第38回 ISOC-JP Workshop での登壇資料です。
https://isoc.jp/activities/38th_isocjp_workshop/
AI関連技術の急速な発展に伴い、分散深層学習や推論処理といった要求の厳しいワークロードを支えるため、ハードウェアやソフトウェア・フレームワークなどの要素技術は多様化しています。また、サービスごとに異なる要件が求められる可能性もあります。このような状況では、従来のベストプラクティスとは異なるアプローチが必要となり、基盤システムのアーキテクチャ全体にわたる変革が求められています。
このワークショップでは、実際のサービス構築・実装を通じて見えてきた課題や、課題解決のために提案されている最新の技術動向について話します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
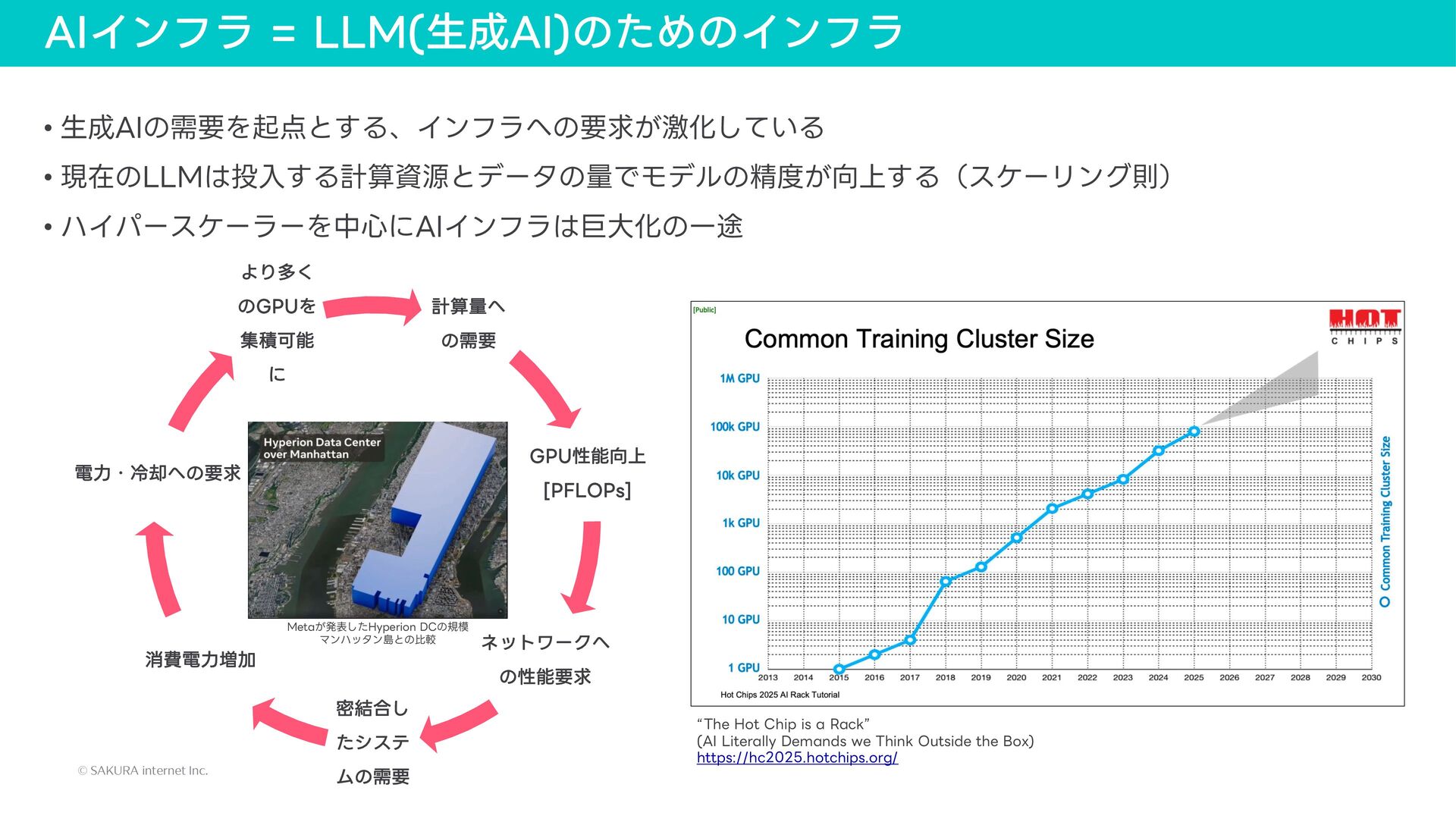{kind=link}
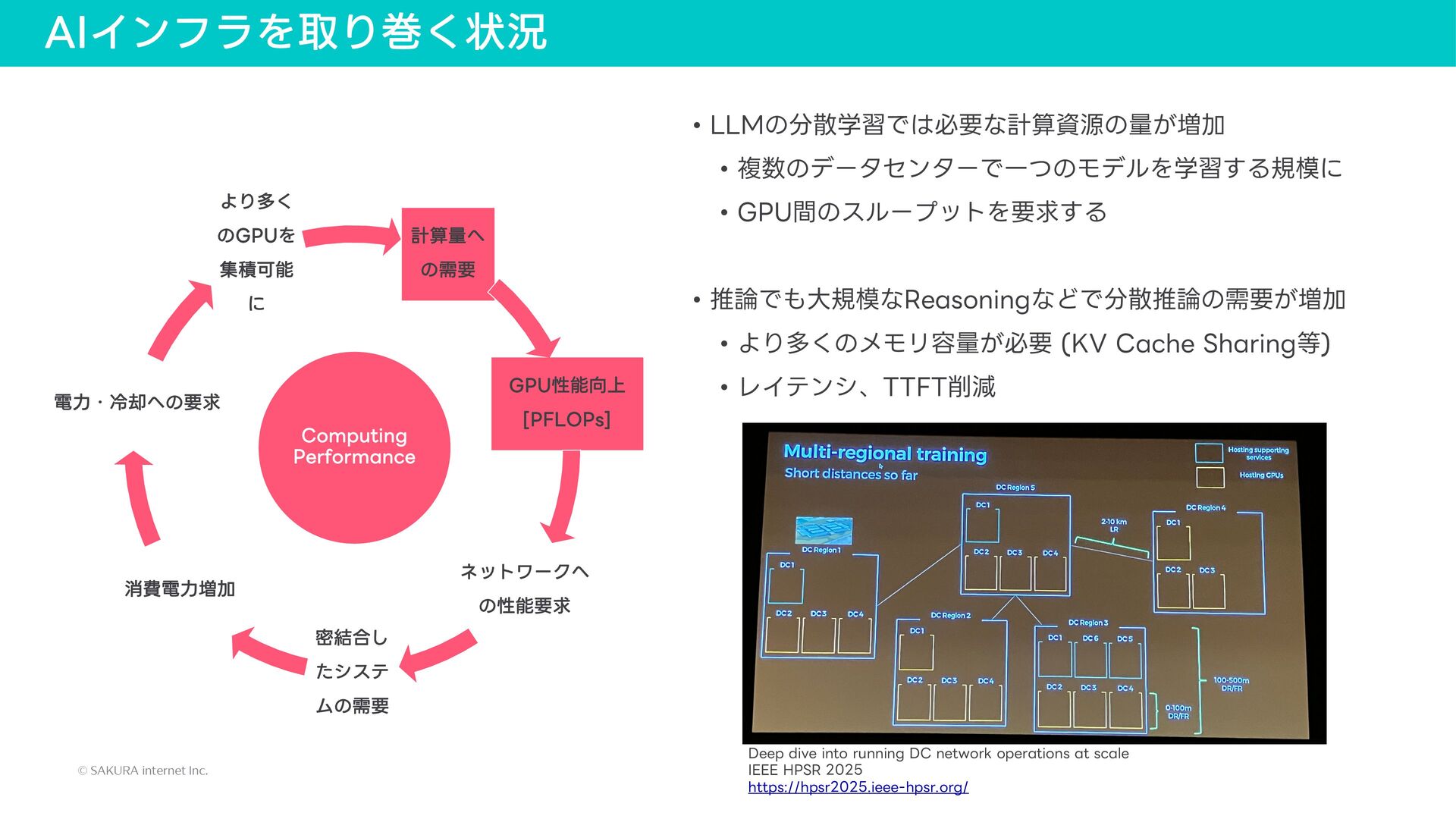{kind=link}
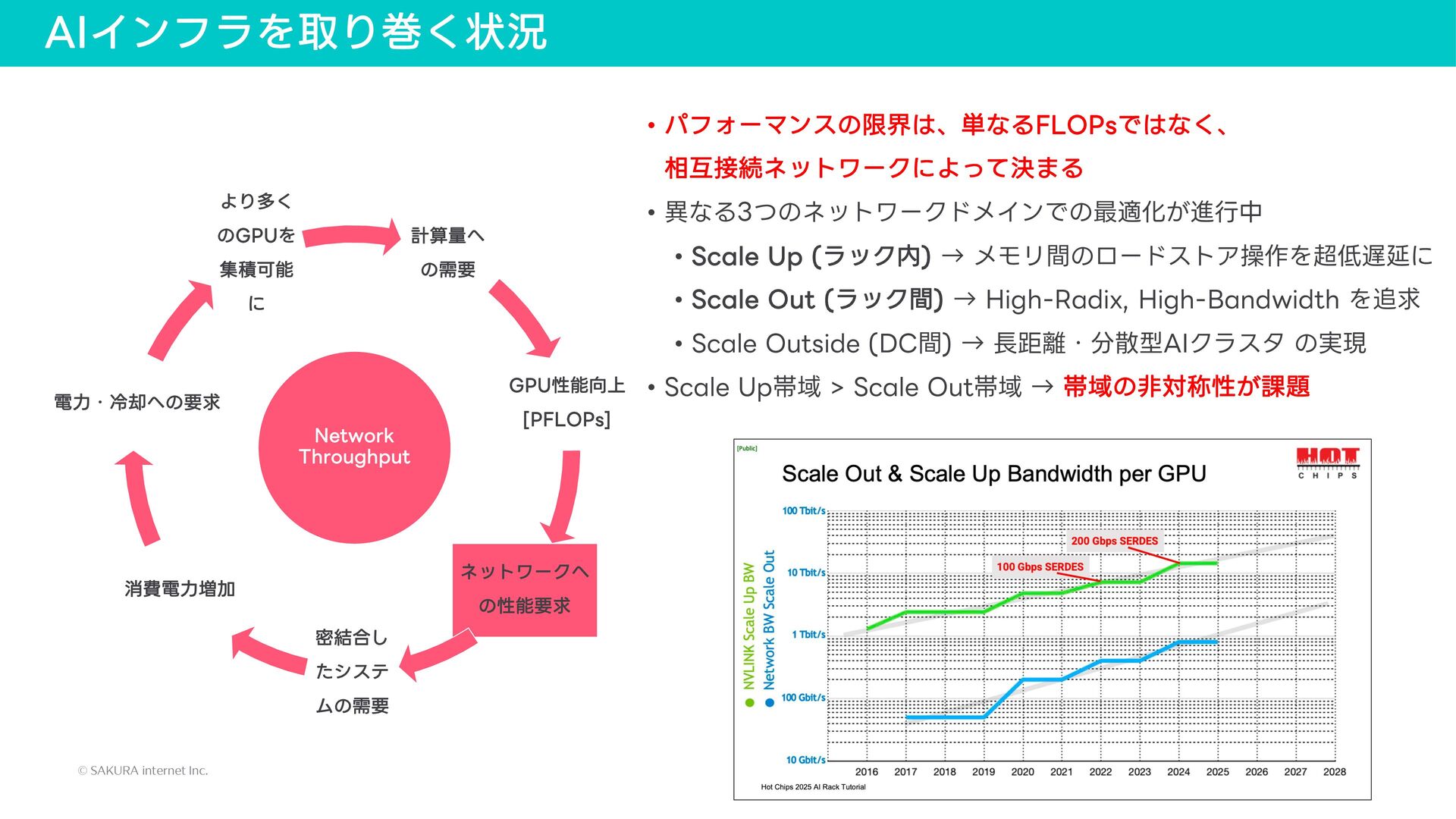{kind=link}
