Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
自分の学習データで画像生成AIを使ってみる話
Search
moyashi
June 08, 2024
Technology
980
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
自分の学習データで画像生成AIを使ってみる話
画像生成を手元データから追加学習。Stable Diffusionで使える LoRAを作成。ただ、キャラクターの学習は思っていたような結果にならなかった話。
moyashi
June 08, 2024
More Decks by moyashi
See All by moyashi
ポートを開けないVPN Tailscaleの話
moyashi
0
130
AWS SES VDMで 将来の配信事故を防げた話
moyashi
0
1.3k
順番待ちWebサービス 「MATENE」を 有料化した話と サービスを続けられた理由
moyashi
0
110
AIコーディングエージェントのはなし
moyashi
0
140
機械学習で画像を分類してみた話
moyashi
1
130
メールを受信トレイに届けよう - Gmailガイドラインの話
moyashi
3
900
Visual Studio Codeの使い方 基礎編
moyashi
0
150
プログラミング支援AI GitHub Copilot すごいの話
moyashi
0
5.1k
アナログ電話のナンバーディスプレイを安価にIT化する話
moyashi
1
240
Other Decks in Technology
See All in Technology
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.1k
AI時代の EM への処方箋
staka121
PRO
0
140
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
530
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
1
380
世界、断片、モデル。そして理解
ardbeg1958
1
110
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
180
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
620
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
