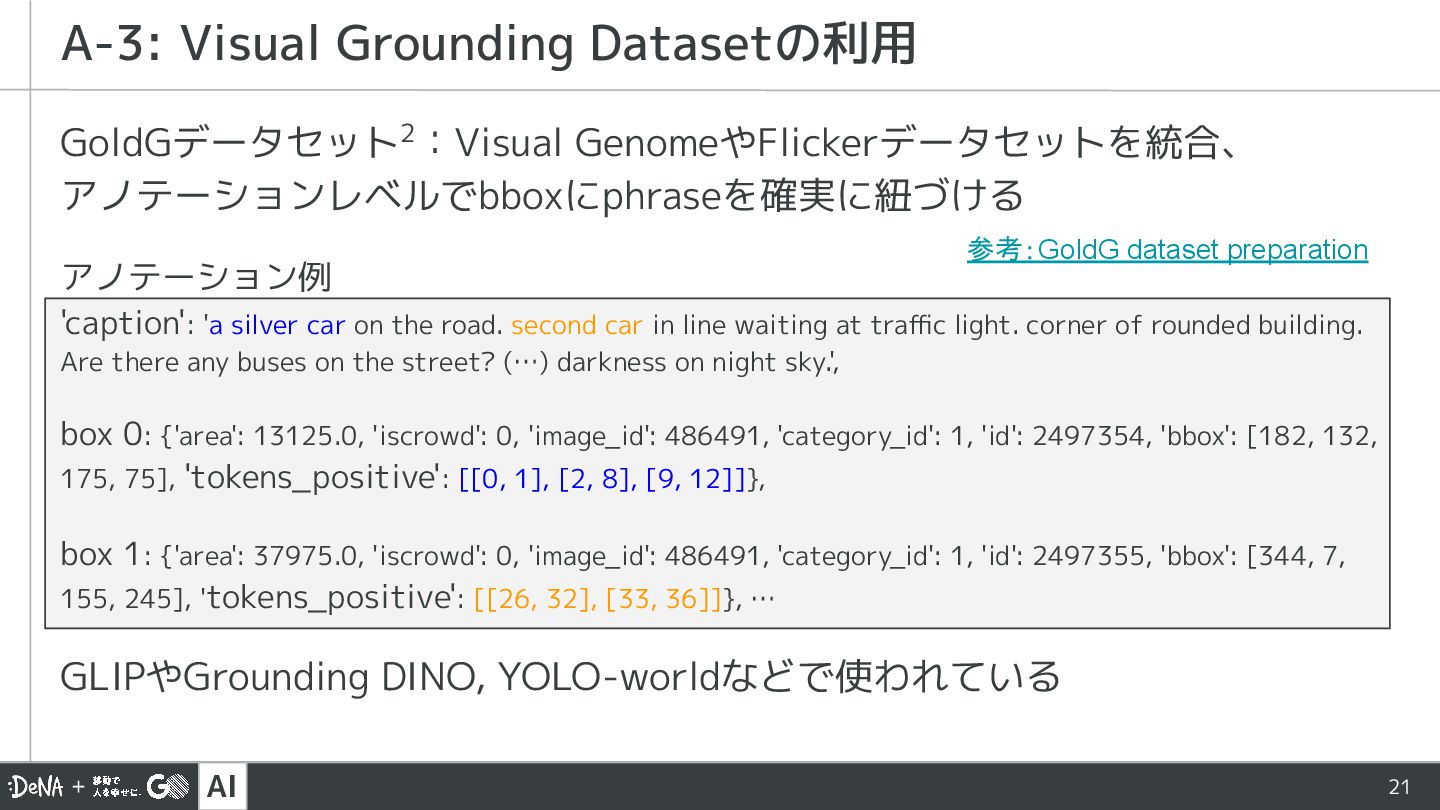
on the road. second car in line waiting at traffic light. corner of rounded building. Are there any buses on the street? (…) darkness on night sky.', box 0: {'area': 13125.0, 'iscrowd': 0, 'image_id': 486491, 