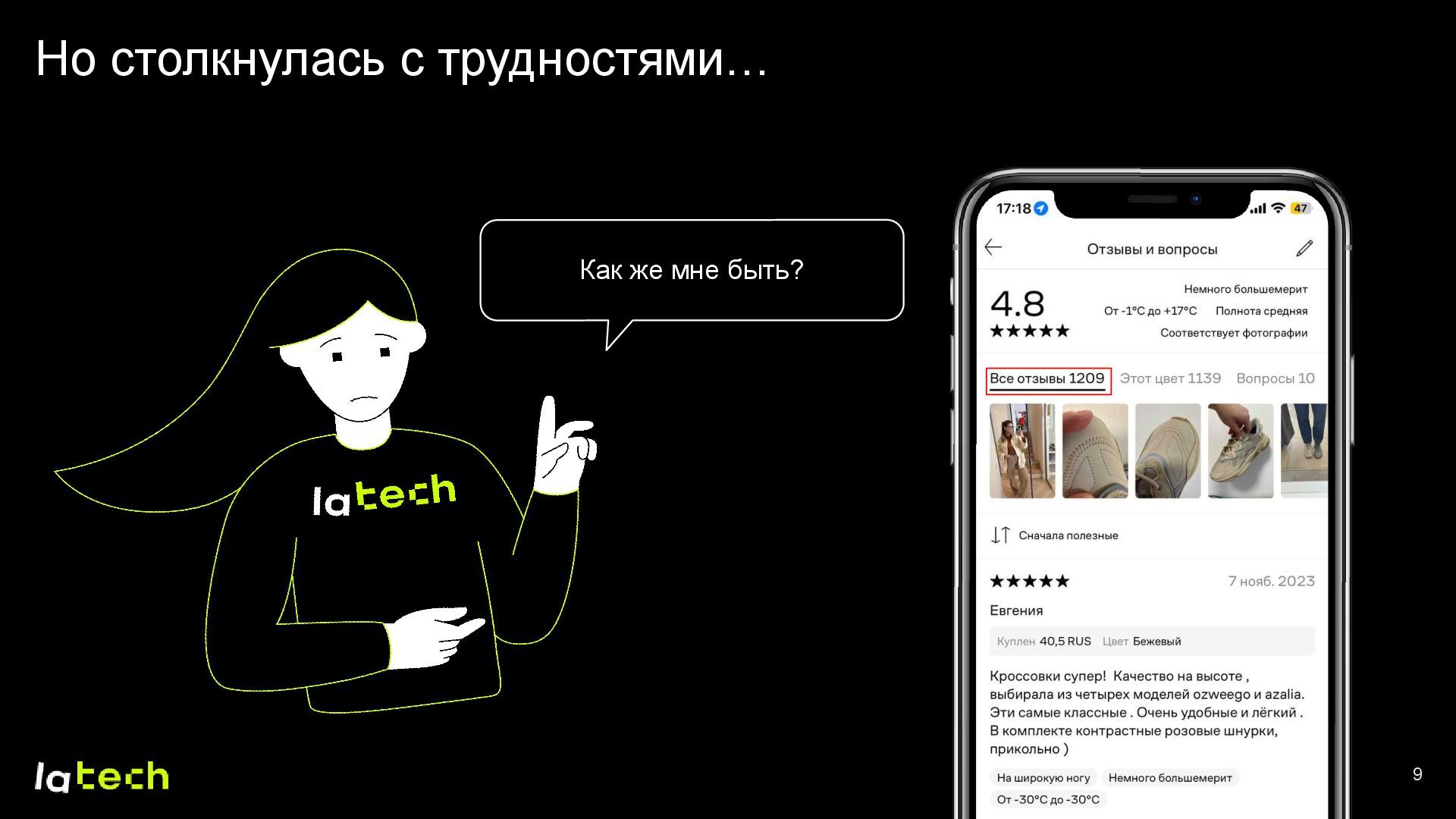
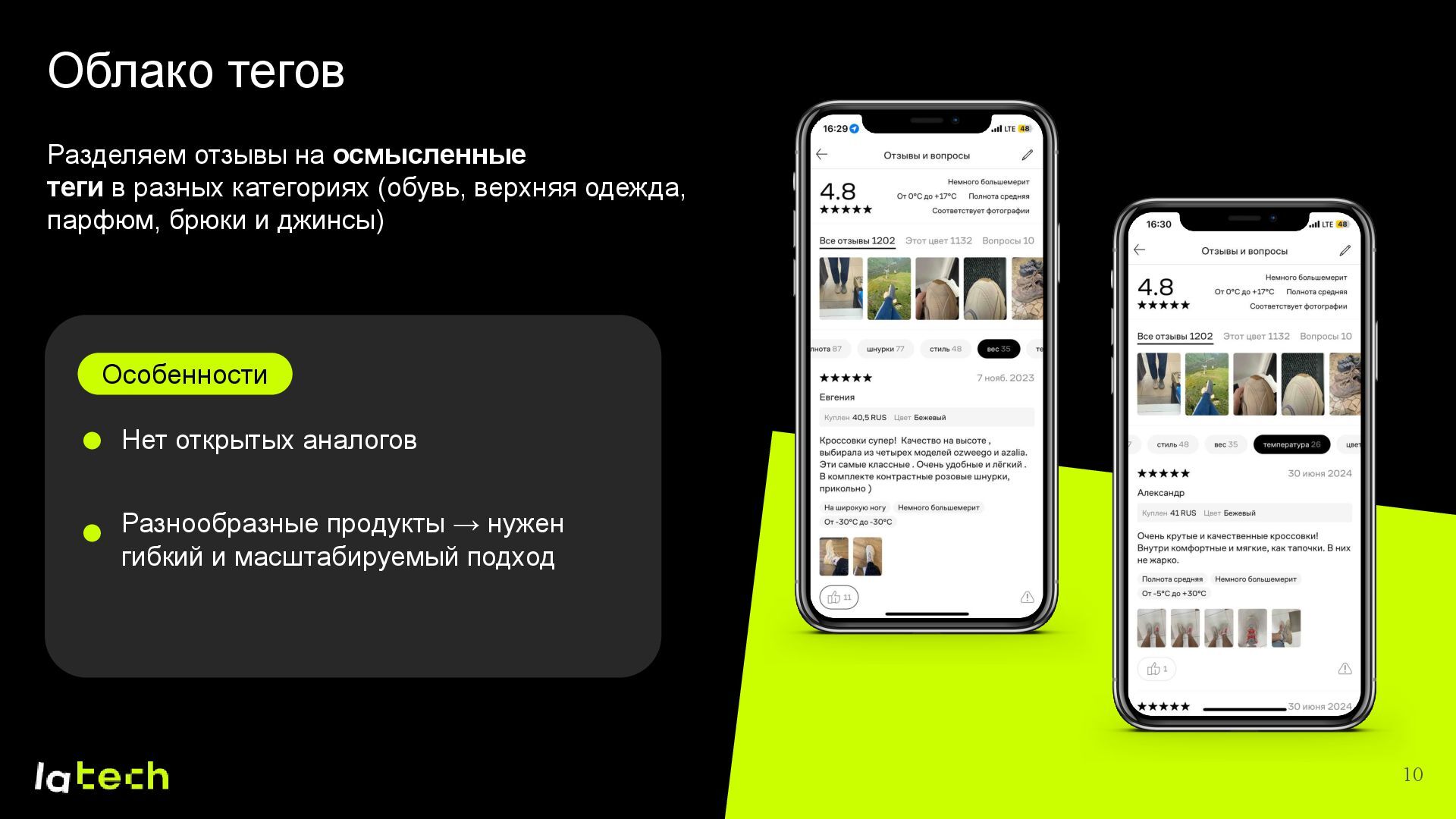
Осенью прошлого года в Lamoda Tech появилась задача разделять отзывы клиентов по осмысленным категориям (тегам). Перед нами стоял вызов: получить большие объёмы качественно размеченных данных для обучения нейросети, не имея готовых решений и аналогов на рынке. Я расскажу о полном цикле создания подобного решения, уделив особое внимание следующим пунктам:
• Почему первоначальный подход с ручной разметкой и краудсорсингом оказался недостаточно эффективным для масштабного решения задачи?
