способность системы предоставлять достаточную информацию о своём внутреннем состоянии на основе внешнего поведения. Observability — это подход, позволяющий понять, что происходит внутри системы, не меняя её поведение, за счёт сбора метрик, логов и трассировок.
способность системы предоставлять достаточную информацию о своём внутреннем состоянии на основе внешнего поведения. Observability — это подход, позволяющий понять, что происходит внутри системы, не меняя её поведение, за счёт сбора метрик, логов и трассировок. “A system is observable if you can determine the internal state of the system from its outputs.” (с) Control Theory
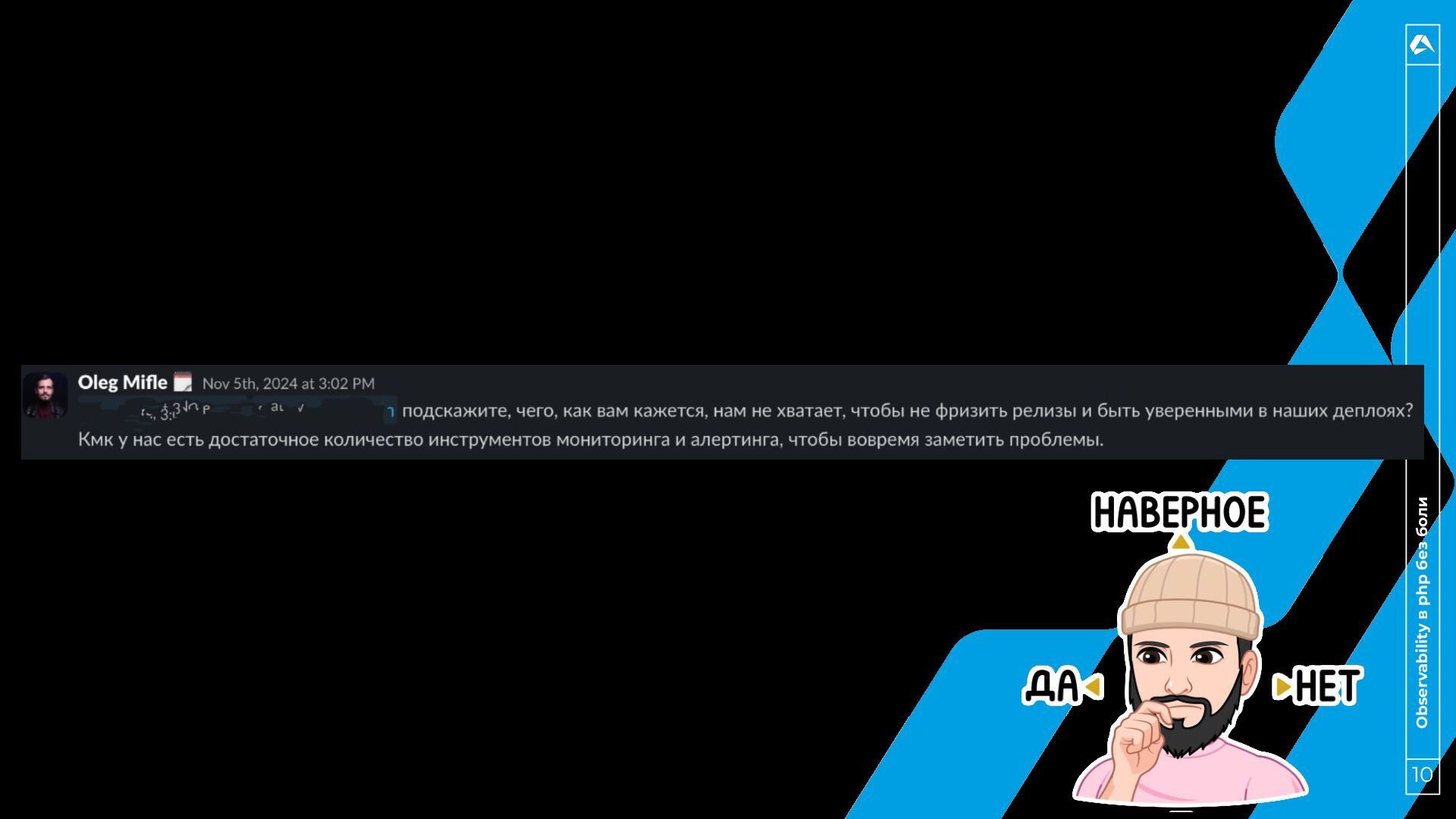
Быстро понять, что мы упали. 2. Быстро всё закатить назад. a. Быстро поднятое упавшим не считается 3. Удобные и понятные