Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How to use scikit-learn to solve machine learni...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Olivier Grisel
April 22, 2015
Technology
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
How to use scikit-learn to solve machine learning problems
AutoML Hackathon - Paris - April 2015
Olivier Grisel
April 22, 2015
More Decks by Olivier Grisel
See All by Olivier Grisel
Intro to scikit-learn
ogrisel
5
750
An Intro to Deep Learning
ogrisel
1
340
Predictive Modeling and Deep Learning
ogrisel
2
400
Intro to scikit-learn and what's new in 0.17
ogrisel
1
420
Big Data, Predictive Modeling and tools
ogrisel
2
340
Recent Developments in Deep Learning
ogrisel
3
730
Documentation
ogrisel
2
280
Build and test wheel packages on Linux, OSX and Windows
ogrisel
2
370
Big Data and Predictive Modeling
ogrisel
3
260
Other Decks in Technology
See All in Technology
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
210
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
知らん間に、回ってる
ming_ayami
0
480
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
370
AICoEでAIネイティブ組織への進化
yukiogawa
0
160
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
100
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
230
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
10
6.6k
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Making Projects Easy
brettharned
120
6.7k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
YesSQL, Process and Tooling at Scale
rocio
174
15k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Transcript
How to use scikit-learn to solve machine learning problems AutoML
Hackathon April 2015
Outline • Machine Learning refresher • scikit-learn • Demo: interactive
predictive modeling on Census Data with IPython notebook / pandas / scikit-learn • Combining models with Pipeline and parameter search
Predictive modeling ~= machine learning • Make predictions of outcome
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
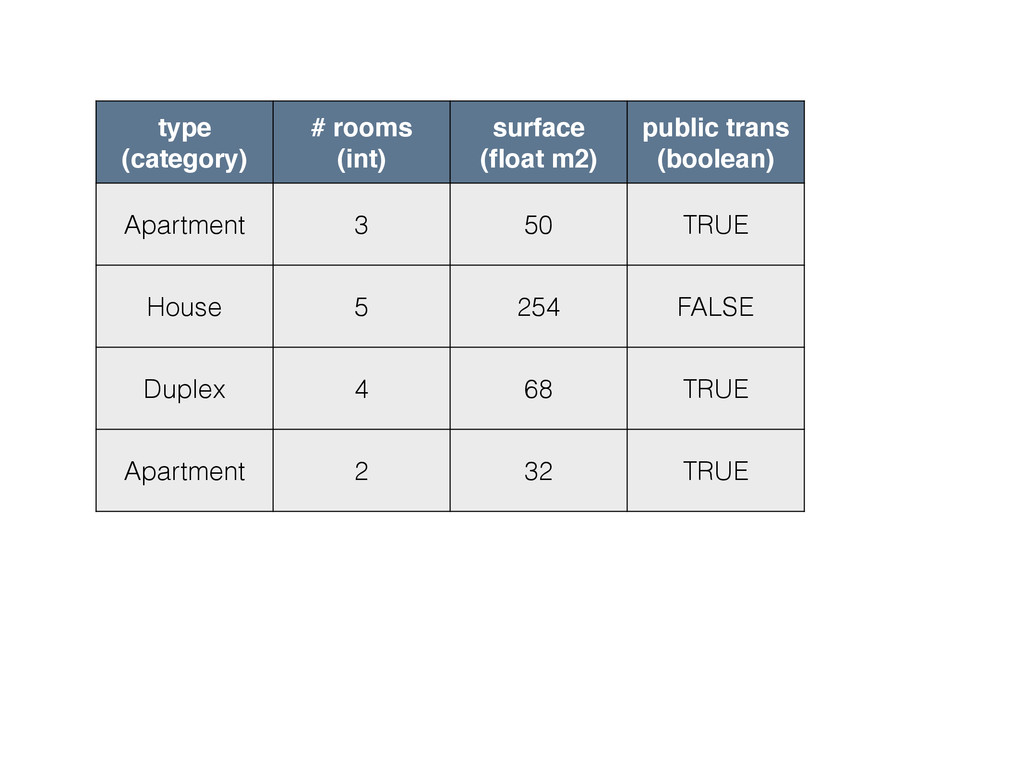
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE
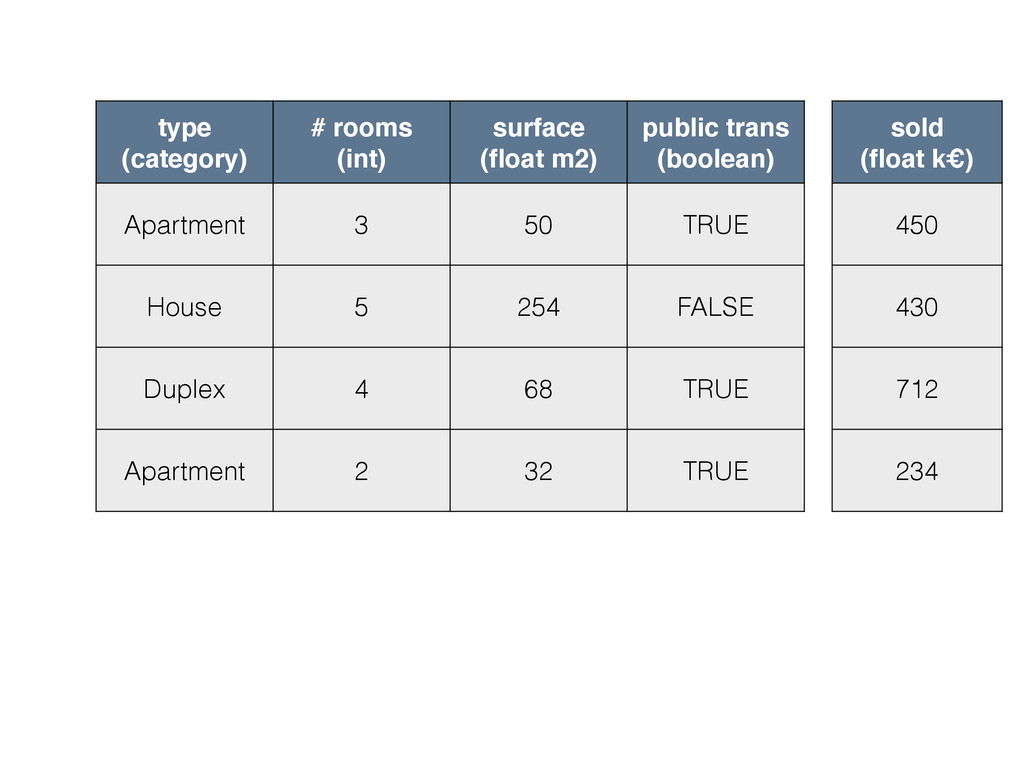
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234
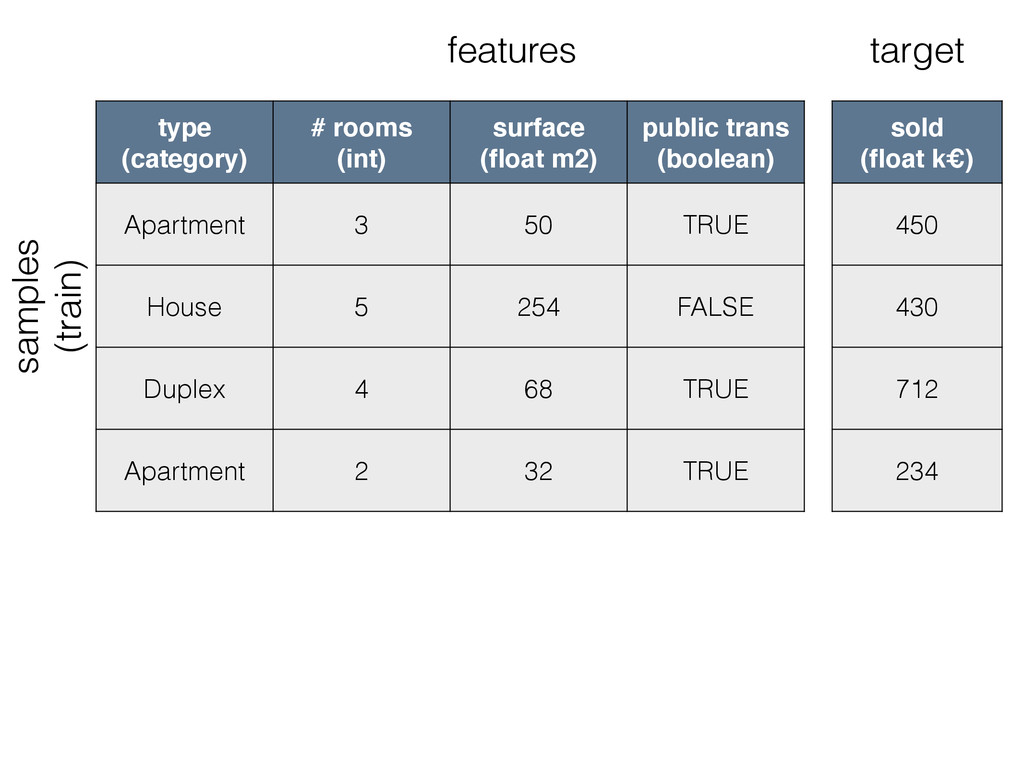
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train)
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train) Apartment 2 33 TRUE House 4 210 TRUE samples (test) ? ?
