Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
オンデマンド交通のための車両ルーティング問題
Search
GO Inc. dev
July 07, 2025
450
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
オンデマンド交通のための車両ルーティング問題
社内勉強会で使用した資料です。
オンデマンド交通のための車両ルーティング問題についてまとめました。
GO Inc. dev
July 07, 2025
More Decks by GO Inc. dev
See All by GO Inc. dev
バグチケットをAIで全自動解決する 生成AIに人の仕事を任せきるために必要だったこと
mot_techtalk
1
280
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
3
270
エンジニアはドメイン知識とどう向き合うべきか?
mot_techtalk
1
470
ちょっとだけ踏み込んだ ダイナミックプライシング 〜オンデマンド交通への拡張〜
mot_techtalk
1
150
MySQL, PostgreSQLのオブザーバビリティをGrafanaで向上させた話
mot_techtalk
3
900
タクシー車両の位置状態情報を支えるシステムのインフラ構成
mot_techtalk
2
920
SREの視点で挑む Redis Stream 無停止移行
mot_techtalk
2
890
生成AIで社内データを整備しよう
mot_techtalk
1
310
GO Tech Talk #31 タクシーアプリ『GO』におけるNext.jsの活用
mot_techtalk
2
730
Featured
See All Featured
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Technical Leadership for Architectural Decision Making
baasie
3
440
Accessibility Awareness
sabderemane
1
160
We Are The Robots
honzajavorek
0
280
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Transcript
AI 2025.07.03 宮本 真実 GO株式会社 オンデマンド交通のための 車両ルーティング問題
AI 2 項目 01|車両ルーティング問題とその解法 02|相乗り問題への拡張 03|実装 04|最新動向
AI 3 01 車両ルーティング問題とその解法
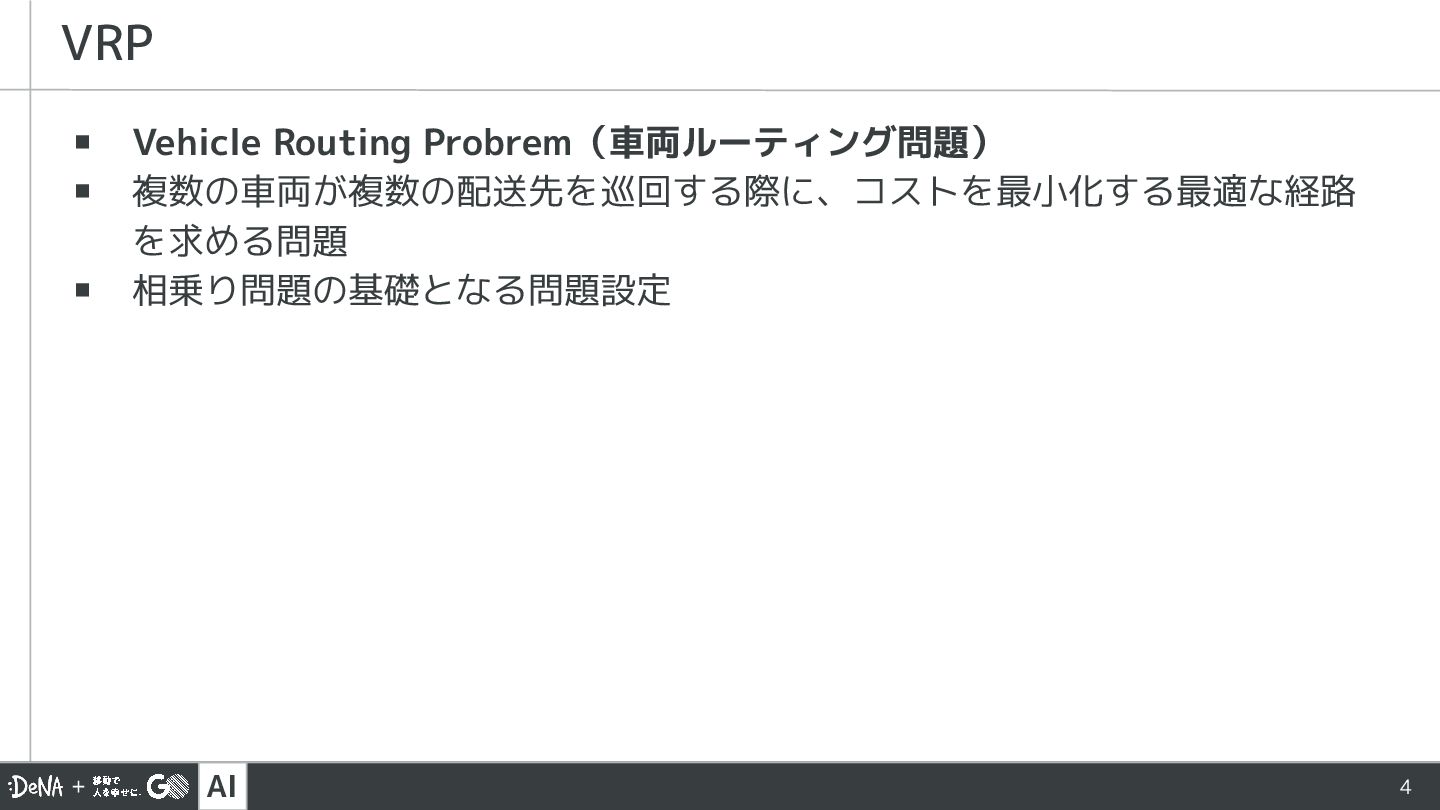