инструменты чтобы понять a. что упало; b. где упало; c. почему упало.
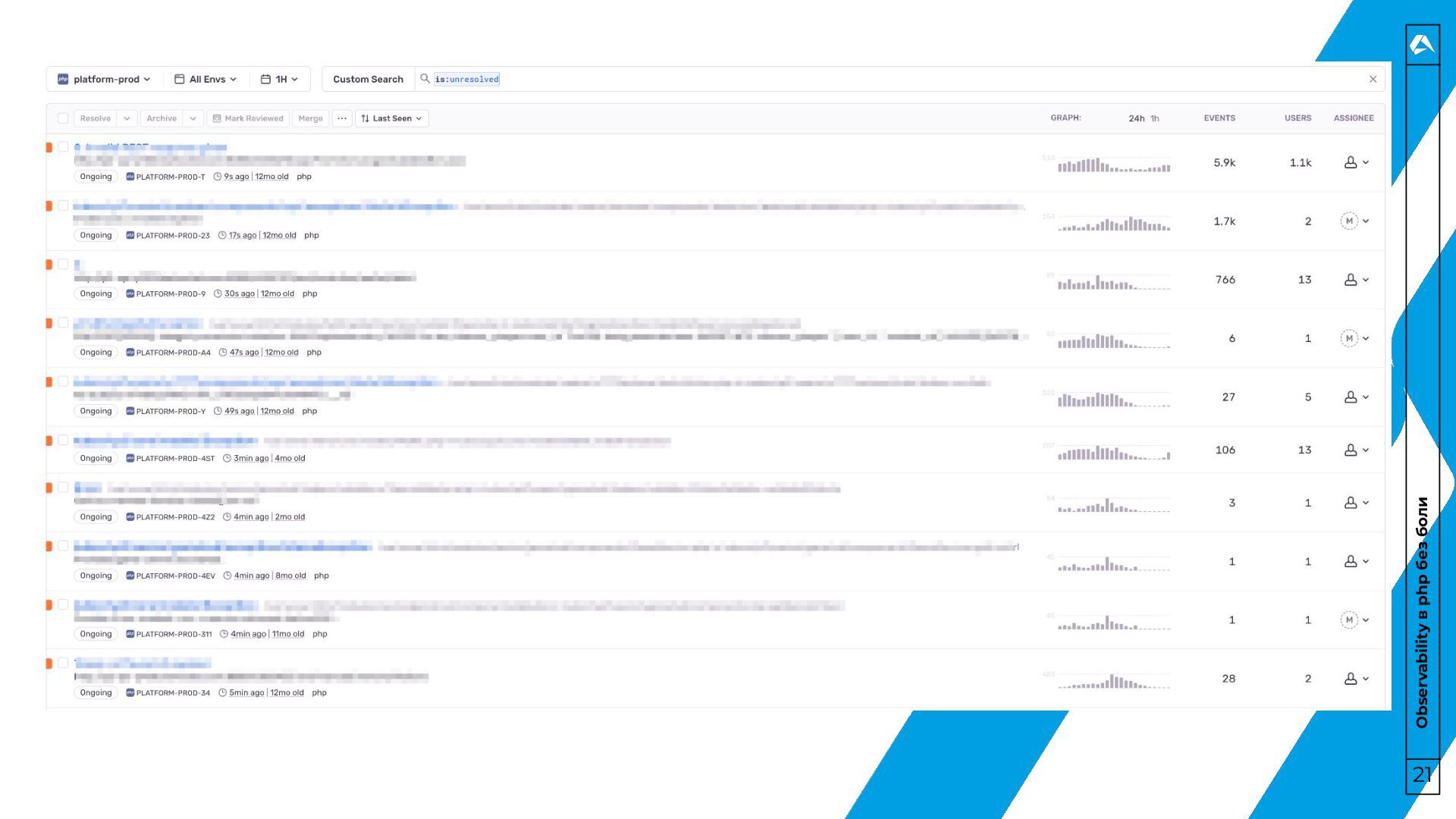
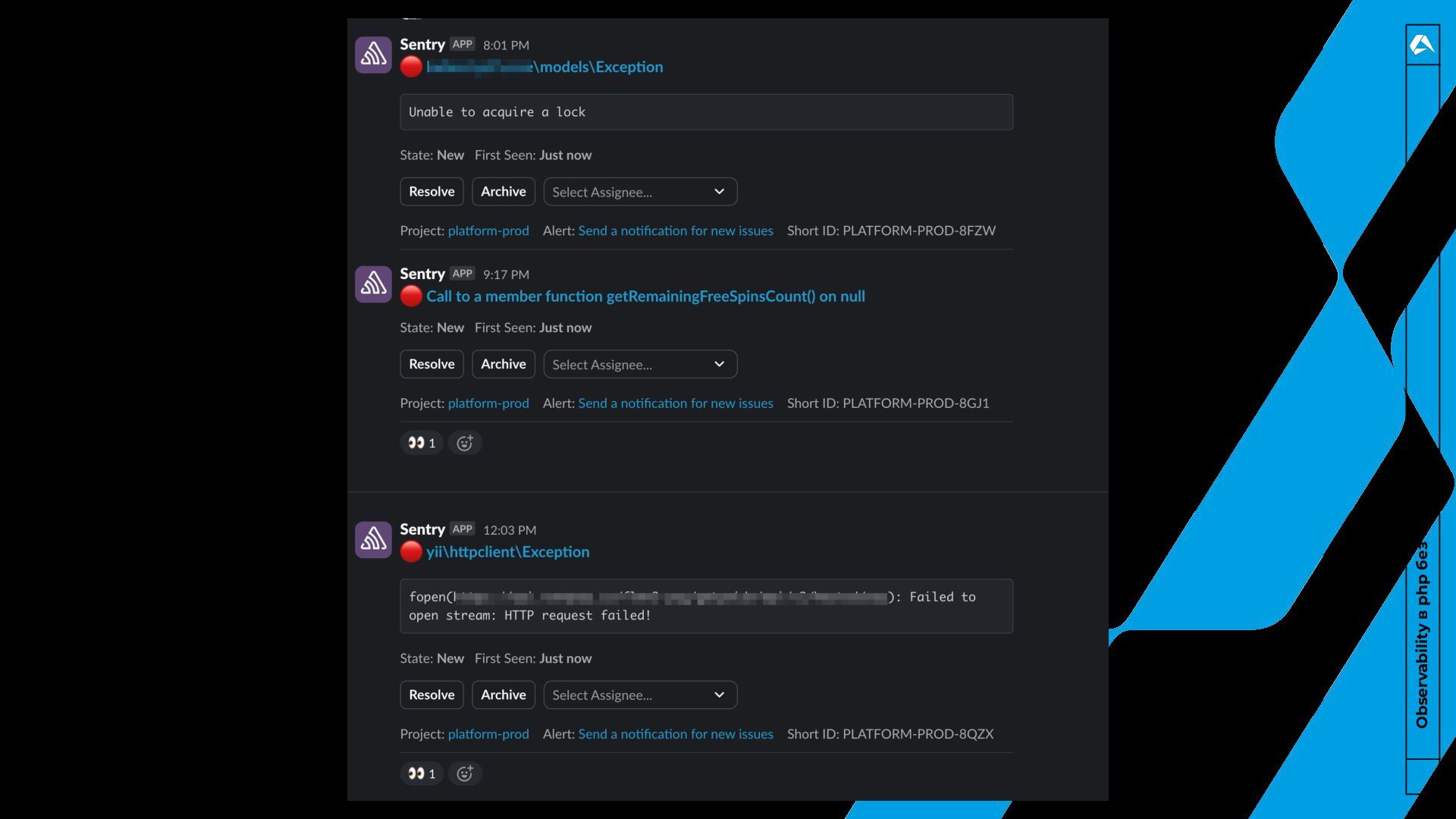
логировать все ошибки. ◦ Например валидация, 404, устаревание токена. • Issue в sentry != логи • Кардинальность событий. ◦ Например userId в заголовке события • Максимально обогащать событие ◦ Второго шанса получить старое событие не будет