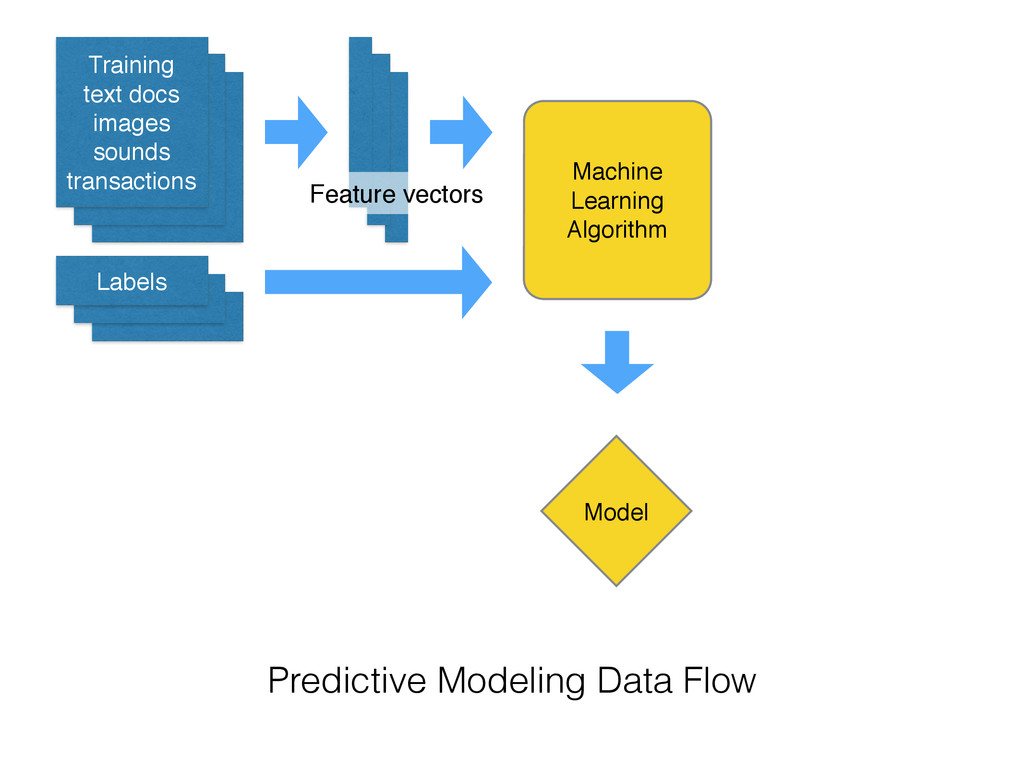
Training text docs images sounds transactions Labels Machine Learning Algorithm
Model Predictive Modeling Data Flow Feature vectors
New text doc image sound transaction Model Expected Label Predictive
Modeling Data Flow Feature vector Training text docs images sounds transactions Labels Machine Learning Algorithm Feature vectors
Inventory forecasting & trends detection Predictive modeling in the wild
Personalized radios Fraud detection Virality and readers engagement Predictive maintenance Personality matching
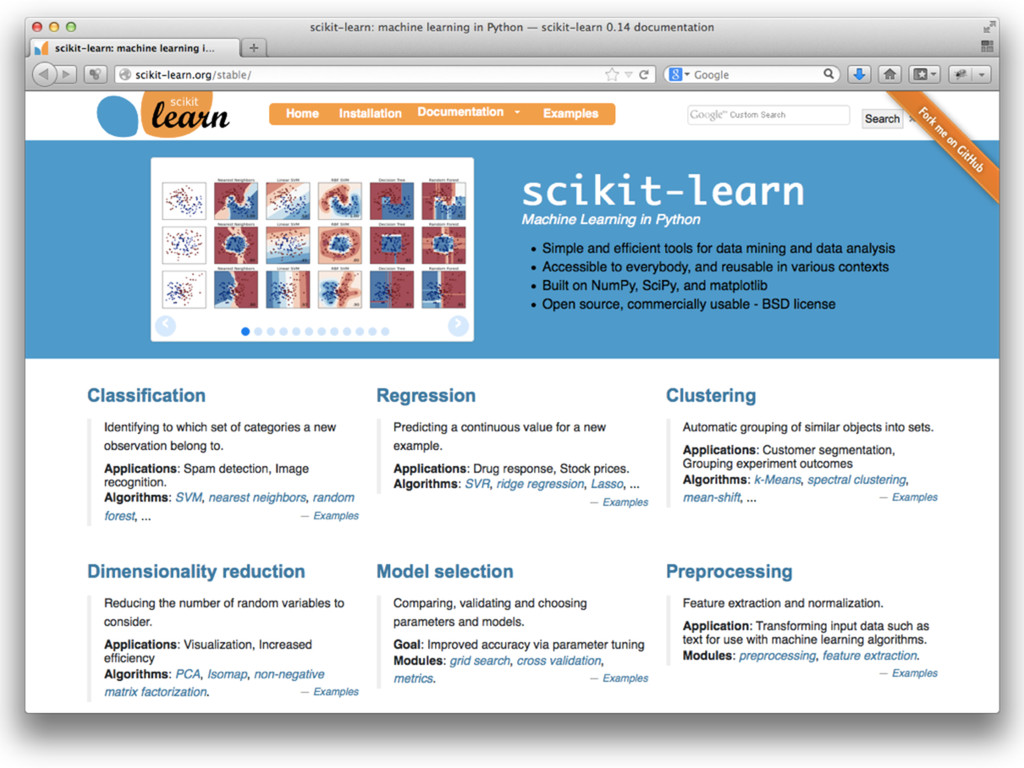
• Library of Machine Learning algorithms • Focus on established
methods (e.g. ESL-II) • Open Source (BSD) • Simple fit / predict / transform API • Python / NumPy / SciPy / Cython • Model Assessment, Selection & Ensembles