![© SAKURA internet Inc. AIインフラを取り巻く状況 計算量へ の需要 GPU性能向上 [PFLOPs] ネットワークへ](https://files.speakerdeck.com/presentations/e264c283266b4c31afd6c64026923390/slide_7.jpg){kind=link}
![© SAKURA internet Inc. AIインフラを取り巻く状況 計算量へ の需要 GPU性能向上 [PFLOPs] ネットワークへ](https://files.speakerdeck.com/presentations/e264c283266b4c31afd6c64026923390/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
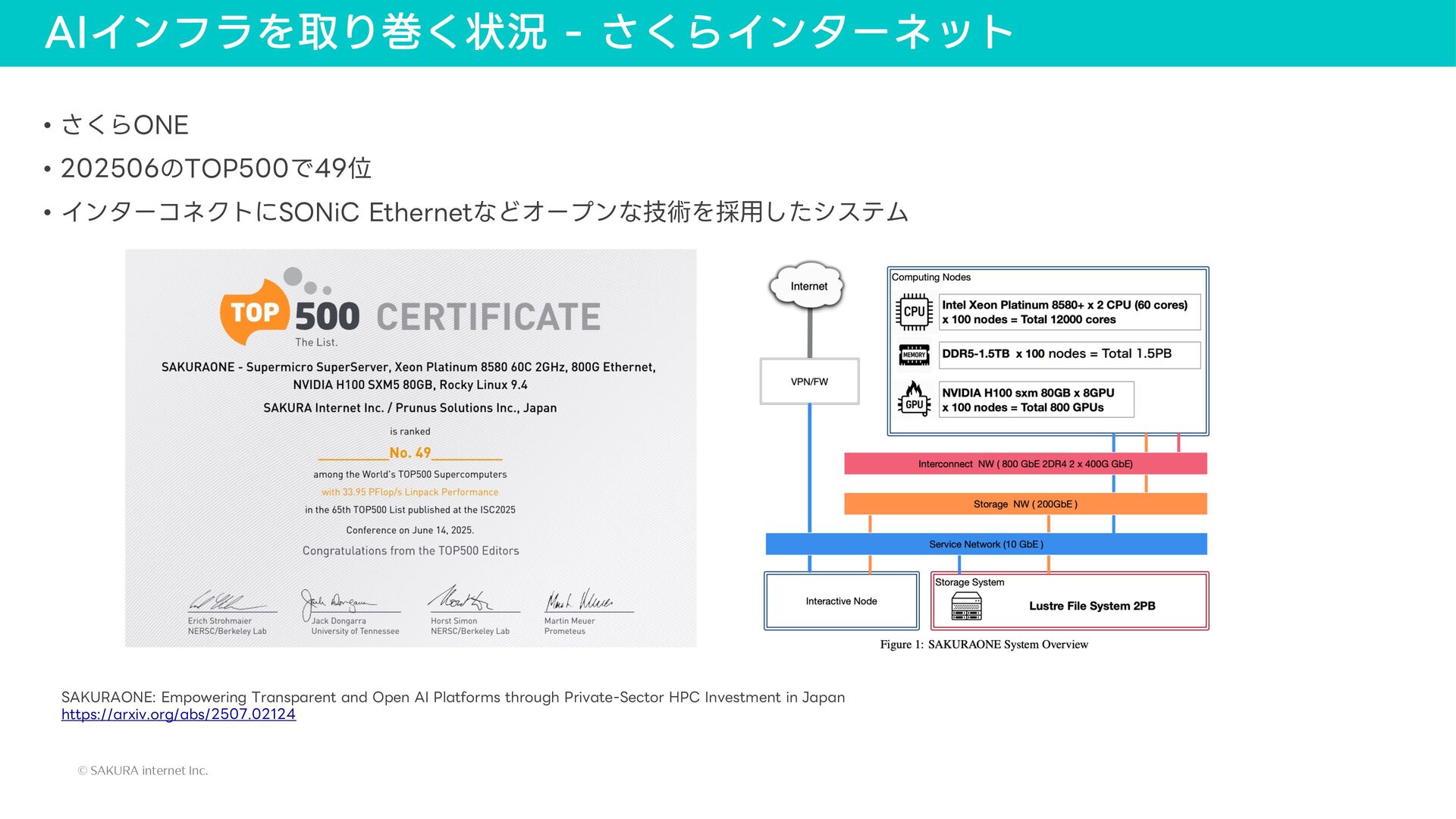{kind=link}
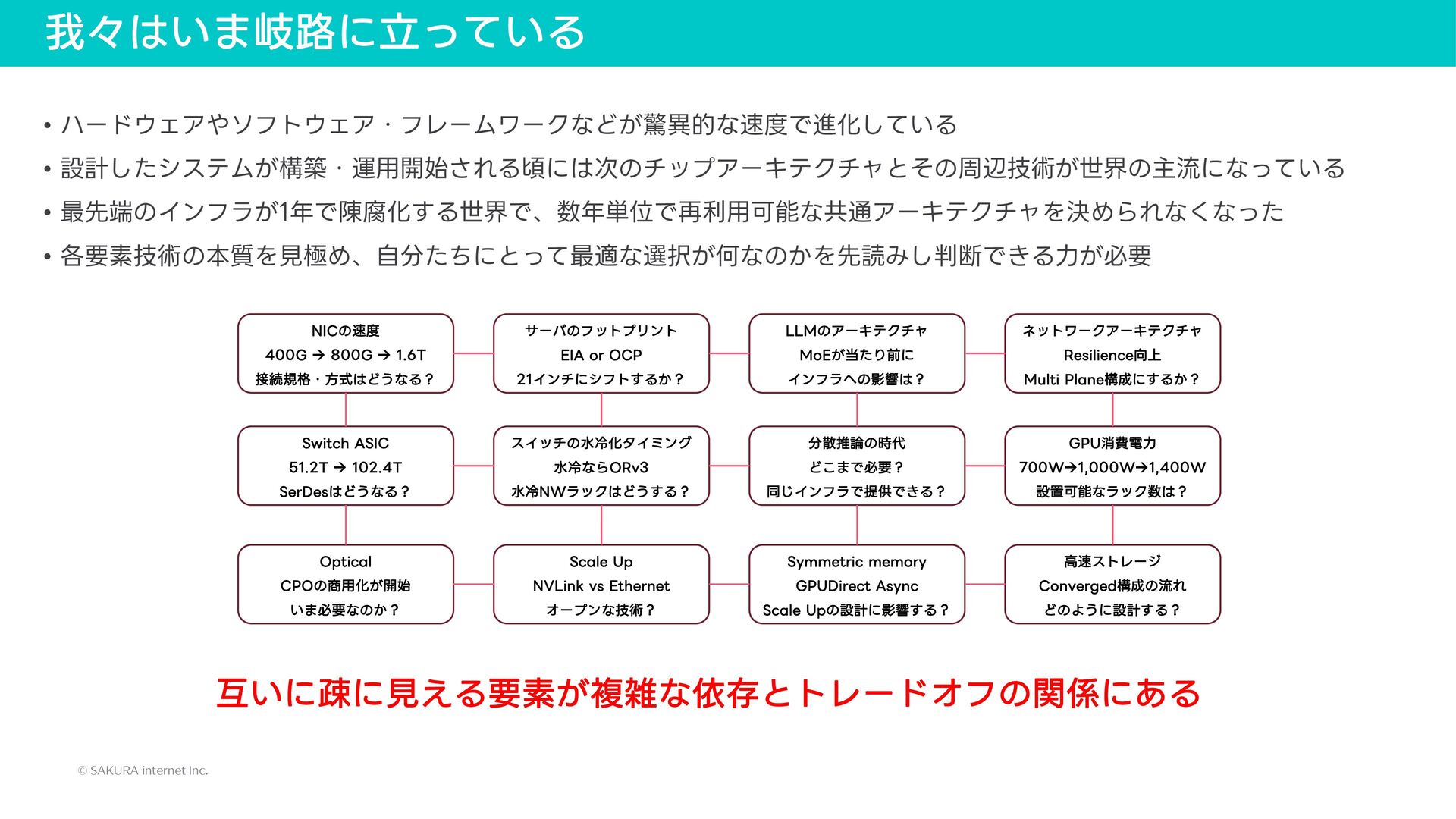{kind=link}
{kind=link}
{kind=link}
{kind=link}
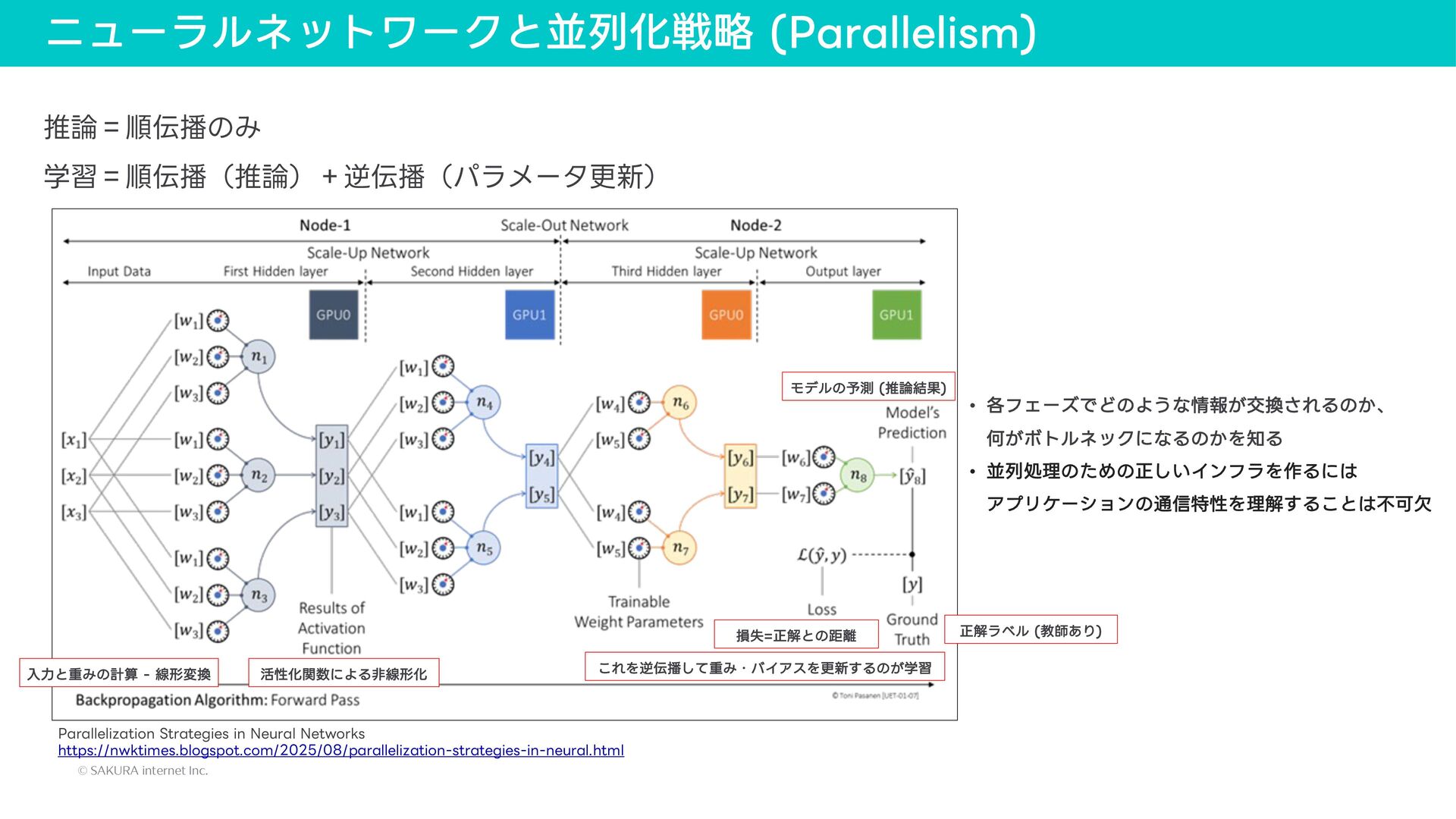{kind=link}
