This talk presents a high-level overview over our work on data parallel programming in Haskell. I presented it at the MSR Faculty Summit 2012. A video of my talk (preceded by a talk by Don Syme and followed by Antonio Cisternino) is at https://research.microsoft.com/apps/video/dl.aspx?id=169976
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Graphics [Haskell 2012a] Ray tracing](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_7.jpg){kind=link}
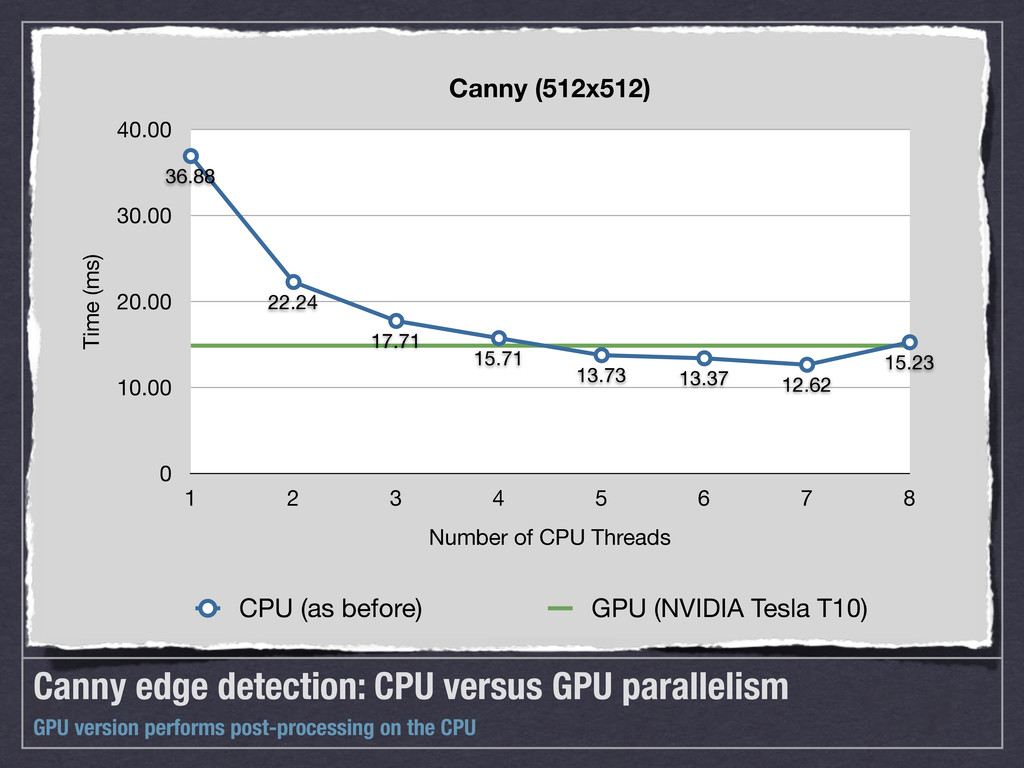
![Computer Vision [Haskell 2011] Edge detection](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
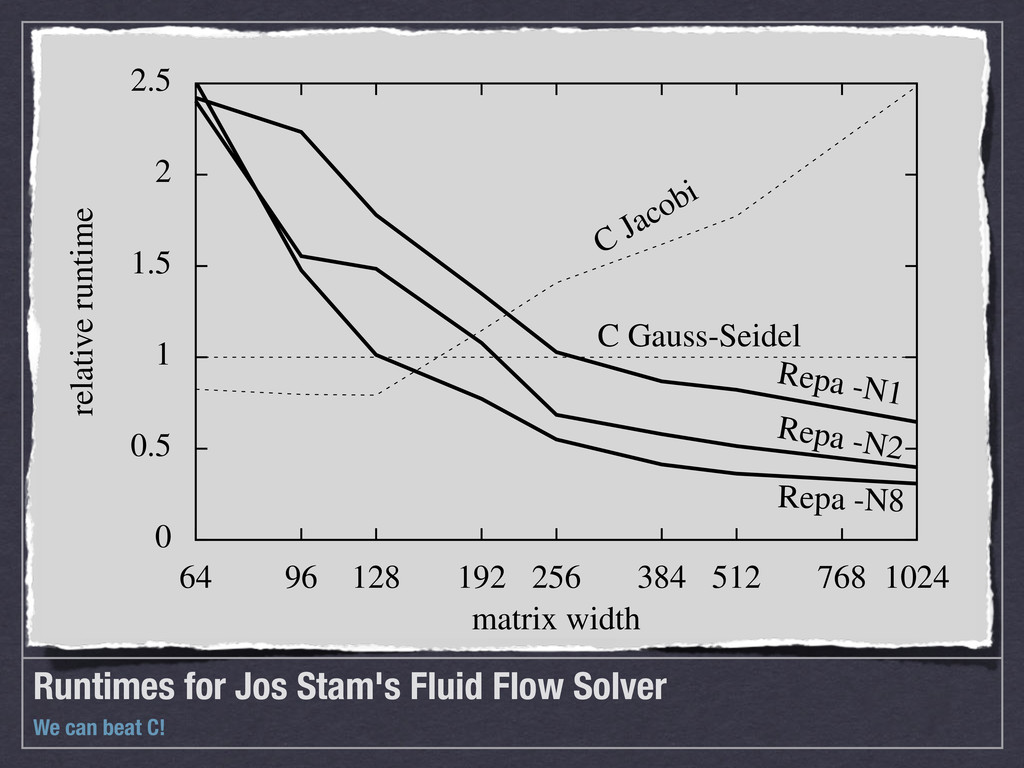
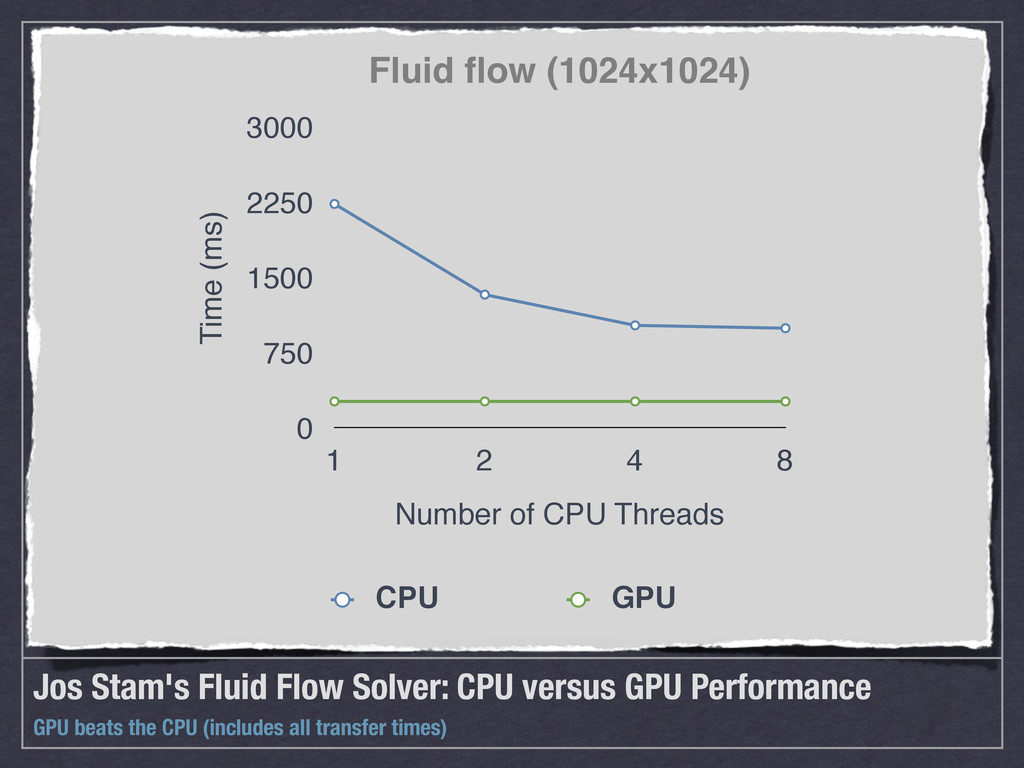
![Physical Simulation [Haskell 2012a] Fluid flow](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![Medical Imaging [Haskell 2012a] Interpolation of a slice though a](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
