& Indexing (ii) Prof. Lipyeow Lim InformaBon & Computer Science Department University of Hawaii at Manoa 1 Lipyeow Lim -‐-‐ University of Hawaii at Manoa
selecBons on the search key fields for the index. – Any subset of the fields of a relaBon can be the search key for an index on the relaBon. – Search key is not the same as key (minimal set of fields that uniquely idenBfy a record in a relaBon). • An index contains a collecBon of data entries, and supports efficient retrieval of all data entries k* with a given key value k. – A data entry is usually in the form <key, rid> – Given data entry k*, we can find record with key k in at most one disk I/O. (Details soon …) Lipyeow Lim -‐-‐ University of Hawaii at Manoa 2
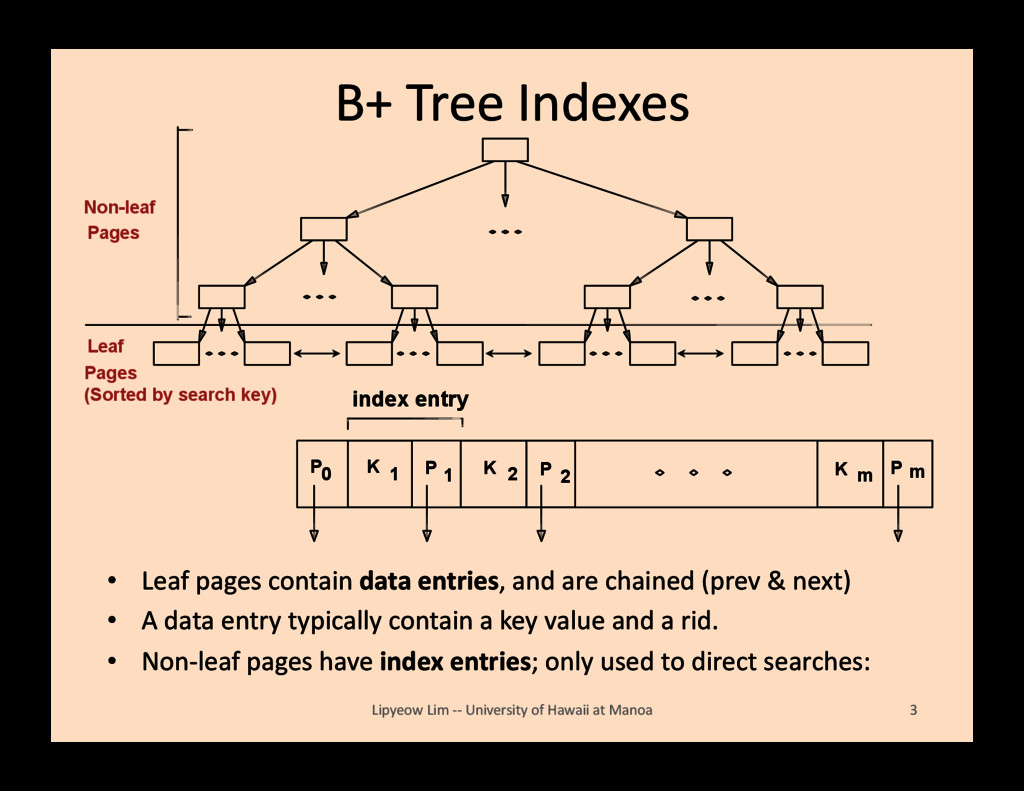