100
Claude Code 珍プレー好プレー
shinyasaita
0
330
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
210
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.3k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
KATA
mclloyd
PRO
35
15k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Transcript
自分の学習データで 画像生成AIを 使ってみる話 2024/06/08 伊勢IT交流会
もやし工房 石黒 光茂 @koike_moyashi mitsushige.ishiguro もやし工房
画像生成 色々ある ChatGPT(DALL-E) Bing Image Creator Midjourney Adobe Firefly その他
色々
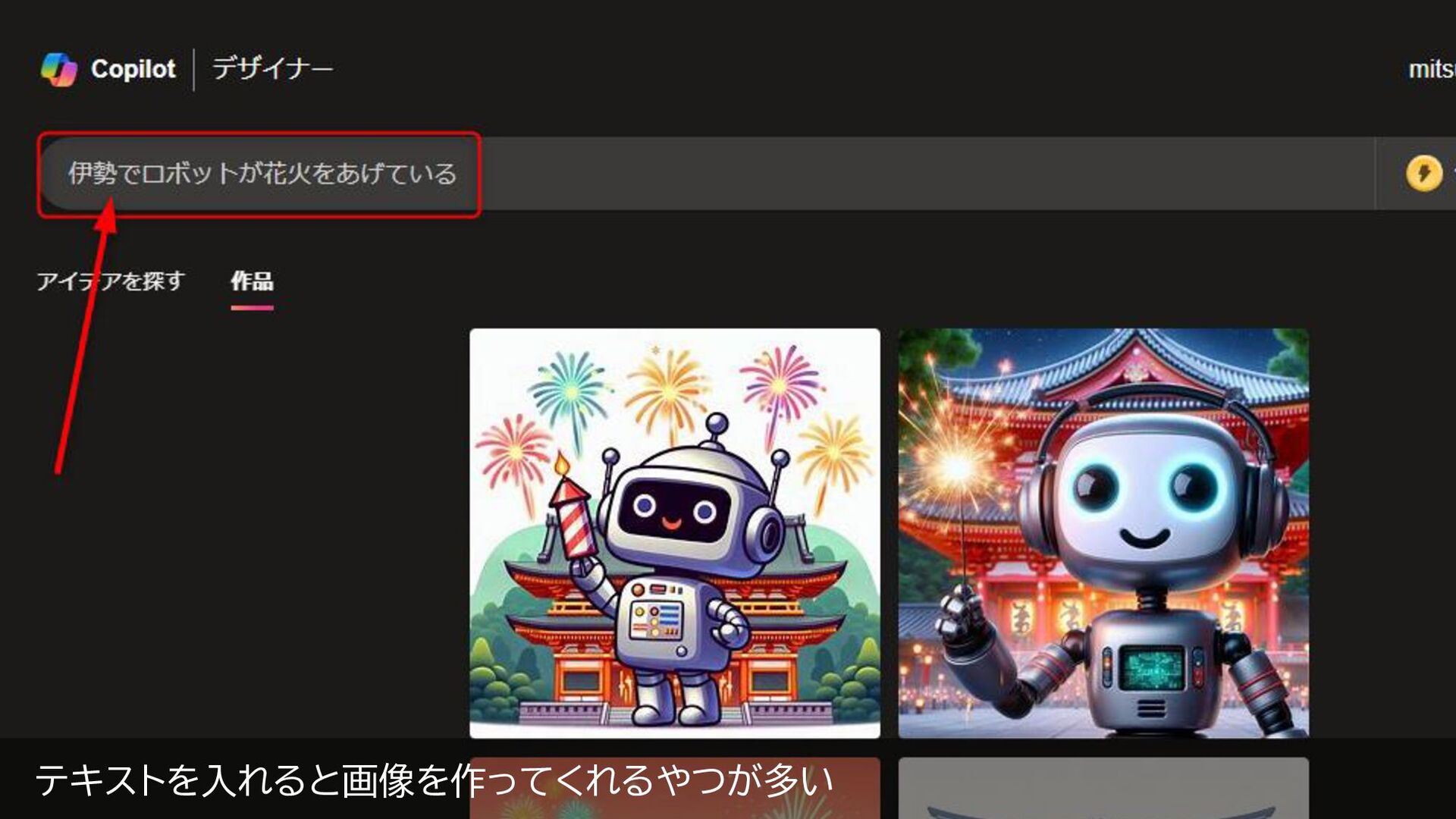
テキストを入れると画像を作ってくれるやつが多い
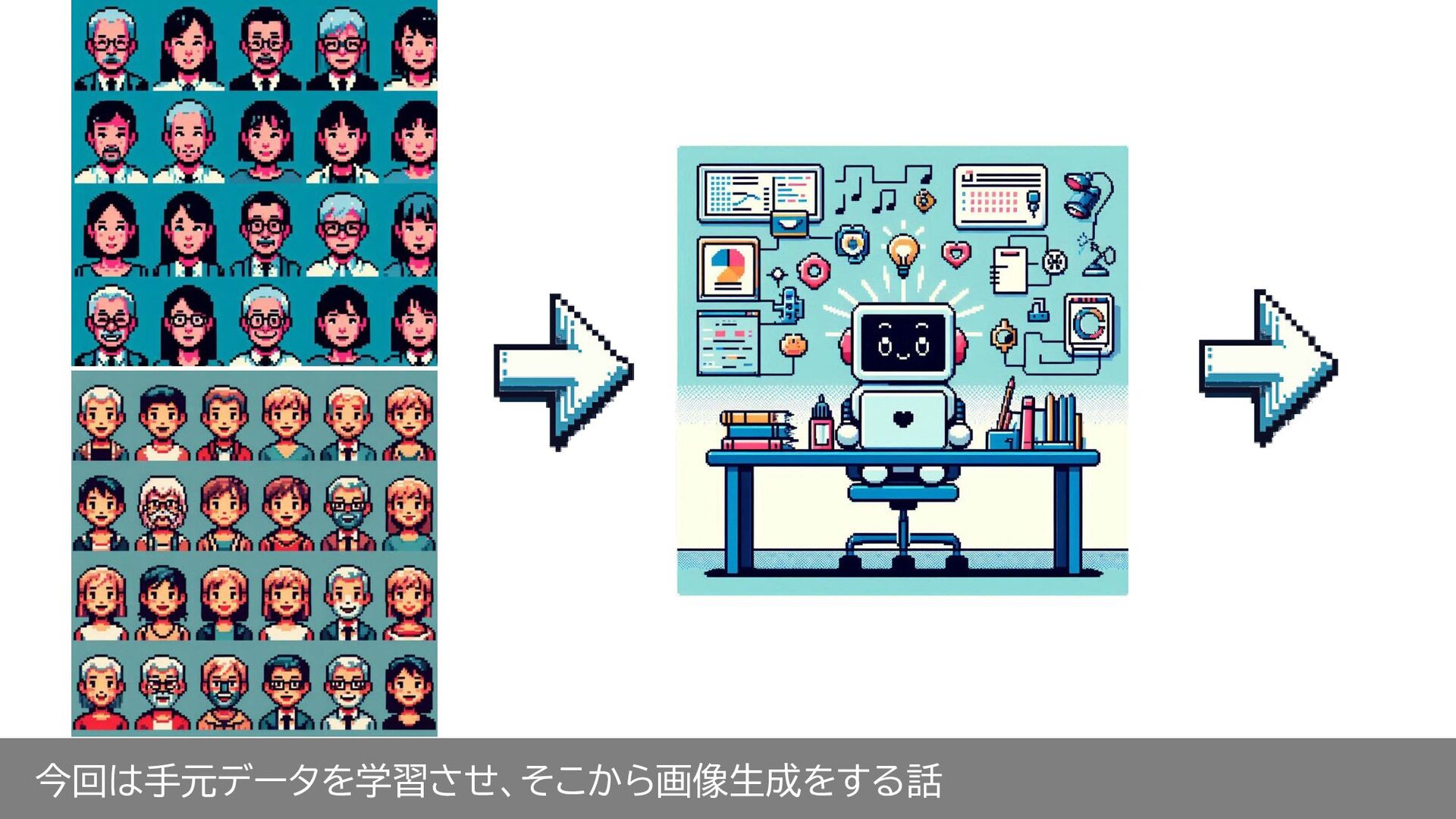
今回は手元データを学習させ、そこから画像生成をする話
きっかけ → 昨年グラフィックボード(ゲーム用ではない)を買った → 使い道がない
ローカルPCでの画像生成と言えば... Stable Diffusion “イオン”の本屋さんでも1、2冊は本が置いてあるくらいメジャー! オープンソース。無料、商用利用も可能。 Pythonベースで、Windows、Linux、MacOSで動く。
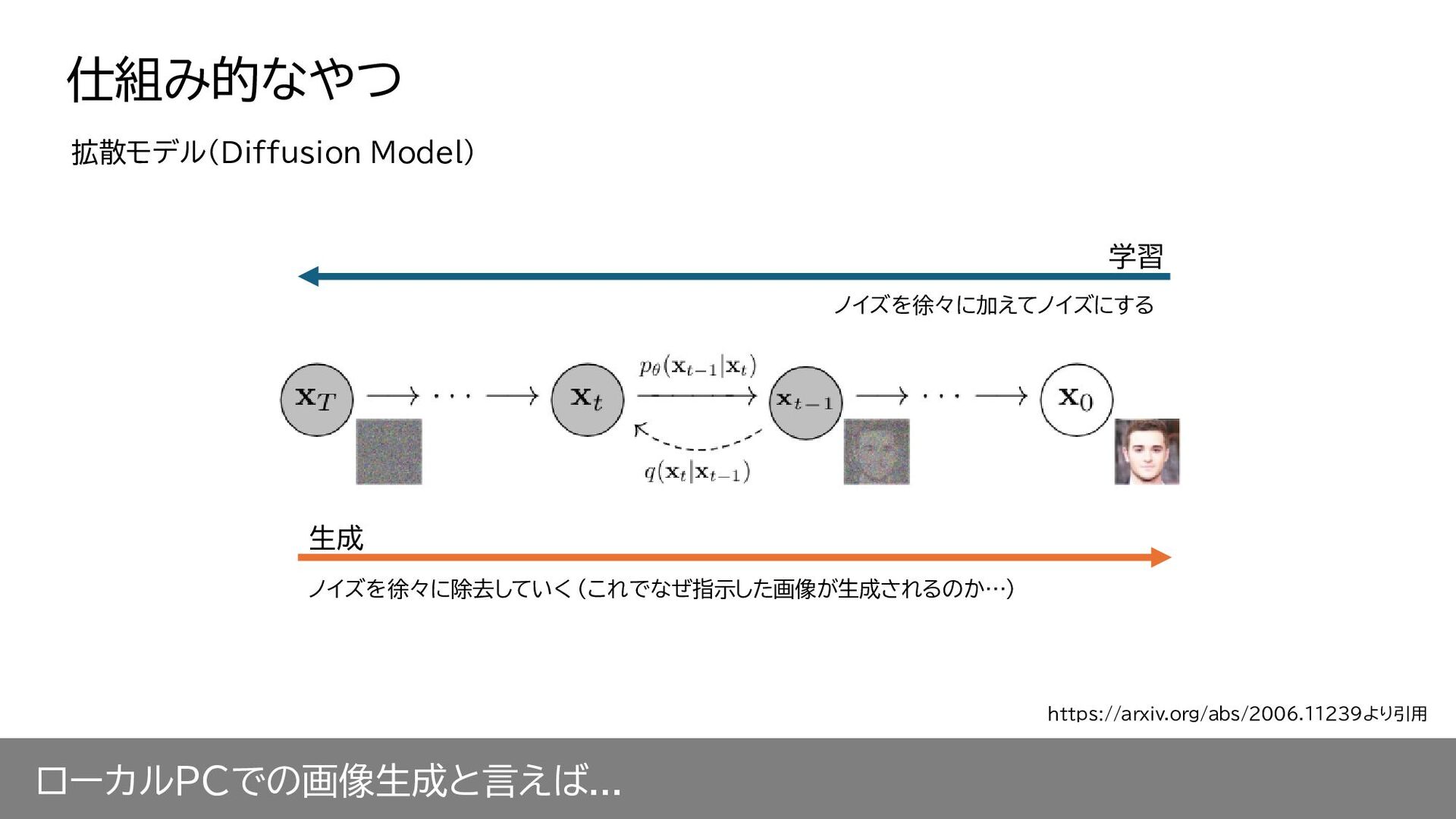
ローカルPCでの画像生成と言えば... 生成 学習 ノイズを徐々に加えてノイズにする ノイズを徐々に除去していく (これでなぜ指示した画像が生成されるのか…) 拡散モデル(Diffusion Model) 仕組み的なやつ https://arxiv.org/abs/2006.11239より引用
ローカルPCでの画像生成と言えば... 生成 学習 ノイズを徐々に加えてノイズにする ノイズを徐々に除去していく (これでなぜ指示した画像が生成されるのか…) 拡散モデル(Diffusion Model) 仕組み的なやつ https://arxiv.org/abs/2006.11
239 なんだか良く分からないけど すごい!
