Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Intro to scikit-learn
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Olivier Grisel
August 27, 2017
Technology
750
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Intro to scikit-learn
EuroScipy 2017
Olivier Grisel
August 27, 2017
More Decks by Olivier Grisel
See All by Olivier Grisel
An Intro to Deep Learning
ogrisel
1
340
Predictive Modeling and Deep Learning
ogrisel
2
400
Intro to scikit-learn and what's new in 0.17
ogrisel
1
420
Big Data, Predictive Modeling and tools
ogrisel
2
340
Recent Developments in Deep Learning
ogrisel
3
730
Documentation
ogrisel
2
280
How to use scikit-learn to solve machine learning problems
ogrisel
0
1.1k
Build and test wheel packages on Linux, OSX and Windows
ogrisel
2
370
Big Data and Predictive Modeling
ogrisel
3
260
Other Decks in Technology
See All in Technology
CIで使うClaude
iwatatomoya
0
230
Claude Codeとハーネスについて考えてみる
oikon48
18
9.3k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
270
DatabricksにおけるMCPソリューション
taka_aki
1
230
はじめてのWDM
miyukichi_ospf
1
140
貴方はどのエンジニアリングを磨くのか
hatyibei
0
120
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
ゼロをイチにする仕事が終わったあと
smasato
0
330
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.8k
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
290
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
110
Featured
See All Featured
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
WENDY [Excerpt]
tessaabrams
11
38k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Transcript
Intro to scikit-learn EuroScipy 2017 - Olivier Grisel - Tim
