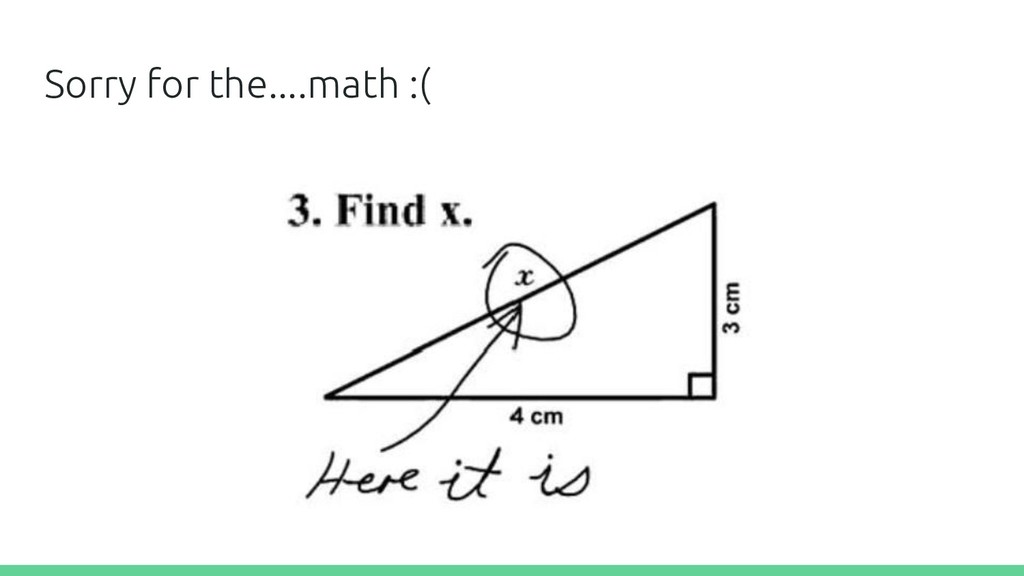
technical context without boiling the ocean. In other words, this is a very, very high level overview of a topic where each slide can easily be a session on it’s own.
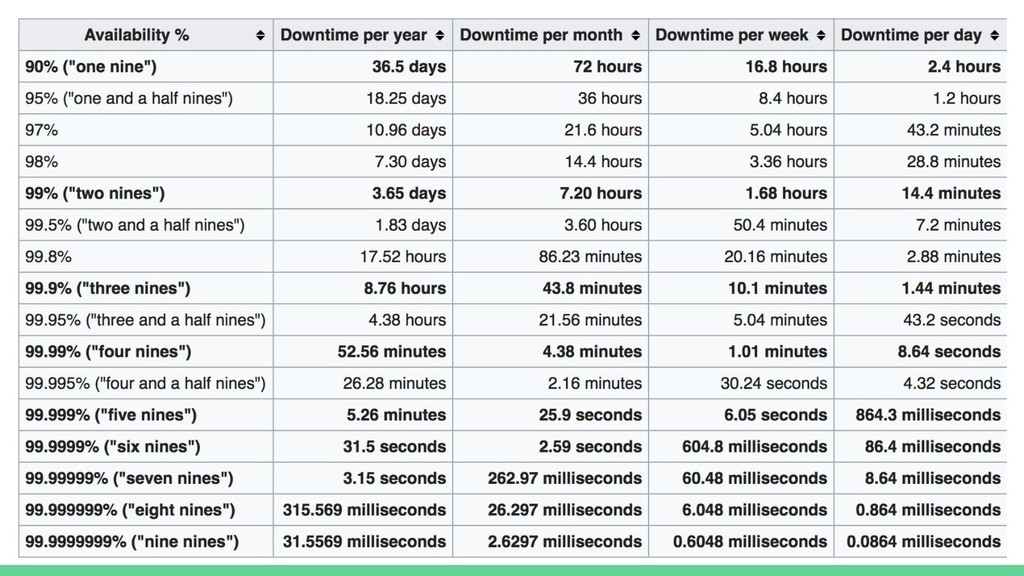
in a usable state. Also measured in 9s. Scheduled downtimes do not count towards availability, but may impact customer satisfaction metrics (more so in a B2C model).
