A quick look at parsing and generating RSS with Python; introduces feedparser and PyRSS2Gen, and illustrates how to combine the two to generate subfeeds filtered on some given criteria. Presented to ClePy on December 5, 2005.
format for “Really Simple Syndication” • Used for... • News • Blogs • E-Commerce • Wiki changes • Source control checkins • Software releases • Podcasts • And much more!
own • Fetch data: • urllib or urllib2 • Read file on disk • Parse it: • Write your own parser (too much work) • Use your favorite Python XML parser (too many choices, too much work) • But you're smarter than that, and too busy!
data for you • From a URL or a filename • Transparently handles: • Atom • RSS 1.0 • RSS 2.0 • Robust • Uses “loose” parser if strict XML parsing fails • Delightfully Pythonic • Access elements by key or attribute
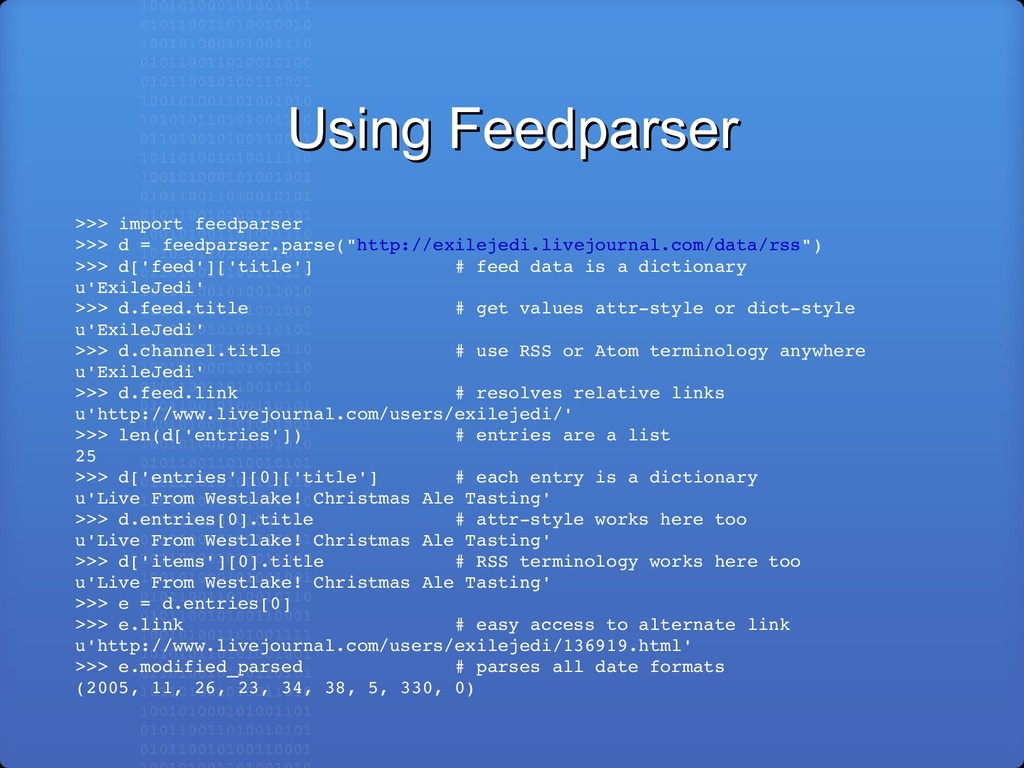
feedparser.parse("http://exilejedi.livejournal.com/data/rss") >>> d['feed']['title'] # feed data is a dictionary u'ExileJedi' >>> d.feed.title # get values attrstyle or dictstyle u'ExileJedi' >>> d.channel.title # use RSS or Atom terminology anywhere u'ExileJedi' >>> d.feed.link # resolves relative links u'http://www.livejournal.com/users/exilejedi/' >>> len(d['entries']) # entries are a list 25 >>> d['entries'][0]['title'] # each entry is a dictionary u'Live From Westlake! Christmas Ale Tasting' >>> d.entries[0].title # attrstyle works here too u'Live From Westlake! Christmas Ale Tasting' >>> d['items'][0].title # RSS terminology works here too u'Live From Westlake! Christmas Ale Tasting' >>> e = d.entries[0] >>> e.link # easy access to alternate link u'http://www.livejournal.com/users/exilejedi/136919.html' >>> e.modified_parsed # parses all date formats (2005, 11, 26, 23, 34, 38, 5, 330, 0)
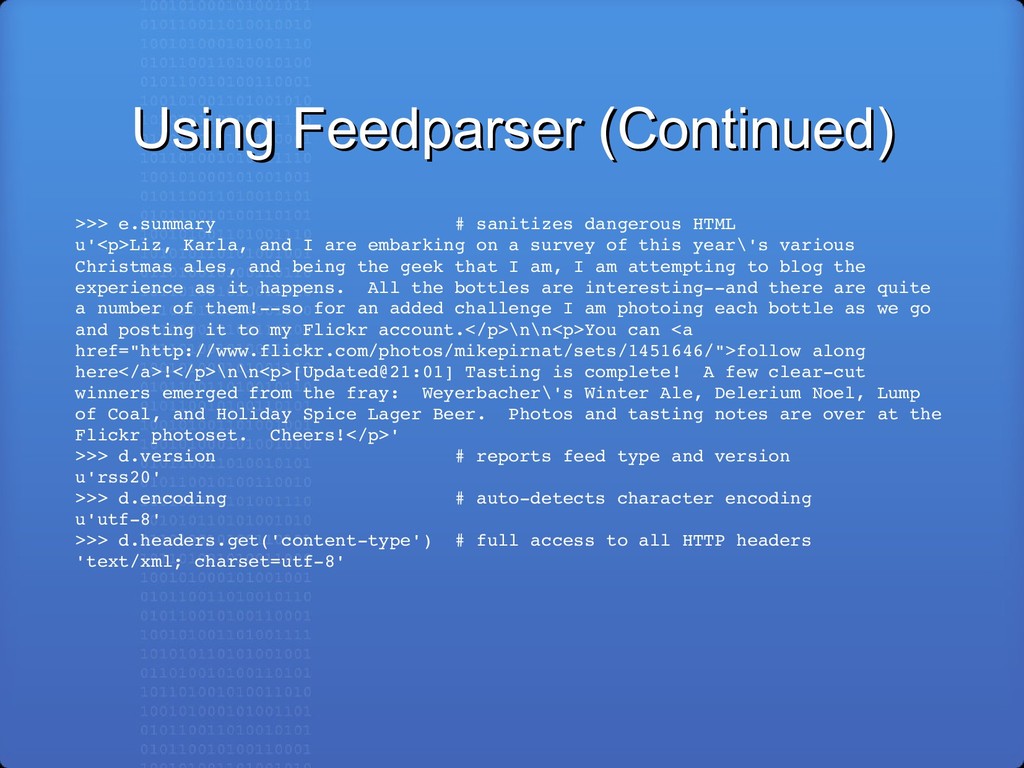
dangerous HTML u'<p>Liz, Karla, and I are embarking on a survey of this year\'s various Christmas ales, and being the geek that I am, I am attempting to blog the experience as it happens. All the bottles are interestingand there are quite a number of them!so for an added challenge I am photoing each bottle as we go and posting it to my Flickr account.</p>\n\n<p>You can <a href="http://www.flickr.com/photos/mikepirnat/sets/1451646/">follow along here</a>!</p>\n\n<p>[Updated@21:01] Tasting is complete! A few clearcut winners emerged from the fray: Weyerbacher\'s Winter Ale, Delerium Noel, Lump of Coal, and Holiday Spice Lager Beer. Photos and tasting notes are over at the Flickr photoset. Cheers!</p>' >>> d.version # reports feed type and version u'rss20' >>> d.encoding # autodetects character encoding u'utf8' >>> d.headers.get('contenttype') # full access to all HTTP headers 'text/xml; charset=utf8'
Plain old string concatenation • Roll your own objects that str down to individual elements • Use your favorite Python XML generator (too many choices—it's like picking a web framework!) • But you're still not getting any younger...
