have mostly worked on performance features like group commit and faster in-memory sorting • Also worked on pg_stat_statements (9.2 normalization stuff) • Work for Heroku as an engineer in the Department of Data – build internal infrastructure for Postgres database-as-a-service
it is sensible to discuss in a single hour – many things covered in passing could easily justify their own hour • Aspects of concurrency like locking, transaction isolation level and MVCC, and issues surrounding concurrency for application developers. • Mostly, how the database handles things so you often don't have to give concurrency issues any thought • Sometimes you do, though, so it's useful to at least be able to judge if it's one of those times • Ongoing development work, and other topical stuff
Used by IBM DB2 and SQL Server (strictly speaking they use SS2PL). Writers and readers may block each other. Can perform poorly, but behaviour at least easy to reason about. Pessimistic. Locks more. Tacitly assumed by SQL standard, which is occasionally evident in subtle ways. Classic model from 1970s (System R). • 2PL seems really weird to me, because you frequently have situations were transactions block on writing data, just because existing data has been “sullied” by being read by some other still current transaction. And vice-versa. • Big banks love 2PL!
concurrency model used by Postgres, Oracle, and many other systems. • Multiple versions of rows are stored at the same time. Each session has snapshot which dictates which versions are visible to it. Readers don't block writers, and writers don't block readers. Locks much less than 2PL, but locks are still frequently taken (usually far lighter locks).
– generally fairly rare to have to take them explicitly yourself, but can be done with SQL. • These locks last until end of transaction (with some obscure exceptions). • Just reading from a table (or an index) takes a very light lock on it. This just prevents some other session from dropping the table, for example (since that needs a very heavy lock that blocks all other locks). • Full taxonomy of Postgres locks at: http://www.postgresql.org/docs/current/static/explicit-locking.html • Includes useful conflict table – some don't block others. • Some locks block themselves (across multiple sessions)
pg_locks system view – can be joined against pg_stat_activity to show query involved and so on. • https://wiki.postgresql.org/wiki/Lock_Monitoring A useful resource for locking problems. • https://wiki.postgresql.org/wiki/Lock_dependency_information For lock dependencies. • Locks automatically taken on newly inserted rows, or a row when updated or deleted. • Unique constraints (indexes) sometimes block pending the outcome of other transactions. Sometimes system can't be sure that your value (say, 5) really violates constraint until other session (that inserted same value first) commits or aborts.
that are not exposed to users. • For example, the btree code uses a technique sometimes called “latching” to ensure correct concurrent access. Takes tiny page-level locks for an instant (not duration of transaction) so that data structure can be accessed correctly and efficiently by different sessions – no one gets to see a half-written page, for example. • Totally orthogonal to table-level locks – people often confuse the two.
of Postgres is to let you pretend that your transaction is the only one running at the time. It makes your life much easier as an application developer if you don't have to worry about things disappearing from under you • This is also the job of locks, that work pretty much the same at all isolation levels • Transaction isolation is essentially the lengths that the database goes to to fool your application. In general, the database has to work harder for it to be more convincing so that you can worry less about getting some aspect of concurrency wrong. • Which particular trade-off is right for your particular application or even individual transaction is up to you. • In my experience, many application developers don't know what this is. Sometimes they pay for this, but mostly things accidentally work out fine. • On the other hand, if you listen to certain database geeks, they'd tell you that you'd be crazy to not use higher isolation levels.
Each statement executed sees rows that are consistent with its snapshot. Each statement gets a new snapshot. • Sometimes, you can have some anomalies occur where in the course of a transaction (but not during the execution of a single statement) you see rows (more strictly speaking, row versions) that differ from earlier in the transaction. These anomalies are called nonreapeatable reads and phantom reads. • You can only see data committed by other transactions, and never uncommitted data (“dirty data”) from another transaction.
was called “serializable” in 9.0, and Oracle implements the same semantics and calls it serializable, just as Postgres used to. • This is kind of similar to Read committed, except you get one snapshot per transaction, not per statement. So you never see data that someone else has committed since the start of your transaction. • There is one big downside/difference (aside from some implications for performance): Postgres is now allowed to throw serialization errors if it cannot give you behavior consistent with the set of guarantees you asked for. This is only an issue with write statements when two transactions UPDATE or DELETE the same data concurrently – one “wins” (unless lock holding transaction aborts, in which case the conflict is averted).
repeatable read is when doing reporting, but certainly not uncommon to use it all the time. • Suppose you have a typical financial report with rows for sales across different departments or something, but also some totals at the bottom. Maybe the totals have to be queried separately by a different command. • If you did this against live data (i.e other transactions modified the data and committed), and didn’t use at least repeatable read isolation level in Postgres, you might get a situation the where numbers don’t add up! • With repeatable read, that wouldn’t happen because both queries would use the same snapshot.
said repeatable read’s behavior used to be called Serializable by Postgres, and what Oracle still calls serializable is equivalent (snapshot isolation)? • Well, this is free from all the anomalies that the SQL standard says serializable can’t have...but is it really serializable, in the general, everyday sense? In other words, can you rely on things just working as if your transaction was the only one (with maybe some blocking)?