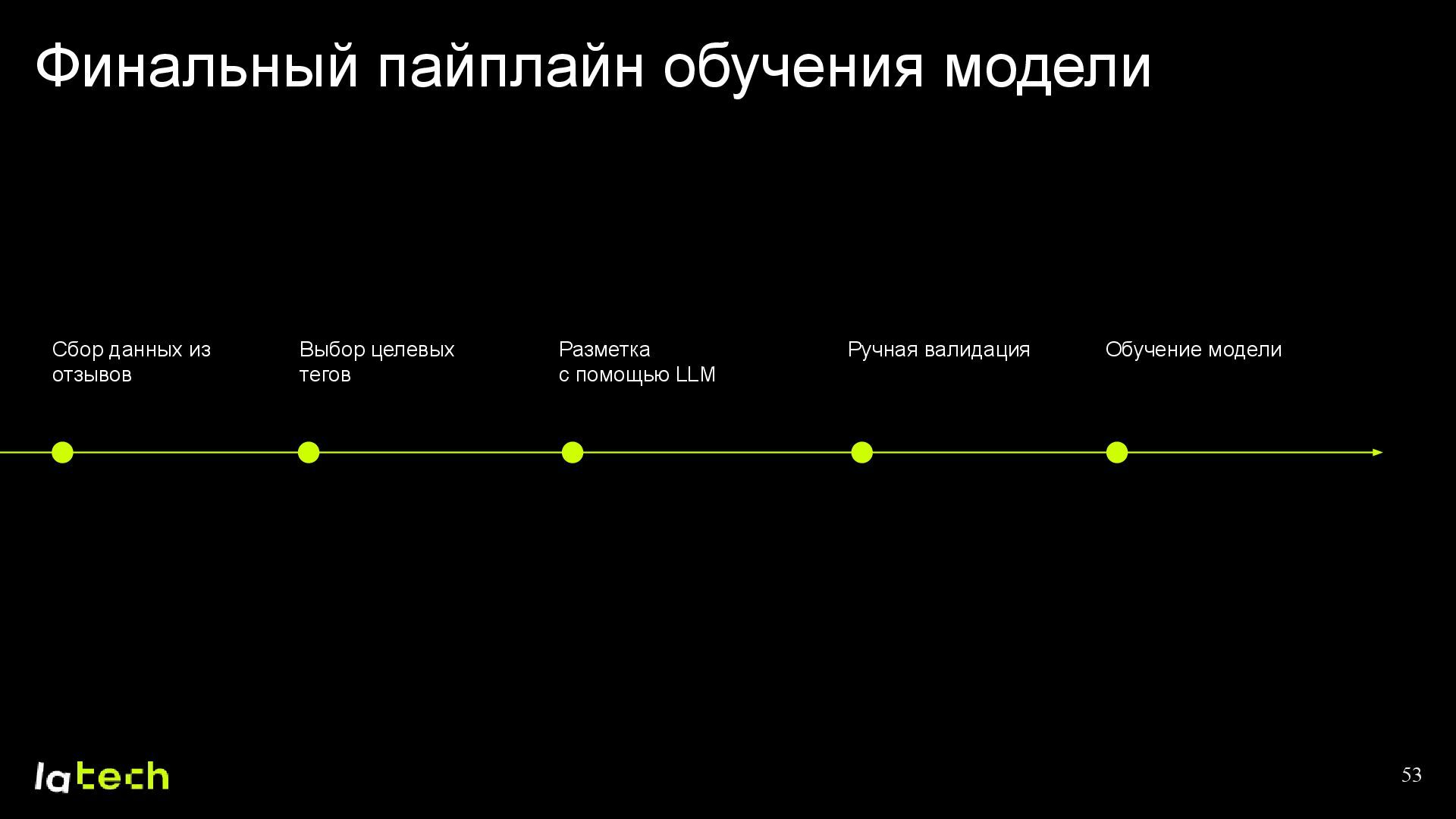
• Как мы тестировали опенсорс и некоторые проприетарные LLM для разметки, и что повлияло на итоговый выбор?
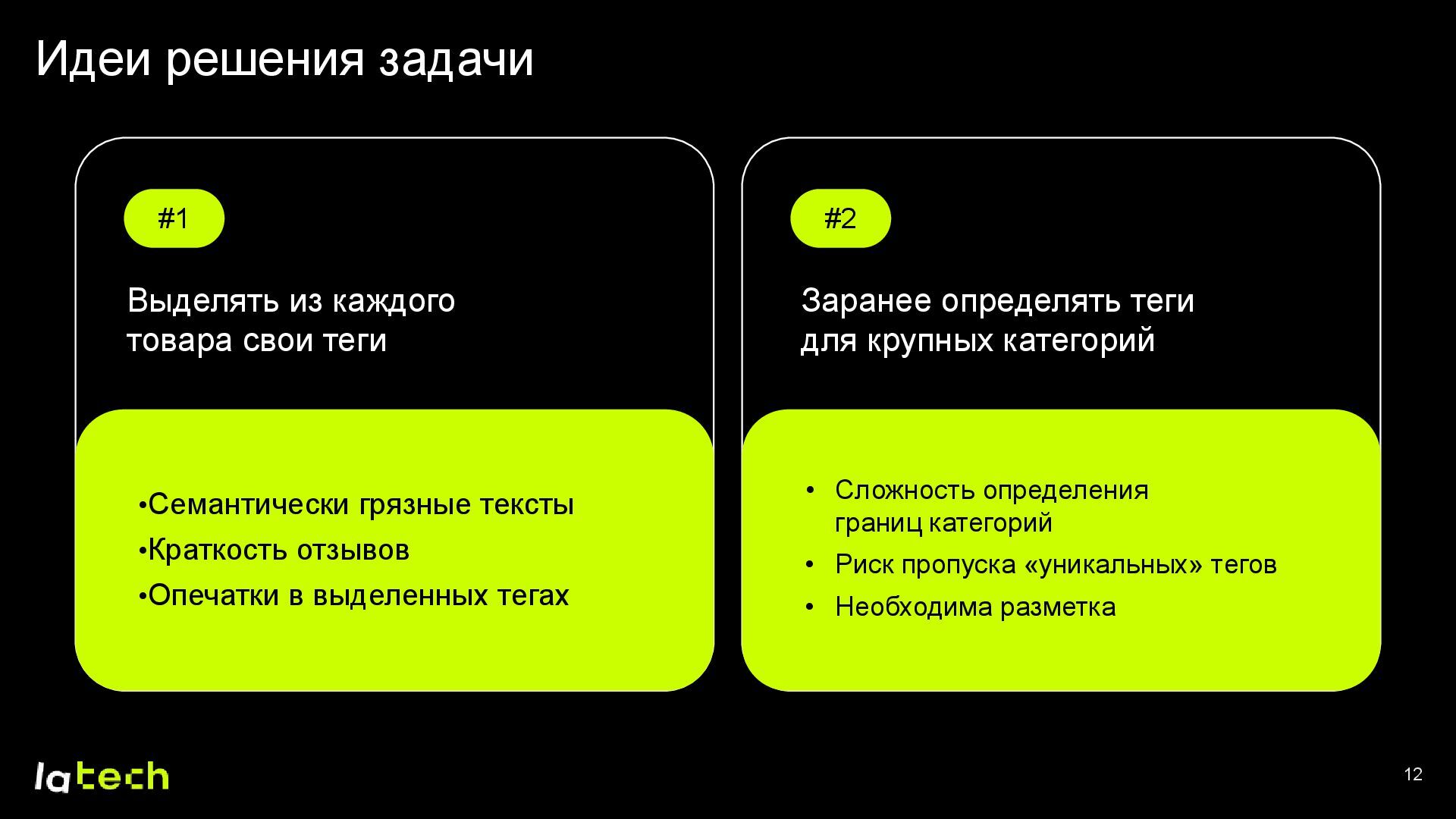
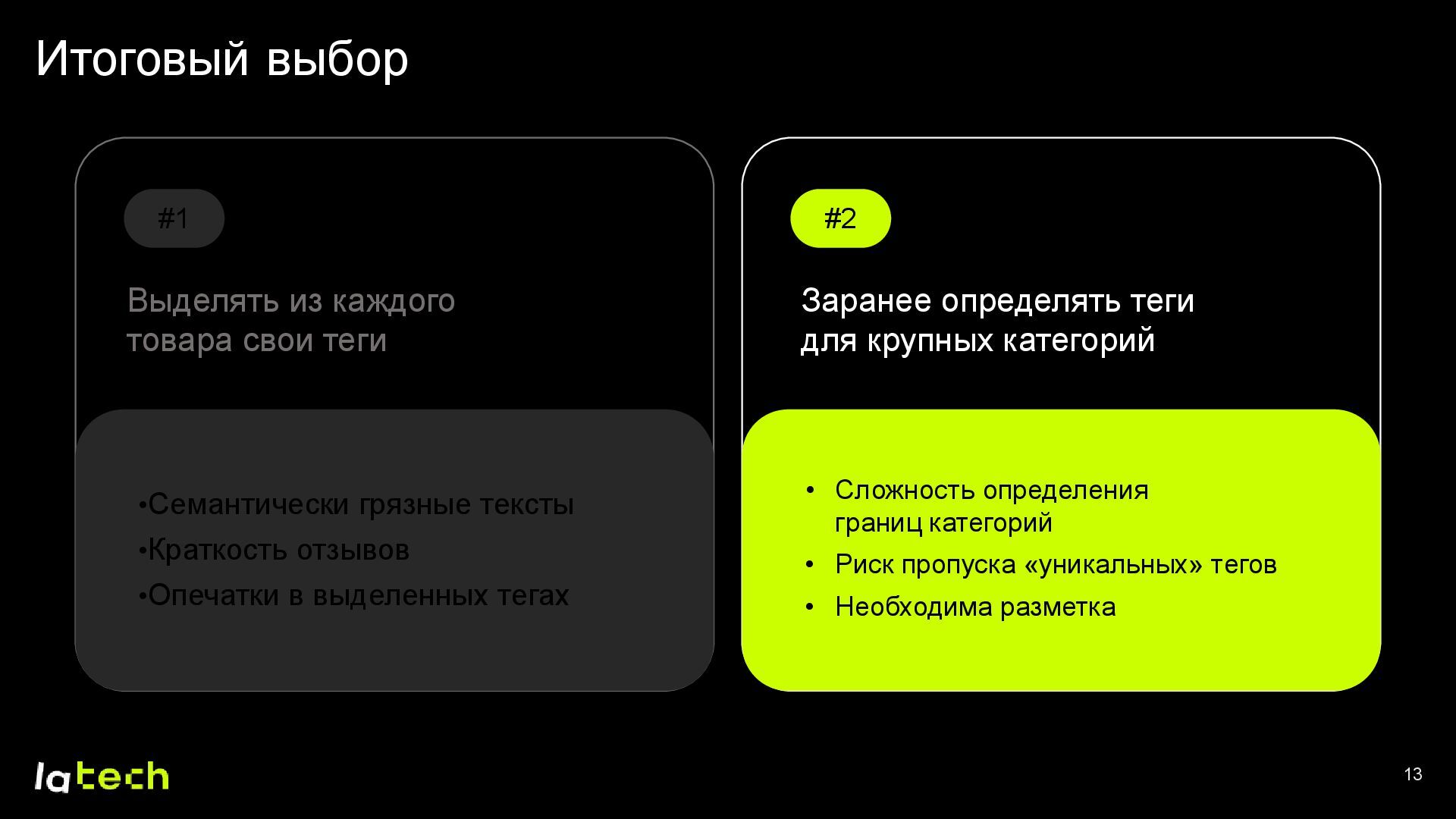
