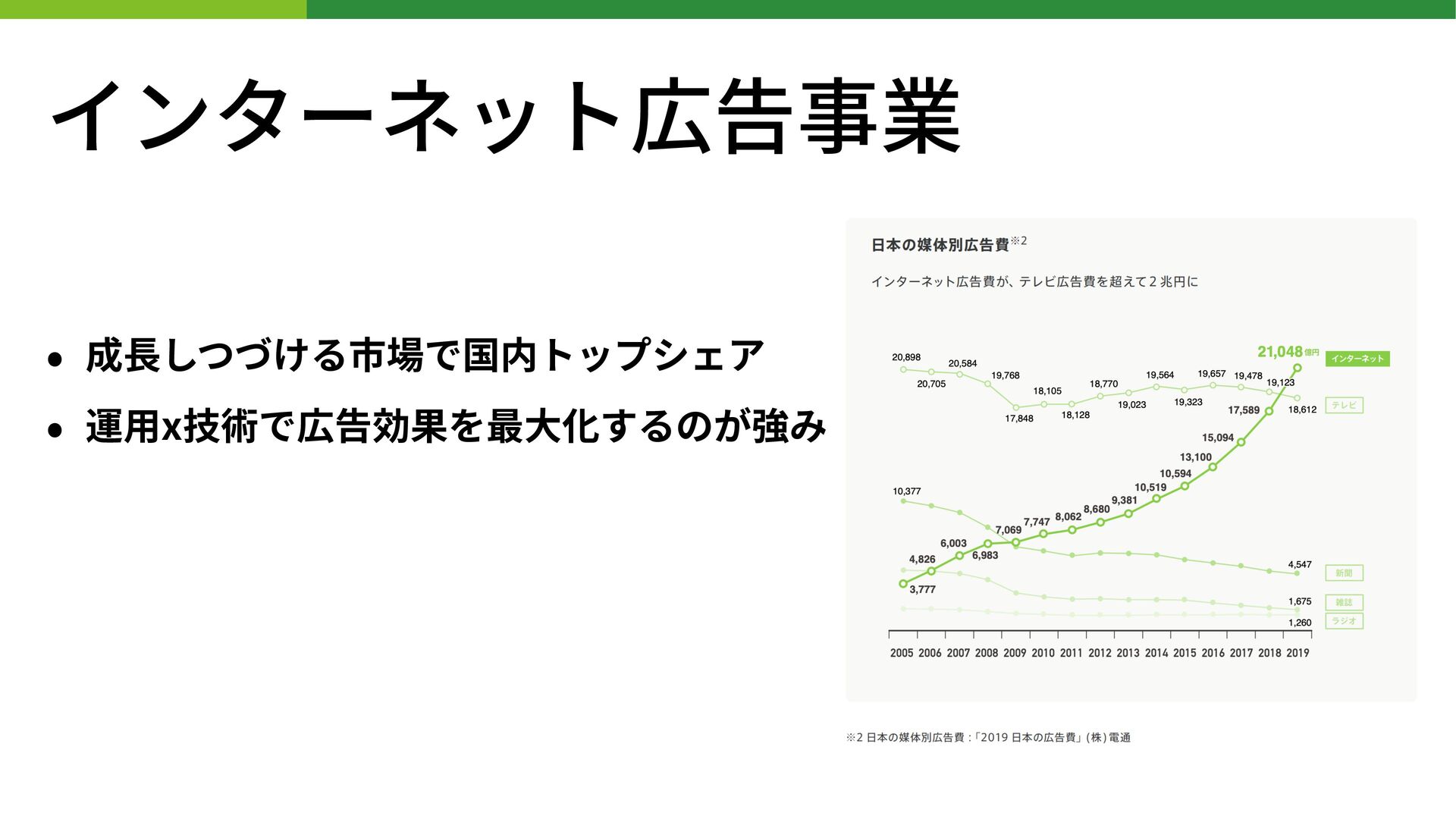
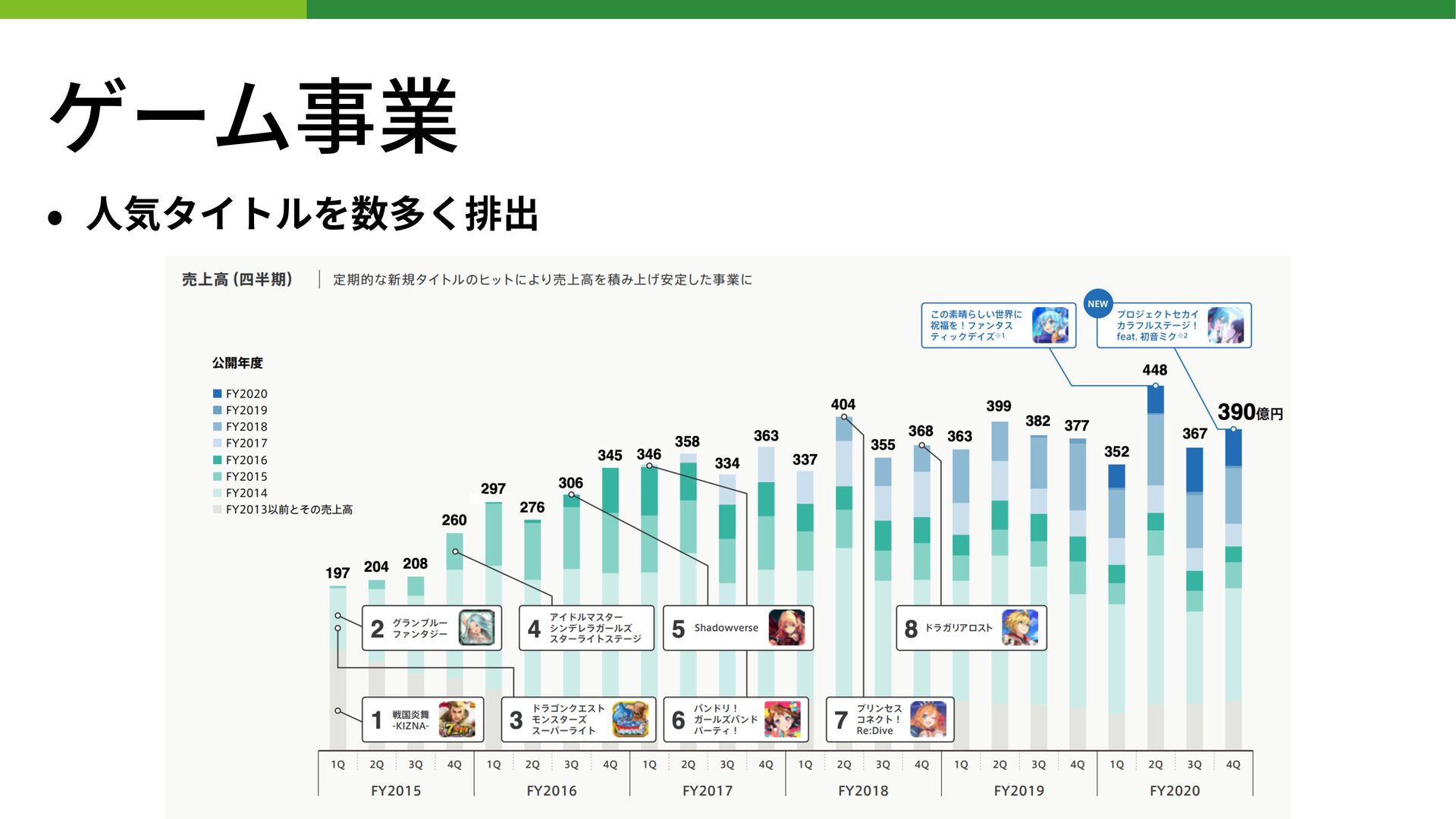
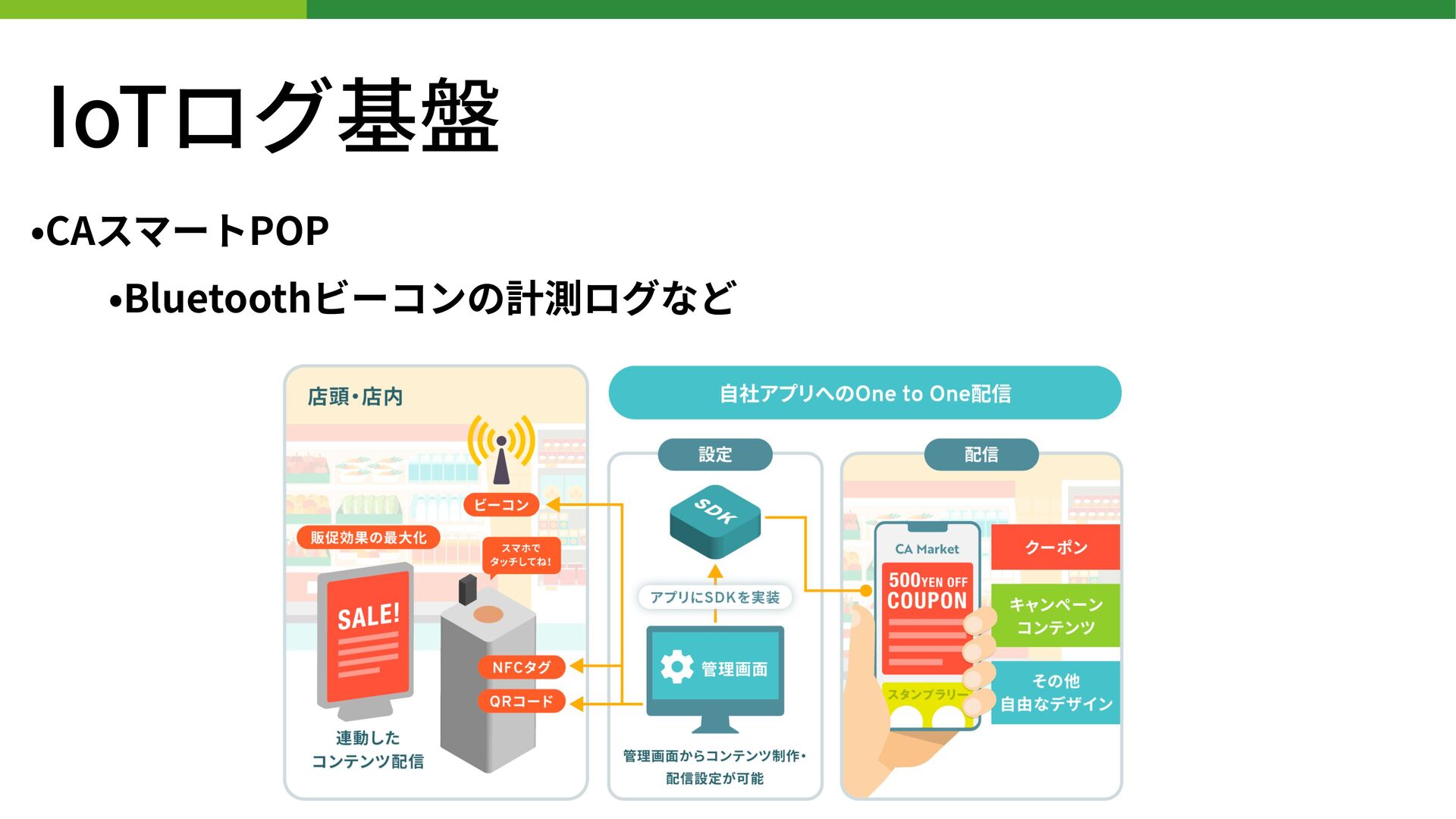
BUILD.localイベントはコミュニティメンバーによってリードされており、「BUILD」の名の通り、データアプリケーション、データサイエンス、データエンジニアリング、そしてデータシェアリングの領域でイノベーションを作り上げている人たちのためのイベントです。
https://usergroups.snowflake.com/events/details/snowflake-japan-presents-buildlocal-japan-snowparkdexi-ufei-gou-zao-deta-playing-with-unstructured-data-using-snowpark/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}