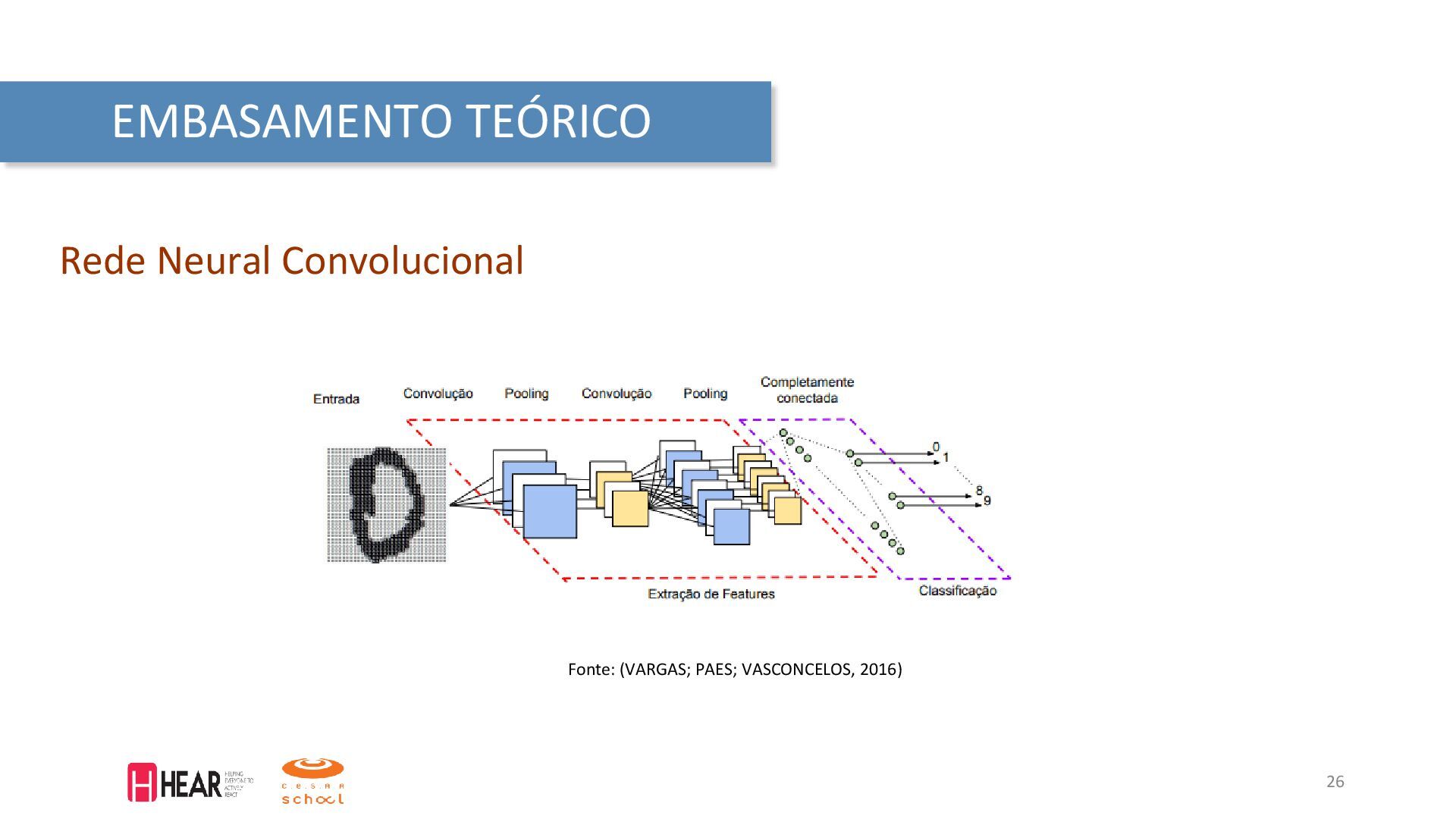
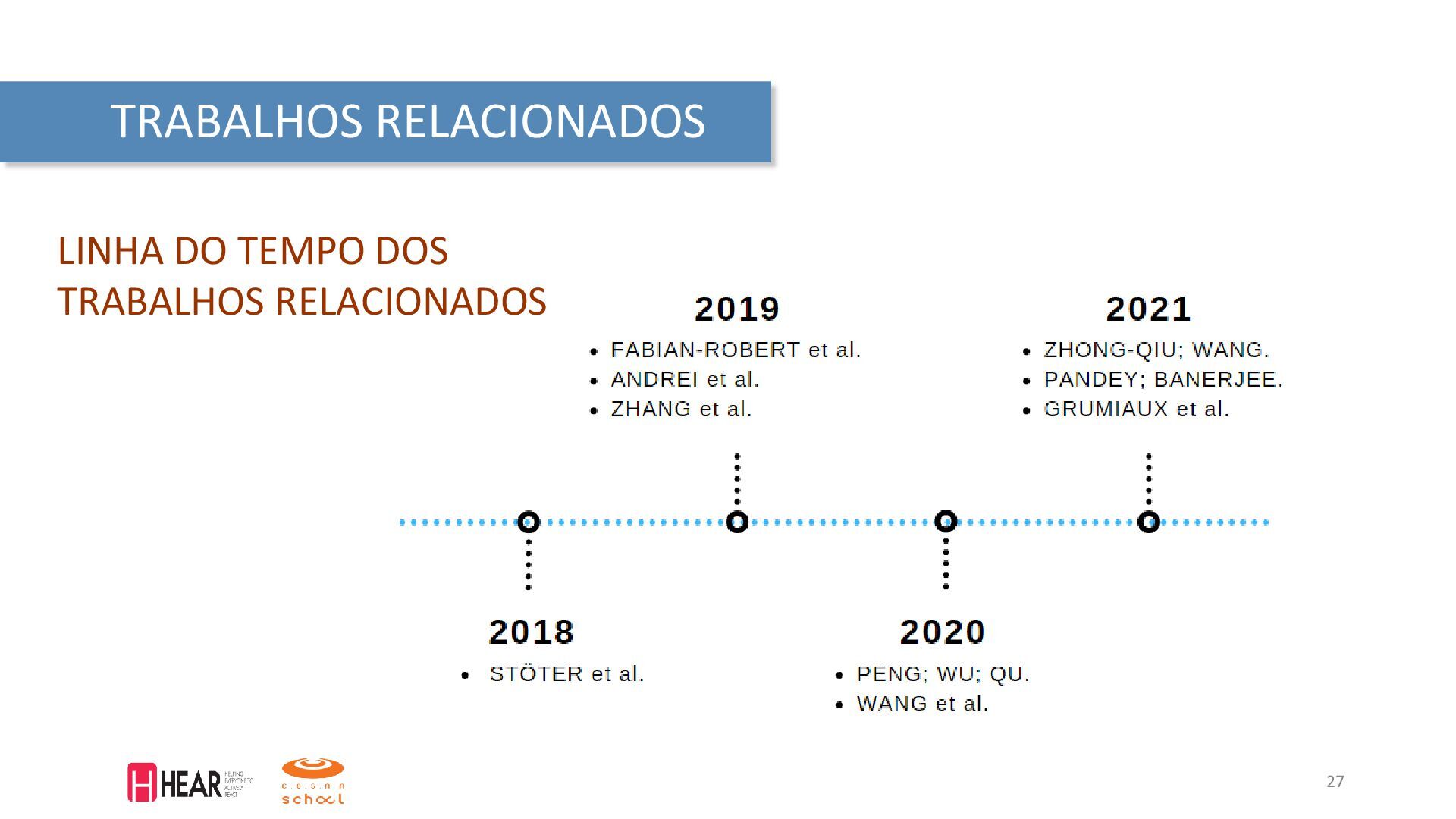
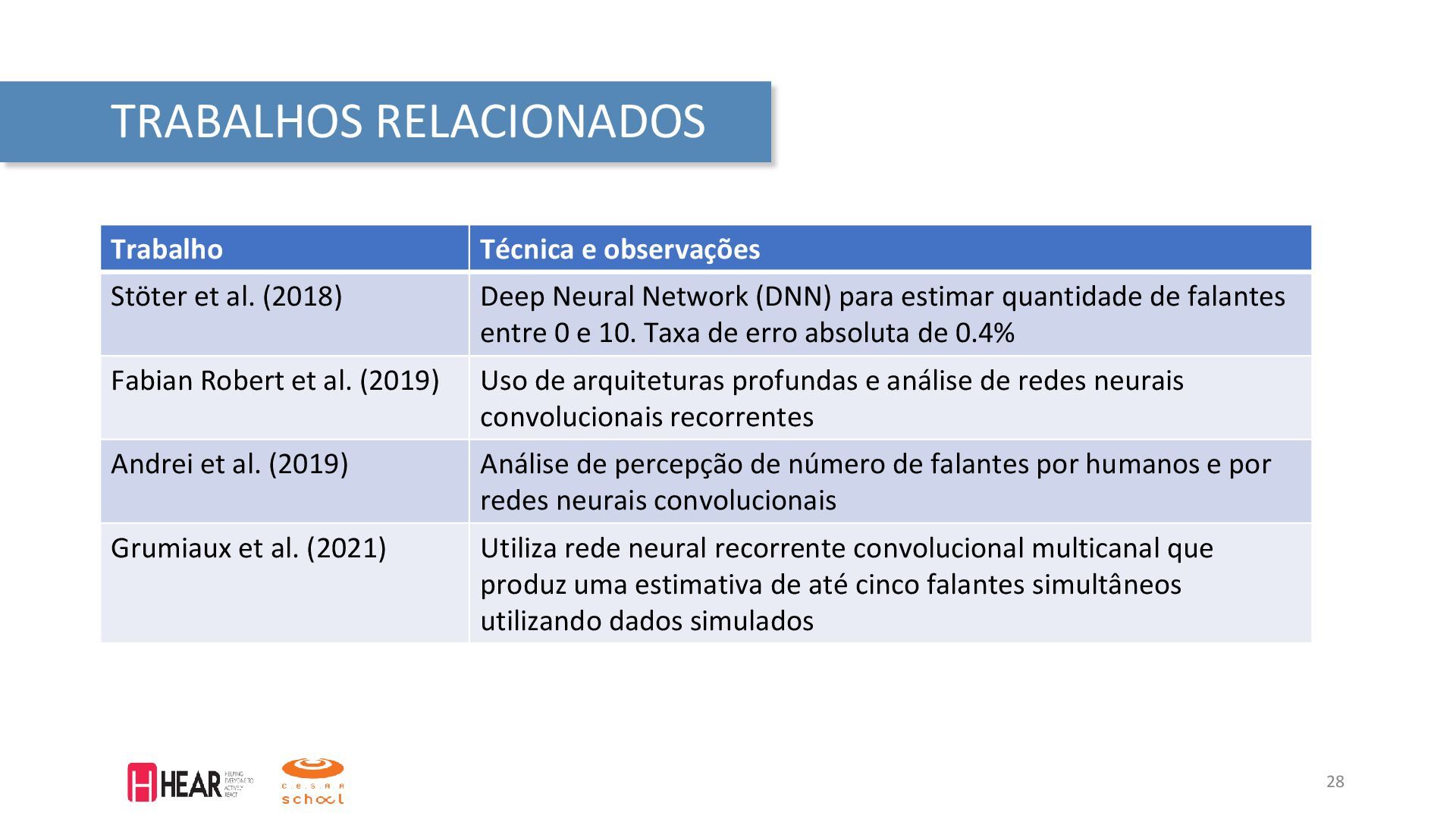
em: <https://www.kaggle.com/ananta/solving-data-science-problems-usingcrisp-dm/notebook>. Acesso em: 15 de dezembro de 2021. IBM. What is computer vision? 2021. Disponível em: <https://www.ibm.com/topics/computer-vision>. Acesso em: 30 de janeiro de 2021. MAKEABILITY, Lab. Signals: Frequency Analysis. 