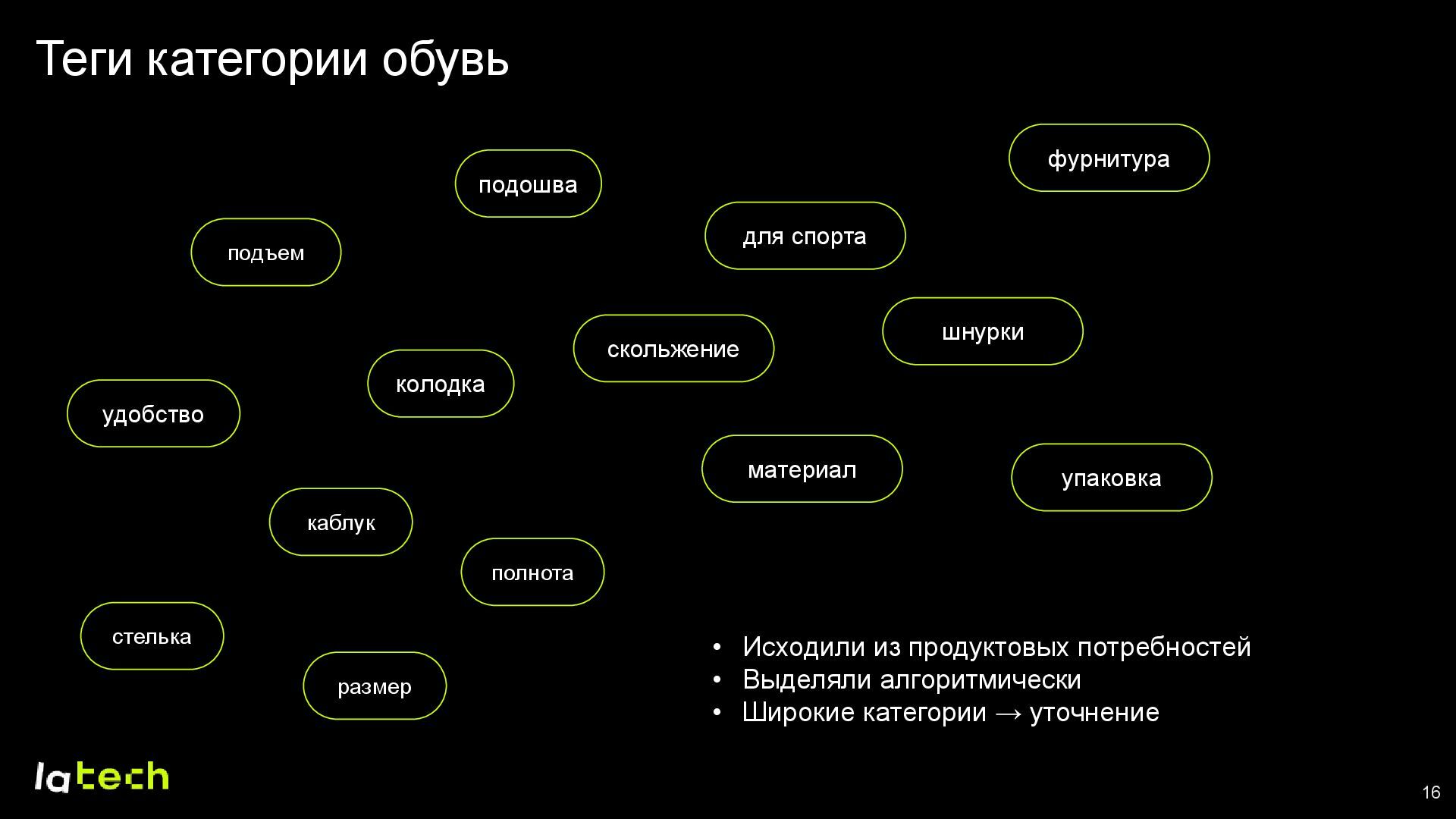
• Как выбирались подходящие теги и формировался финальный набор данных для обучения модели?
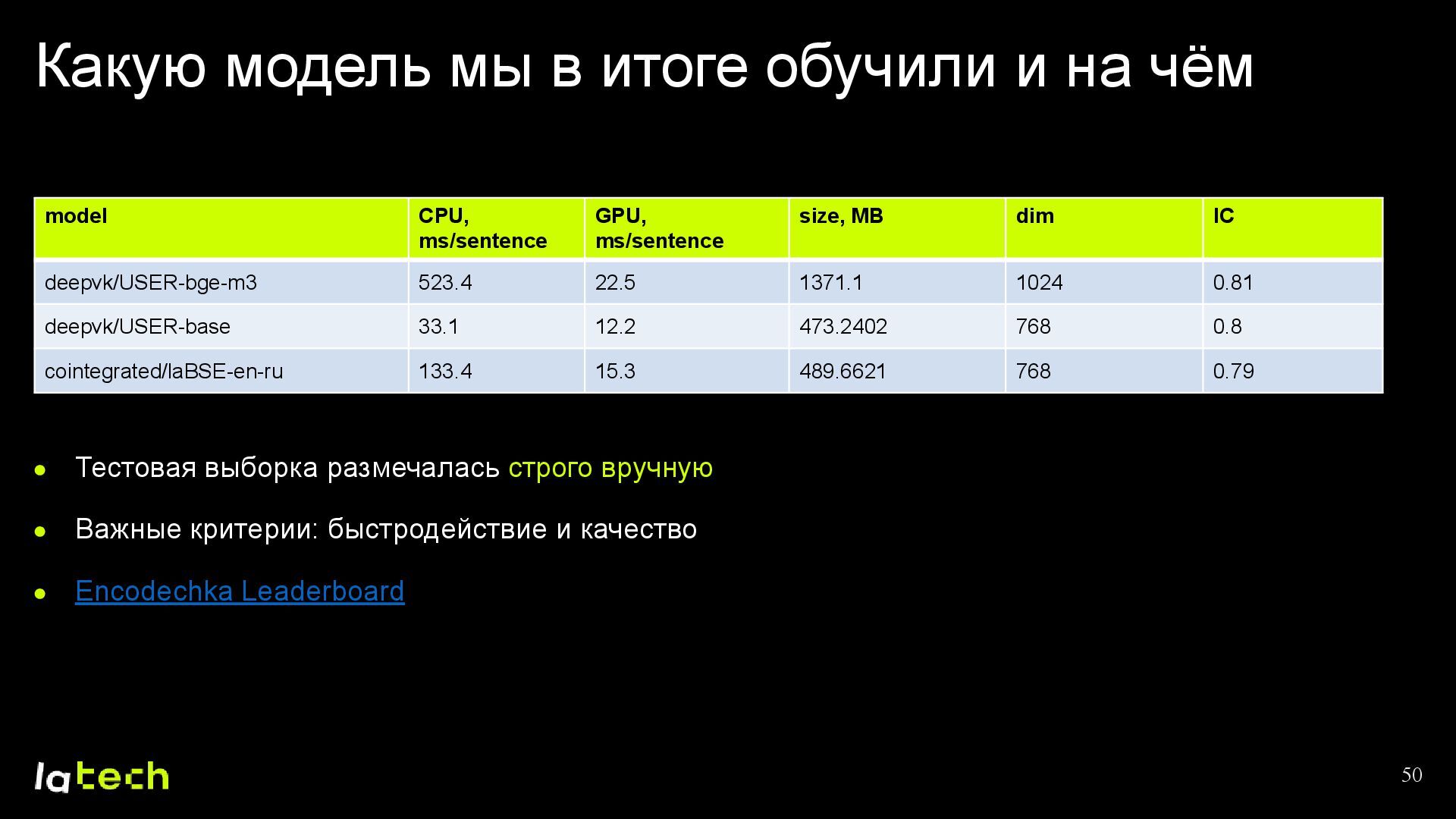
• Какие модели мы рассматривали и на какой остановились?