AI ▪ Vehicle Routing Probrem(車両ルーティング問題) ▪ 複数の車両が複数の配送先を巡回する際に、コストを最小化する最適な経路 を求める問題 ▪ 相乗り問題の基礎となる問題設定
VRP 4
AI ▪ 目的関数 ▪ x ij : 地点iから地点jへの道を通る場合は1, 通らない場合は0 ▪
c ij : 地点iから地点jへ移動するのにかかるコスト VRP ▪ 制約 ▪ 各顧客は必ず1回だけ訪問される ▪ 車両はある顧客を訪問したら、必ずそこから出発する ▪ 全ての車両はデポ(車庫)から出発し、デポに戻る 目的関数は一つとは限らず「総移動距離を最小化する」だけ でなく「車両台数を最小化する」「全ドライバーの走行距離 を平準化する」など複数の目的を組み合わせることもある 5
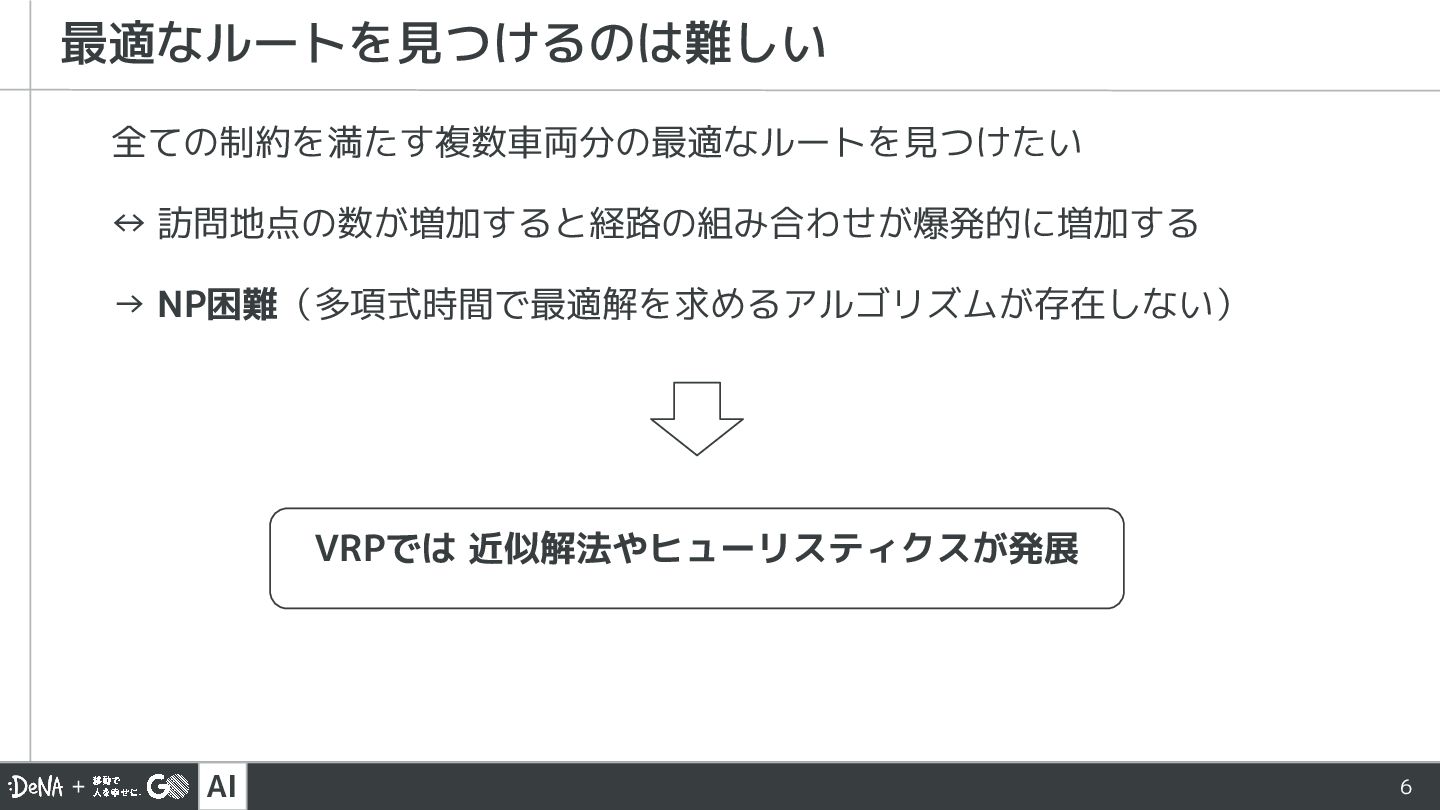
AI 全ての制約を満たす複数車両分の最適なルートを見つけたい ↔ 訪問地点の数が増加すると経路の組み合わせが爆発的に増加する → NP困難(多項式時間で最適解を求めるアルゴリズムが存在しない) 最適なルートを見つけるのは難しい VRPでは 近似解法やヒューリスティクスが発展 6
AI 最適解ではなく近似解を素早く見つける 構築的ヒューリスティクス (Constructive Heuristics) • 何もない状態からある一定のルールにしたがって逐次 的に解を構築する手法 • 得られる解の質は最適解から大きく劣ることが多い
