nbtree: An architectural perspective
Video (lacks original animations): https://www.youtube.com/watch?v=p5RaATILoiE
Many PostgreSQL users have a basic understanding of how Postgres nbtree indexes work internally (e.g., how the structure is maintained, high level details of how a new level is added to the tree, the role of VACUUM in garbage collection). A smaller number have some understanding of advanced topics (e.g., details of Lehman & Yao's B-Link technique, details of crash recovery). Even an experienced backend hacker could be forgiven for concluding that this is all well explored territory, leaving little room for improvement, since all the important components are already in place.
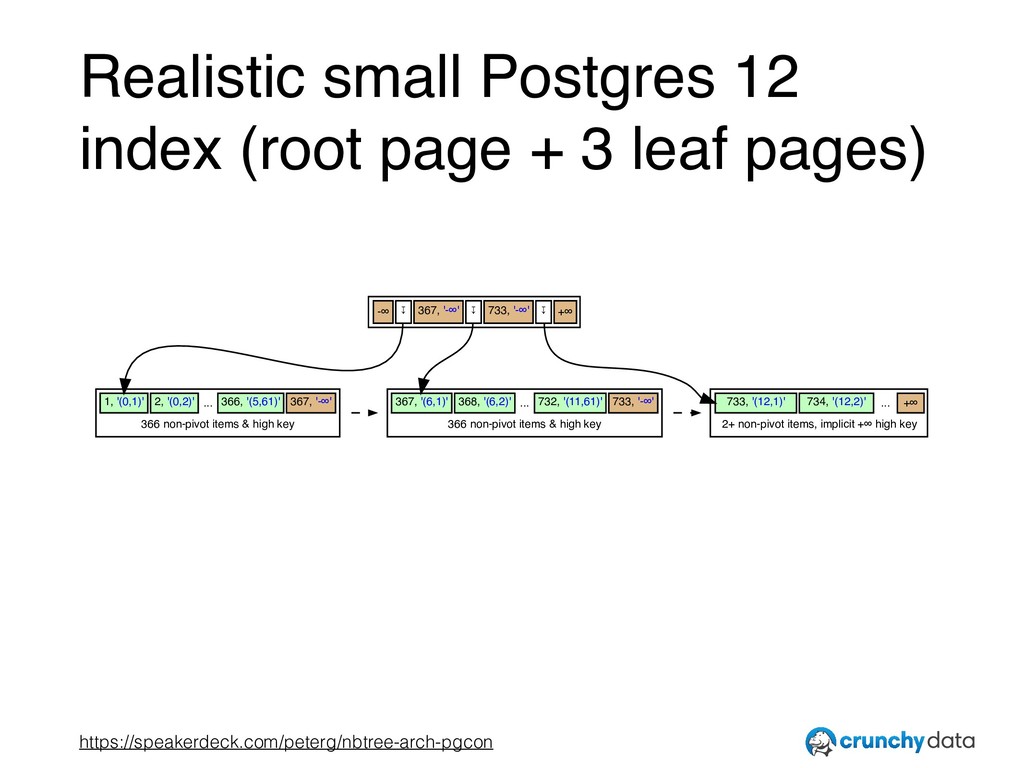
This view of things is based on a correct premise, and yet cannot explain why nbtree doesn't perform well with certain specific real world workloads. For example, there is an excessive amount of nbtree index bloat created by the industry standard TPC-C benchmark, despite the fact that TPC's transactions rarely update indexed columns, and therefore handily avoid so-called "write amplification". Certain pieces are missing.
Code enhancements (authored by the speaker) that will appear in PostgreSQL 12 will significantly improve matters for affected workloads. In some ways, this work is based on a return to decades old fundamentals. In other ways, it is based on practical experience, involving analyzing real-world index structures in an effort to learn where problems may lie.