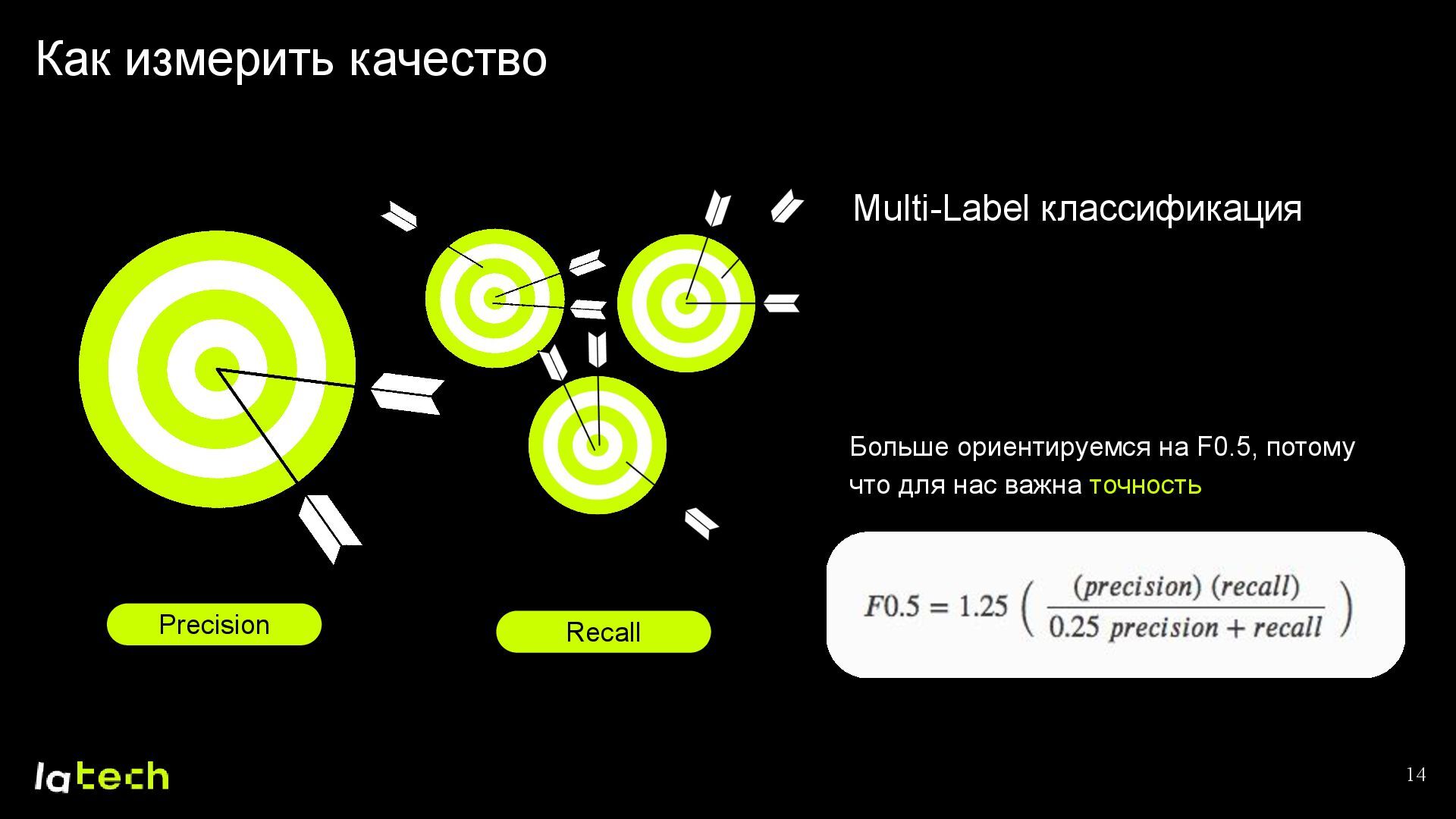
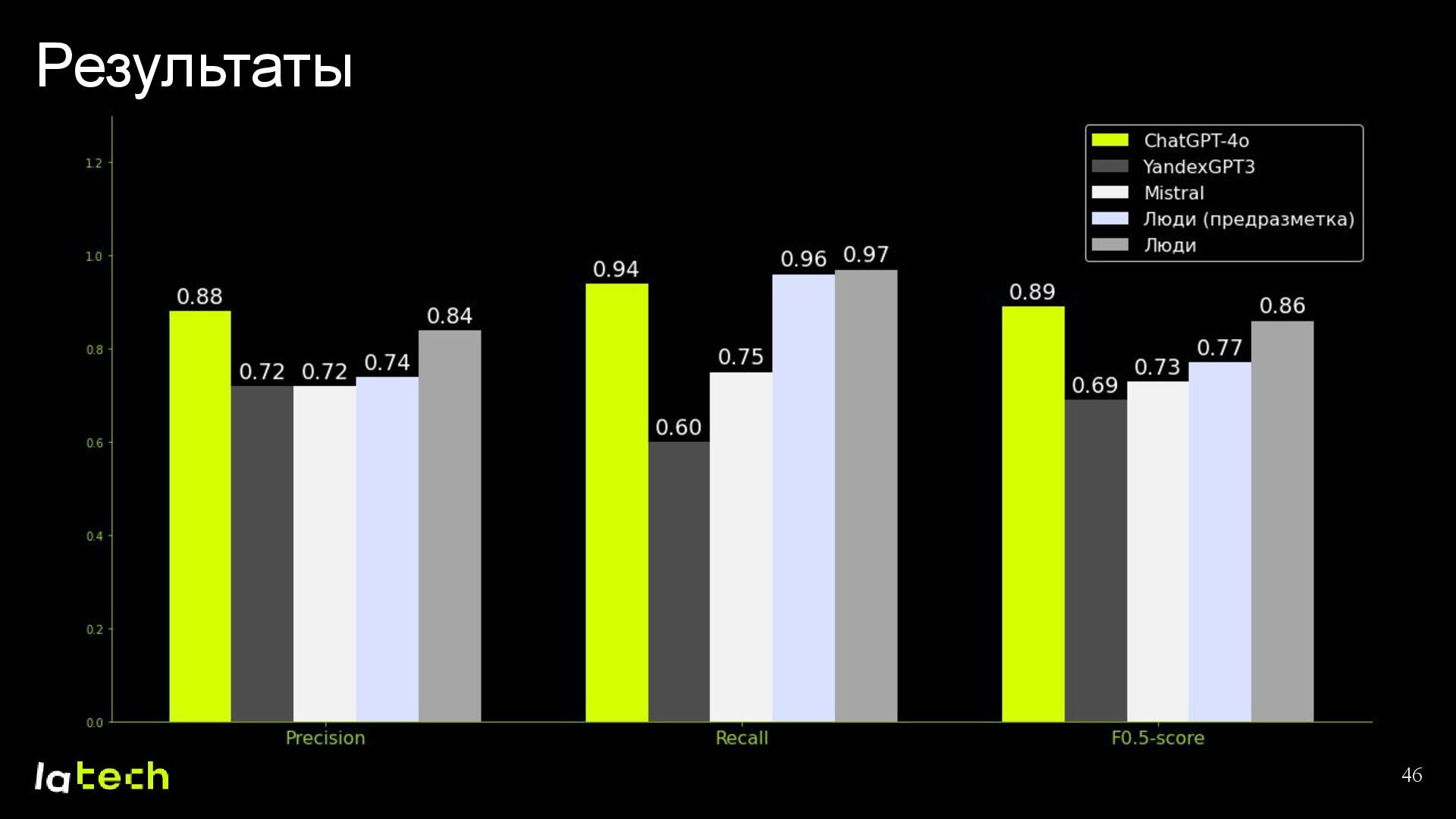
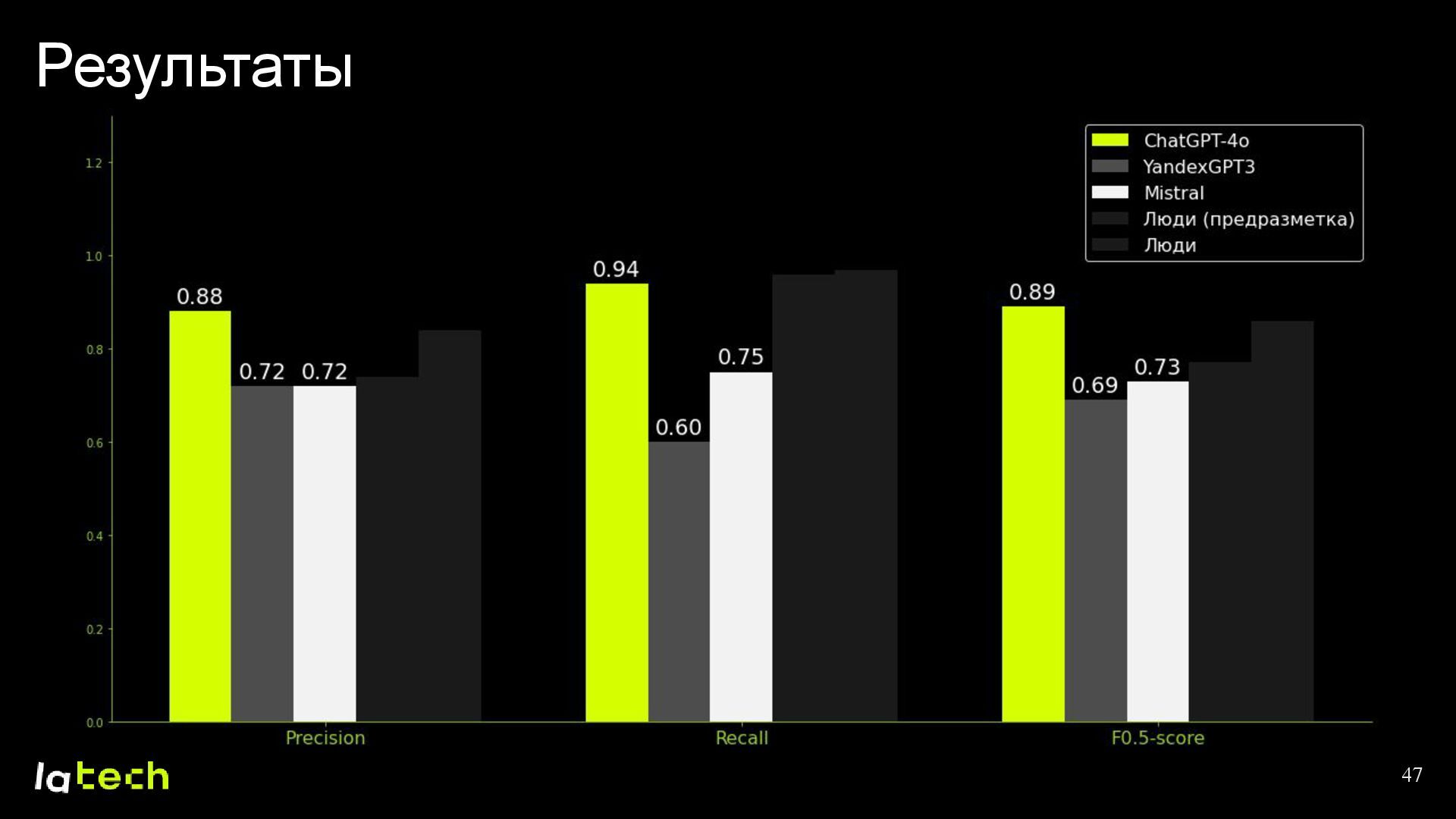