2020. Disponível em: <https://makeabilitylab.github.io/physcomp/signals/FrequencyAnalysis/index.html>. Acesso em: 04 de março de 2022. VARGAS, A; PAES, A; VASCONCELOS, C. Um estudo sobre redes neurais convolucionais e sua aplicação em detecção de pedestres. In: PROCEEDINGS of the XXIX Conference on Graphics, Patterns and Images. [S.l.: s.n.], 2016. P. 1–4. Fórum de Segurança Pública. Segurança em Números. Julho 2021. Disponível em: < https://forumseguranca.org.br/wp-content/uploads/2021/07/infografico-2020-v6.pdf> Fórum de SP. Infográfico visível e invisível. Maio 2021. Disponível em: <https://forumseguranca.org.br/wp-content/uploads/2021/05/infografico-visivel-e-invisivel-2ed.pdf> ANDREI, Valentin et al. Overlapped Speech Detection and Competing Speaker Counting—Humans Versus Deep Learning. IEEE Journal of Selected Topics in Signal Processing, v. 13, n. 4, p. 850–862, 2019. FABIAN-ROBERT et al. CountNet: Estimating the Number of Concurrent Speakers Using Supervised Learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, v. 27, n. 2, p. 268–282, 2019. GRUMIAUX, Pierre-Amaury et al. High-Resolution Speaker Counting in Reverberant Rooms Using CRNN with Ambisonics Features. In: 2020 28th European Signal