AI技術開発1部 部長 経歴 April 2020 - July 2025 グループマネージャ@GO April 2019 - March 2020 AI研究開発エンジニア@DeNA April 2010 - March 2019 研究員@三菱電機 March 2010 博士@東北大学 https://dcai-jp.connpass.com/ https://gihyo.jp/book/2025/978-4-297-14663-4
Tonini et al., “Object-aware gaze target detection,” ICCV, 2023. [3] https://www.isus.jp/wp-content/uploads/openvino/2024/docs/omz_models_model_gaze_estimation_adas_0002.html [4] http://gazefollow.csail.mit.edu/explore.html [5] E. Chong et al., ”Detecting attended visual targets in video,” CVPR, 2020. [6] A. Recasens et al., ”Where are they looking?,” NIPS, 2015. [7] A. Gupta et al., “A modular multimodal architecture for gaze target prediction: Application to privacy-sensitive settings,” CVPR Workshops, 2022. [8] S. Tafasca et al., “Sharingan: A Transformer architecture for multi-person gaze following,” CVPR, 2024. [9] M. Oquab et al., “DINOv2: Learning robust visual features without supervision,” arXiv:2304.07193, 2023. [10] Q. Miao et al., “Patch-level gaze distribution prediction for gaze following,” WACV, 2023. [11] D. Tu et al., “End-to-end human-gaze-target detection with Transformers,” CVPR, 2022.
{kind=link}
{kind=link}
{kind=link}
![© GO Drive Inc. 4 視線推定と注視対象推定の違い[2] 視線推定 (gaze estimation) •](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_3.jpg){kind=link}