and are chained (prev & next) • A data entry typically contain a key value and a rid. • Non-‐leaf pages have index entries; only used to direct searches: Lipyeow Lim -‐-‐ University of Hawaii at Manoa 3 Non-leaf Pages Pages (Sorted by search key) Leaf P 0 K 1 P 1 K 2 P 2 K m P m index entry
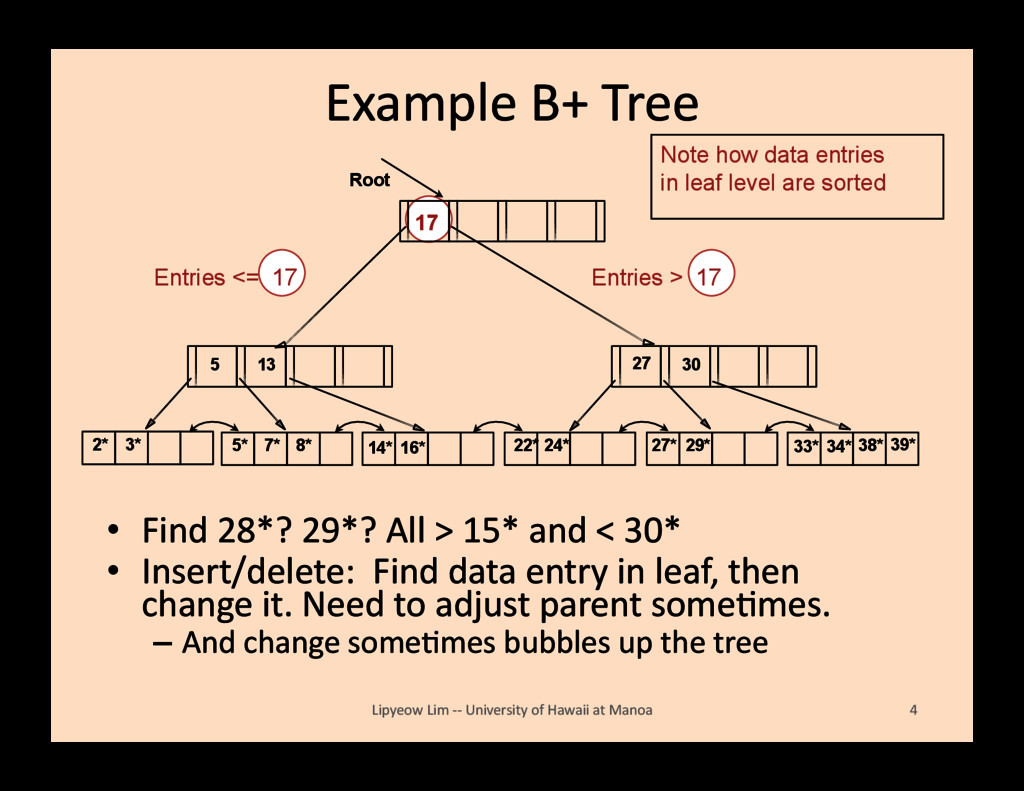
15* and < 30* • Insert/delete: Find data entry in leaf, then change it. Need to adjust parent someBmes. – And change someBmes bubbles up the tree Lipyeow Lim -‐-‐ University of Hawaii at Manoa 4 2* 3* Root 17 30 14* 16* 33* 34* 38* 39* 13 5 7* 5* 8* 22* 24* 27 27* 29* Entries <= 17 Entries > 17 Note how data entries in leaf level are sorted
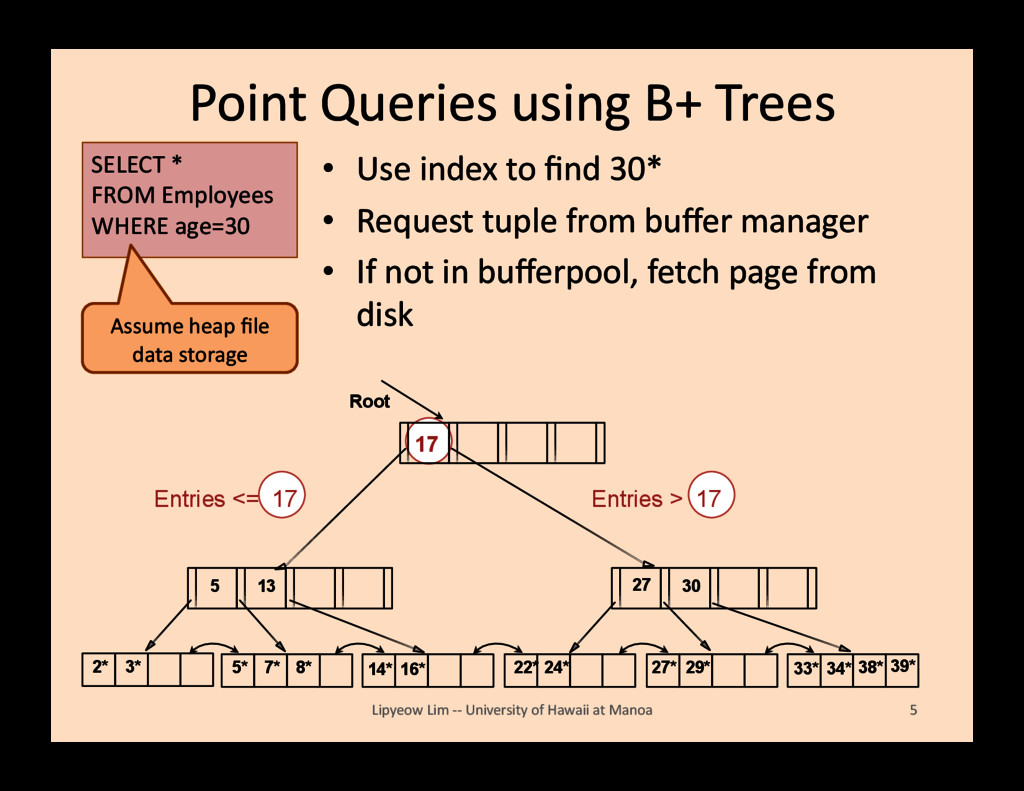
