moteur de votre avantage compétitif. De la gestion de serveurs à l'orchestration d'intelligence. De la prévisibilité linéaire à l'adaptation dynamique. Une révolution des coûts et de la performance. UN NOUVEAU PARADIGME STRATÉGIQUE
Scalabilité horizontale linéaire (Besoin +1 = Machine +1). Patterns de charge lisses et prévisibles (Black Friday, Fin de mois). L'ÈRE IA-NATIVE Infrastructure qui "pense" et anticipe. Utilise le ML pour prédire les charges. Gère des pools de GPUs avec une granularité à la seconde. Négocie entre qualité, coût et latence. LE MONDE D'AVANT VS. L'IA-NATIVE
Un LLM pèse entre 10 Go et 800 Go. Le chargement devient un événement critique. MÉMOIRE GPU Le modèle doit résider en VRAM. Une ressource rare, coûteuse et physiquement limitée. LATENCE VARIABLE Une requête peut prendre 100ms ou 10s. Le dimensionnement moyen devient impossible. LES 3 DÉFIS MAJEURS DE L'IA
APIs REST classiques, il n'y a plus de requête "moyenne". Un utilisateur peut mobiliser un GPU pendant 30 secondes pour une seule demande complexe. L'infrastructure doit passer d'une réaction aux métriques à une prédiction des besoins. LE CHOC DE L'IMPRÉVISIBILITÉ
batch intensif, massif et capitalistique. Dure des semaines sur des milliers de GPUs. Consomme des téraoctets de datasets. Bande passante critique entre nœuds (400 Gbps). Tolérance à la panne quasi nulle.
modèle existant sur vos données spécifiques (emails, jargon interne, produits). Besoin : Agilité plutôt que puissance brute. 1 à 8 GPUs pour quelques heures ou jours. LE FINE-TUNING : L'ATELIER AGILE
production Ressources Milliers de GPUs 1 - 8 GPUs Élastique / Variable Latence Non critique Faible Ultra-critique Coût Capex massif Opex modéré Opex proportionnel COMPARAISON DES CHARGES DE TRAVAIL