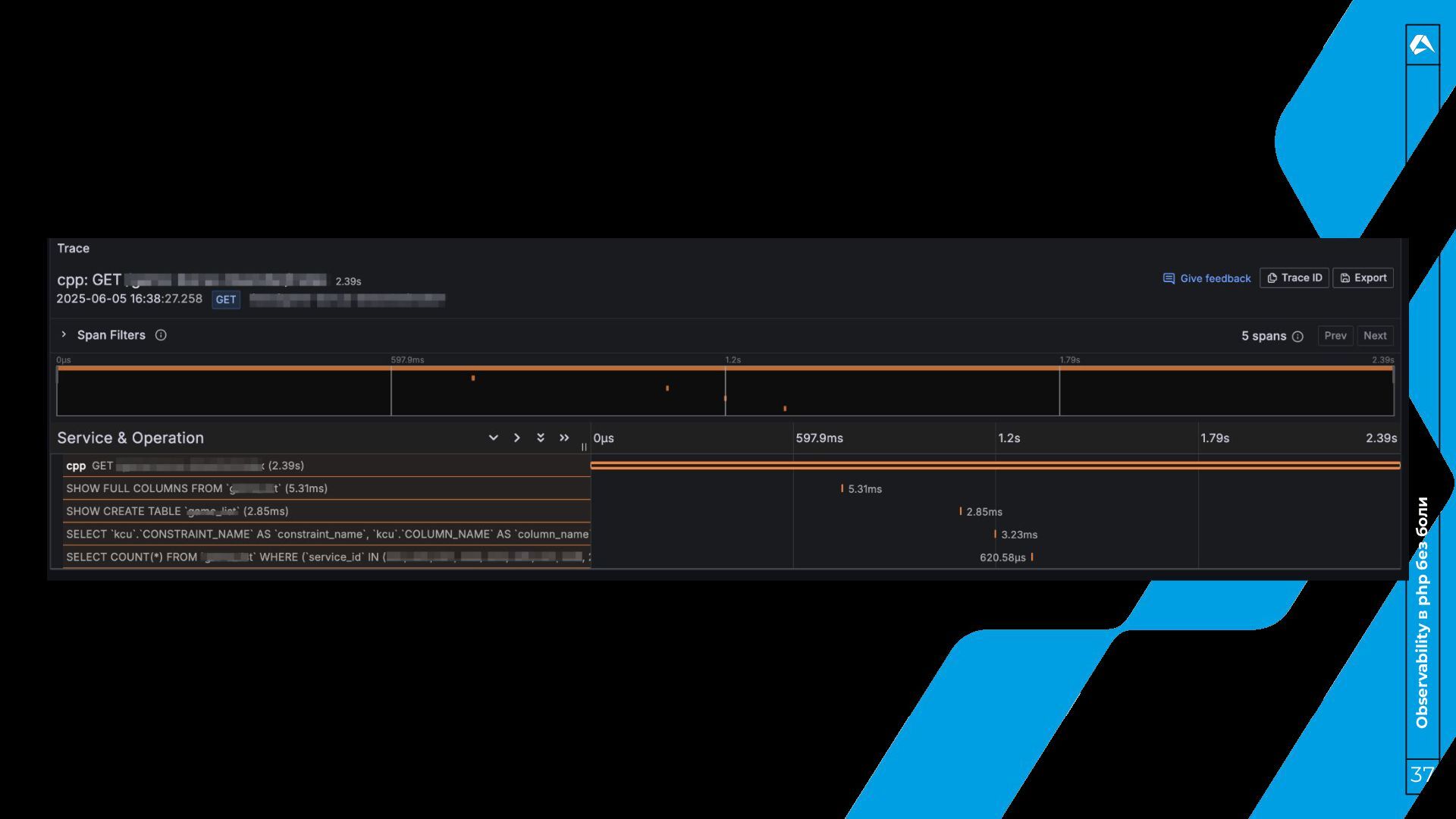
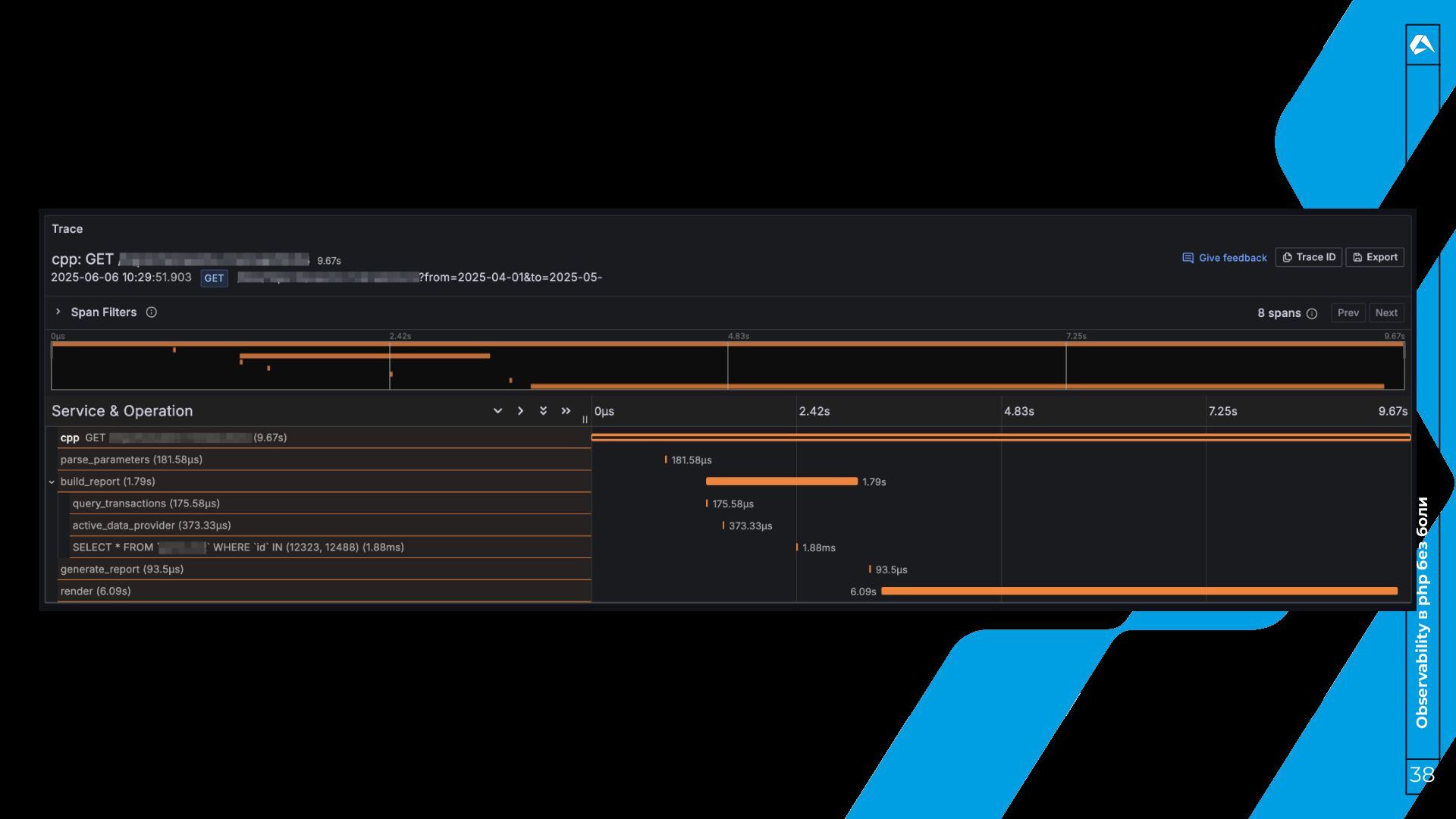
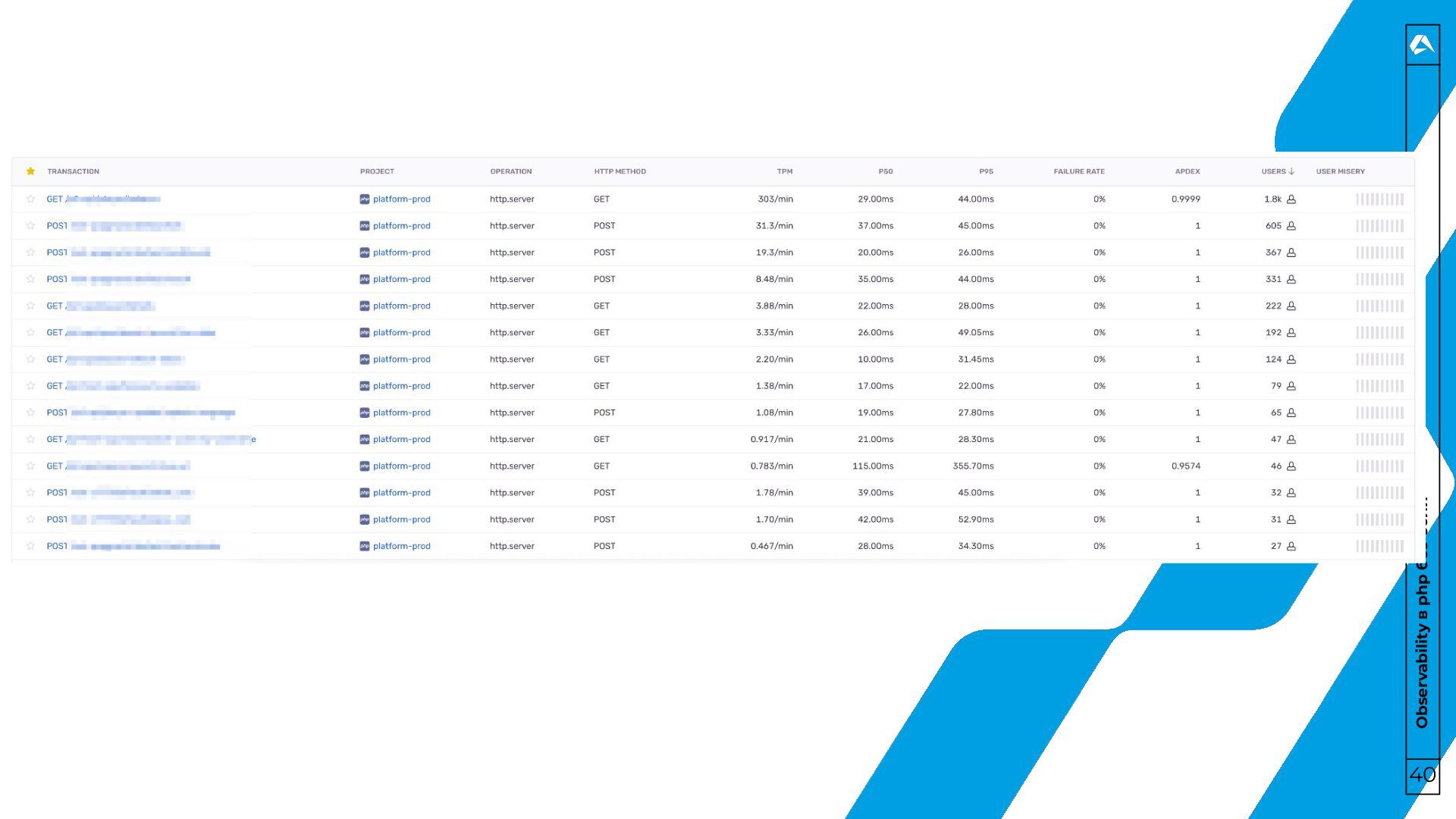
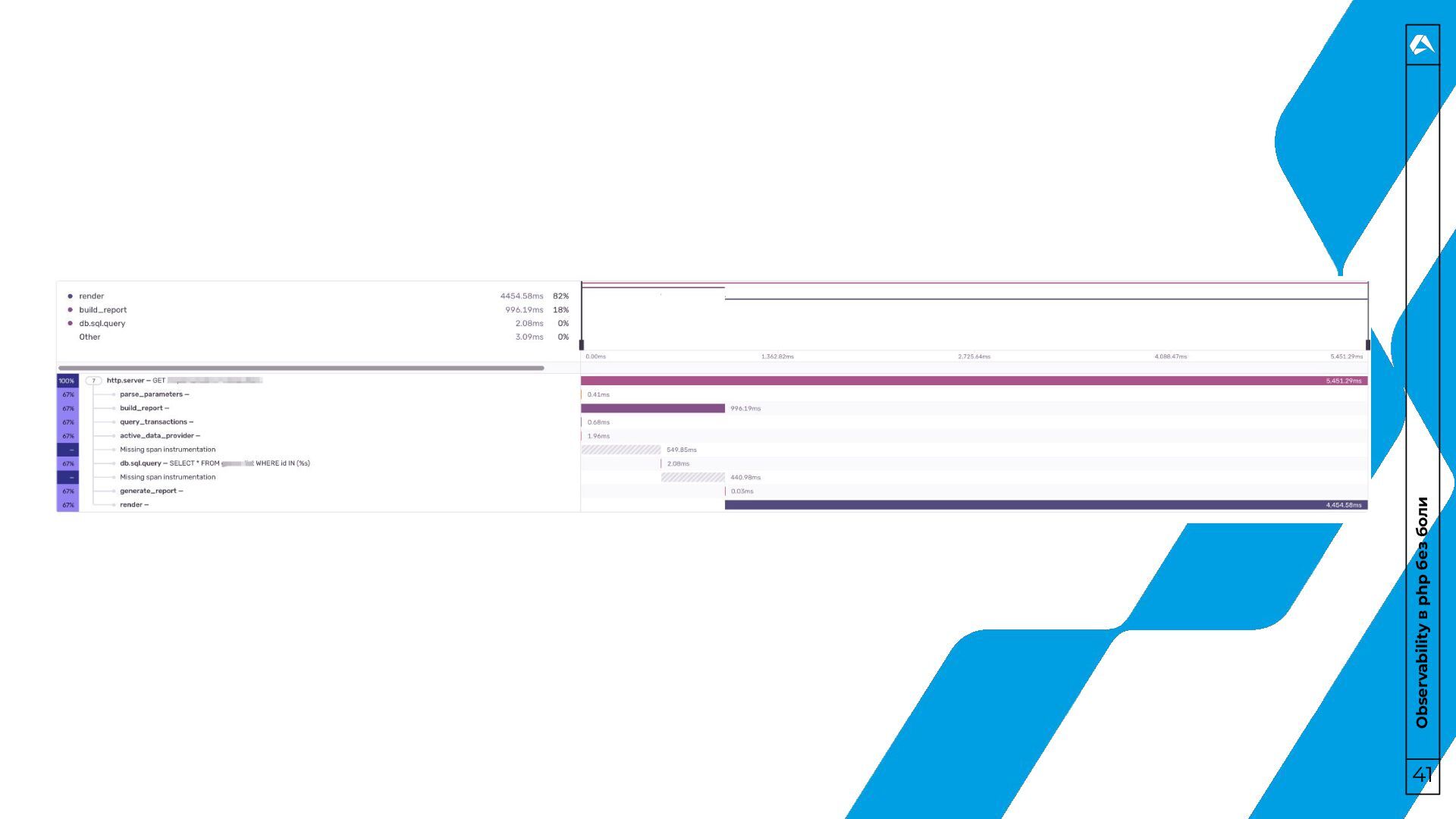
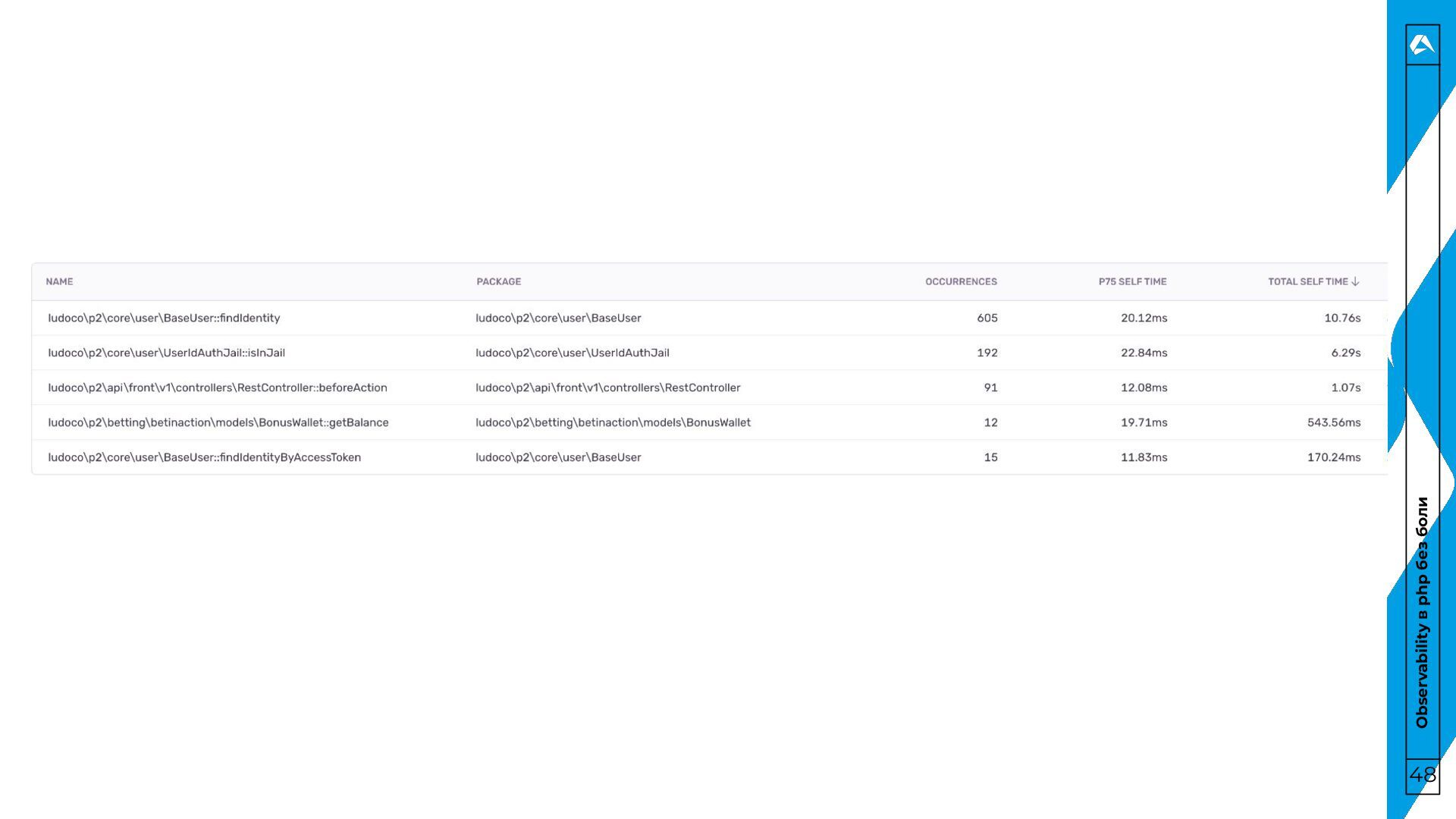
трейсы? 31 • Трейс – это “история” одного запроса. Для чего? • Диагностика производительности. • Анализ запросов в распределенных системах. • Понимание зависимостей и взаимодействий компонентов.