RSS2, the current “recommended” version of RSS • Escapes things properly • Pythonic • Perhaps not as much as ElementTree, but... • Integers, dates, and lists are REAL integers, dates, and lists!
PyRSS2Gen.RSS2( title = "ClePy r0x0rs!", link = "http://clepy.org", description = "The latest news from ClePy, " "the Cleveland Python group", lastBuildDate = datetime.datetime.now(), items = [ PyRSS2Gen.RSSItem( title = "Mike Rambles About PyRSS2Gen", link = "http://clepy.org/news/mikerss2gen.html", description = "At tonight's meeting, Mike went on and on " "about PyRSS2Gen, and you liked it.", guid = PyRSS2Gen.Guid("http://clepy.org/news/mikerss2gen.html"), categories = ['presentations', 'Mike Pirnat'], pubDate = datetime.datetime(2005, 12, 5, 18, 30)), ]) xml = rss.to_xml() # or do... rss.write_xml(open("clepy.xml", "w"))
encoding="iso88591"?> <rss version="2.0"> <channel> <title>ClePy r0x0rs!</title> <link>http://clepy.org</link> <description>The latest news from ClePy, the Cleveland Python group</description> <lastBuildDate>Sun, 04 Dec 2005 11:46:59 GMT</lastBuildDate> <generator>PyRSS2Gen1.0.0</generator> <docs>http://blogs.law.harvard.edu/tech/rss</docs> <item><title>Mike Rambles About PyRSS2Gen</title> <link>http://clepy.org/news/mikerss2gen.html</link> <description>At tonight's meeting, Mike went on and on about PyRSS2Gen, and you liked it.</description> <category>presentations</category> <category>Mike Pirnat</category> <guid isPermaLink="true">http://clepy.org/news/mikerss2gen.html</guid> <pubDate>Mon, 05 Dec 2005 18:30:00 GMT</pubDate> </item> </channel> </rss>
to blog, but also have a personal site • I want to republish my recent blog entries on the main page of my personal site • I sometimes blog about TurboGears and want to be carried by planet.turbogears.org... • But I don't want to pollute the planet site with vacation photos or stories about cute things my cats do (that would be rude)
• Feedparser downloads and parses my RSS • Most recent posts written to HTML with a basic FeedRenderer class (DIY, very simple) • Entry list is filtered based on category • PyRSS2Gen builds a new feed from the filtered list
import feedparser import datetime import PyRSS2Gen # get the data d = feedparser.parse('http://exilejedi.livejournal.com/data/rss/') # do the filtering & build a list of RSSItem objects items = [PyRSS2Gen.RSSItem( title = x.title, link = x.link, description = x.summary, guid = x.link, pubDate = datetime.datetime( x.modified_parsed[0], x.modified_parsed[1], x.modified_parsed[2], x.modified_parsed[3], x.modified_parsed[4], x.modified_parsed[5])) for x in d.entries if some_criteria(x)]
do the filtering & build a list of RSSItem objects entries = [PyRSS2Gen.RSSItem(...) for x in feed.entries if func(x)] return entries def category_is(category): def f(d): if 'categories' in d: for (junk, cat) in d.categories: if cat.lower() == category: return True return False category = category.lower() return f def find_in_title(title): def f(d): if 'title' in d: return title in d.title.lower() return False title = title.lower() return f
have abandoned programming altogether • Patches aren't getting incorporated into CVS, releases • Check the SourceForge site for patches • Will it get a new maintainer? • Or will I just fork it? (May be an opportunity for Clepy to provide value to the community) • Must subclass things in PyRSS2Gen to support non-standard tags (eg, <lj:mood>)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}