Head
Outline • Machine Learning refresher • scikit-learn • Hands on:
interactive predictive modeling on Census Data with Jupyter notebook / pandas / scikit-learn • Hands on: parameter tuning with scikit-optimize
Predictive modeling ~= machine learning • Make predictions of outcome
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
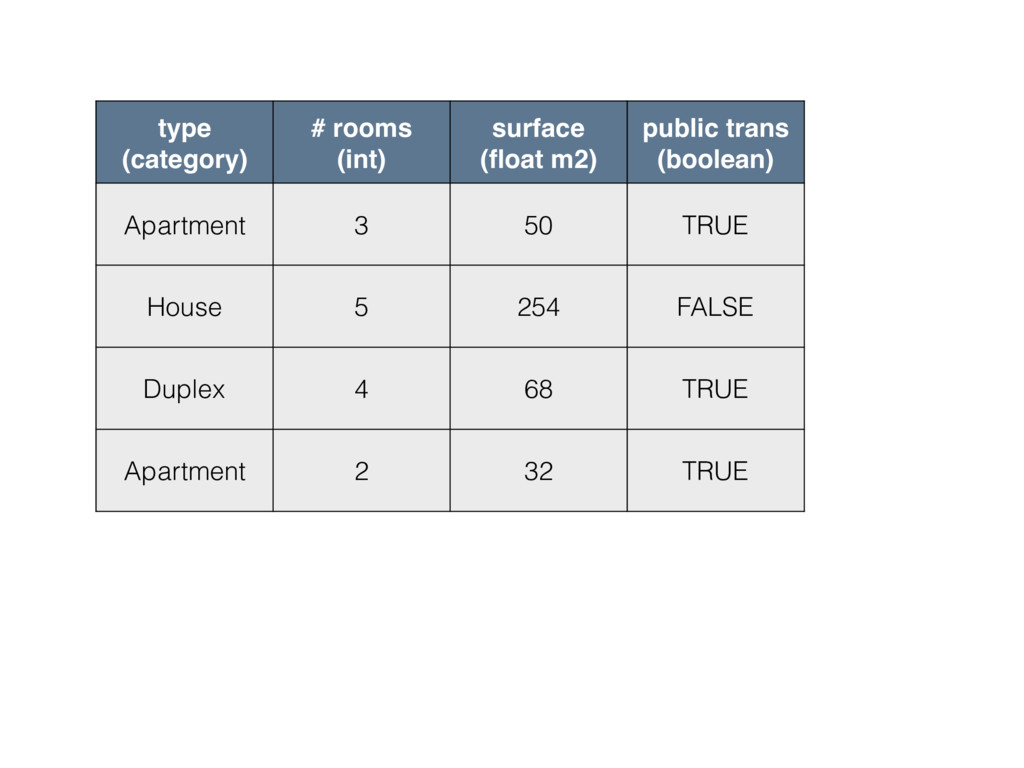
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE
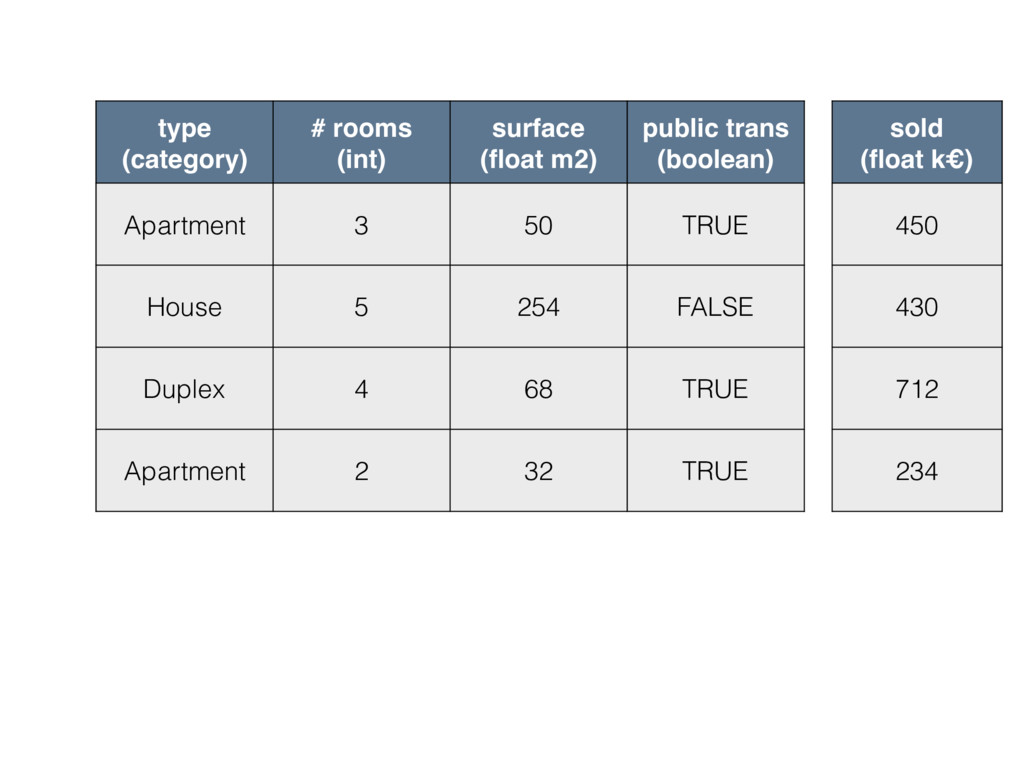
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234
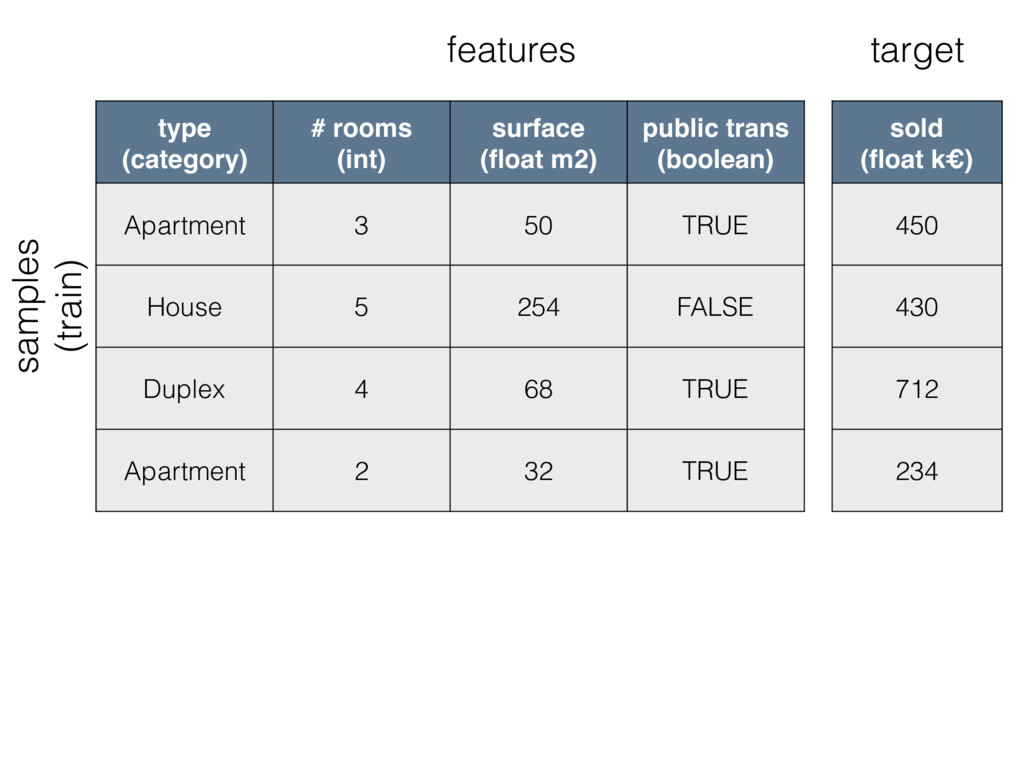
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train)
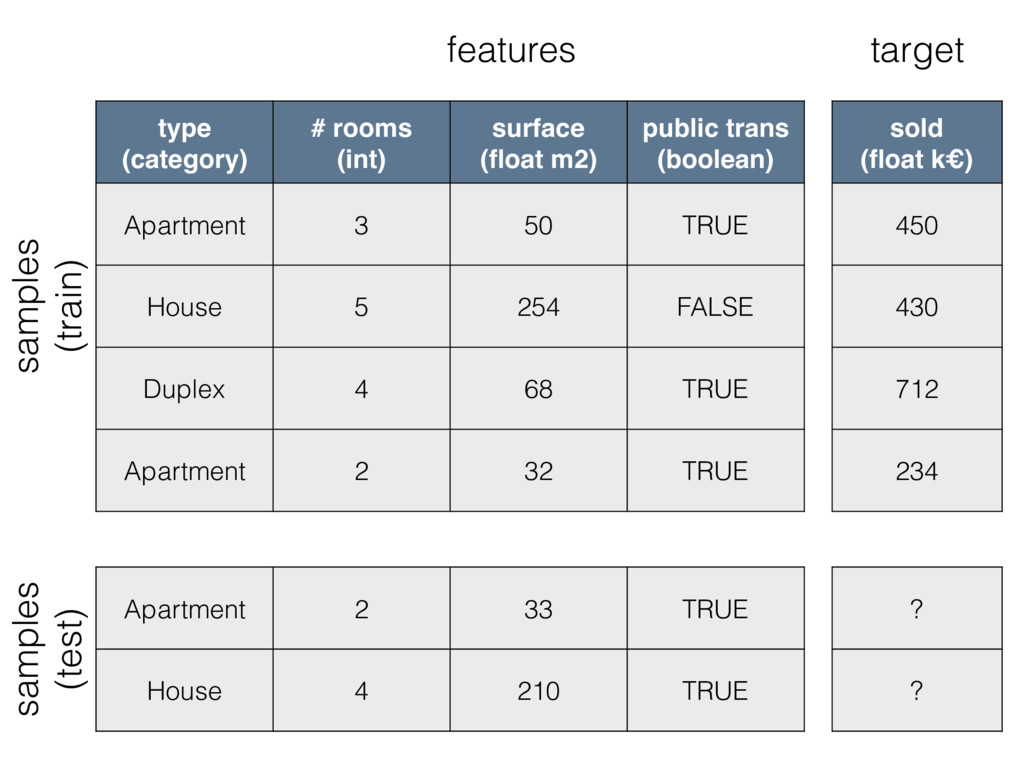
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train) Apartment 2 33 TRUE House 4 210 TRUE samples (test) ? ?