in a way that makes it look exactly like transactions occurred independently in a serial order to everyone? • Can you test your app with a single session and be confident it's correct? • It turns out that the answer is no!
readers don’t block writers and writers don’t block readers. • Remember how I said banks like 2PL databases like DB2? • I didn’t just mean because it’s simple and easy to reason about, though that’s probably part of it. • Because 2PL can have select statements block on some writes in other transactions, it can’t have write-skew anomalies.
pretty simple. • It turns out that 2PL systems might not be so dumb for considering data that another running transaction saw as “sullied”... • Still pretty dumb, though. Certainly, this doesn't matter 99%+ of the time. • But it will matter to you someday.
this example from Snapshot Isolation wikipedia page: http://en.wikipedia.org/wiki/Snapshot_isolation • Consider the example of a person with two bank accounts at the same bank. The bank lets the person have a negative balance in one if the balance in the other is enough that in aggregate the person has a non-negative balance (>= 0). • So application checks if constraint holds, and lets transaction go through. If not, it aborts with error for user. • What happens if two requests come in at approximately the same time with snapshot isolation?
one bank account, or they happened to try to deduct from the same account, a lock implicitly acquired by UPDATE would have saved us here. Hence, the “skew”. • So what do I do? Accept this as the cost of having MVCC, and its guarantee that readers don't block writers and vice-versa? Artificially introduce a write dependency? • Even read-only transactions can be affected by these problems with snapshot isolation. • I'm very conservative when it comes to my data...should I think about a 2PL system instead? • No, just use Postgres. Version 9.1+ has something called Serializable Snapshot isolation (SSI). This is what you get when you ask for serializable level on these versions.
• Based on recent research. Postgres is world's first implementation. • Sometimes SSI (like repeatable read) throws serialization failures. You have to retry transaction. • It's much better than 2PL; it doesn't just throw failures where 2PL would block. But is still slightly conservative in that sometimes it throws errors when not strictly necessary; it's clever, but not magic. • This system has Postgres keep track of read/write dependencies across transactions that cannot otherwise know what each other transaction is doing. • Fully equivalent to some serial execution order – doesn't promise which one. • Works okay with one session? Automatically works with many (if you can handle serialization conflicts).
is an tacit assumption that things execute in a certain order relative to each other, when in fact there is nothing to guarantee that’s the case. • Write-skew anomaly is a race condition. • Locks will get you pretty far when it comes to avoiding these. • A big offender for races is a trigger than enforces a business rule. “When you insert new tuple, this other condition about this other table must hold; otherwise, abort transaction”.
you can avoid it. • Lock the whole table first (obvious disadvantages). • Use a declarative constraint instead. With Postgres, this is possible surprisingly often. For example, exclusion constraints solve many problems that other systems need these kinds of triggers for. It’s always a big bonus to be able to do this, because it will perform better than ad-hoc methods, and you don’t have to worry about the correctness of your own implementation. • Always use SSI. If you can live with the impact on performance and don’t mind handling serialization failures.
deadlock - when one transaction acquires a lock that another blocks on acquiring, while the blocked one itself has locks that the first transaction ends up itself requiring. Nothing can proceed - it’s a “deadly embrace”. In this scenario, Postgres randomly has one of the two transactions abort after a second or so. • The key to avoiding this situation is to acquire locks - including implicit locks from UPDATEs, or locks on values held when inserting into a table with a unique index constraint - in consistent order.
implemented internally as triggers. They acquire locks on referenced (or referencing in the case of the foreign table) rows. • This works much better in 9.3. • You need referenced rows to stick around for your whole transaction when inserting, updating or deleting. • These triggers use special “dirty snapshots” to see uncommitted data...so general “triggers enforces business rule” caveats don't quite apply. • No, you do not want to use dirty snapshots for your app directly. • I guess you could if you really wanted to, and felt like writing your triggers in C, though. This is Postgres.
major work in this area in 9.3, which took a great deal of effort. • In 9.2, the foreign key triggers acquire SELECT FOR SHARE locks on rows (it actually used to be SELECT FOR UPDATE many years ago). • The type of lock involved doesn’t block other locks of the same kind, so you can insert a value referencing the same row in two concurrent transactions. But the lock taken does block some other locks, like those taken by UPDATE statements. • This is all needed for correct behavior; the transaction needs to do the rest of its work while knowing that the other row won’t go away. Everything it does is predicated on the row actually being around.
UPDATEs really prevent the row from continuing to be around in any real sense? • Not usually - if you updated every single column in the row, you might consider that a whole new row, and then that the lock enforcement makes sense. But those UPDATEs probably aren’t updating the primary key values of the referenced row most of time time.
triggers now use FOR KEY SHARE. You can even use these locks yourself from SQL (if you were so inclined). • UPDATE statements may use FOR NO KEY UPDATE. • This greatly improves the performance with many clients, because they will block each other far less frequently. This tends to help a lot with deadlocking, because in my experience deadlocking tends to involve foreign key acquired locks.