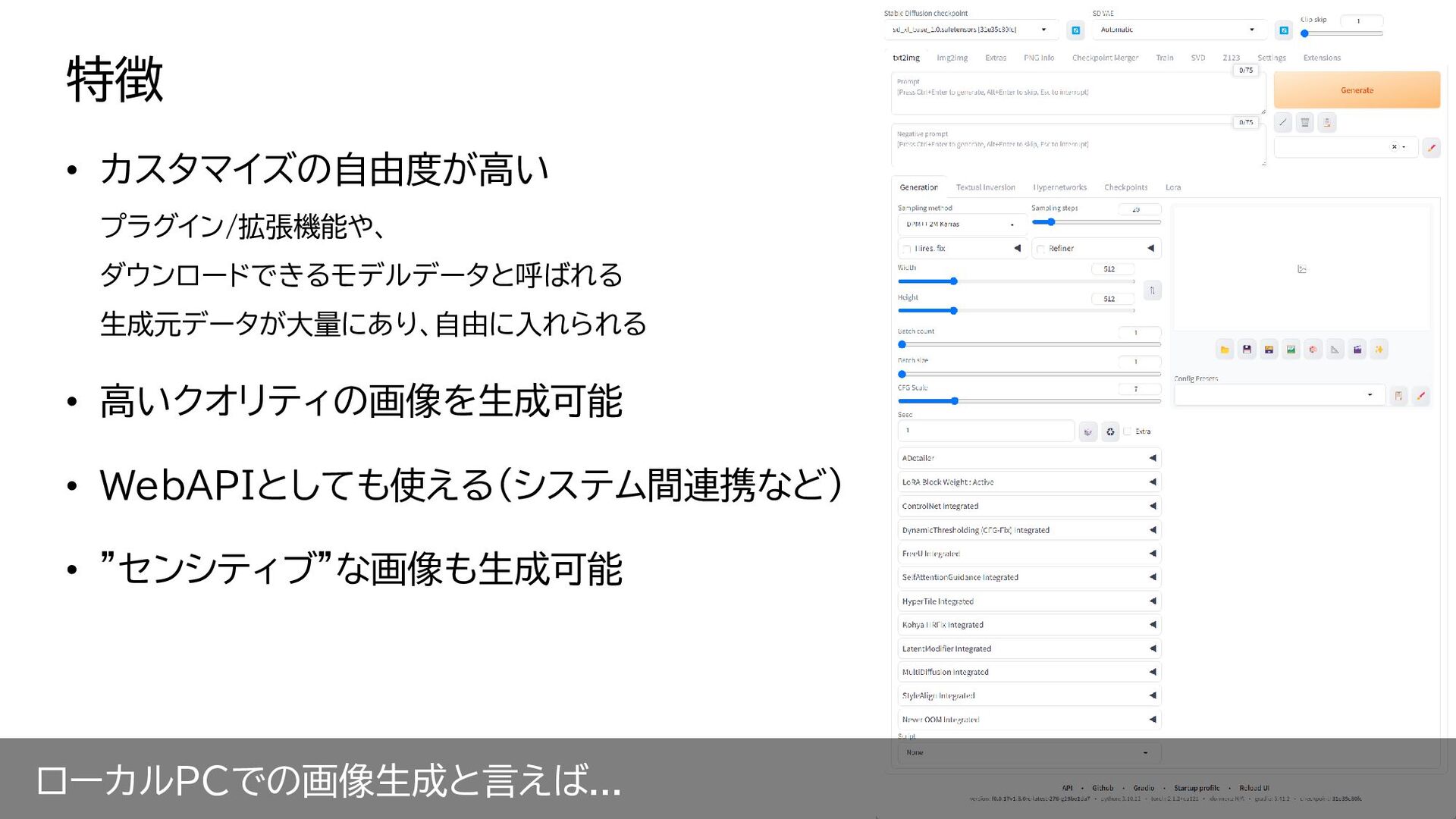
ローカルPCでの画像生成と言えば... • カスタマイズの自由度が高い プラグイン/拡張機能や、 ダウンロードできるモデルデータと呼ばれる 生成元データが大量にあり、自由に入れられる • 高いクオリティの画像を生成可能 • WebAPIとしても使える(システム間連携など)
• ”センシティブ”な画像も生成可能 特徴
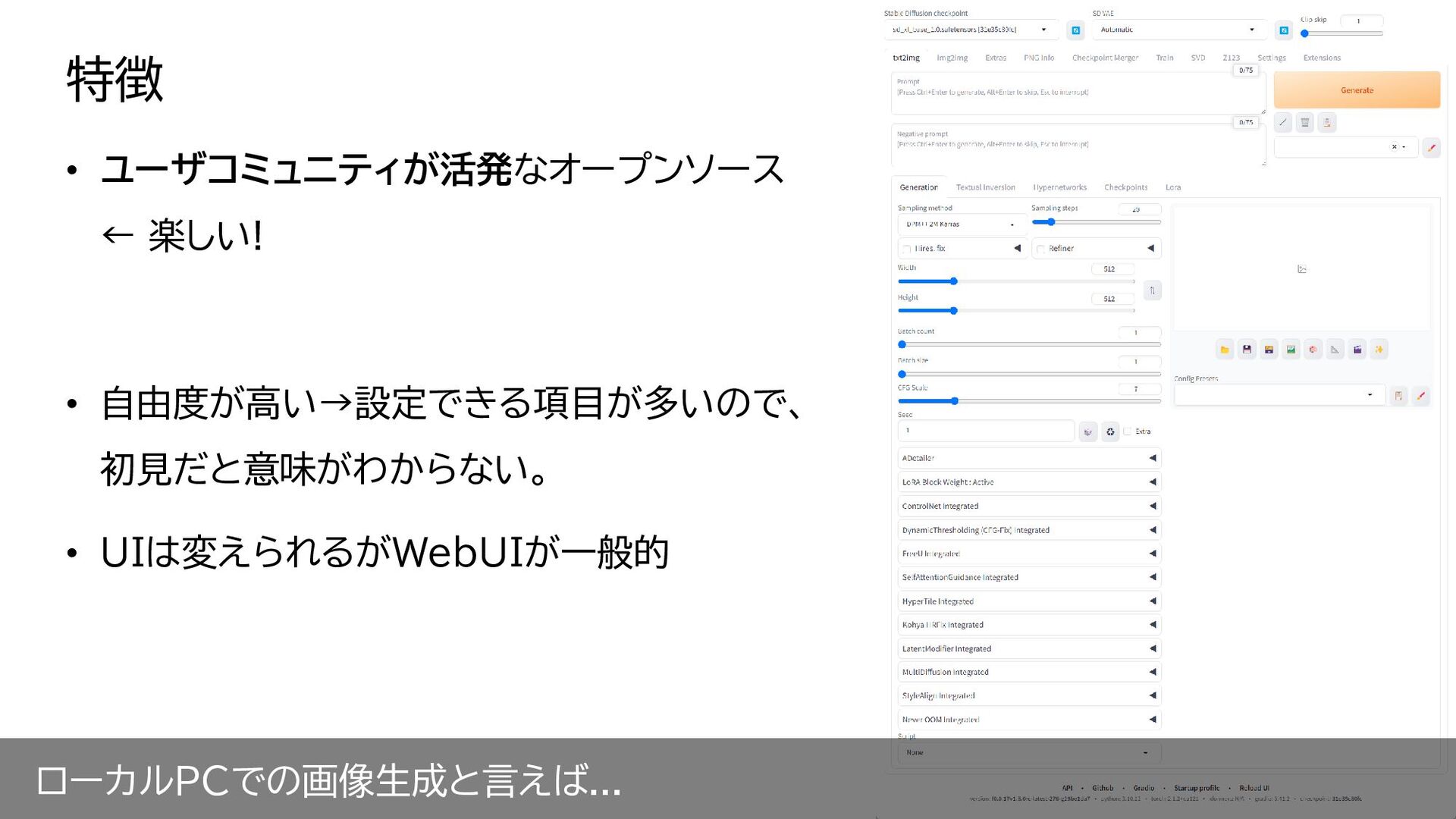
ローカルPCでの画像生成と言えば... • ユーザコミュニティが活発なオープンソース ← 楽しい! 特徴
ローカルPCでの画像生成と言えば... • ユーザコミュニティが活発なオープンソース ← 楽しい! • 自由度が高い→設定できる項目が多いので、 初見だと意味がわからない。 • UIは変えられるがWebUIが一般的
特徴
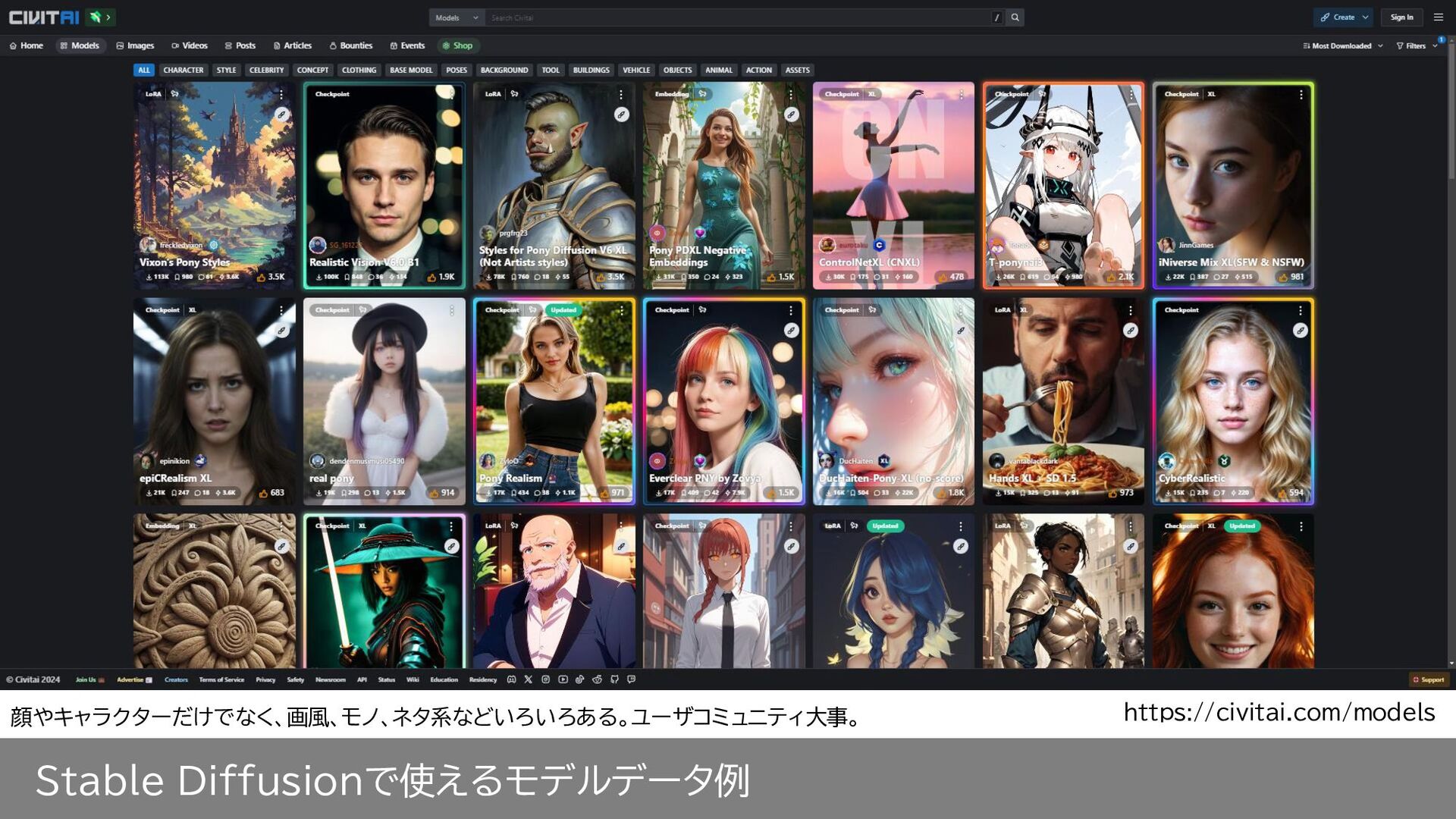
Stable Diffusionで使えるモデルデータ例 https://civitai.com/models 顔やキャラクターだけでなく、画風、モノ、ネタ系などいろいろある。ユーザコミュニティ大事。
動かし方 • ストレージはちょっと大きいほうが良い • 1モデルデータで3~5GBとか • ビデオメモリは大きければ大きいほど楽 • OSにそのまま Python(venv)
• Windows: WSL 2 + docker (今回はこれ) • Google Colab (Pro) 、専用サービスなど 動かし方