This talk will cover:
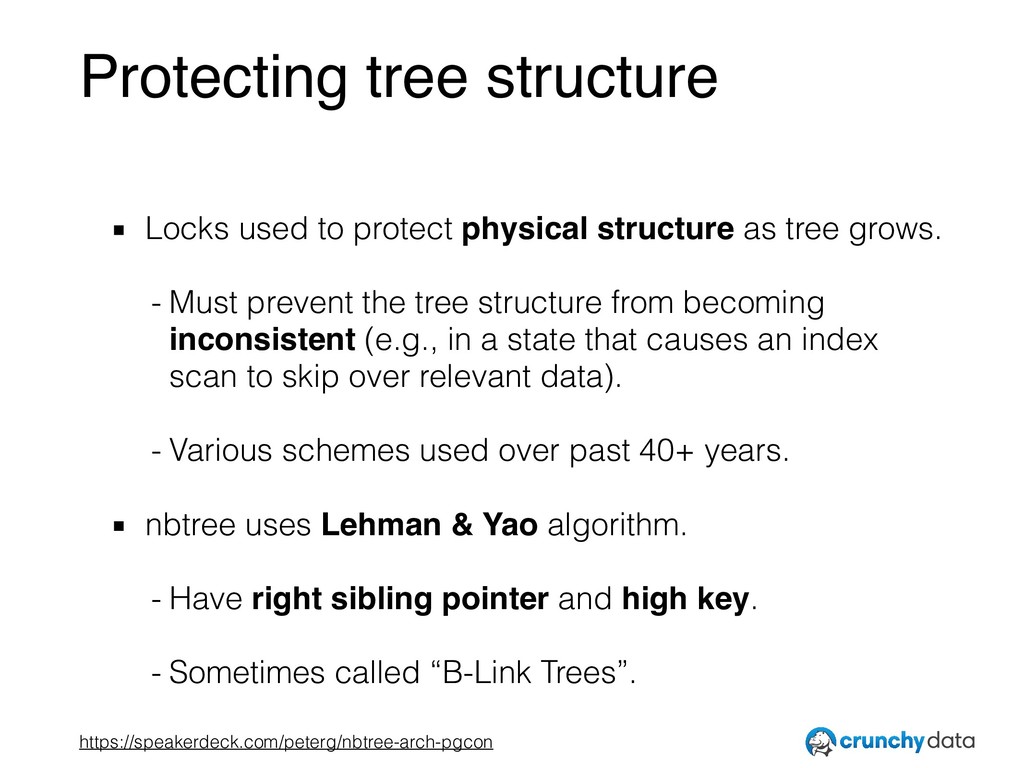
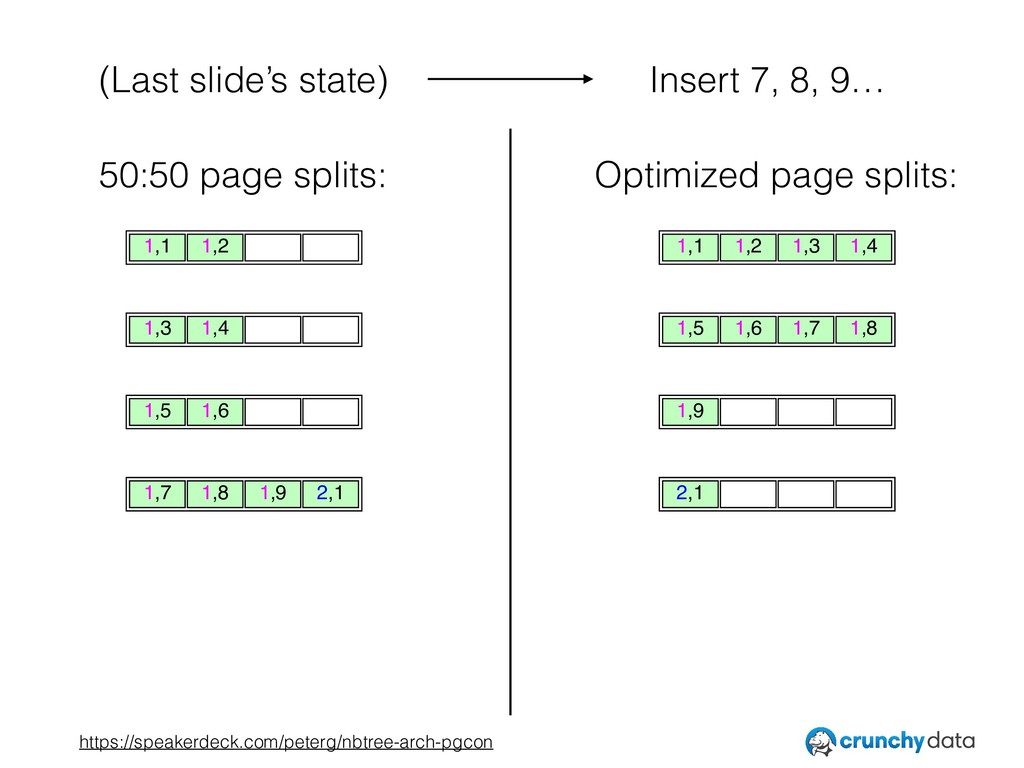
• A review of the design of nbtree, especially its high level goals.
