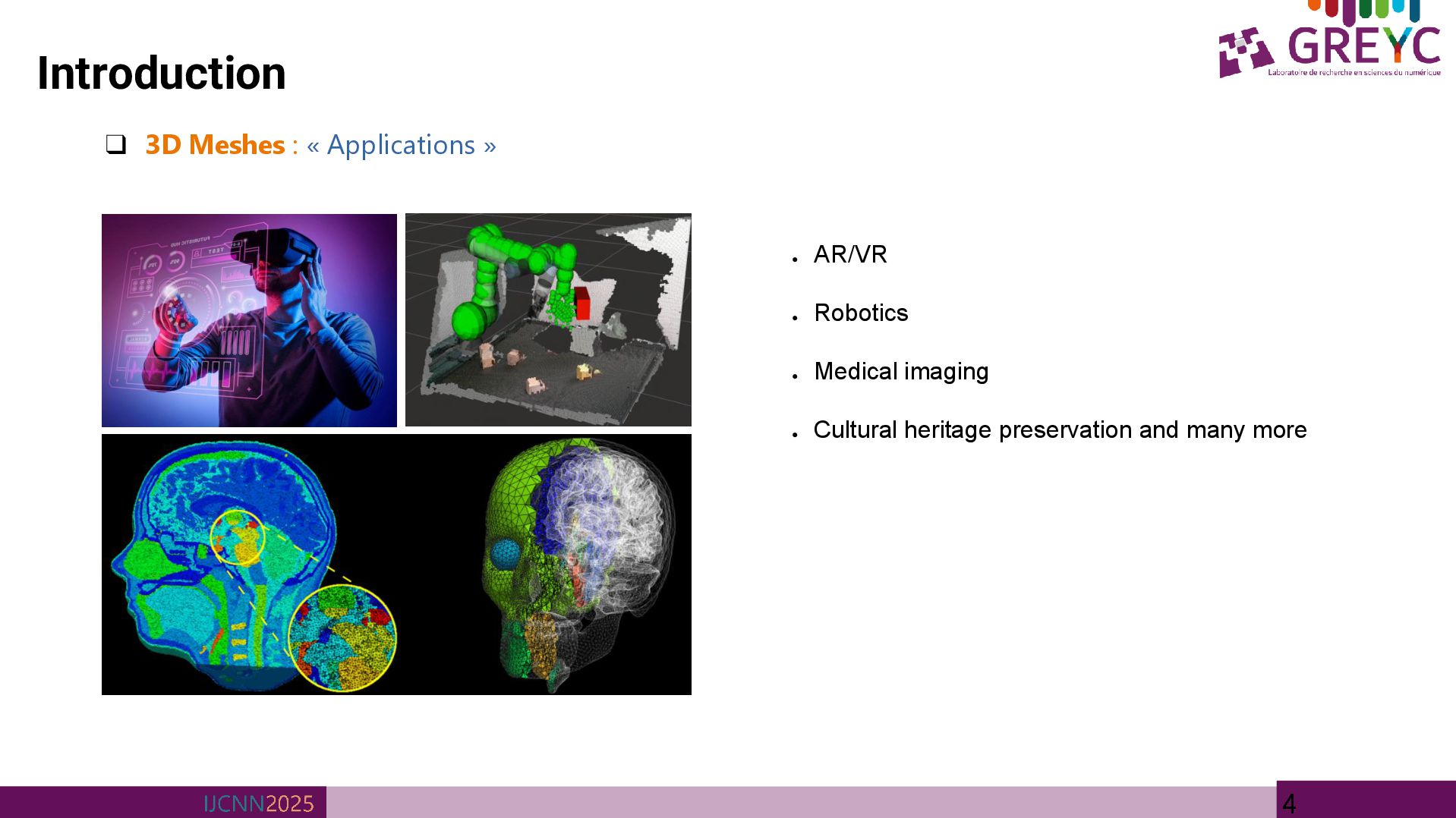
3D Models have appeared everywhere in our lives as a result of recent advances in 3D scanning devices such as • Laser, LiDAR, RGB-D, and rendering technologies • 3D Meshes are fundamental data representations for capturing complex geometric shapes in computer vision and graphics applications LiDAR MS Kinect
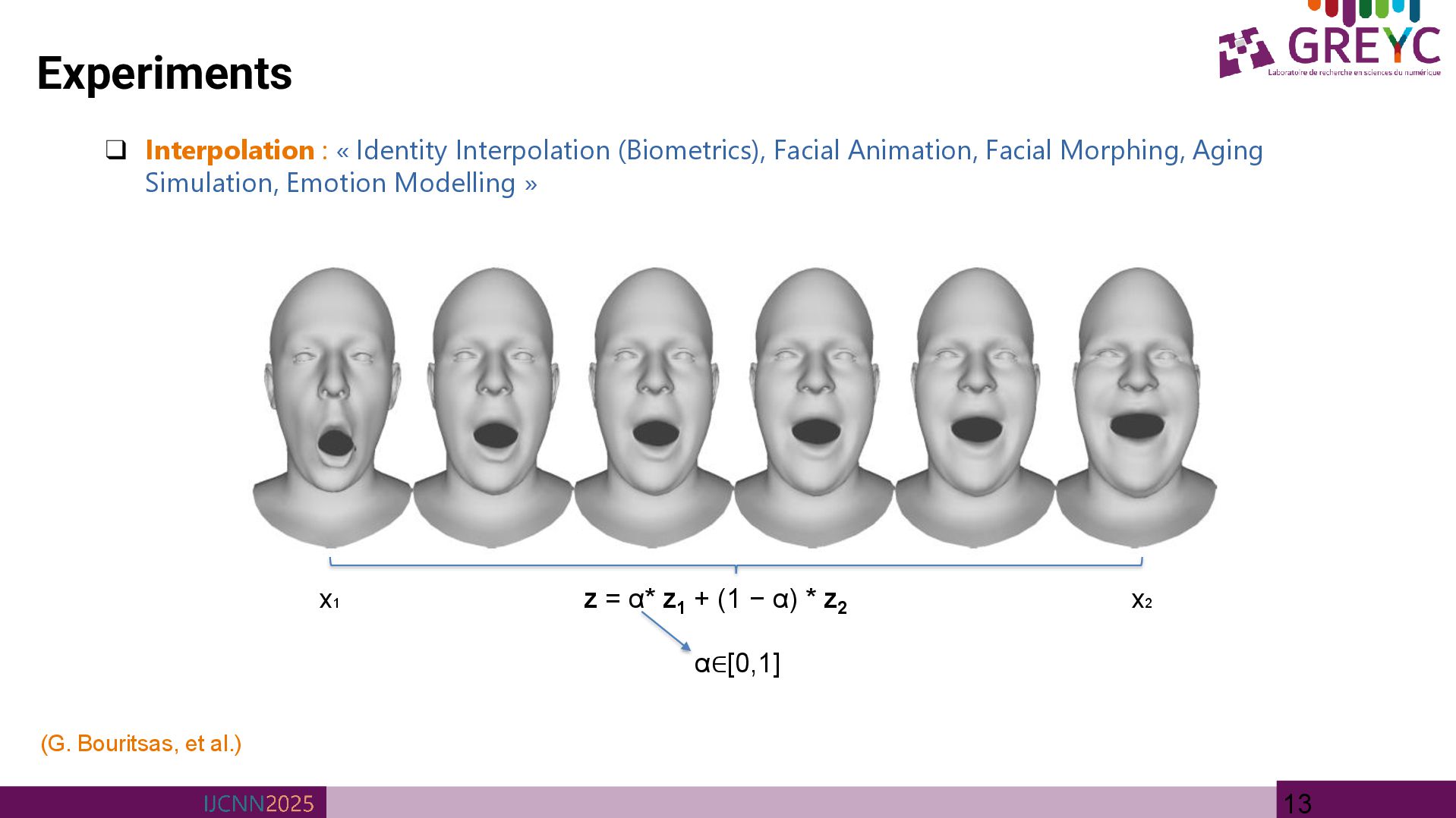
• 3D Mesh reconstruction is a process of reconstructing the input mesh as close as possible • 3D Mesh reconstruction is a pre-processing step that could be used for many downstream tasks such as: • Mesh Completion • Mesh Interpolation/ Extrapolation • Mesh Denoising etc.
