T., & Prisacariu, V. A. (2023). Accelerated Coordinate Encoding: Learning to Relocalize in Minutes Using RGB and Poses. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition
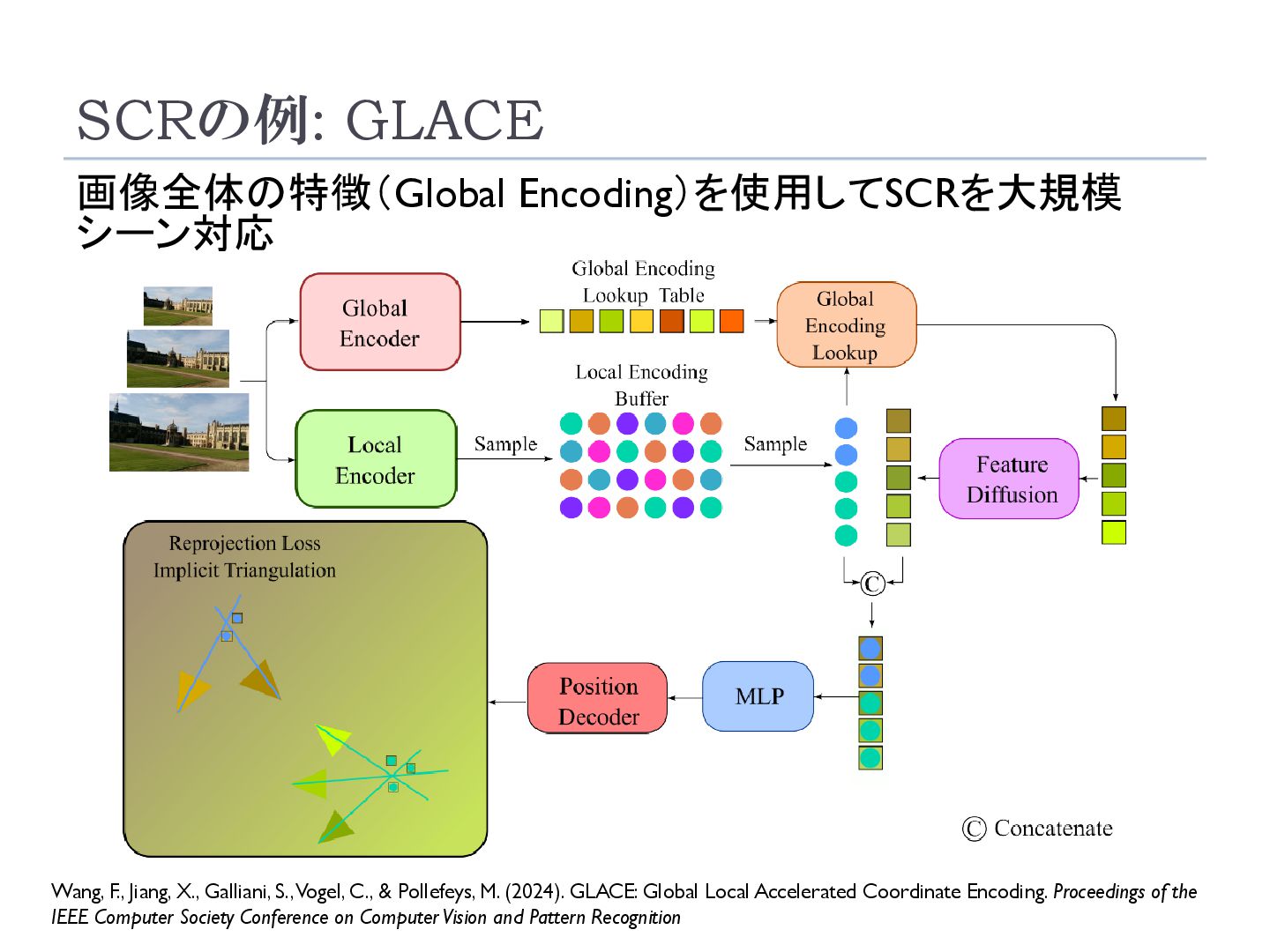
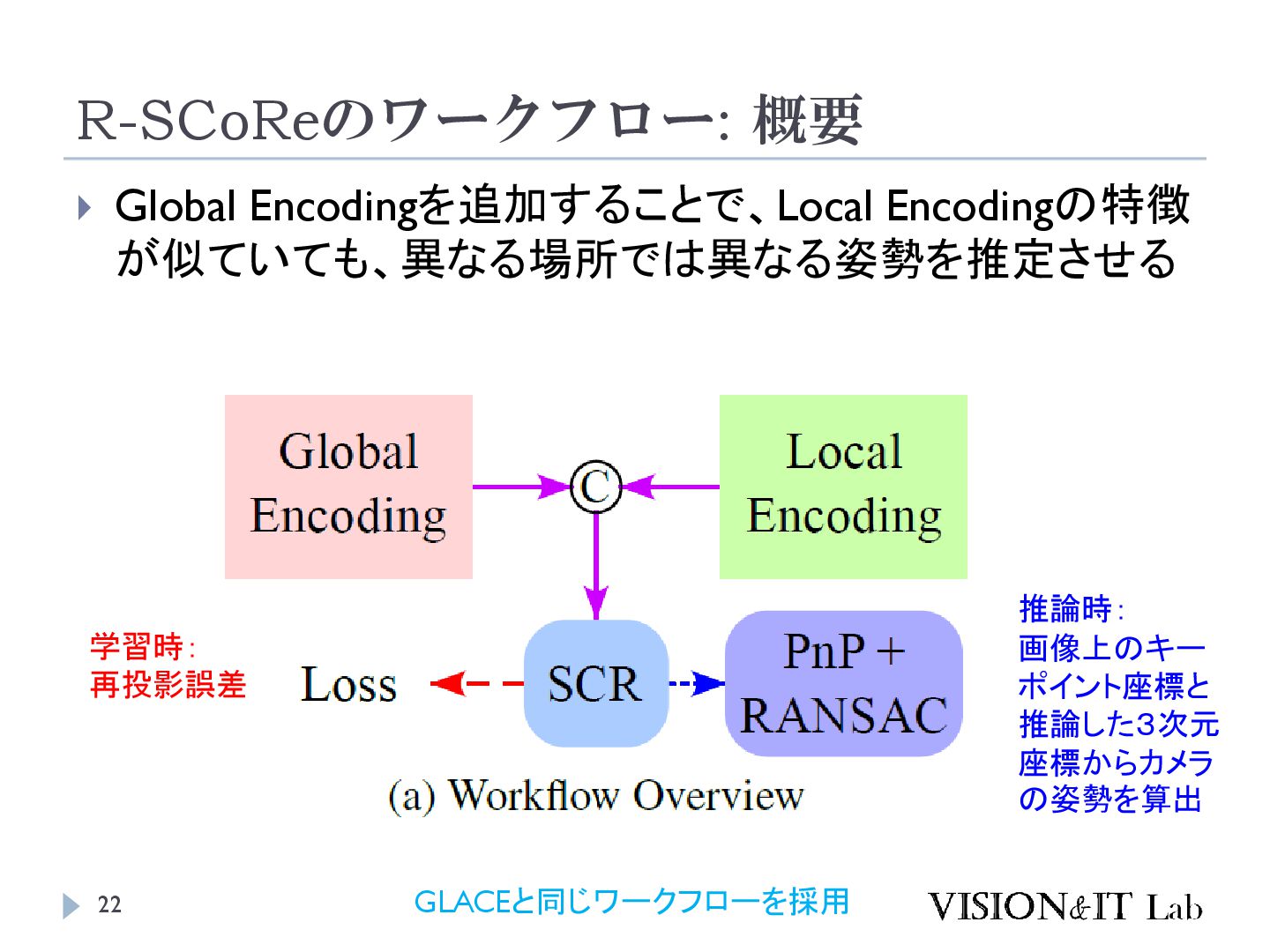