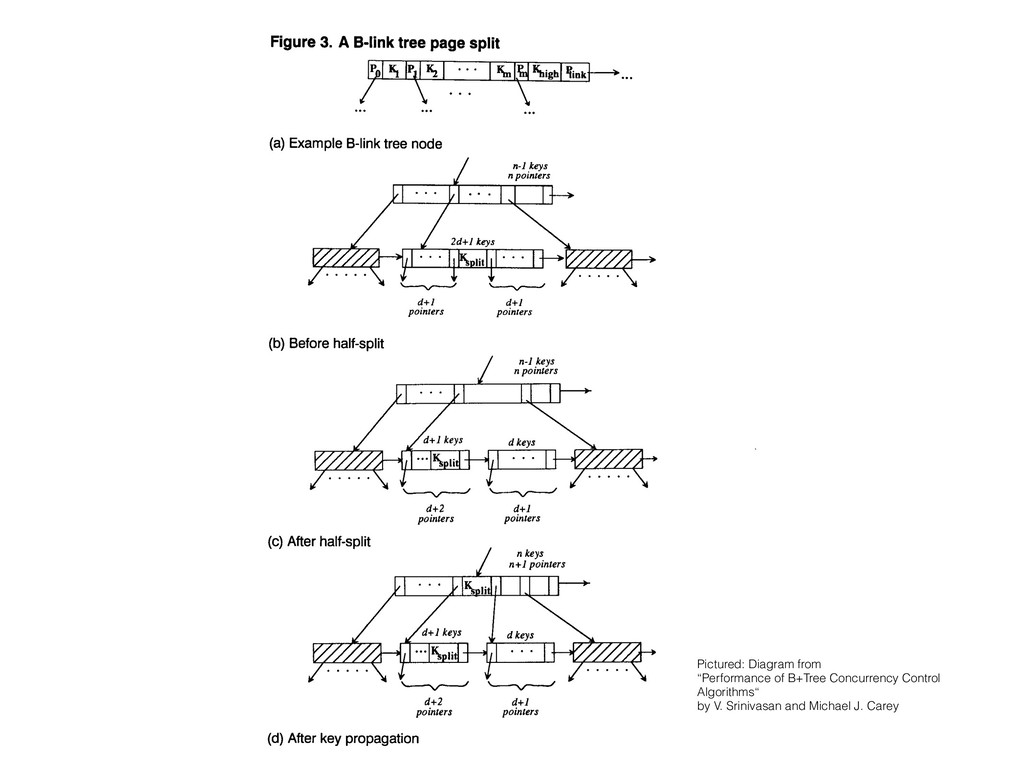
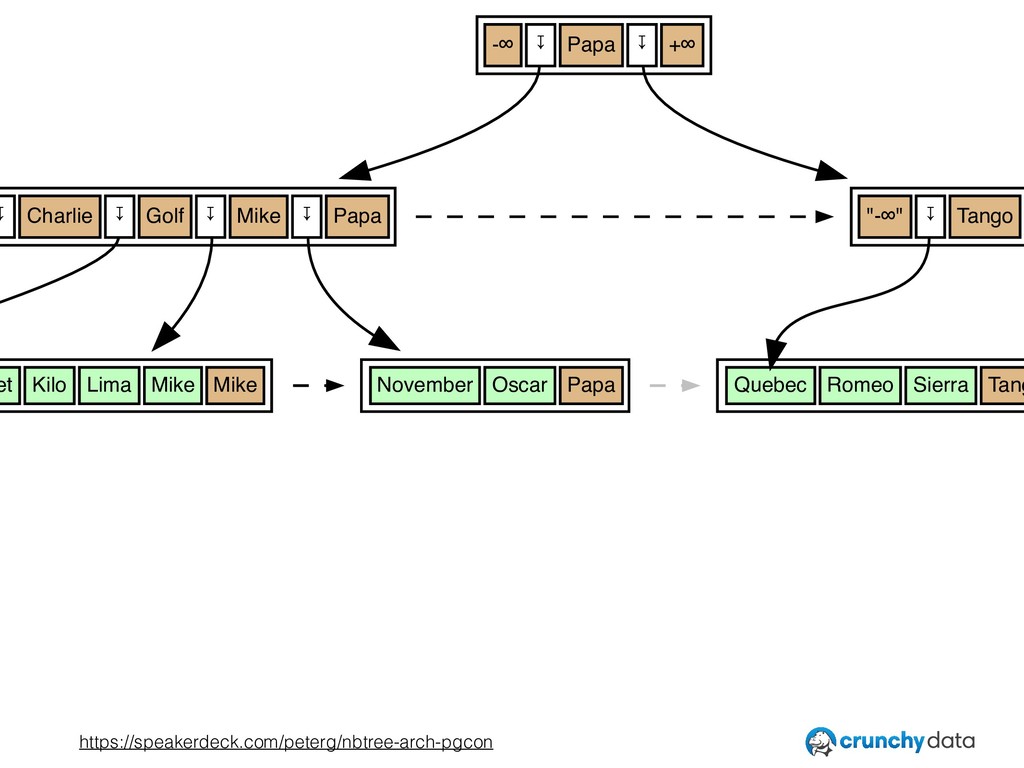
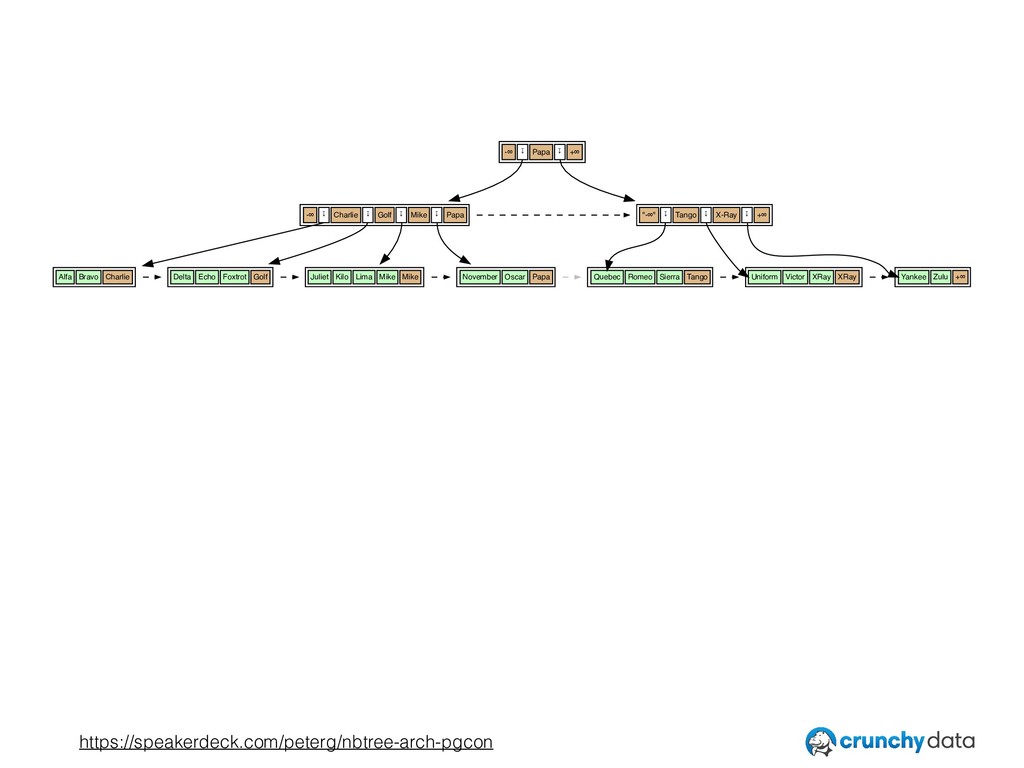
• The importance of thinking in terms of invariants — the rules underlying what belongs where in the index.