51 • Файлы не централизованы • Нет ротации → переполнение диска • Не видно в реальном времени • Нет семантики • Нельзя подключить алерты • Могут быть потеряны или не попадать наружу
Вывод логов в stdout ◦ А дальше — лог-агент (Vector, Fluent Bit) передаёт в систему хранения (Loki, OpenSearch, ELK, VictoriaLogs и т.д.) • Структурированные логи ◦ Не текст, а JSON — с полями timestamp, level, message, context. • Корреляция с трейсом
писать чувствительные данные • Добавлять в логи исключения стектрейс • Не генерировать логи в цикле • Писать уровни • Не оставлять необработанные ошибки без логов • Следить за типом данных 🧨
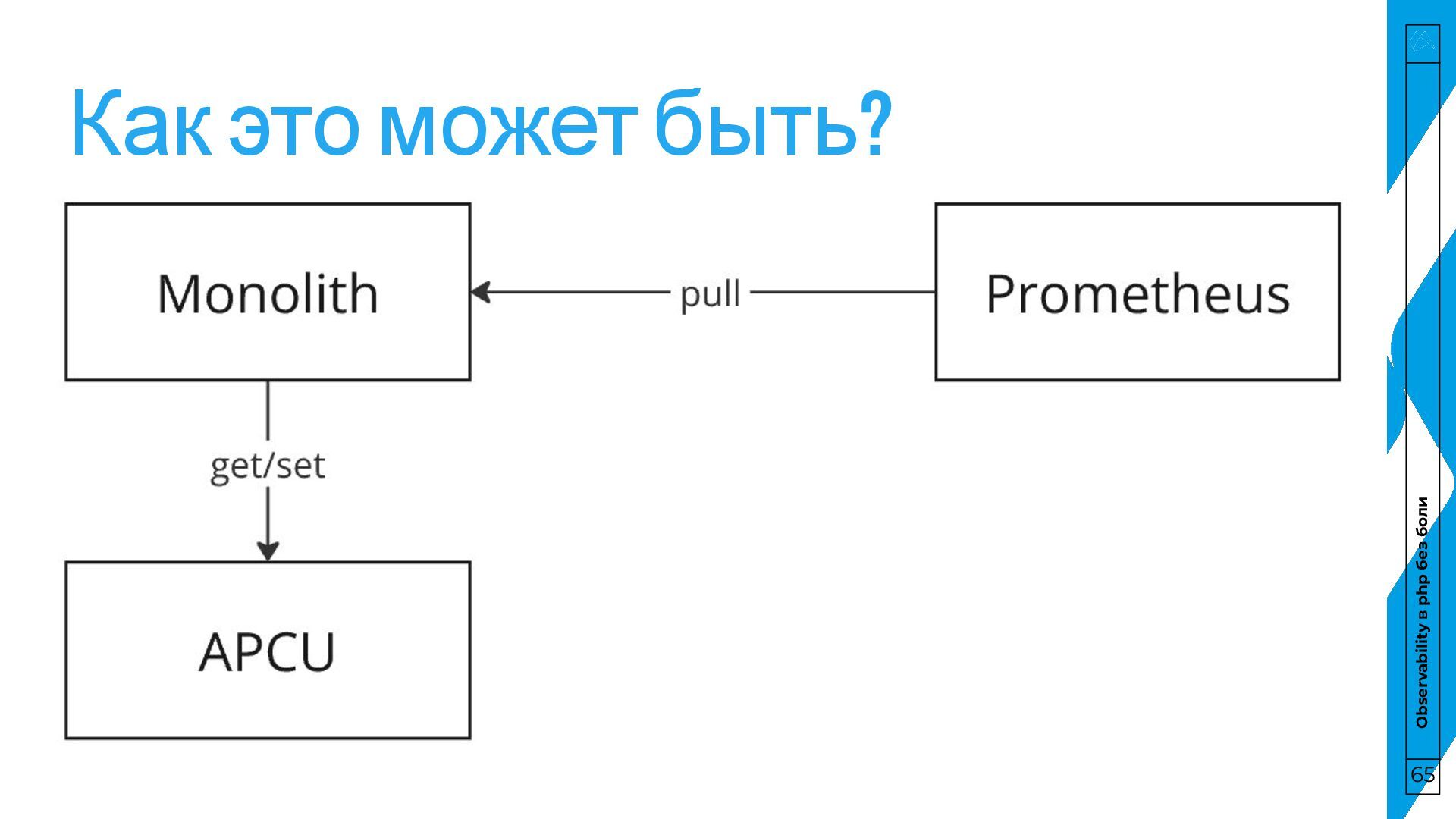
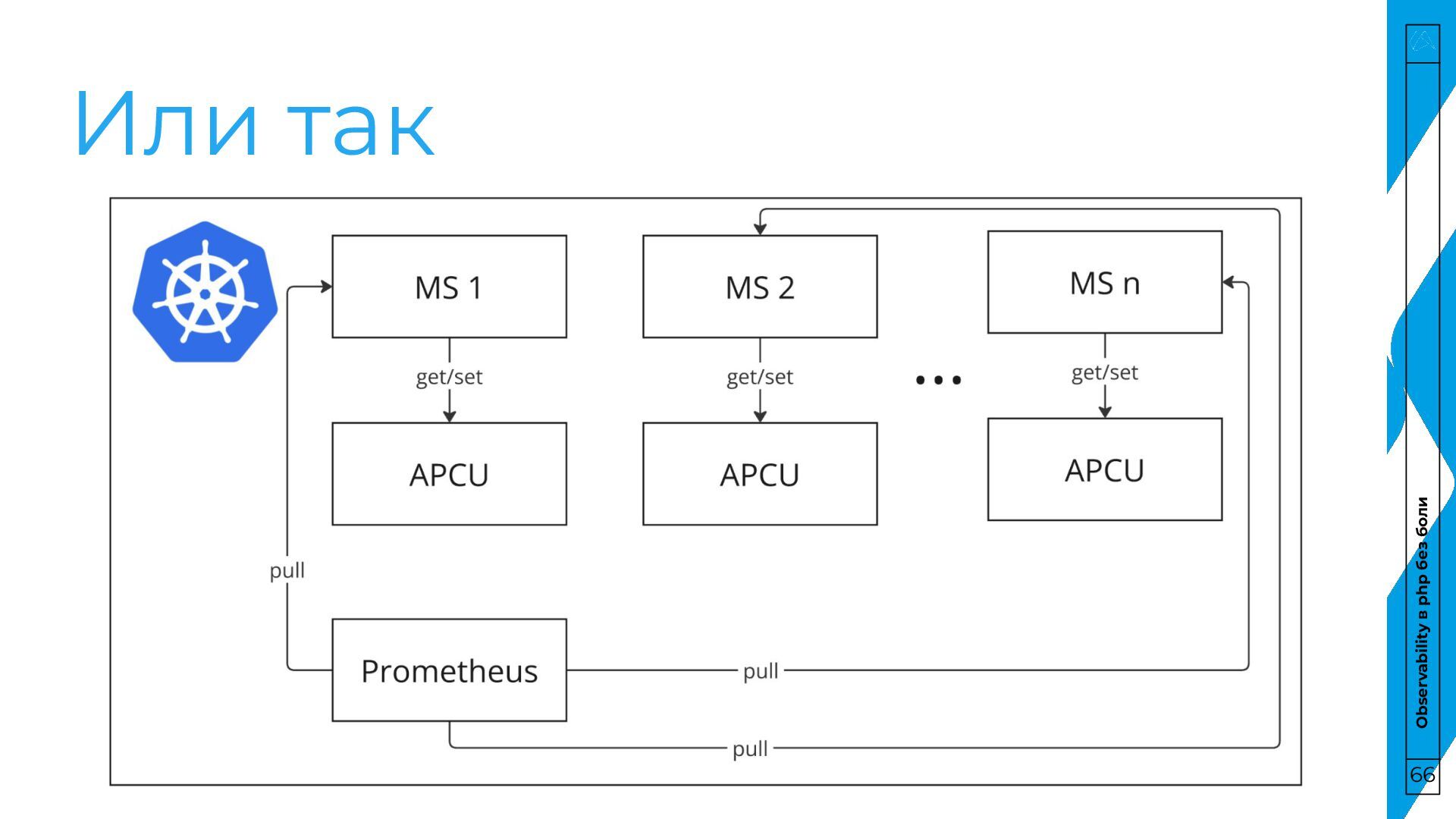
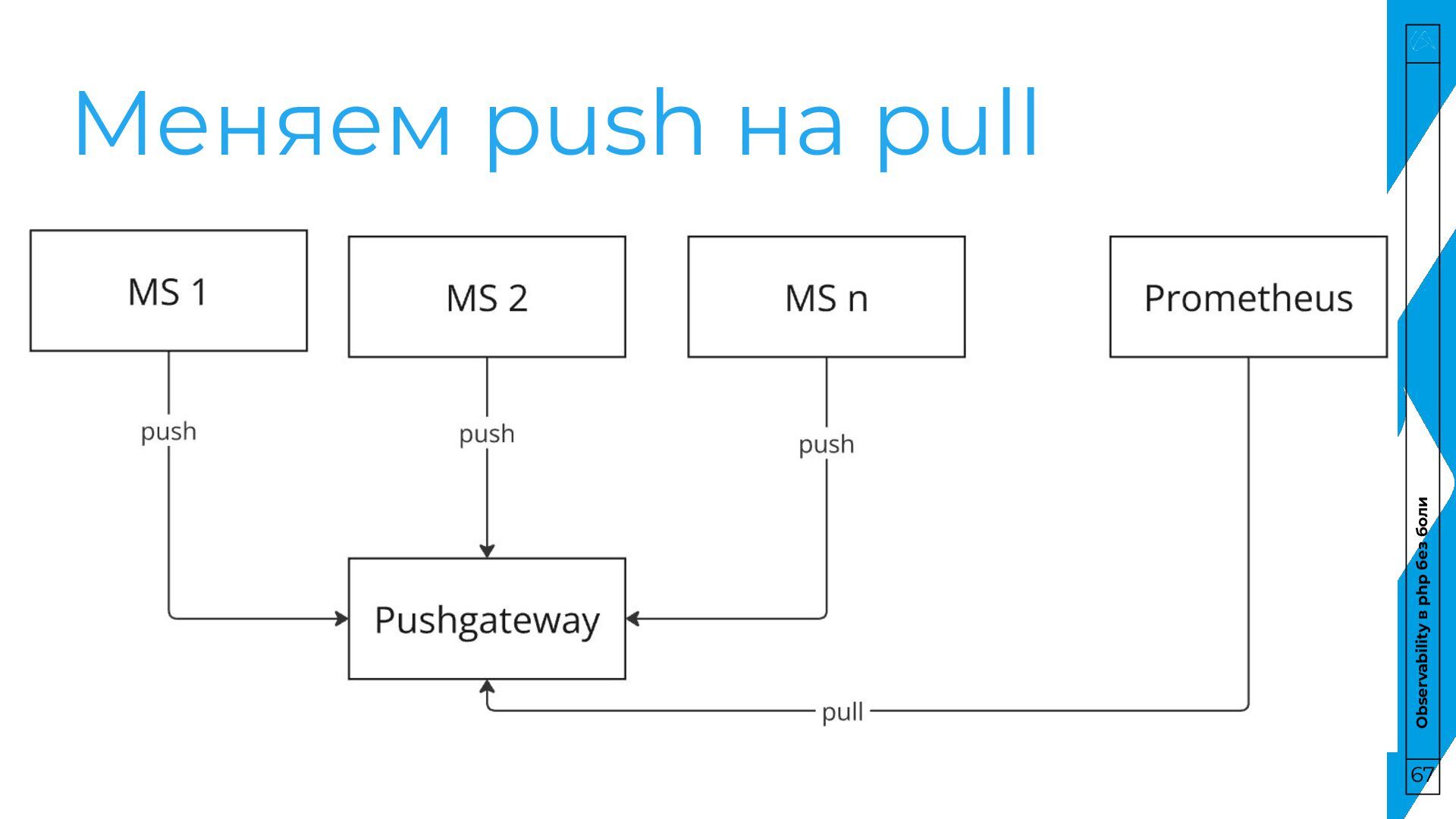
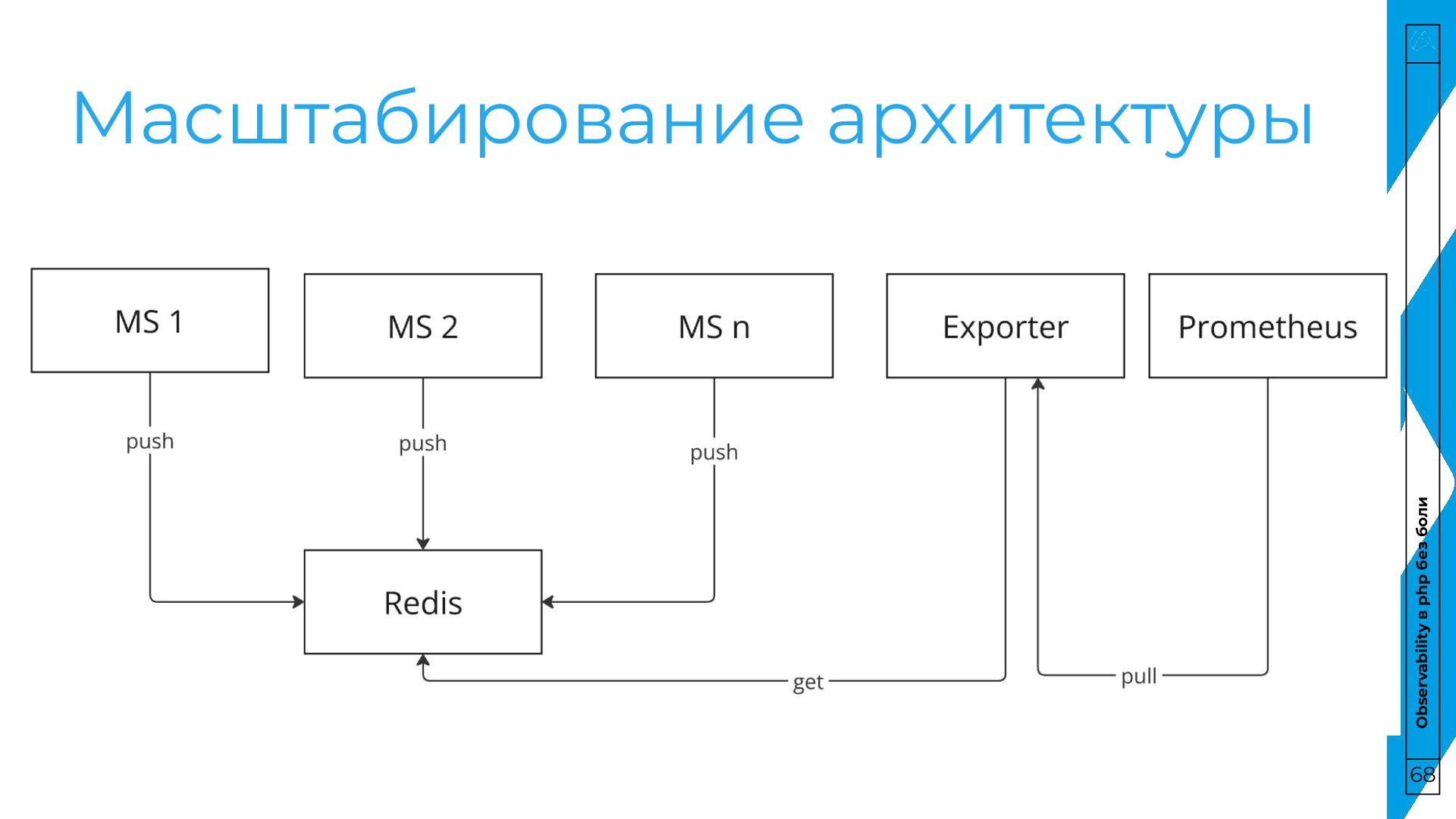
