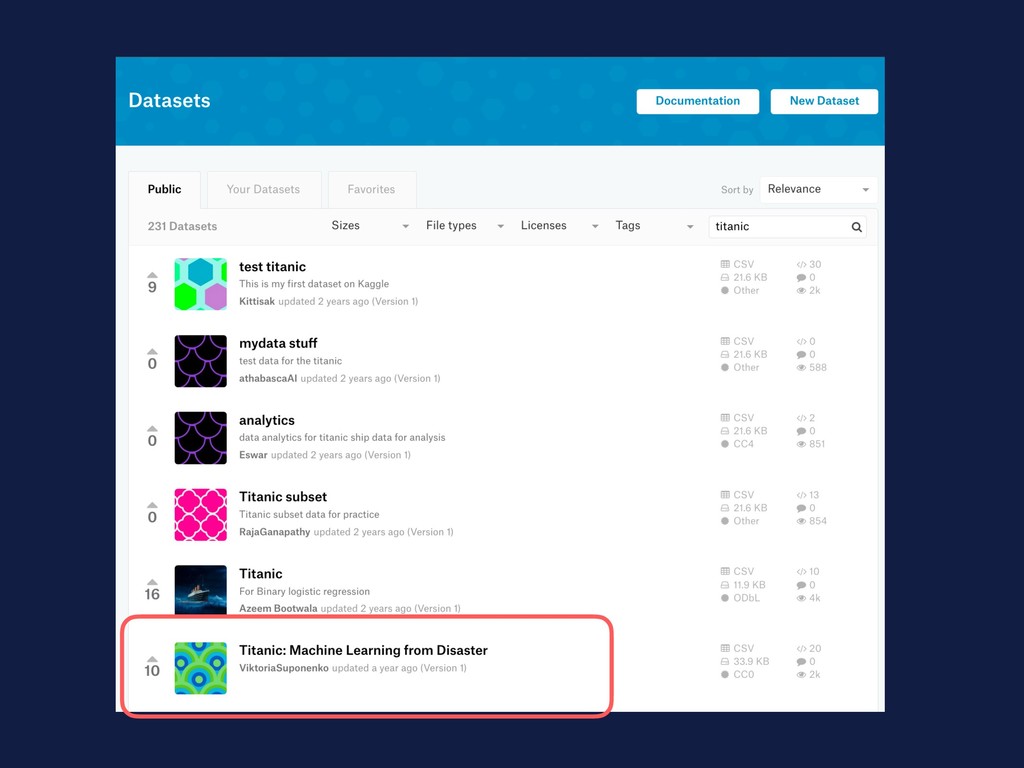
of datasets, it already have installed most of tools you’ll need for a basic analysis, is a good place to see the people’s code and built a portfolio Why Kaggle?
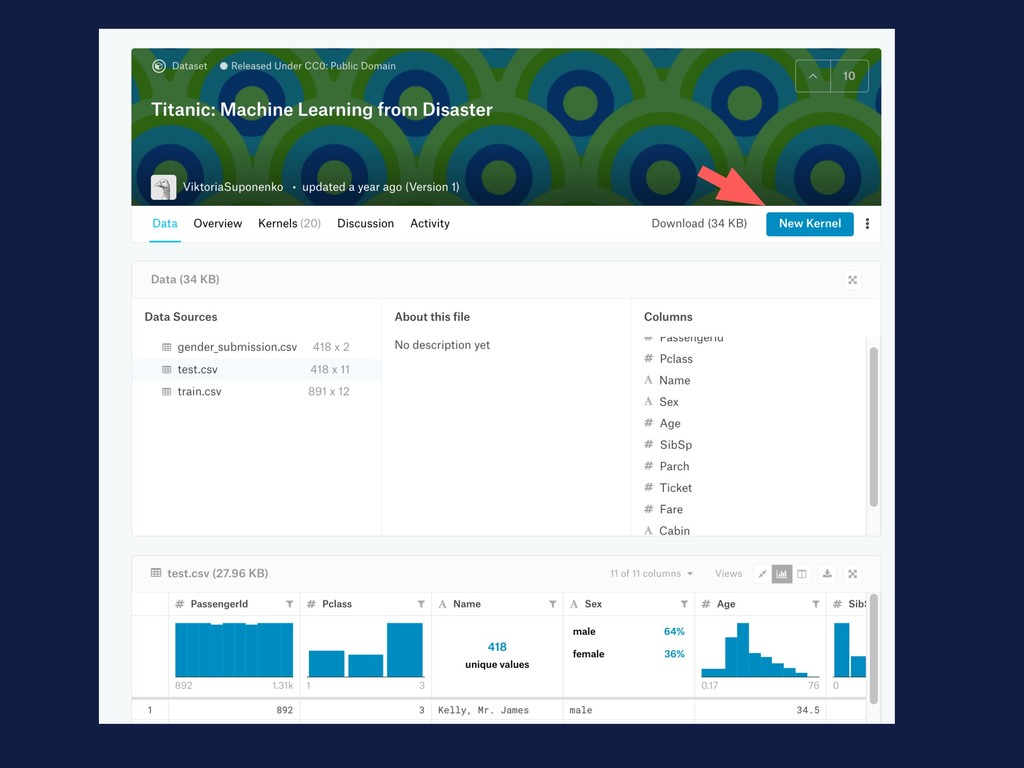
will tell you that the documents are ready for you in ../input/. So, we can read the files by with a Pandas function and with the path of the file df = pd.read_csv(‘../input/train.csv')
structures. You have rows indicated by numbers and columns with names. You can check the first 5 rows of a data frame to see the basic structure: df.head()