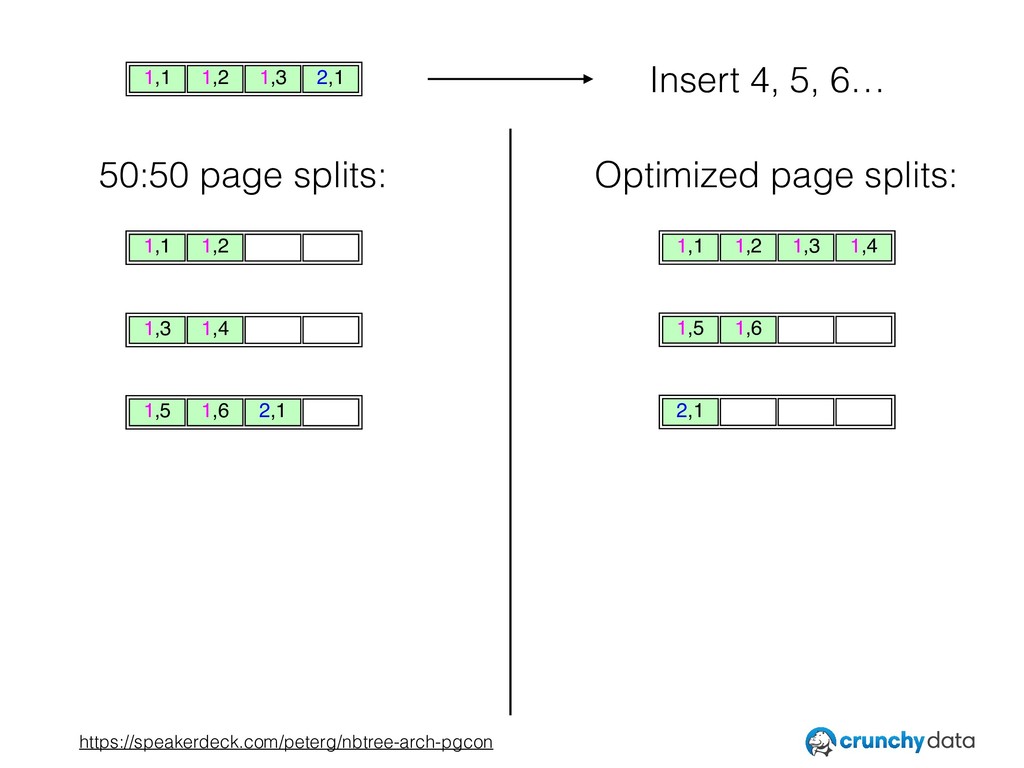
• Interesting ways in which nbtree exceeds what is truly required by the invariants, and how that can be exploited to improve performance.
• Possible future work aimed at reducing CPU cache misses while descending a B-Tree.
• The big picture — how all these techniques are complementary, and worth more than the sum of their parts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
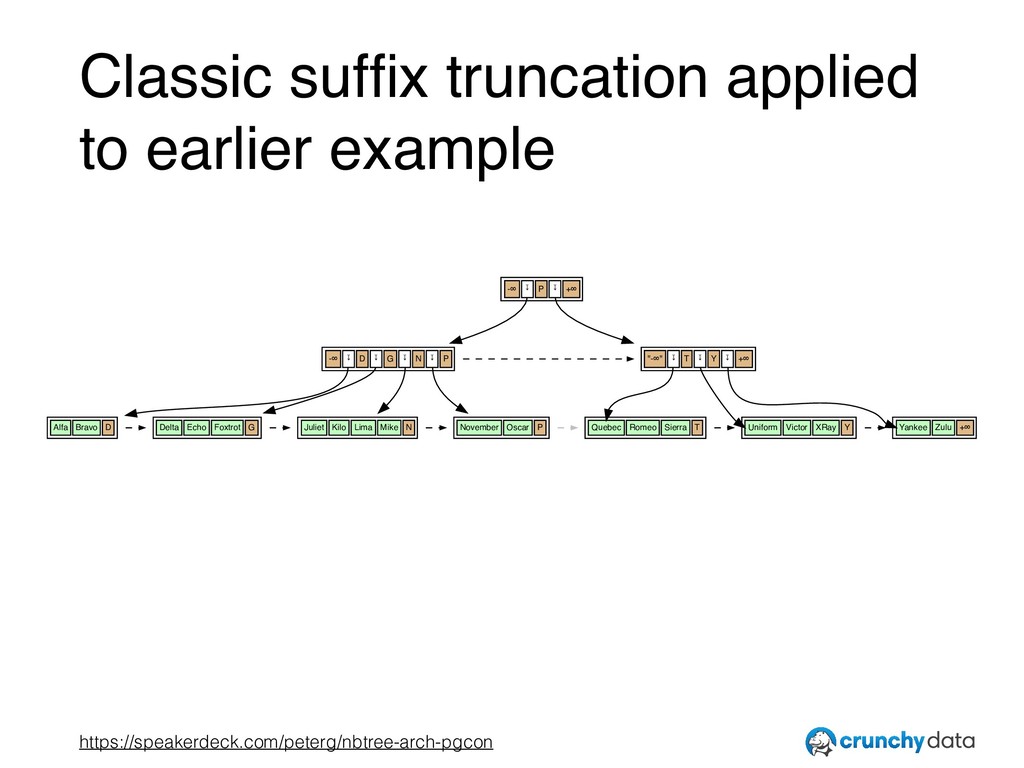