'category_id': 1, 'id': 2497354, 'bbox': [182, 132, 175, 75], 'tokens_positive': [[0, 1], [2, 8], [9, 12]]}, box 1: {'area': 37975.0, 'iscrowd': 0, 'image_id': 486491, 'category_id': 1, 'id': 2497355, 'bbox': [344, 7, 155, 245], 'tokens_positive': [[26, 32], [33, 36]]}, … GLIPやGrounding DINO, YOLO-worldなどで使われている A-3: Visual Grounding Datasetの利用 参考:GoldG dataset preparation
{kind=link}
{kind=link}
{kind=link}
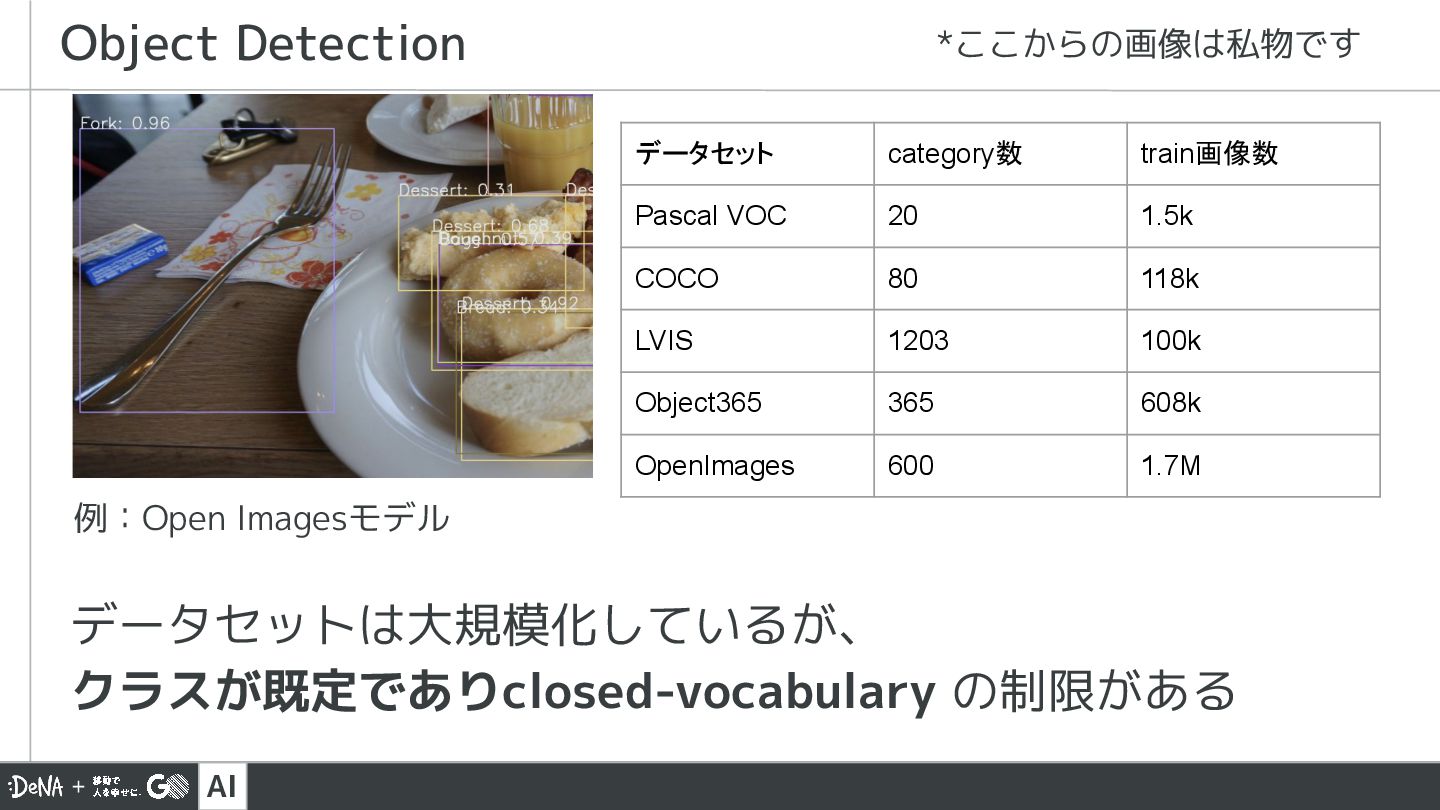
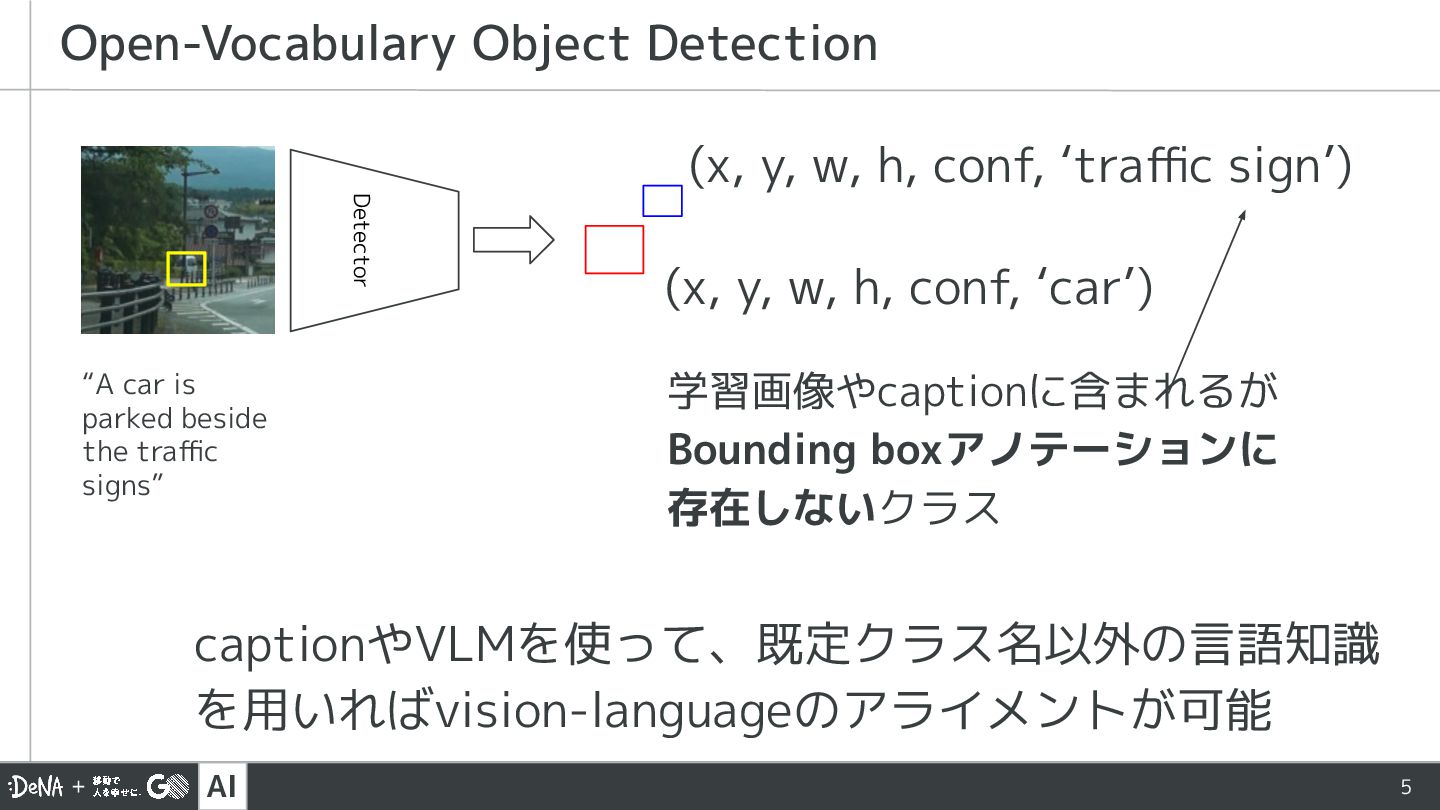
