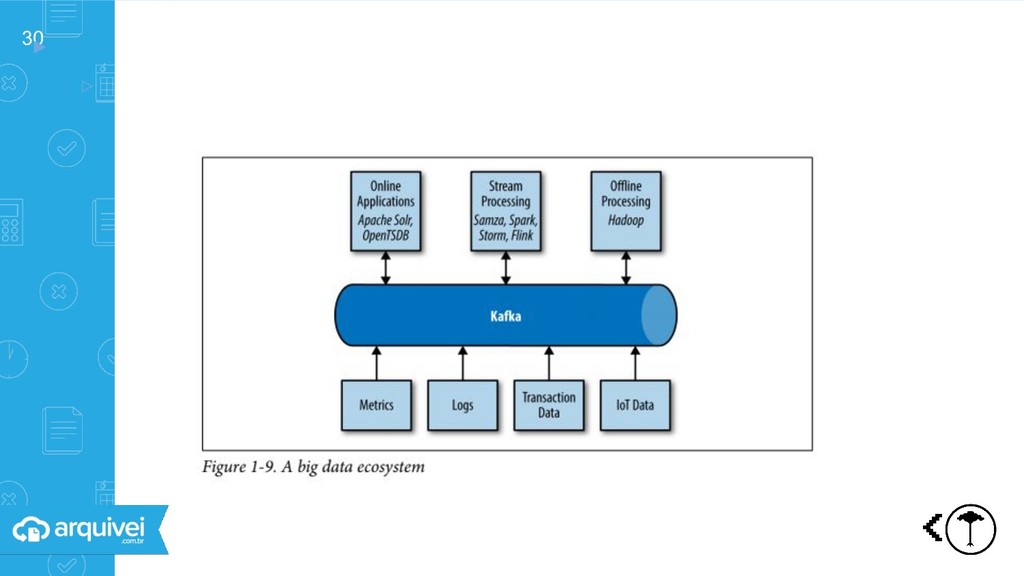
data processing is a complex and exciting field.” ▹Junta dois papers: FlumeJava MillWheel ▹Batchs existentes Alta latência ▹Streaming existentes Tolerância a falhas, escalabilidade, latência Complexidade de janelamento
pipelines em 4 dimensões Quais resultados computados? Onde serão computados? (em event time) Quando serão materializados? (em processing time) Como refinar dados recentes mais tarde?
GroupByKeyAndWindow ocorre ▸ Window: determina onde os dados serão agrupados (event