find 30* • Request tuple from buffer manager • If not in bufferpool, fetch page from disk Lipyeow Lim -‐-‐ University of Hawaii at Manoa 5 2* 3* Root 17 30 14* 16* 33* 34* 38* 39* 13 5 7* 5* 8* 22* 24* 27 27* 29* Entries <= 17 Entries > 17 SELECT * FROM Employees WHERE age=30 Assume heap file data storage
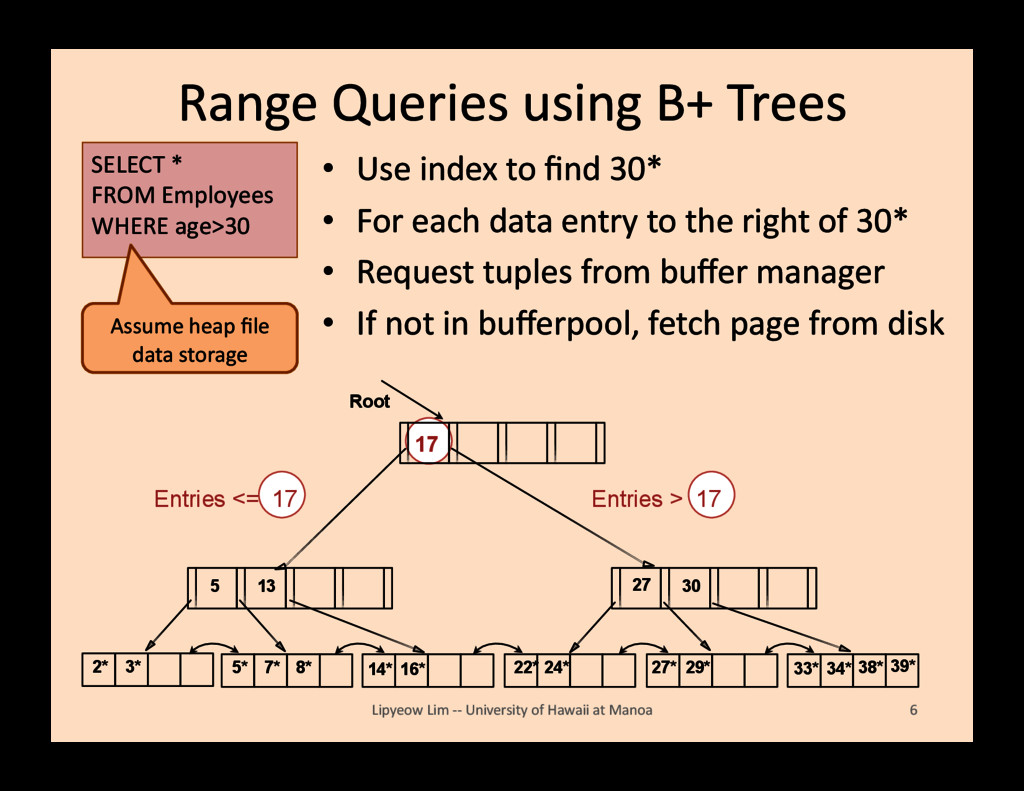
find 30* • For each data entry to the right of 30* • Request tuples from buffer manager • If not in bufferpool, fetch page from disk Lipyeow Lim -‐-‐ University of Hawaii at Manoa 6 2* 3* Root 17 30 14* 16* 33* 34* 38* 39* 13 5 7* 5* 8* 22* 24* 27 27* 29* Entries <= 17 Entries > 17 SELECT * FROM Employees WHERE age>30 Assume heap file data storage
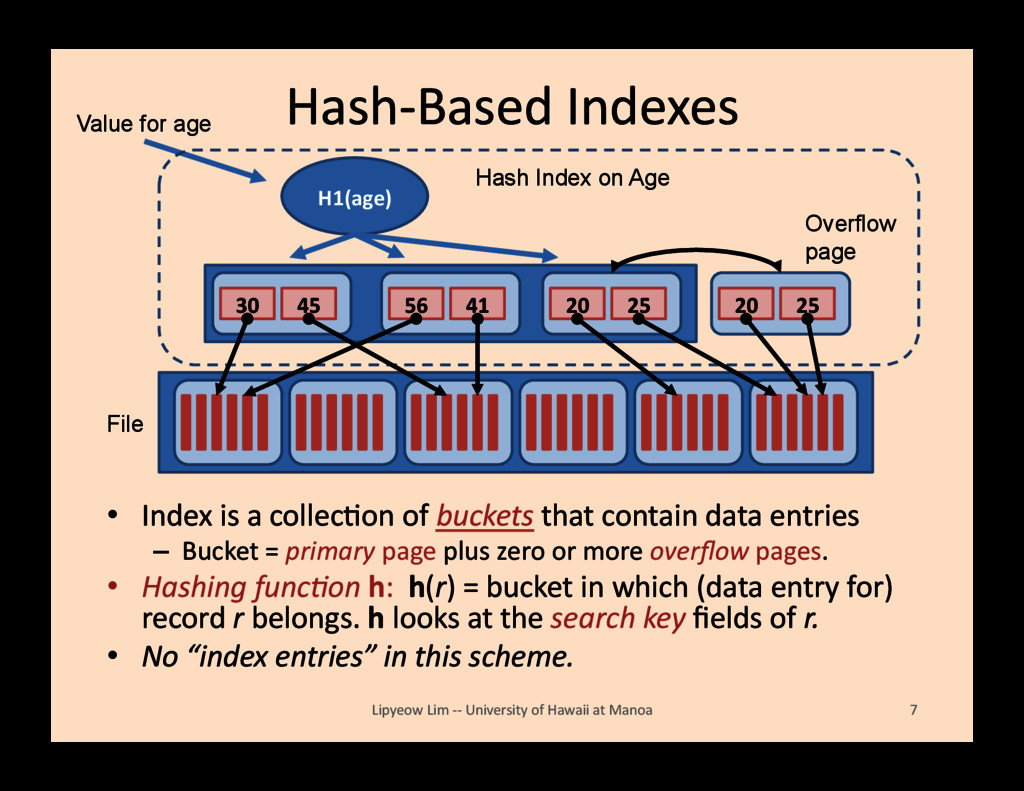
that contain data entries – Bucket = primary page plus zero or more overflow pages. • Hashing func=on h: h(r) = bucket in which (data entry for) record r belongs. h looks at the