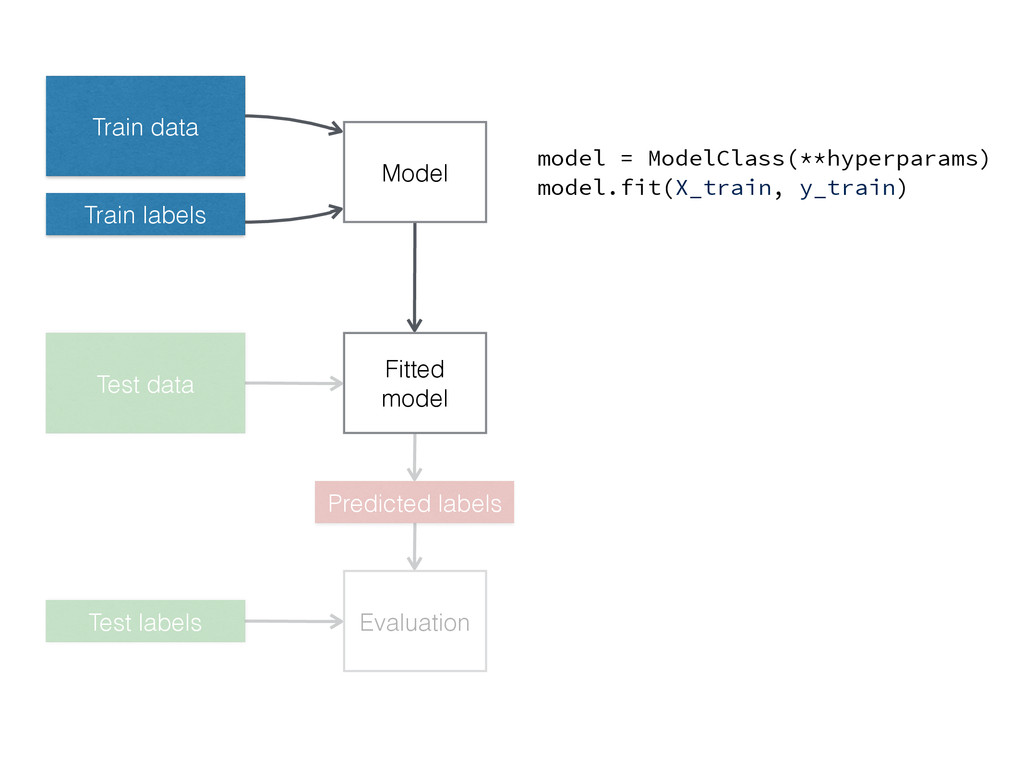
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train)
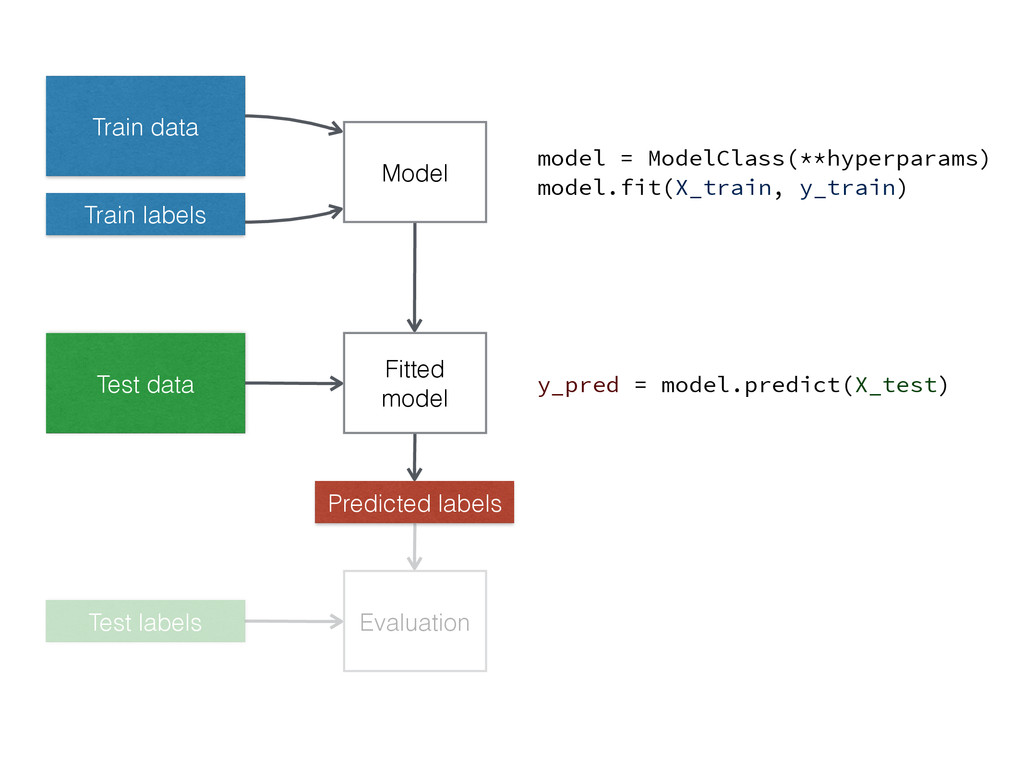
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test)
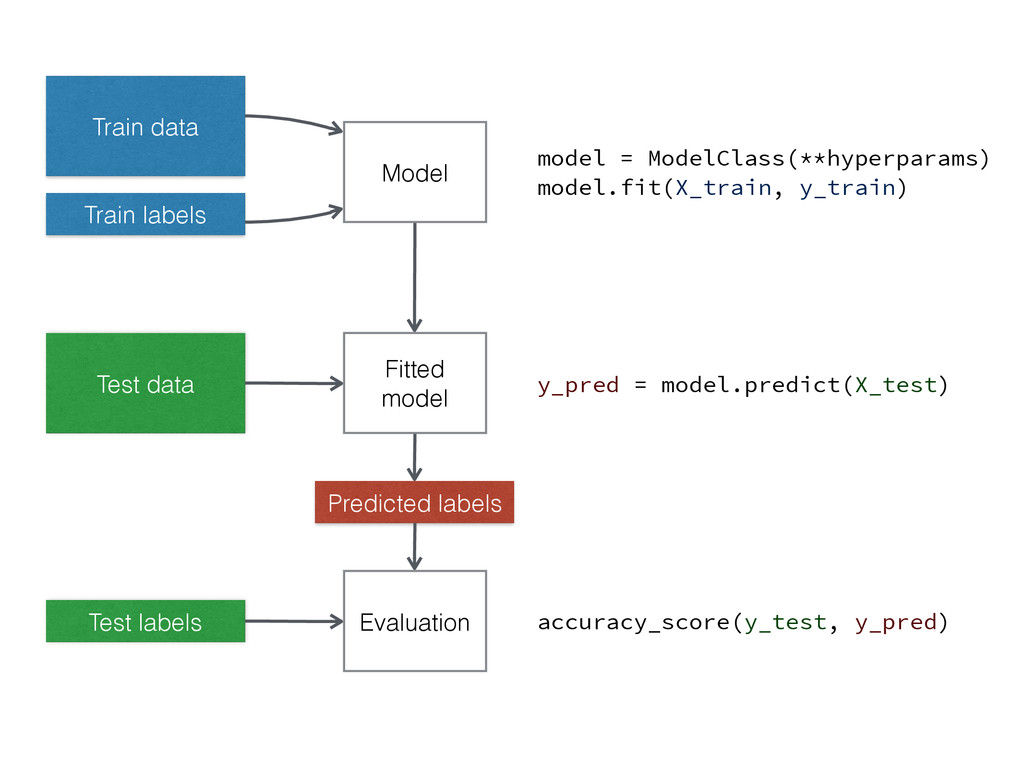
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
Support Vector Machine from sklearn.svm import SVC model = SVC(kernel="rbf",
C=1.0, gamma=1e-4) model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Linear Classifier from sklearn.linear_model import SGDClassifier model = SGDClassifier(alpha=1e-4, penalty="elasticnet")
model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Random Forests from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200) model.fit(X_train,
y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
None
None
Demo time! http://nbviewer.ipython.org/github/ogrisel/notebooks/blob/ master/sklearn_demos/Income%20classification.ipynb https://github.com/ogrisel/notebooks
Combining Models from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train)
Pipeline from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA from
sklearn.svm import SVC from sklearn.pipeline import make_pipeline pipeline = make_pipeline( StandardScaler(), RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), ) pipeline.fit(X_train, y_train)
Scoring manually stacked models scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)
pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train) X_test_scaled = scaler.transform(X_test) X_test_pca = pca.transform(X_test_scaled) y_pred = svm.predict(X_test_pca) accuracy_score(y_test, y_pred)
Scoring a pipeline pipeline = make_pipeline( RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), )
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred)
Parameter search import numpy as np from sklearn.grid_search import RandomizedSearchCV
params = { 'randomizedpca__n_components': [5, 10, 20], 'svc__C': np.logspace(-3, 3, 7), 'svc__gamma': np.logspace(-6, 0, 7), } search = RandomizedSearchCV(pipeline, params, n_iter=30, cv=5) search.fit(X_train, y_train) # search.best_params_, search.grid_scores_
Thank you! • http://scikit-learn.org • https://github.com/scikit-learn/scikit-learn @ogrisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}