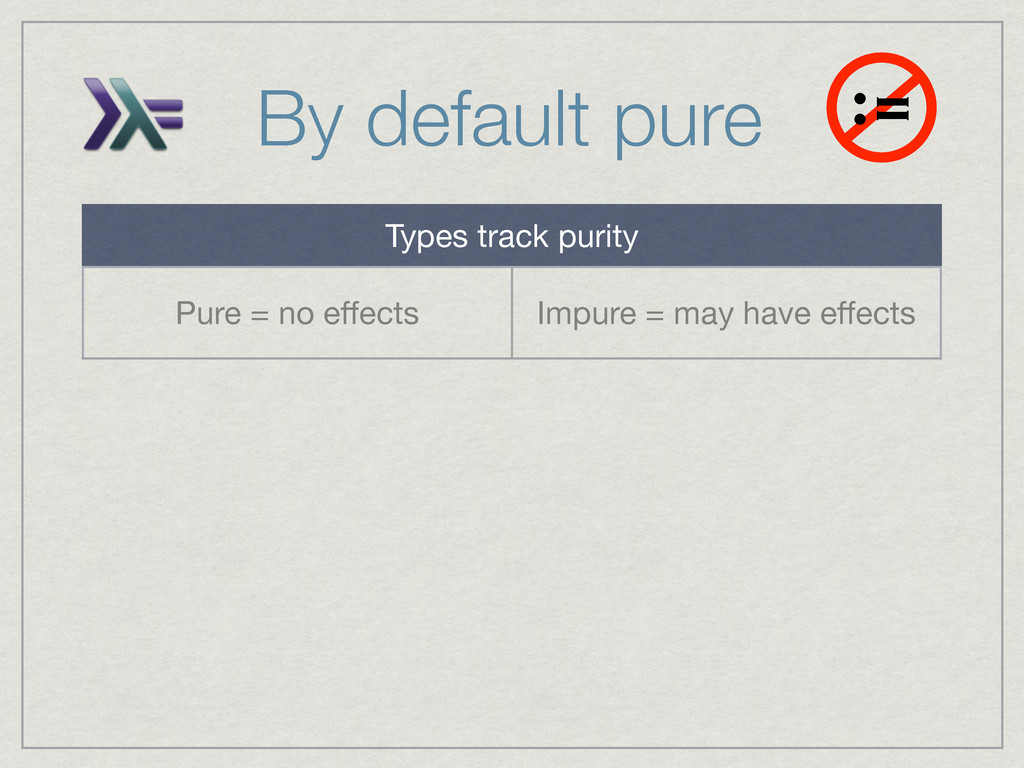
![Purity and parallelism processList :: [Int] -> ([Int], Int) processList](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_21.jpg){kind=link}
![Purity and parallelism processList :: [Int] -> ([Int], Int) processList](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_22.jpg){kind=link}