改善ヒューリスティクス (Improvement Heuristics) • 構築的ヒューリスティクスなどで得られた初期解を出発 点とし、解に小さな変更(近傍操作)を繰り返し加え、より 良い解へと改善していく手法 メタヒューリスティクス (Metaheuristics) • 構築法や改善法を部品として利用しつつ、局所最適解 から脱出するための探索戦略 • 解空間をより広範に探索し、質の高い解を発見する可 能性が高まる ▪ アルゴリズムの洗練度に応じて階層的に分類できる 7
AI 代表的手法 : 最近傍法 (Nearest Neighbor) ▪ 目的関数を直接計算するのではなく、「最も近いところへ行く」という貪欲 なルールに従って逐次的に変数の値(どの x
ij を1にするか)を決めていく ▪ 制約を満たす中で最も近いことろを選ぶ ▪ 制約を満たすところがなければデポに戻り、新しいルートを開始する 構築的ヒューリスティクス 8
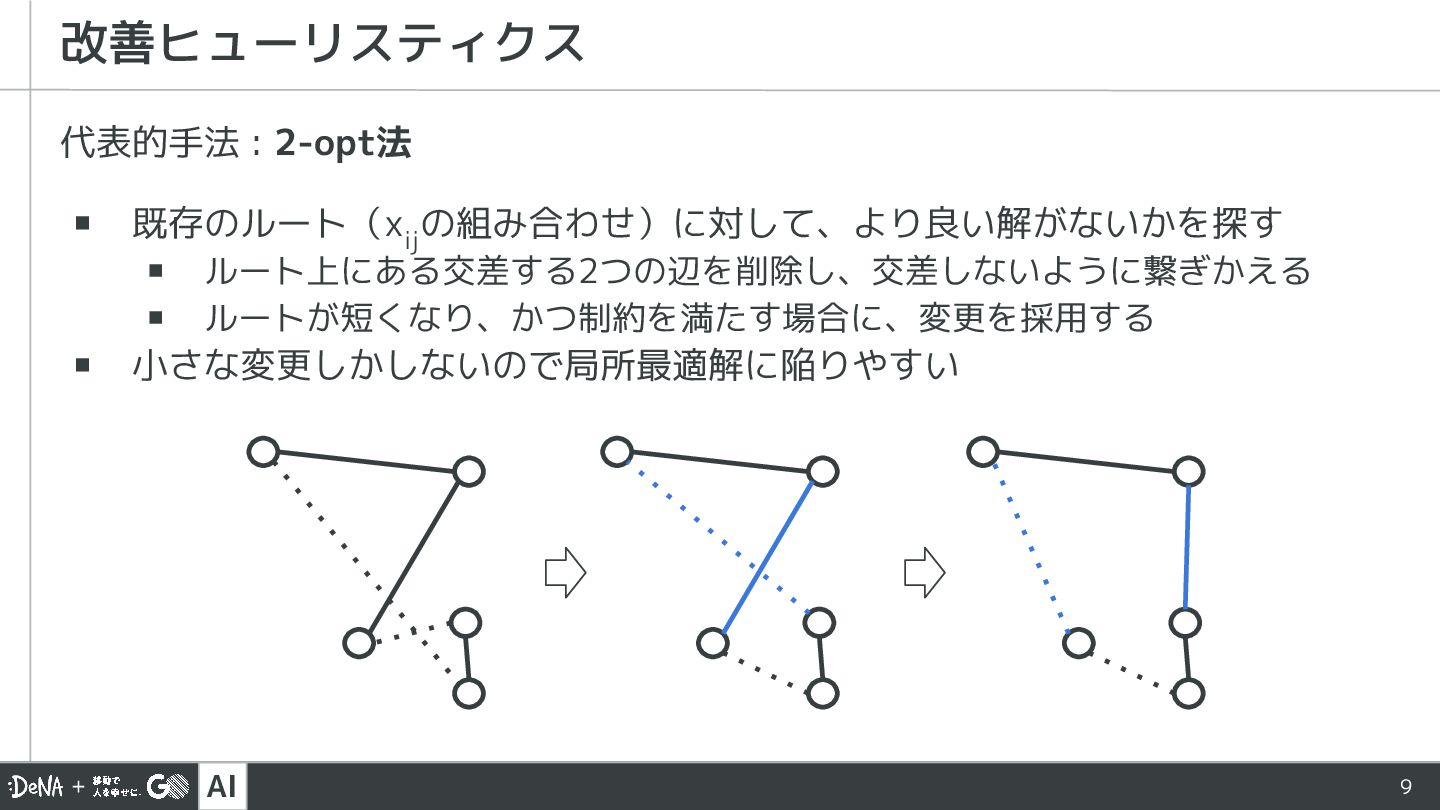
AI 代表的手法 : 2-opt法 ▪ 既存のルート(x ij の組み合わせ)に対して、より良い解がないかを探す ▪ ルート上にある交差する2つの辺を削除し、交差しないように繋ぎかえる
▪ ルートが短くなり、かつ制約を満たす場合に、変更を採用する ▪ 小さな変更しかしないので局所最適解に陥りやすい 改善ヒューリスティクス 9
