Booking.comさんの論文: 150 Successful Machine Learning Models: 6 Lessons Learned at Booking com 6. ニュース推薦のサーベイ論文: News Recommender Systems - Survey and Roads Ahead 7. MLシステムの技術的負債の論文: Hidden Technical Debt in Machine Learning Systems 8. FTI Pipelines Architectureが提案されていたブログ: From MLOps to ML Systems with Feature/Training/Inference Pipelines The Mental Map for MLOps to align your Data-ML-Product Teams 9. Microsoftニュース推薦の論文: Empowering News Recommendation with Pre-trained Language Models 10. TrainingJobの説明がわかりやすかった@kazuneetさんのブログ: エンジニア目線で始める Amazon SageMaker Training ①機械学習 を使わないはじめての Training Job 11. TrainingJobを学習以外に使ってる事例1: Amazon SageMakerを活用した推論パイプライン運用 ディー・エヌ・エーのエンジニ アが語る構成とツール検討の試行錯誤 12. TrainingJobを学習以外に使ってる事例2: 【覚書】SageMakerトレーニングジョブで推論回す本 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
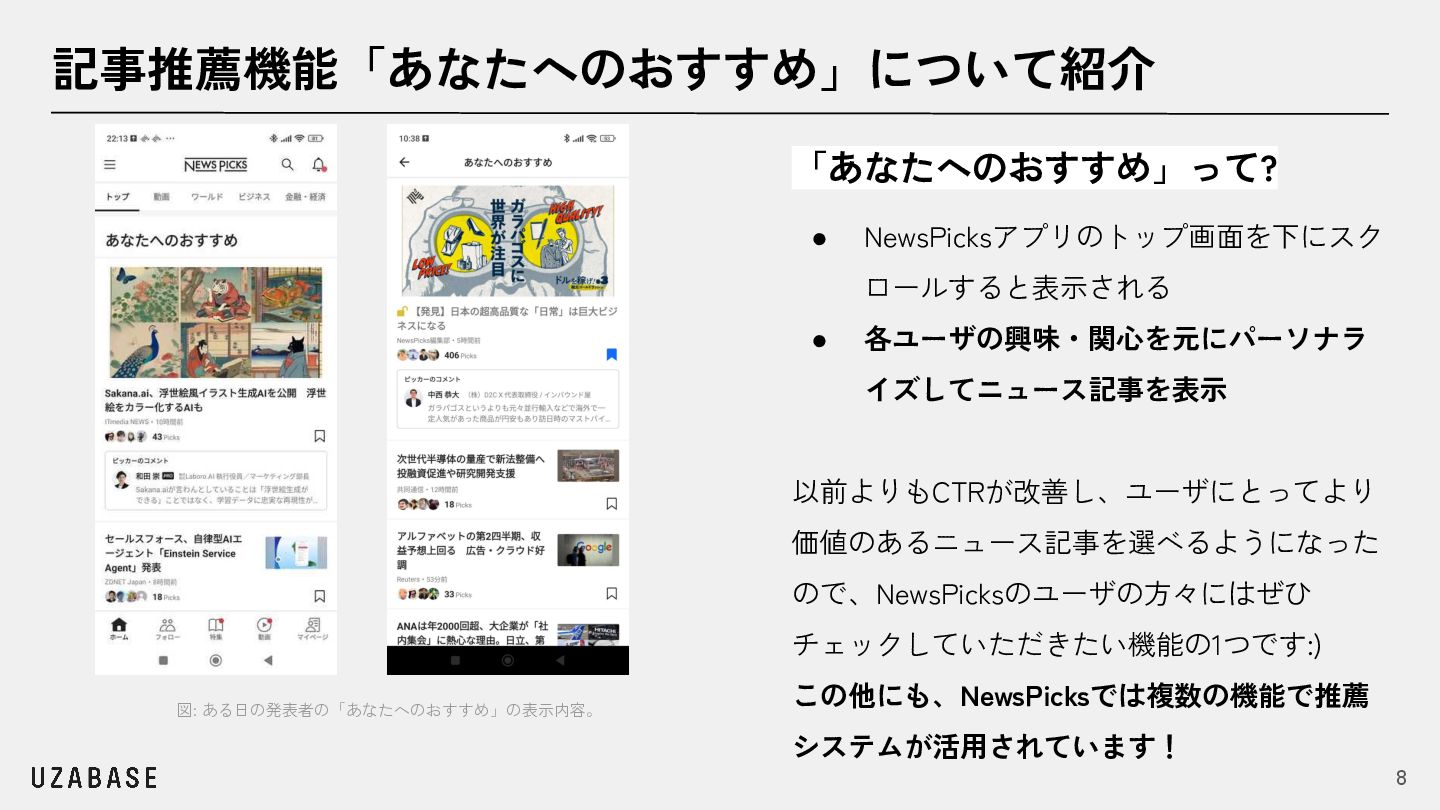{kind=link}
{kind=link}
{kind=link}
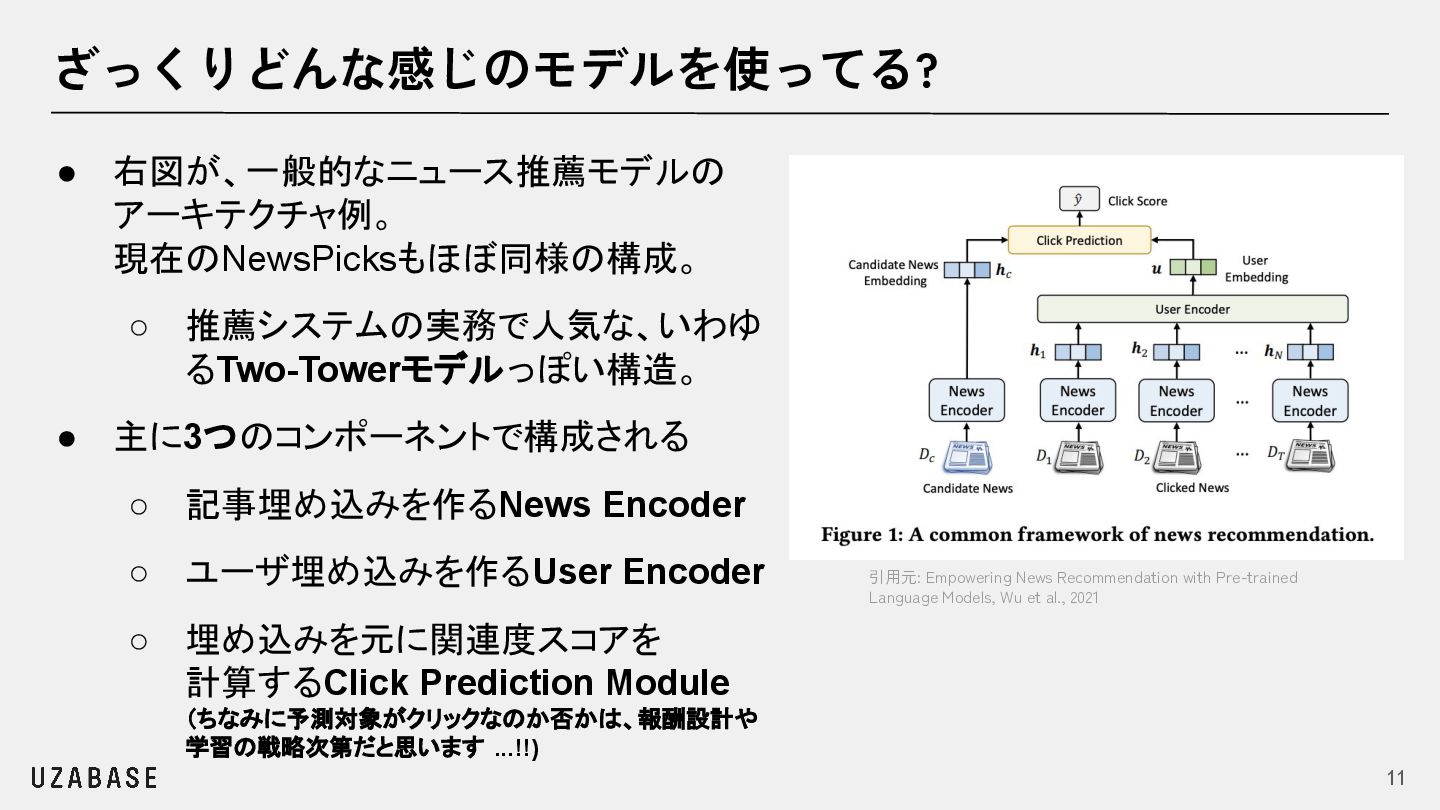{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