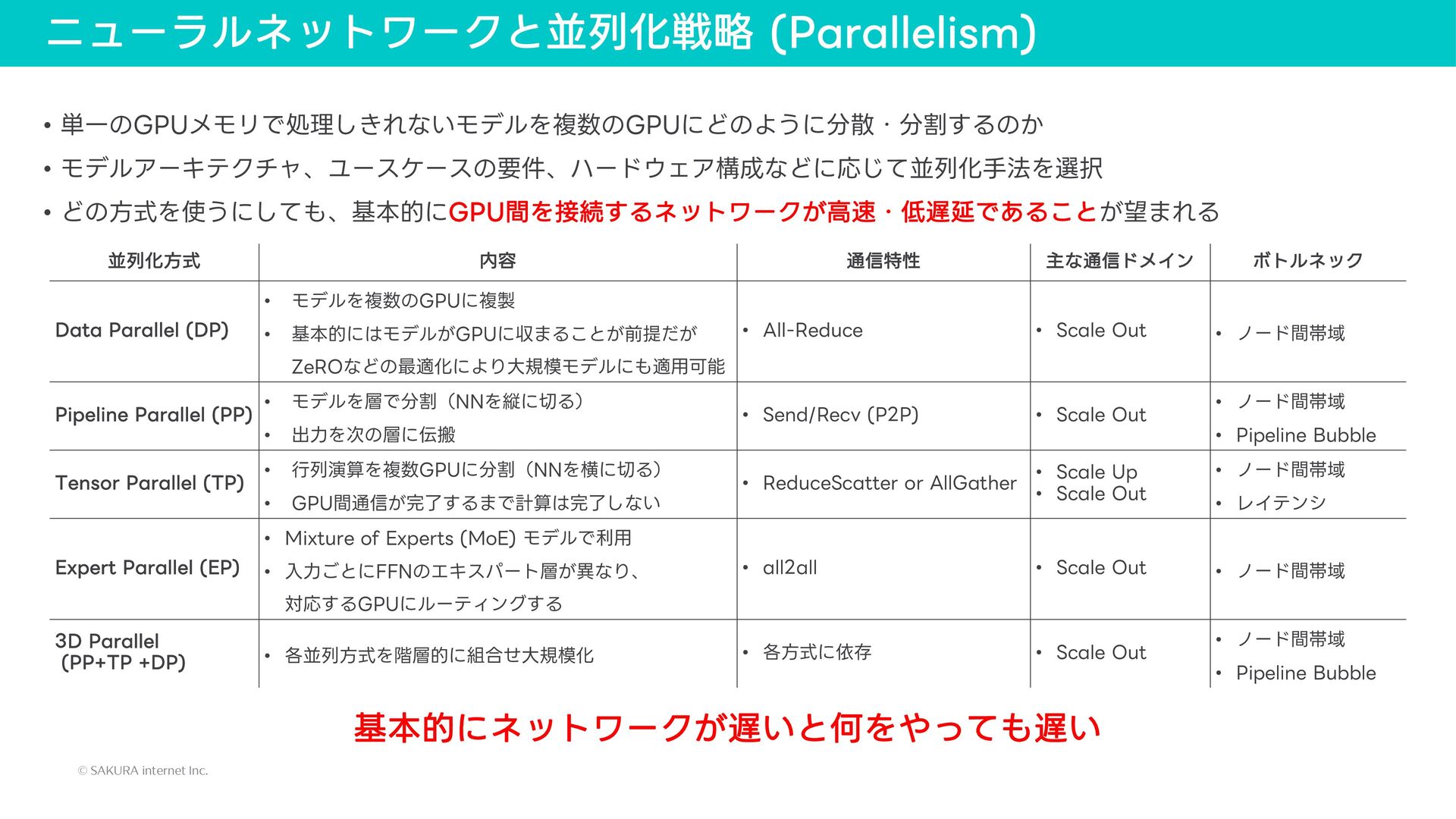{kind=link}
{kind=link}
{kind=link}
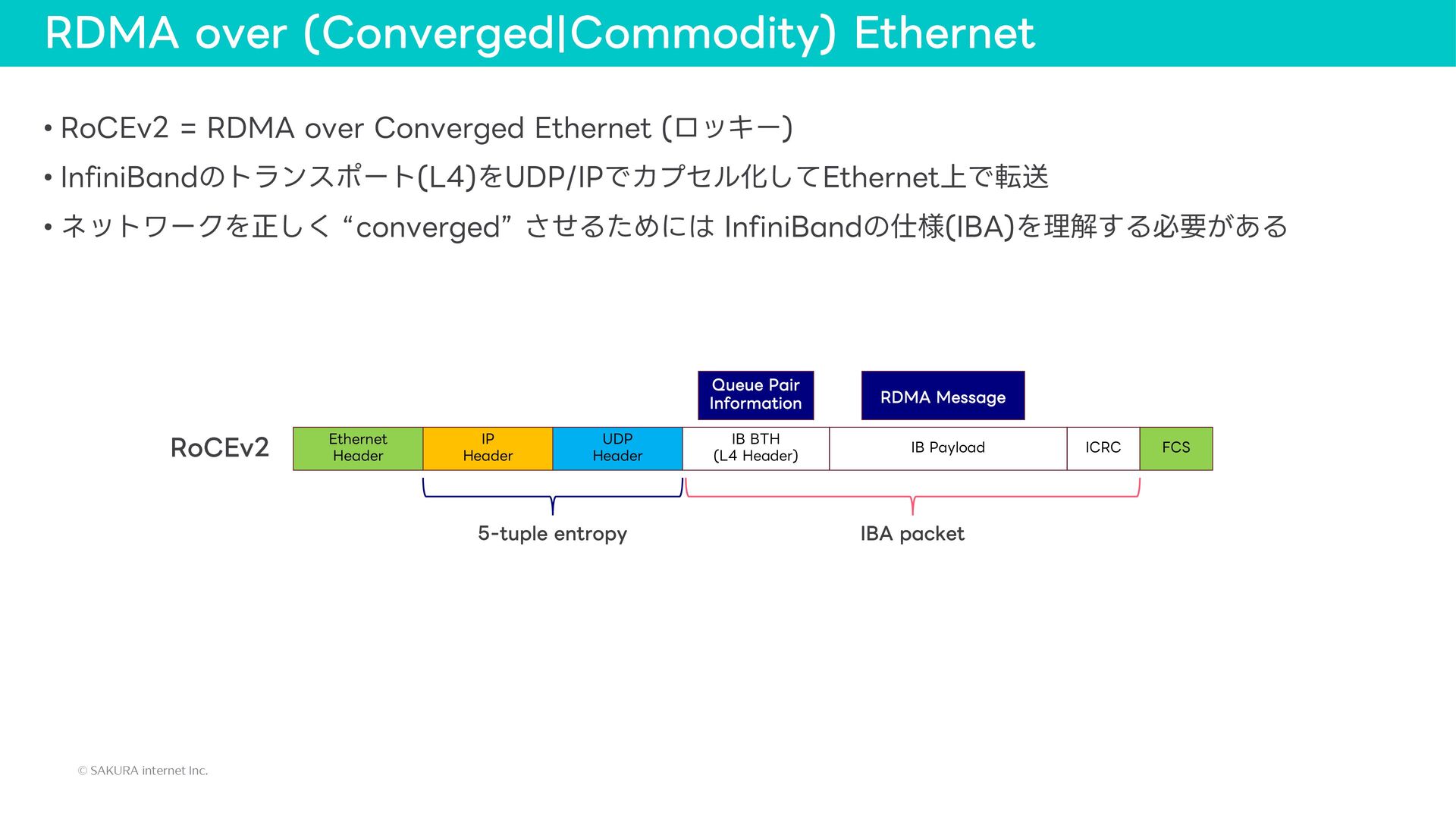{kind=link}
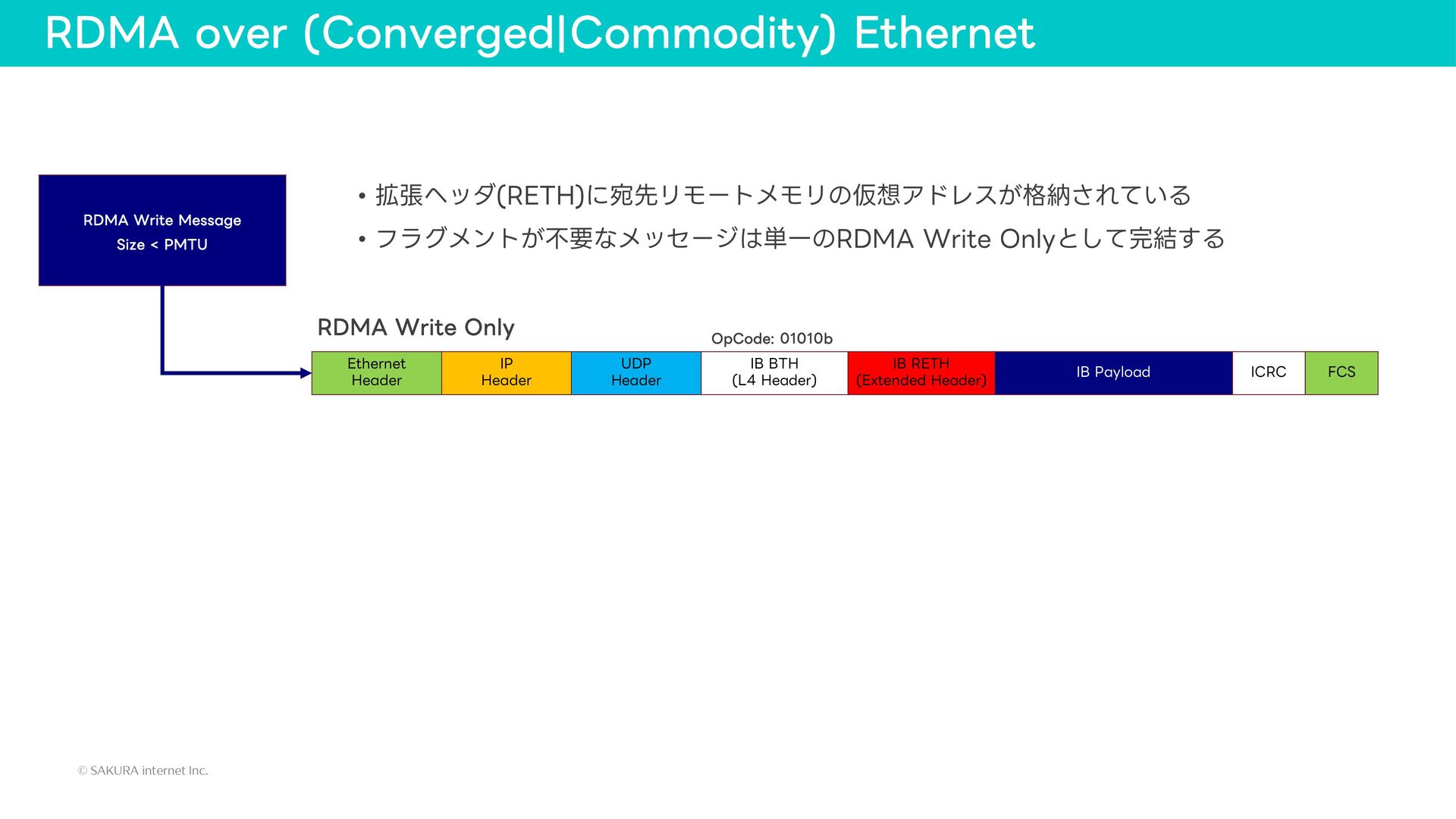{kind=link}
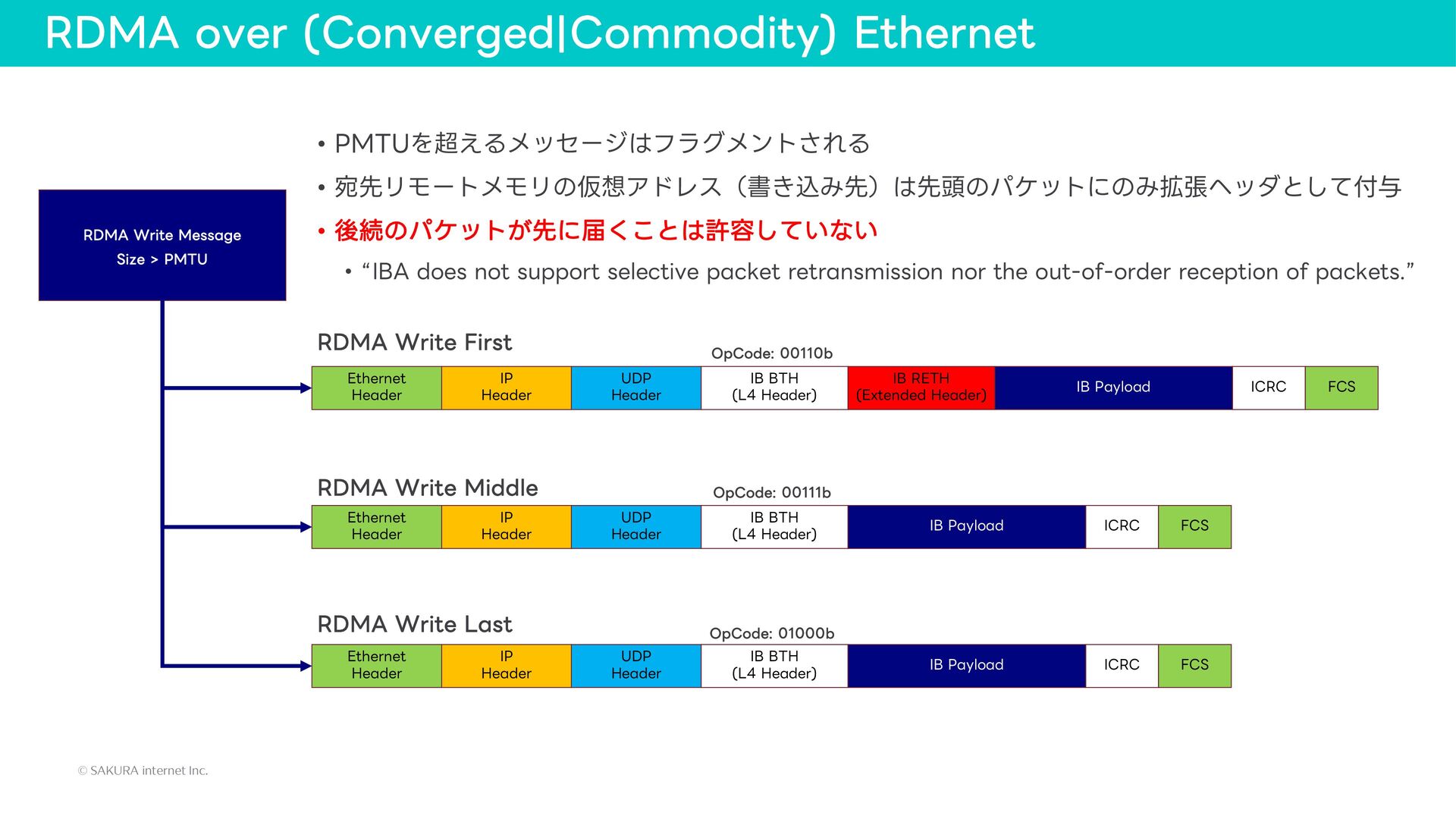{kind=link}
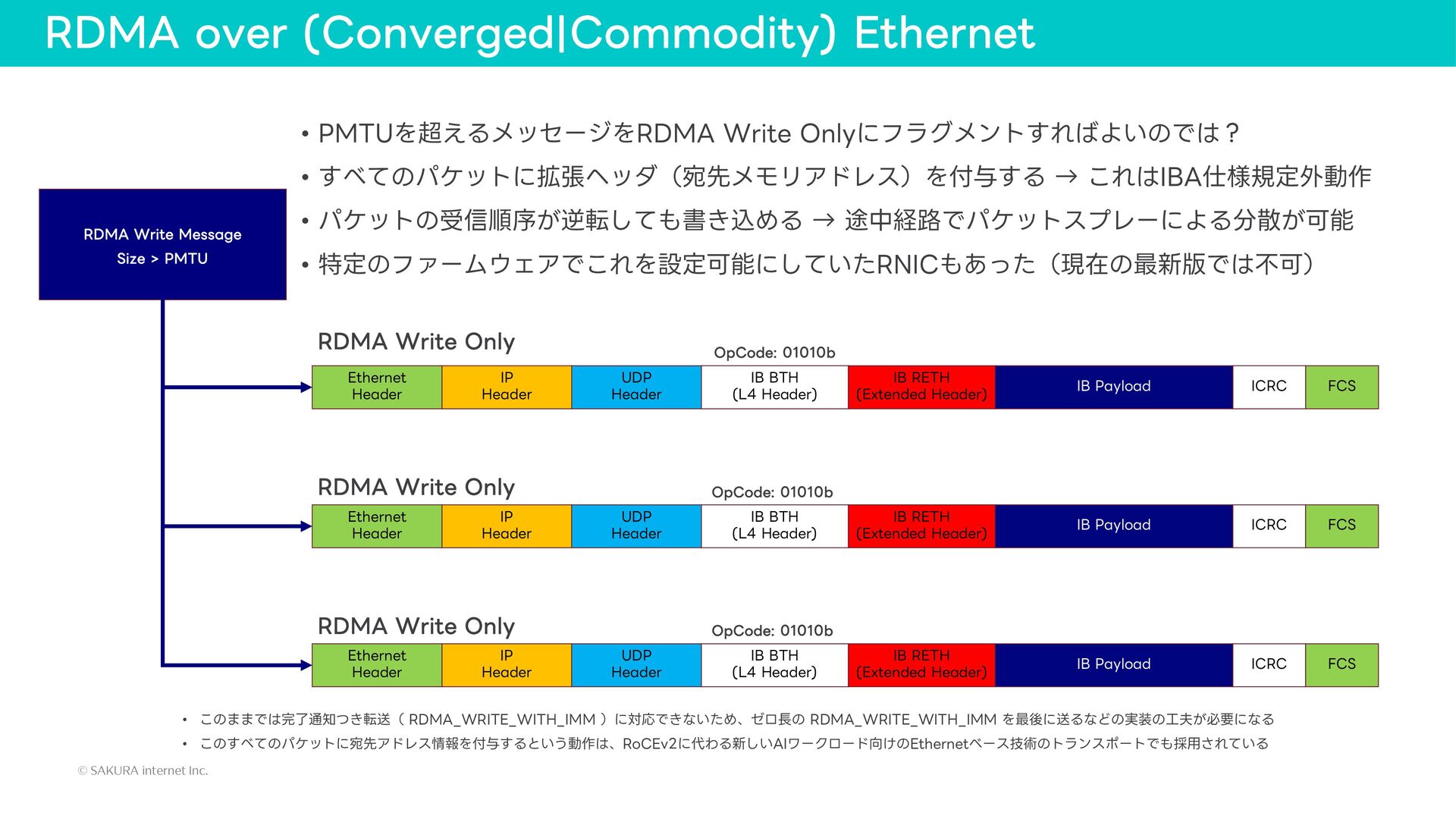{kind=link}