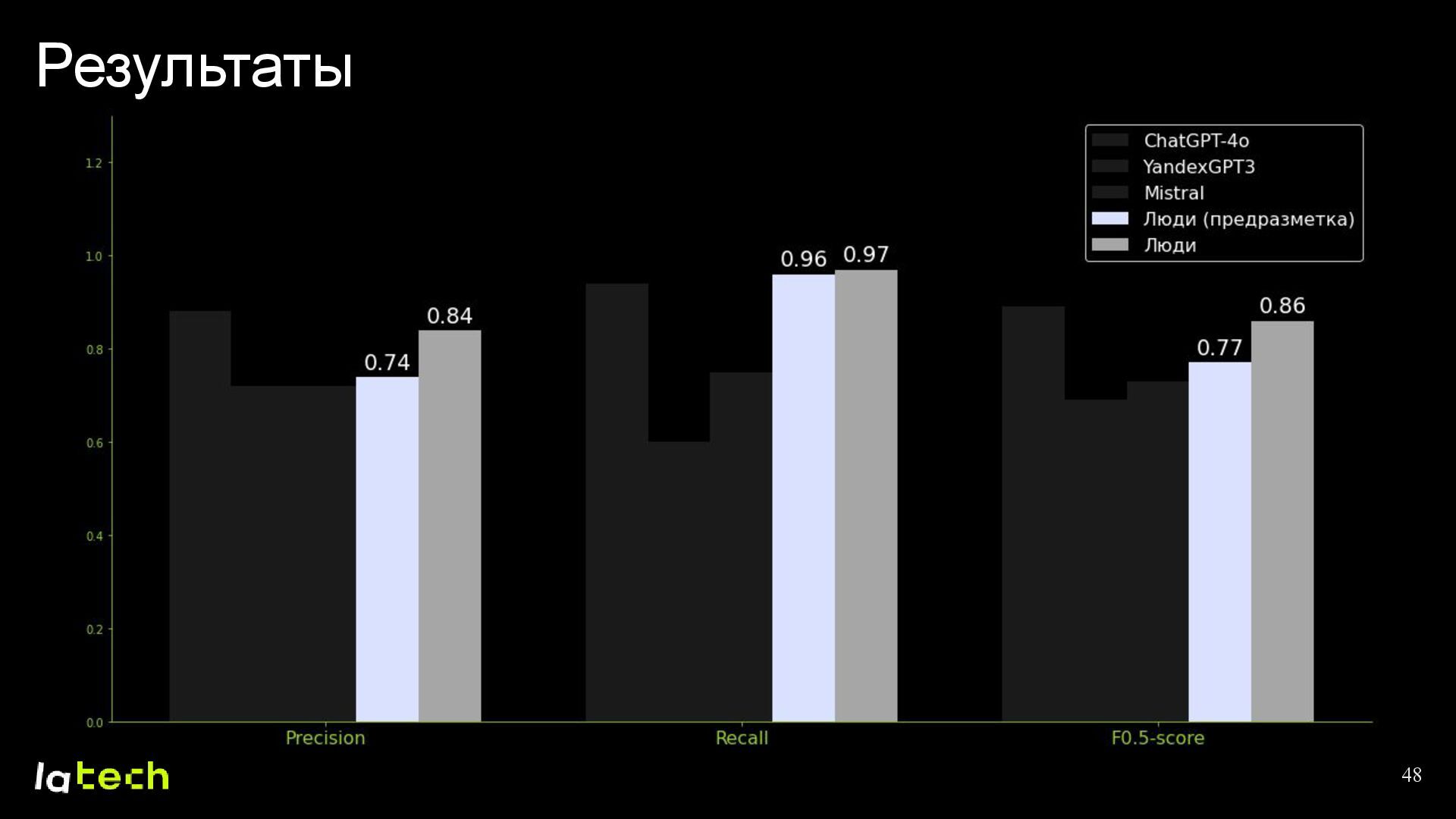
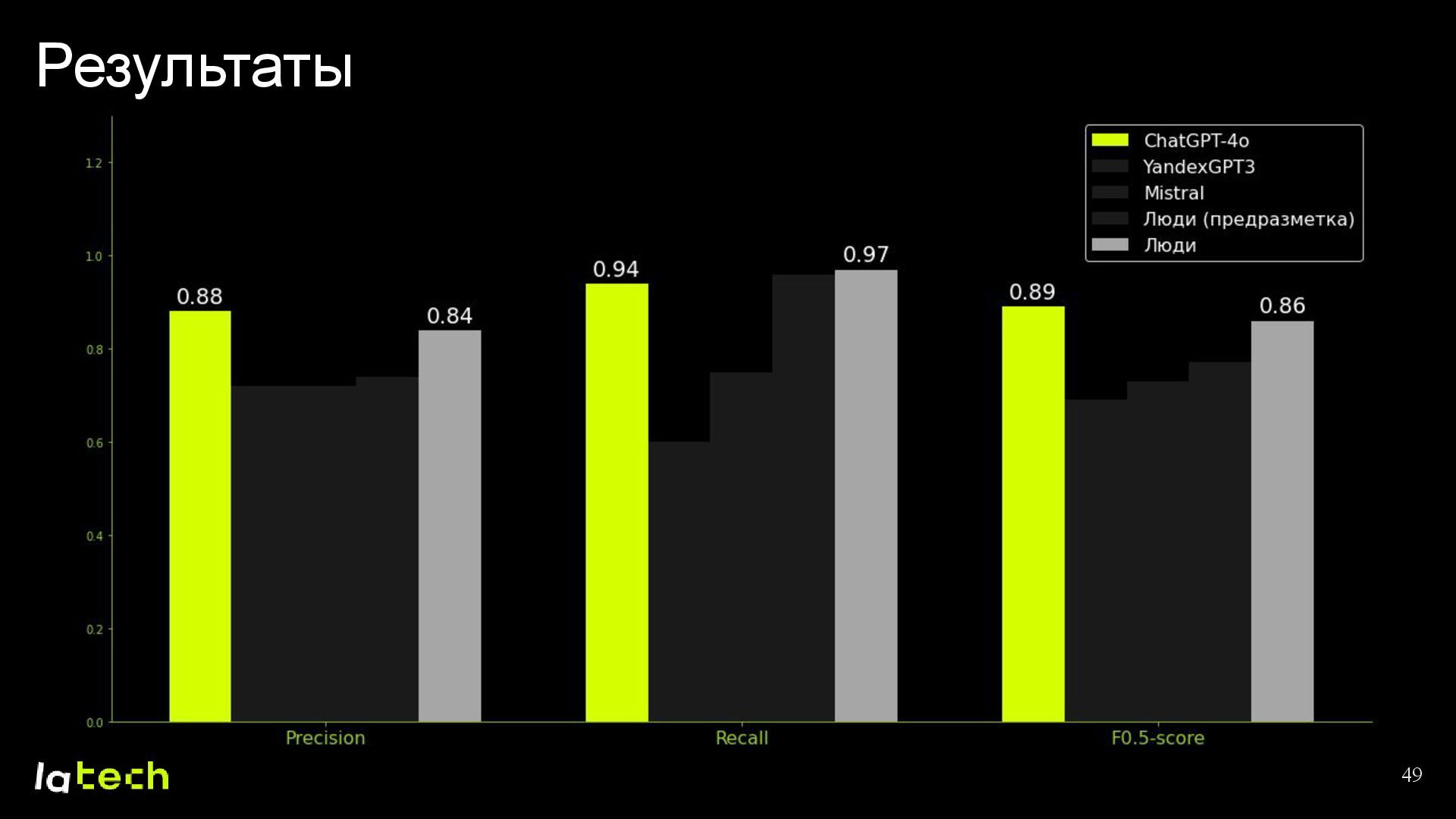
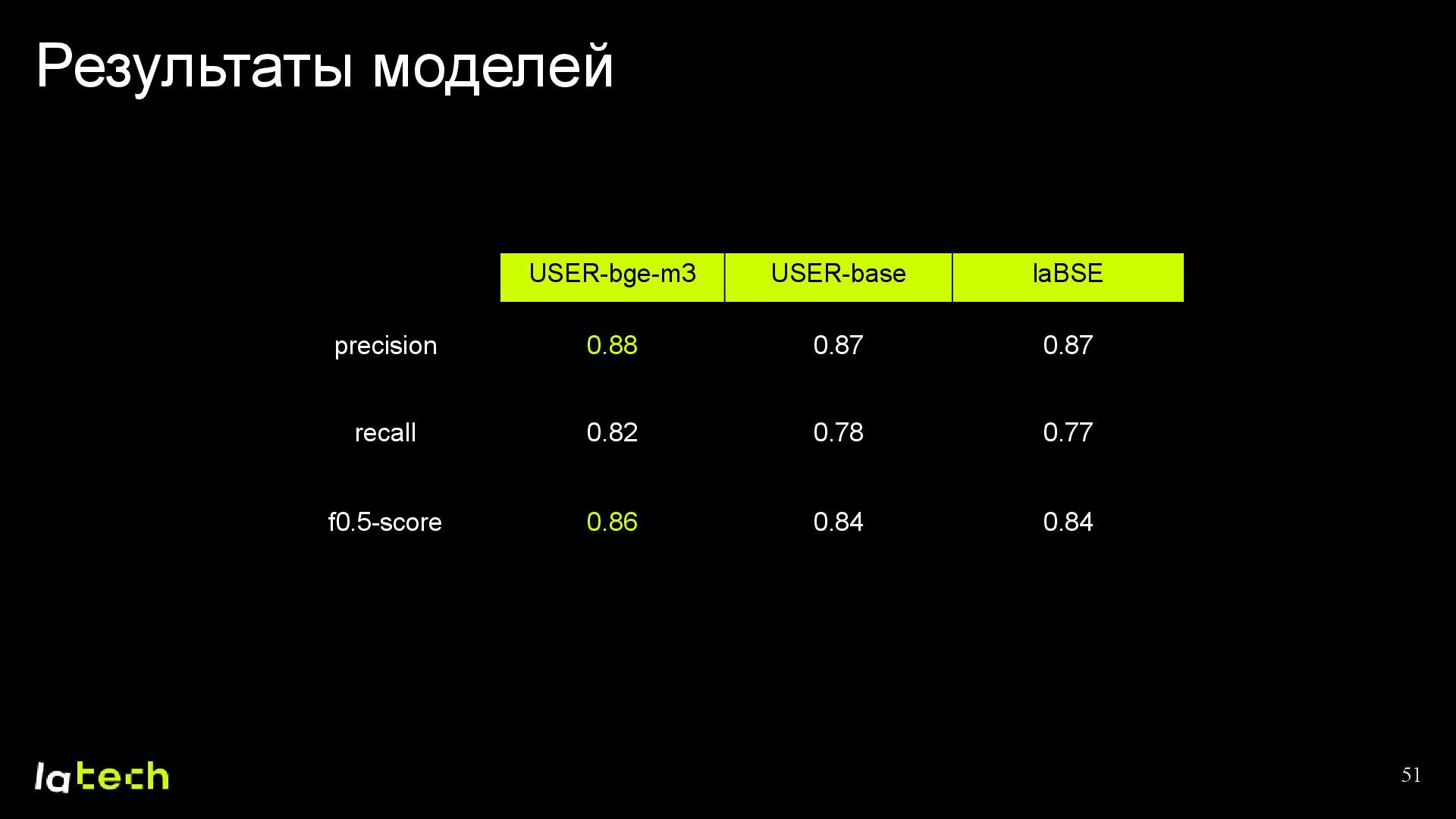