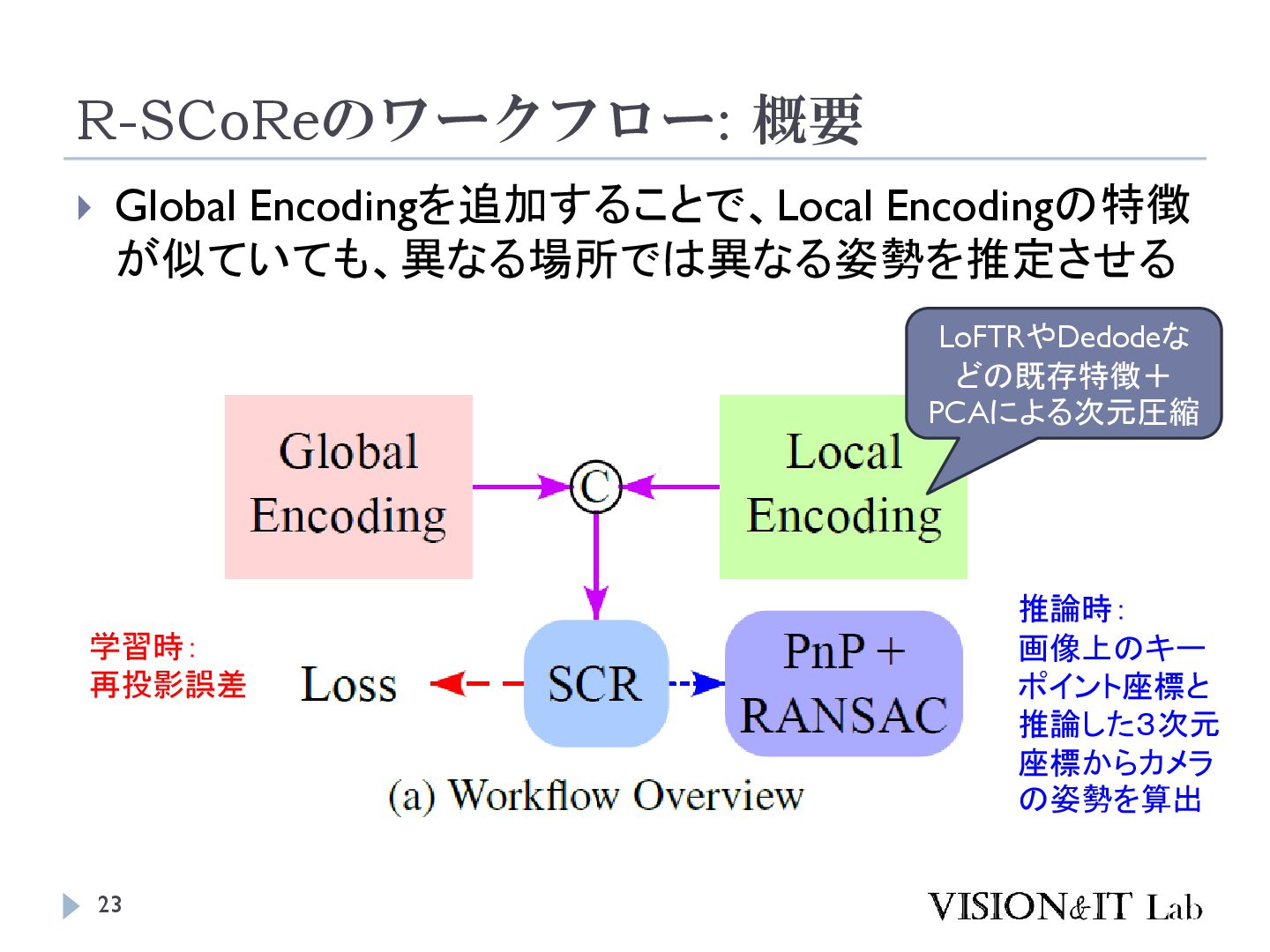
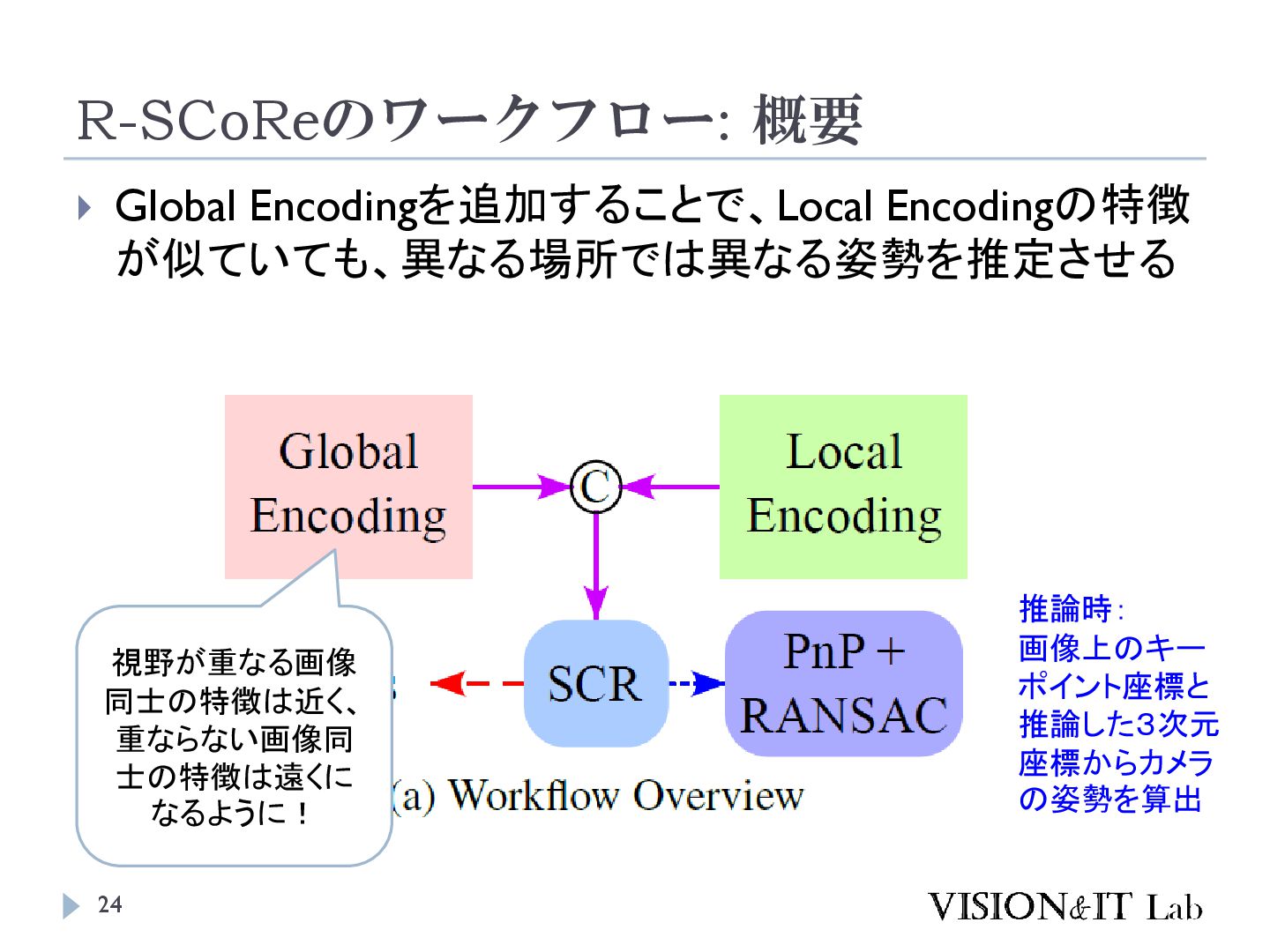
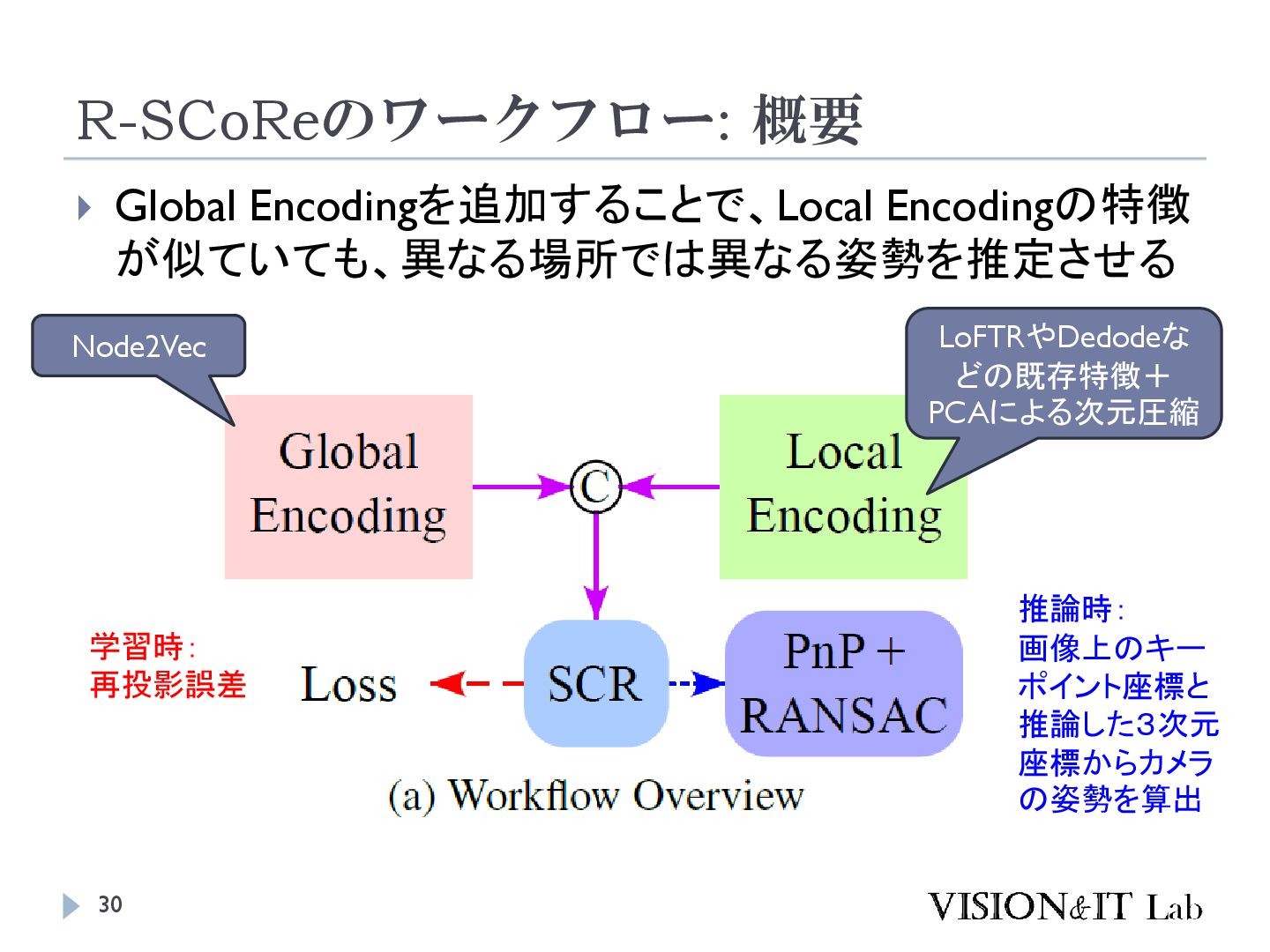
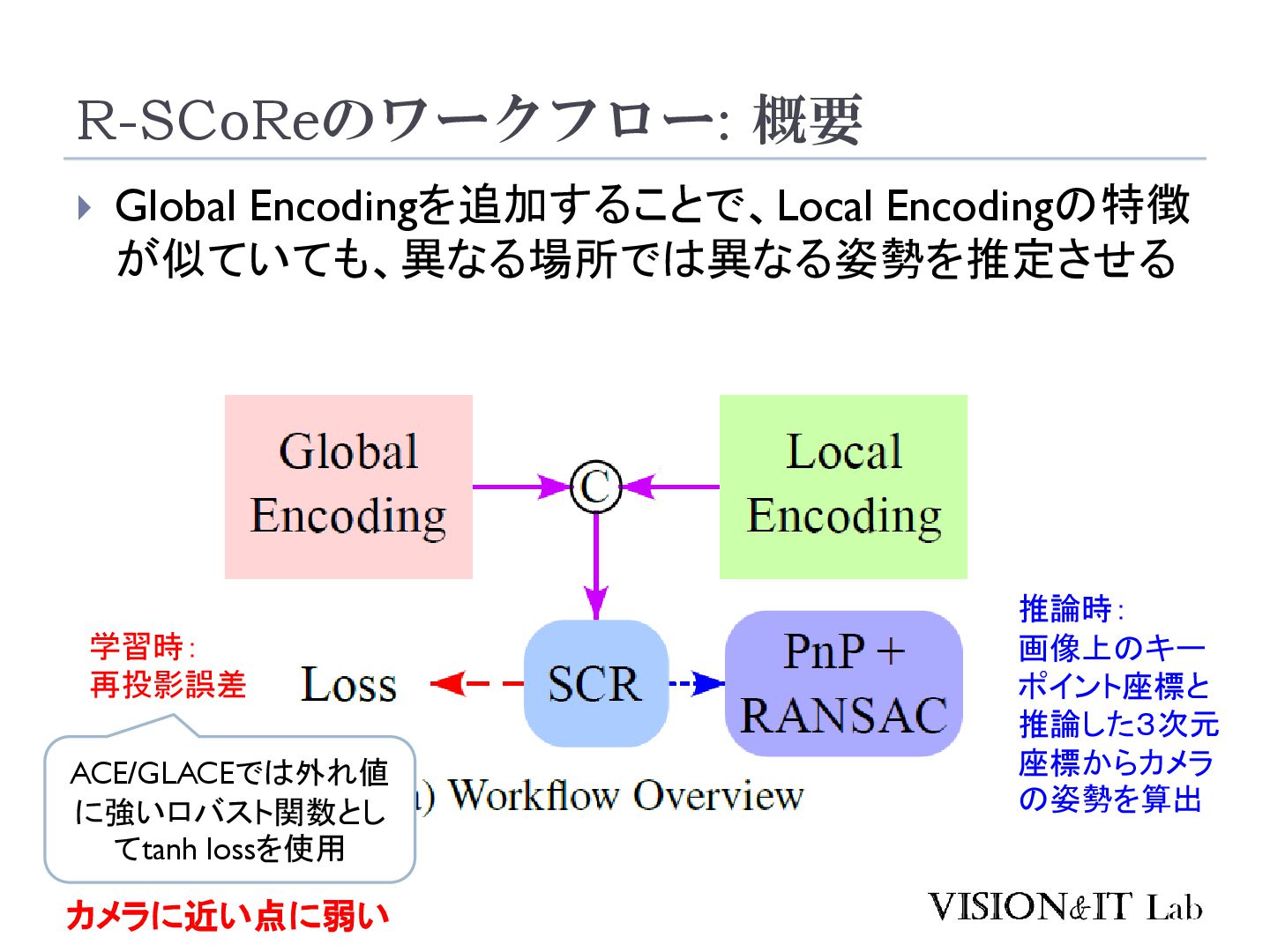
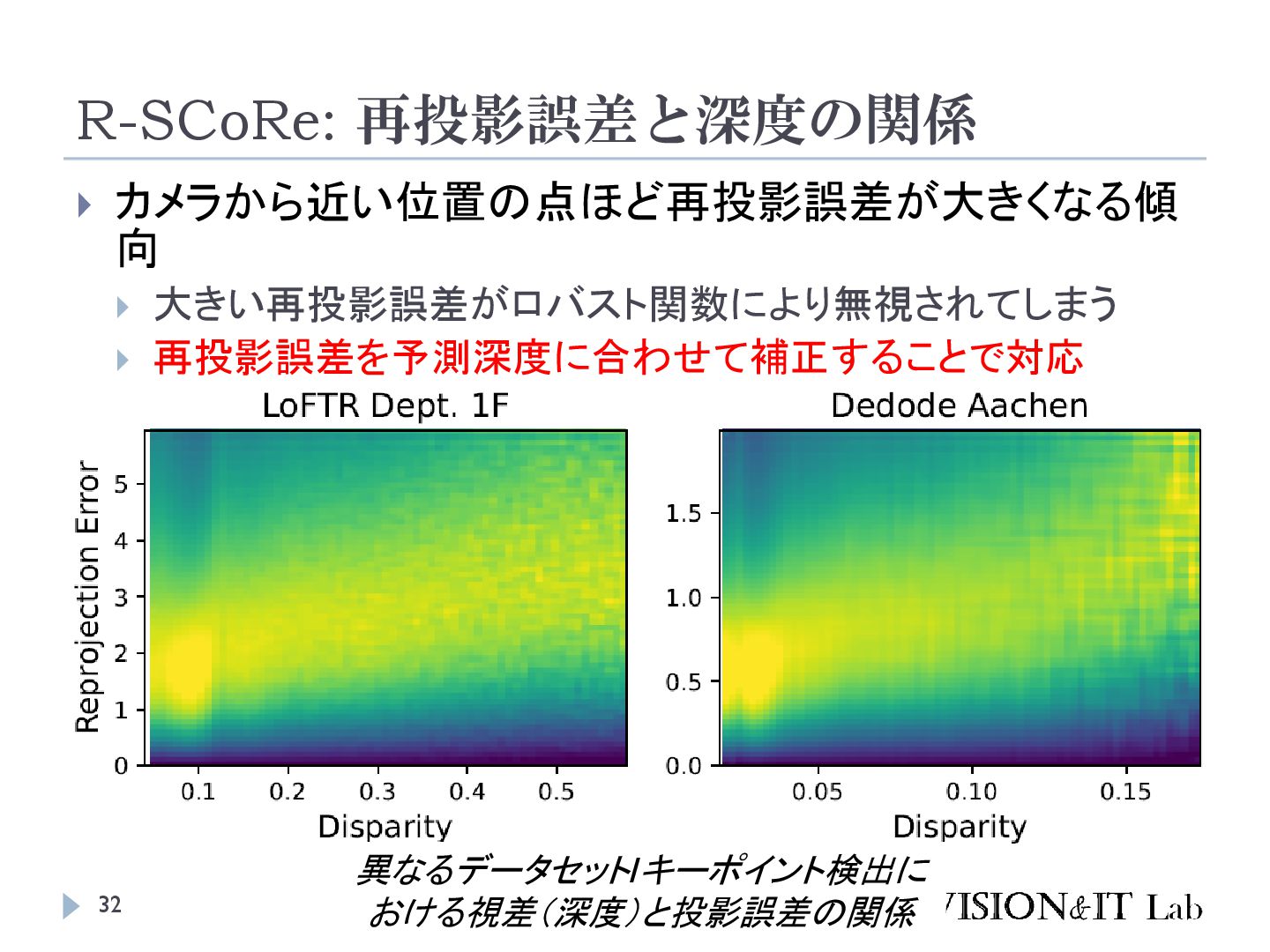
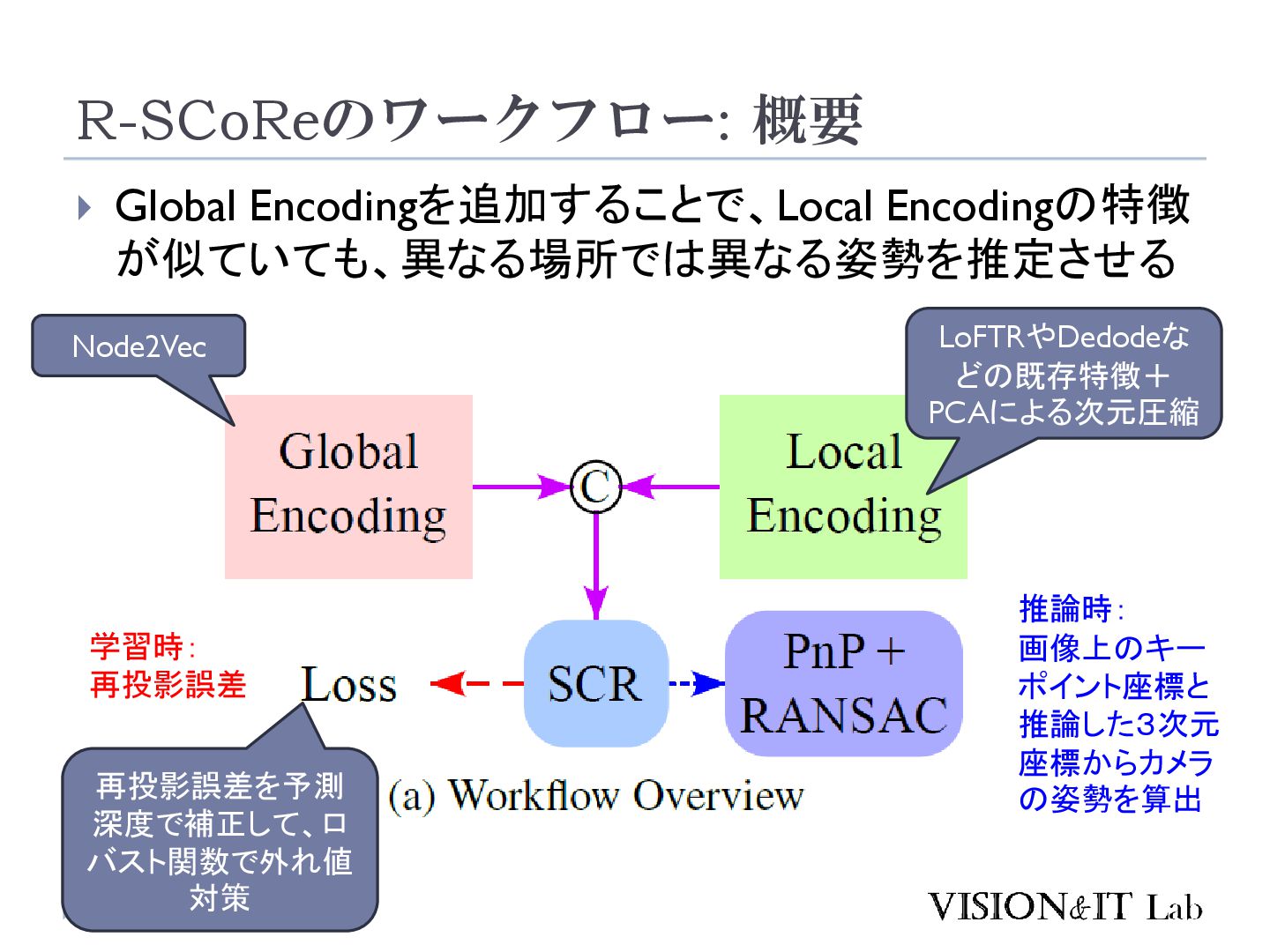
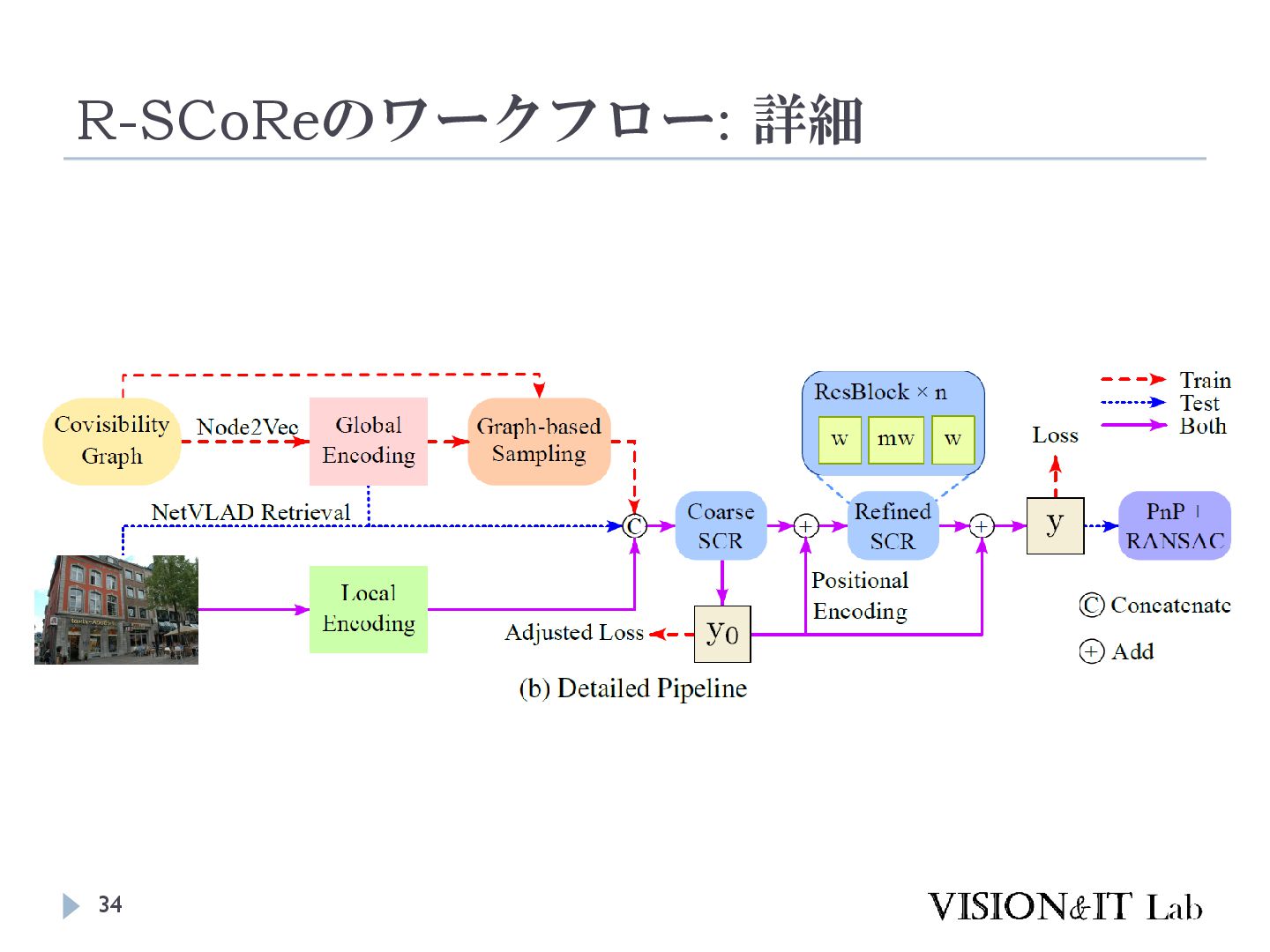