![Purity and parallelism processList :: [Int] -> ([Int], Int) processList](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_23.jpg){kind=link}
![Purity and parallelism processList :: [Int] -> ([Int], Int) processList](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_24.jpg){kind=link}
![Purity and parallelism processList :: [Int] -> ([Int], Int) processList](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
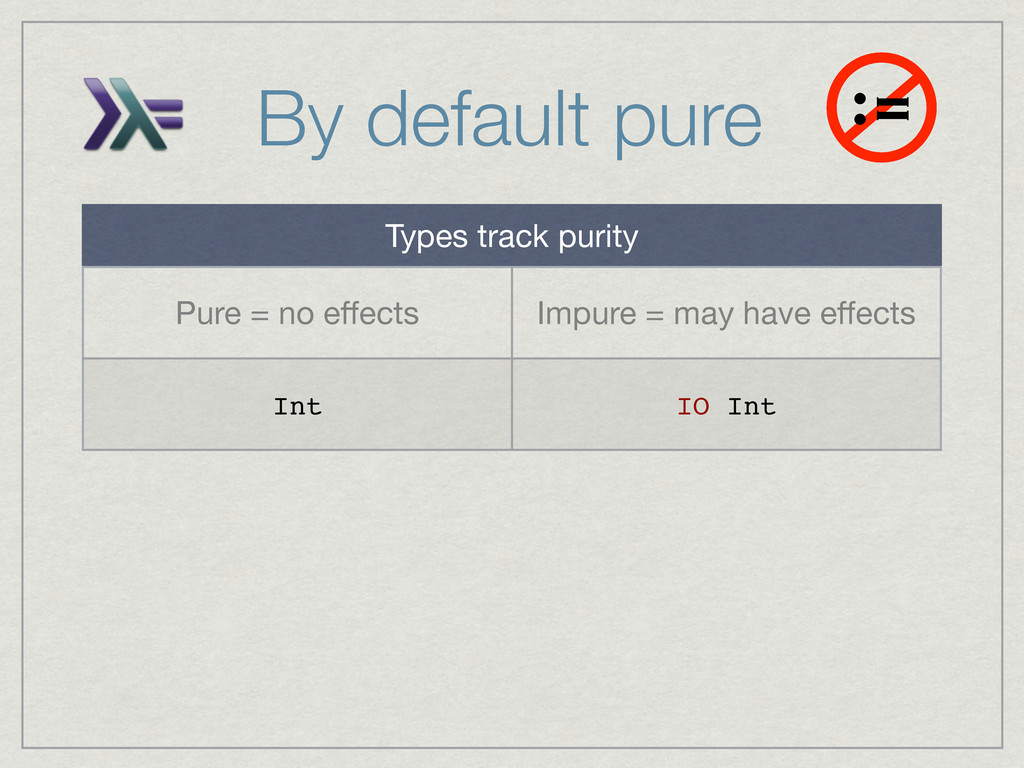{kind=link}