{kind=link}
{kind=link}
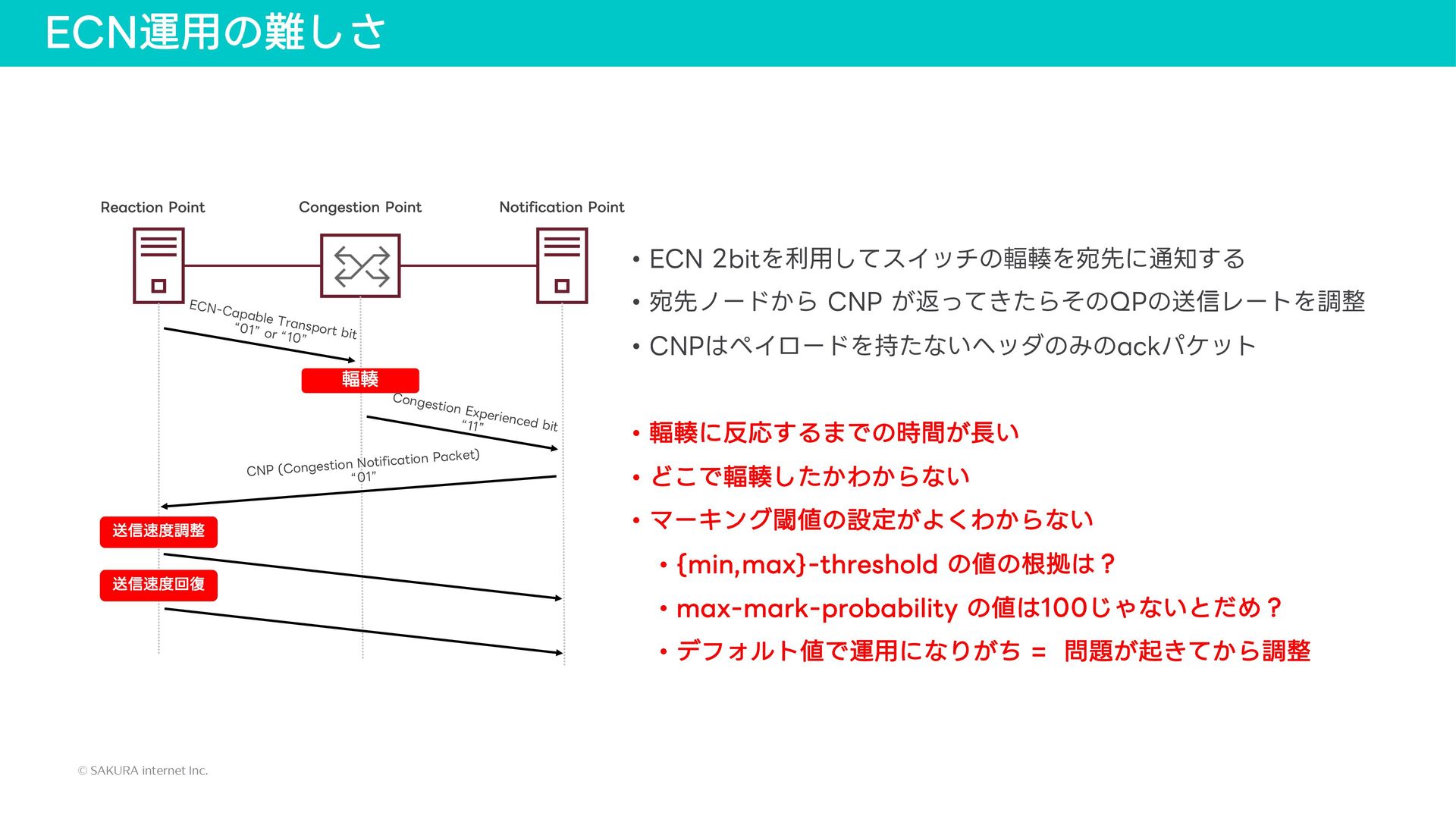{kind=link}
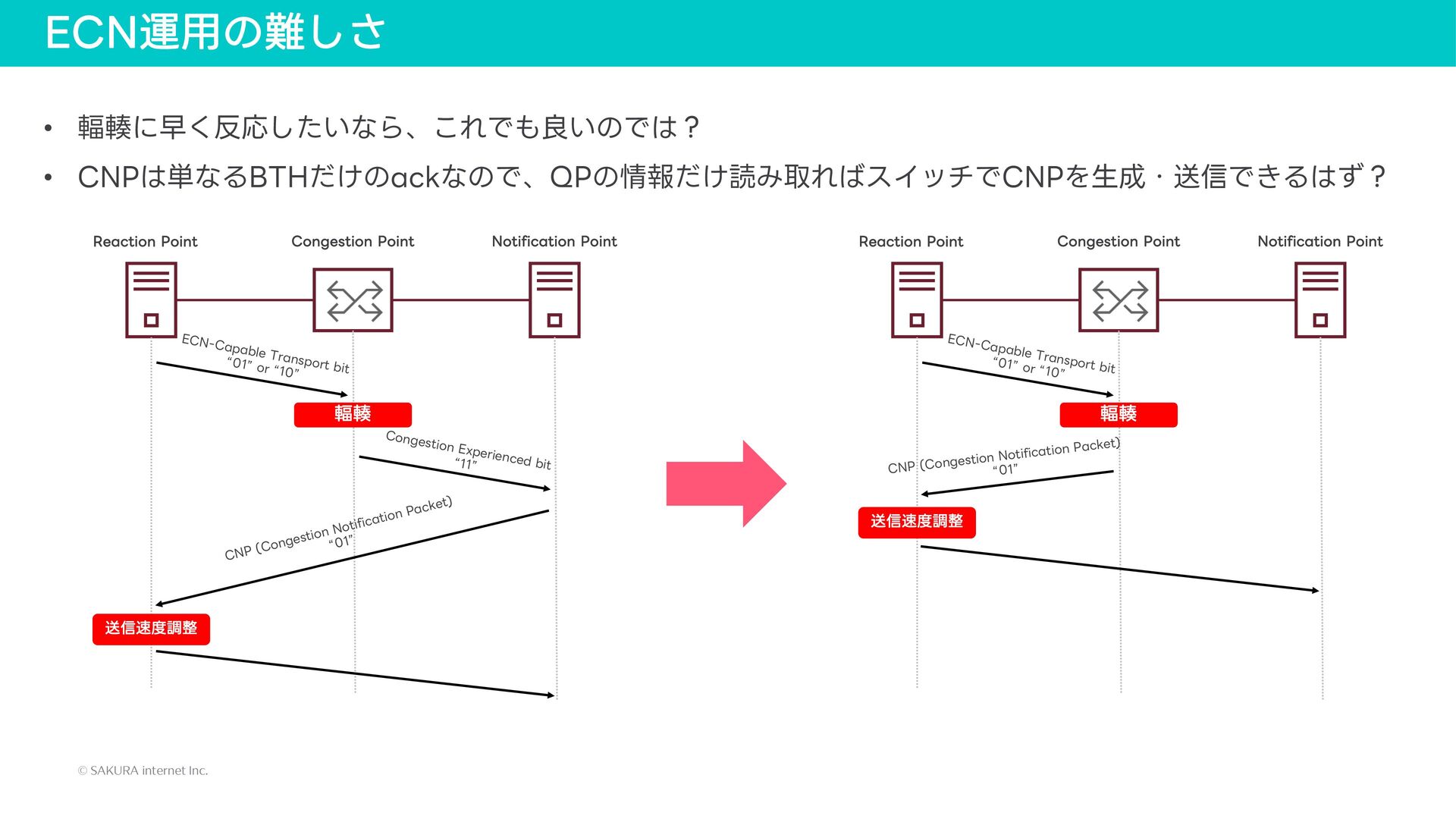{kind=link}
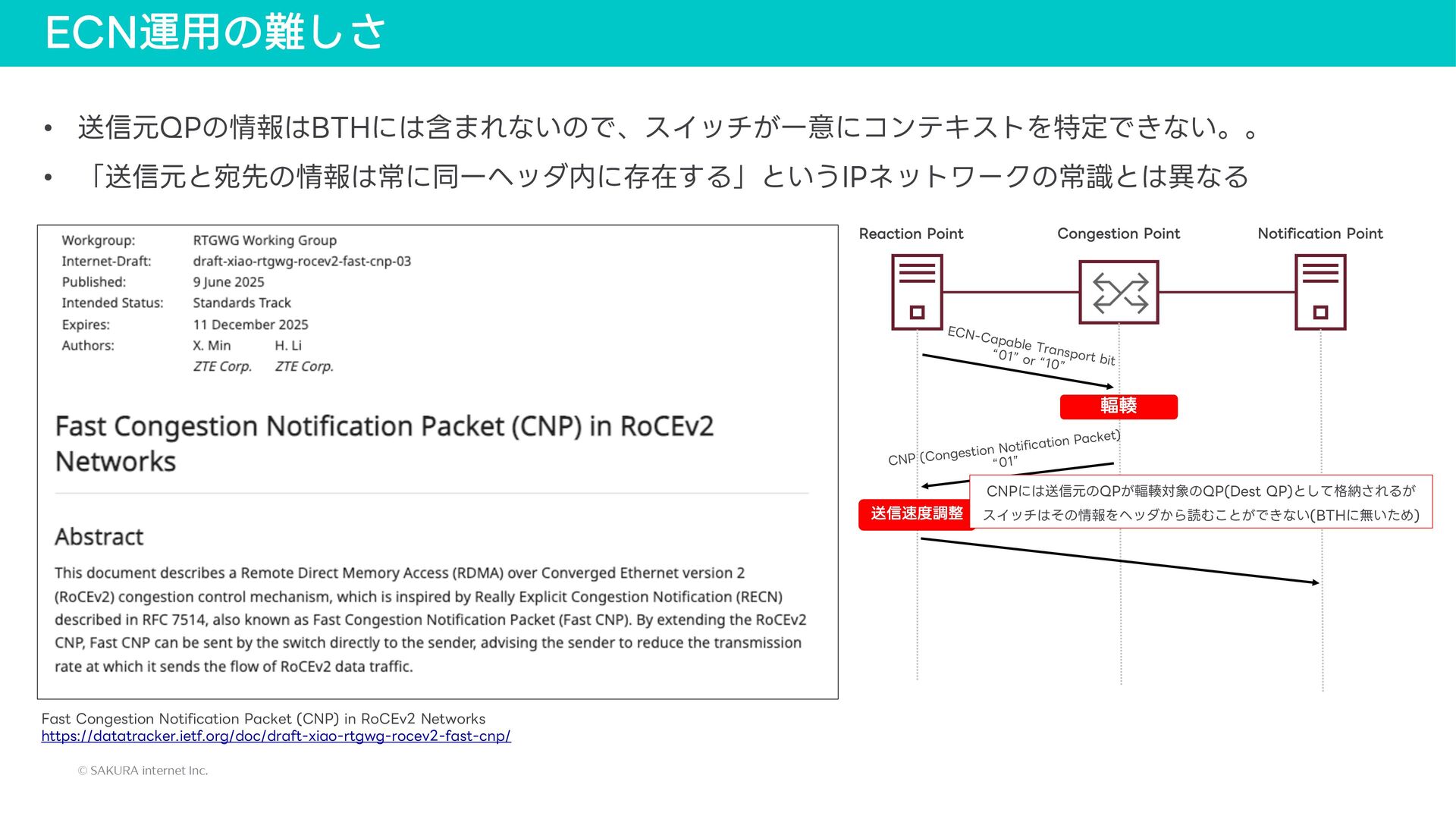{kind=link}
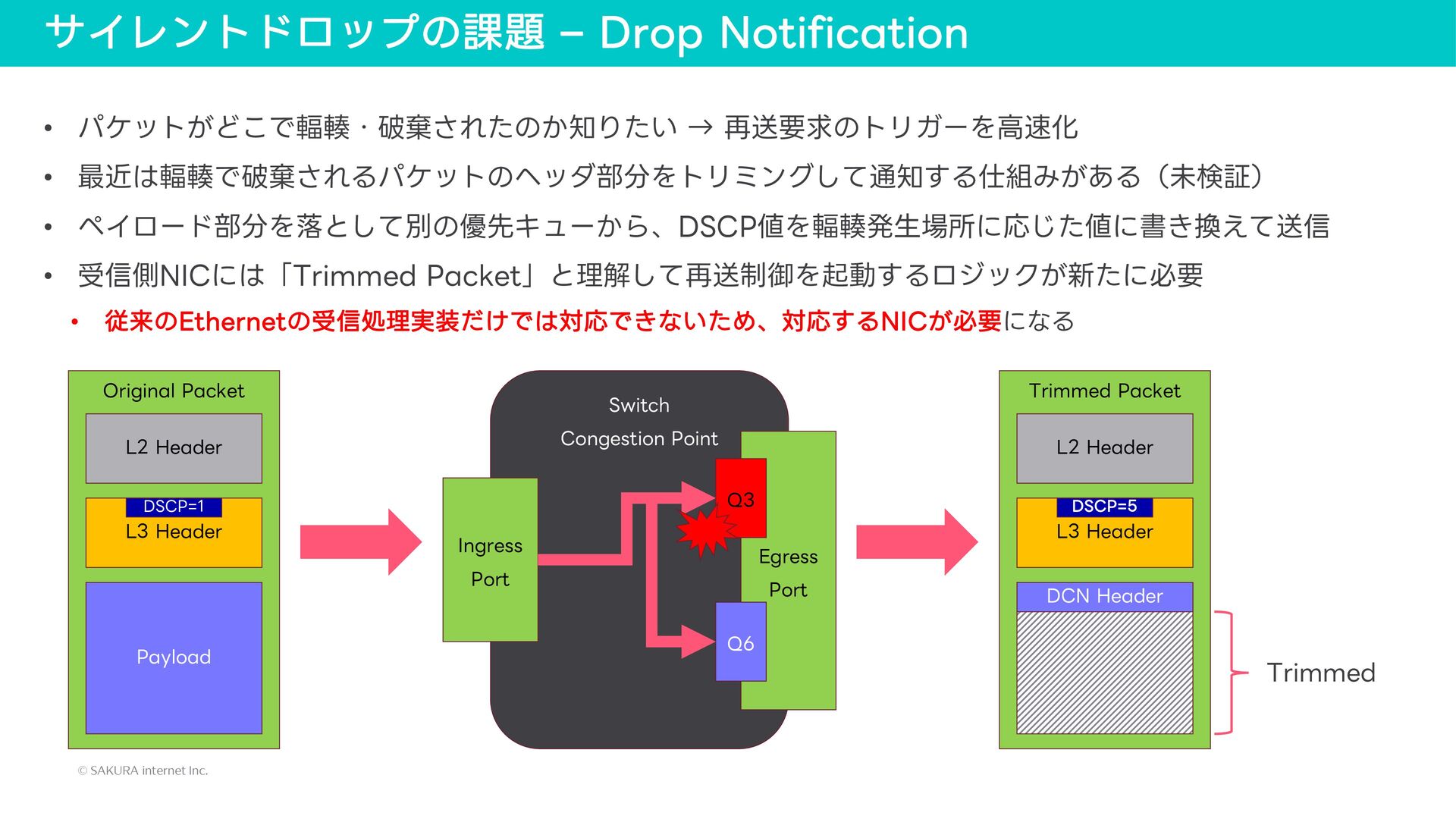{kind=link}
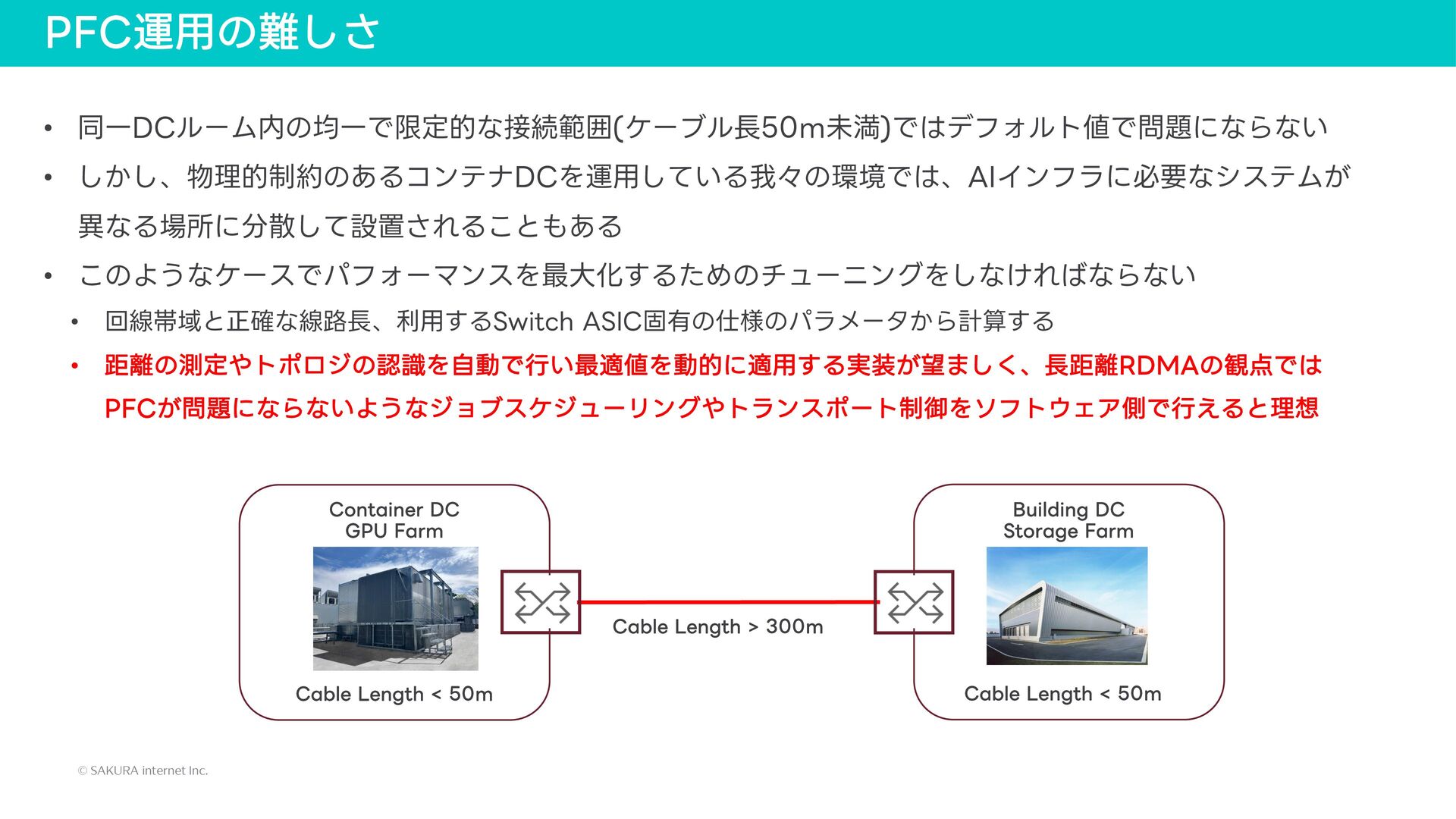{kind=link}
