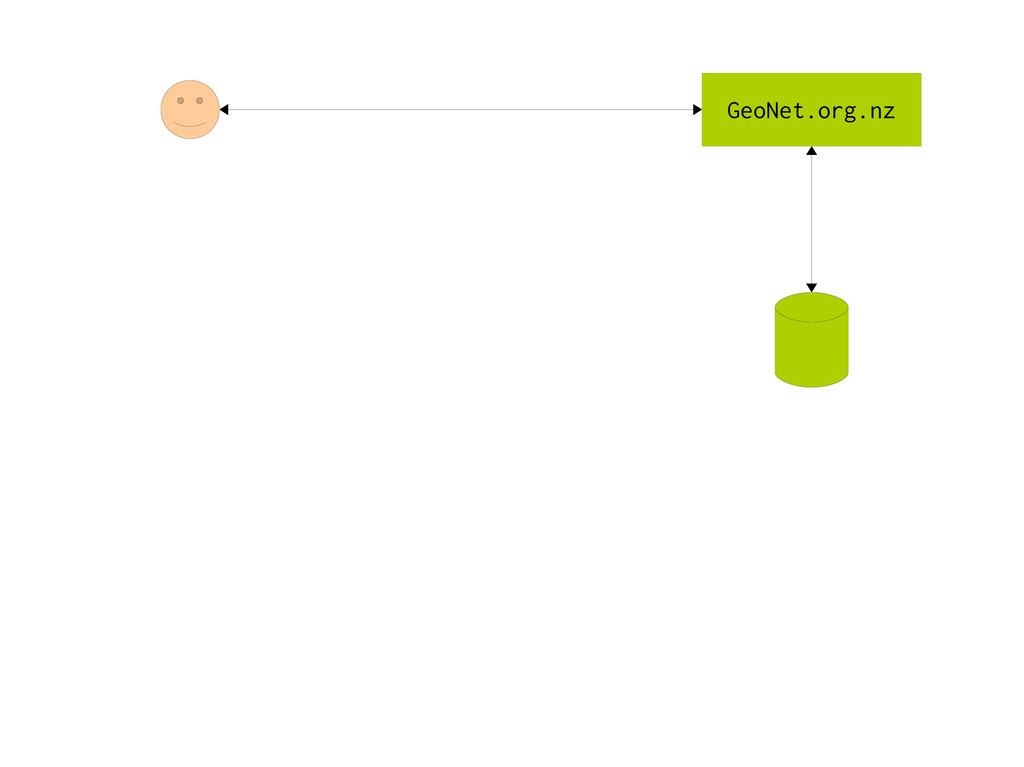
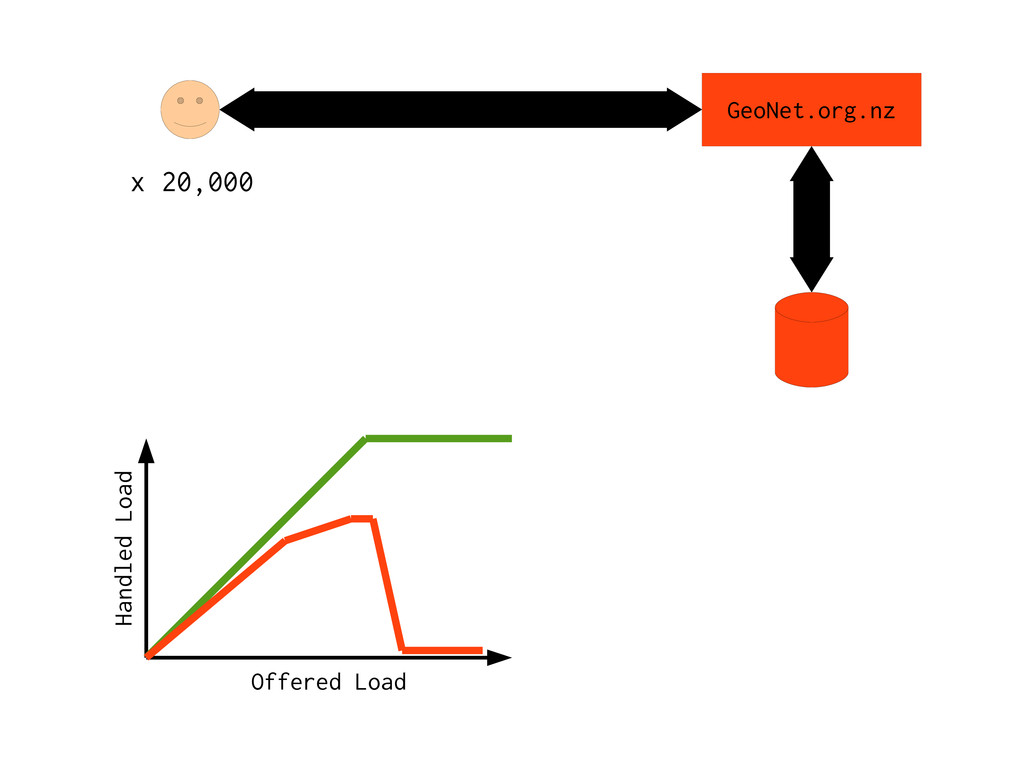
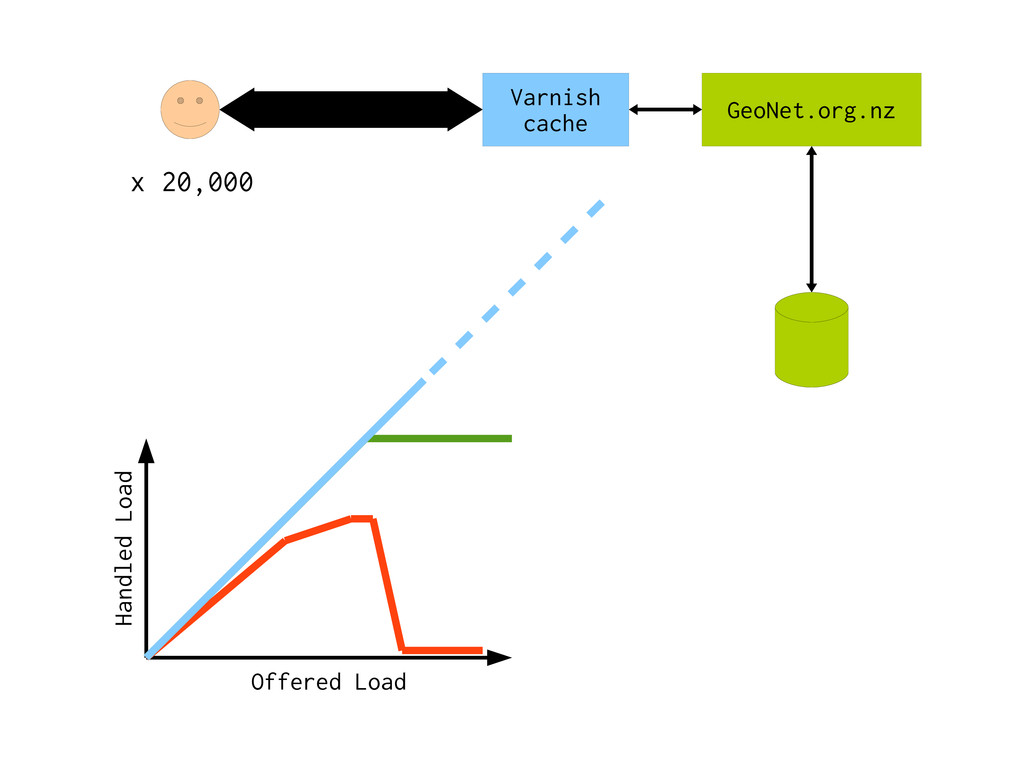
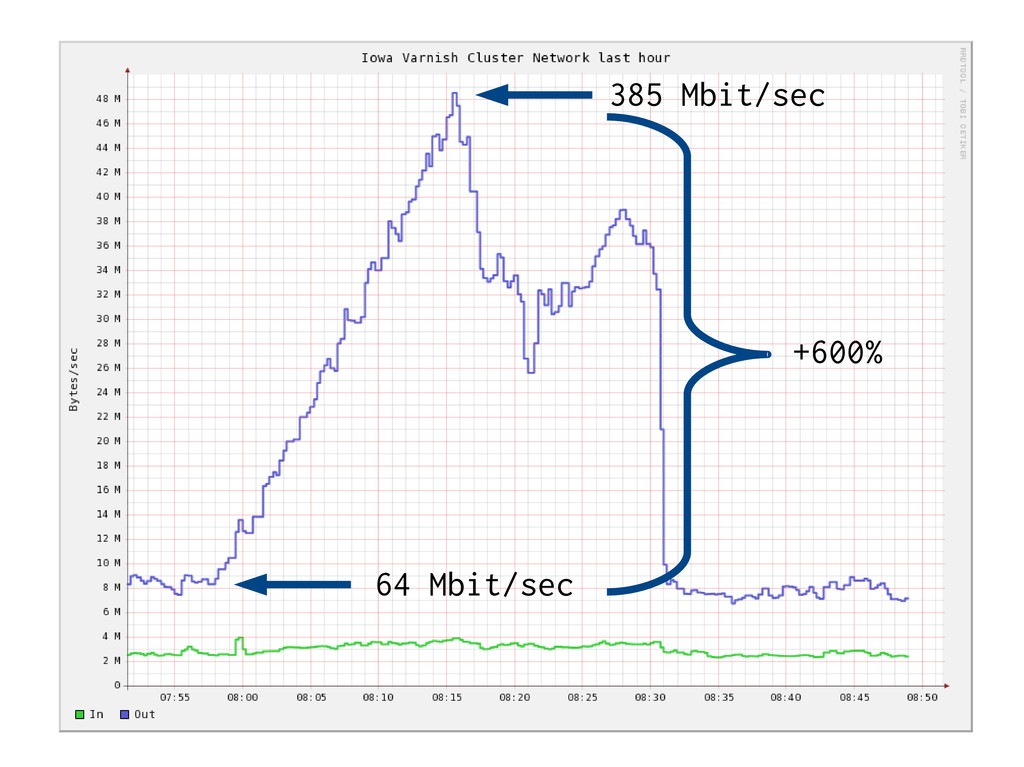
data * Many kinds of data * Layout rules * Policy rules * Taste * Design Content Delivery * Just make copies * High speed * High volume CMS Varnish
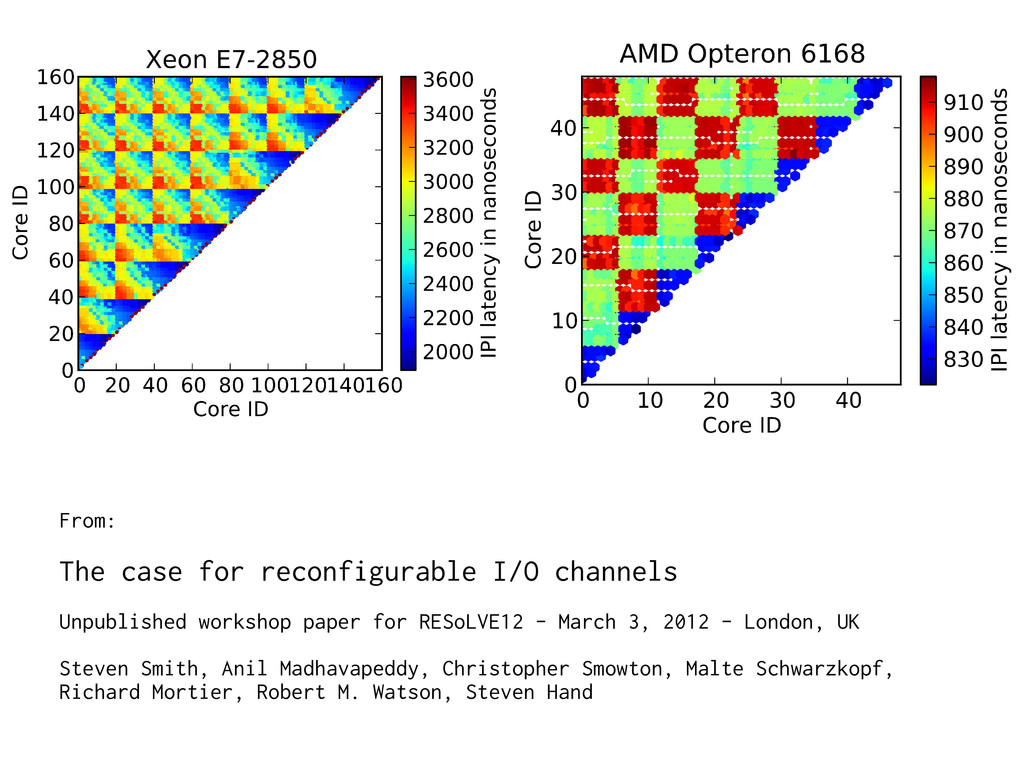
