HASHING 2.1 Sorting 2.2 Hashing 3. DISK ACCESS 3.1 File Scans 3.2 Associative Access Using Indices 3.3 Buffer Management 4. AGGREGATION AND DUPLICATE REMOVAL 4.1 Aggregation Algorithm Based on Nested Loops 4.2 Aggregation Algorithms Based on Sorting 4.3 Aggregation Algorithms Based on Hashing 4.4 A Rough Performance Comparison 4.5 Additional Remarks on Aggregation 5. BINARY MATCHING OPERATIONS 5.1 Nested-Loops Join Algorithms 5.2 Merge-Join Algorithms 5.3 Hash Join Algorithms 5.4 Pointer-Based Joins 5.5 A Rough Performance Comparison 6. UNIVERSAL QUANTIFICATION 7. DUALITY OF SORT AND HASH-BASED QUERY PROCESSING ALGORITHMS 8. EXECUTION OF COMPLEX QUERY PLANS 9. MECHANISMS FOR PARALLEL QUERY 9.1 Parallel versus Distributed Database Systems 9.2 Forms of Parallelism 9.3 Implementation Strategies 9.4 Load Balancing and Skew 9.5 Architectures and Architecture Independence 10. PARALLEL ALGORITHMS 10.1 Parallel Selections and Updates 10.2 Parallel Sorting 10.3 Parallel Aggregation and Duplicate Removal 10.4 Parallel Joins and Other Binary Matching Operations 10.5 Parallel Universal Quantification 11. NONSTANDARD QUERY PROCESSING ALGORITHMS 11.1 Nested Relations 11.2 Temporal and Scientific Database Management 11.3 Object-oriented Database Systems 11.4 More Control Operators 12. ADDITIONAL TECHNIQUES FOR PERFORMANCE IMPROVEMENT 12.1 Precomputation and Derived Data 12.2 Data Compression 12.3 Surrogate Processing 12.4 Bit Vector Filtering 12.5 Specialized Hardware Survey paper. 86 pages! Sections can be read more or less independently, though. Similar observations made in sections we’ll skip.
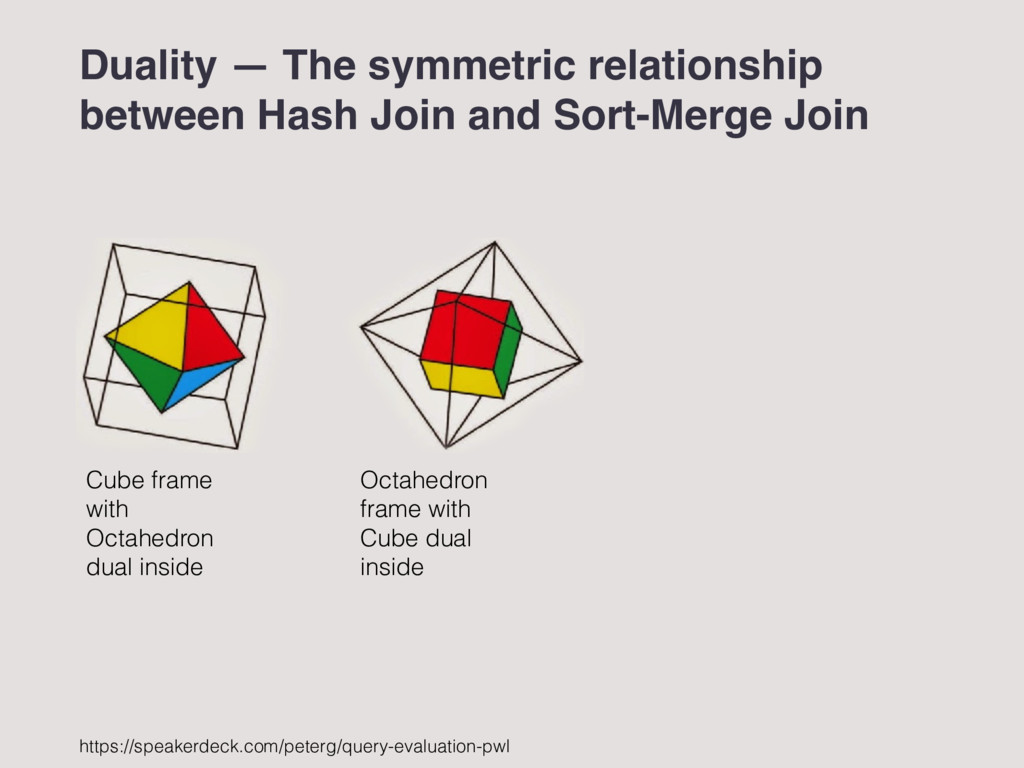