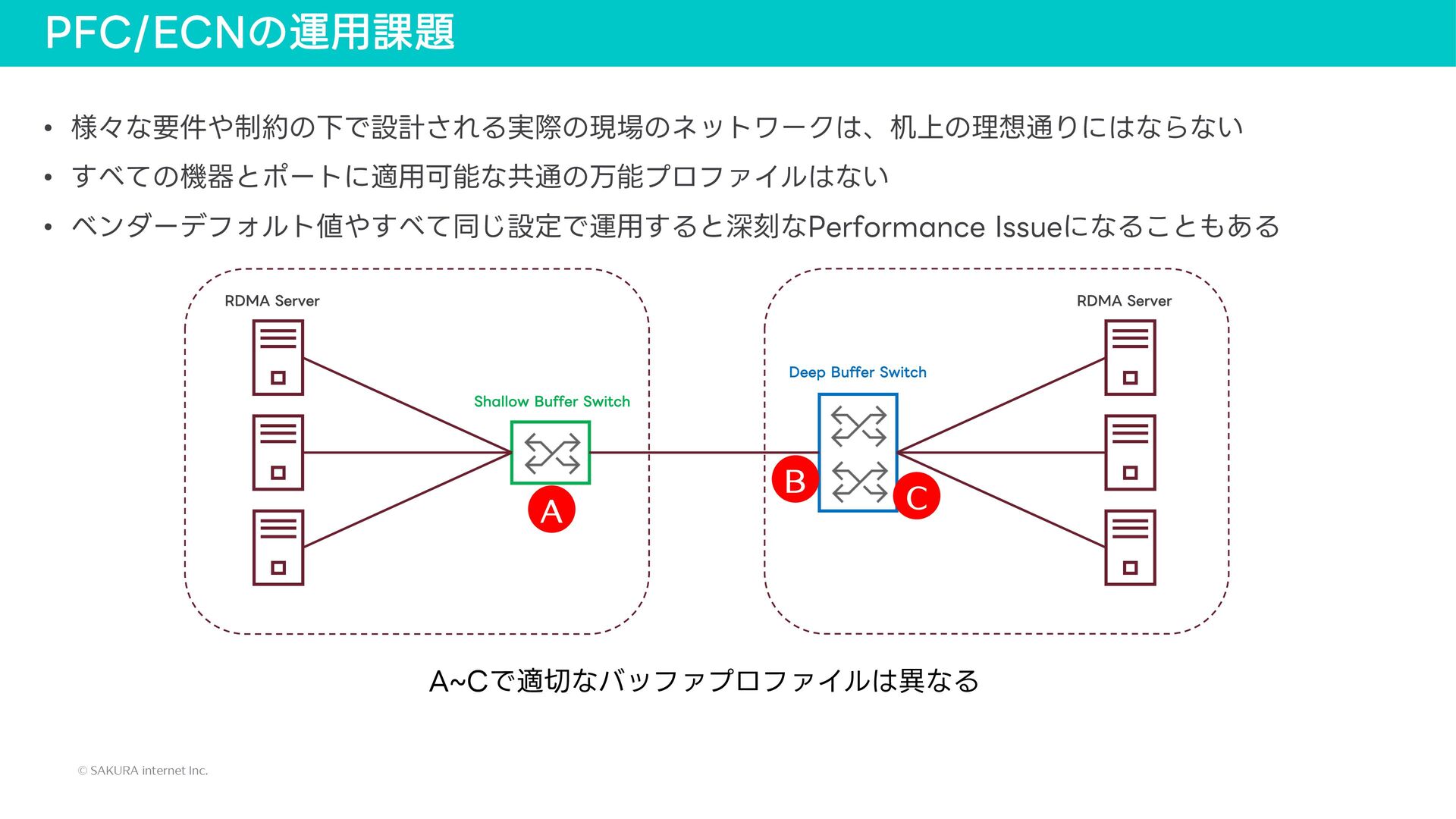{kind=link}
{kind=link}
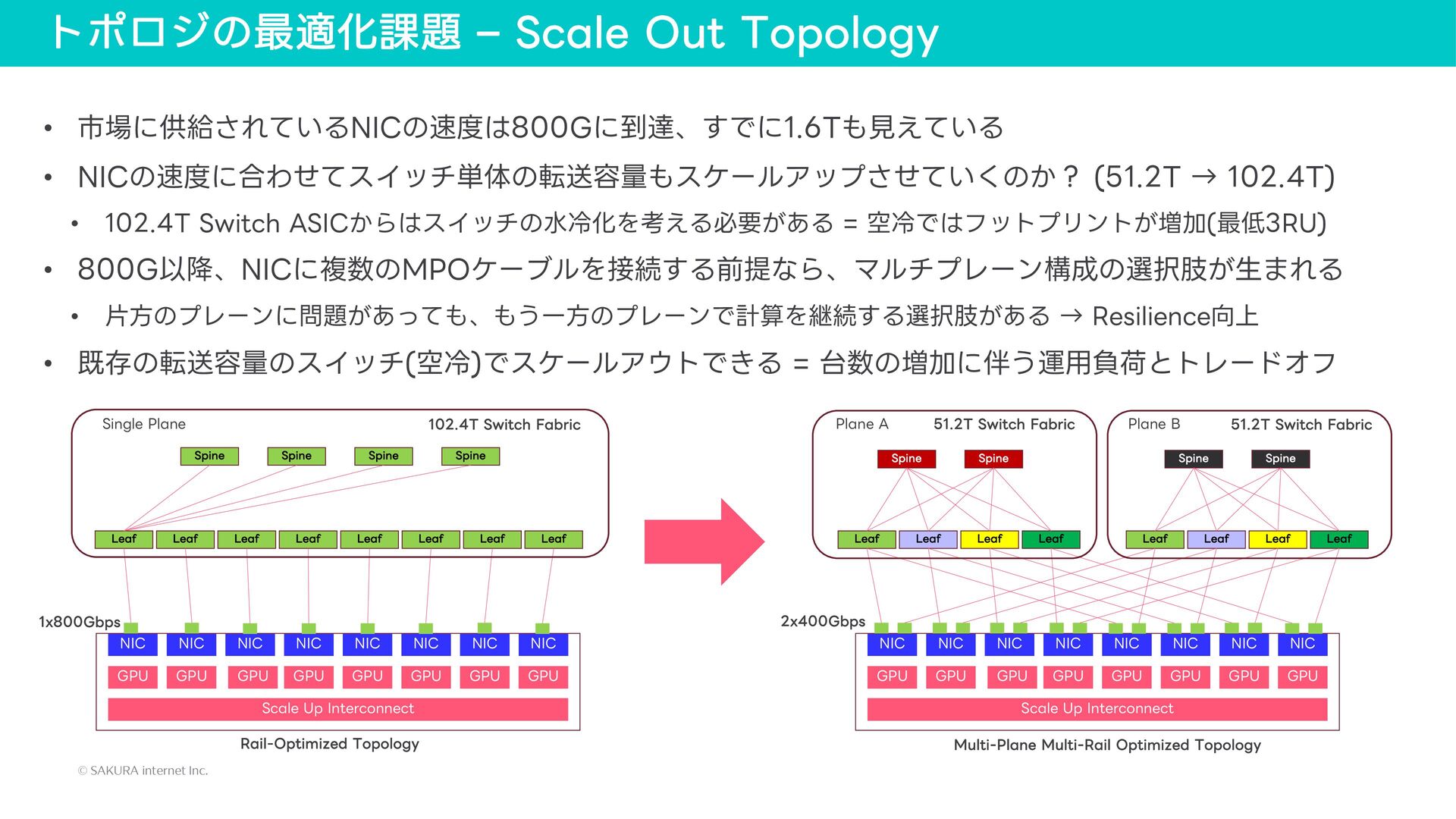{kind=link}
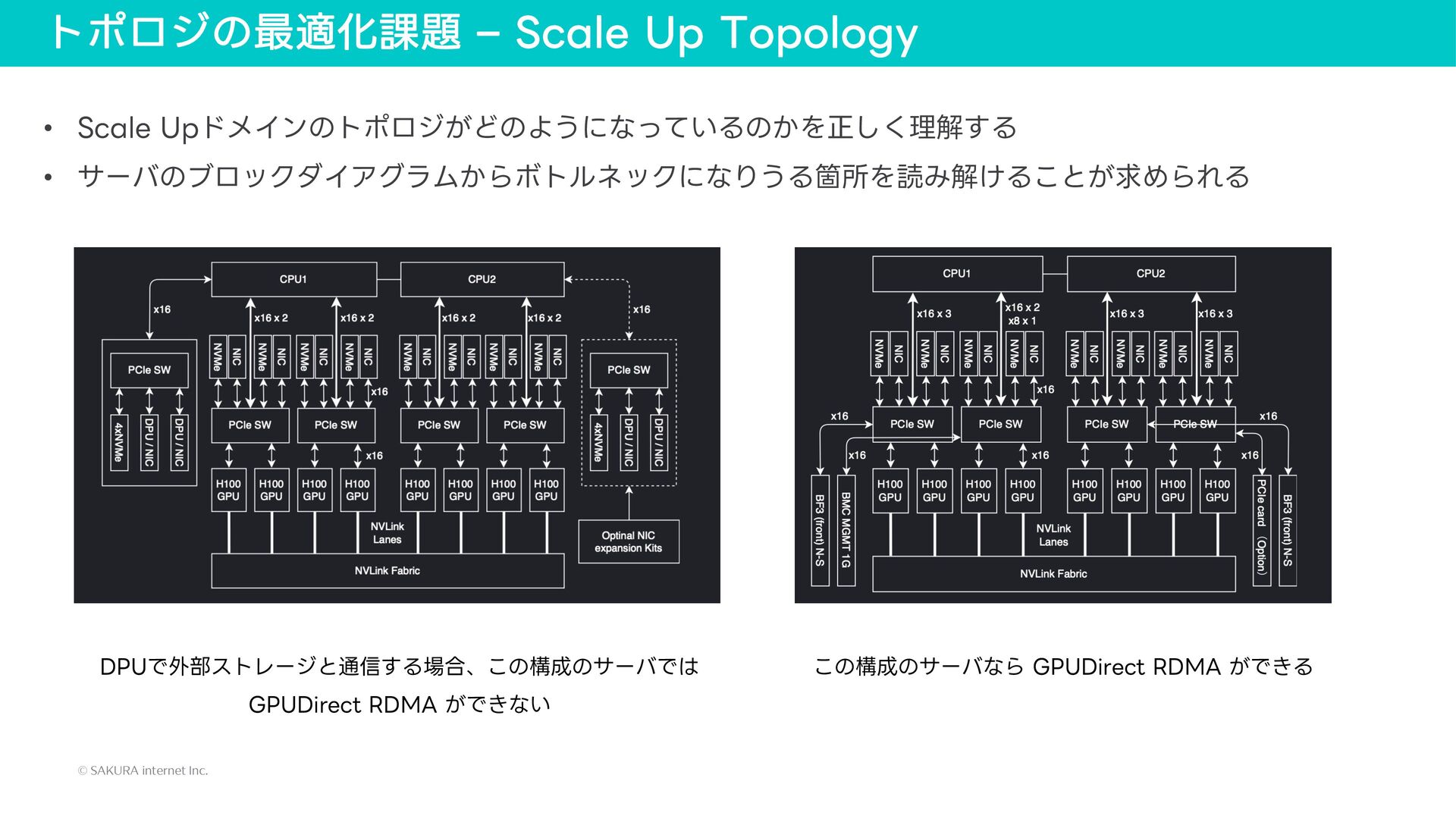{kind=link}
{kind=link}
{kind=link}
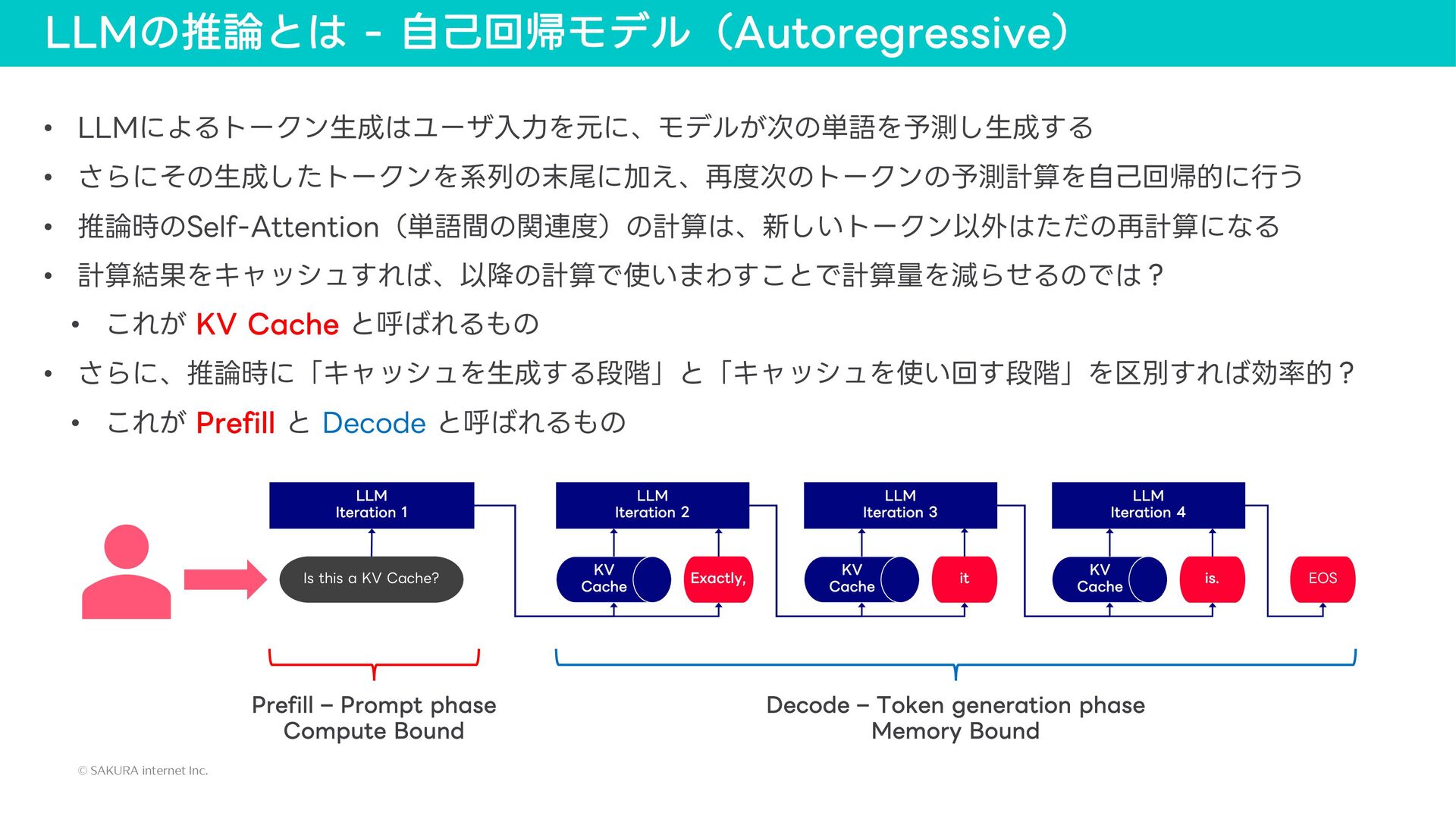{kind=link}
{kind=link}