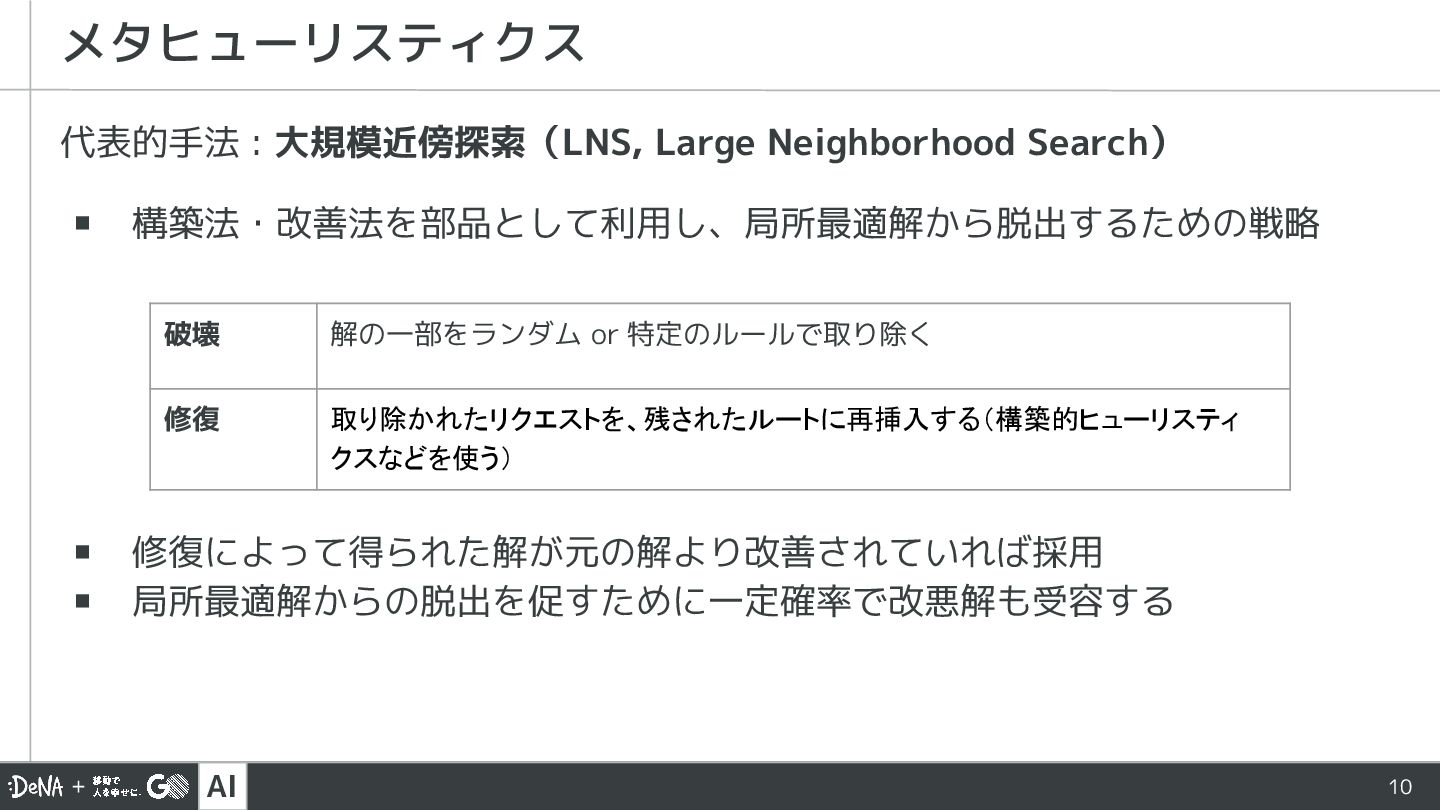
AI 代表的手法 : 大規模近傍探索(LNS, Large Neighborhood Search) ▪ 構築法・改善法を部品として利用し、局所最適解から脱出するための戦略 メタヒューリスティクス
破壊 解の一部をランダム or 特定のルールで取り除く 修復 取り除かれたリクエストを、残されたルートに再挿入する(構築的ヒューリスティ クスなどを使う) ▪ 修復によって得られた解が元の解より改善されていれば採用 ▪ 局所最適解からの脱出を促すために一定確率で改悪解も受容する 10
AI LNSはVRP・相乗り問題(DARP)で特に強力な手法でよく使用される LNSの利点 柔軟性 修復(再挿入)の際にそれが全ての制約を満たすかどうかチェックさえすれば フレームワークが機能し、問題特有の複雑なルールをブラックボックスとして 扱うことができる 探索能力 一度に多くのリクエストを破壊・修復することで、解空間上で大きなジャンプ が可能となる
動的問題への親和性 修復フェーズは動的に発生した新しいリクエストの挿入動作と似ている 特に柔軟性の観点から、VRPより制約が増えるDARPで使われる 11
AI 12 02 相乗り問題への拡張
AI ▪ Dial-a-Ride Probrem ▪ 相乗り問題特有の制約を加える ▪ VRP(輸送問題)と異なり、人間を運ぶため人間中心の性質に起因する 特有の制約がある DARP