Series, we can store this value in a variable and use it to plot a pie chart :) passengers_per_class = df[‘Pclass’].value_counts() passengers_per_class.plot.pie()
it to checkout our variables. Let’s see which class survived the most survived = df[‘Survived'] > 0 filtered_df = df[survived] passenger_per_class = filtered_df[“Pclass”].value_counts() passenger_per_class.plot.pie()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
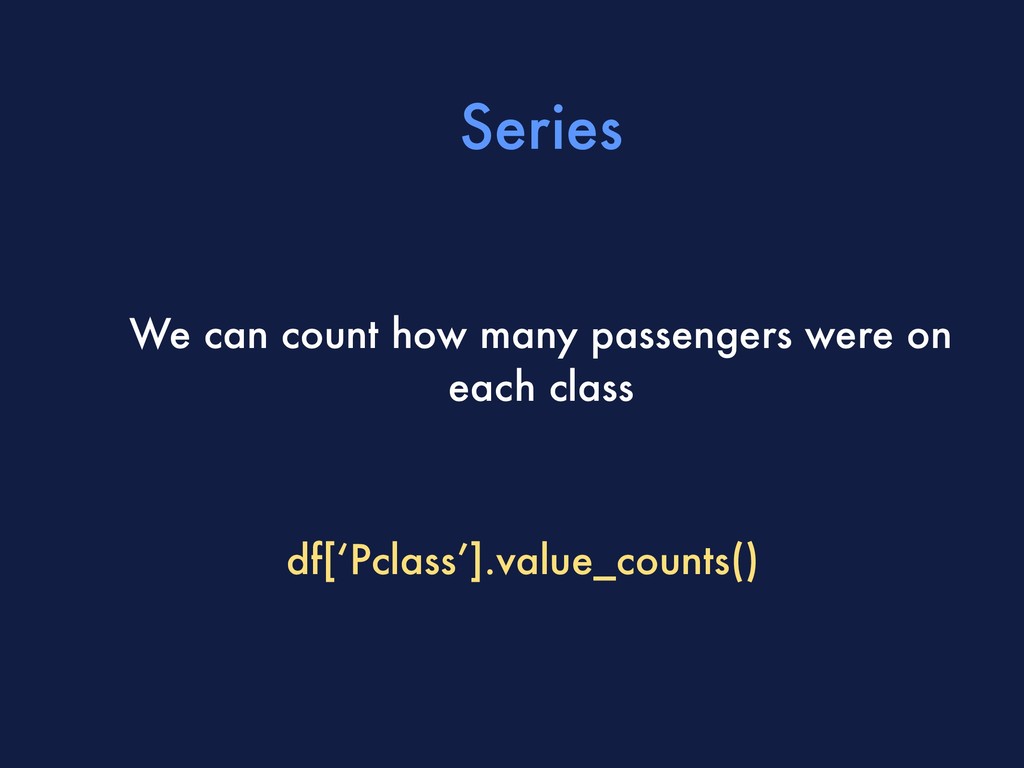{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Dataframes We can group two columns to count df[“Ageclass”] =](https://files.speakerdeck.com/presentations/73ee72dd8b2a4905a341e2efa2e2a078/slide_37.jpg){kind=link}