боли Pull • Сервис хранит данные у себя • Prometheus забирает их по расписанию у сервиса Push • Сервис отправляет данные в хранилище, не хранит у себя • Prometheus забирает их по расписанию из хранилища 64
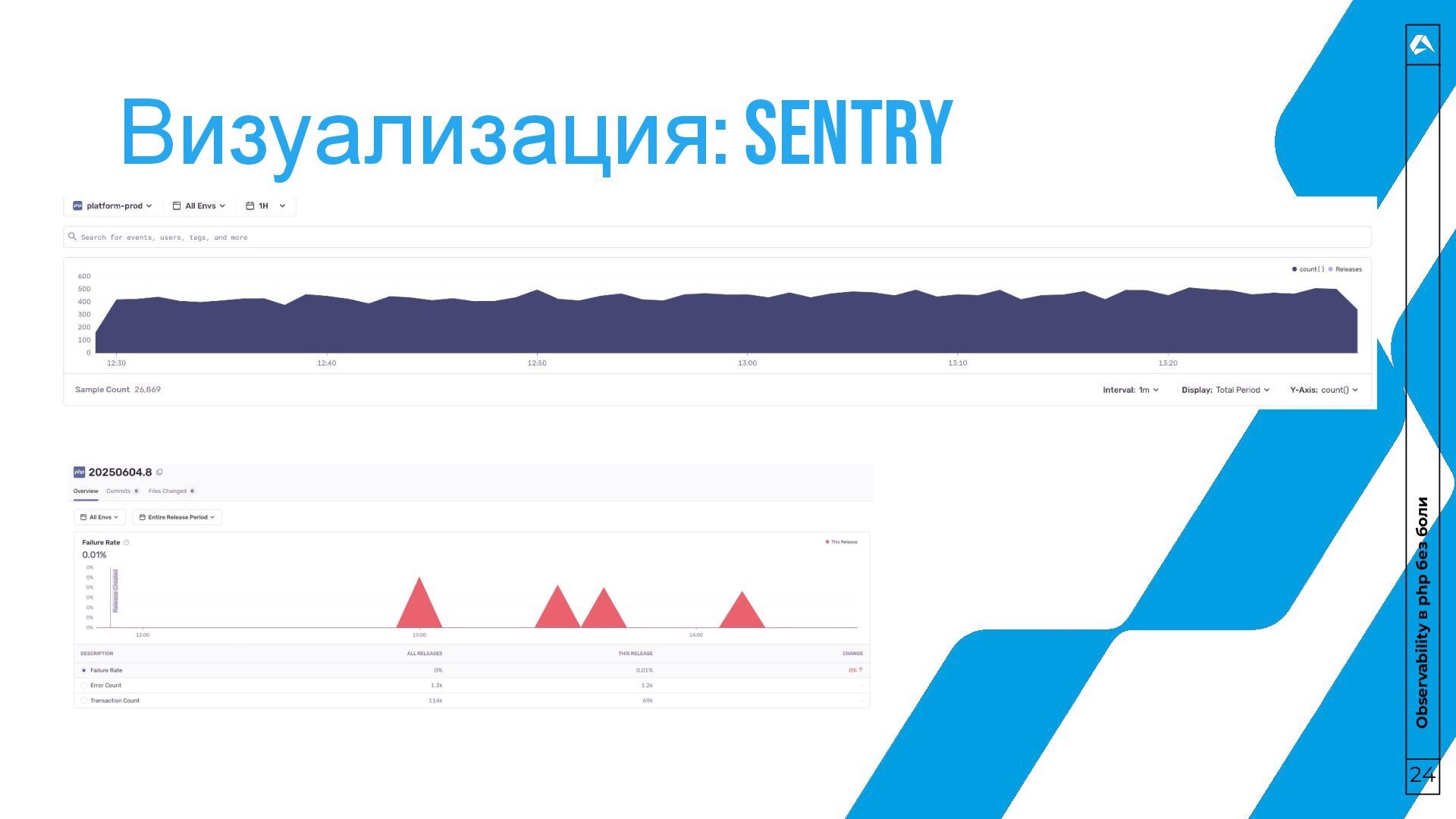
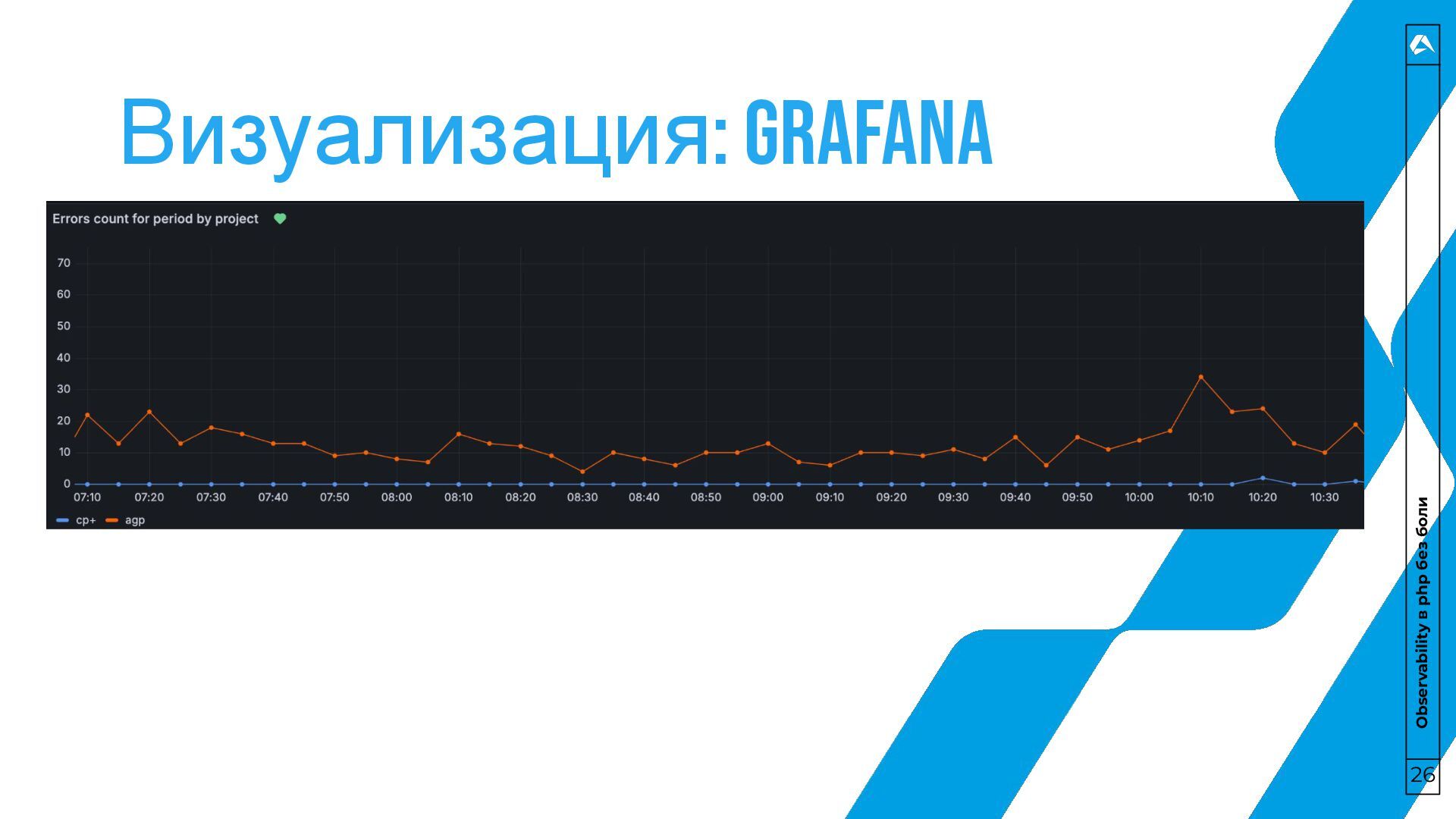
не Opentelemetry • Алертинг – самое быстрое решение для начала • Logs – не просто запись текста в файлик • Tracing – чтобы понимать, что происходит внутри системы • Profiling – чтобы понимать, как это происходит внутри системы • Визуализация – очень важный этап
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Observability в php без боли Структура лога 53 [2023-10-27 14:35:10]](https://files.speakerdeck.com/presentations/8d5a5989a7cd4de7a62e69058a92b738/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}