génération autoregressive séquentielle (chaque mot dépend du précédent). AGENTS AUTONOMES L'IA qui planifie et utilise des outils. Workflow complexe plutôt que simple réponse. Coût et durée imprévisibles. LA NOUVELLE DIVERSITÉ DES MODÈLES
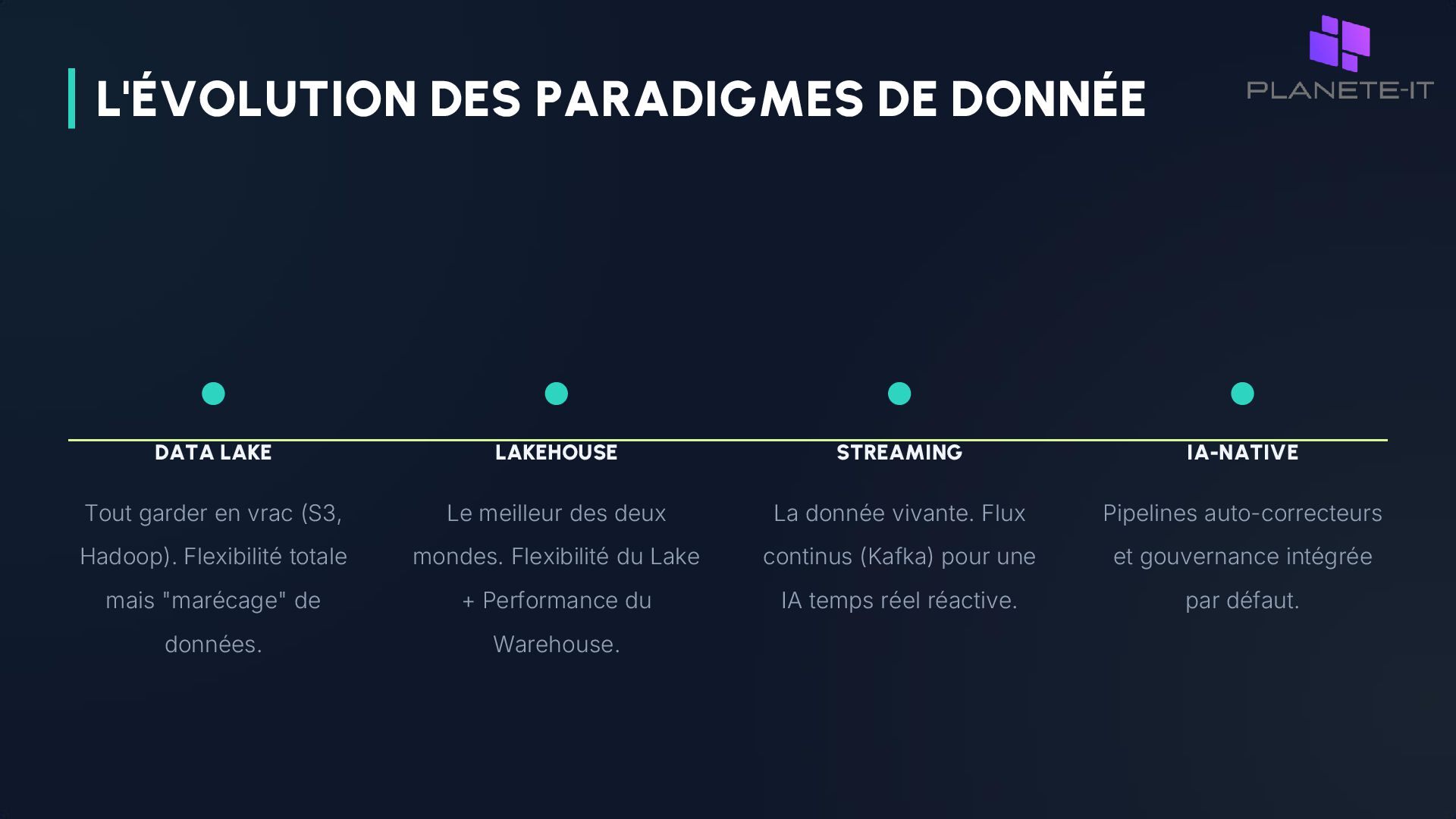
mais "marécage" de données. LAKEHOUSE Le meilleur des deux mondes. Flexibilité du Lake + Performance du Warehouse. STREAMING La donnée vivante. Flux continus (Kafka) pour une IA temps réel réactive. IA-NATIVE Pipelines auto-correcteurs et gouvernance intégrée par défaut. L'ÉVOLUTION DES PARADIGMES DE DONNÉE
facile à indexer. IMAGE & VIDÉO Scans médicaux, surveillance. Nécessite un stockage ultra-rapide. DOCS COMPLEXES PDFs avec mix texte/image. Le casse-tête du parsing IA. LE DÉFI DU NON-STRUCTURÉ
lac de données médiocre. Data Lineage : Capacité à tracer chaque prédiction jusqu'à sa source d'entraînement. Éthique & Biais : L'IA amplifie les biais. La gouvernance est une nécessité opérationnelle. Compliance RGPD : Gérer le droit à l'oubli dans des modèles entraînés. GOUVERNANCE : LA DONNÉE EST LE PRODUIT
sophistiqués). Le GPU est une armée (7000+ cœurs simples). Efficacité : Le GPU offre un calcul par Watt bien supérieur pour les multiplications matricielles de l'IA. CPU VS GPU : SPÉCIALISATION MASSIVE
et coût explosif sur la durée. ON-PREMISE Coût optimal pour charges constantes. Performance garantie mais Capex massif et gestion complexe. HYBRIDE / SPÉCIALISÉ Clouds spécialisés (CoreWeave, Lambda). Bare metal sans virtualisation pour la performance brute. GPU AS A SERVICE : QUEL MODÈLE CHOISIR ?