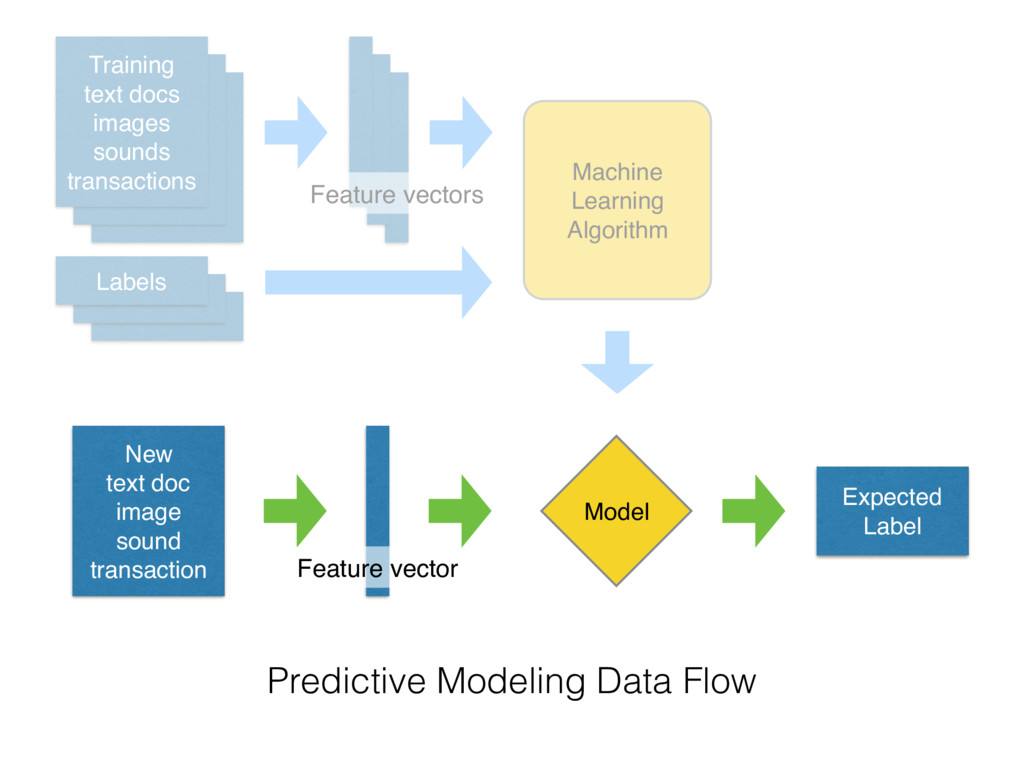
Training text docs images sounds transactions Labels Machine Learning Algorithm
Model Predictive Modeling Data Flow Feature vectors
New text doc image sound transaction Model Expected Label Predictive
Modeling Data Flow Feature vector Training text docs images sounds transactions Labels Machine Learning Algorithm Feature vectors
Inventory forecasting & trends detection Predictive modeling in the wild
Personalized radios Fraud detection Virality and readers engagement Predictive maintenance Personality matching
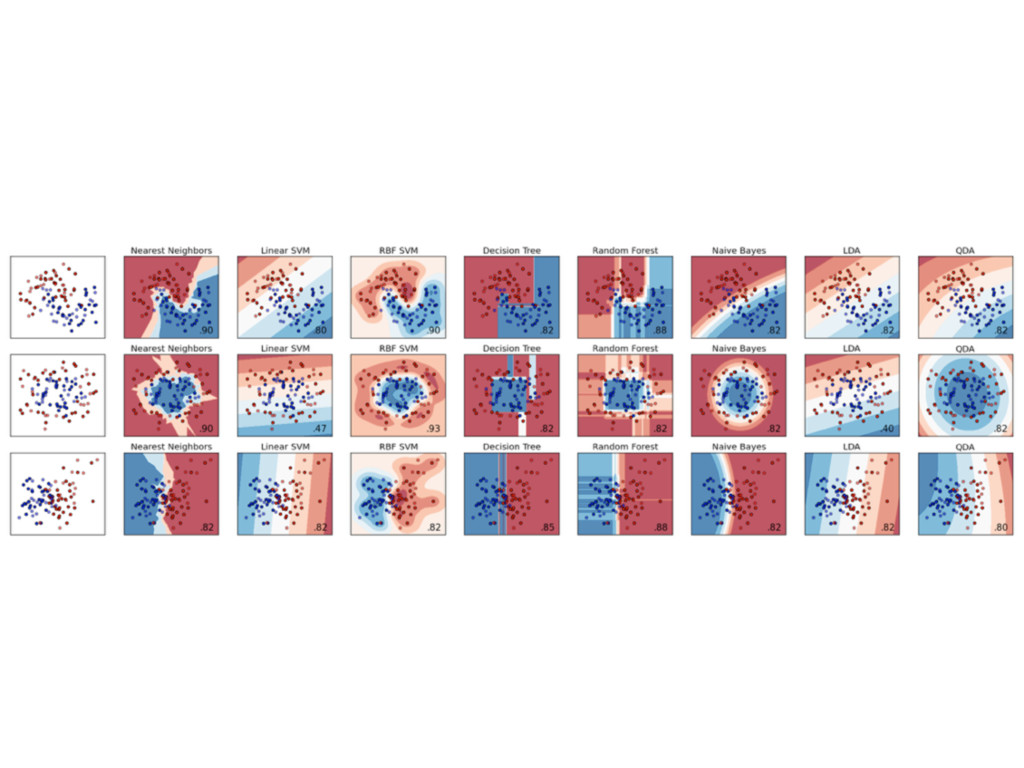
• Library of Machine Learning algorithms • Focus on established
methods (e.g. ESL-II) • Open Source (BSD) • Simple fit / predict / transform API • Python / NumPy / SciPy / Cython • Model Assessment, Selection & Ensembles