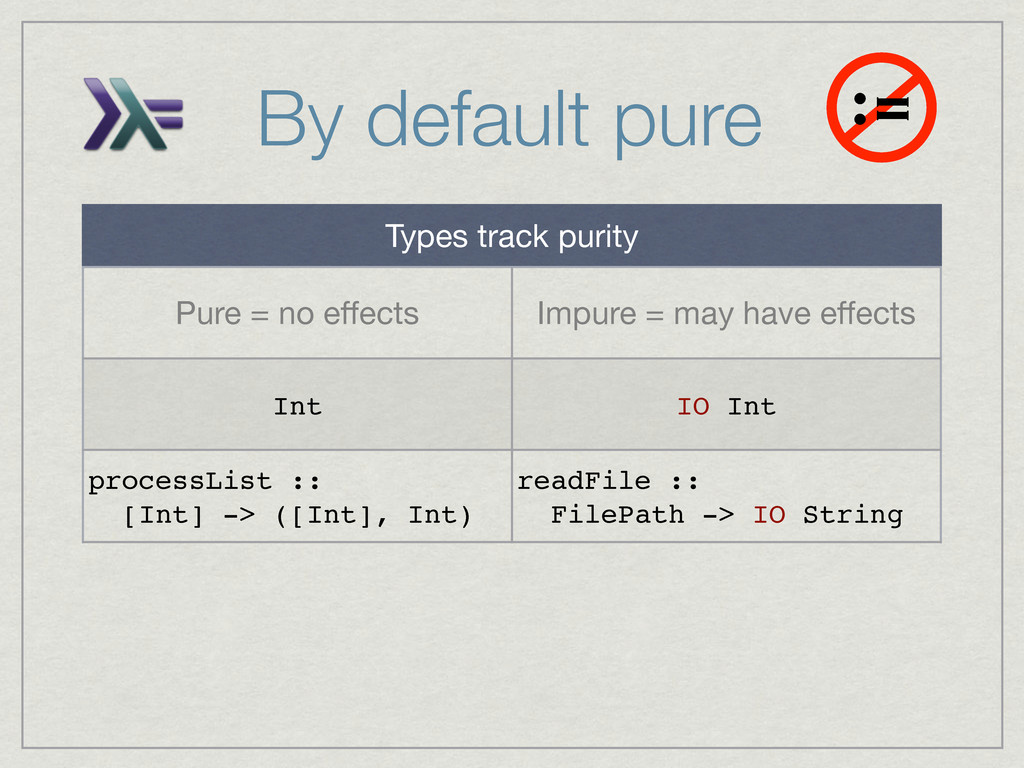{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
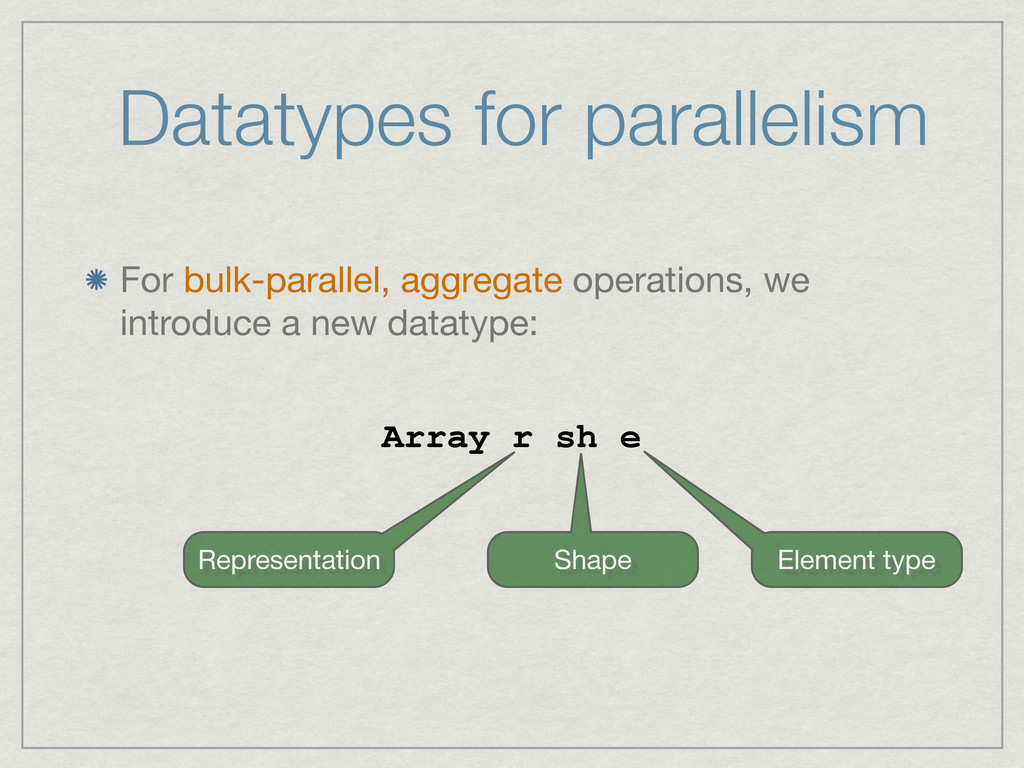{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
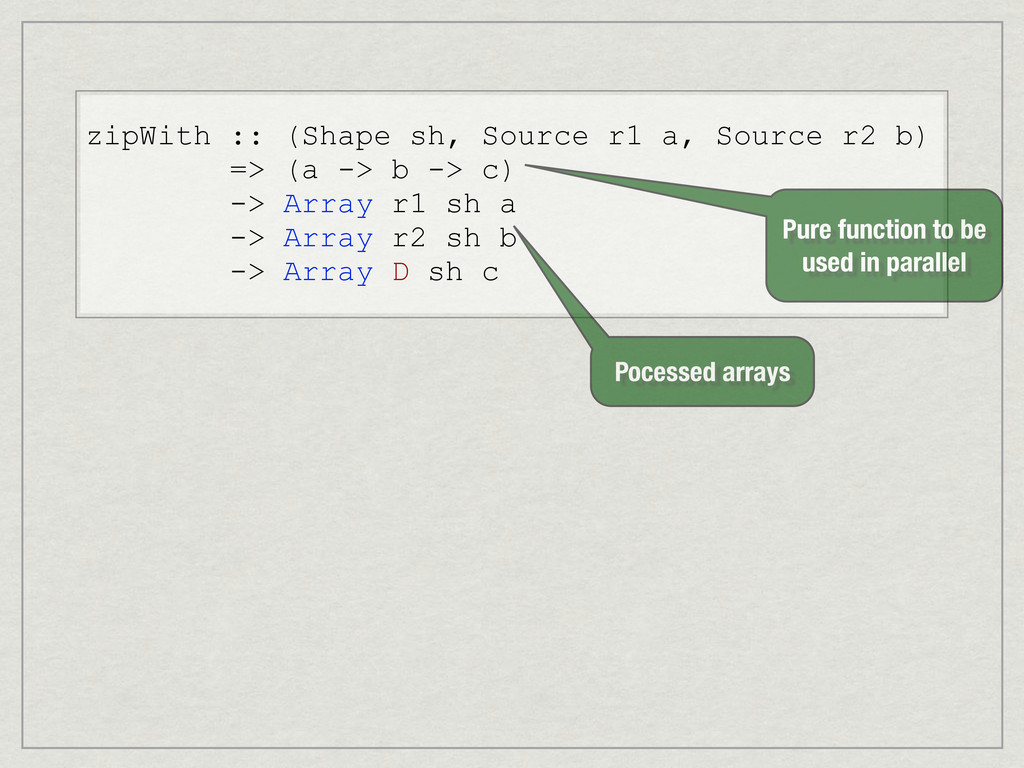{kind=link}
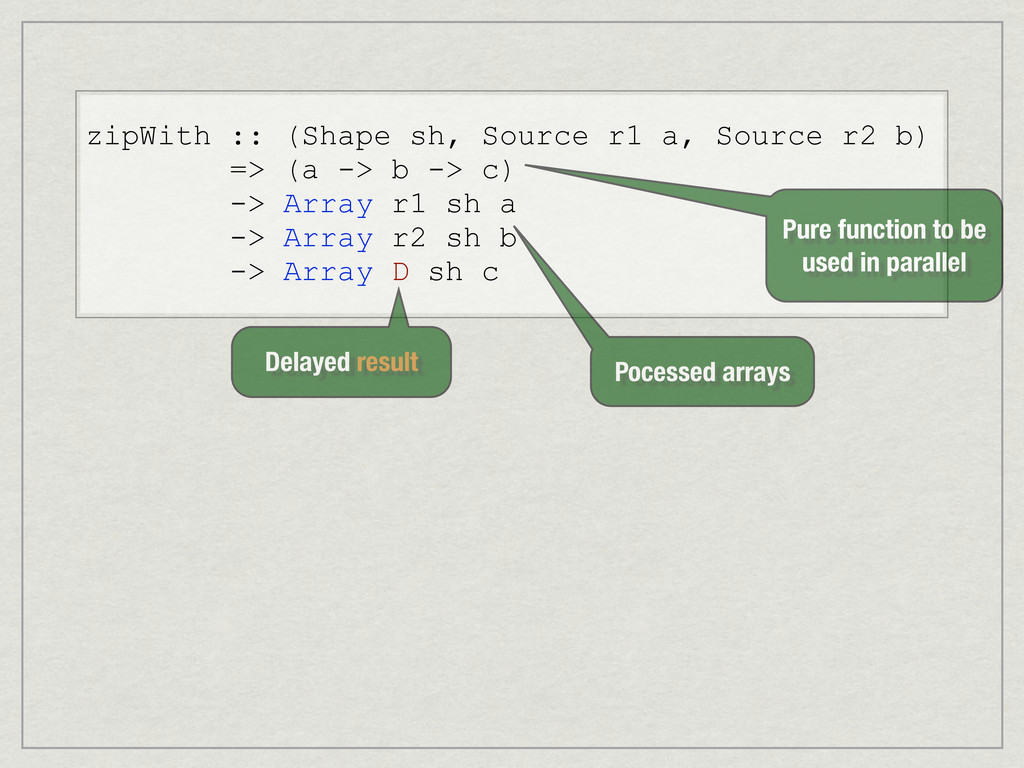{kind=link}
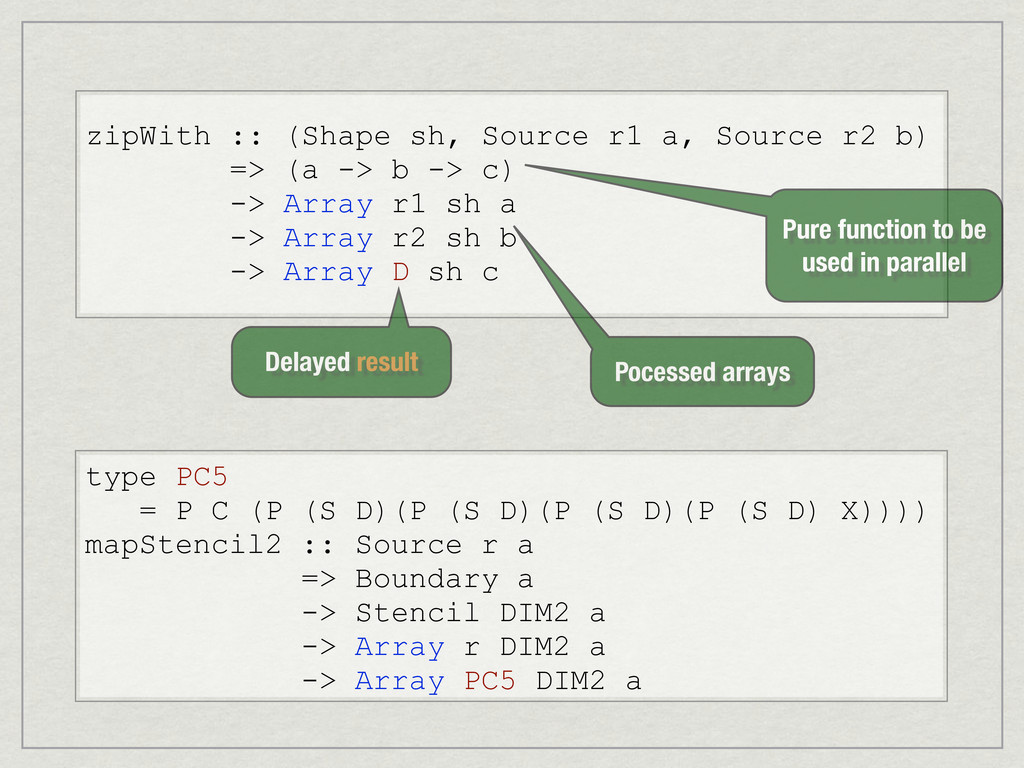{kind=link}
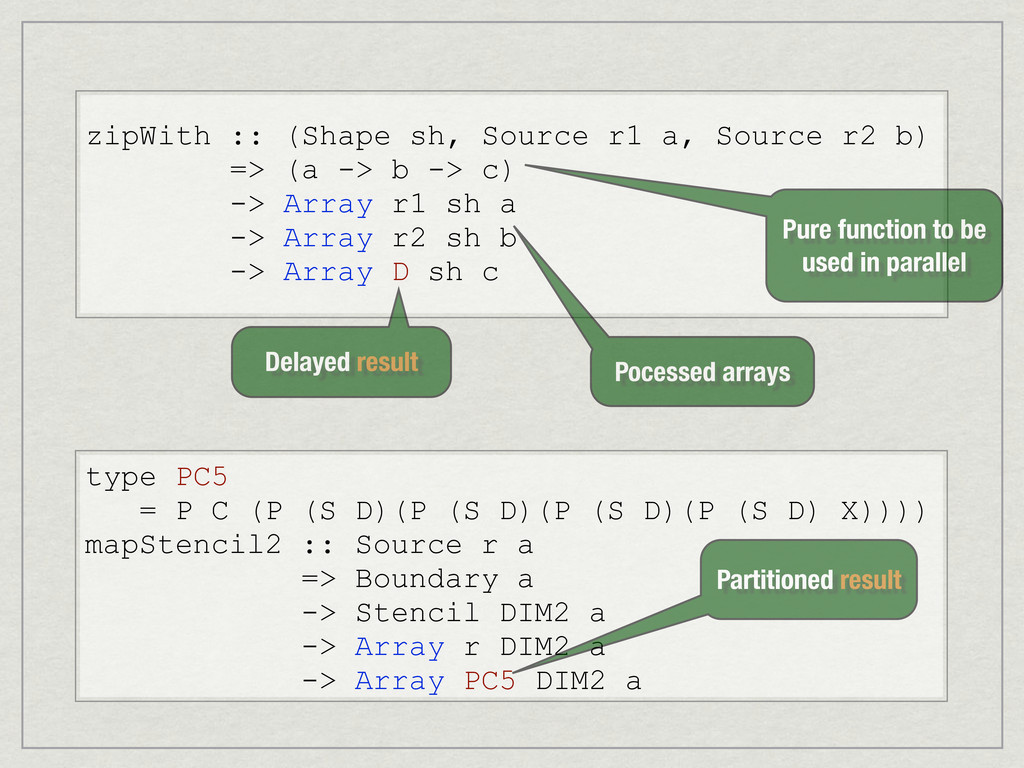{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