(Multi-Instance GPU) : Partitionner physiquement un GPU en 7 petites instances isolées. MPS (Multi-Process Service) : Plusieurs processus partagent un GPU simultanément (idéal pour l'inférence). Scheduling IA : Ray, Slurm ou Run:ai pour gérer les files d'attente et priorités. MUTUALISATION : MAXIMISER L'USAGE
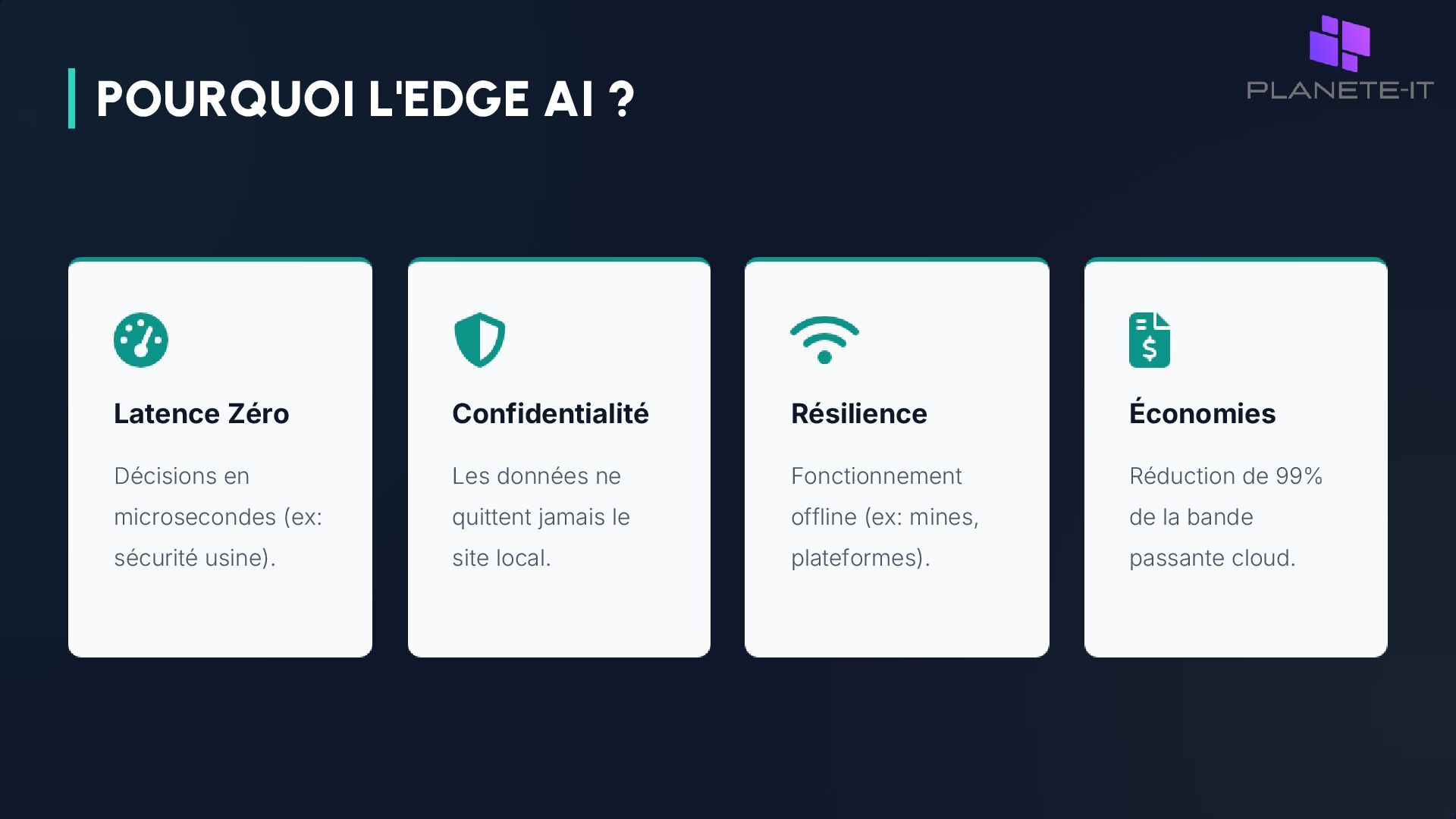
sécurité usine). Confidentialité Les données ne quittent jamais le site local. Résilience Fonctionnement offline (ex: mines, plateformes). Économies Réduction de 99% de la bande passante cloud.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}