乗降ペア・先行制約 リクエストが乗車地点・降車地点のペアで構成され、その順番を守らな ければいけない 容量制約 車両の定員を超えてはいけない time-window制約 乗客が希望する乗車時間・到着時間を守らなければいけない 最大乗車時間制約 乗客が車内で過ごす最大許容時間を超えてはいけない 13
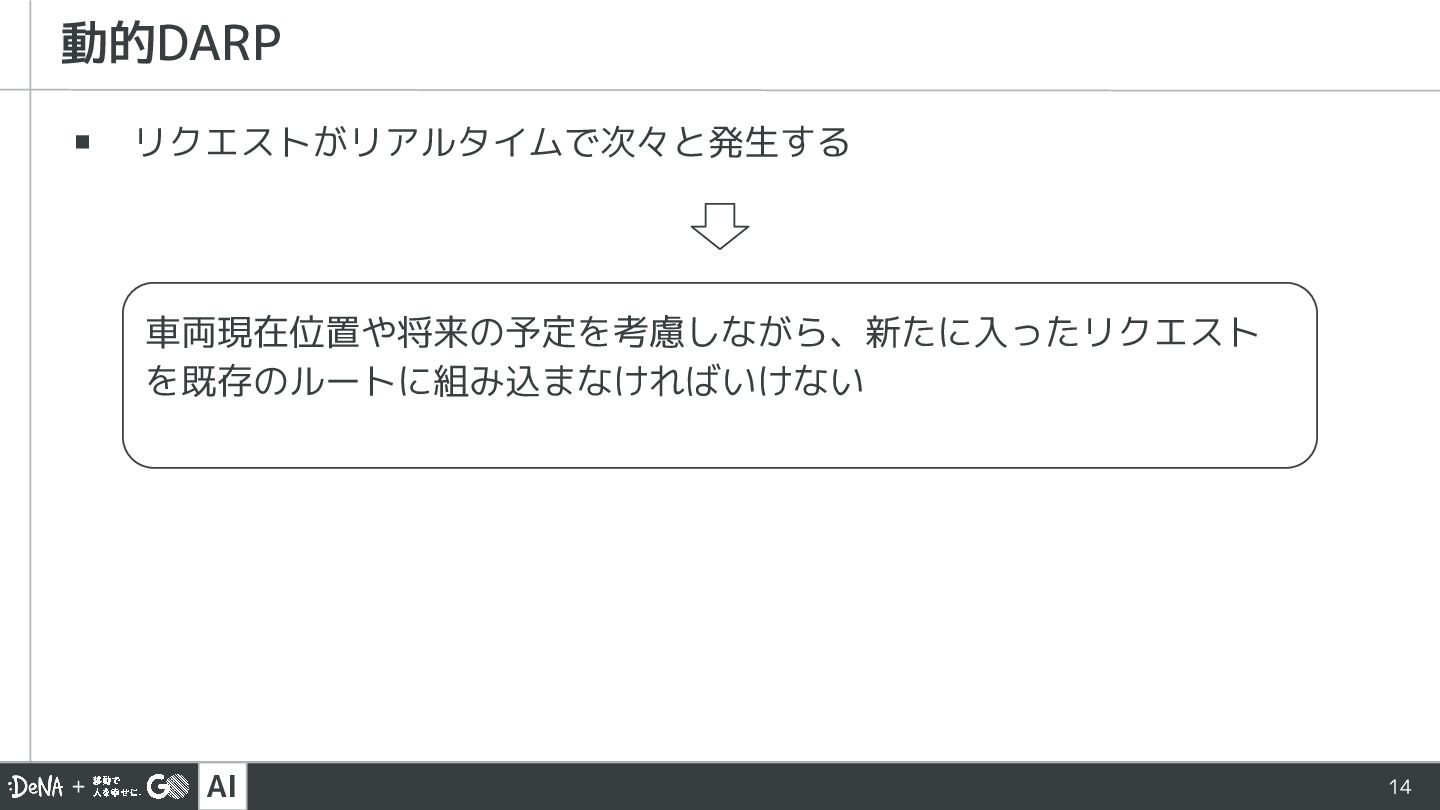
AI ▪ リクエストがリアルタイムで次々と発生する 動的DARP 車両現在位置や将来の予定を考慮しながら、新たに入ったリクエスト を既存のルートに組み込まなければいけない 14
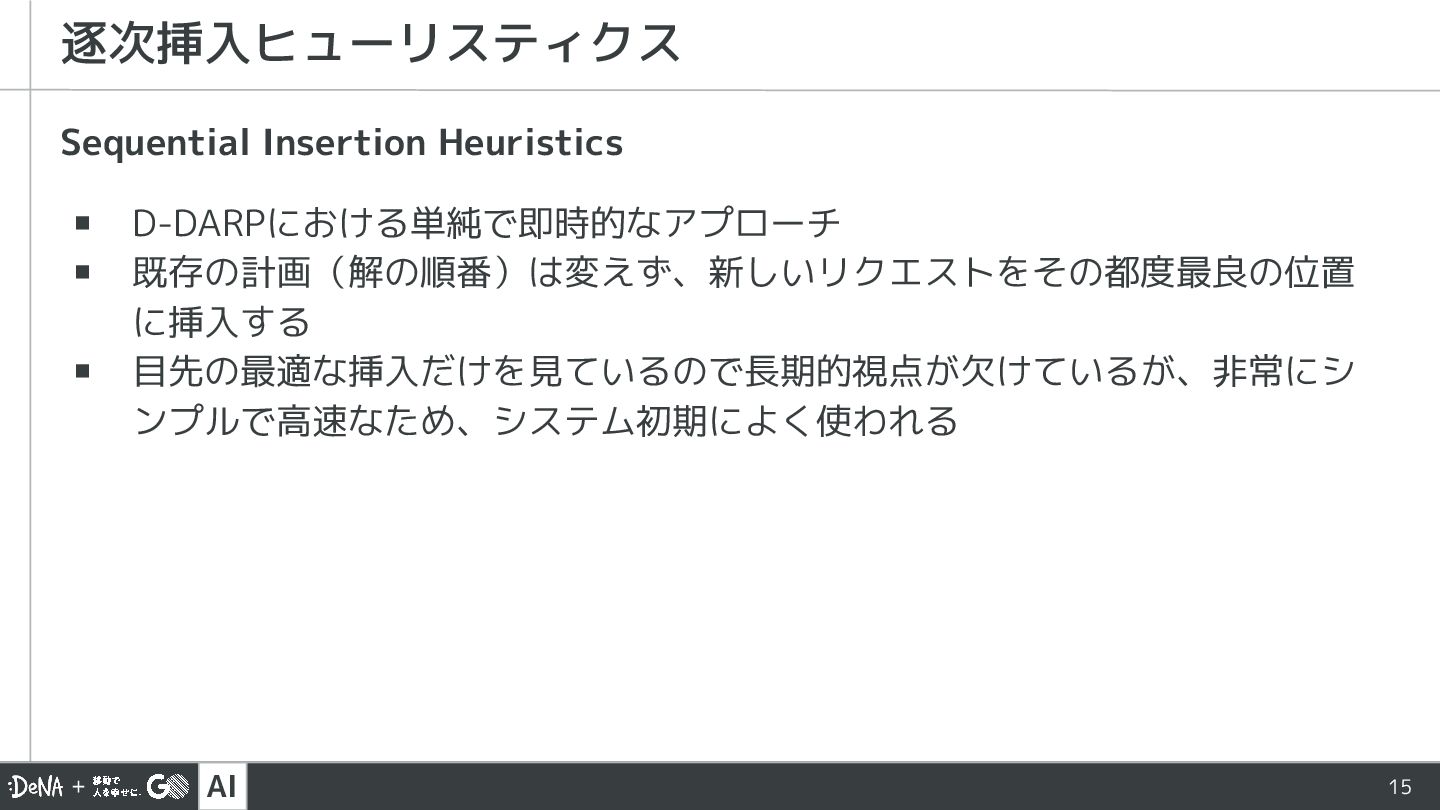
AI Sequential Insertion Heuristics ▪ D-DARPにおける単純で即時的なアプローチ ▪ 既存の計画(解の順番)は変えず、新しいリクエストをその都度最良の位置 に挿入する ▪
目先の最適な挿入だけを見ているので長期的視点が欠けているが、非常にシ ンプルで高速なため、システム初期によく使われる 逐次挿入ヒューリスティクス 15
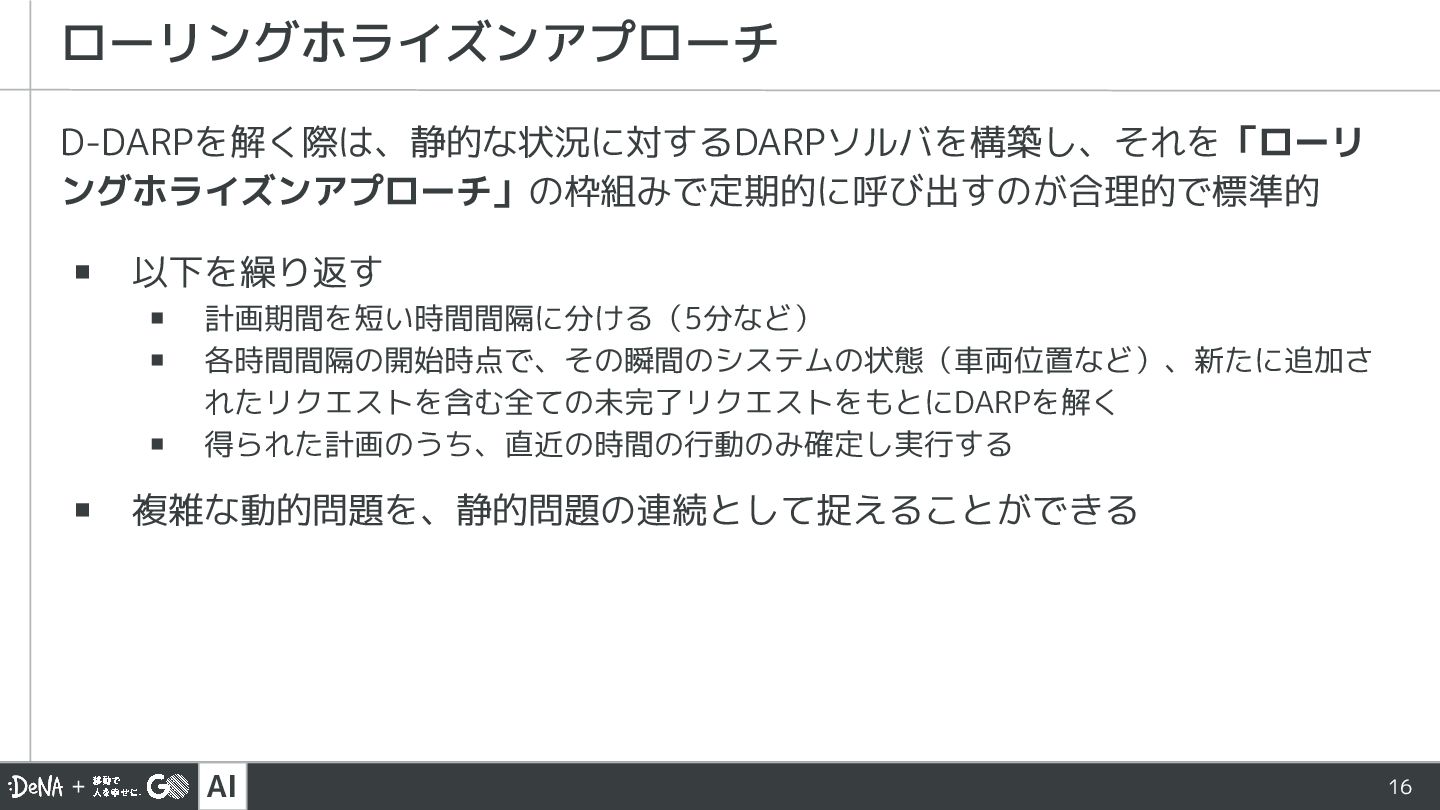
AI D-DARPを解く際は、静的な状況に対するDARPソルバを構築し、それを「ローリ ングホライズンアプローチ」の枠組みで定期的に呼び出すのが合理的で標準的 ▪ 以下を繰り返す ▪ 計画期間を短い時間間隔に分ける(5分など) ▪ 各時間間隔の開始時点で、その瞬間のシステムの状態(車両位置など)、新たに追加さ れたリクエストを含む全ての未完了リクエストをもとにDARPを解く