search key fields of r. • No “index entries” in this scheme. Lipyeow Lim -‐-‐ University of Hawaii at Manoa 7 H1(age) File Value for age Hash Index on Age 30 45 56 41 20 25 20 25 Overflow page
Entry k* ? – PossibiliBes: • The data record itself with key value k • <k, rid of data record with key value k> • <k, list of rids of data records with key value k> – Variable size data entries – Applies to any indexing technique • Primary vs Secondary – Primary index : search key contains primary key – Unique Index : search key contains candidate key • Clustered vs unclustered – Clustered index: order of data records same or close to order of data entries Lipyeow Lim -‐-‐ University of Hawaii at Manoa 8
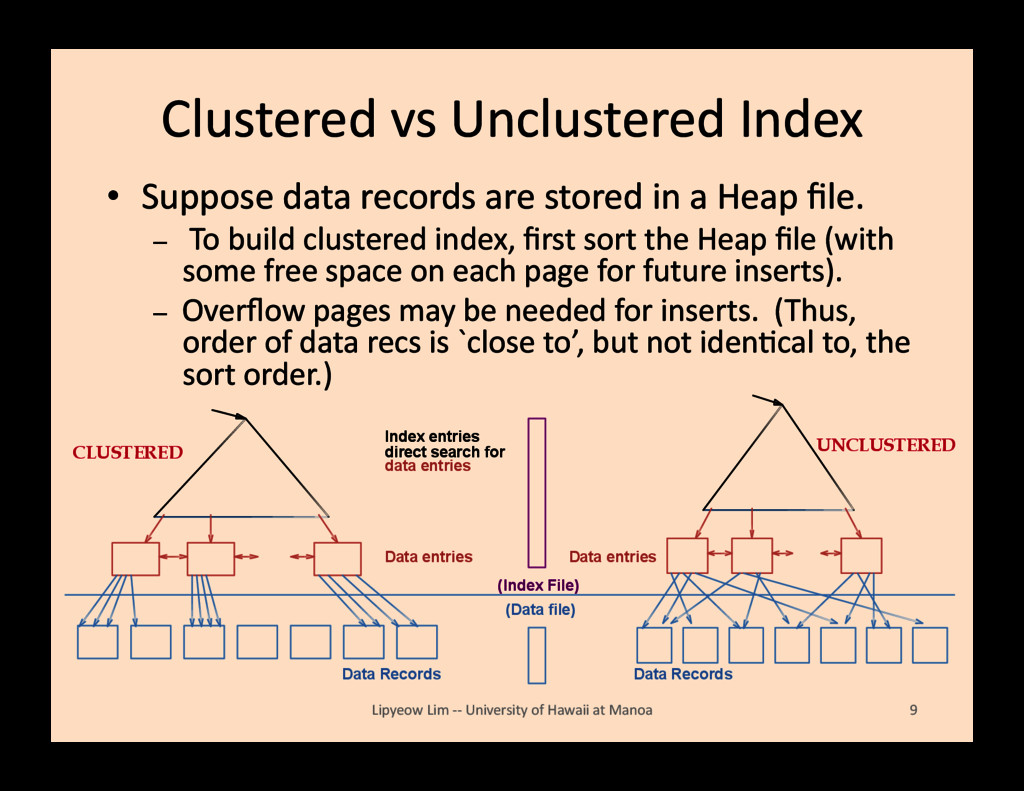