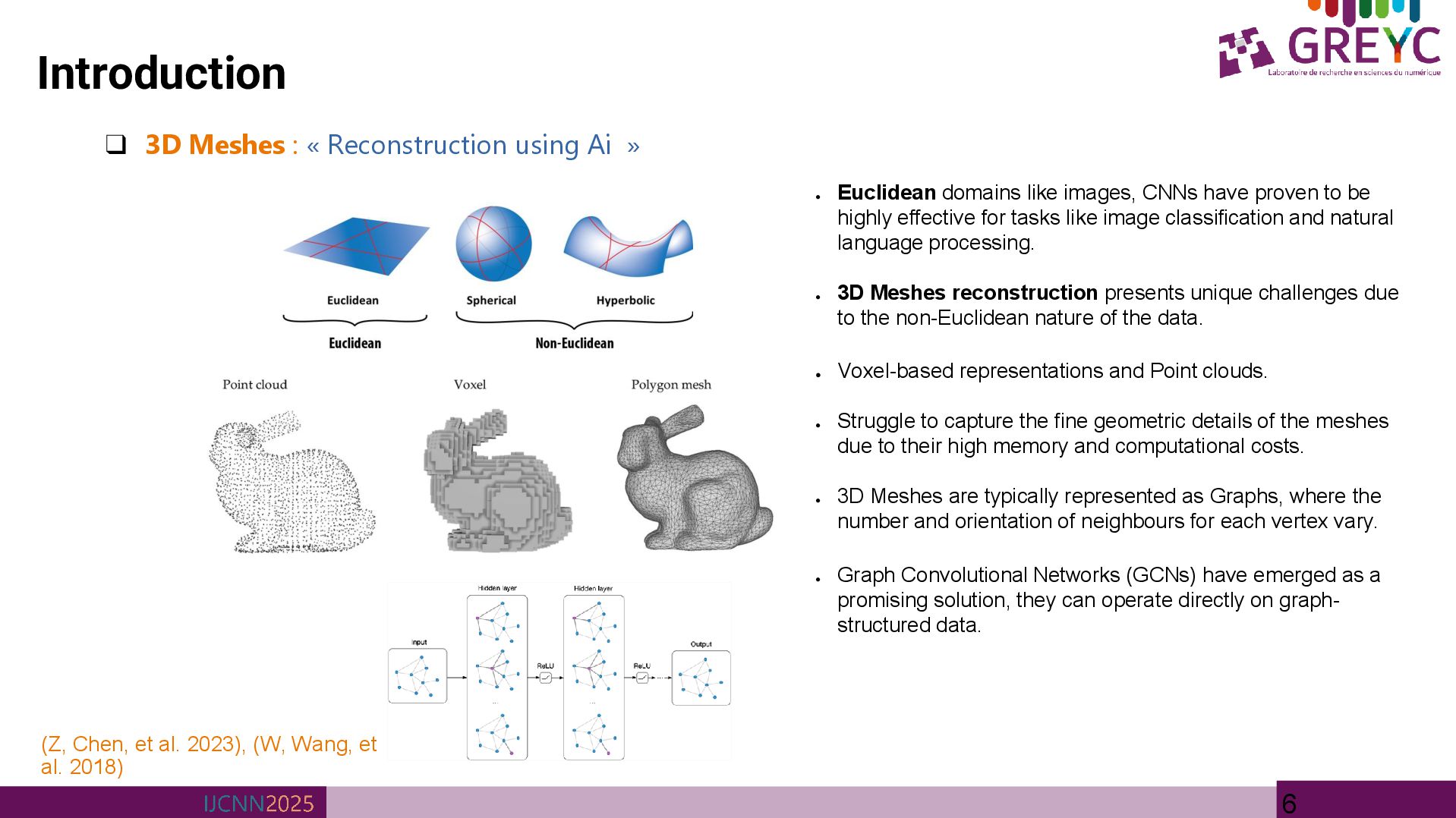
» • Euclidean domains like images, CNNs have proven to be highly effective for tasks like image classification and natural language processing. • 3D Meshes reconstruction presents unique challenges due to the non-Euclidean nature of the data. • Voxel-based representations and Point clouds. • Struggle to capture the fine geometric details of the meshes due to their high memory and computational costs. • 3D Meshes are typically represented as Graphs, where the number and orientation of neighbours for each vertex vary. • Graph Convolutional Networks (GCNs) have emerged as a promising