time) ▸ Trigger: determina quando os resultados dos agrupamentos serão emitidos (processing time)
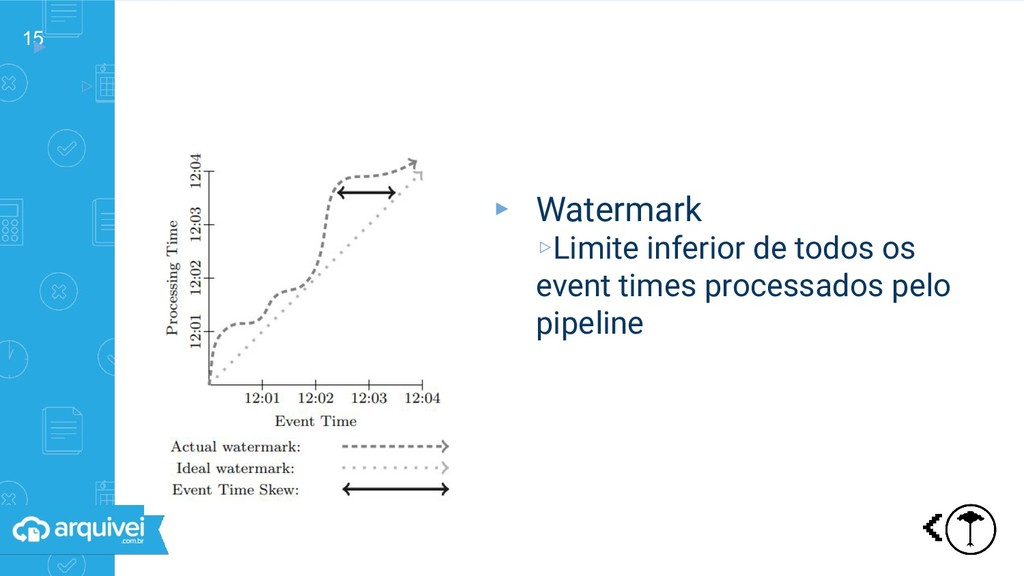
event time em relação ao processing time ▹Refinamentos: Descarte: resultados futuros não dependem de dados passados Acúmulo: resultados futuros dependem de dados passados Acúmulo + Retração: resultados futuros dependem de dados passados resultados passados dependem de dados futuros
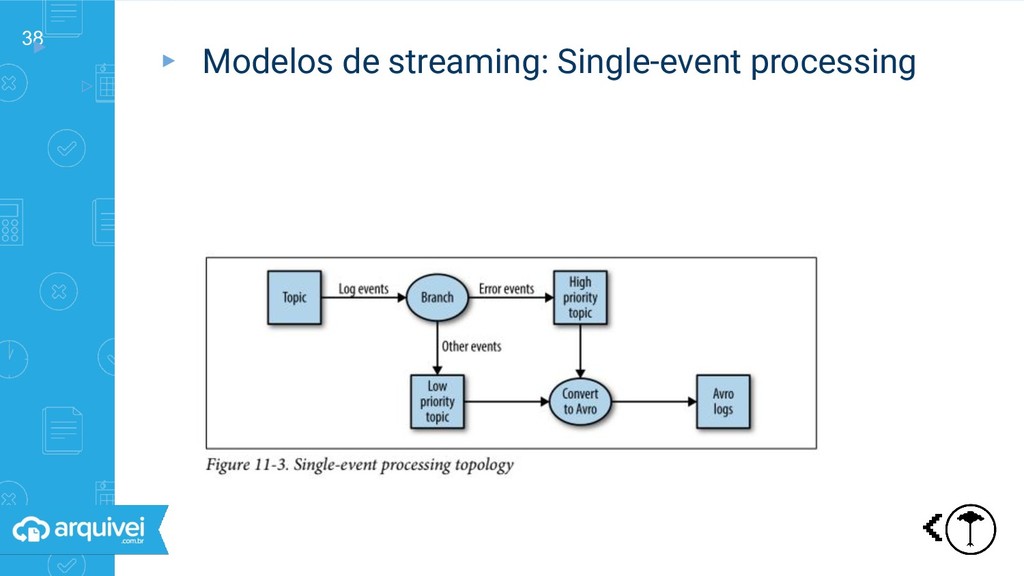
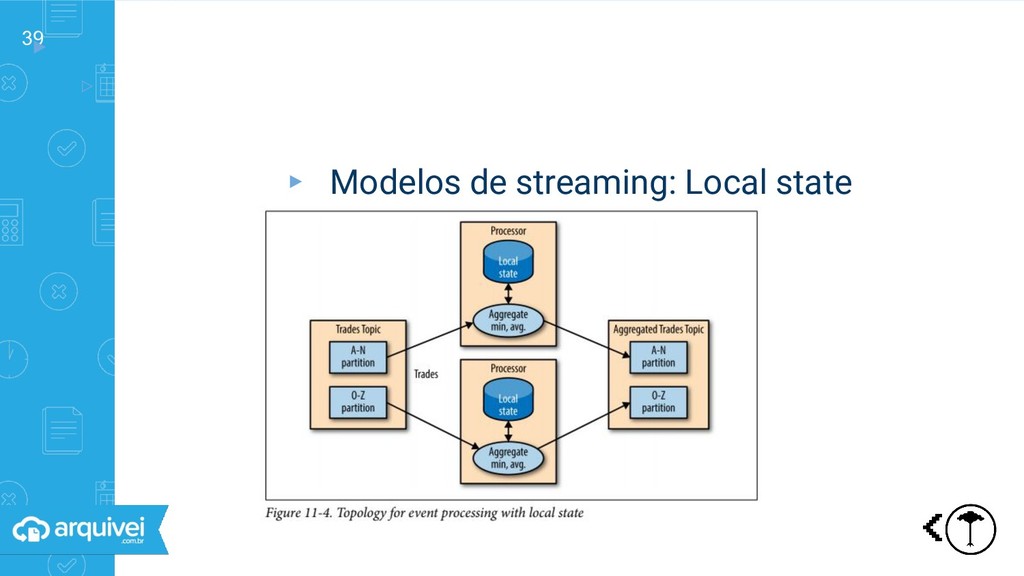
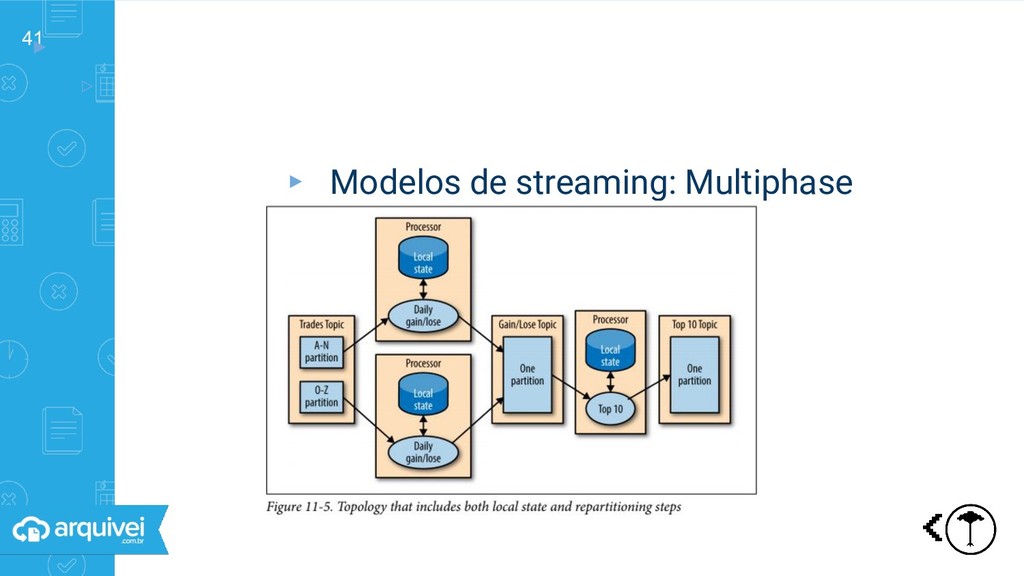
