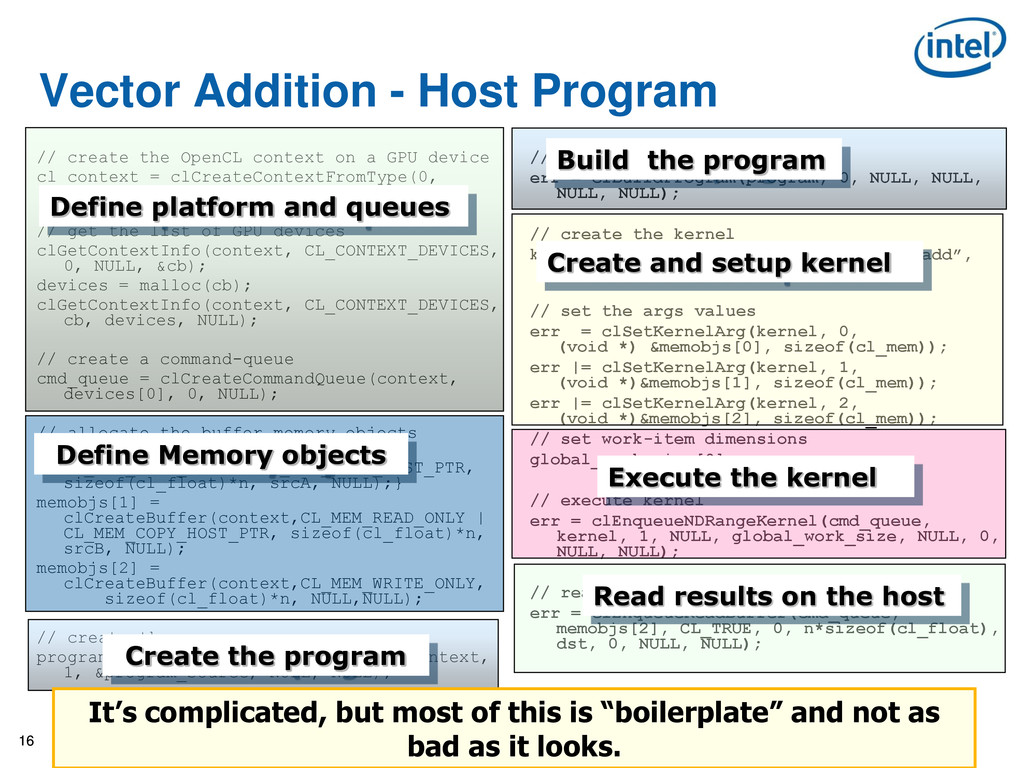
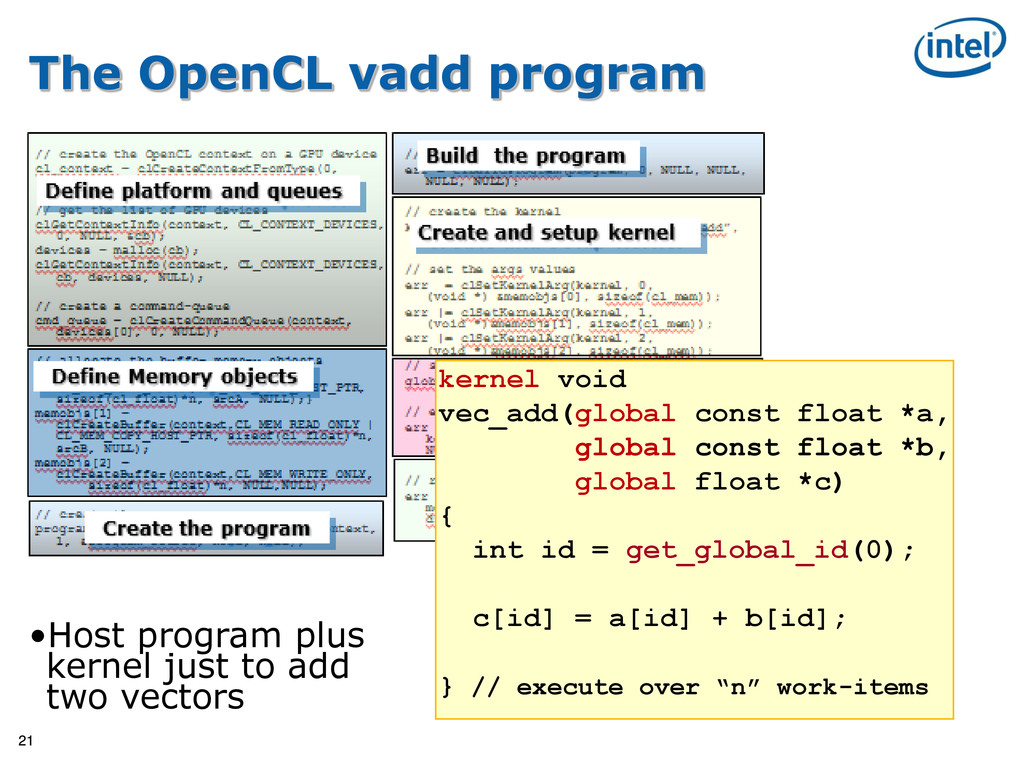
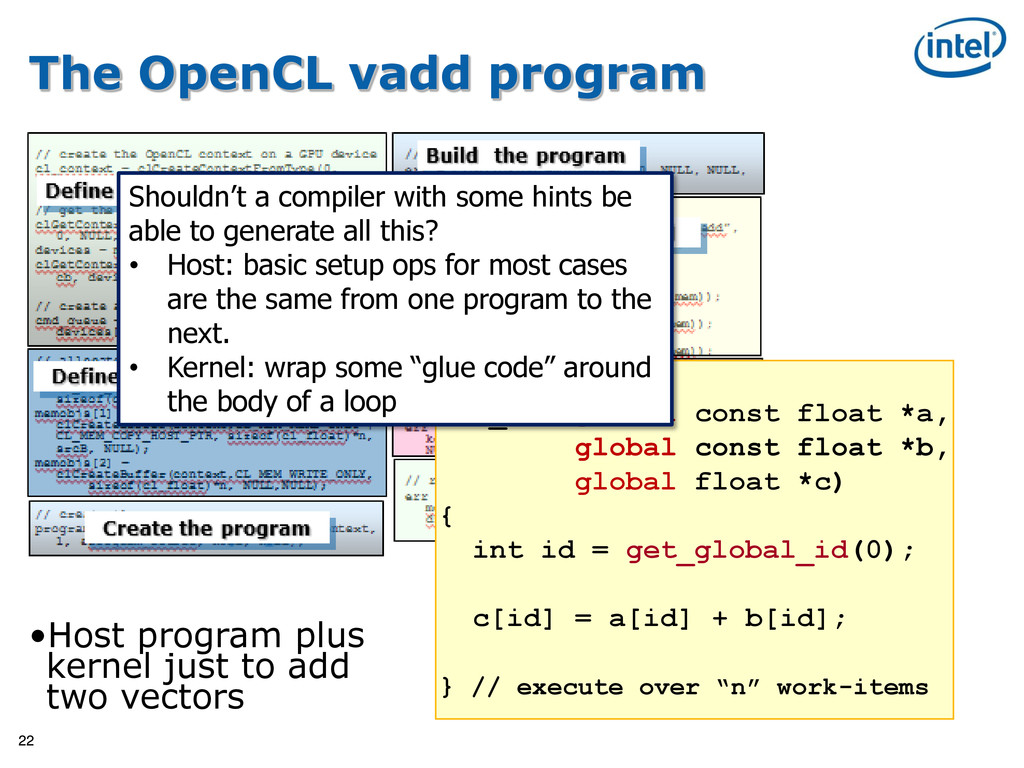
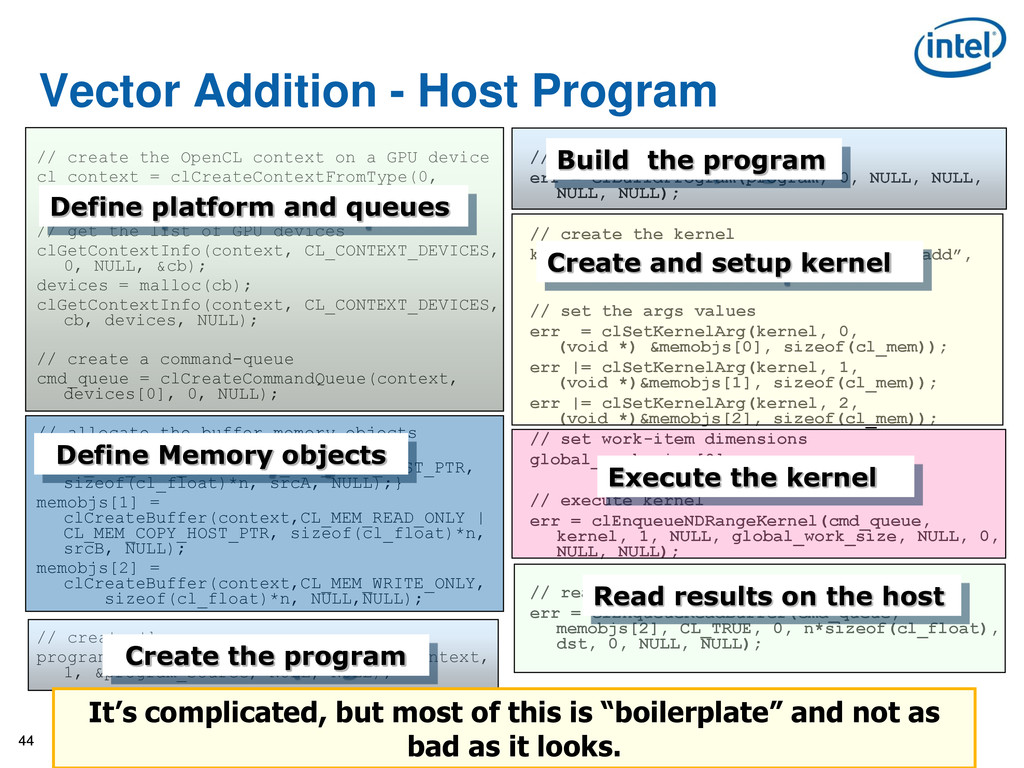
OpenCL context on a GPU device cl_context = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, NULL, NULL, NULL); // get the list of GPU devices clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &cb); devices = malloc(cb); clGetContextInfo(context, CL_CONTEXT_DEVICES, cb, devices, NULL); // create a command-queue cmd_queue = clCreateCommandQueue(context, devices[0], 0, NULL); // allocate the buffer memory objects