for RESoLVE12 - March 3, 2012 - London, UK Steven Smith, Anil Madhavapeddy, Christopher Smowton, Malte Schwarzkopf, Richard Mortier, Robert M. Watson, Steven Hand
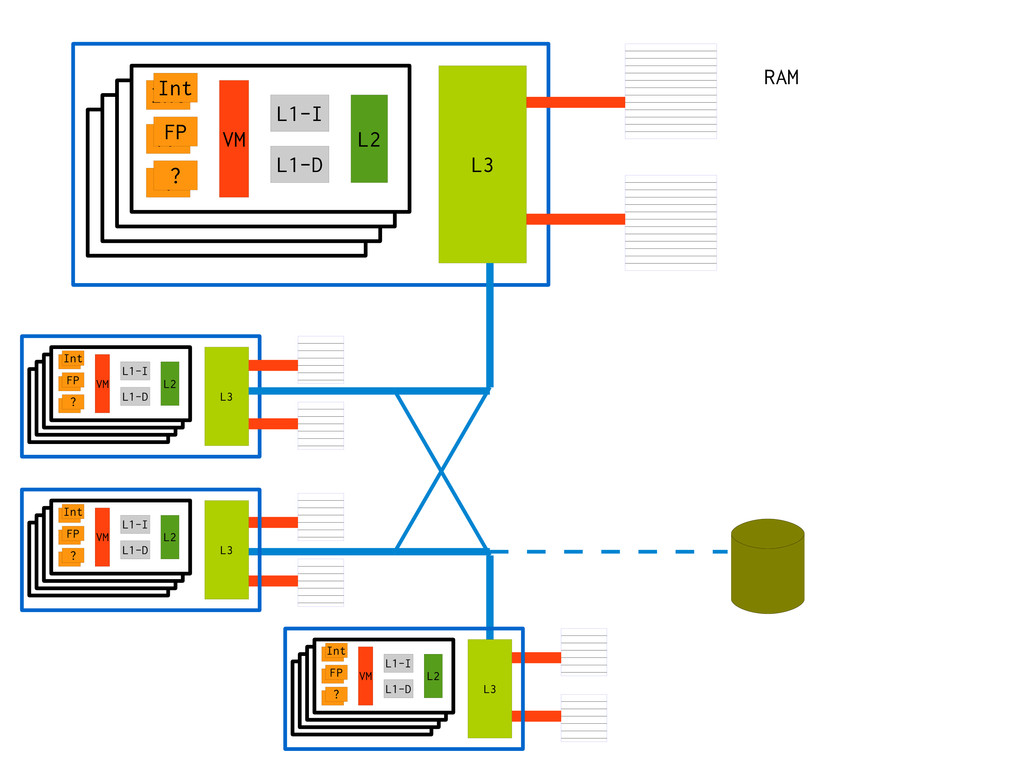
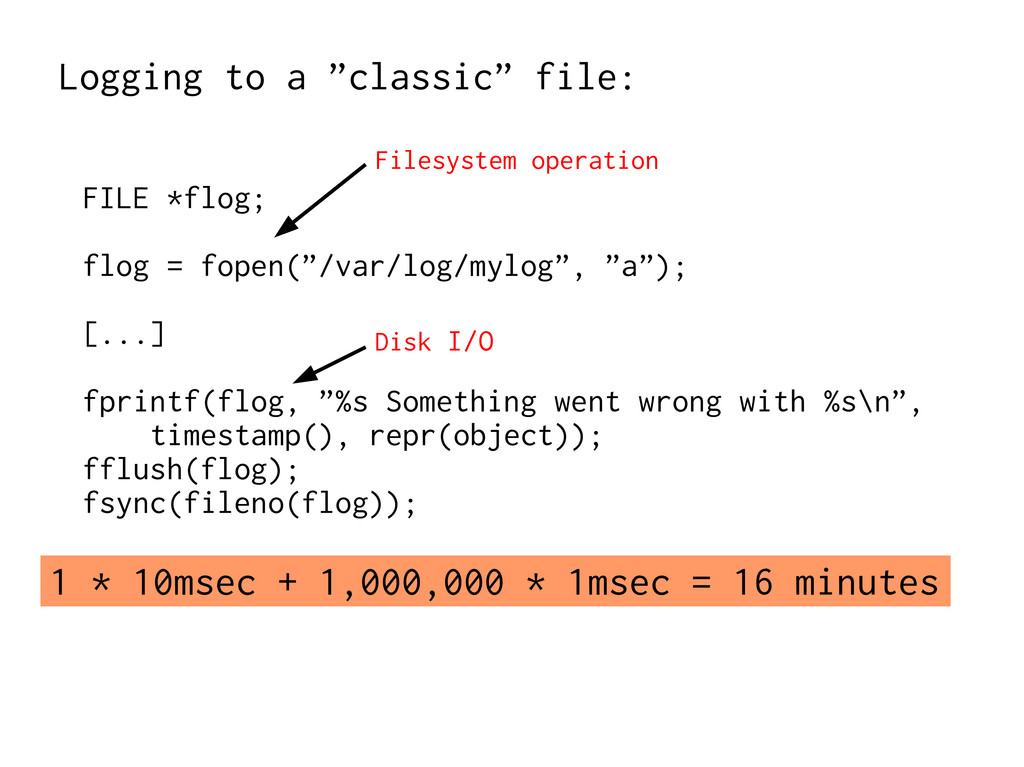
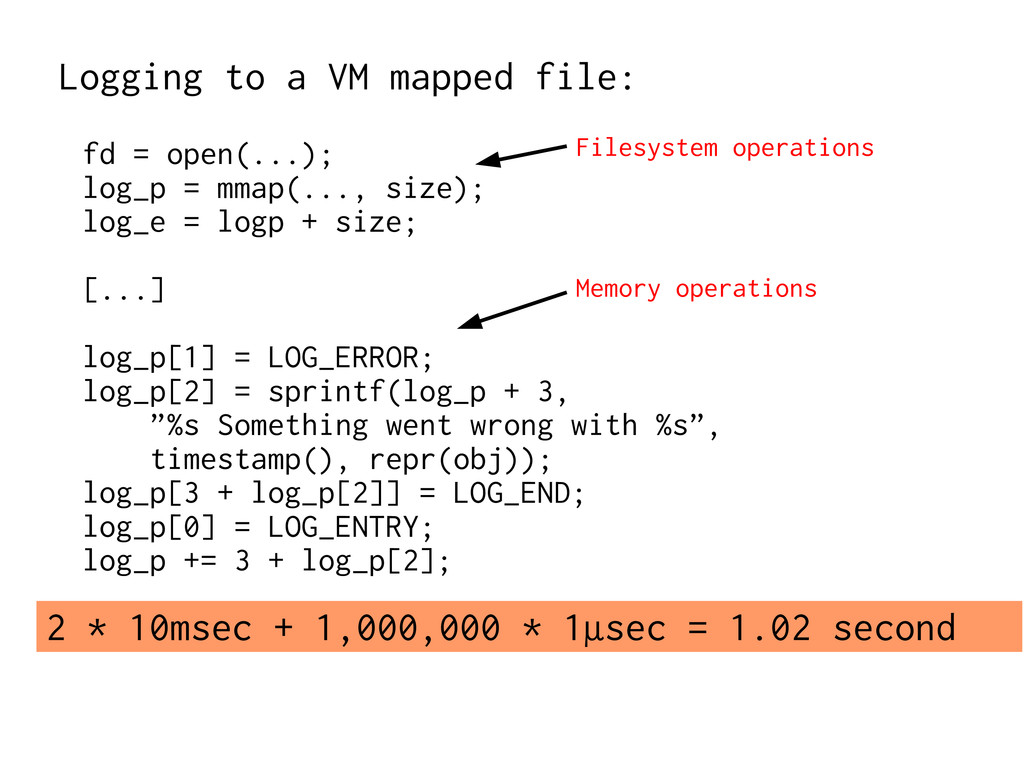