どんな事ができるか? • テキストから画像を作成 text2img • 画像から画像を作成 img2img 元の画像をベースに新たに描く ポーズ指定 一部だけ◯◯
• 追加学習データを使う • 拡張機能を使って、その他色々
画像から画像を作成(元の画像をベースに新たに描く)
画像から画像を作成(ポーズ指定) プロンプトだけでは指定が難しいポーズを指定できる。写真のポーズをイラストに反映したりとかにも使える。
追加学習データを使う これが本題 手元のデータを使って、オリジナルのキャラクターを出したり、 特定の顔の写真を生成できる
学習データ作成は大きく分けて2種類 • データの大元のモデルデータと言うのを作る →すごく時間がかかる&VRAMも沢山必要 &学習させる枚数も多い。大変(らしい) • モデルデータを利用して追加学習データを作る →今回はこれ。 追加学習の方法は何種類かある。 現在ちょうど良いバランス(情報も多い)なのが、
LoRA(Low-Rank Adaptation)と言う手法。
追加学習(LoRA) 顔やイラストそのものだけでは無く、色々なことを学習できる。 色合い、画風、光具合、などなど • イラストならイラストのモデル、 人間なら人間のモデルデータを元に作る(元学習データに挟み込む) • 高いクオリティの元モデル + 独自の(顔、キャラクター、色合い、画風、などなど)
→ 高いクオリティの独自の(顔、キャラクター、色合い、画風、などなど)が作れる
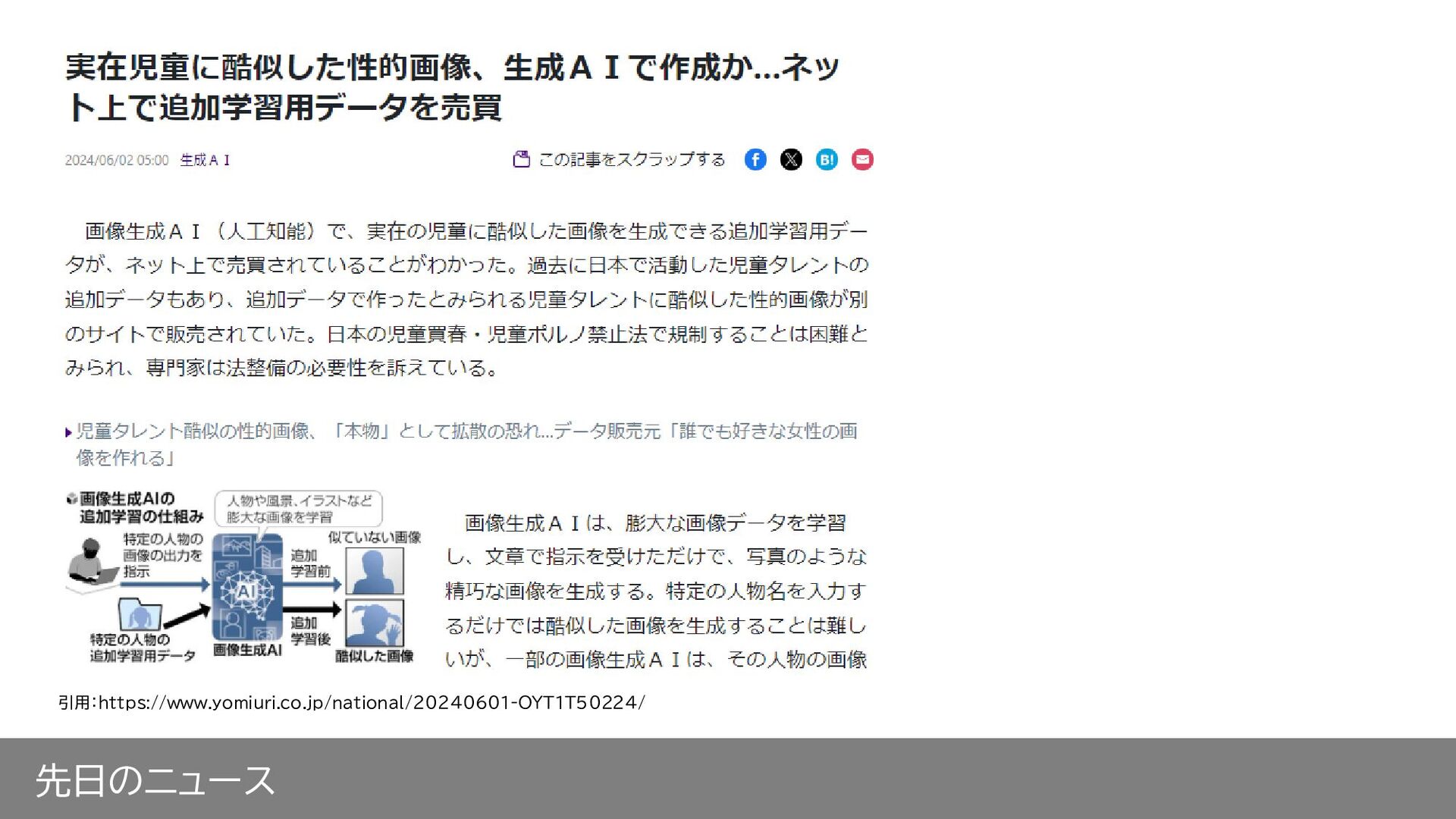
先日のニュース 引用:https://www.yomiuri.co.jp/national/20240601-OYT1T50224/