{kind=link}
![© GO Drive Inc. 6 注視対象推定タスクとマルチブランチ手法の提案[6] • MS COCO等の既存データセットから人物が写った画像を選定し、注視対象をアノテーシ ョンしたGazeFollowデータセットを公開](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_5.jpg){kind=link}
![© GO Drive Inc. 7 マルチモーダルへの拡張[7] • 頭部をクロップした画像から視線を推定し、その結果を画像全体、姿勢、デプスの各モダ リティと連結したうえで特徴を抽出(姿勢とデプスはoff-the-shelfモデルで推論) •](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_6.jpg){kind=link}
![© GO Drive Inc. 8 Transformerの活用[8] CVPR’24 • 複数人の注視対象推定を同時に行うTransformerベースのアーキテクチャを提案 •](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_7.jpg){kind=link}
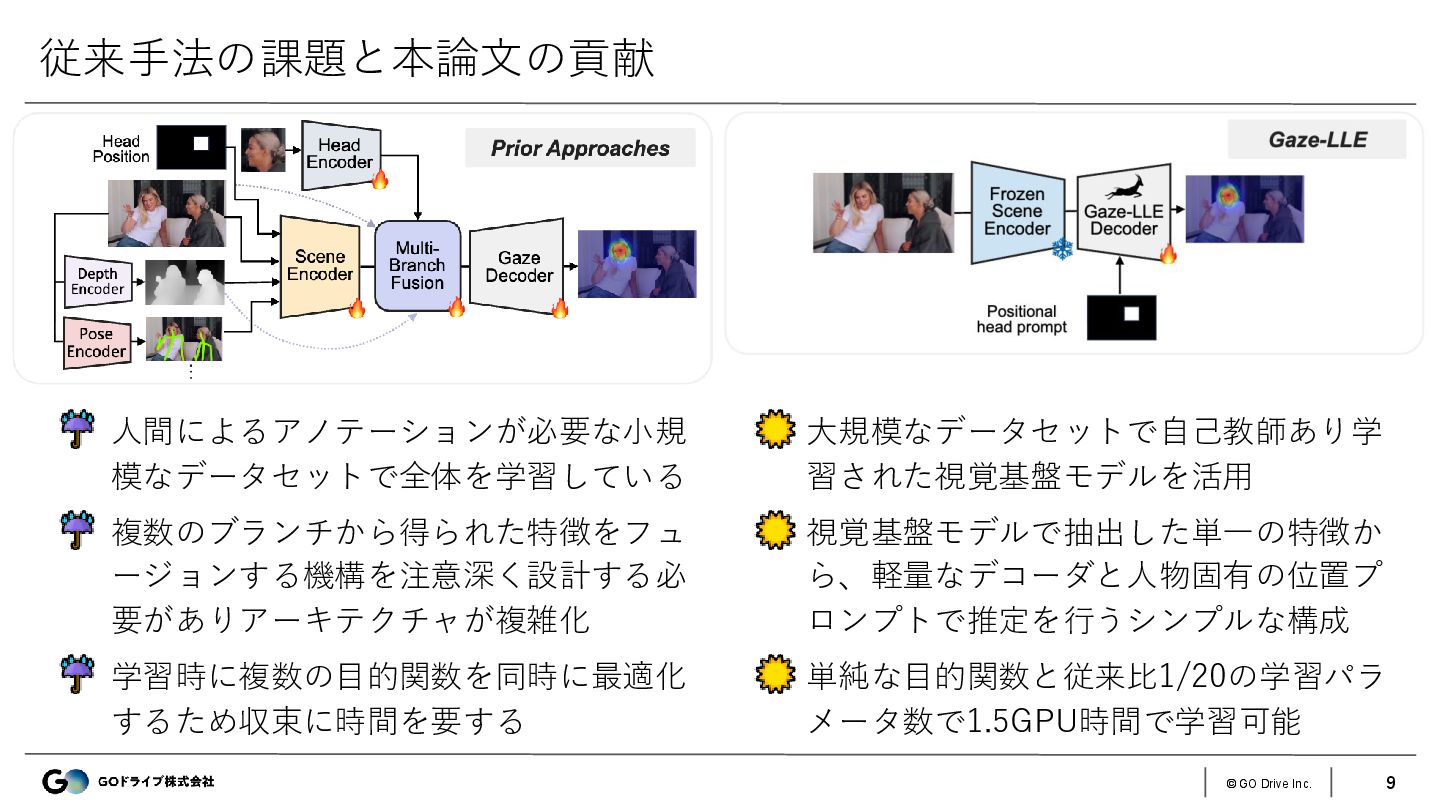{kind=link}
![© GO Drive Inc. 10 視覚基盤モデル -DINOv2 [9]- DINOv2で抽出されたパッチ特徴量を列方向の画像間でPCAして得られた最初の 3つの主成分の可視化結果(教師なし学習であるにも関わらず前景背景分離やパ](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_9.jpg){kind=link}