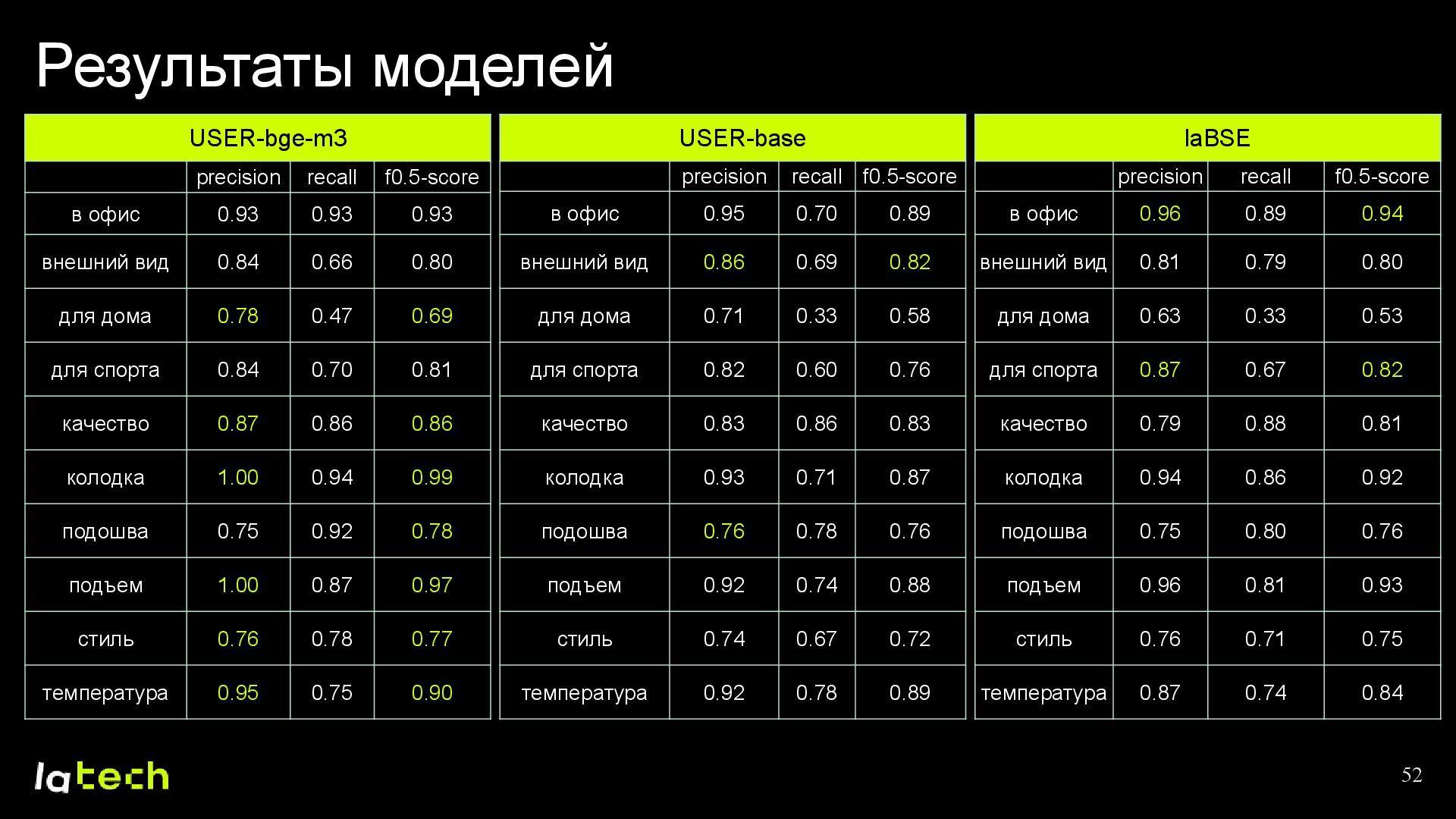
• Какие результаты мы получили и какие планы по дальнейшему развитию проекта?