memobjs[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(cl_float)*n, srcA, NULL);} memobjs[1] = clCreateBuffer(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(cl_float)*n, srcB, NULL); memobjs[2] = clCreateBuffer(context,CL_MEM_WRITE_ONLY, sizeof(cl_float)*n, NULL,NULL); // create the program program = clCreateProgramWithSource(context, 1, &program_source, NULL, NULL); // build the program err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL); // create the kernel kernel = clCreateKernel(program, “vec_add”, NULL); // set the args values err = clSetKernelArg(kernel, 0, (void *) &memobjs[0], sizeof(cl_mem)); err |= clSetKernelArg(kernel, 1, (void *)&memobjs[1], sizeof(cl_mem)); err |= clSetKernelArg(kernel, 2, (void *)&memobjs[2], sizeof(cl_mem)); // set work-item dimensions global_work_size[0] = n; // execute kernel err = clEnqueueNDRangeKernel(cmd_queue, kernel, 1, NULL, global_work_size, NULL, 0, NULL, NULL); // read output array err = clEnqueueReadBuffer(cmd_queue, memobjs[2], CL_TRUE, 0, n*sizeof(cl_float), dst, 0, NULL, NULL); Define platform and queues Define Memory objects Create the program Build the program Create and setup kernel Execute the kernel Read results on the host It’s complicated, but most of this is “boilerplate” and not as bad as it looks.