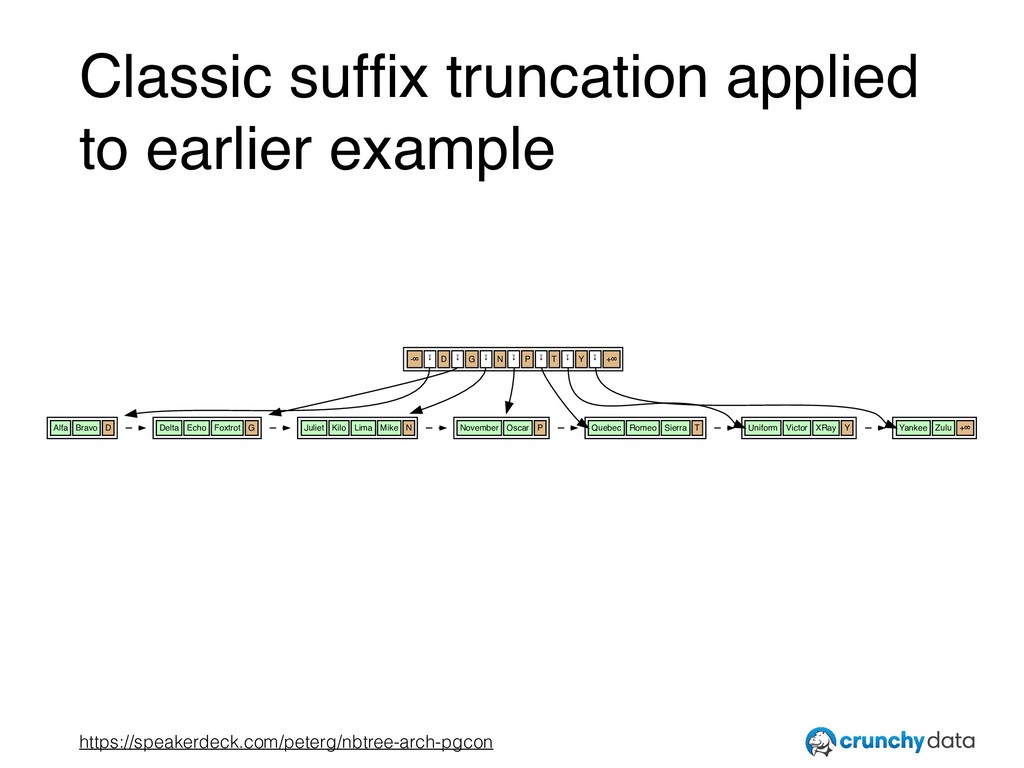
![– Lanin & Sasha paper (LS86) [emphasis added], from “2.2](https://files.speakerdeck.com/presentations/931c3f5a93784a37a8445e0be1280b9f/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://speakerdeck.com/peterg/nbtree-arch-pgcon Future work [1] https://wiki.postgresql.org/wiki/Key_normalization Key normalization [1] — make](https://files.speakerdeck.com/presentations/931c3f5a93784a37a8445e0be1280b9f/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}