solution, they can operate directly on graph- structured data. (Z, Chen, et al. 2023), (W, Wang, et al. 2018)
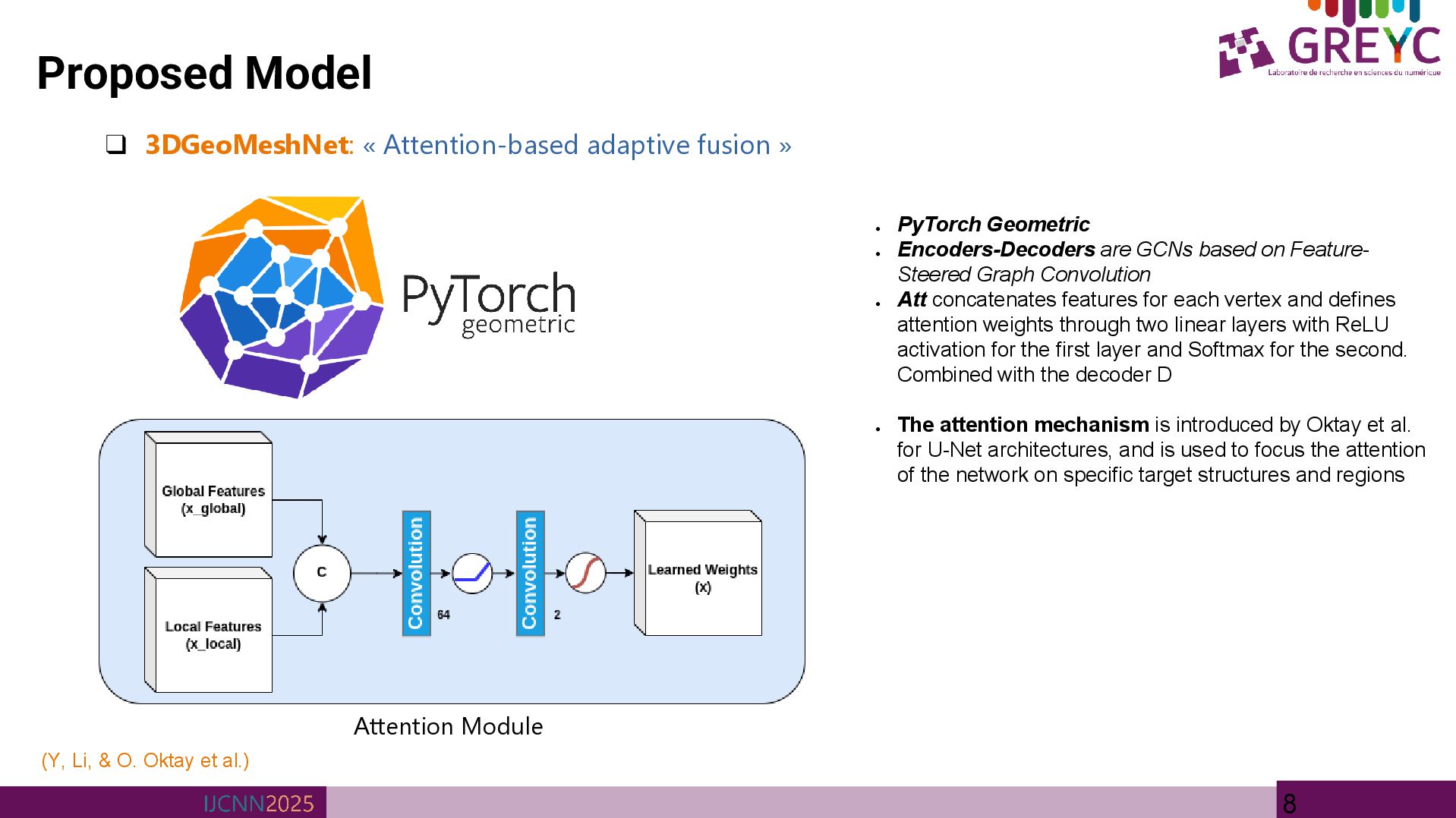
• PyTorch Geometric • Encoders-Decoders are GCNs based on Feature- Steered Graph Convolution • Att concatenates features for each vertex and defines attention weights through two linear layers with ReLU activation for the first layer and Softmax for the second. Combined with the decoder D • The attention mechanism is introduced by Oktay et al. for U-Net architectures, and is used to focus the attention of the network on specific target structures and regions (Y, Li, & O. Oktay et al.) Attention Module