追加学習の大きな流れ (同じような顔、キャラクターを作る場合) 1.元データ(画像)を用意 (場合よっては面倒) 2.いい感じに加工 (面倒くさい) 3.1枚1枚にキャプションを付ける (自動) 4.キャプションの編集 (面倒くさい)
5.学習させる (やや時間かかる) 6.学習結果を使う
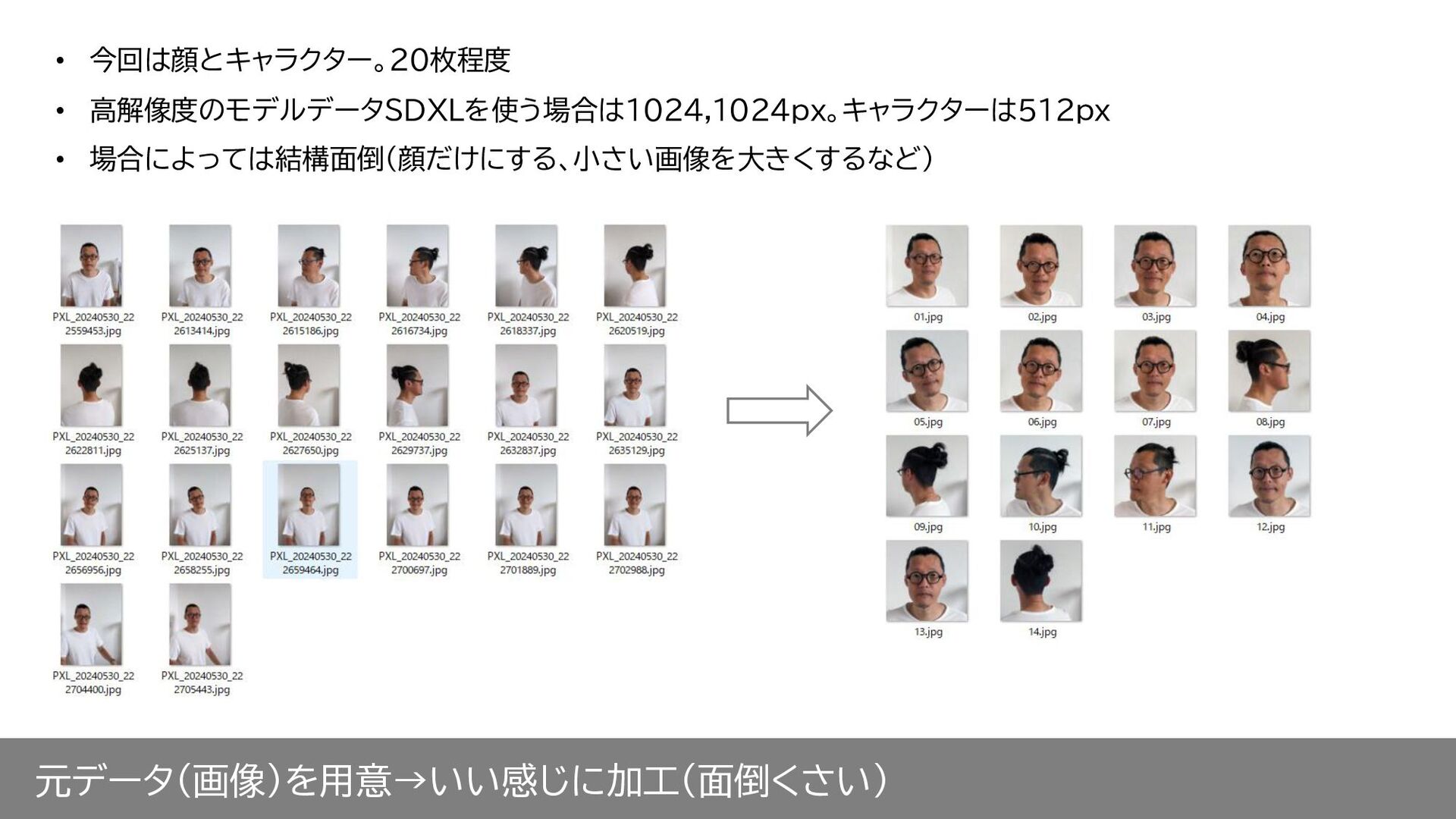
元データ(画像)を用意→いい感じに加工(面倒くさい) • 今回は顔とキャラクター。20枚程度 • 高解像度のモデルデータSDXLを使う場合は1024px。キャラクターはSD1.5 512px。 • 場合によっては結構面倒(顔だけにする、小さい画像を大きくするなど)
元データ(画像)を用意 • 三重のおやつと言えば • マスヤの方に、キャラクターのラフ案みたいなのを AIに書かせることができないか?と言う話を聞いていた。 • 学習用データを提供していただいた ※ このスライドを公開する事も許可をいただいています
元データ(画像)を用意→いい感じに加工(面倒くさい) • 今回は顔とキャラクター。20枚程度 • 高解像度のモデルデータSDXLを使う場合は1024,1024px。キャラクターは512px • 場合によっては結構面倒(顔だけにする、小さい画像を大きくするなど)
1枚1枚にキャプションを付ける • 1枚1枚にキャプションと呼ばれる説明書きをつける • 手で書いても良いけど面倒なのでAIにやらせて、後で直す • 画像の内容を短文で説明してくれる。すごい。 • cartoon style,