speed, isotropic – Shared Caches Layers, gradually slower, anisotropic – Peristent Objects Very high latency – VM mapping Screw things up, slow things down –
or SIGKILL ?' Well, to tell you the truth, in all this excitement I kind of lost track myself... But being as this is SIGKILL, the most powerful signal in UNIX, and would blow your address space clean off, you've got to ask yourself one question: 'Do I feel lucky?' Well, do ya, proc? Go Ahead, Fight my Kernel...
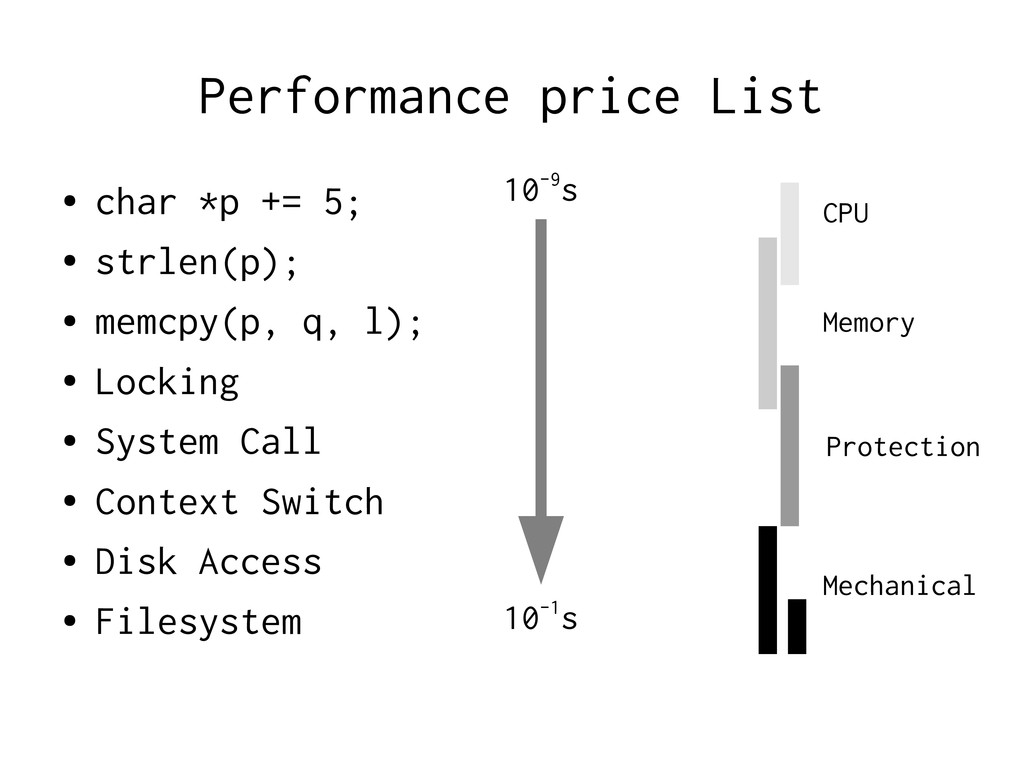
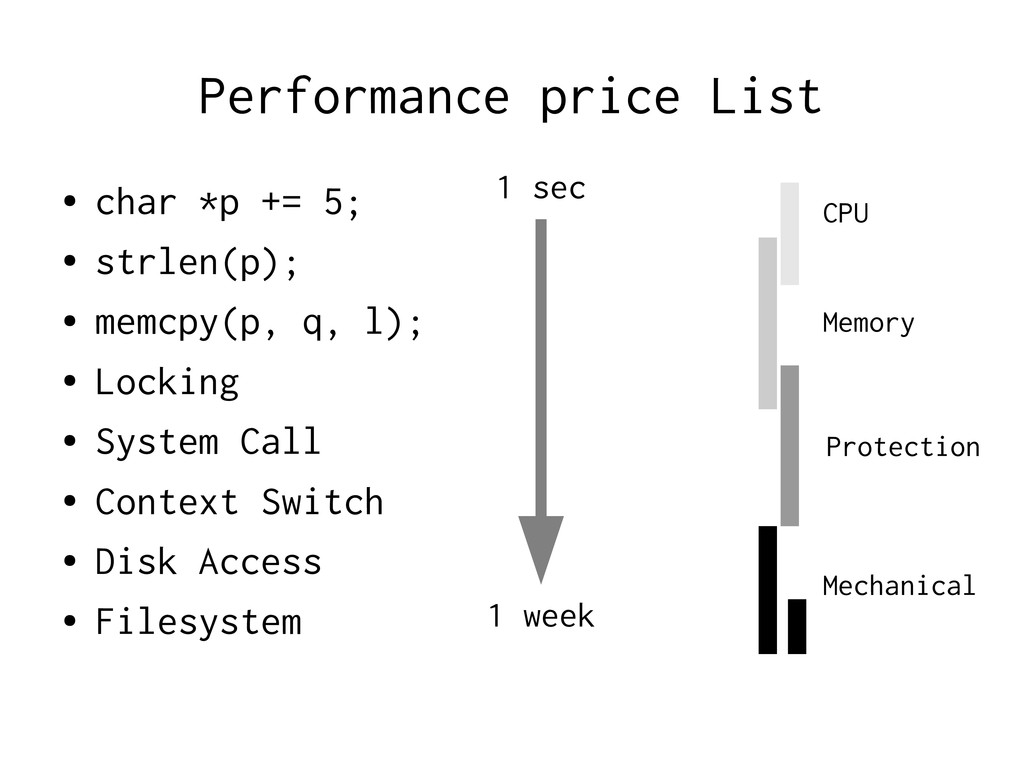
really is • Exploit the envelope of your requirements • Avoid unecessary work • Use few cheap operations • Use even fewer expensive operations • Don't fight the kernel • Use the smart kernel-features we gave you