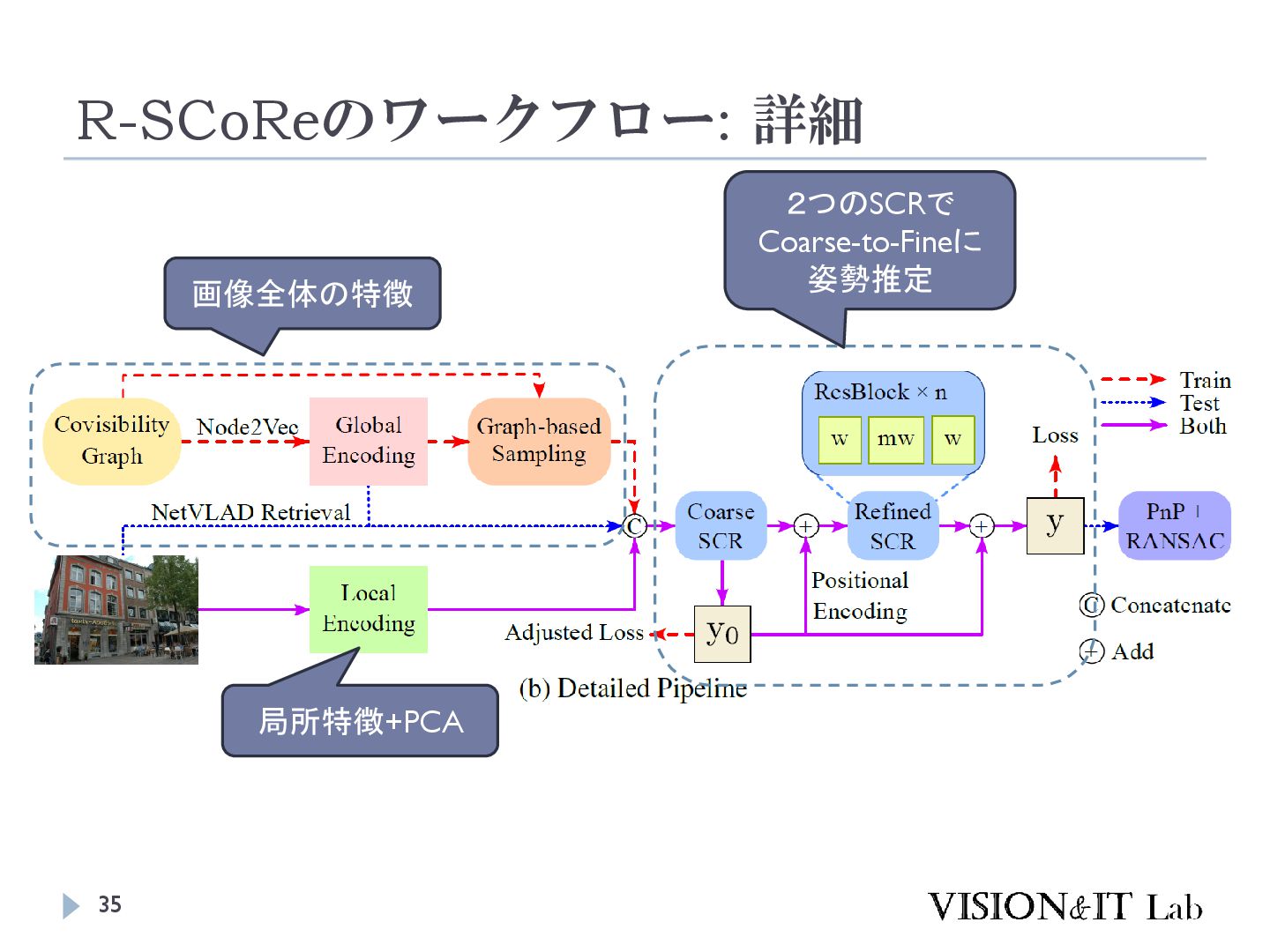
S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 大規模なマップでは、似た特徴を持つ点が異なるシーン で現れることがあり、精度低下の原因となる 画像全体の特徴を局所特徴に追加することで、異なる シーンで異なる座標を出力するようにネットワークを学 習する
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition
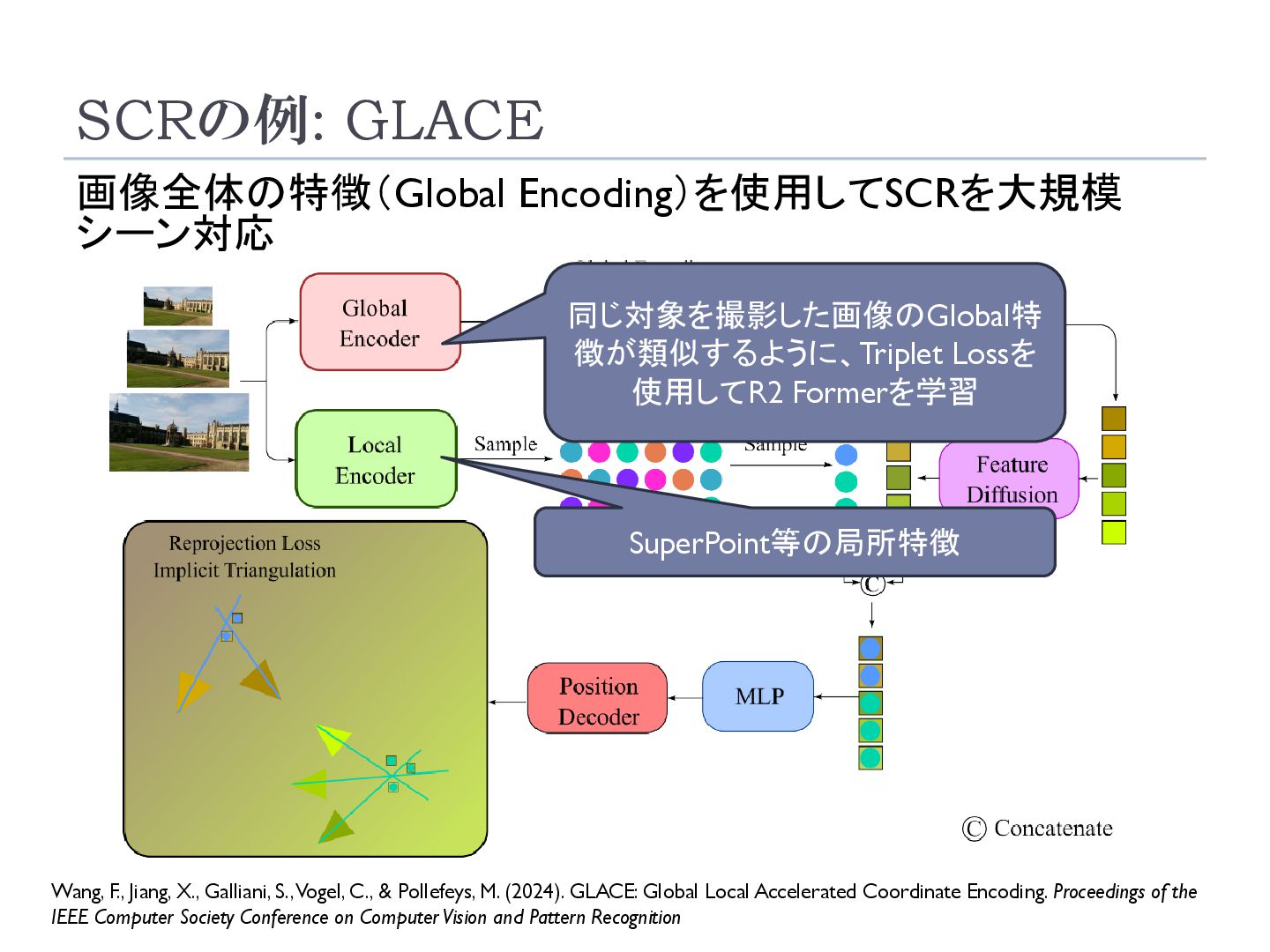