▪ 得られた計画のうち、直近の時間の行動のみ確定し実行する ▪ 複雑な動的問題を、静的問題の連続として捉えることができる ローリングホライズンアプローチ 16
AI 17 03 OR-Toolsによる実装
AI https://developers.google.com/optimization?hl=ja Googleが提供する最適化のためのライブラリ ▪ ルーティング問題 ▪ LNSベースにさらにヒューリスティクスを加えたGLS(Guided Local Search) が主に使われる
▪ GLS ▪ ペナルティを導入して局所最適解から抜け出せるようにしている ▪ 例えば、LNSの探索の中でコストが高い移動が頻繁に登場する場合、局所最適解 に陥っている可能性があるので、その高コストの移動に一時的にペナルティを課 すことで抜け出せるようになる OR-Tools 18
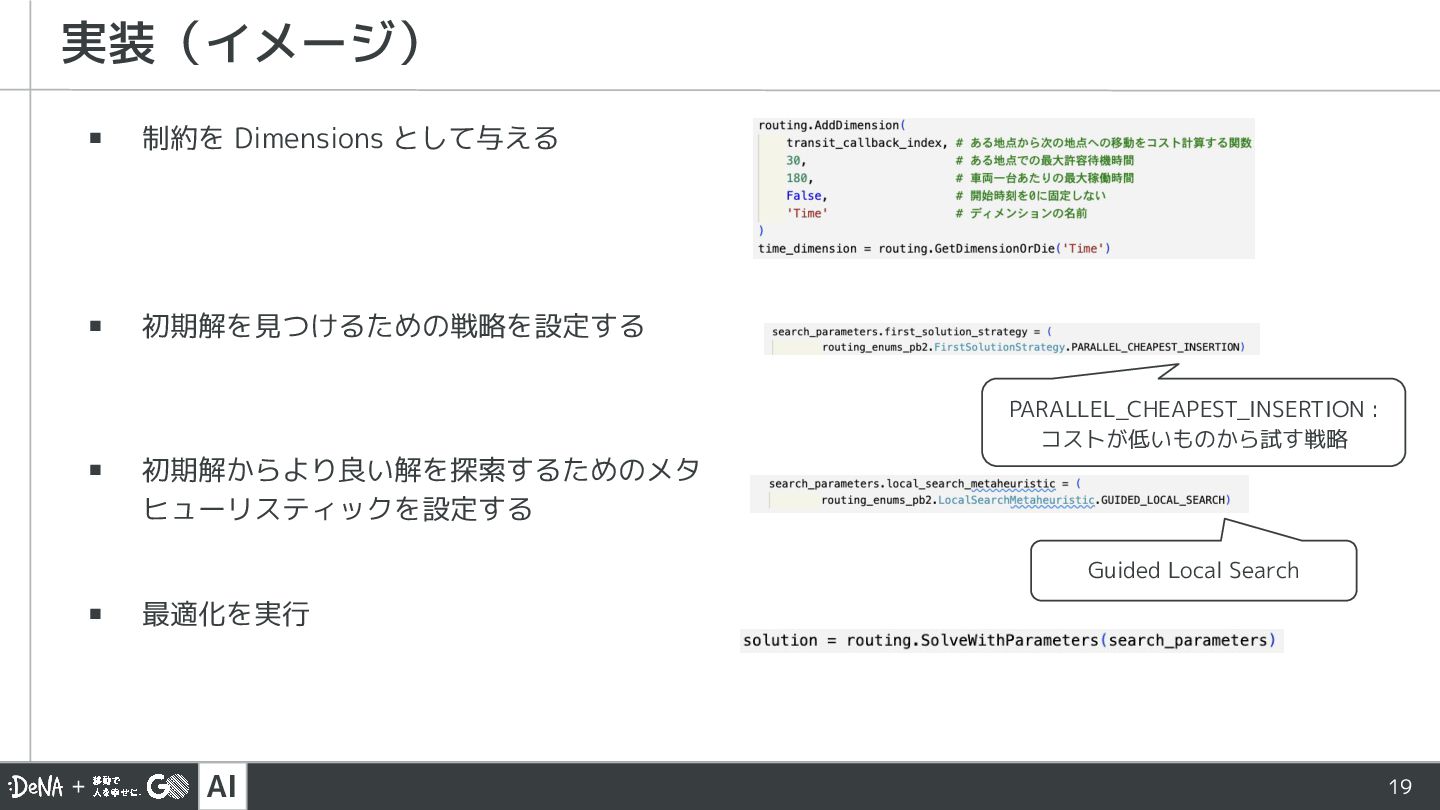
AI ▪ 制約を Dimensions として与える 実装(イメージ) PARALLEL_CHEAPEST_INSERTION : コストが低いものから試す戦略 ▪