is trained using a combination of two losses. • During the training, the reconstruction loss is defined as the Mean Squared Loss (MSE). • To enforce a smooth latent space and maintain a spherical distribution for the latent representations, we use a custom spherical regularization loss. • This ensures that the latent features z lie close to a spherical manifold, promoting better generalization. (Elmoataz, Quéau, Clouard, et al.) Total Loss = LMSE + λreg · LReg 𝐿MSE = 1 𝑁 𝑥out − 𝑦 F 2 𝑥 𝐹 = 𝑖 𝑗 𝑥𝑖𝑗 2 𝐿reg = ( 𝑥out − 𝑦 2 −1) 2 λ reg = 0.0001
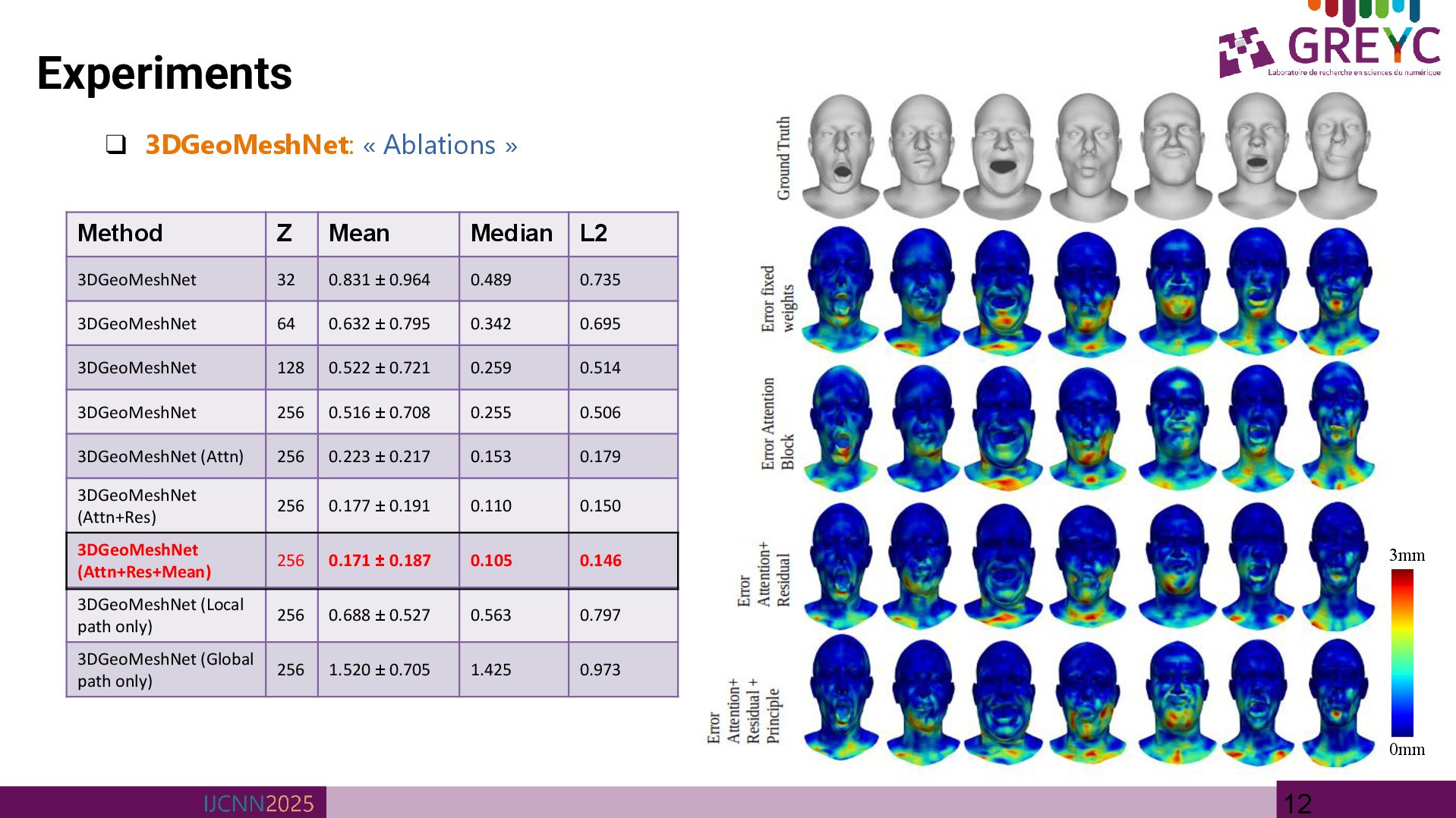
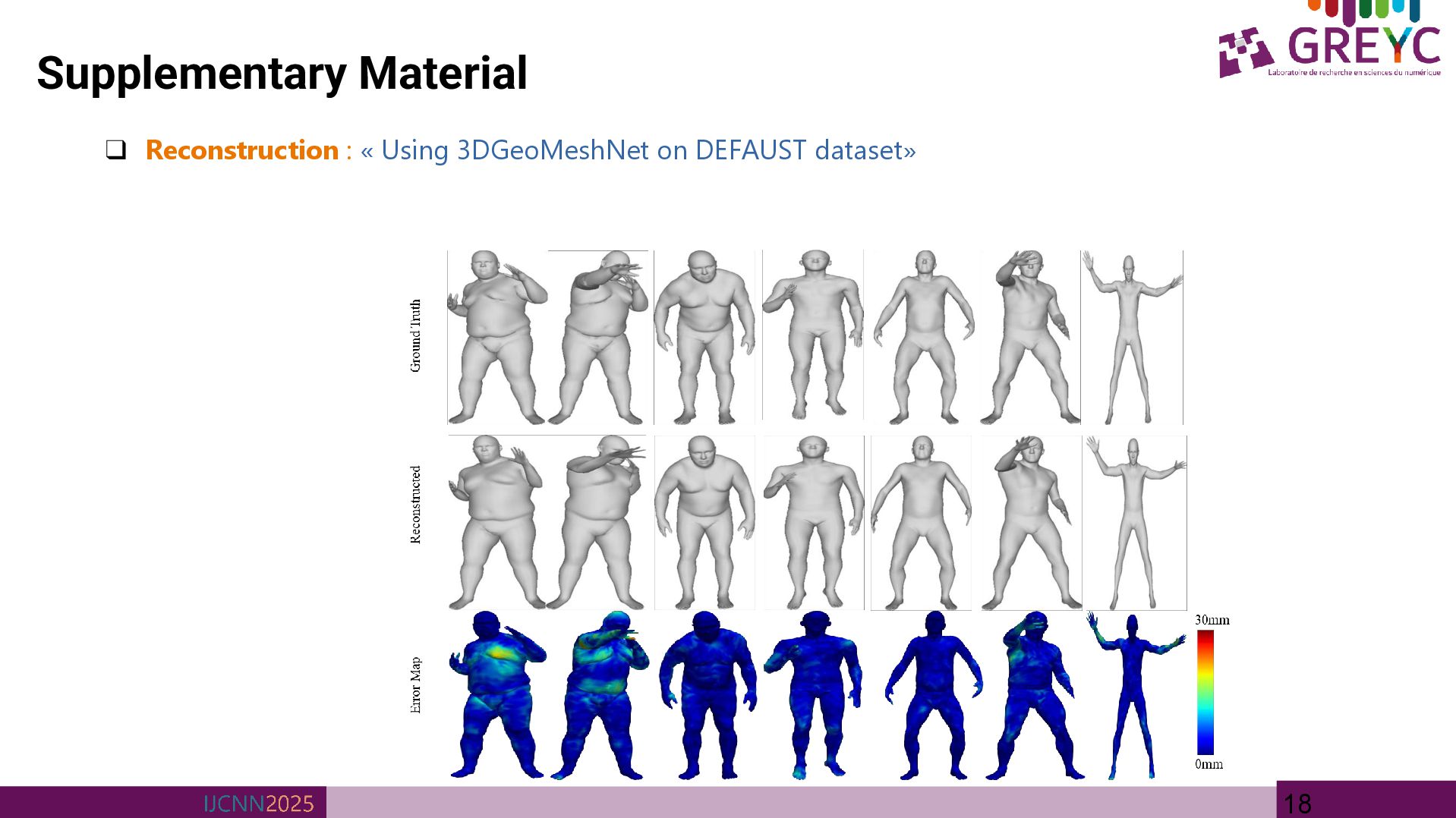