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 同じ対象を撮影した画像のGlobal特 徴が類似するように、Triplet Lossを 使用してR2 Formerを学習 SuperPoint等の局所特徴
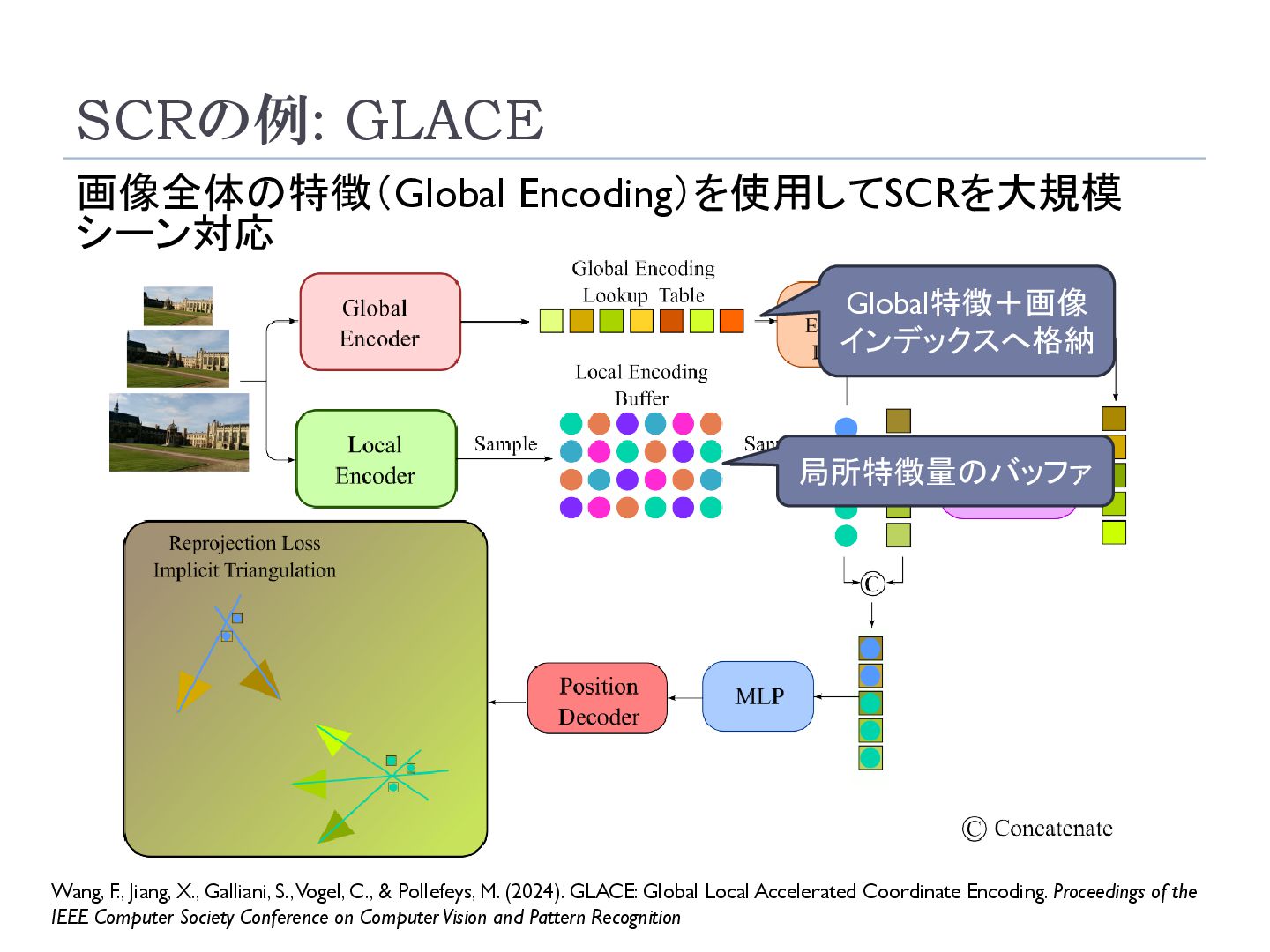
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Global特徴+画像 インデックスへ格納 局所特徴量のバッファ