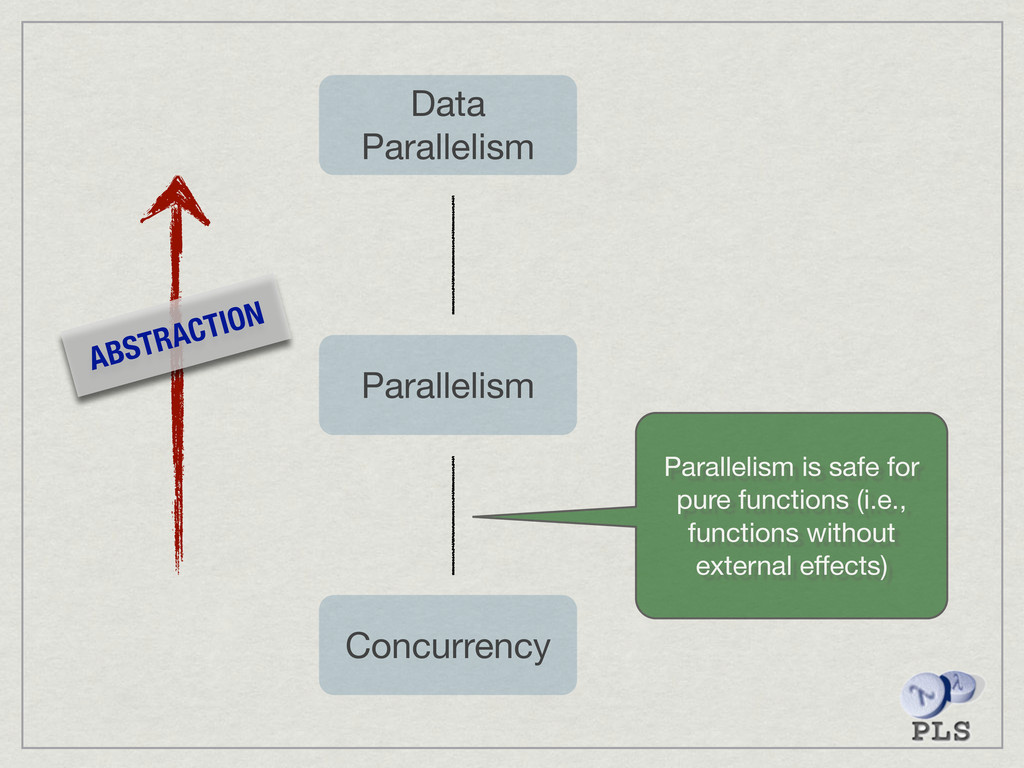{kind=link}
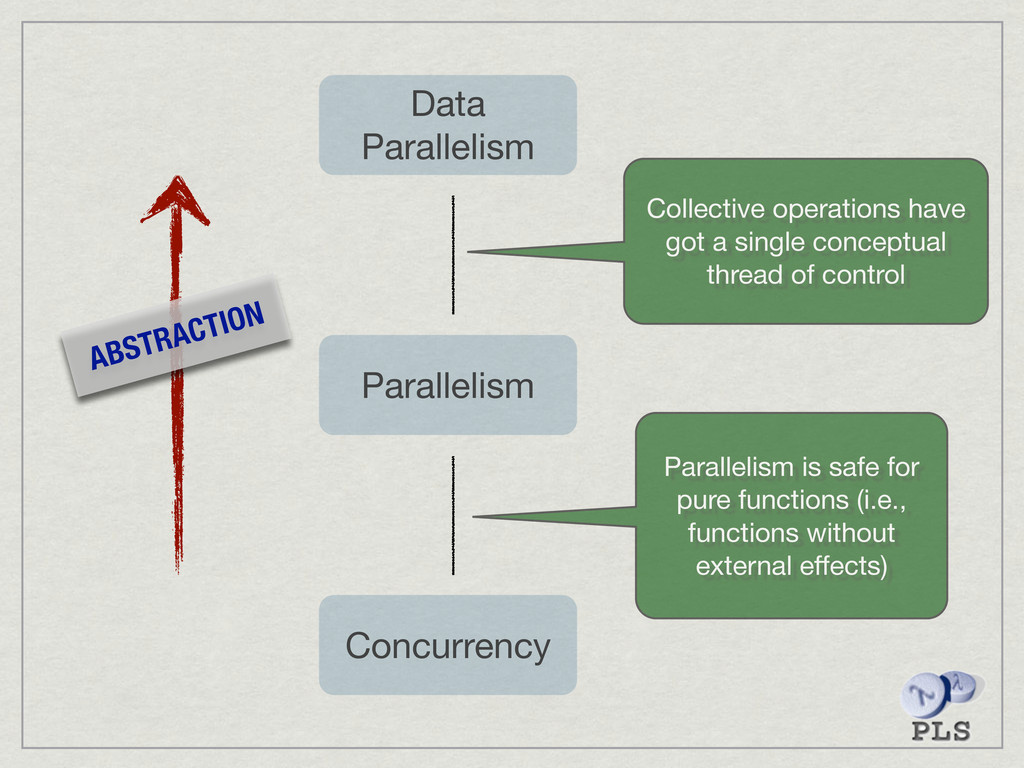{kind=link}
{kind=link}
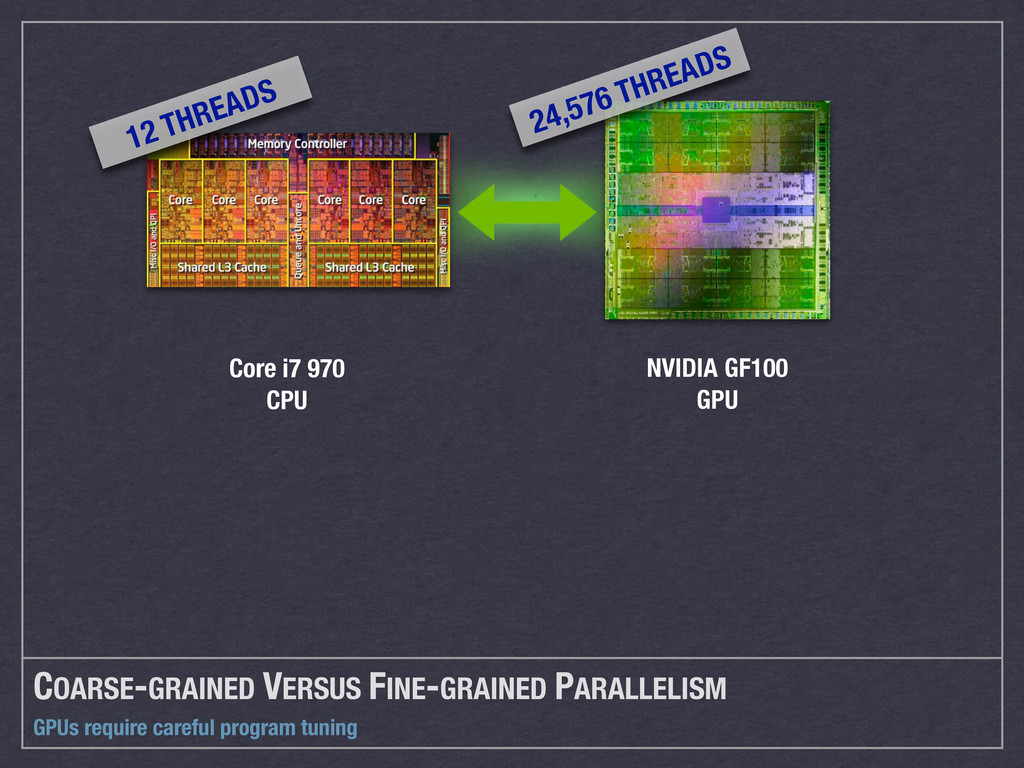{kind=link}
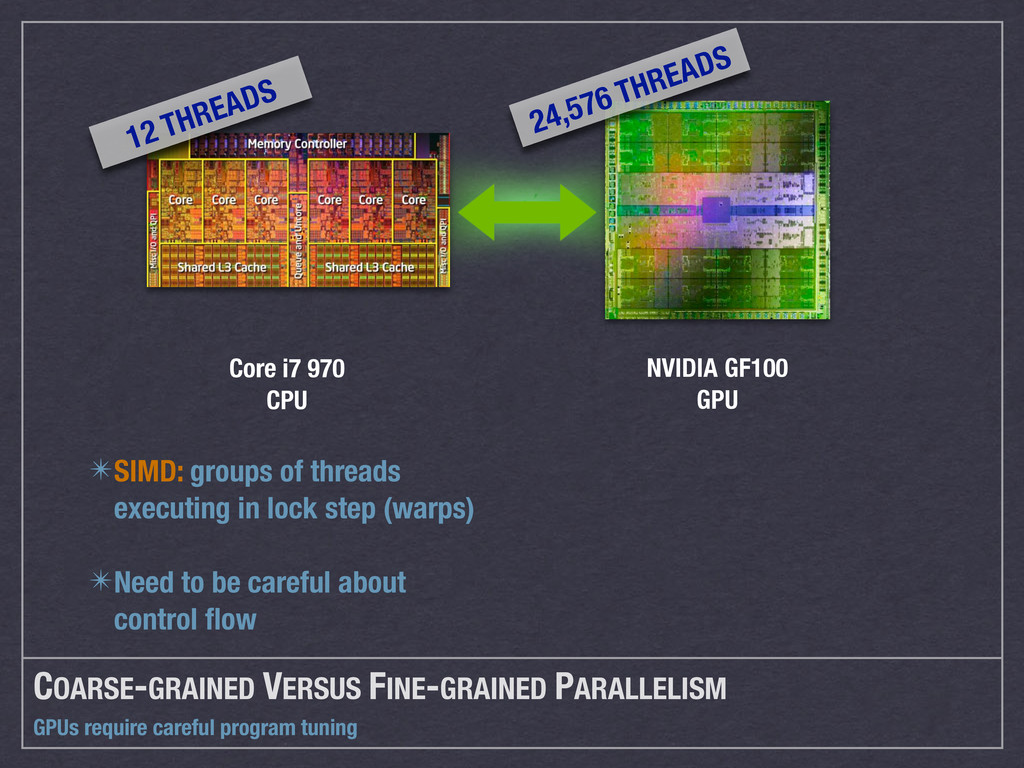{kind=link}
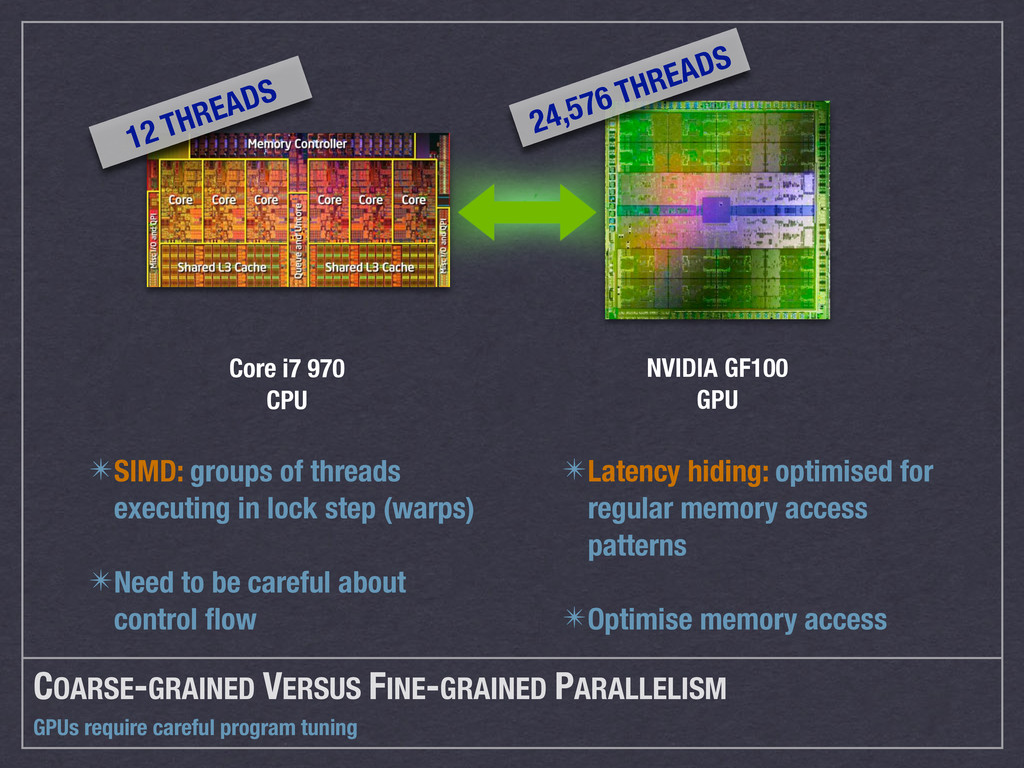{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
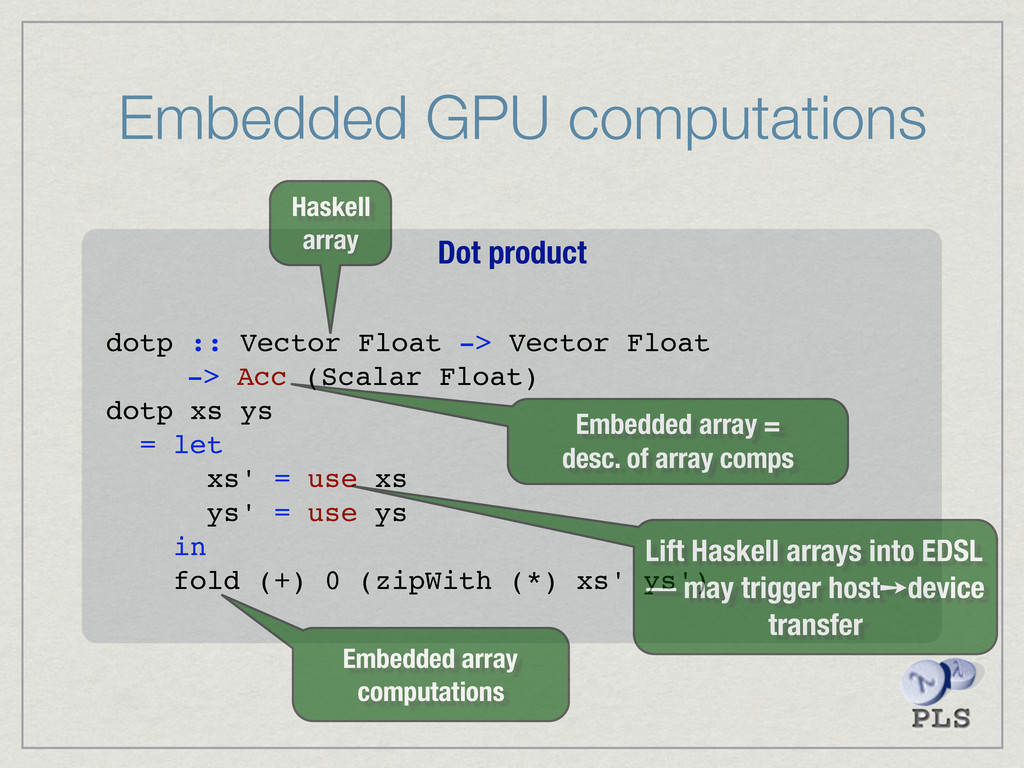{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