• a happy smiling yellow triangle character with red cheeks, • making peace signs with both hands, • vector art 「画像について、Stable Diffusion のプロンプト風に説明してください。 出力は英語のテキストのみにしてください。」
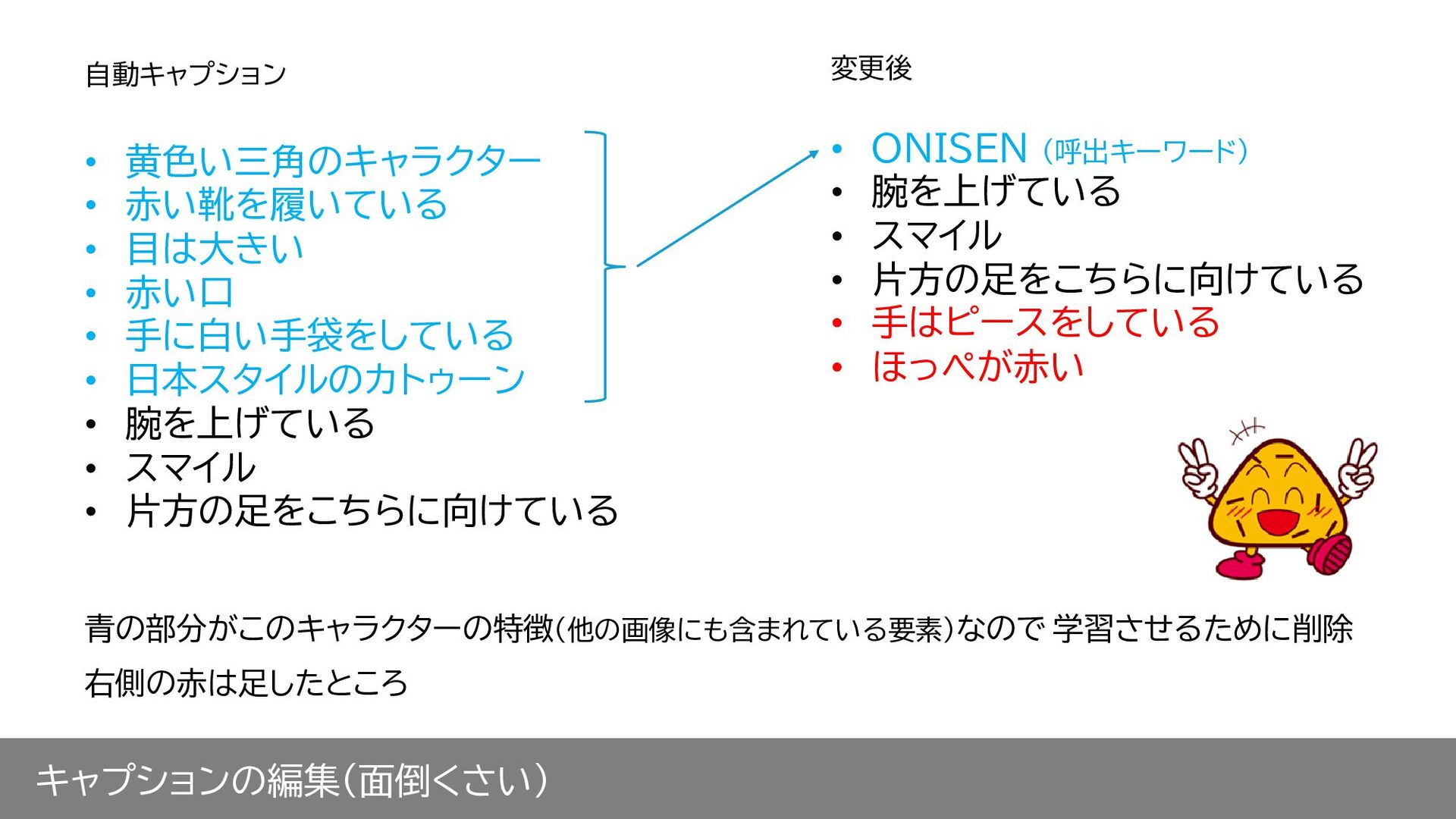
キャプションの編集(面倒くさい) ここから、 • このキャラクターを表している 「イラスト調、黄色の三角、足が赤い、手が白色」 などを削除して、独自の呼出キーワードを加える • AIが独自の呼出キーワードを 「イラスト調、黄色の三角、足が赤い、手が白色 」と認識してくれる
• かなり面倒
キャプションの編集(面倒くさい) • 黄色い三角のキャラクター • 赤い靴を履いている • 目は大きい • 赤い口 •
手に白い手袋をしている • 日本スタイルのカトゥーン • 腕を上げている • スマイル • 片方の足をこちらに向けている • ONISEN (呼出キーワード) • 腕を上げている • スマイル • 片方の足をこちらに向けている • 手はピースをしている • ほっぺが赤い 自動キャプション 変更後 青の部分がこのキャラクターの特徴(他の画像にも含まれている要素)なので 学習させるために削除 右側の赤は足したところ
学習させる(時間かかる) • キャラクターは15分程度 • 高解像度の顔は2時間程度 • グラフィックボードの性能によって早さは変わる • 何やかや難しいパラメータが沢山ある •