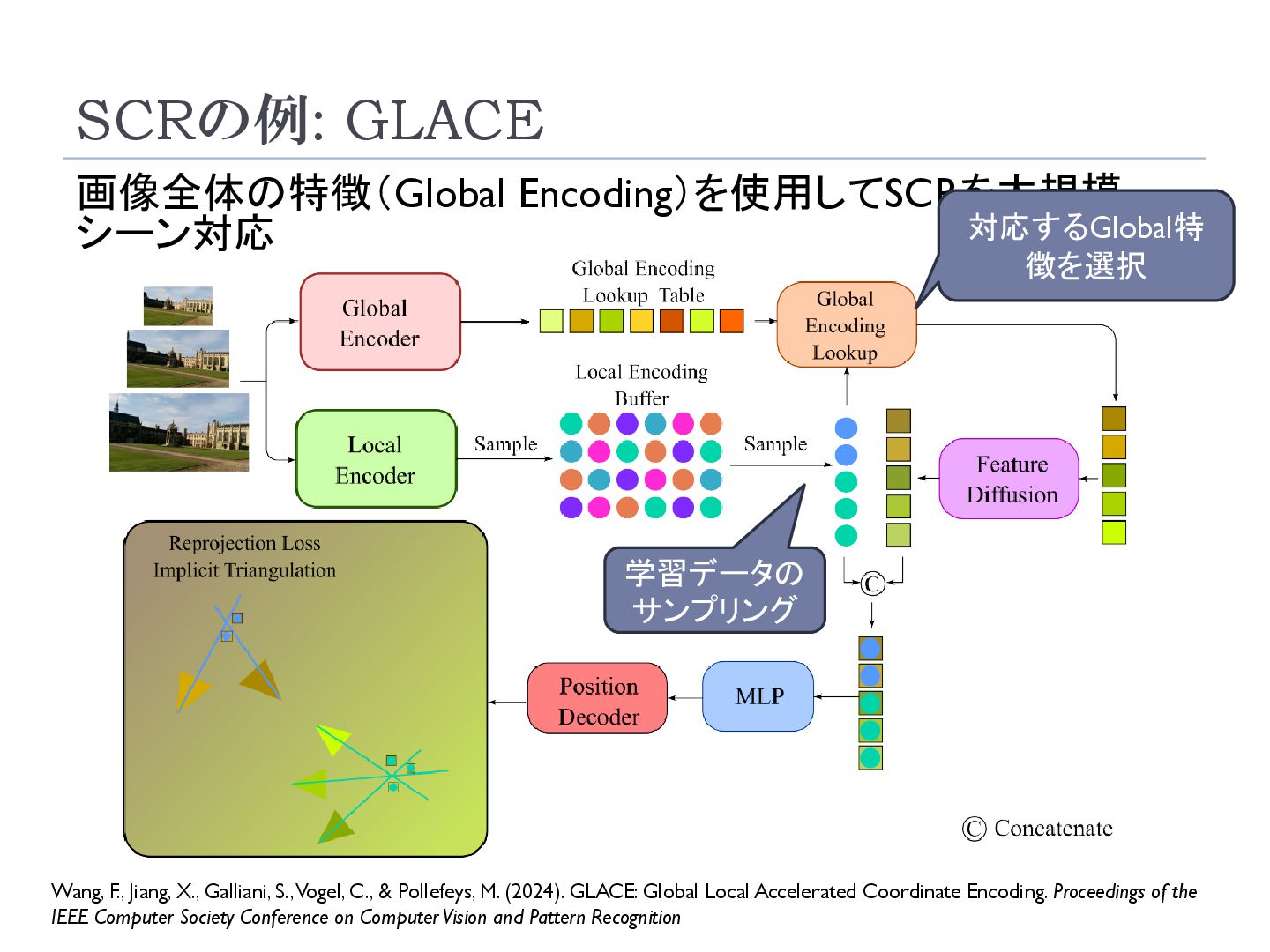
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 対応するGlobal特 徴を選択 学習データの サンプリング
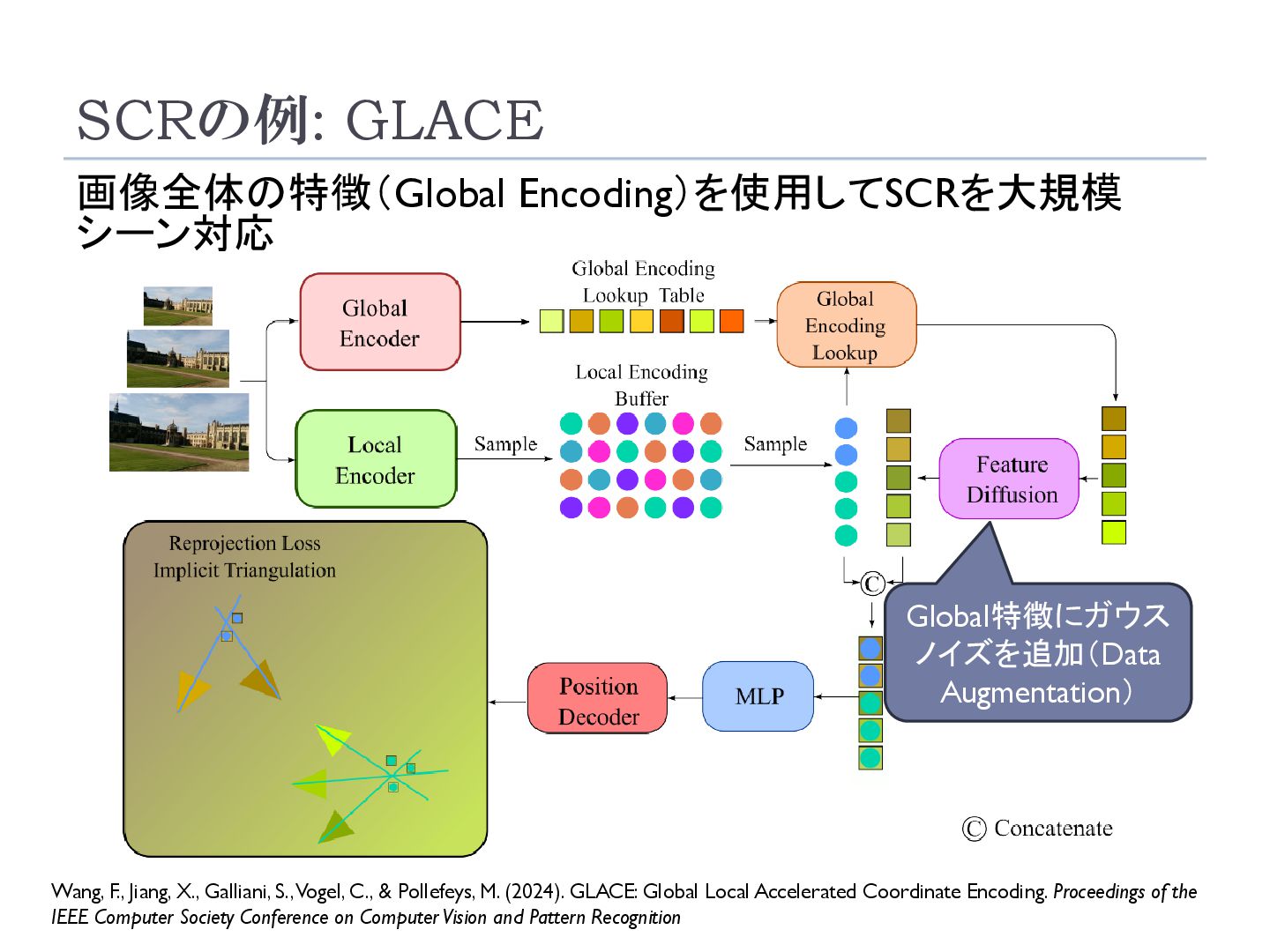
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Global特徴にガウス ノイズを追加(Data Augmentation)
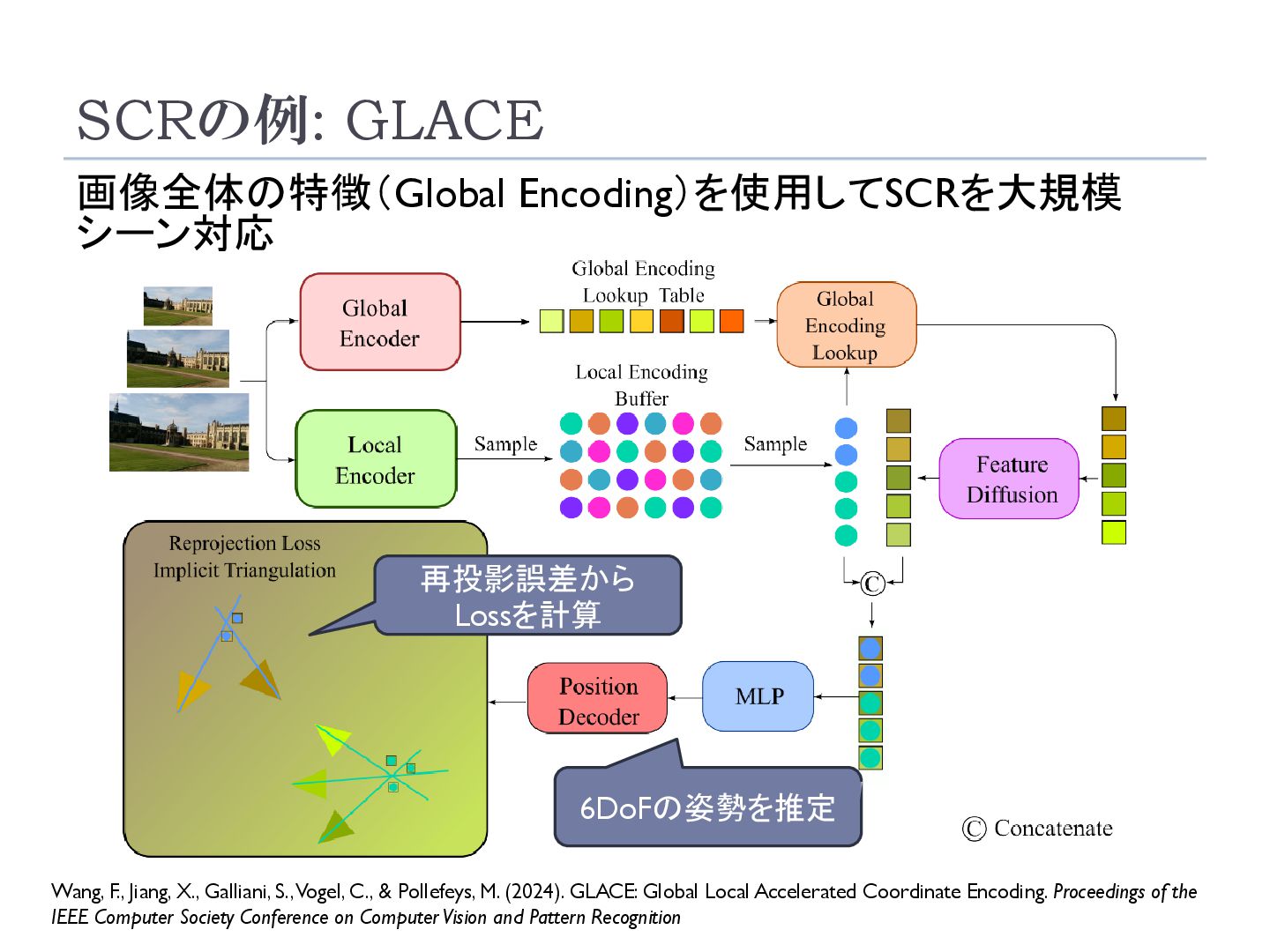