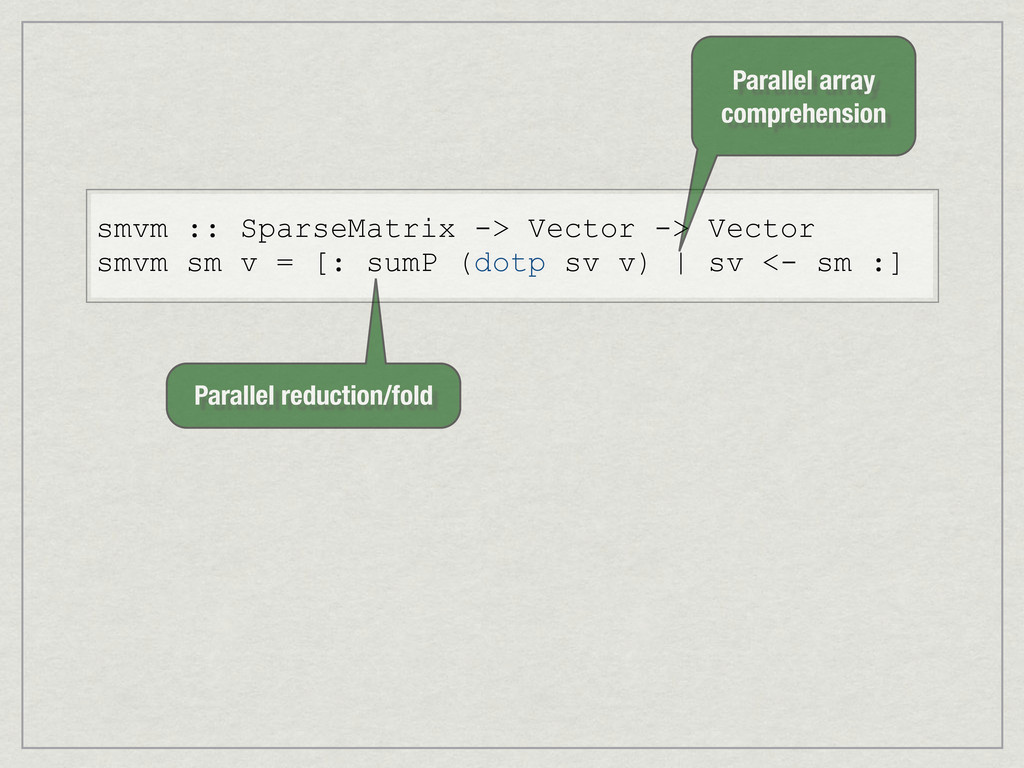{kind=link}
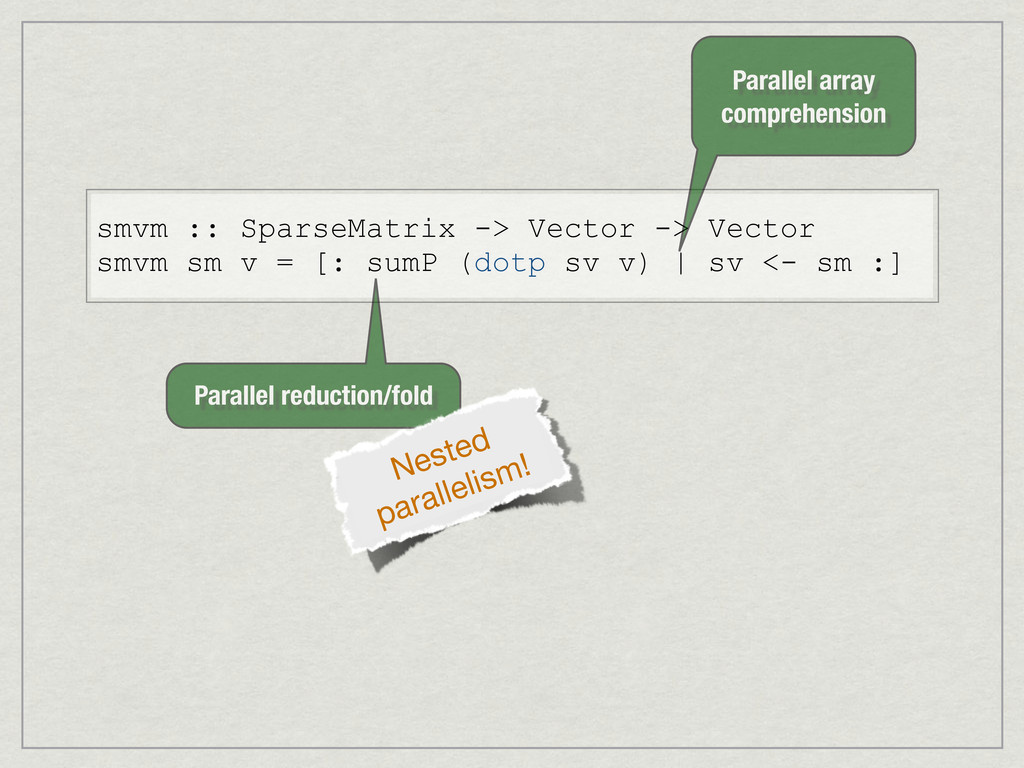{kind=link}
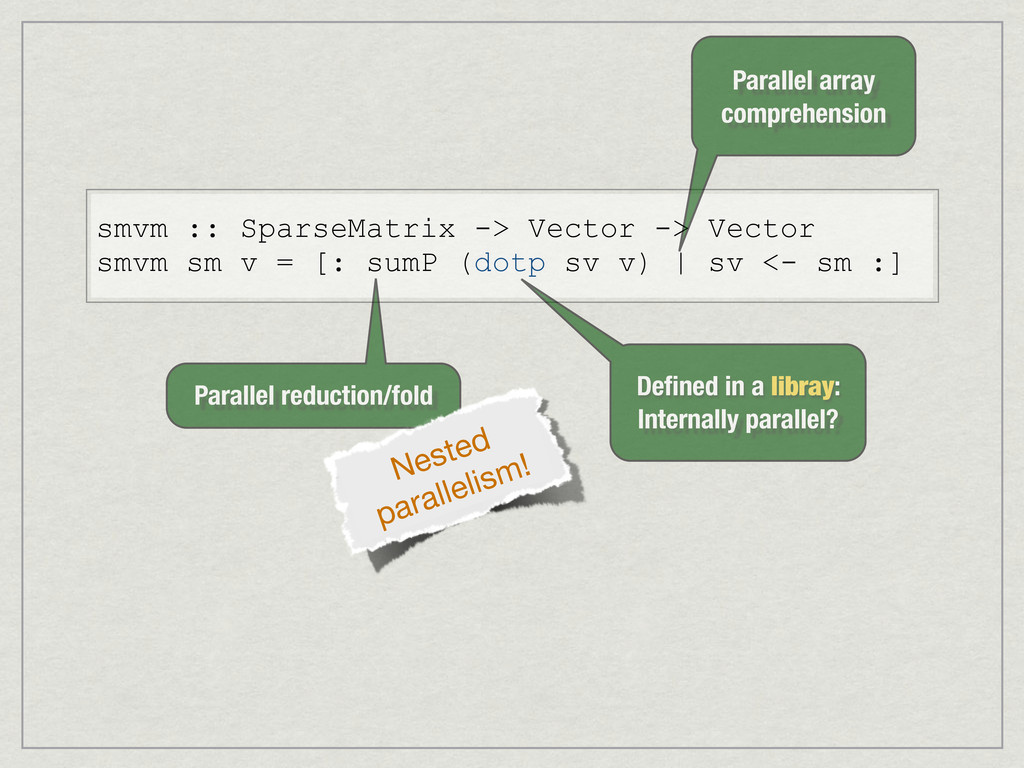{kind=link}
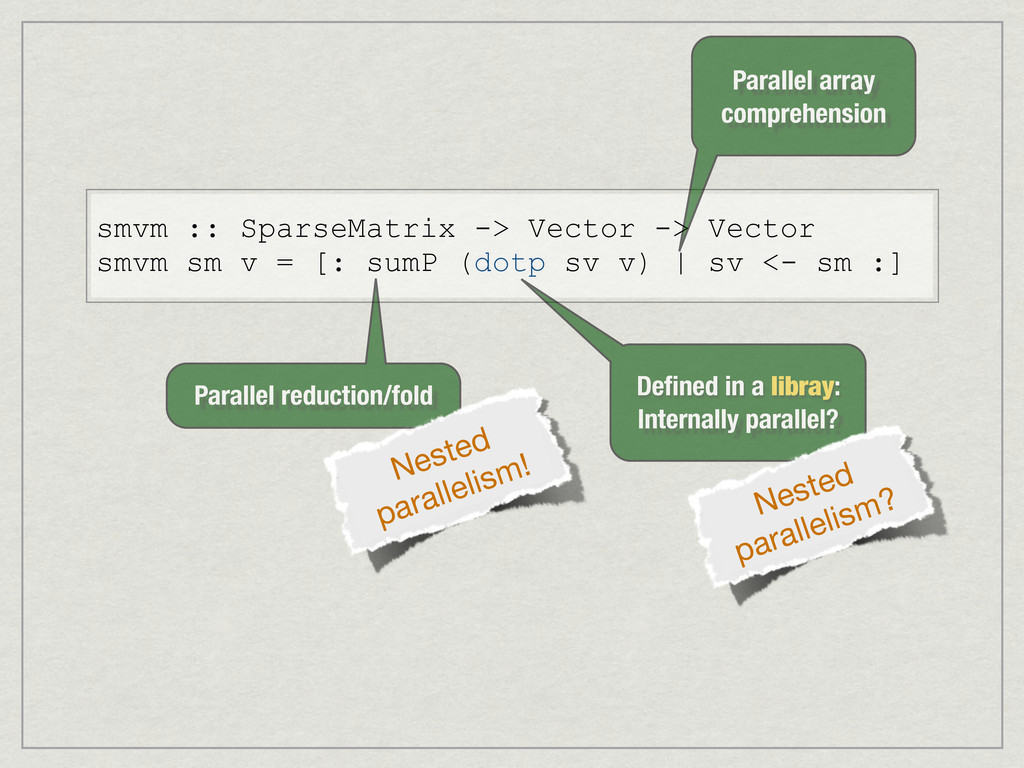{kind=link}
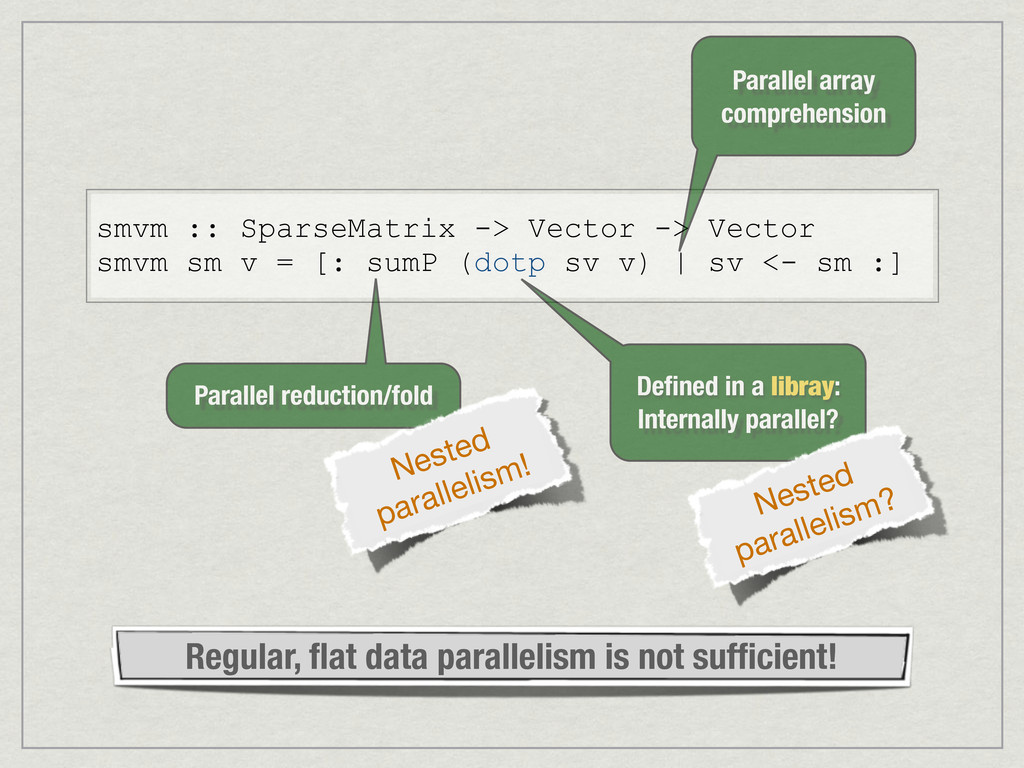{kind=link}
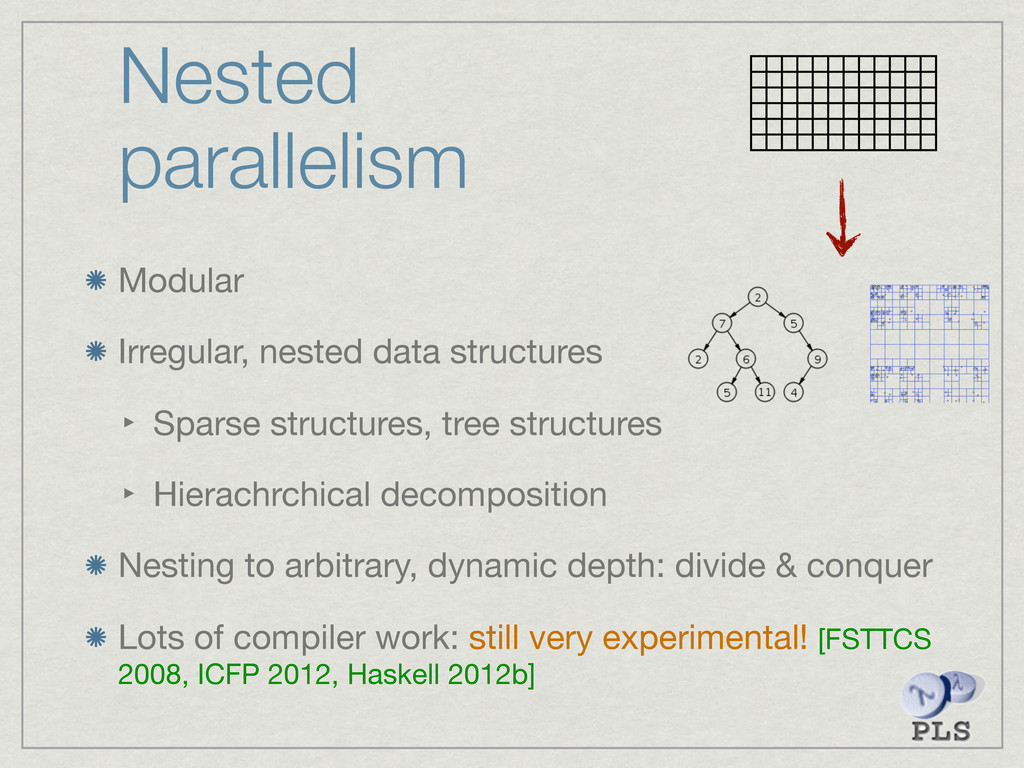{kind=link}
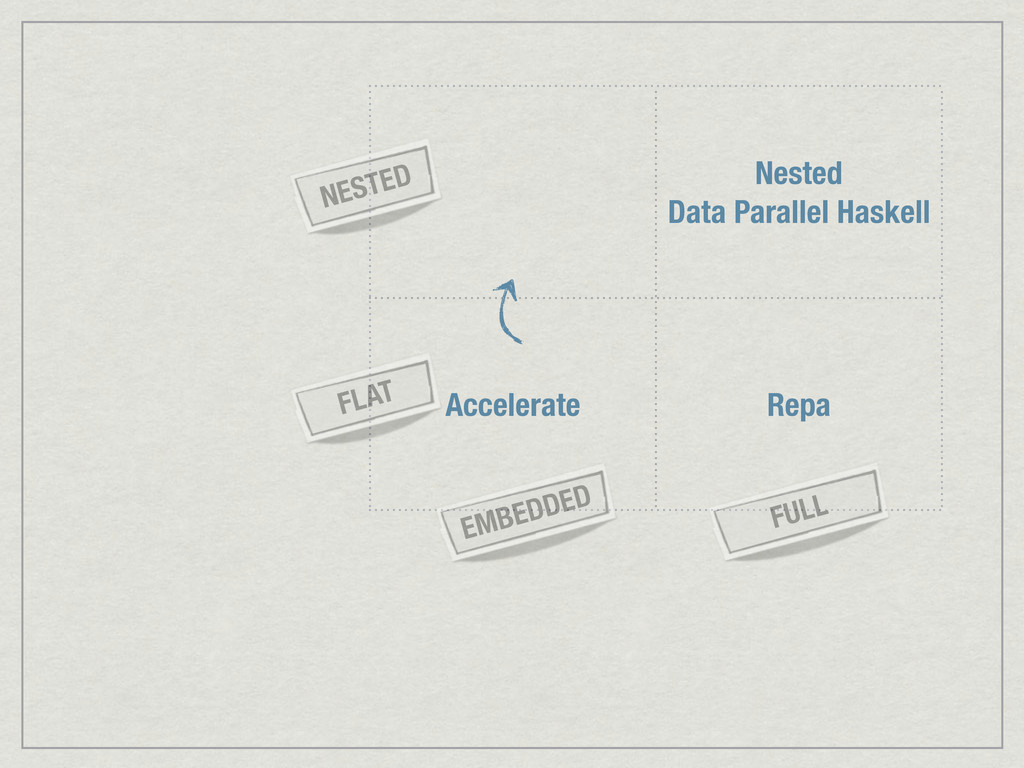{kind=link}
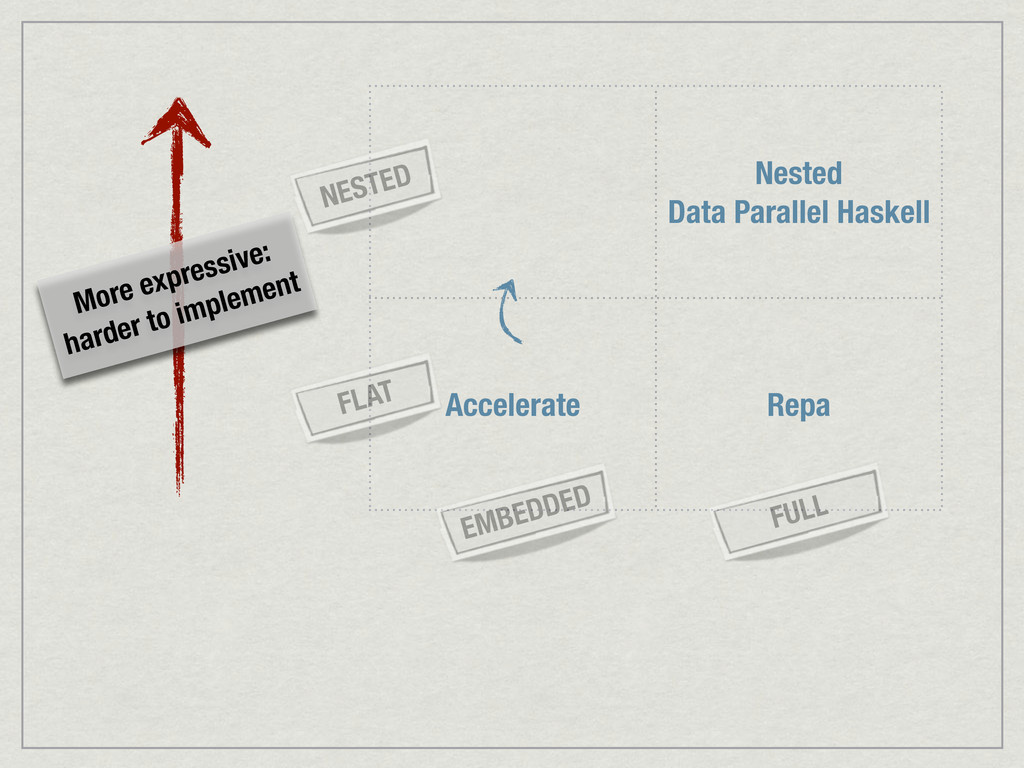{kind=link}