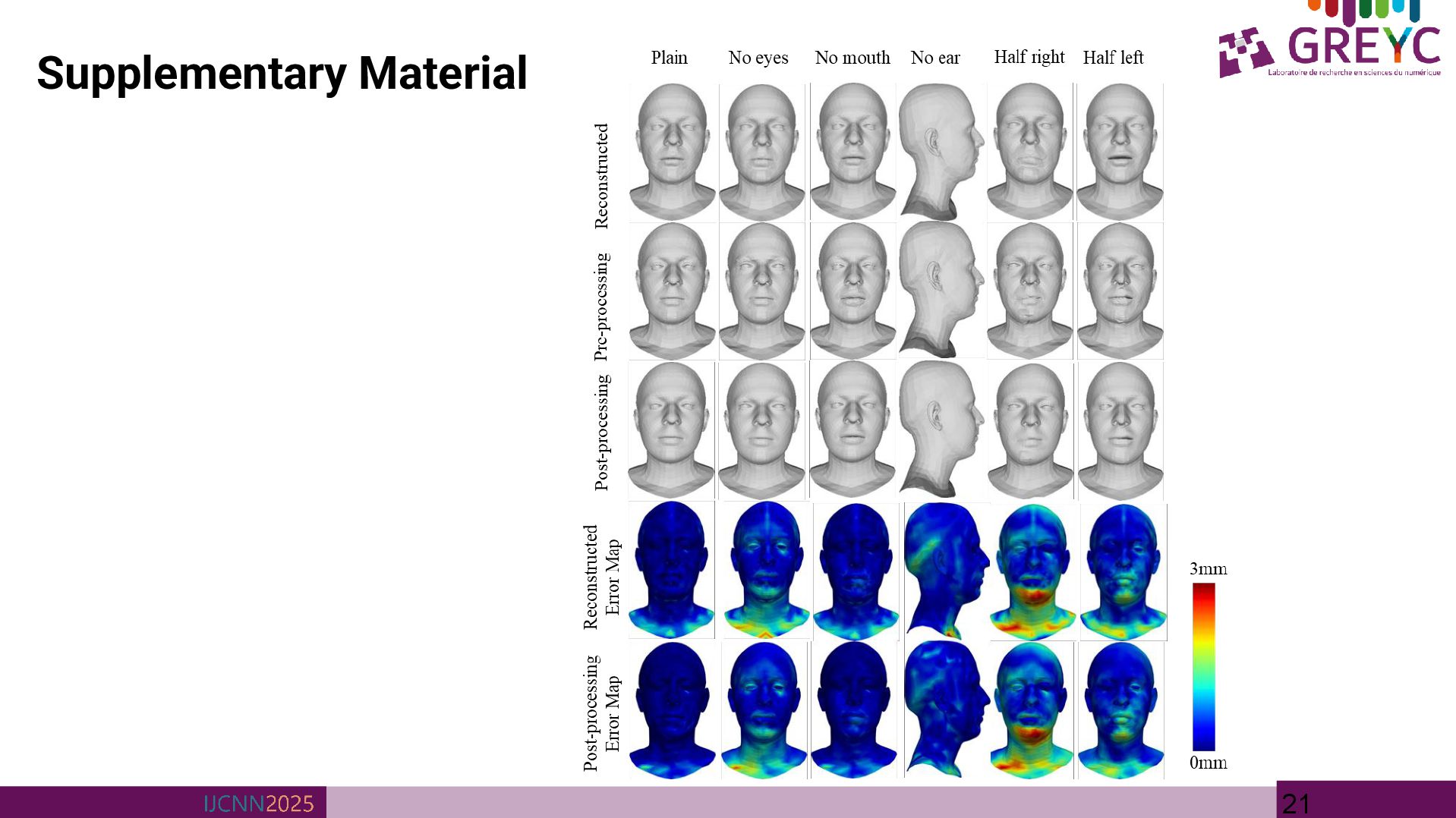
Details» • 3DGeoMeshNet is trained on COMA dataset • COMA is a human facial dataset that consists of 12 classes of extreme expressions from 12 different subjects. • The dataset contains 20466 3D meshes that were registered to a common reference template with N = 5023 vertices. • Learning rate at 0.0005 and halved it every 50 epoch. • The batch size is 32 and the total epoch number is 300. • Local convolutional layers are configured with feature sizes of 8, 16, and 32 • Global convolutional layers are designed with feature sizes of 32, 64, and 128. • The training process utilized the Adam optimizer within