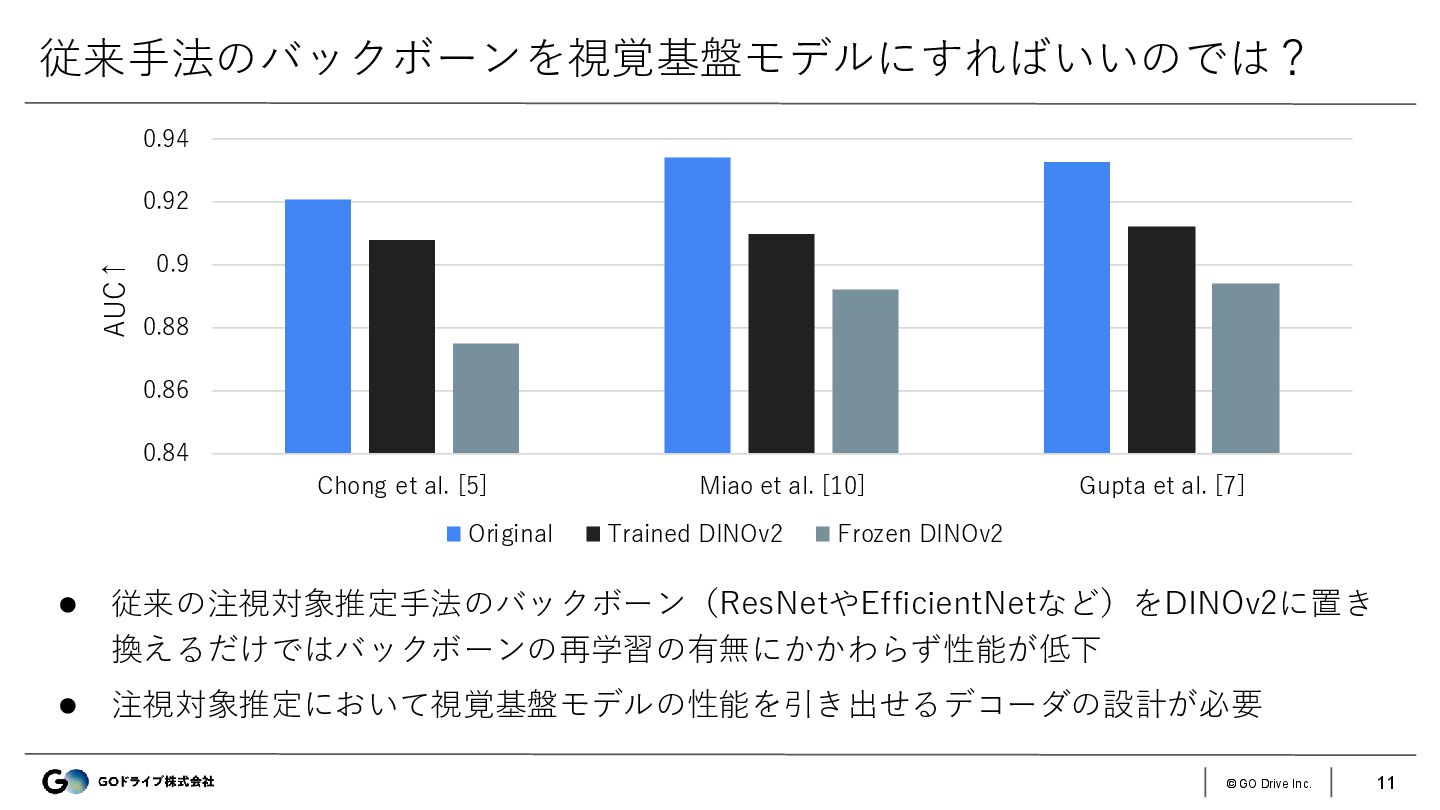{kind=link}
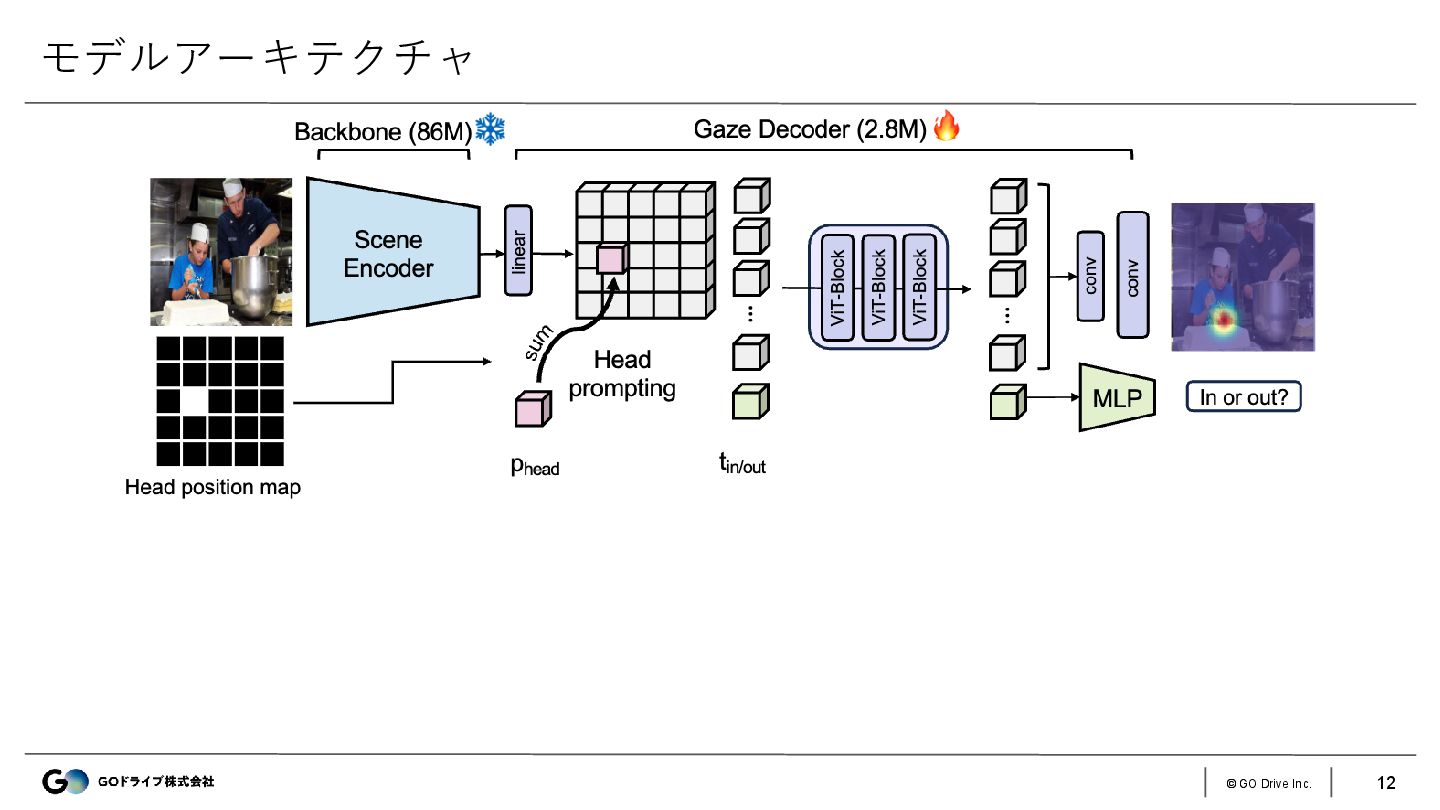{kind=link}
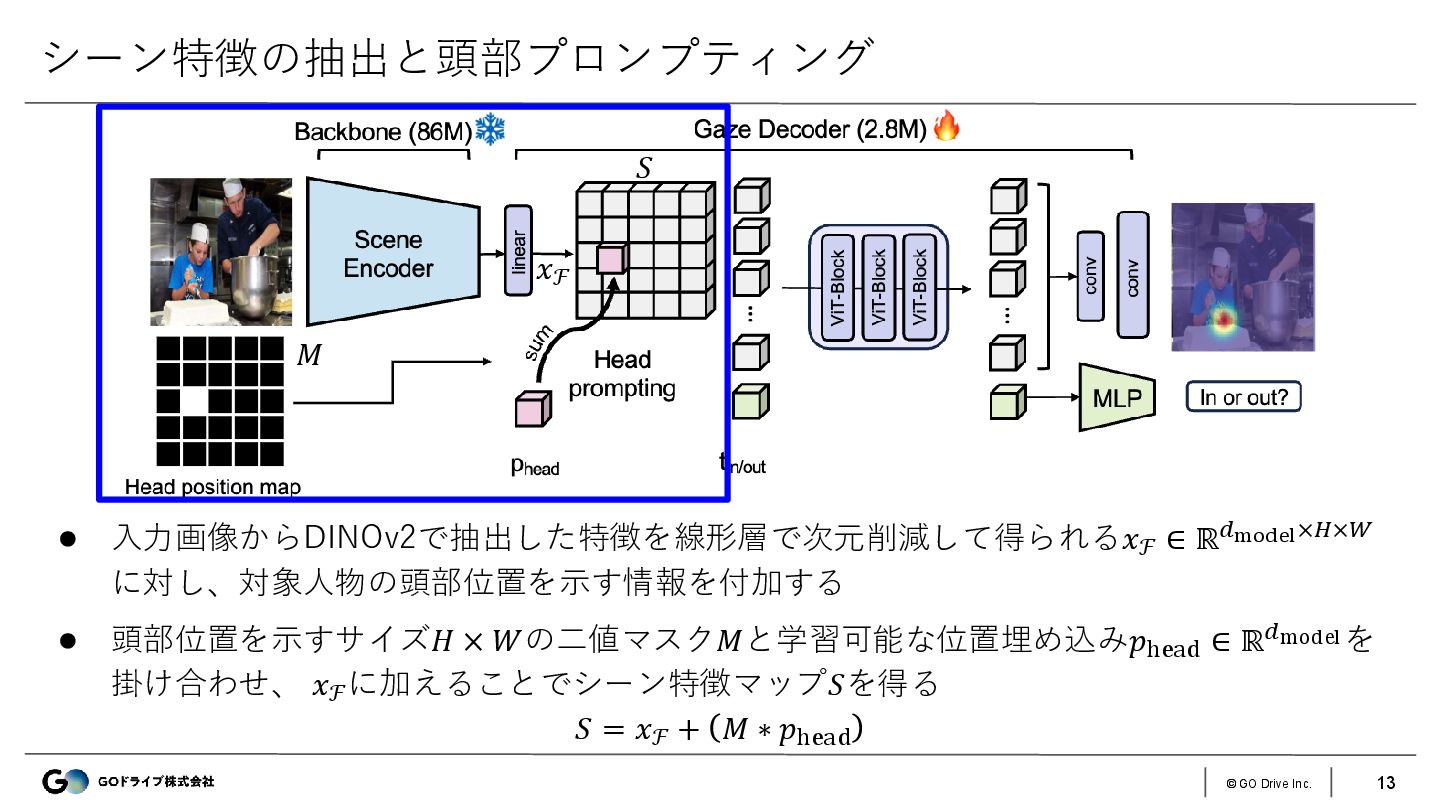{kind=link}
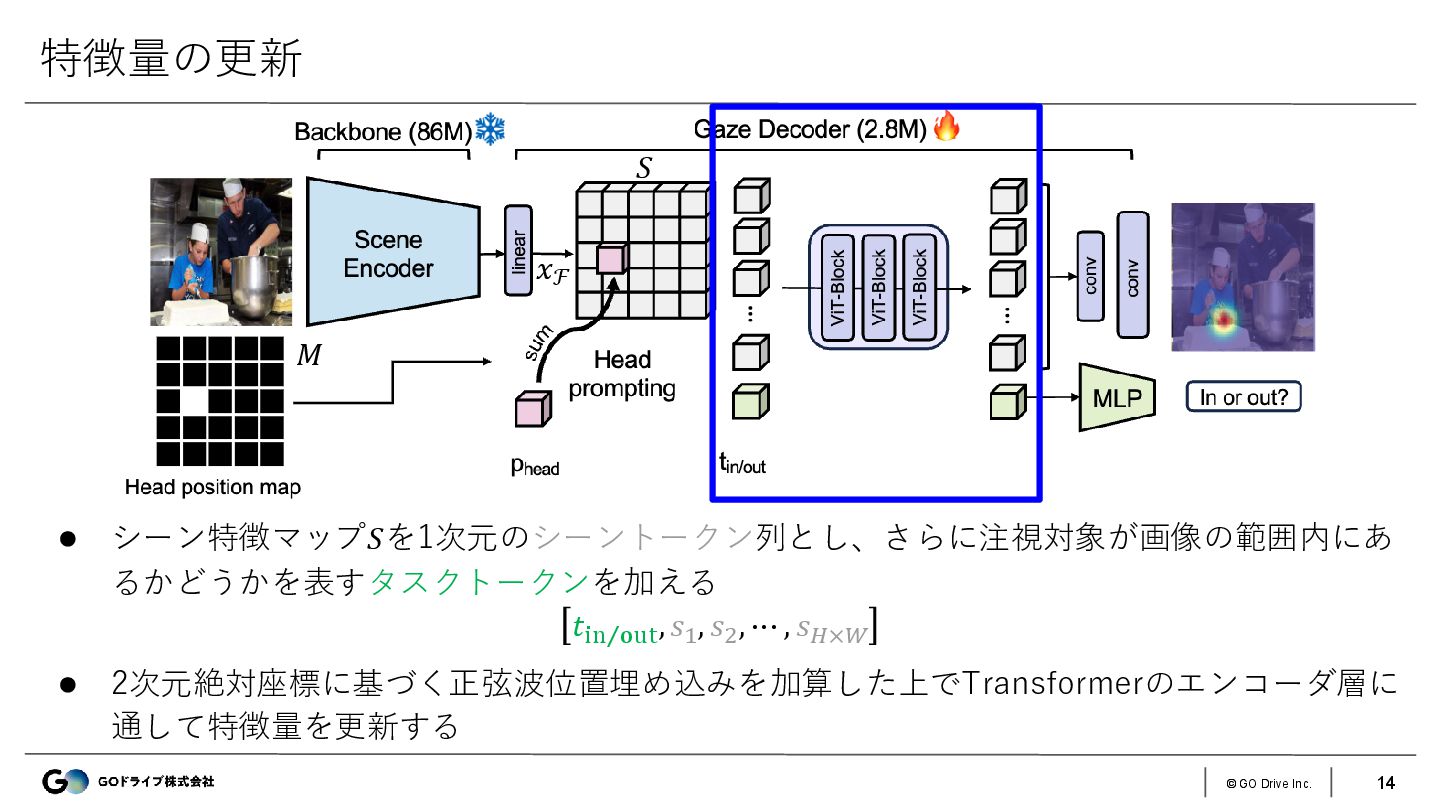{kind=link}
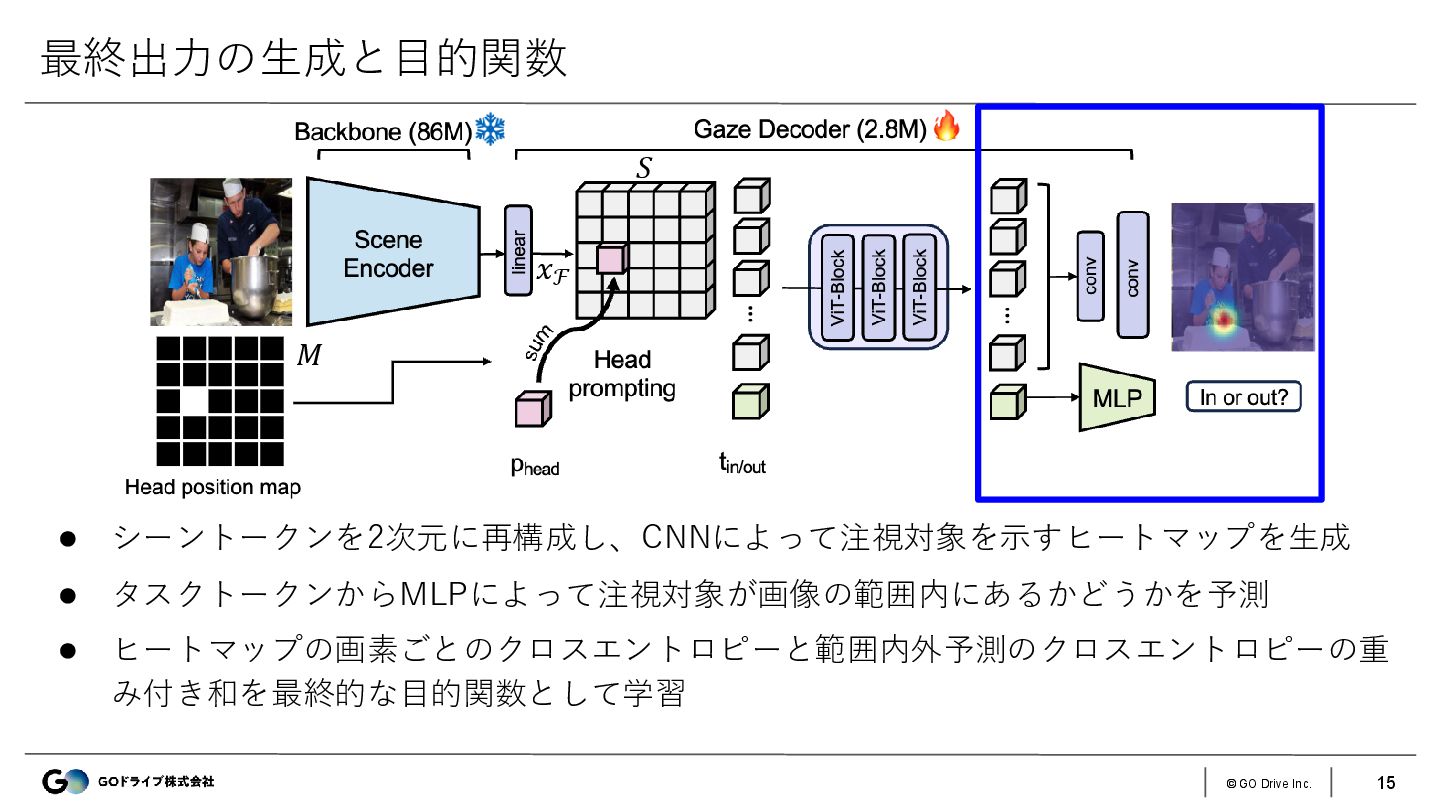{kind=link}
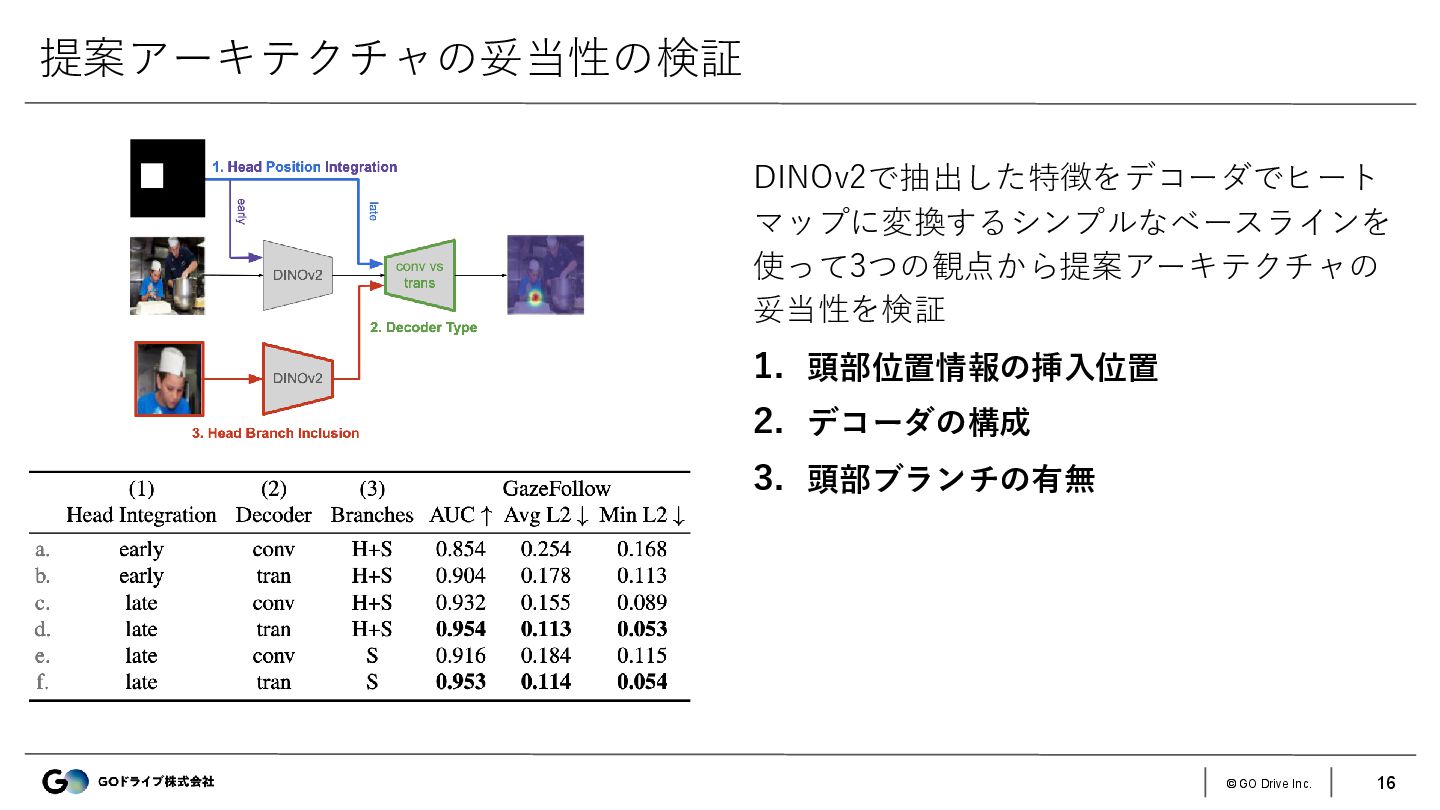{kind=link}
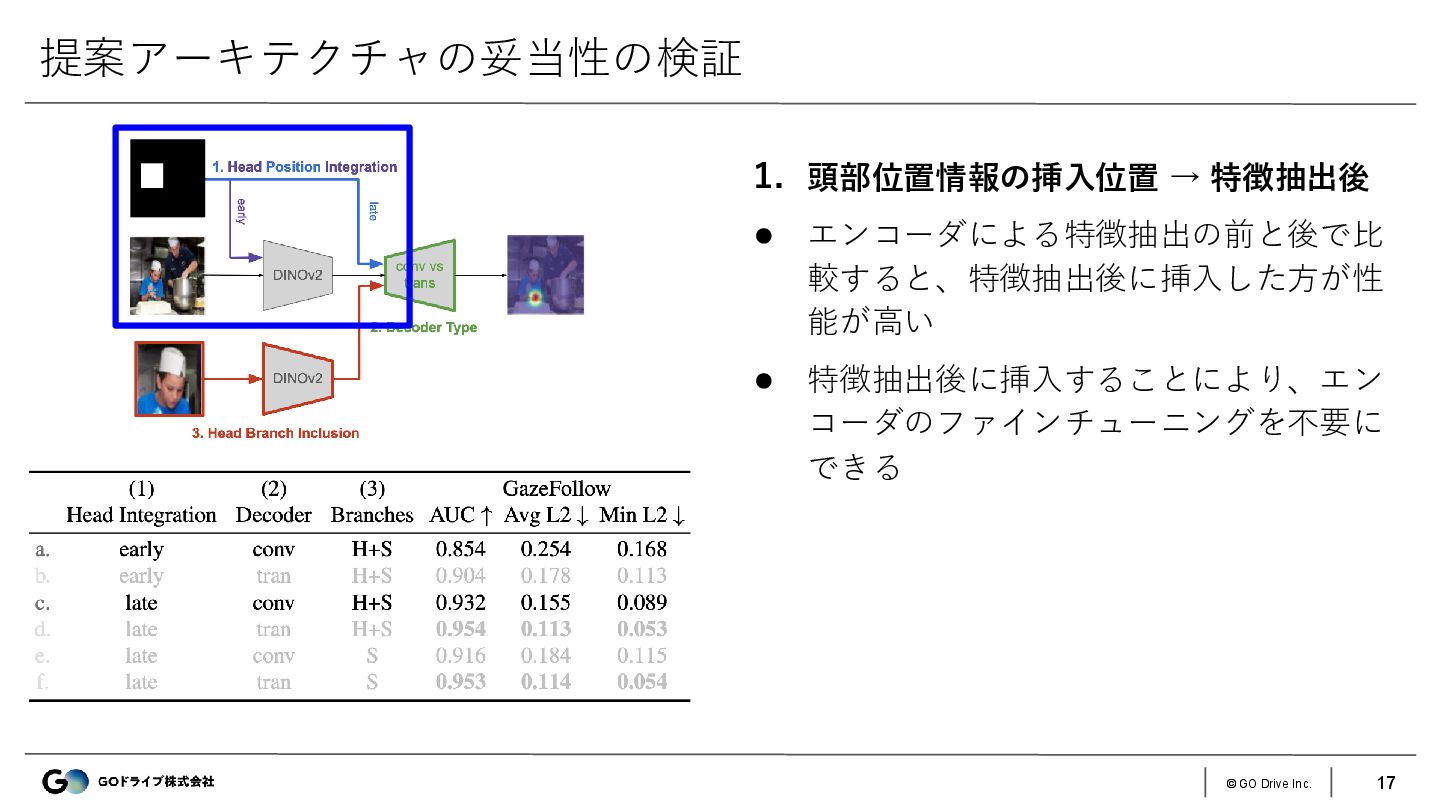{kind=link}
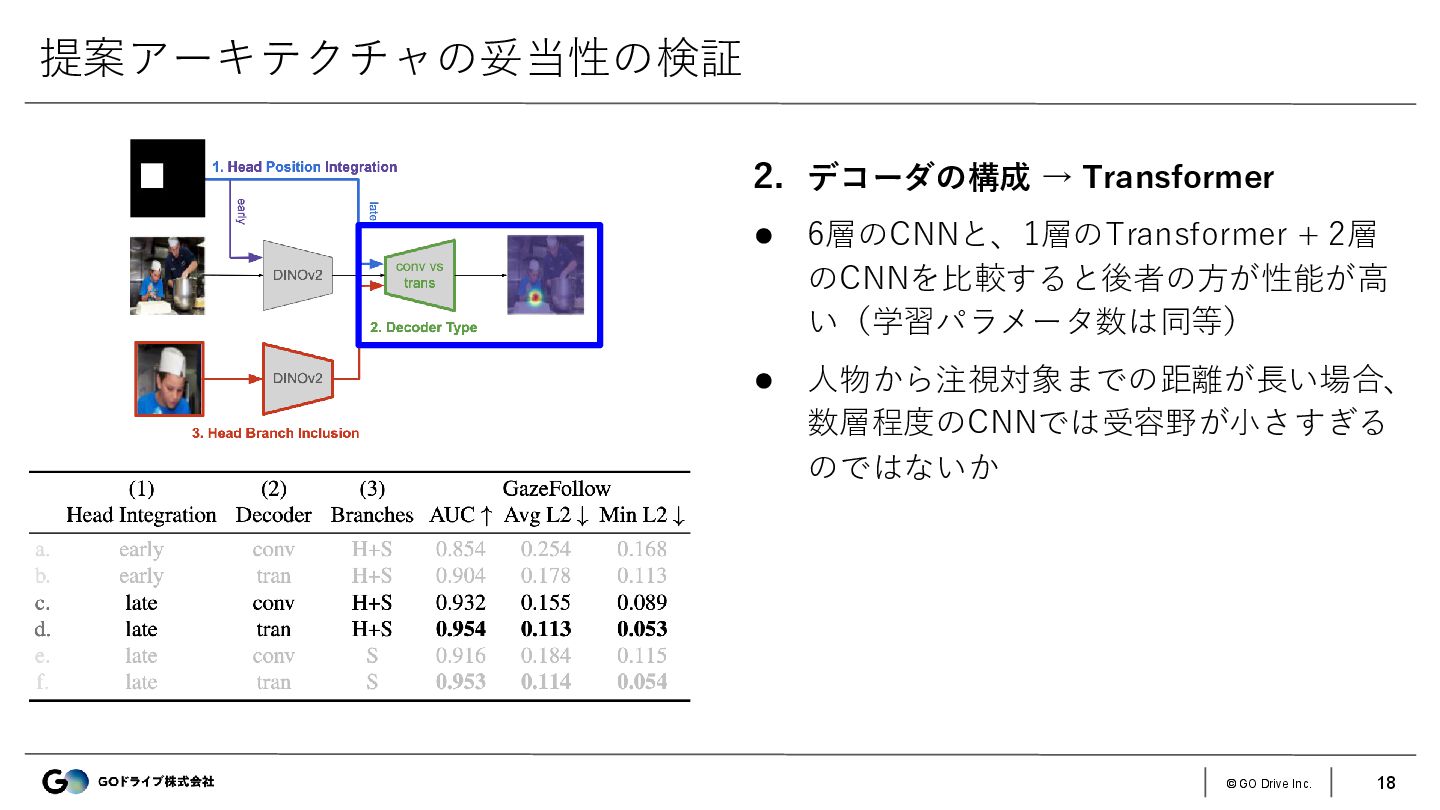{kind=link}