GPUメモリをあふれさせると、PCのメモリを使う→すごく遅くなる • 設定箇所が多く、調整が難しくて未だによくわからない
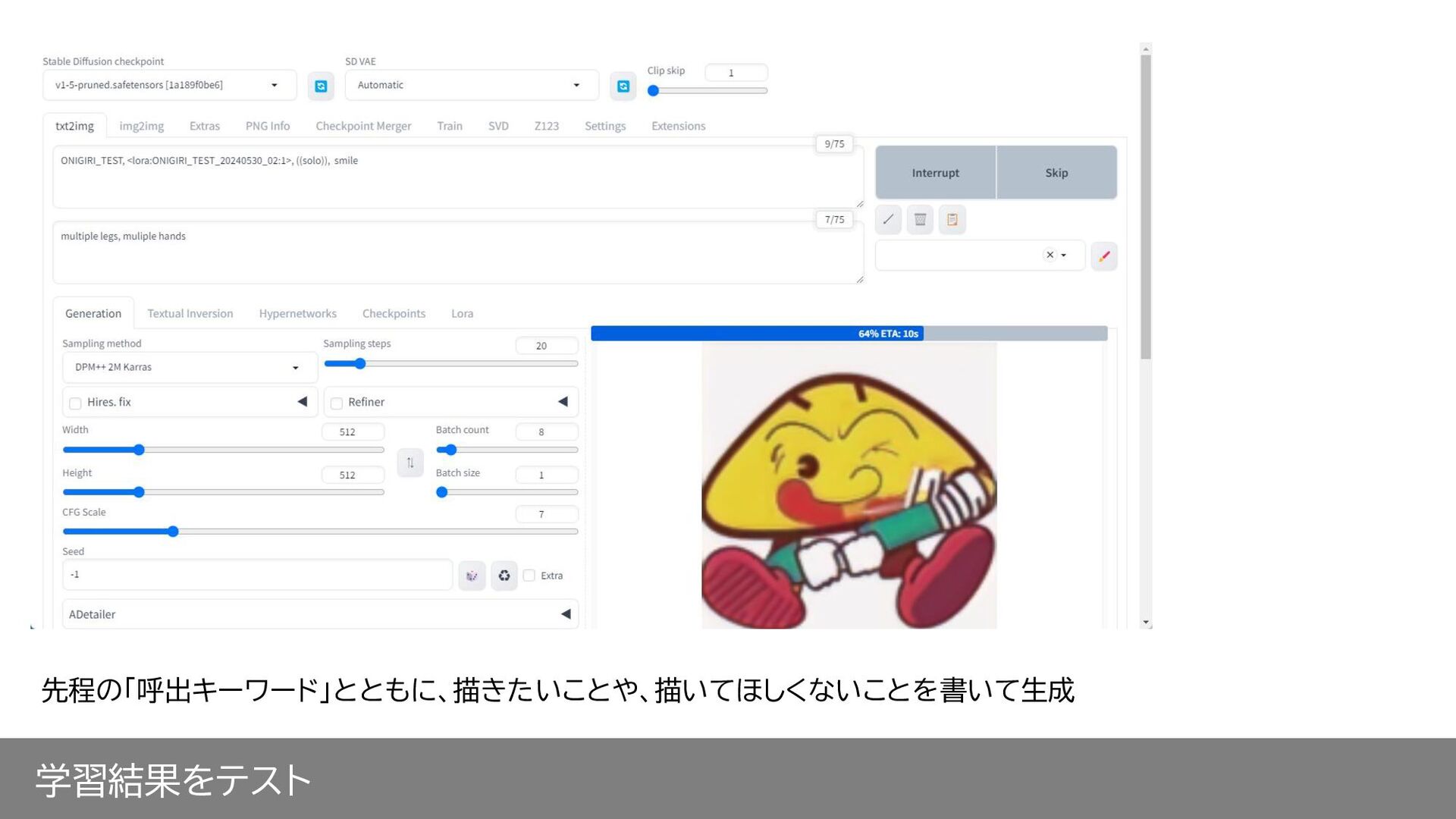
学習結果をテスト 先程の「呼出キーワード」とともに、描きたいことや、描いてほしくないことを書いて生成
繰り返す 1回では上手く行かないので、上記を色々変えながら繰り返す 青の部分を学習しすぎた? 学習データを少なくしすぎた? コツがわからない。ネットを見てるといい 感じに作ってるので、私の実力不足かと… 顔データは比較的簡単にできたけど、キャラクターは難しかった。 元データ
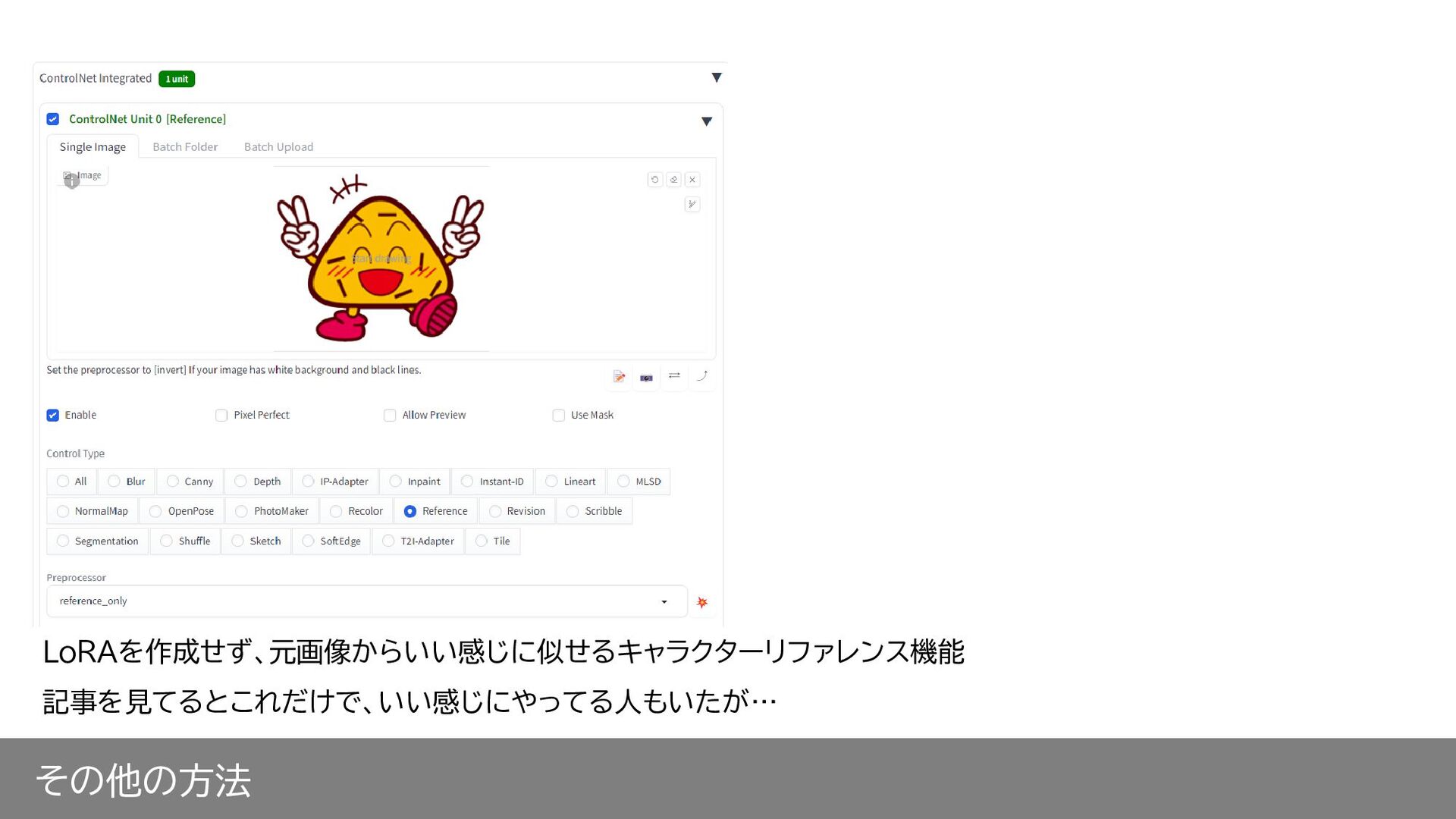
その他の方法 LoRAを作成せず、元画像からいい感じに似せるキャラクターリファレンス機能 記事を見てるとこれだけで、いい感じにやってる人もいたが…
雑感 • AIに学習させる行為そのものは楽しいが、 試行錯誤はあまり自動化できず、かなり時間かかる。経験? • ネットの記事を見てると簡単そうだけど、そこまで上手く行かなかった。 聞いたこと無い用語が多く、内容が想像できない。経験・知識不足。 • この技術をお金に変える方法は 分からない
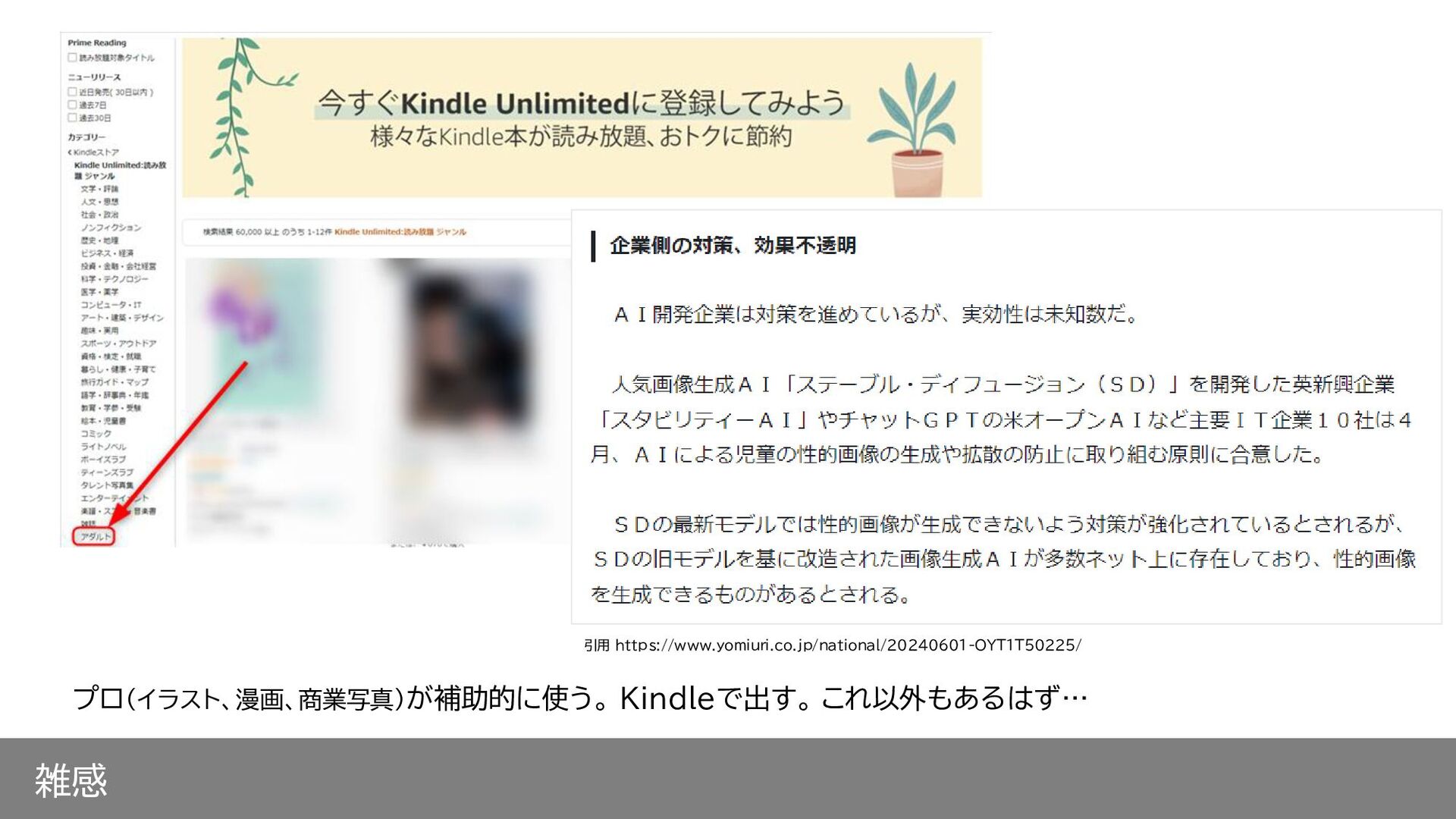
雑感 プロ(イラスト、漫画、商業写真)が補助的に使う。 Kindleで出す。 これ以外もあるはず… 引用 https://www.yomiuri.co.jp/national/20240601-OYT1T50225/
雑感 • 自分の顔のモデルデータは実験には使いづらい 気軽にいつもしてない服装とかが楽しめるが、使い道は思いつかない • 進歩が早く(経験不足もあり) できてくるデータに気まぐれ感があるので、 クライアントワークでは怖くてできない • 数ヶ月後にはもっと簡単に良い感じのものができてそう
参考 Stable Diffusion本体 Stable Diffusion WebUI https://github.com/AUTOMATIC1111/stable-diffusion-webui Stable Diffusion WebUI
Docker https://github.com/AbdBarho/stable-diffusion-webui-docker Stable Diffusion WebUI Forge https://github.com/lllyasviel/stable-diffusion-webui-forge LoRA作成 Kohya's GUI https://github.com/bmaltais/kohya_ss キャラクター (結局うまく行ってない) 元モデル: runwayml/stable-diffusion-v1-5 繰り返し:10 Epoch:25 枚数:20 Optimizer: Adafactor 写真 元モデル: stabilityai/stable-diffusion-xl-base-1.0 繰り返し:10 Epoch:25 枚数:20 Optimizer: Adafactor
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}