Processing Conference (EUSIPCO). [S.l.: s.n.], 2021. P. 71–75. PANDEY, S.; BANERJEE, A. A. Distributed Approach to Speaker Count Problem in na Open-Set Scenario by Clustering Pitch Features. IEEE Signal Processing Magazine, abr. 2021. PENG, Chao; WU, Xihong; QU, Tianshu. Competing Speaker Count Estimation on the Fusion of the Spectral and Spatial Embedding Space. In: PROC. Interspeech 2020. [S.l.: s.n.], 2020. P. 3077–3081. ZHANG, Wangyou et al. End-to-End Overlapped Speech Detection and Speaker Counting with Raw Waveform. In: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). [S.l.: s.n.], 2019. P. 660–666. ZHONG-QIU, Wang; WANG, DeLiang. Count And Separate: Incorporating Speaker Counting For Continuous Speaker Separation. In: ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). [S.l.: s.n.], 2021. P. 11–15. WANG, Wei et al. Speaker Counting Model based on Transfer Learning from SincNet Bottleneck Layer. In: 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom). [S.l.: s.n.], 2020. P. 1–8. WIRTH, Rüdiger; HIPP, Jochen. CRISP-DM: Towards a Standard Process Model for Data Mining. In: PROCEEDINGS of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining. [S.l.: s.n.], 2000. P. 29–39. 41 REFERÊNCIAS BIBLIOGRÁFICAS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