streaming ▹Request-response: um sistema espera outro ▹Batch: dados processados de tempos em tempos ▹Streaming Não é necessário espera Processamento contínuo
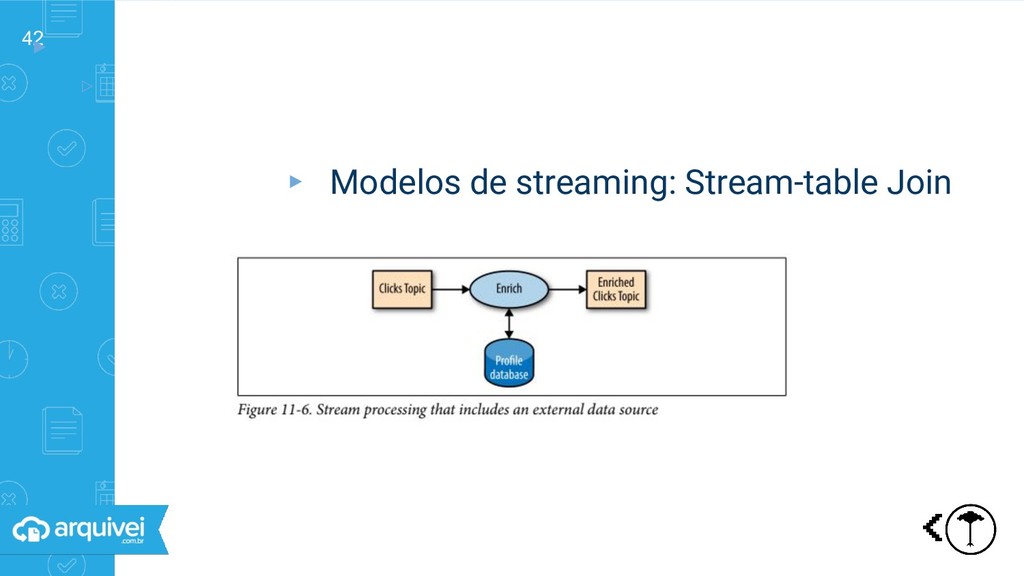
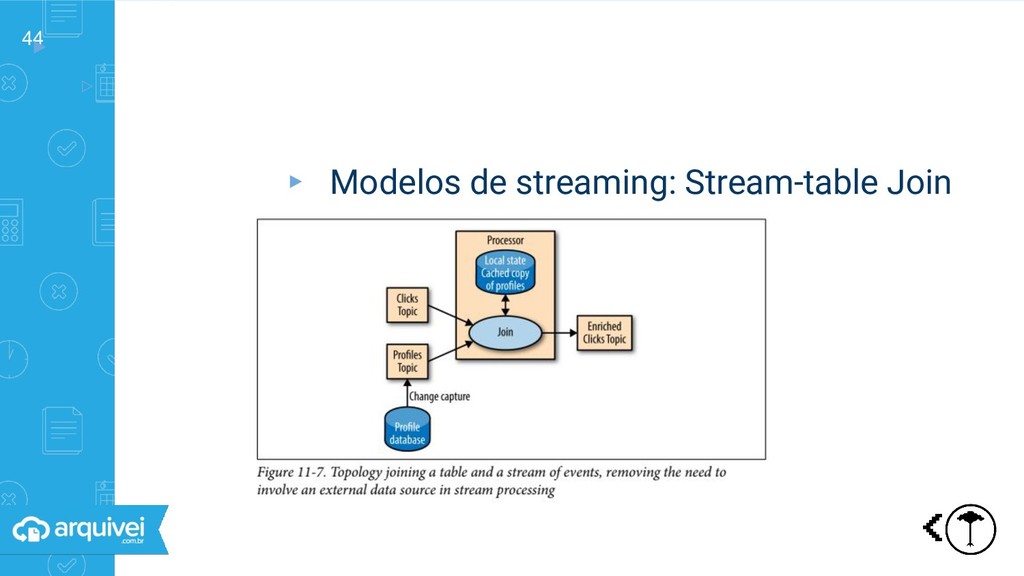
Table: coleção de registros Stream: cadeias de eventos que modificam algo ▹Table != Stream ▹Tabela pode ser convertida em stream (CDC) ▹Stream pode ser convertida em tabela (materialização) ▹Diferentes tipos de redundância
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}