初期解を見つけるための戦略を設定する ▪ 初期解からより良い解を探索するためのメタ ヒューリスティックを設定する ▪ 最適化を実行 Guided Local Search 19
AI 20 04 最新動向
AI ▪ 強化学習の活用 ▪ その都度最適化問題を解くのではなく、長期的な価値が最大になるような行動方針を学 習する ▪ 一度学習すれば意思決定が高速になる ▪ ヒューリスティクスの学習
▪ LNSなどの手法をより賢くする ▪ Learning-to-Delegate (MIT) ▪ https://news.mit.edu/2021/machine-learning-speeds-vehicle-routing-1210 ▪ どの部分問題を解けば最も解全体の質が向上するかを予測する ▪ GNNの活用 ▪ VRPはグラフ上の問題のため、ノード間の複雑な関係を捉えるために、グラフ構造を直 接扱うことができるGNNの活用が進んでいる ▪ LLMによるヒューリスティクス生成 機械学習の応用 21
AI ▪ 問題設定 ▪ 相乗りにおける最適化問題は乗客中心のサービス品質制約によって定義 されるDARP ▪ 解法 ▪ DARPの複雑性から、厳密解法は非現実的
▪ 高度なメタヒューリスティクスを用いる ▪ 実装ツール ▪ OR-Tools ▪ アーキテクチャ ▪ D-DARPに対しては、静的ソルバを中核に据えたローリングホライズン まとめ 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}