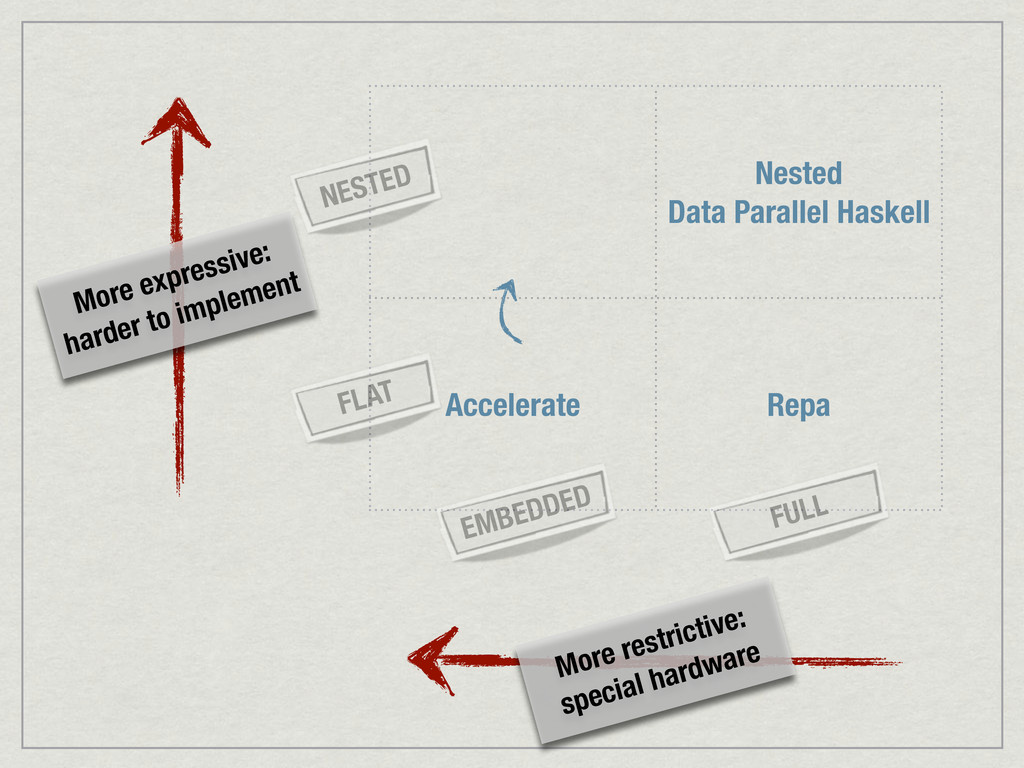{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[EuroPar 2001] Nepal -- Nested Data-Parallelism in Haskell. Chakravarty, Keller,](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_86.jpg){kind=link}
![[Haskell 2011] Efficient Parallel Stencil Convolution in Haskell. Lippmeier &](https://files.speakerdeck.com/presentations/5031be018bc57e00020180cc/slide_87.jpg){kind=link}