stored in a Heap file. – To build clustered index, first sort the Heap file (with some free space on each page for future inserts). – Overflow pages may be needed for inserts. (Thus, order of data recs is `close to’, but not idenBcal to, the sort order.) Lipyeow Lim -‐-‐ University of Hawaii at Manoa 9 Index entries Data entries direct search for (Index File) (Data file) Data Records data entries Data entries Data Records CLUSTERED UNCLUSTERED
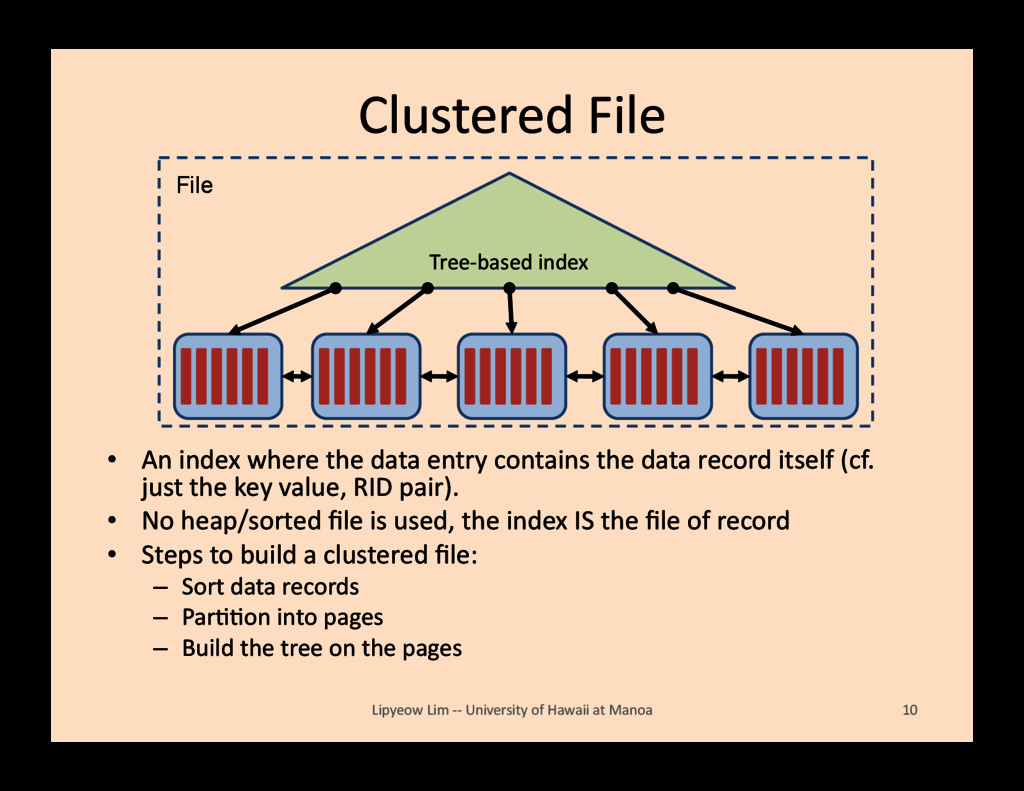
contains the data record itself (cf. just the key value, RID pair). • No heap/sorted file is used, the index IS the file of record • Steps to build a clustered file: – Sort data records – ParBBon into pages – Build the tree on the pages Lipyeow Lim -‐-‐ University of Hawaii at Manoa 10 Tree-‐based index File
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}