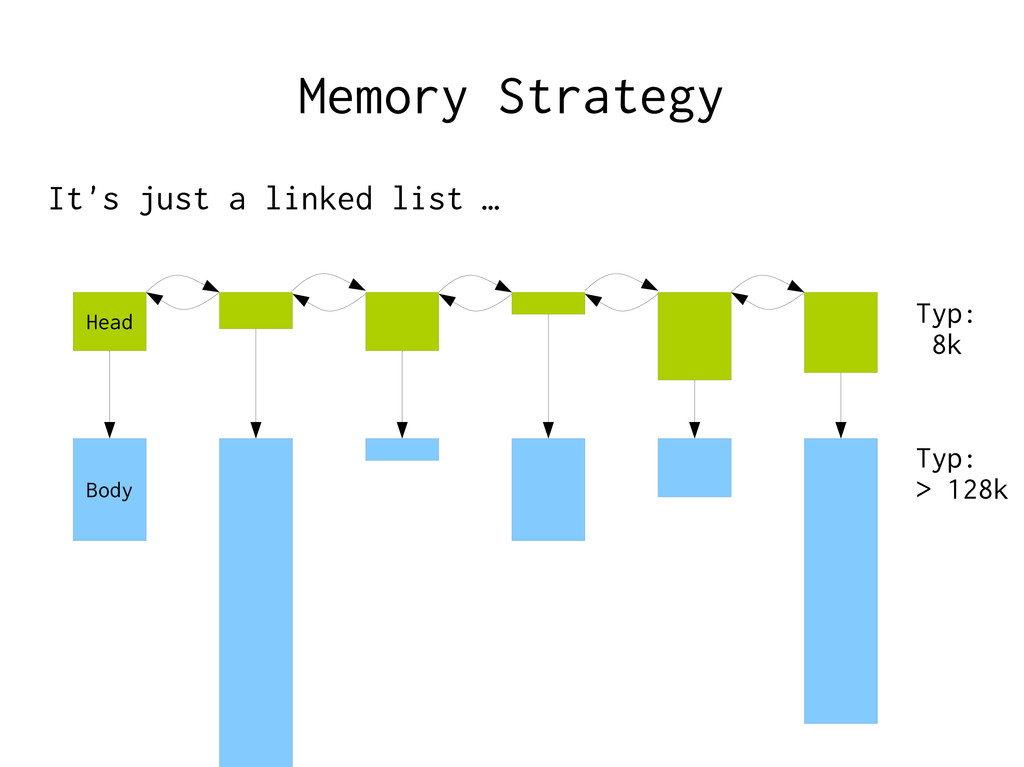
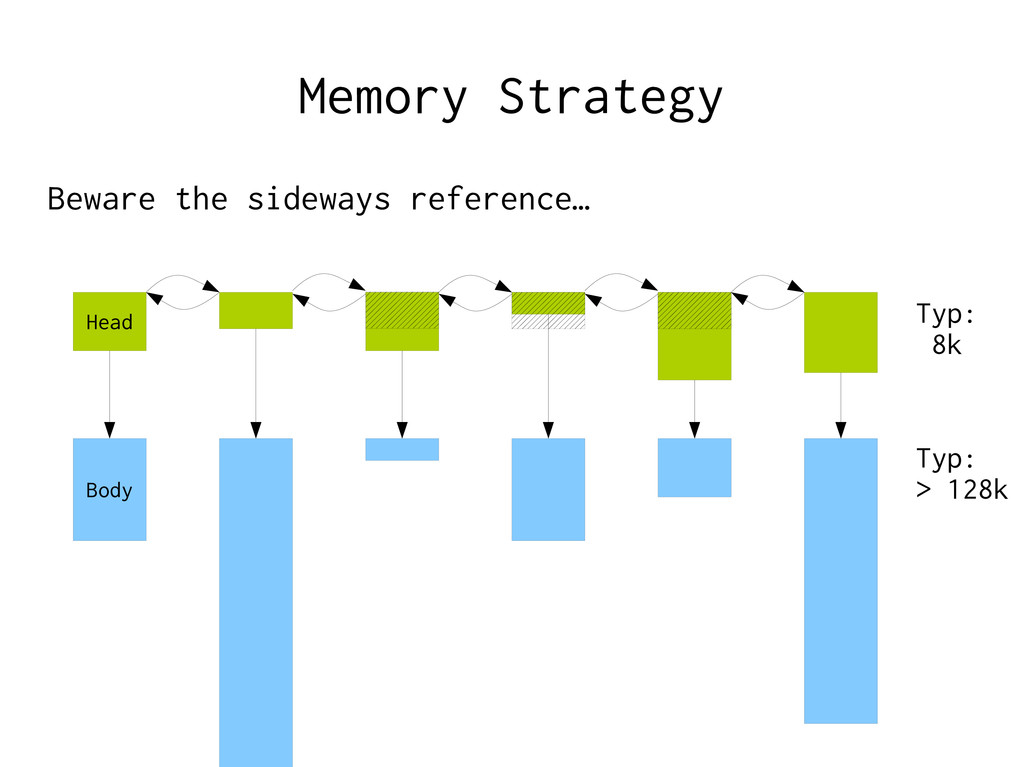
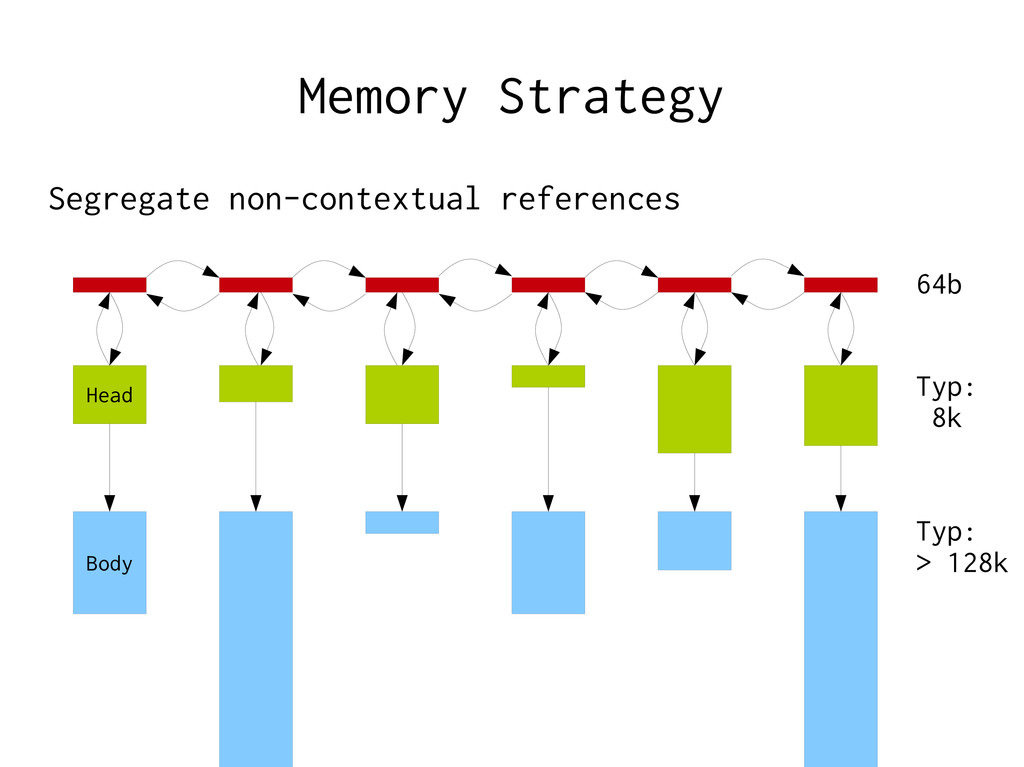
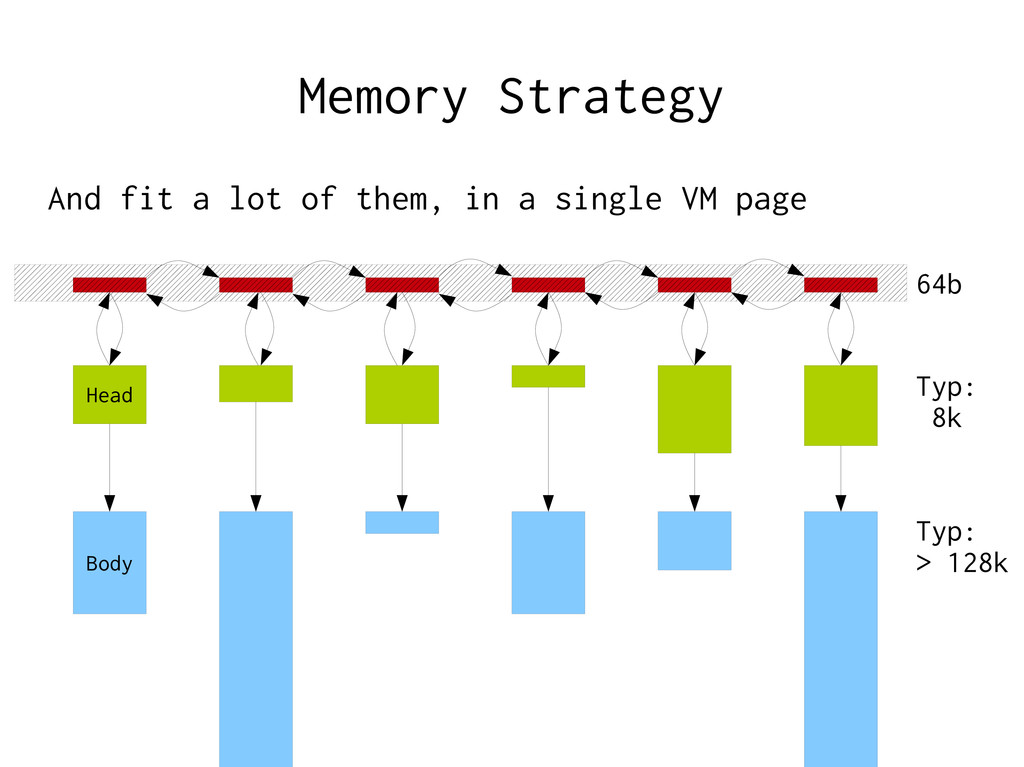
Using malloc(3) – malloc(3) manipulates a global state Locking → Give each thread a local ”workspace” – Reset when request done, ready for next request