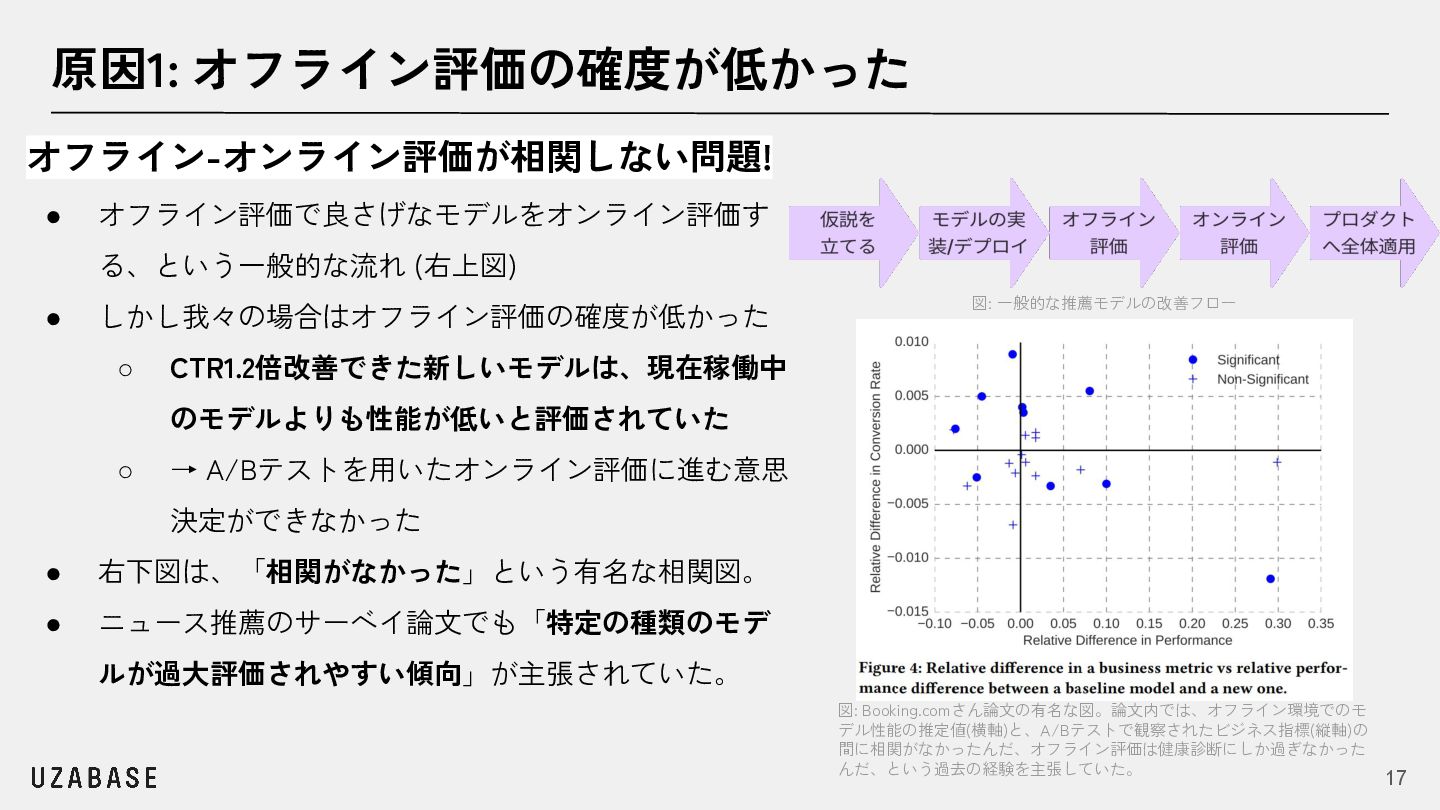{kind=link}
{kind=link}
{kind=link}
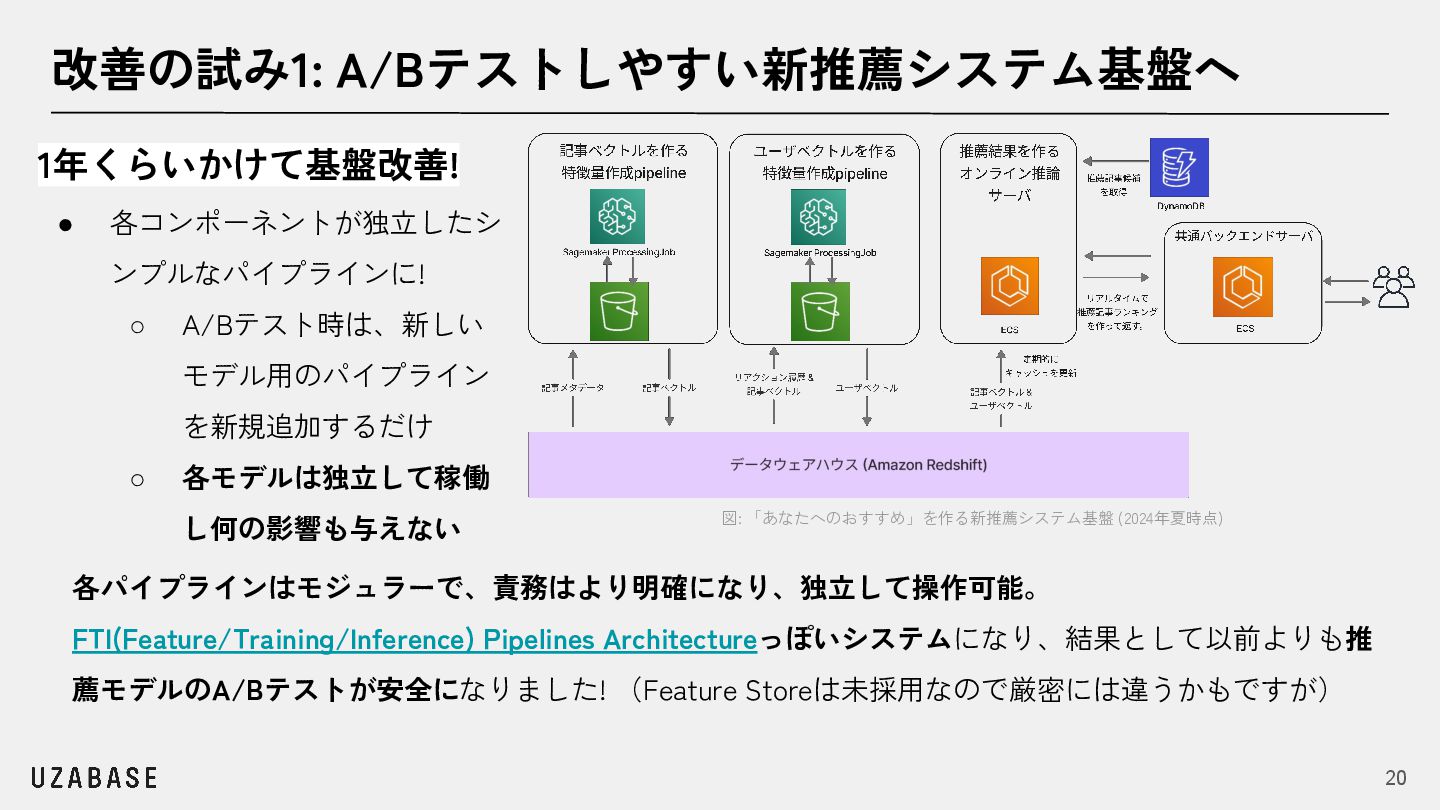{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
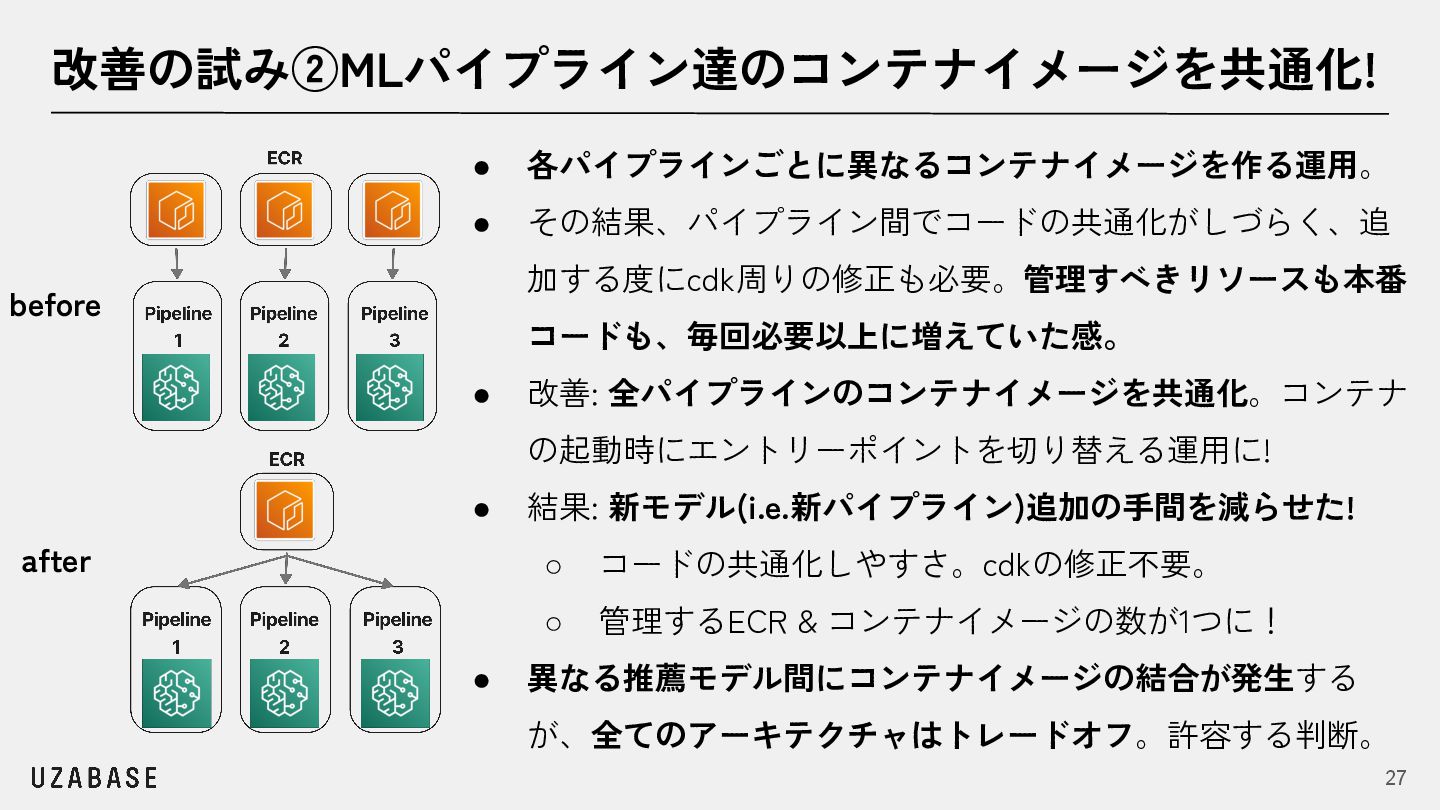{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}