the PyTorch framework, with the entire training process taking approximately 24 hours on an NVIDIA Geforce RT X4090 GPU. (Elmoataz, Quéau, Clouard, et al.) COMA facial Dataset
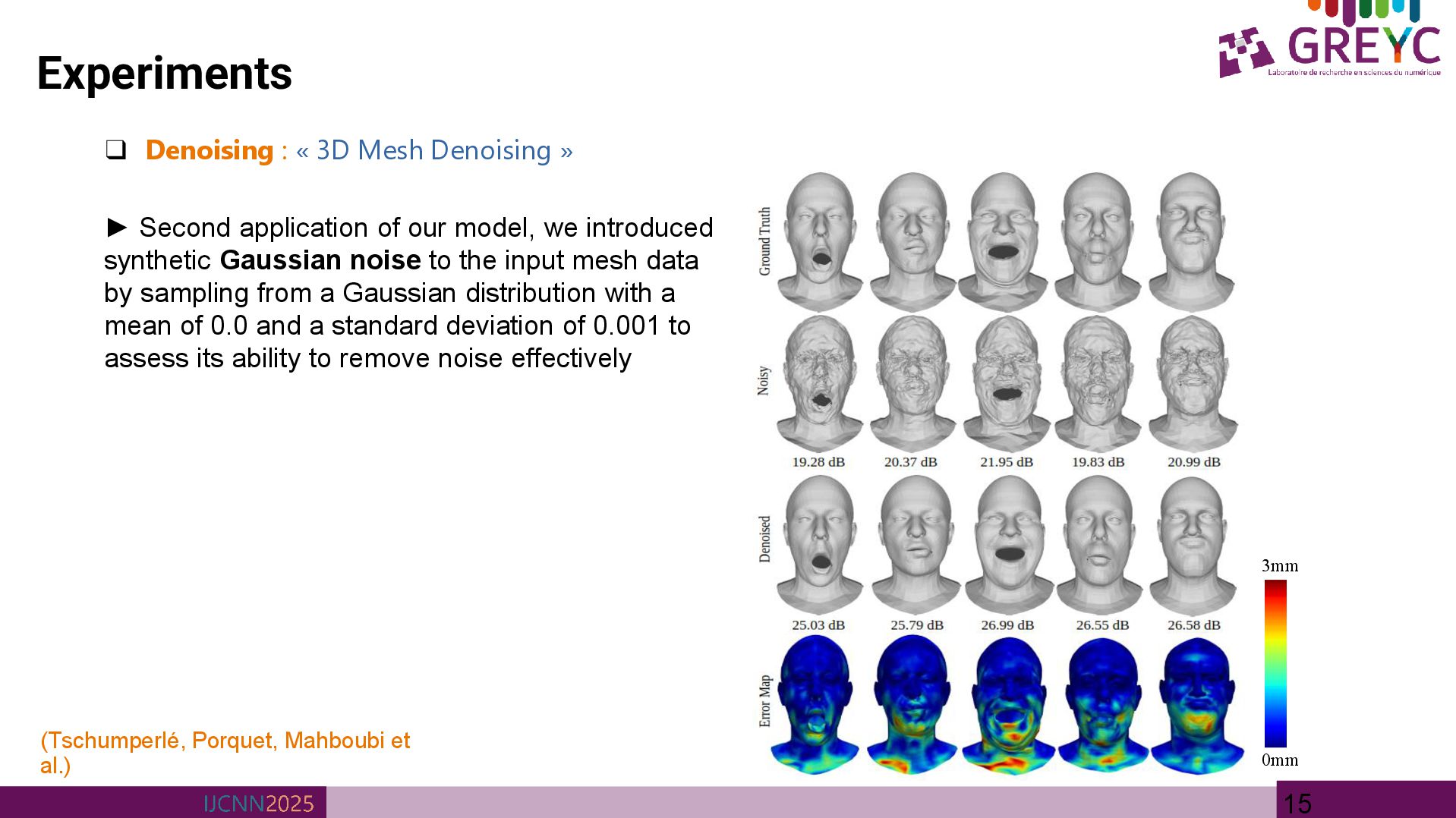
(Tschumperlé, Porquet, Mahboubi et al.) ► Second application of our model, we introduced synthetic Gaussian noise to the input mesh data by sampling from a Gaussian distribution with a mean of 0.0 and a standard deviation of 0.001 to assess its ability to remove noise effectively 3mm 0mm
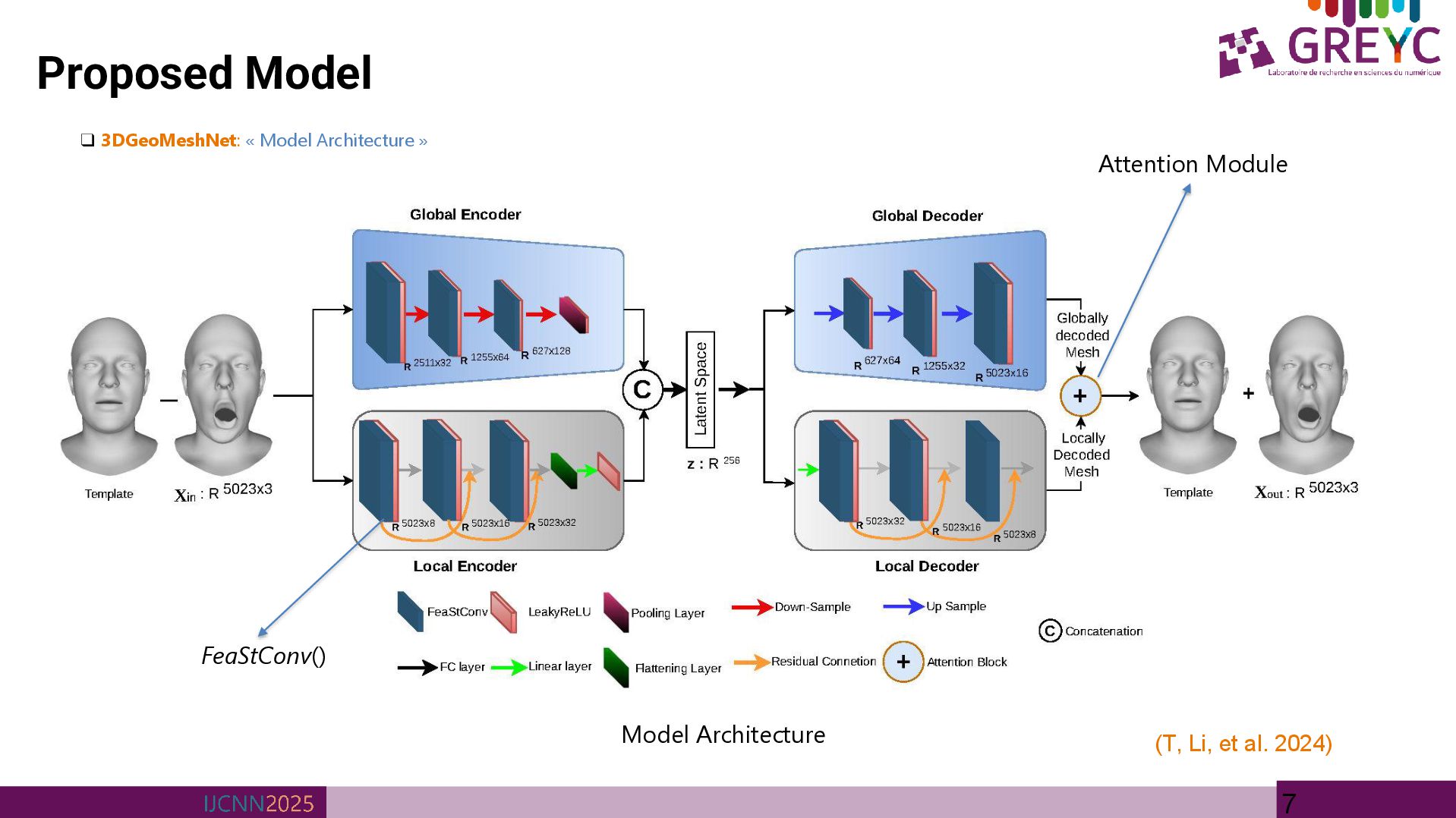
multi-scale GCN for 3D mesh representation and reconstruction. • Utilizes an autoencoder-decoder architecture comprising complementary local and global networks. • Global network is optimized for capturing macro-level mesh characteristics, including overall shape topology. • Local network focuses on micro-level details, such as facial expressions. • Experimental results conducted on the widely utilized COMA human facial dataset. • Future works: The current implementation is constrained to non-textured, monochromatic meshes; a logical extension of this research will involve the incorporation of textured mesh data. • Furthermore, while the present approach operates on meshes with fixed vertex counts and topologies, future investigations will focus on generalizing the framework to accommodate meshes with heterogeneous topologies and variable vertex counts, thereby enhancing the robustness and versatility of the proposed methodology. • Applications: provide an efficient and scalable way to represent surfaces, making them highly suitable for applications such as 3D shape reconstruction, shape modelling, face recognition, and shape segmentation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 Experiments Method Z Mean Median PCA [10] – 1.639](https://files.speakerdeck.com/presentations/33306a4f3f4f42ac94dfefb6d5d0c6f7/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}