… – Has been doing nothing for the longest time – Has nothing in L1 cache – Has nothing in L2 cache – Has nothing in L3 cache – May not even be in RAM at all = The guaranteed slowest thread you can pick
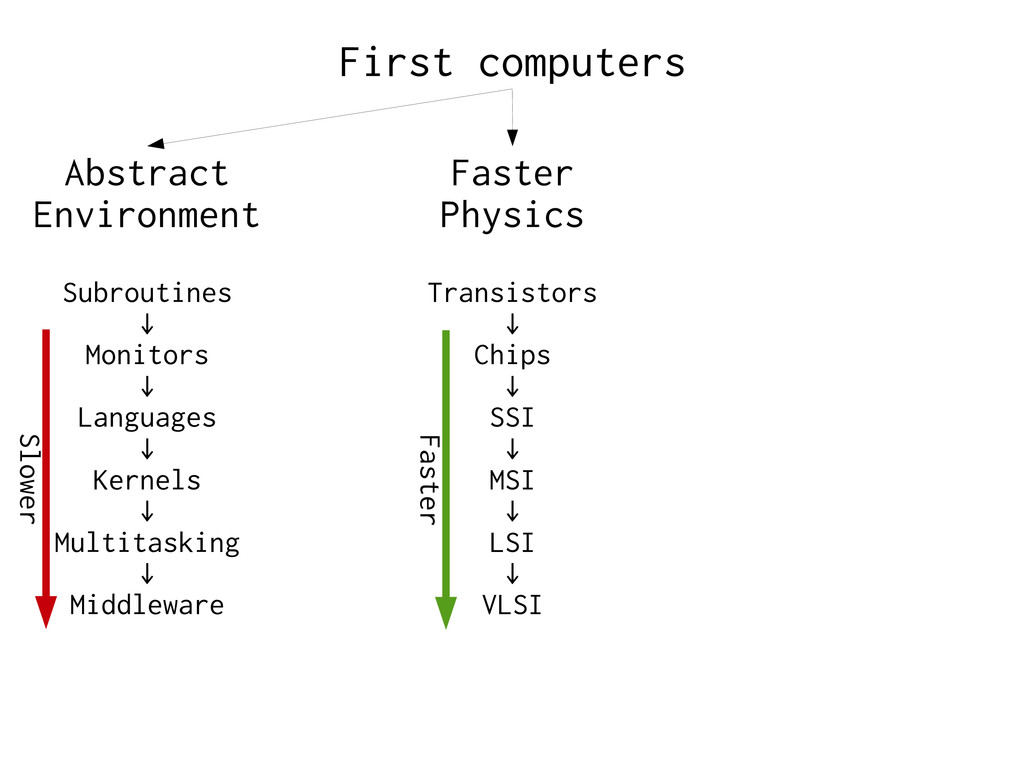
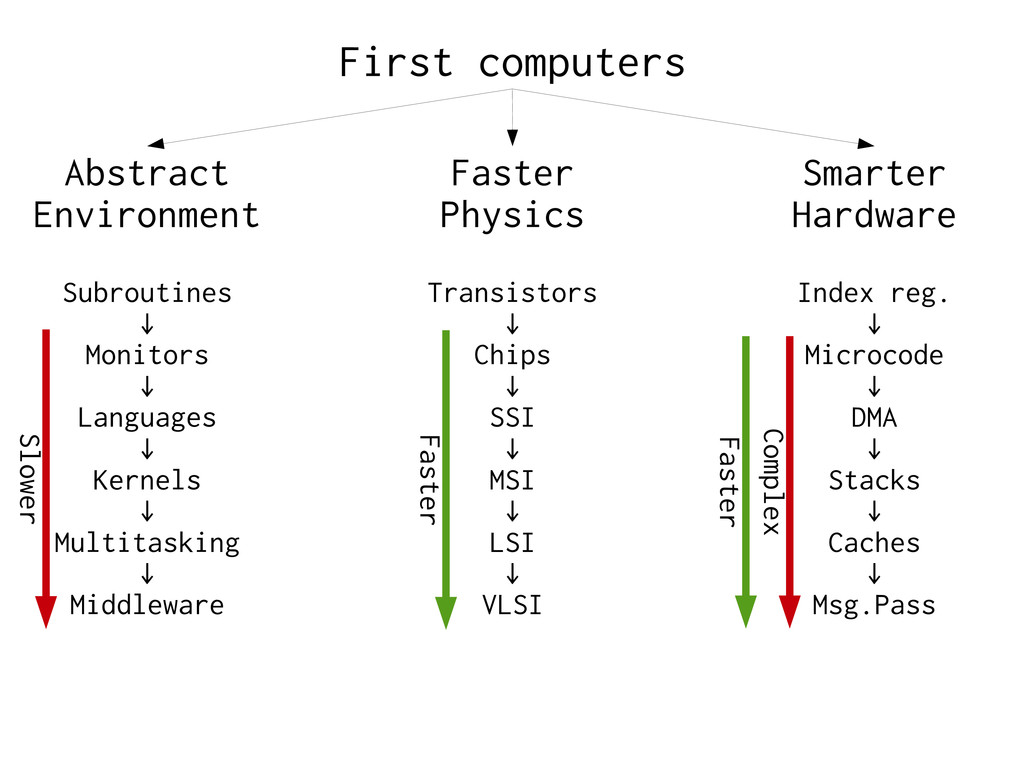
Algorithm: Do something faster → Architecture: Do fewer slow things Virtual Memory is expensive to ignore → Most O(foo) estimates are invalid with VM. ” → Just add more RAM” does not help on MPP
var·nished, var·nish·ing, var·nish·es 1. To cover with varnish. 2. To give a smooth and glossy finish to. 3. To give a deceptively attractive appearance to; gloss over.