{kind=link}
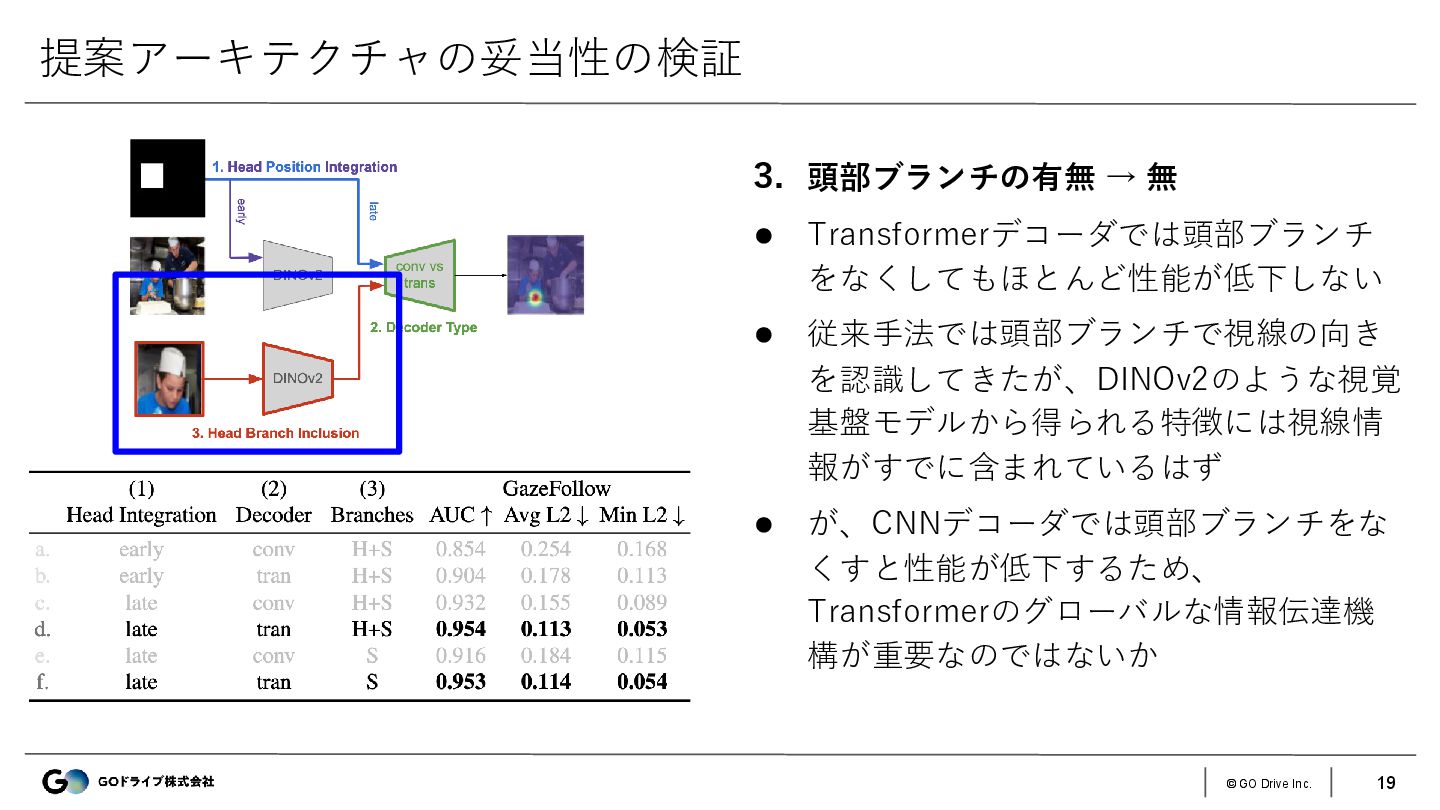
{kind=link}
{kind=link}
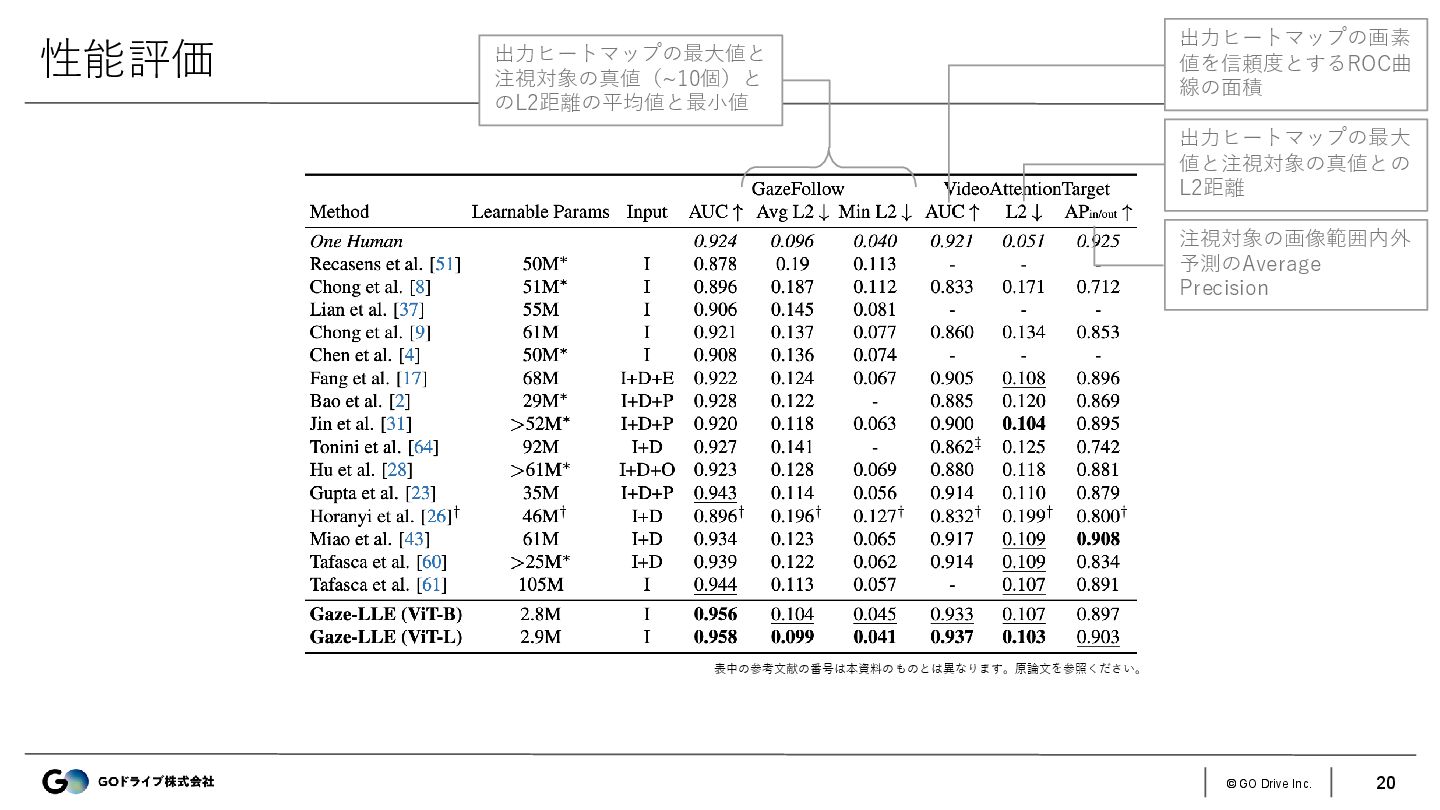
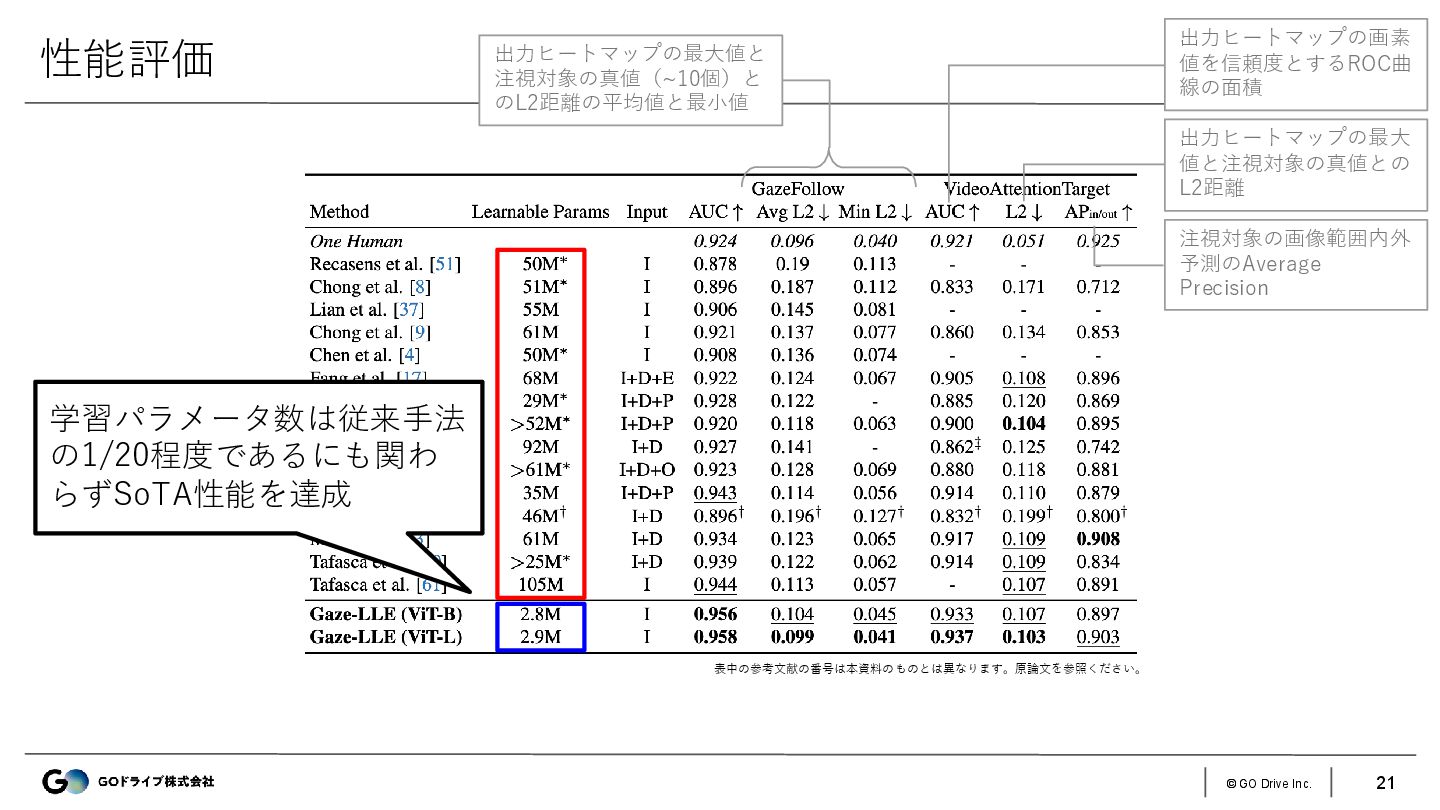
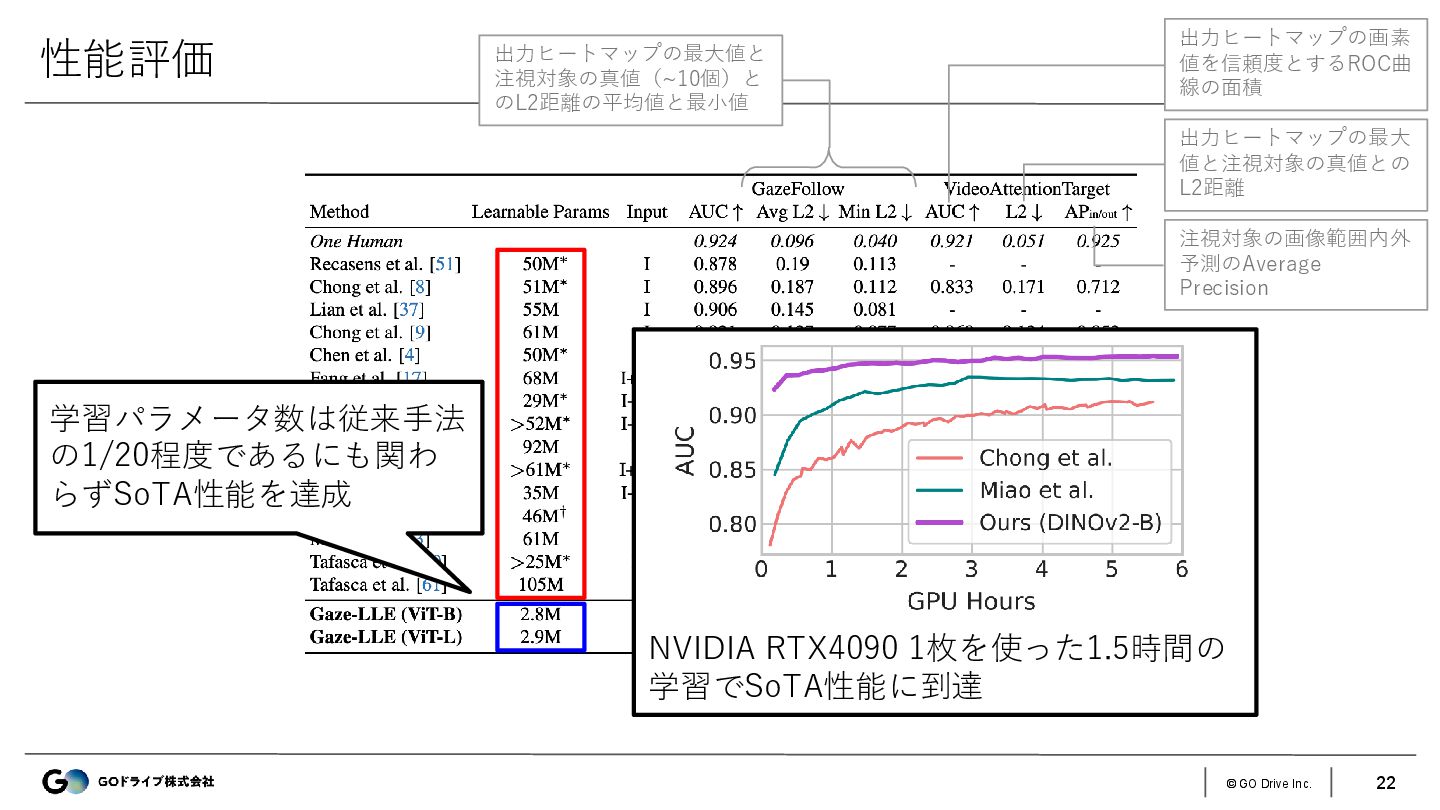{kind=link}
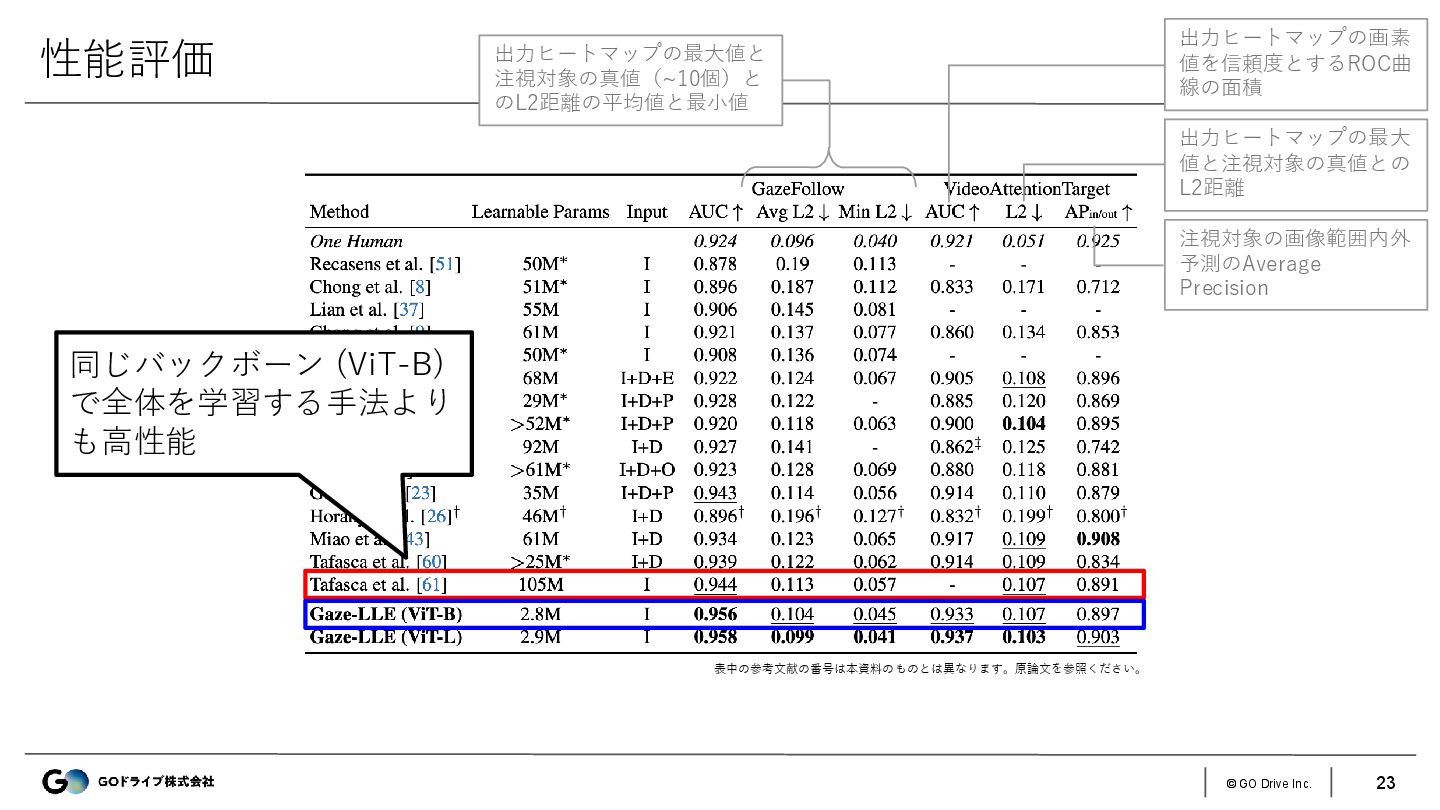{kind=link}
{kind=link}
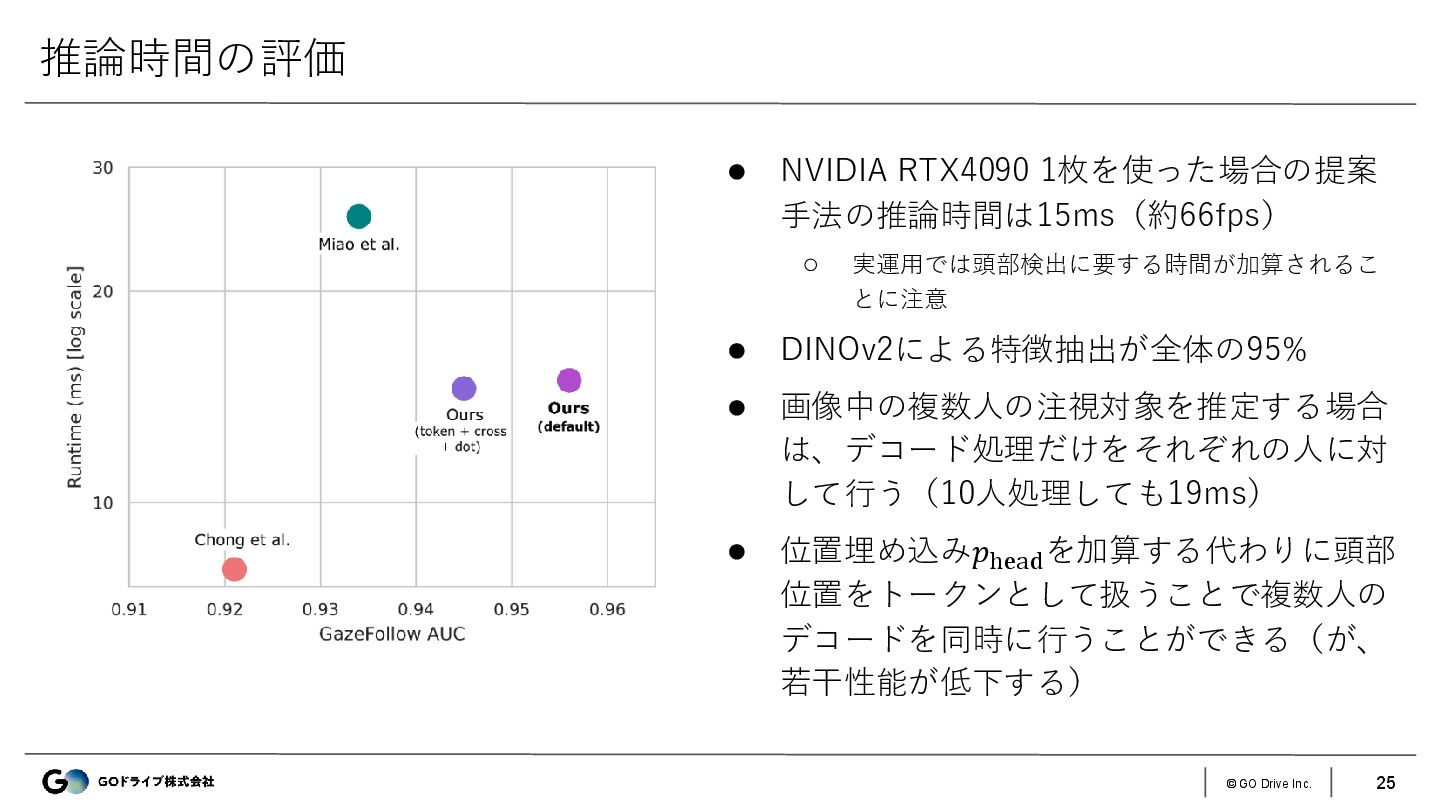{kind=link}
{kind=link}
{kind=link}
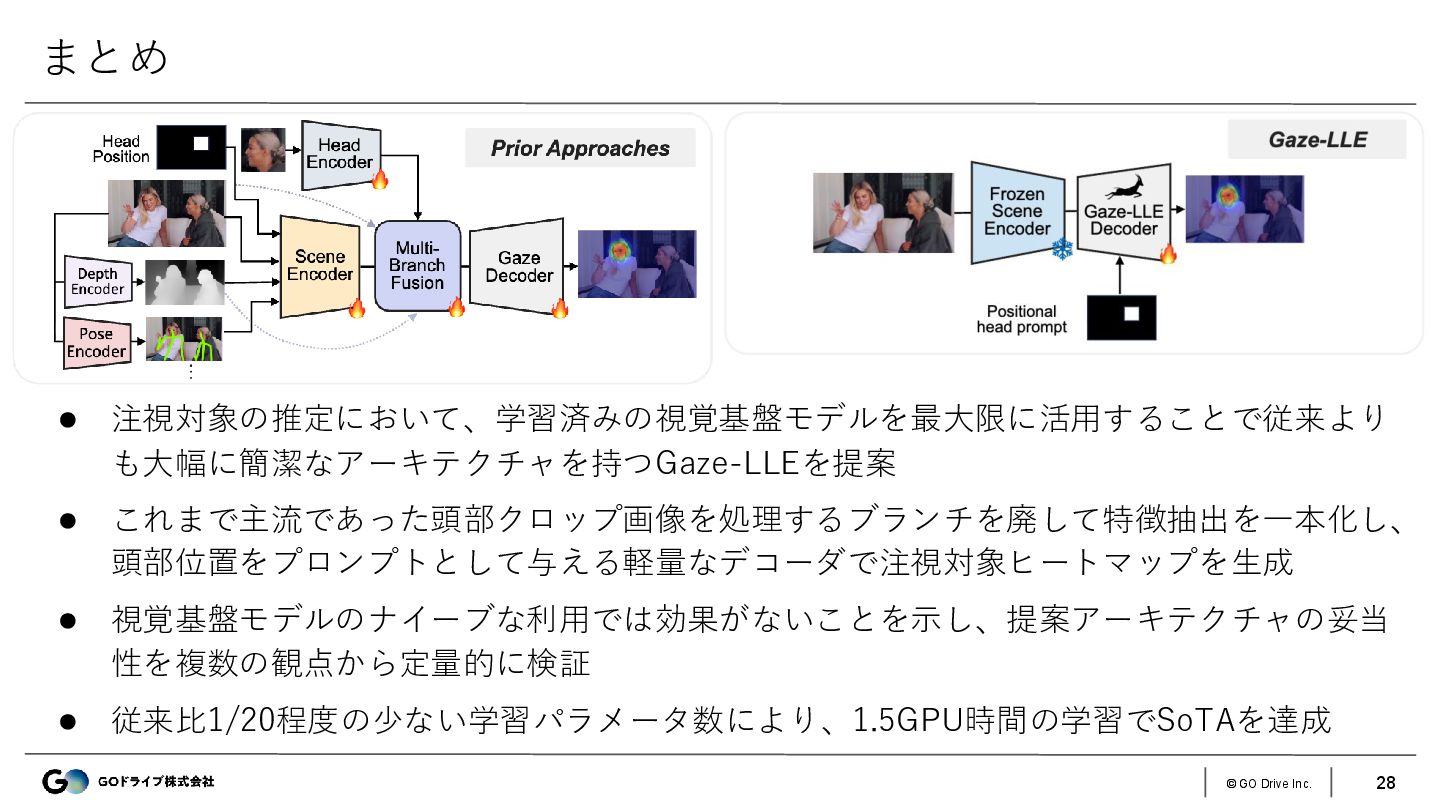{kind=link}