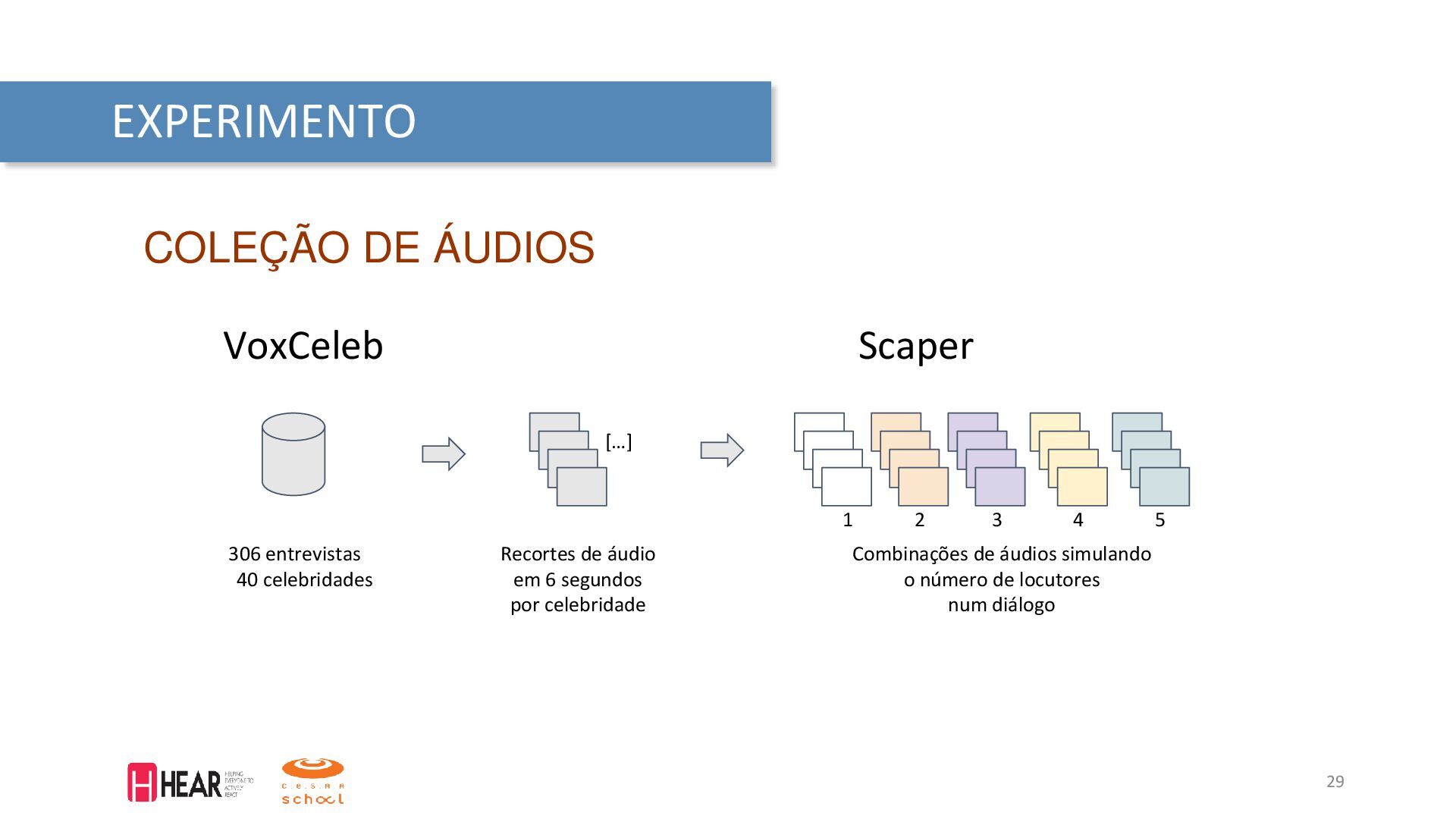{kind=link}
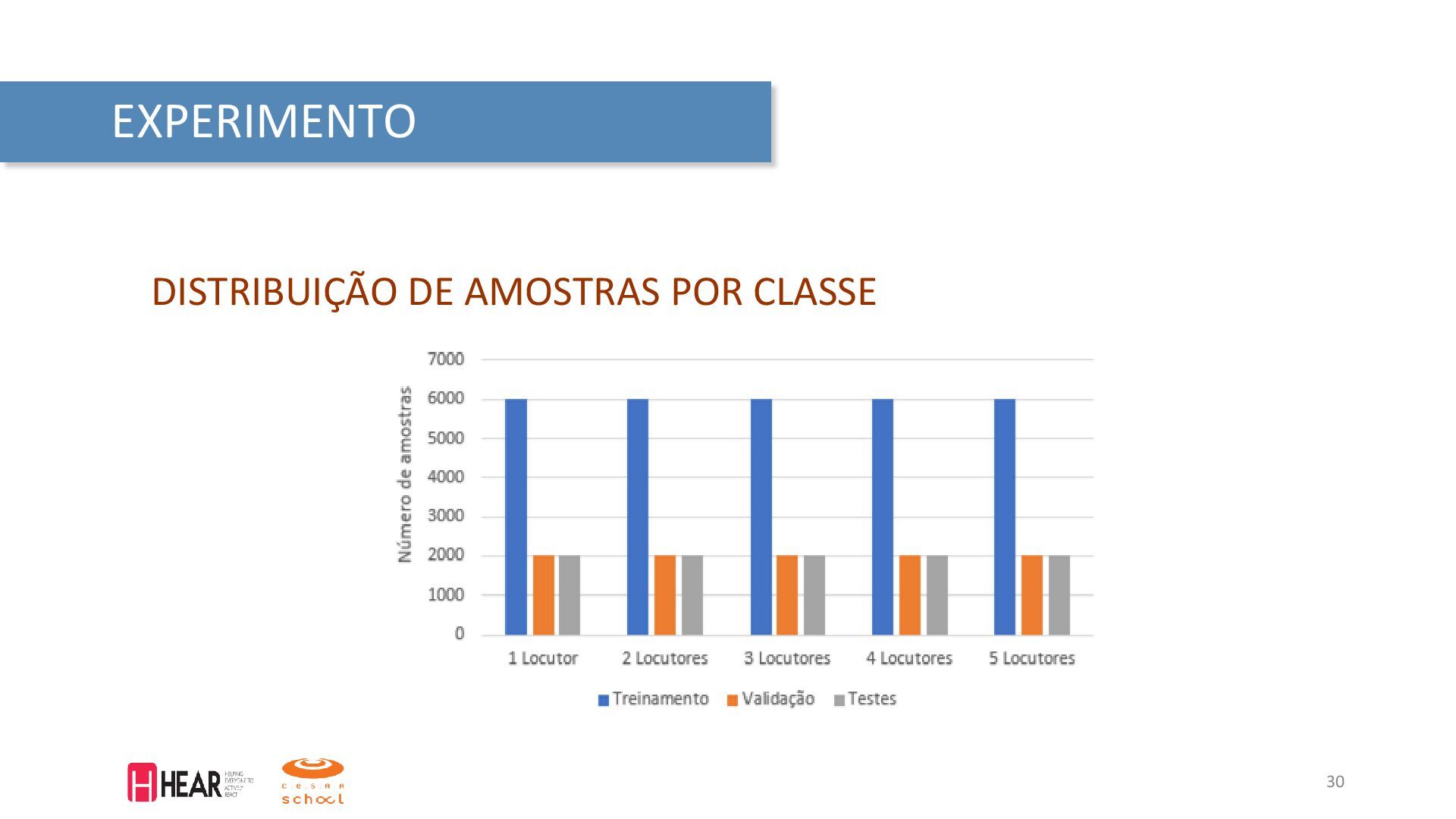{kind=link}
{kind=link}
{kind=link}
{kind=link}
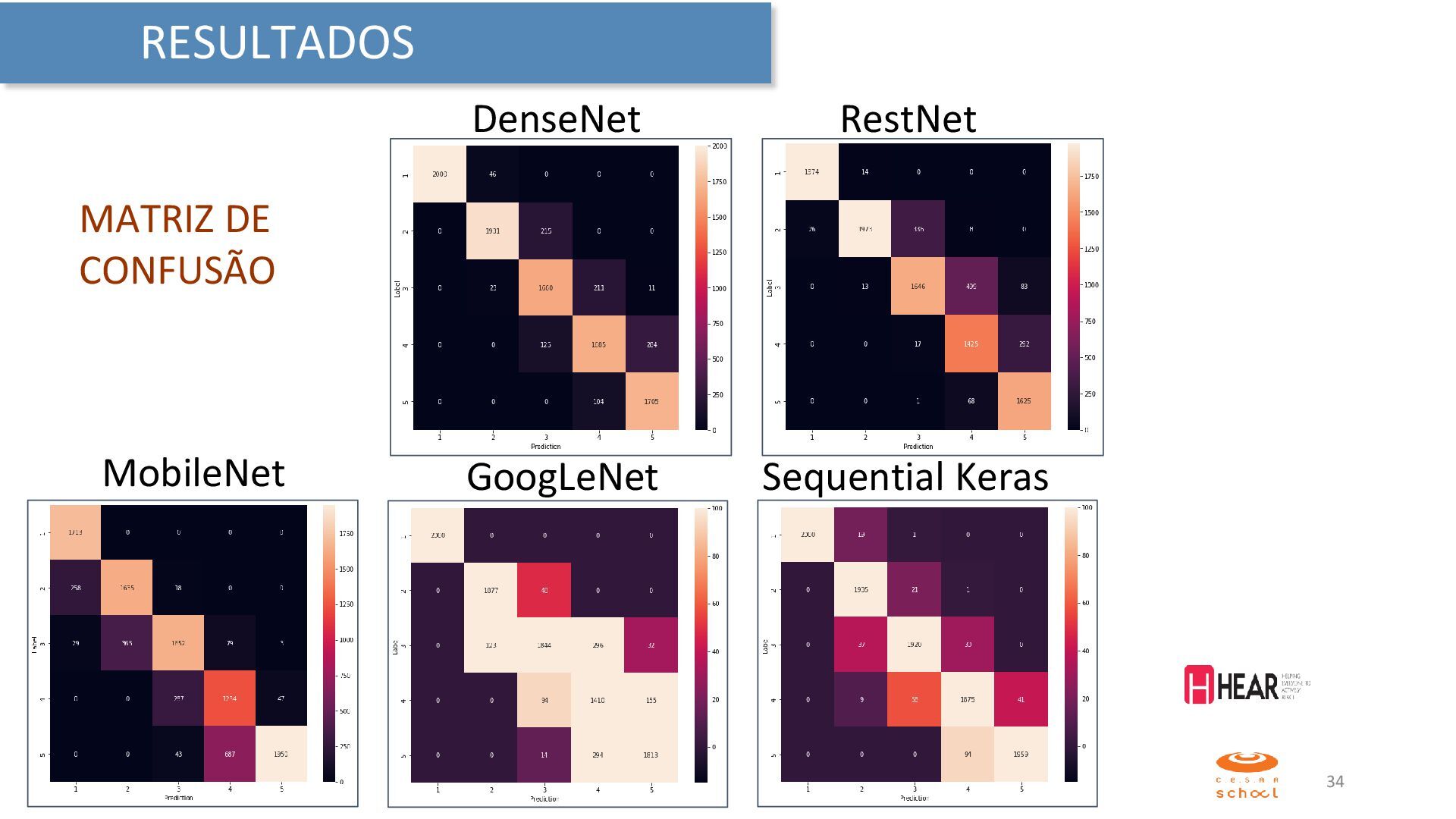{kind=link}
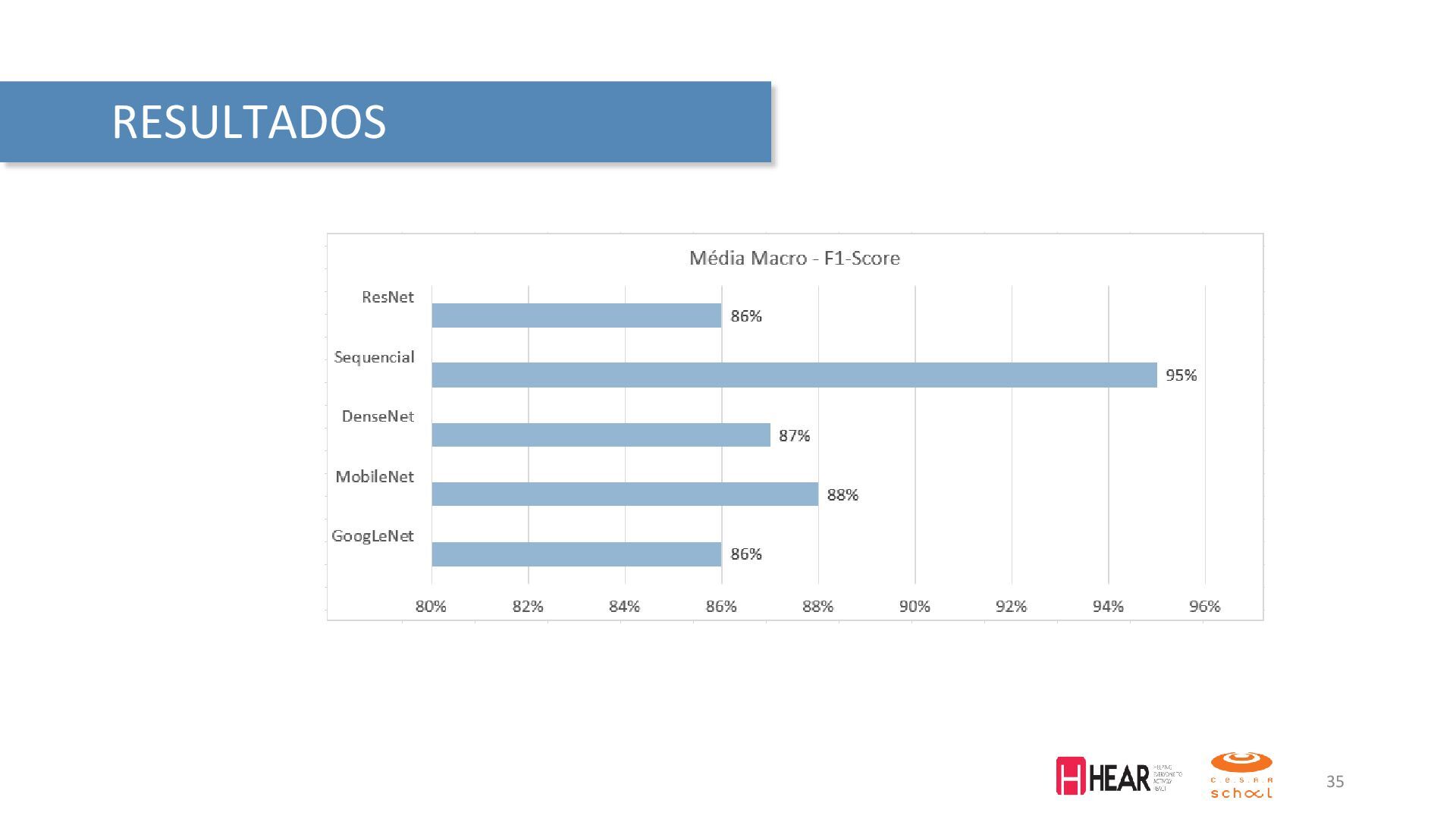{kind=link}
{kind=link}
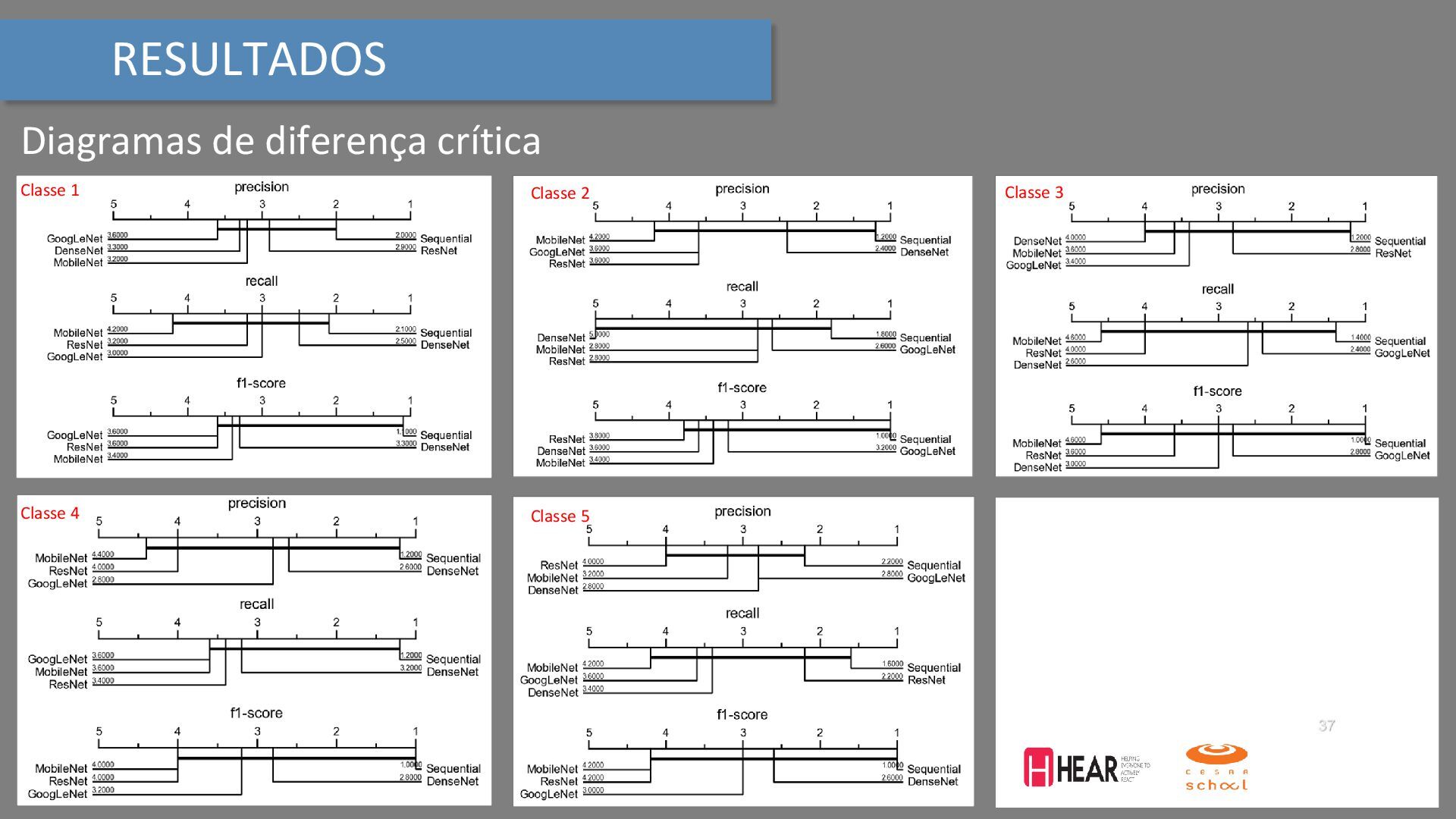{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}