movie theatres are big TV's. But imagine you gave them a compute cluster... Randomized battle-scenes ? Audience Cameos ? CGI approaching theaters ”unique each evening” ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![var·nish (värʹnĭsh) n. 1. a. A paint containing [...] tr.v.](https://files.speakerdeck.com/presentations/0d707b9059d60130b5ab22000a8f8802/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
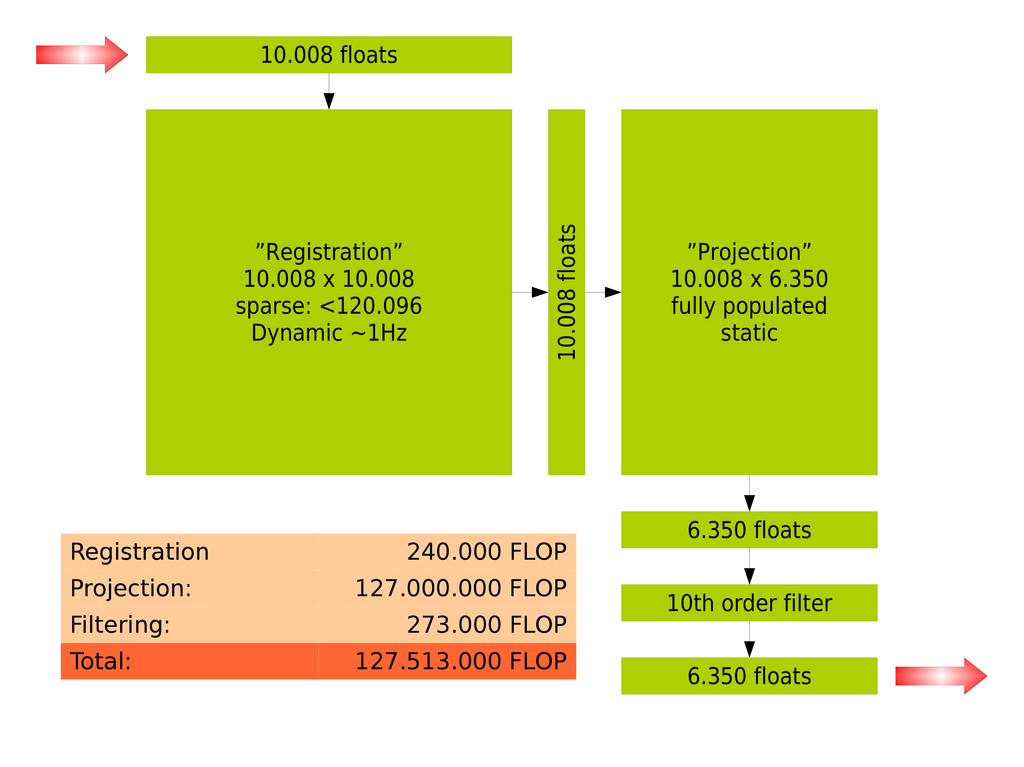{kind=link}
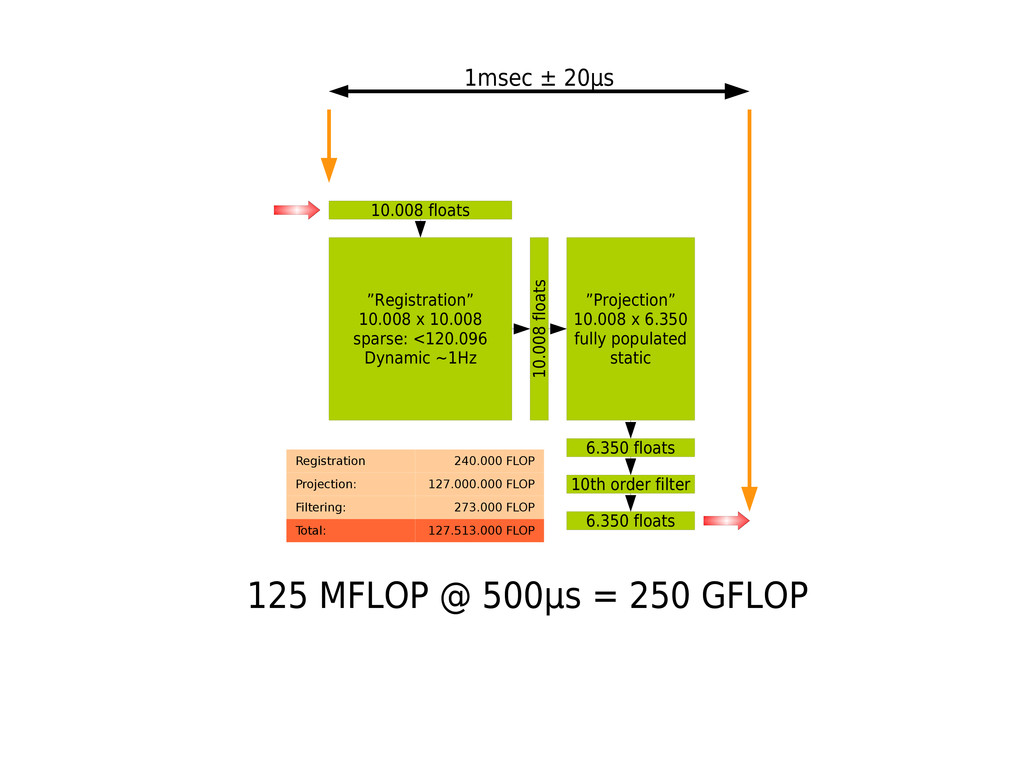{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}