Galliani, S., Vogel, C., & Pollefeys, M. (2024). GLACE: Global Local Accelerated Coordinate Encoding. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 6DoFの姿勢を推定 再投影誤差から Lossを計算
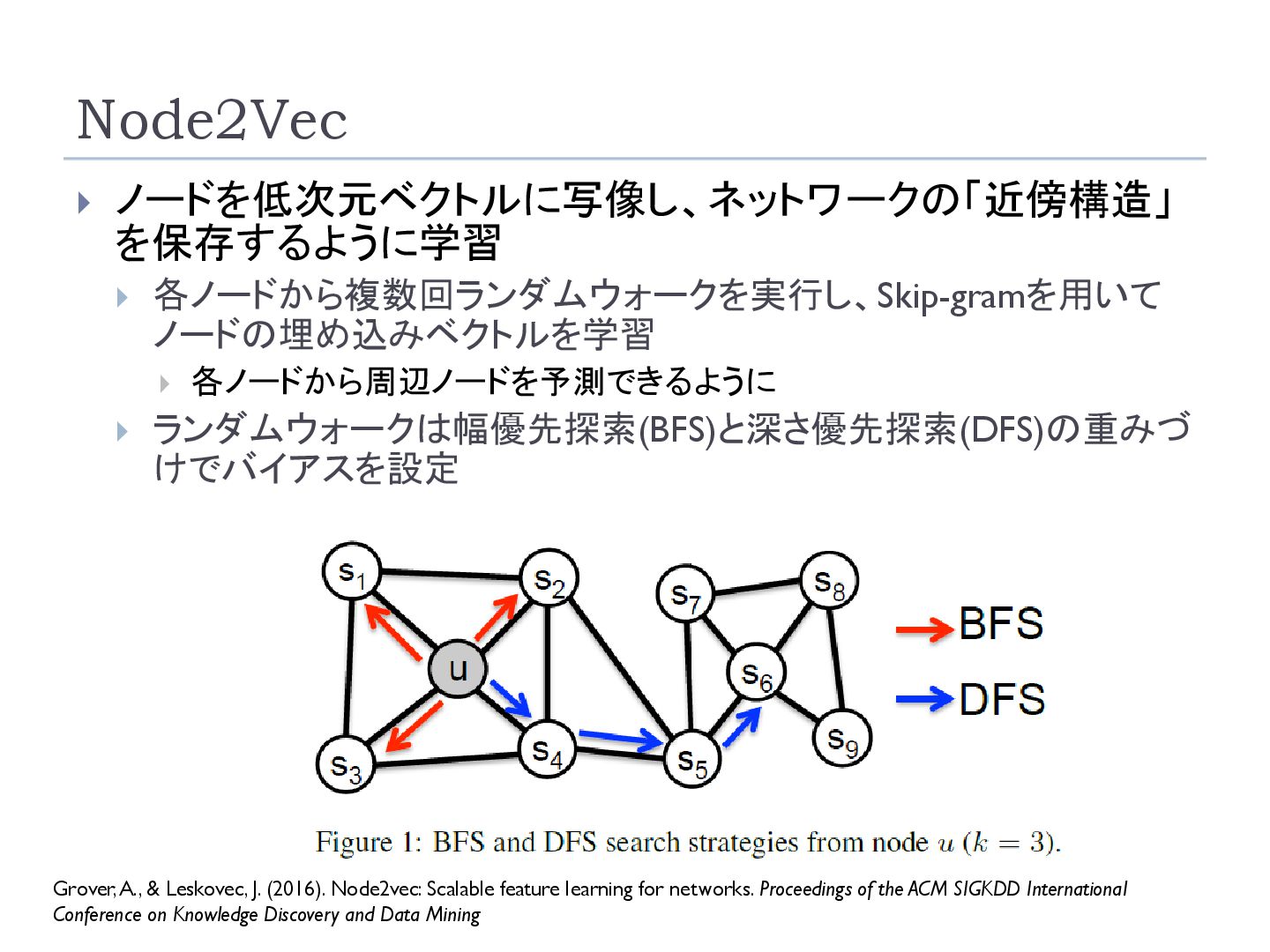
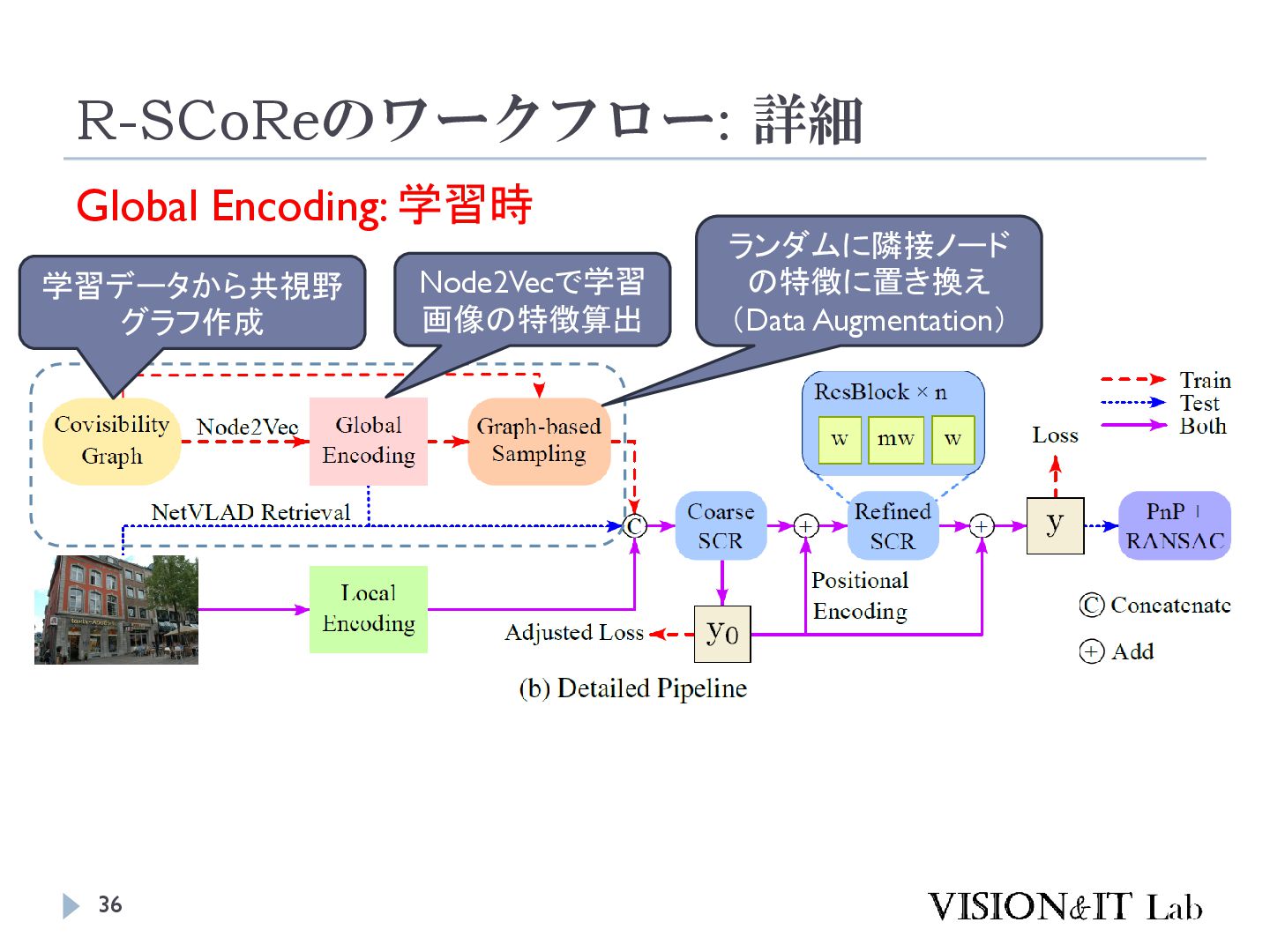