in a usable state for a period of time. Mean Time to Failure (MTTF) Mean Time to Repair (MTTR) Mean Time between Failures (MTBF) Mostly used for hardware such as Network/IO controllers, power supplies, etc.
and resiliency planning) is the process of creating systems of prevention and recovery to deal with potential threats to a company.” - Wikipedia Usually owned and managed by the COO
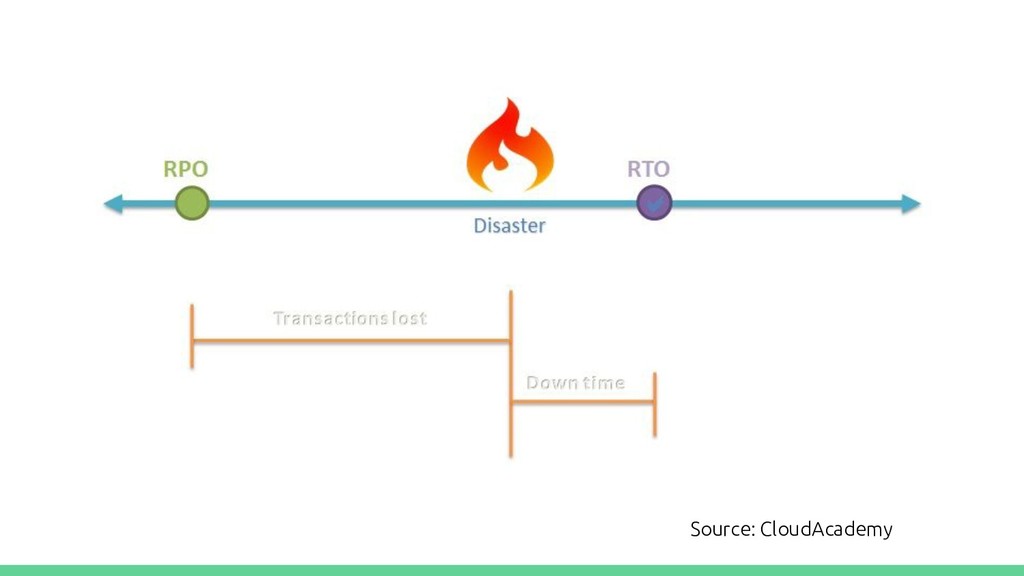
must have (good) backups of data no older than 4 hours. Think about your laptop. How much far back in time you can go where any data loss beyond that time is tolerable?
the last backup that was done 4 hours ago, then RTO is >= 2 hours, and RPO is >= 4 hours. If a master fails, and the slave is 10 minutes behind, your RPO cannot be < 10 minutes. If the application needs to be bounced to update the db connections which takes 10 minutes, then the RTO cannot be < 10 minutes.
RTO and/or RPO is realistically impossible. (why?) The business has to establish the tolerable RTO and RPO. This acts as a requirements-spec for the DR Plan and Implementation. These limits also help establish the SLA with customers.
minutes = lost transactions. For an online broker, an RTO greater than a few minutes = lost trades. For a media company, RTO greater than a few minutes = angry tweets. For a static website, weekly backups are acceptable with a RPO of 1 week. For an HR system, RPO greater than a day may be acceptable, but RTO greater than a few hours may not.
site. Infrastructure has to be spun up on the recovery site in the event of a disaster. RPO and RTO can be in hours, if not days. Inexpensive - Costs few hundred dollars a month for the storage.
Infrastructure is provisioned, but needs to be started before taking any traffic (RTO!) Data replication may be a few seconds/minutes behind (RPO!) Lower RTO and RPO than Backup & Restore, a bit more $$ for replication.
take on traffic. May need to be scaled up to handle full production load (Autoscale!) Data replication may be a few seconds/minutes behind (RPO!) Lower RTO than Pilot Light, more $$ (why?)
the Pull-request model for infrastructure changes. Automating a destructive script (unintentionally) is the quickest way to a disaster. foreach ($env == ‘prod’); sudo chmod -R -rx
data center. A faulty switch can take down entire subnet. A service failure can take down all others dependent on it. A Region failure has larger blast radius than an Availability Zone failure A Provider failure has larger blast radius than a Region failure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}