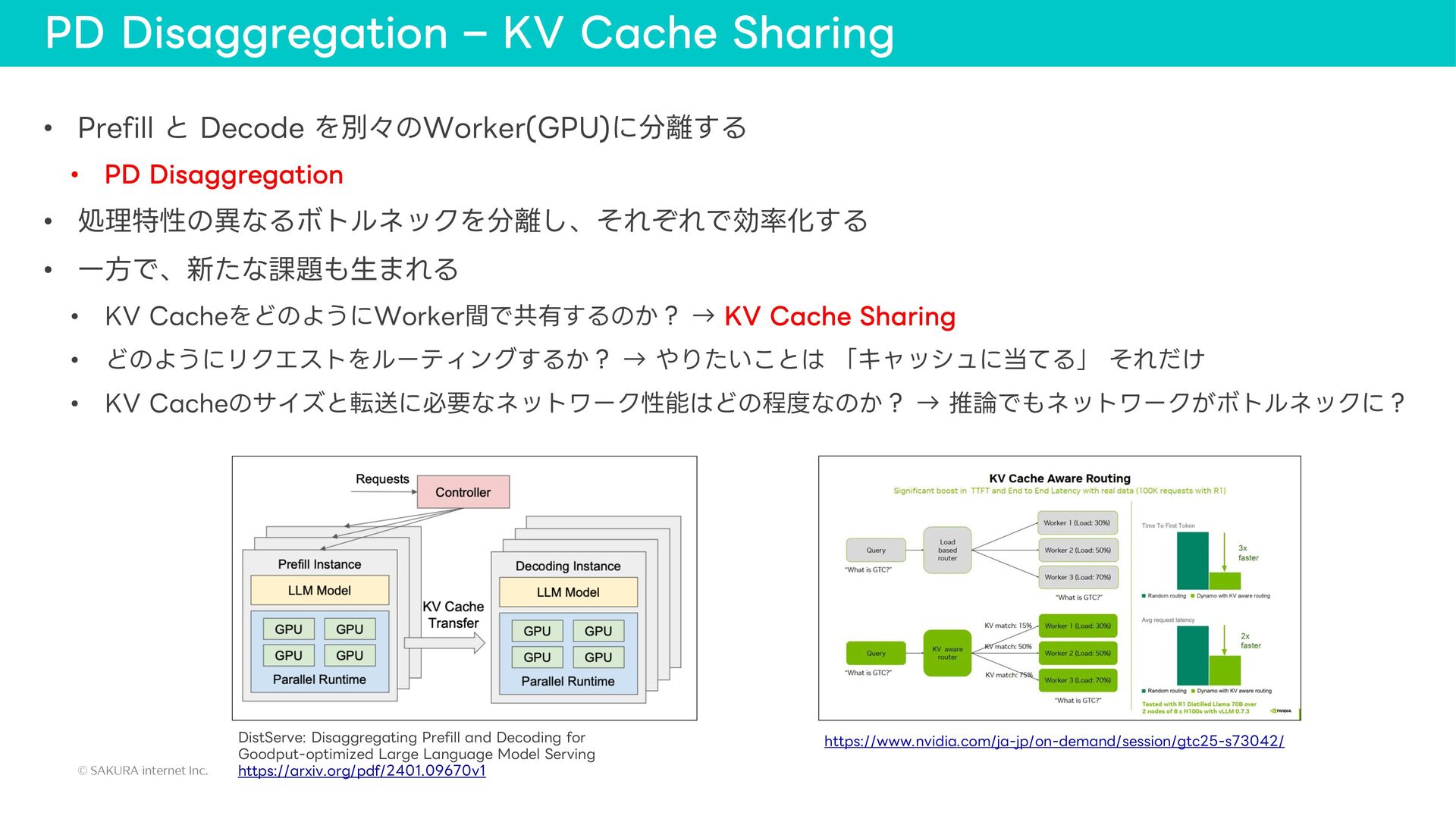{kind=link}
{kind=link}
{kind=link}
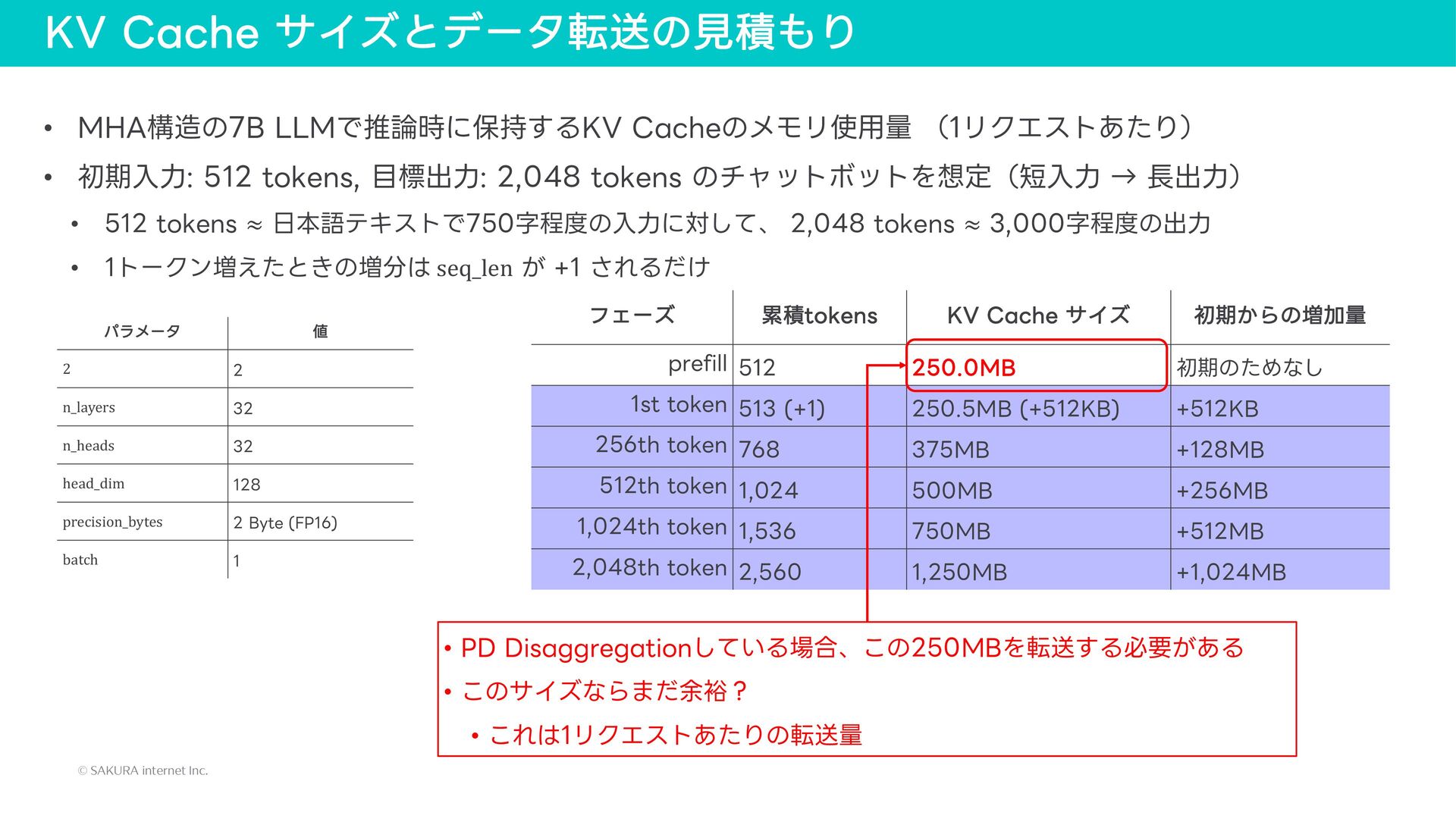{kind=link}
{kind=link}
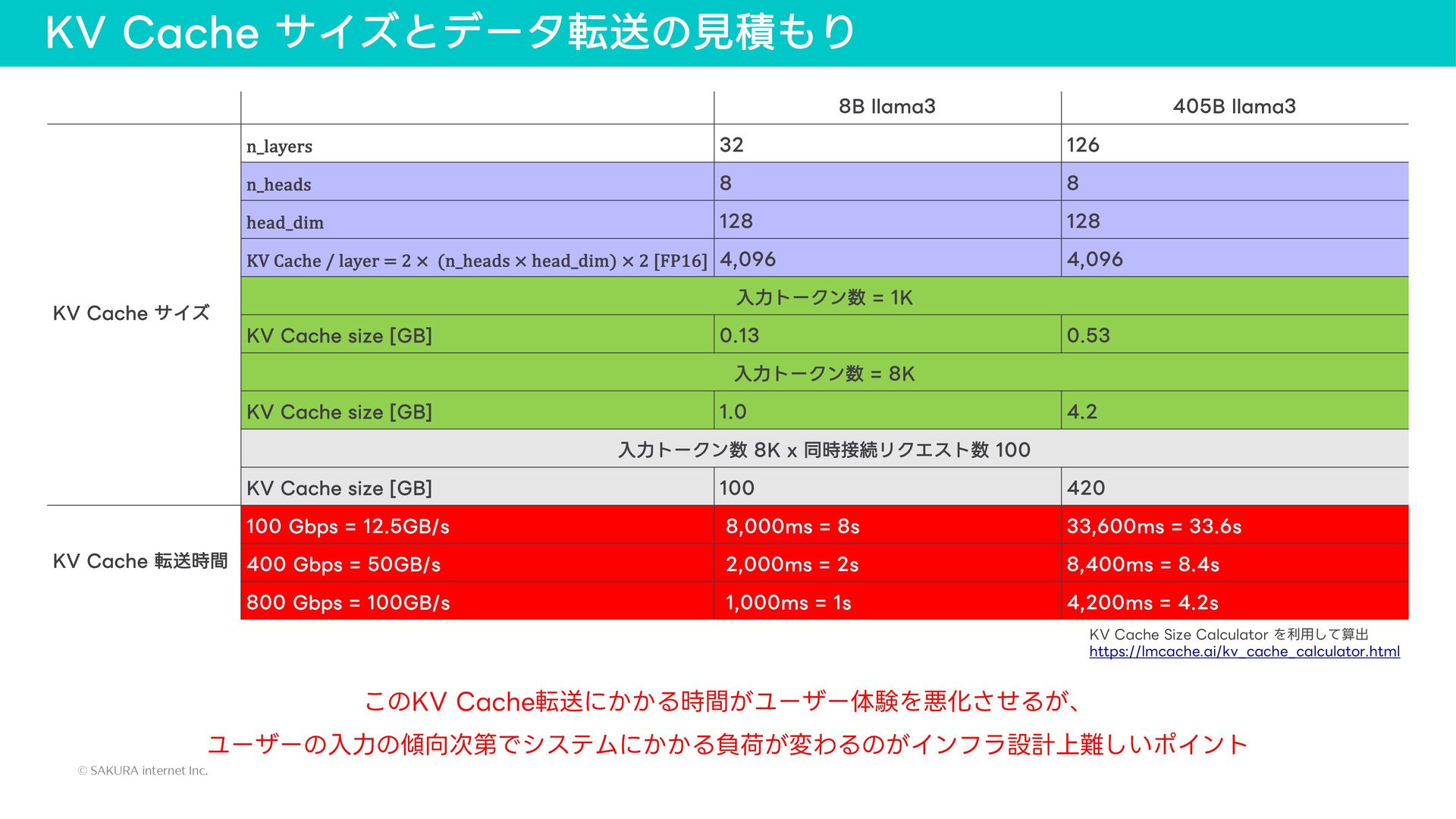{kind=link}
{kind=link}
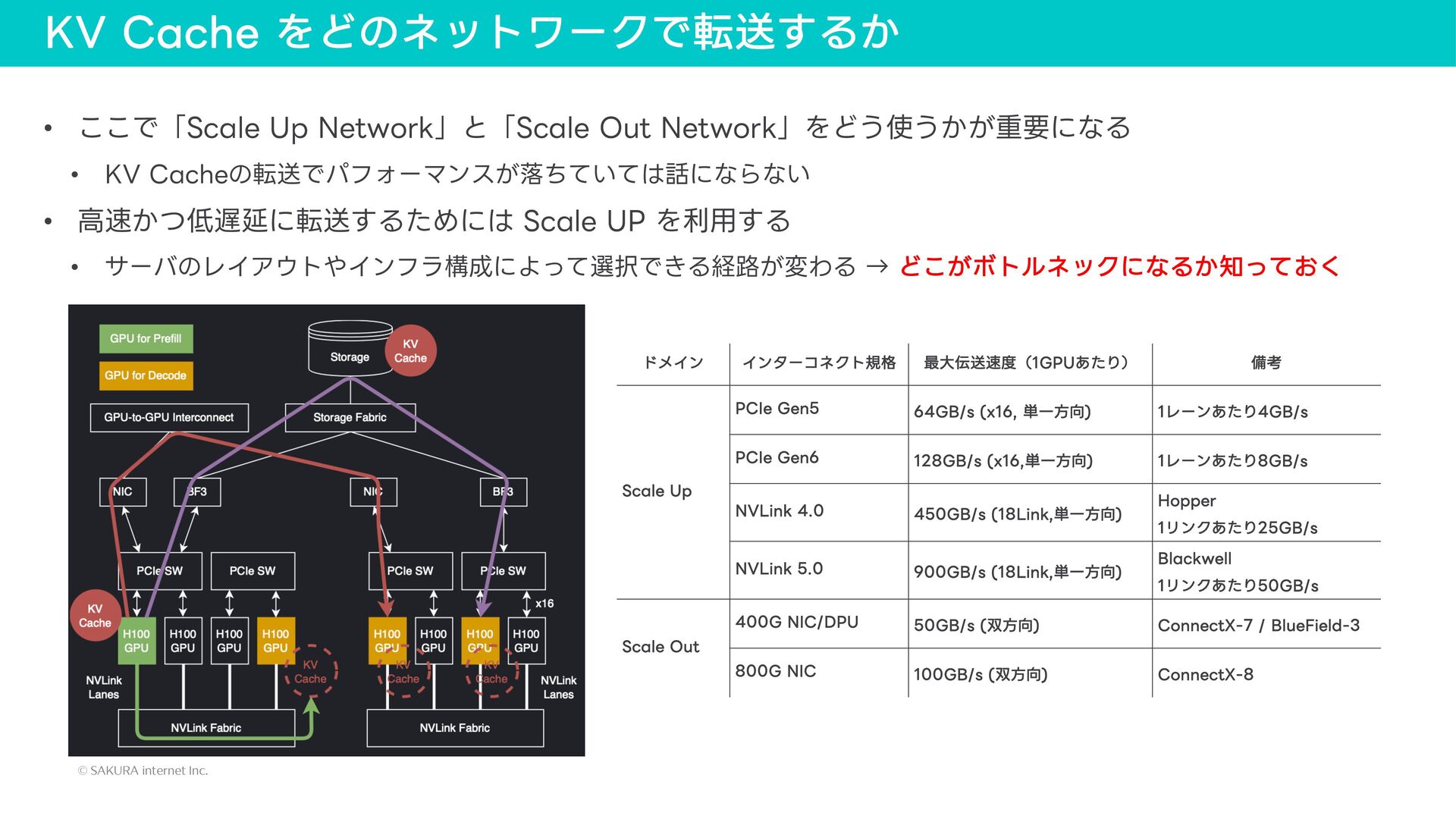{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}