![© GO Drive Inc. 29 所感 Gaze-LLEのFig.1 [11]のFig.1 • 基盤モデルを使って従来手法よりもアーキテクチャをシンプルにしつつ性能も改善する](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_28.jpg){kind=link}
![© GO Drive Inc. 30 参考文献 [1] https://github.com/fkryan/gazelle [2] F.](https://files.speakerdeck.com/presentations/d558aa19794b4556aeb8bb4cf3e75235/slide_29.jpg){kind=link}
{kind=link}
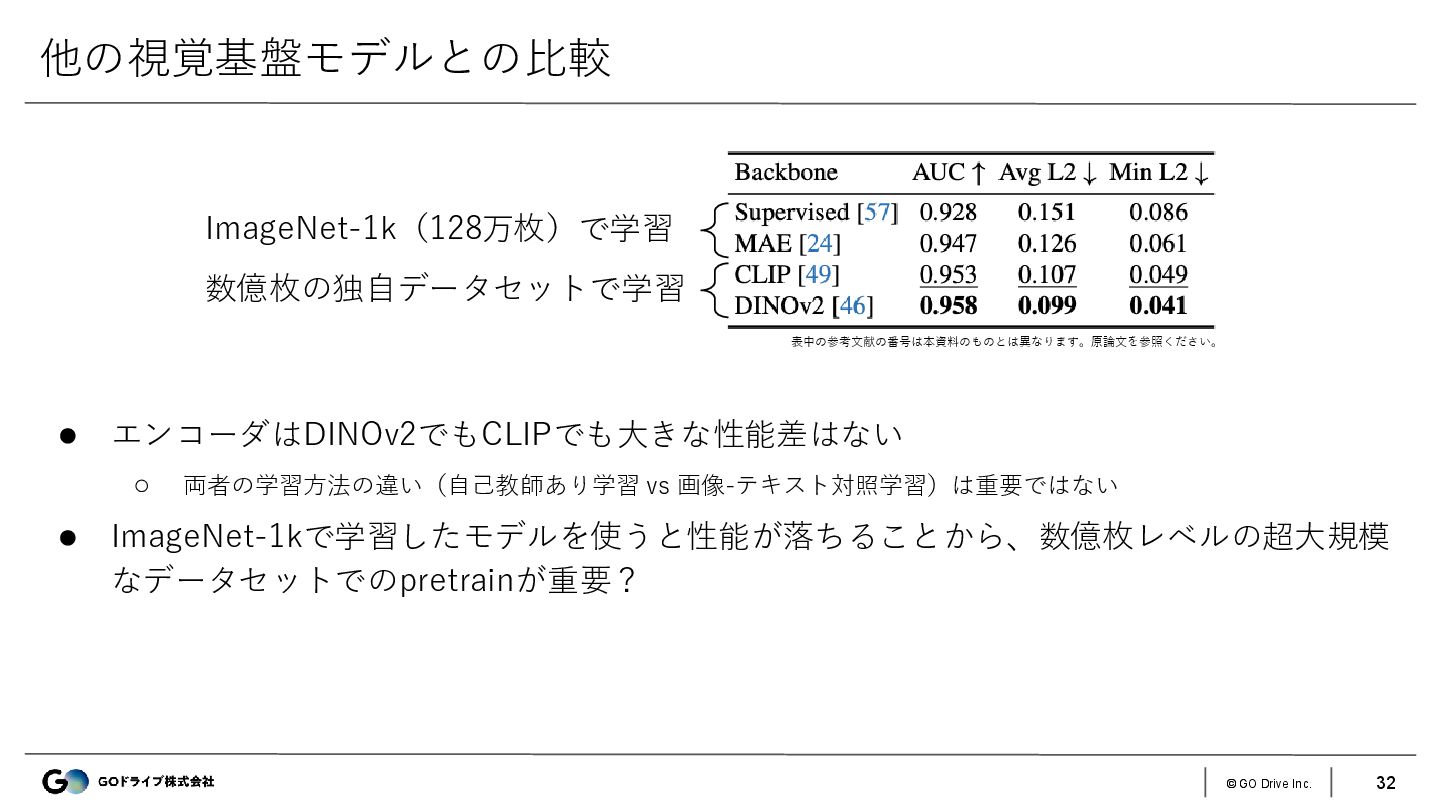{kind=link}
{kind=link}
{kind=link}