feature learning for networks. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining ノードを低次元ベクトルに写像し、ネットワークの「近傍構造」 を保存するように学習 各ノードから複数回ランダムウォークを実行し、Skip-gramを用いて ノードの埋め込みベクトルを学習 各ノードから周辺ノードを予測できるように ランダムウォークは幅優先探索(BFS)と深さ優先探索(DFS)の重みづ けでバイアスを設定
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
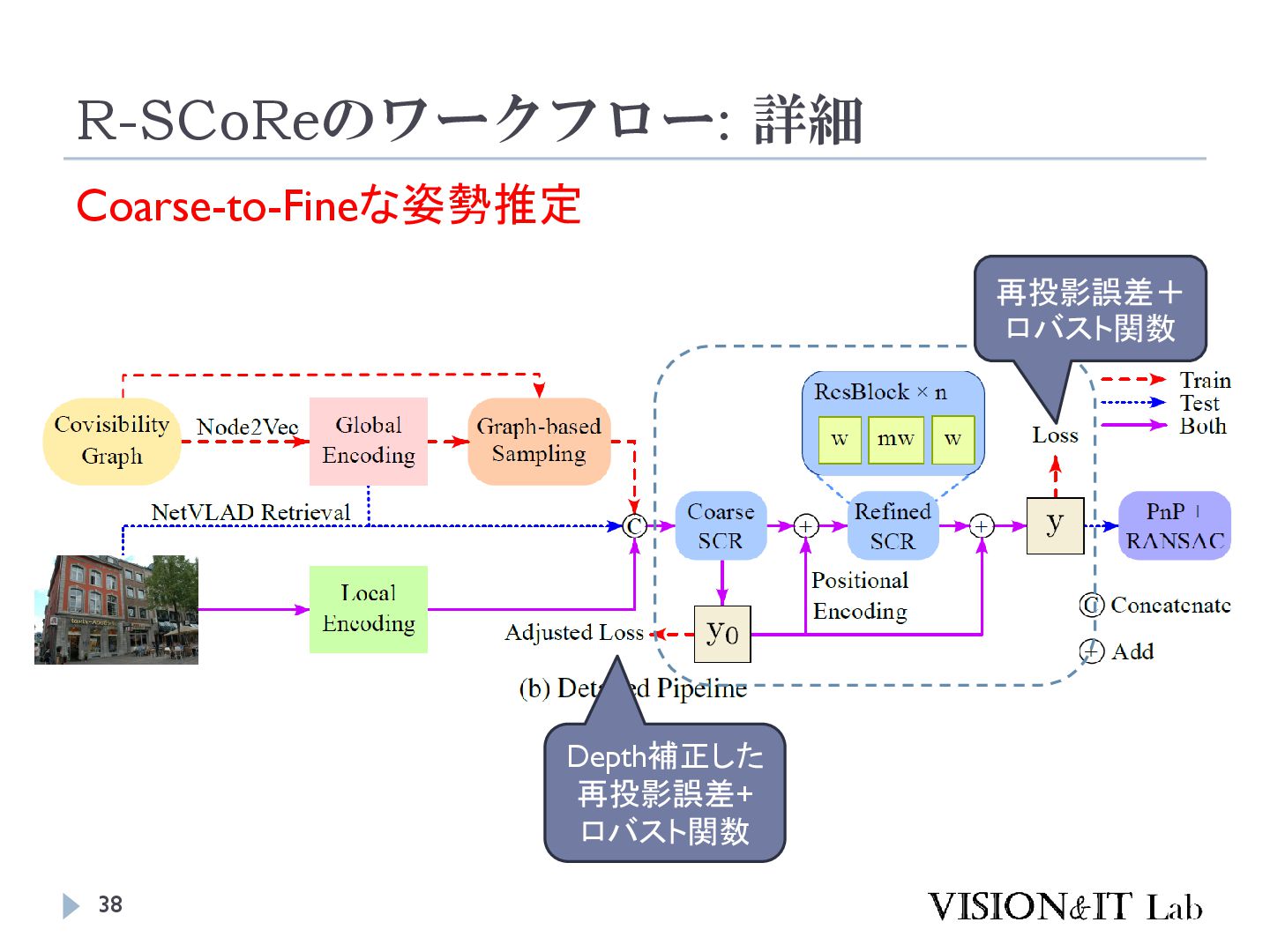{kind=link}
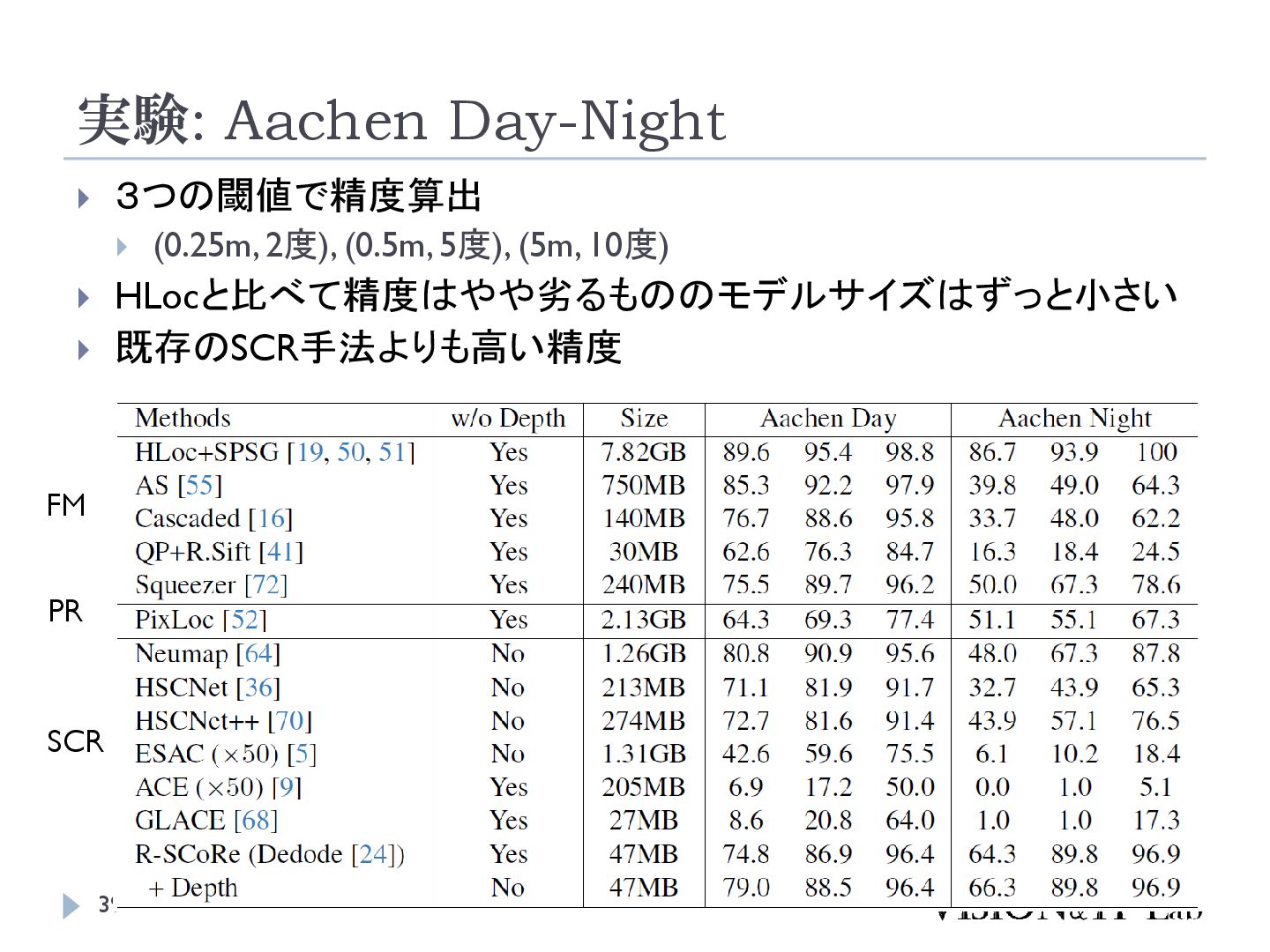{kind=link}
{kind=link}
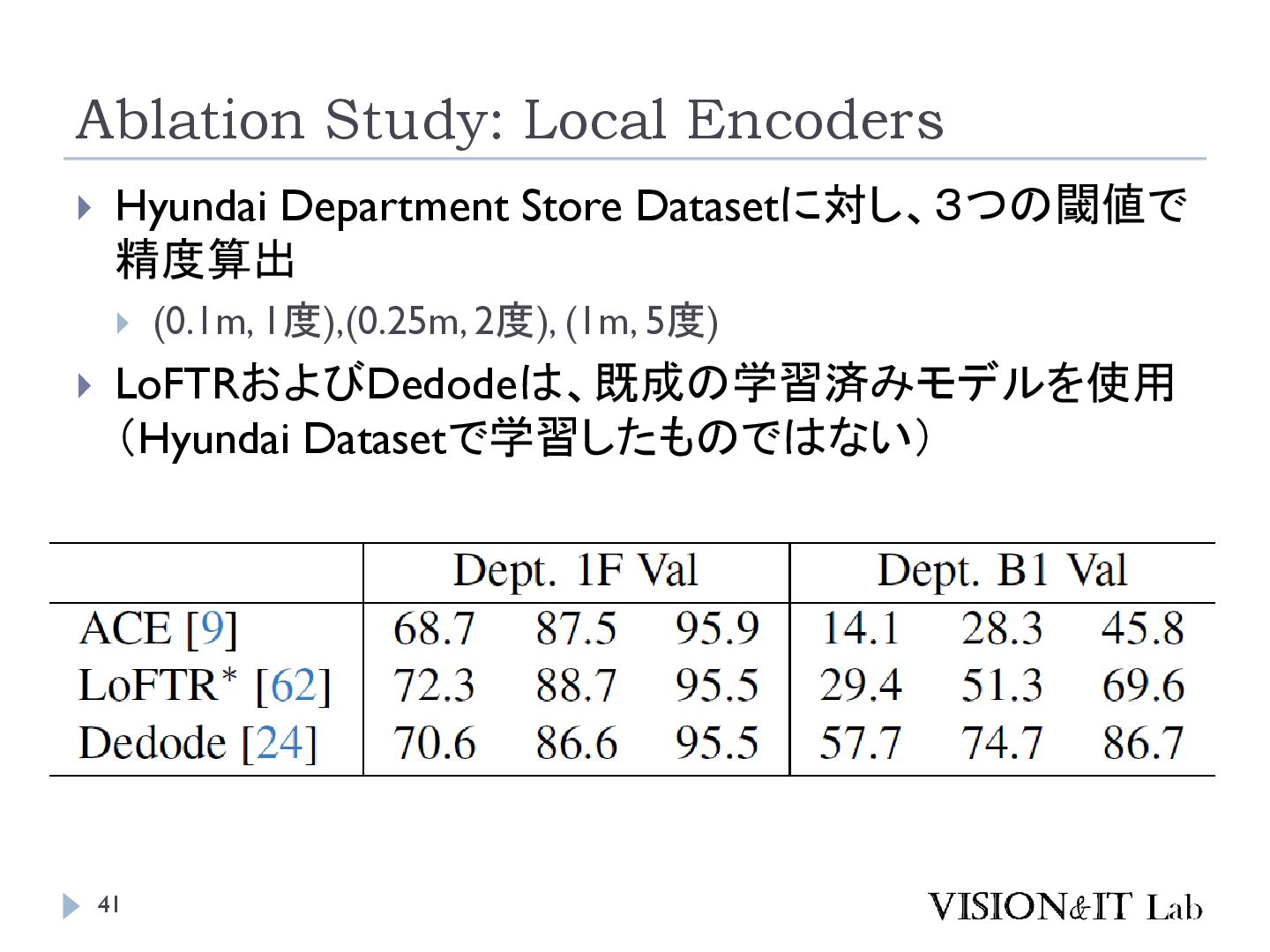{kind=link}
{kind=link}
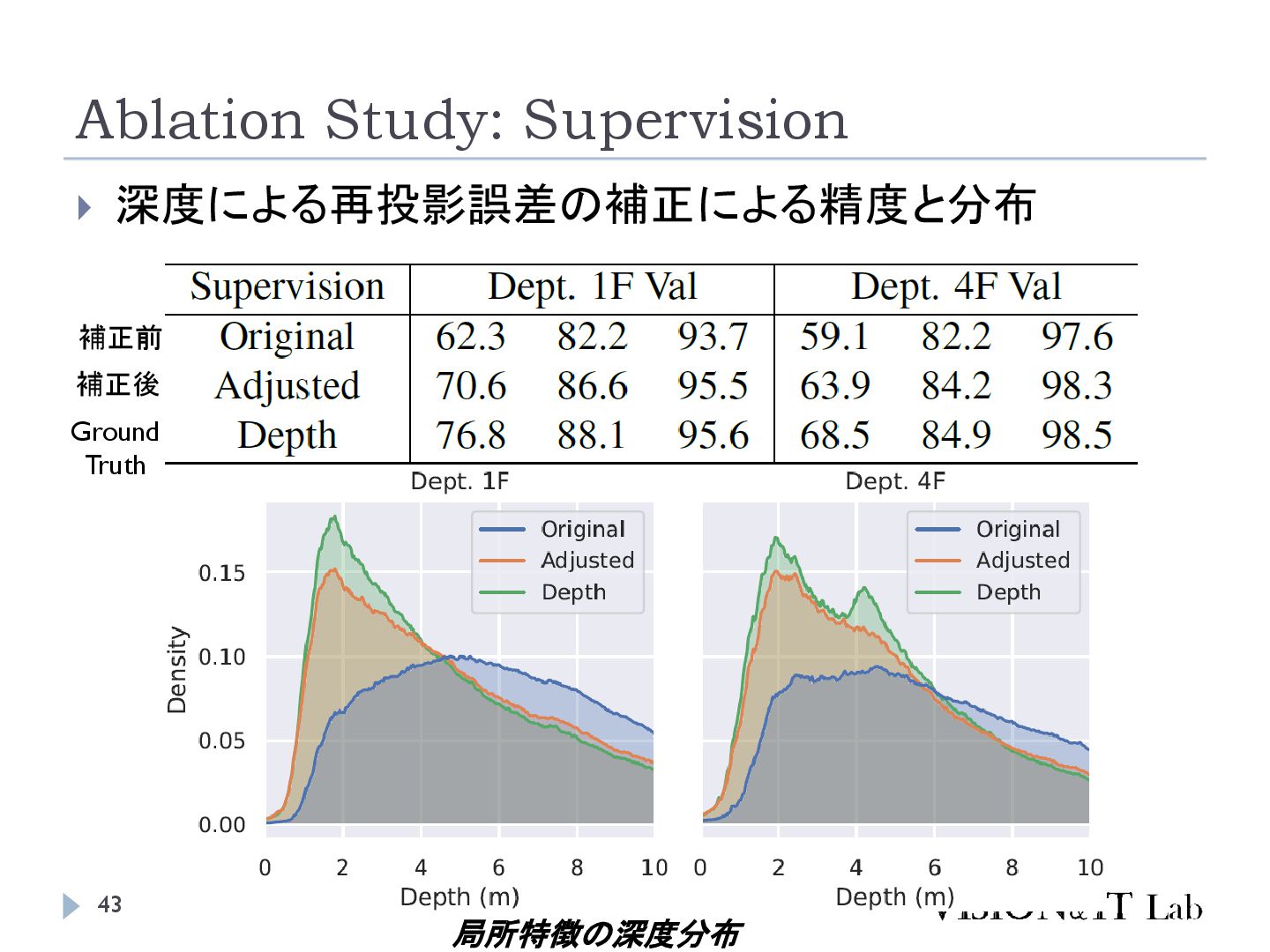{kind=link}
{kind=link}