{kind=link}
{kind=link}
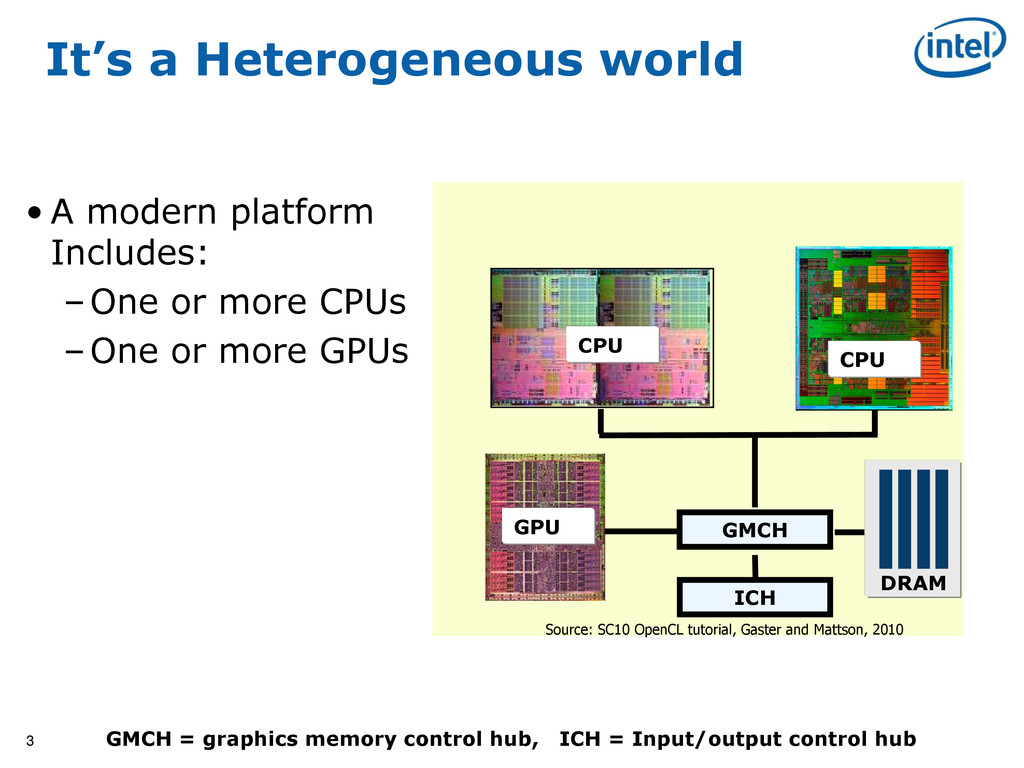{kind=link}
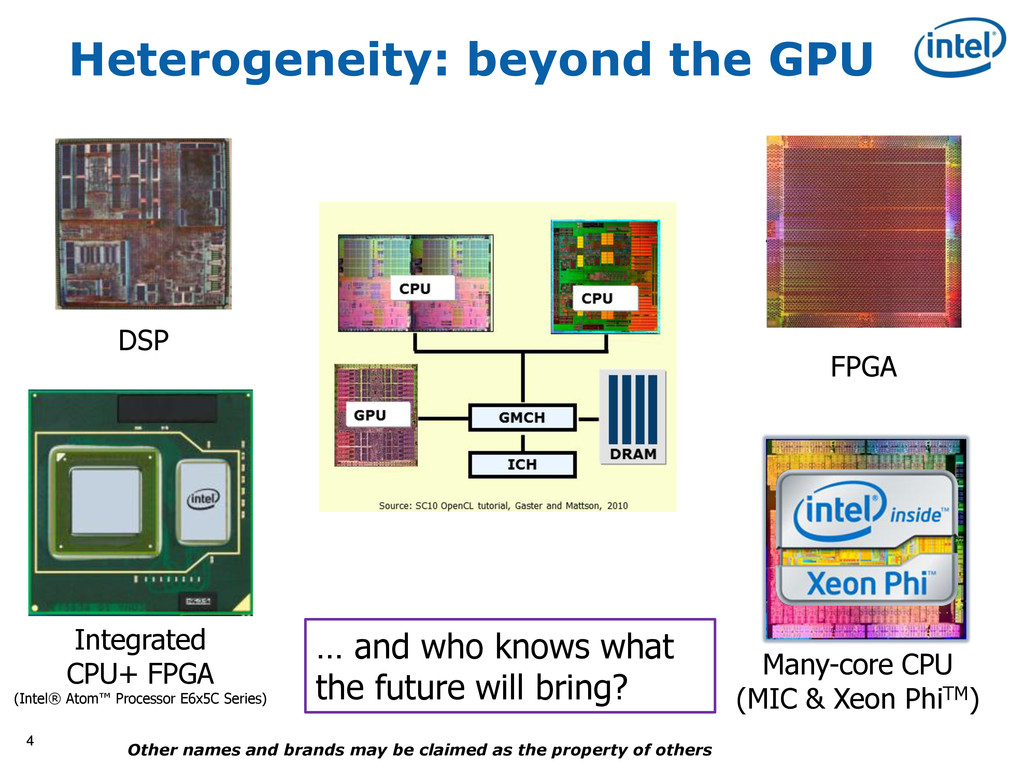{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
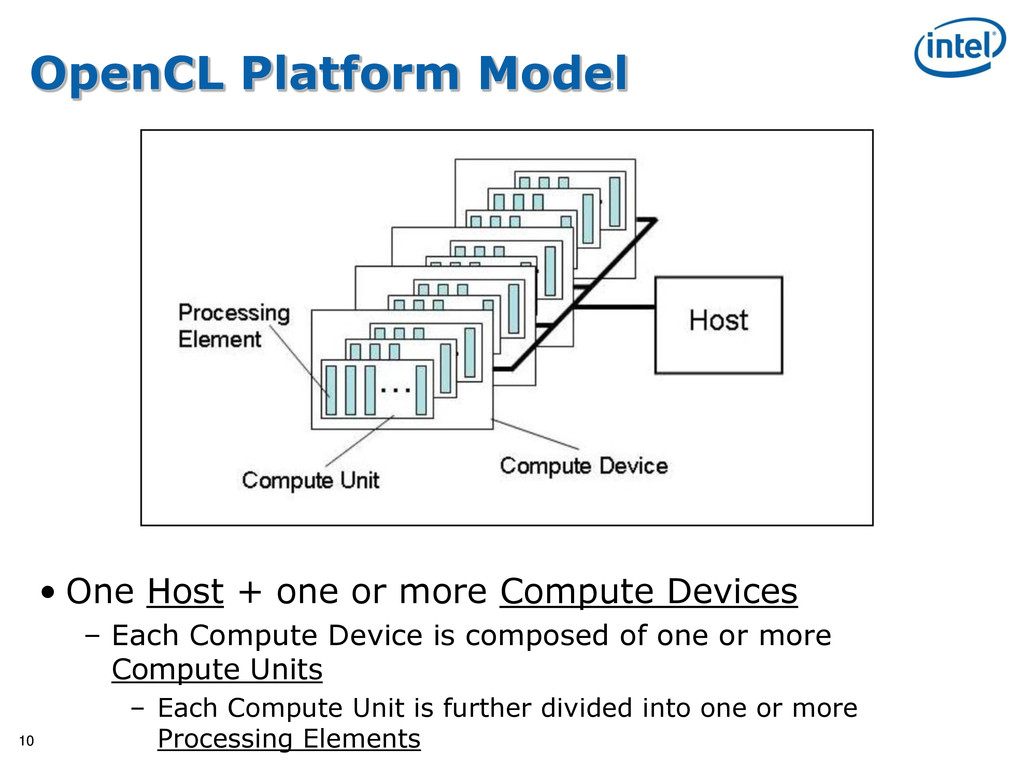{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![18 18 arg [0] value arg [1] value arg [2]](https://files.speakerdeck.com/presentations/0a20dbd05cf70130de5422000a1e8ec5/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}