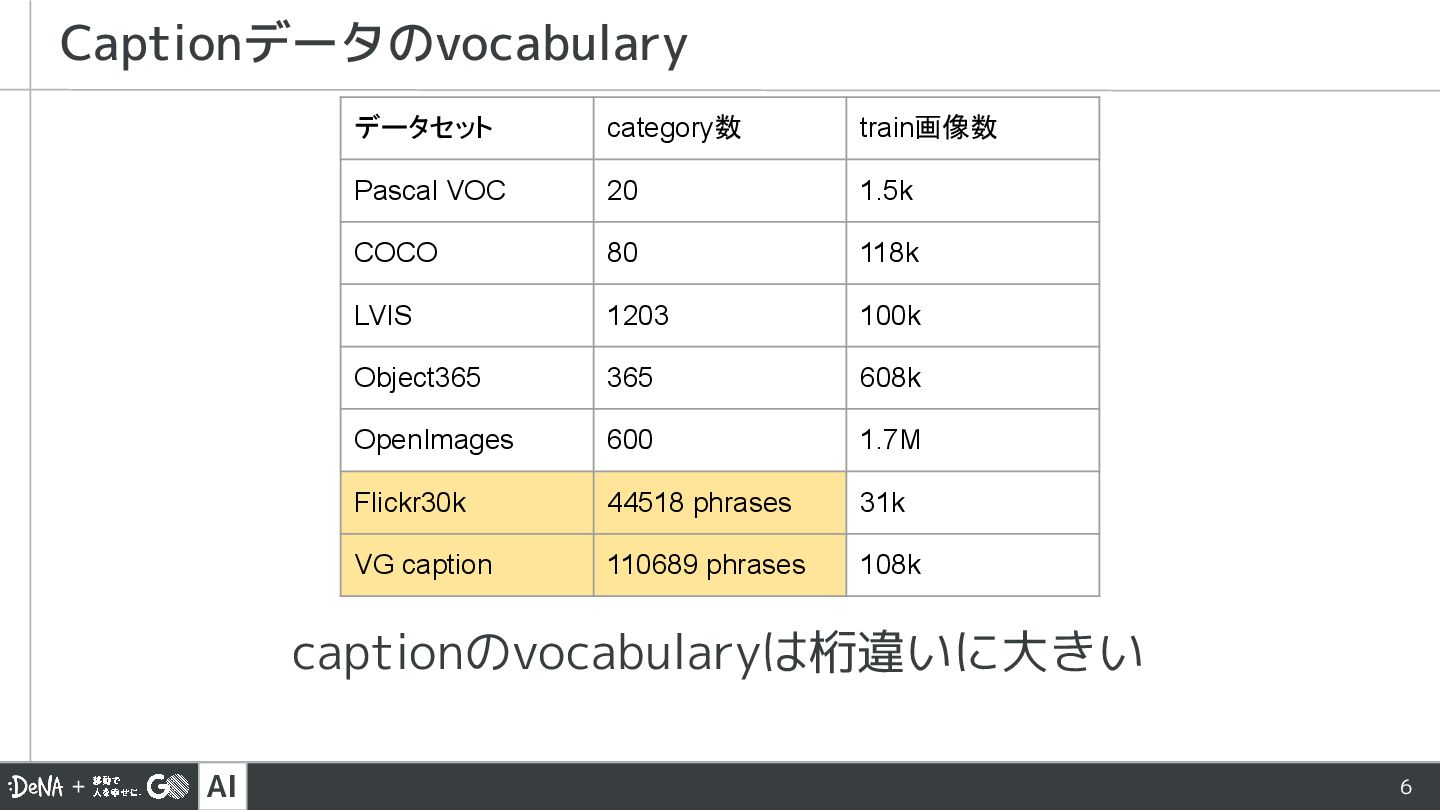
![AI 4 規定の80クラス [‘car’, ‘person’, …] 通常のObject Detection Detector (x,](https://files.speakerdeck.com/presentations/ef323c3d3e0d4d5cba12b057e09aa6cc/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