How nestloop is fundamentally different to hash & sort based algorithms. 2. Duality of Sort-Merge Join and Hash Join Introduction to both algorithms. 3. Trends in hardware driving “Sort vs. Hash” Why hash joins became popular in late 1980s/early 1990s. 4. Parallelism, bus contention, and algorithm choice Key design decisions for parallelism. 5. Duality between Sorting and Hashing revisited Central idea of the paper, in summary. Overview
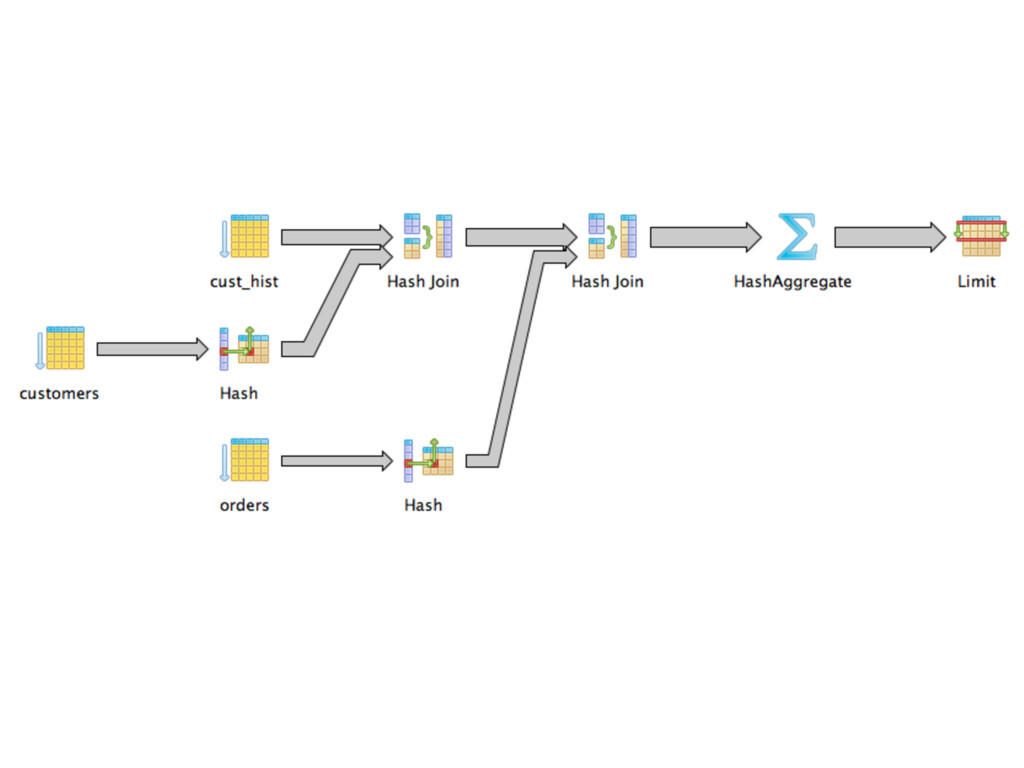
top, answering query. User requests next tuple from root node. Tuple-at-a-time processing. Requests for next tuple cascade down query plan tree. - Not all node types can return tuple quickly (e.g., sort node must do a lot of work up-front), but most can. - Nodes don’t necessarily “give all the tuples they have to give” in the end — perhaps only what they’re asked for. 7
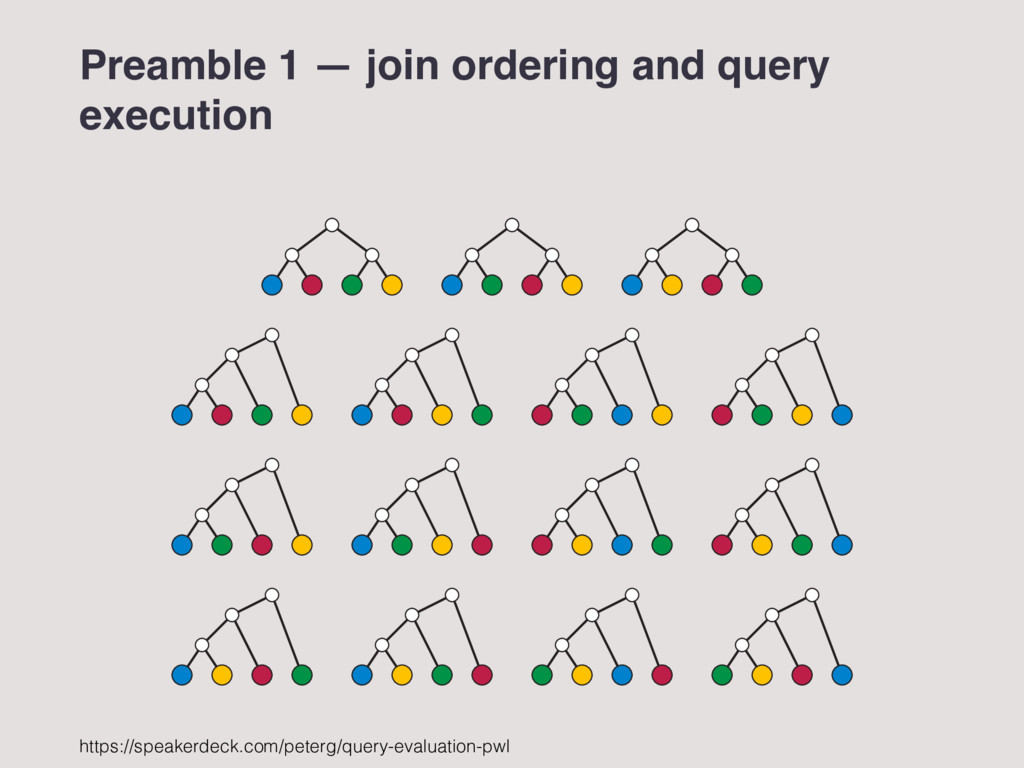
the one that processes fewest tuples in order to give a correct answer. Using an index (with selective qualification) good because most data never read in the first place. Optimizer’s choice driven by statistics, from which selectivity is inferred. Join ordering key to getting good plan. Most joins can be reordered without affecting final answer (they’re commutative and associative). 9 Plan shape
to execute any join that you can express with SQL. Often index scans on both sides of join. Or, another nestloop join on outer side of top-level nestloop join. Output from outer side “plugged into” inner side. Often very fast — “lookup based”. First joined tuple returned almost immediately. 13