Этот доклад будет интересен всем, кто работает с NLP, построением DS-пайплайнов, применением LLM и решает задачи разметки больших массивов пользовательских текстов.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
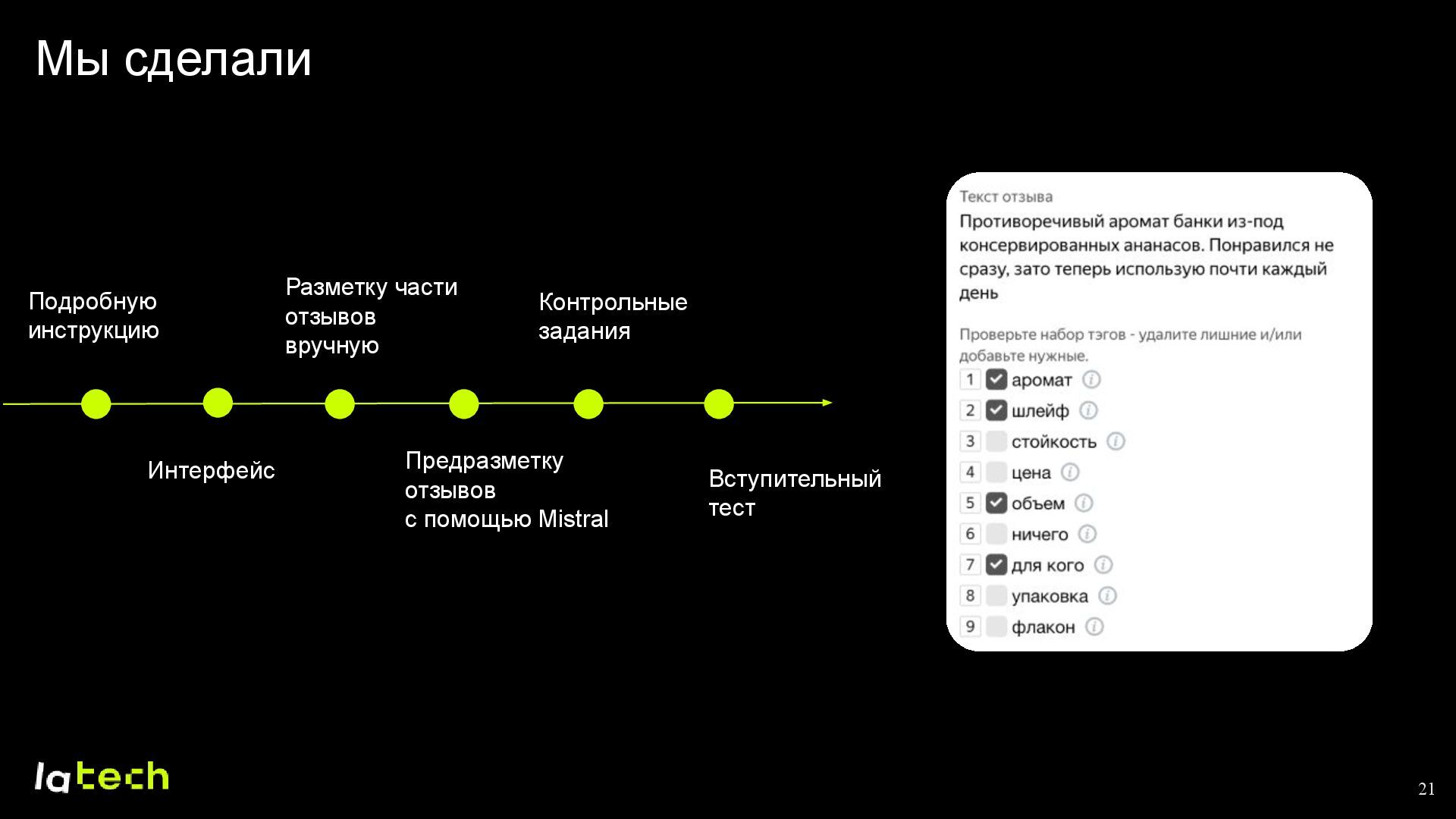{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