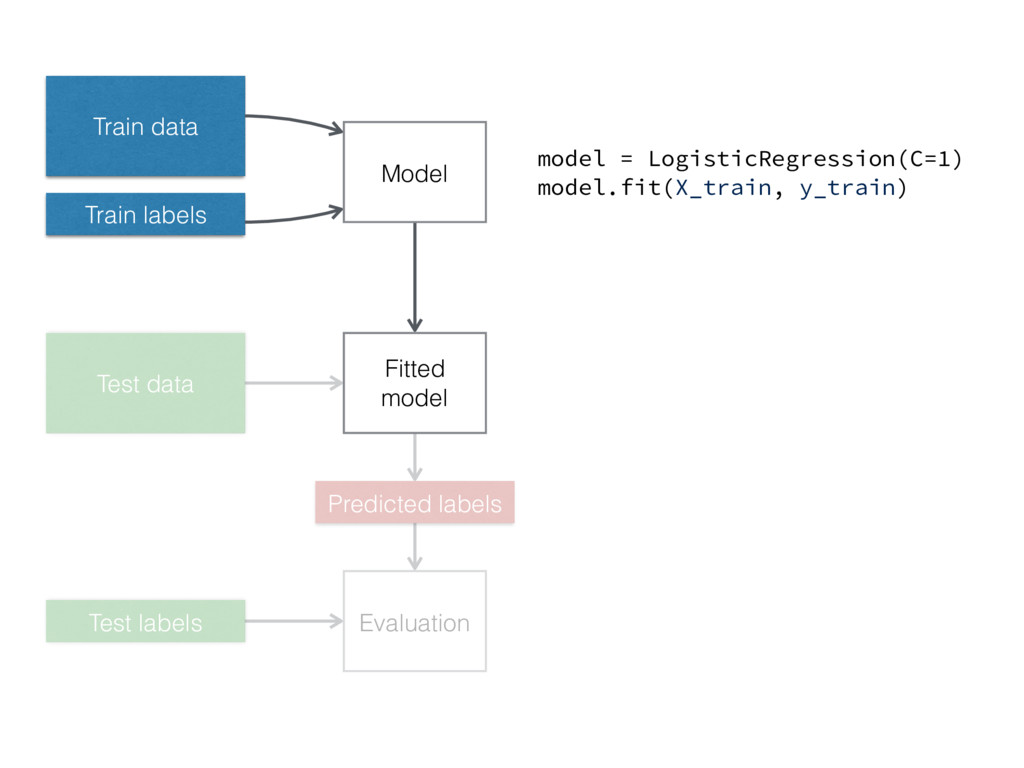
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train)
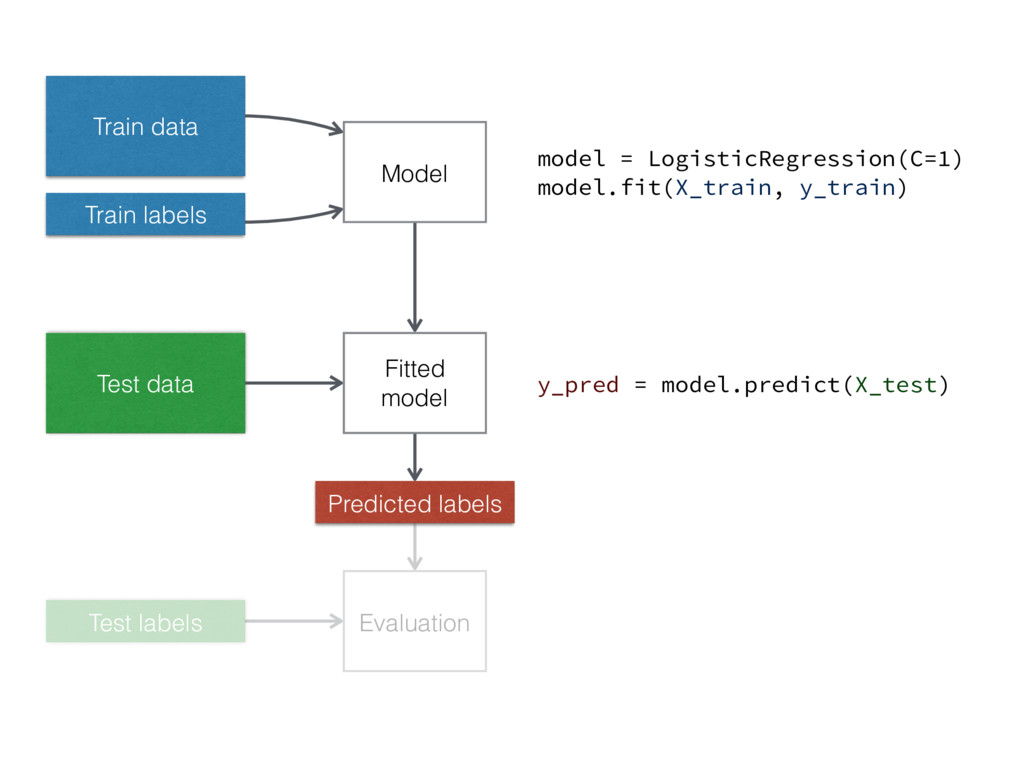
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train) y_pred = model.predict(X_test)
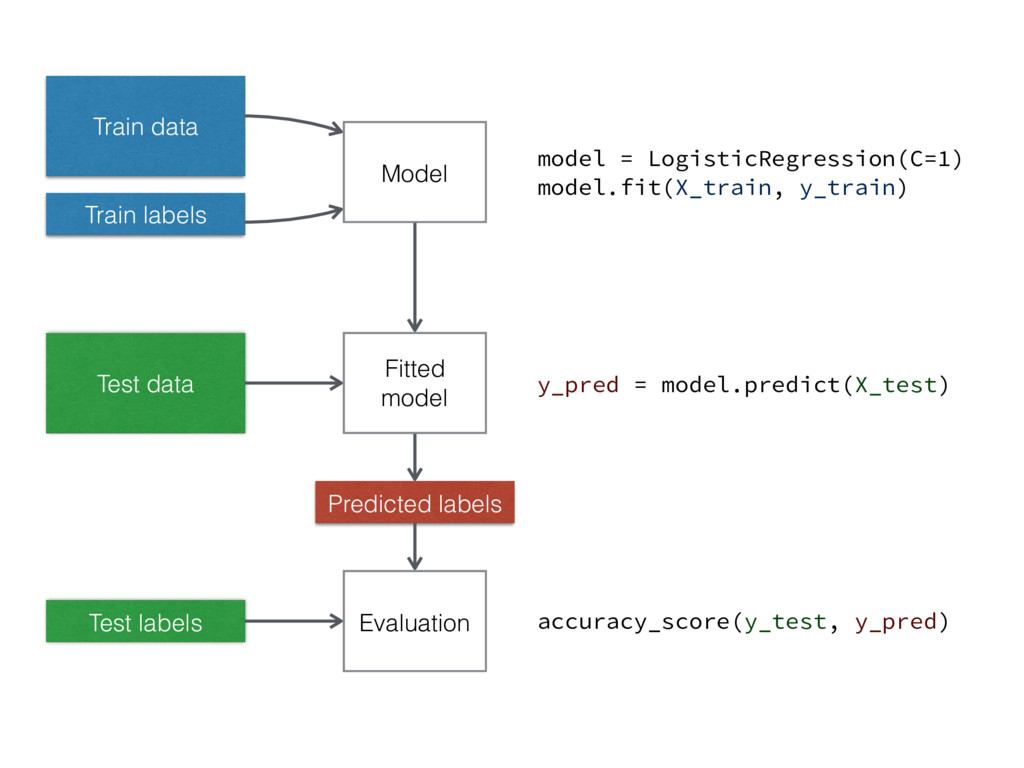
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
Support Vector Machine from sklearn.svm import SVC model = SVC(kernel="rbf",
C=1.0, gamma=1e-4) model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Linear Classifier from sklearn.linear_model import SGDClassifier model = SGDClassifier(alpha=1e-4, penalty="elasticnet")
model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Random Forests from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200) model.fit(X_train,
y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
None
None
Workshop time! https://github.com/ogrisel/euroscipy_2017_sklearn
Combining Models from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train)
Pipeline from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA from
sklearn.svm import SVC from sklearn.pipeline import make_pipeline pipeline = make_pipeline( StandardScaler(), RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), ) pipeline.fit(X_train, y_train)
Scoring manually stacked models scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)
pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train) X_test_scaled = scaler.transform(X_test) X_test_pca = pca.transform(X_test_scaled) y_pred = svm.predict(X_test_pca) accuracy_score(y_test, y_pred)
Scoring a pipeline pipeline = make_pipeline( RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), )
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred)
Parameter search import numpy as np from sklearn.grid_search import RandomizedSearchCV
params = { 'randomizedpca__n_components': [5, 10, 20], 'svc__C': np.logspace(-3, 3, 7), 'svc__gamma': np.logspace(-6, 0, 7), } search = RandomizedSearchCV(pipeline, params, n_iter=30, cv=5) search.fit(X_train, y_train) # search.best_params_, search.grid_scores_
Thank you! • http://scikit-learn.org • https://github.com/scikit-learn/scikit-learn @ogrisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}