WHERE key = 1 FOR UPDATE; -- Postgres 8.1 - 9.2 foreign keys: SELECT * FROM foreign_table WHERE key = 2 FOR SHARE; -- Postgres 9.3+ foreign keys: SELECT * FROM foreign_table WHERE key = 3 FOR KEY SHARE; -- Many updates just implicitly take -- a lock like this in 9.3: SELECT * FROM foreign_table WHERE key = 4 FOR NO KEY UPDATE;
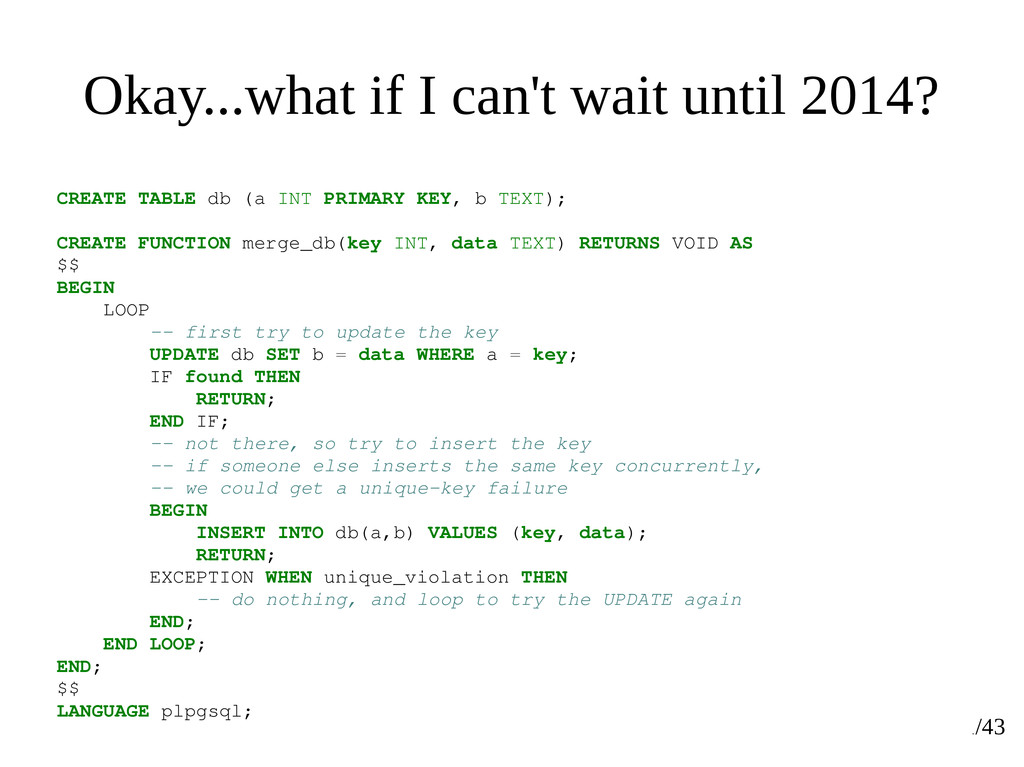
to write a simple atomic SQL statement that will either insert a row, or update it in the event of it already existing (that is, update a row found that has the same primary key value as the row proposed for insertion, or perhaps exclusive constraint values). • MySQL has INSERT...ON DUPLICATE KEY UPDATE • Postgres requires you to use substransactions. In a loop. It's rather subtle to get all the details right. • Frankly, this is kind of a poor showing for Postgres, because it's such a common operation.
test(a, b) VALUES(123, 'Chicago'), (456, 'Dublin') ON DUPLICATE KEY LOCK FOR UPDATE RETURNING REJECTS * ) UPDATE test SET test.b = rej.b FROM rej WHERE test.a = rej.a; • Think of a common table expression as like a temporary table that lasts only the duration of a statement. • In Postgres, these can contain DML (with RETURNING clause).
db (a INT PRIMARY KEY, b TEXT); CREATE FUNCTION merge_db(key INT, data TEXT) RETURNS VOID AS $$ BEGIN LOOP -- first try to update the key UPDATE db SET b = data WHERE a = key; IF found THEN RETURN; END IF; -- not there, so try to insert the key -- if someone else inserts the same key concurrently, -- we could get a unique-key failure BEGIN INSERT INTO db(a,b) VALUES (key, data); RETURN; EXCEPTION WHEN unique_violation THEN -- do nothing, and loop to try the UPDATE again END; END LOOP; END; $$ LANGUAGE plpgsql;
values (like the integer 5), then rows (a row in the table with a primary key value of 5), then release the values lock. Row locks persist until end of transaction. • Unique constraints are always btree indexes under the hood. • No good way to lock values. Had to develop “phased locking” approach. • Lock the values in indexes, then maybe lock rows and relase index locks. • Otherwise, insert heap tuple, then pick up from first phase and actually go through with inserting. Then release index locks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}