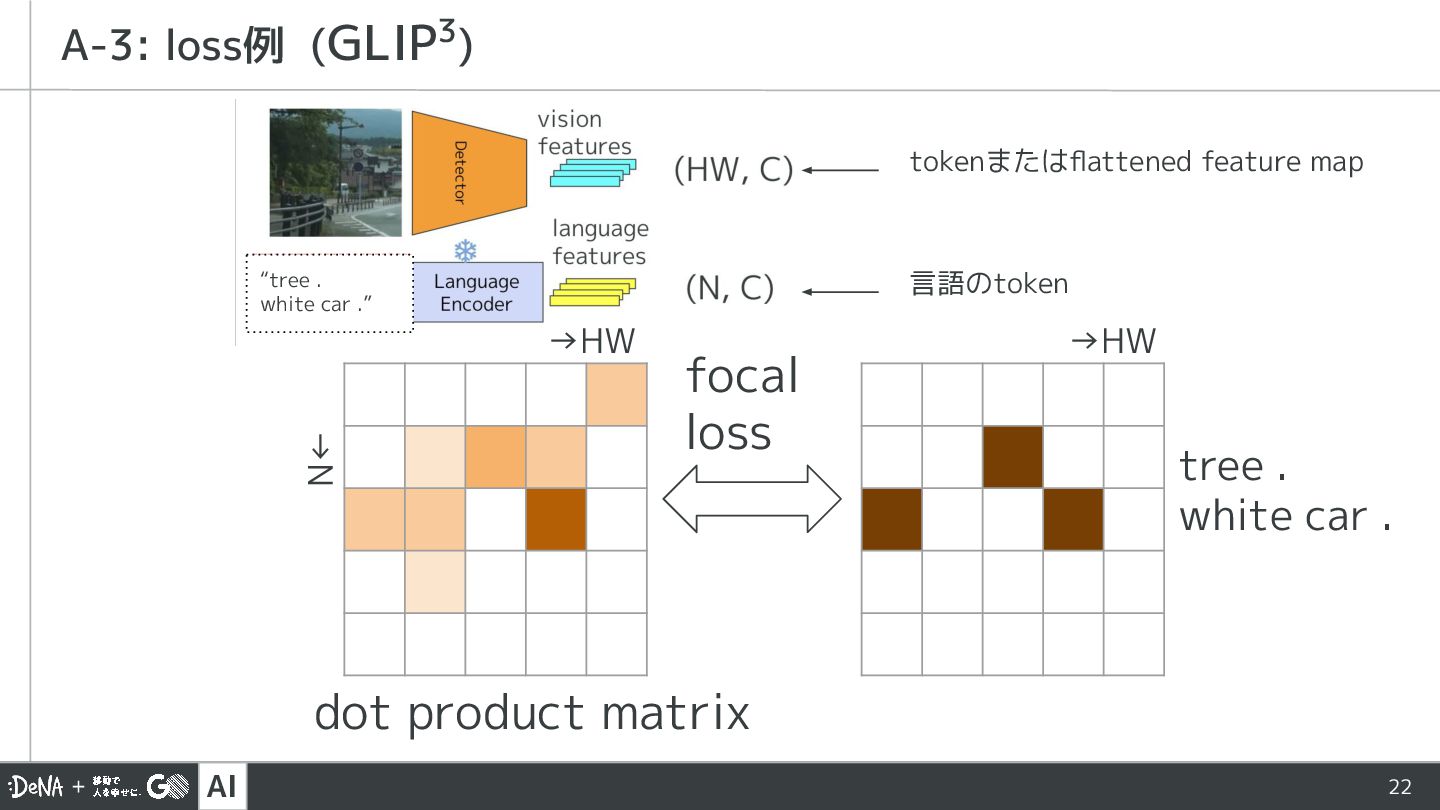{kind=link}
![AI 23 model ZOOの見方 例:mmdet3.3 [link] grounding DINO5 学習に使った データセット](https://files.speakerdeck.com/presentations/ef323c3d3e0d4d5cba12b057e09aa6cc/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}