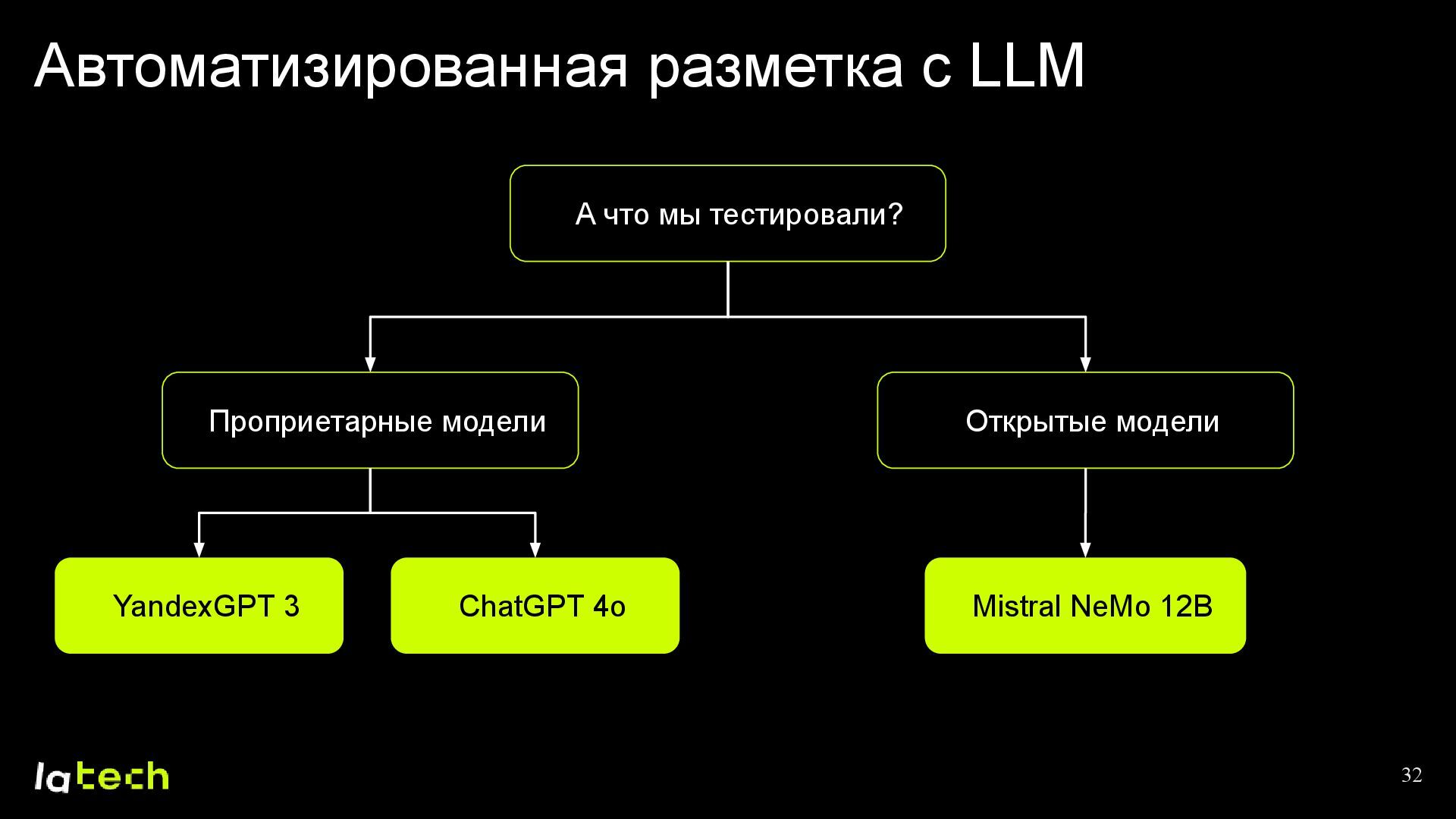{kind=link}
{kind=link}
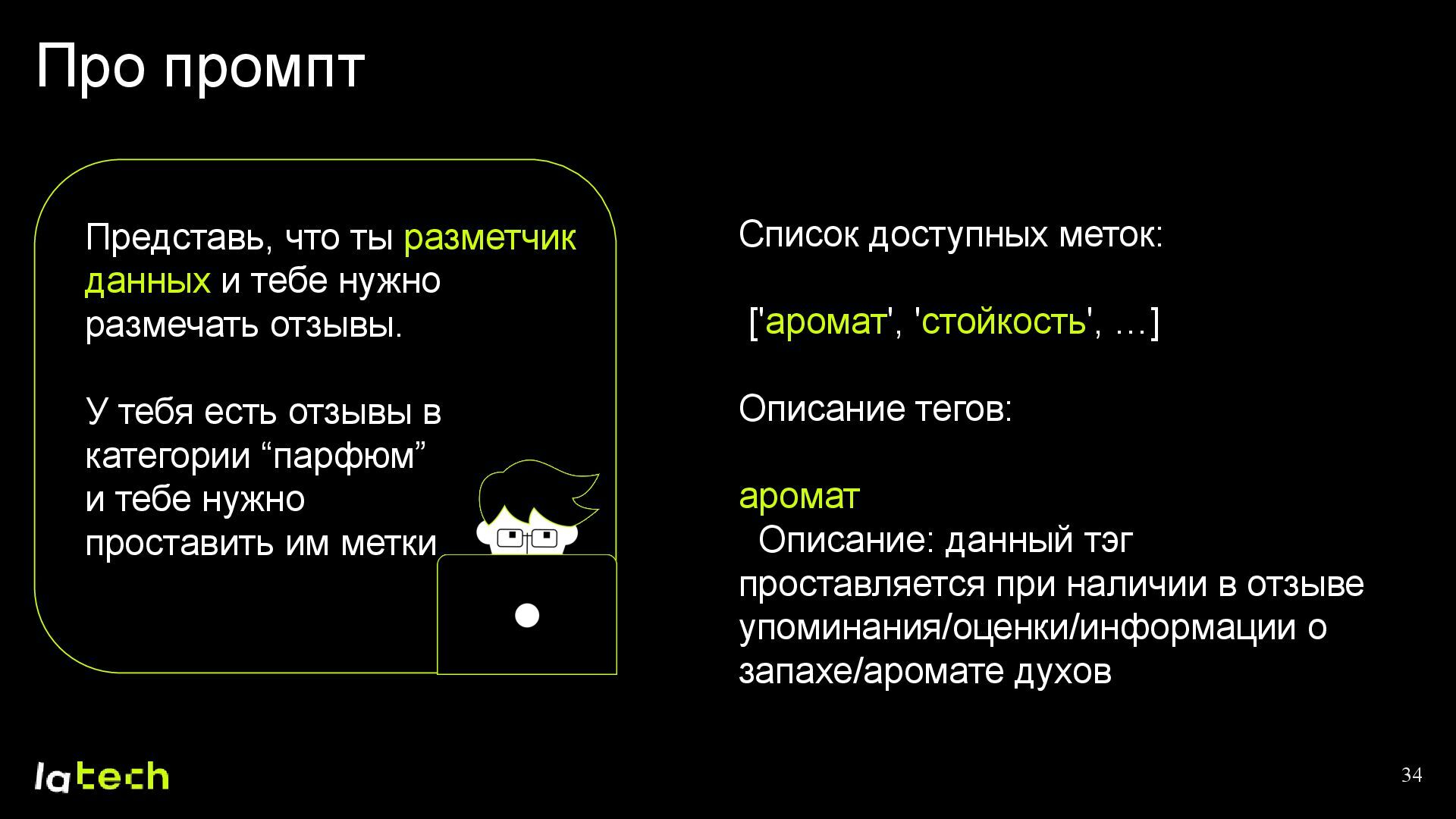{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
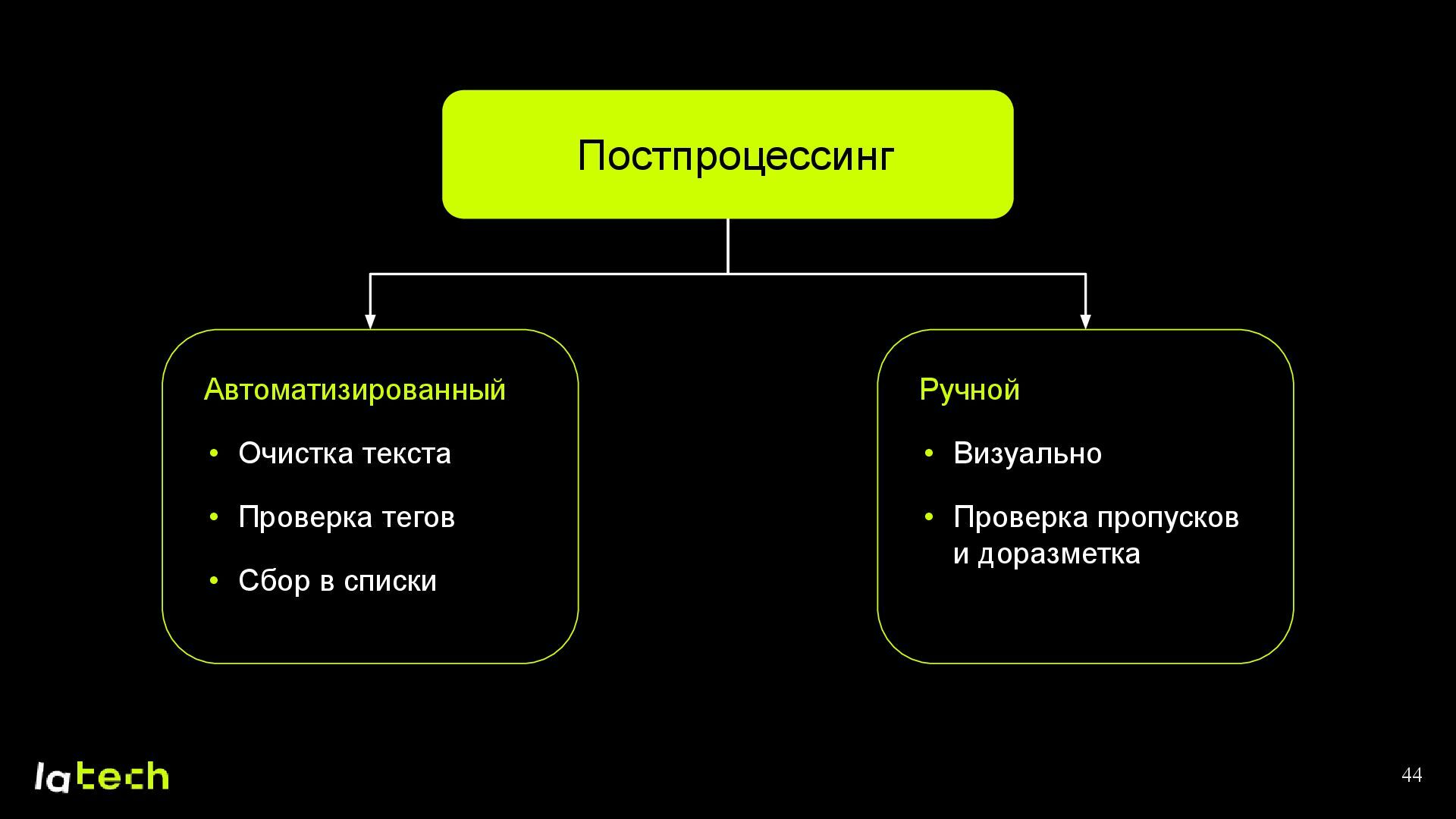{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}