fed by index scans (or another nested loop join) can scale wonderfully well. Nothing scales as well as selective index scans. Decent optimizer important too, to get the join ordering right consistently. Sort-merge join and Hash Join are not really “in competition” with nested loop Join — only each other. 30 Low latency queries
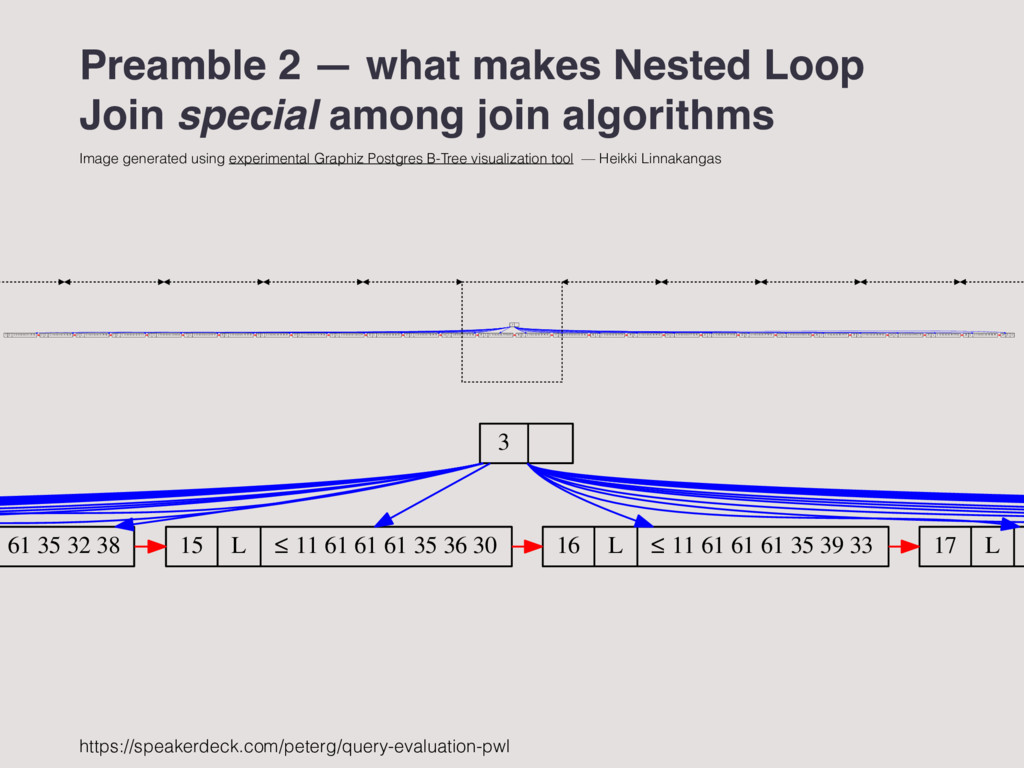
loop join heavy plans] grows linearly with the number of records involved, which might very well mean that the cost is effectively independent of the database size…the cost of index look-ups in traditional B-tree indexes grows logarithmically with the database size…” [1] Modern B-Tree techniques, 5.9 Nested Queries and Nested Iteration — Goetz Graefe, Modern B-Tree techniques [1]
transaction processing (OLTP) and in online analytical processing (OLAP), is to ensure that query results are fetched, not searched and computed…In relational database systems, fetching query results directly means index searches. If a result requires records from multiple indexes, index nested loops join or, more generally, nested iteration are the algorithms of choice.” — Goetz Graefe, Modern B-Tree techniques [1] [1] Modern B-Tree techniques, 5.9 Nested Queries and Nested Iteration
Join How nestloop is fundamentally different to hash & sort based algorithms. 2. Duality of Sort-Merge Join and Hash Join Introduction to both algorithms. 3. Trends in hardware driving “Sort vs. Hash” Why hash joins became popular in late 1980s/early 1990s. 4. Parallelism, bus contention, and algorithm choice Key design decisions for parallelism. 5. Duality between Sorting and Hashing revisited Central idea of the paper, in summary.
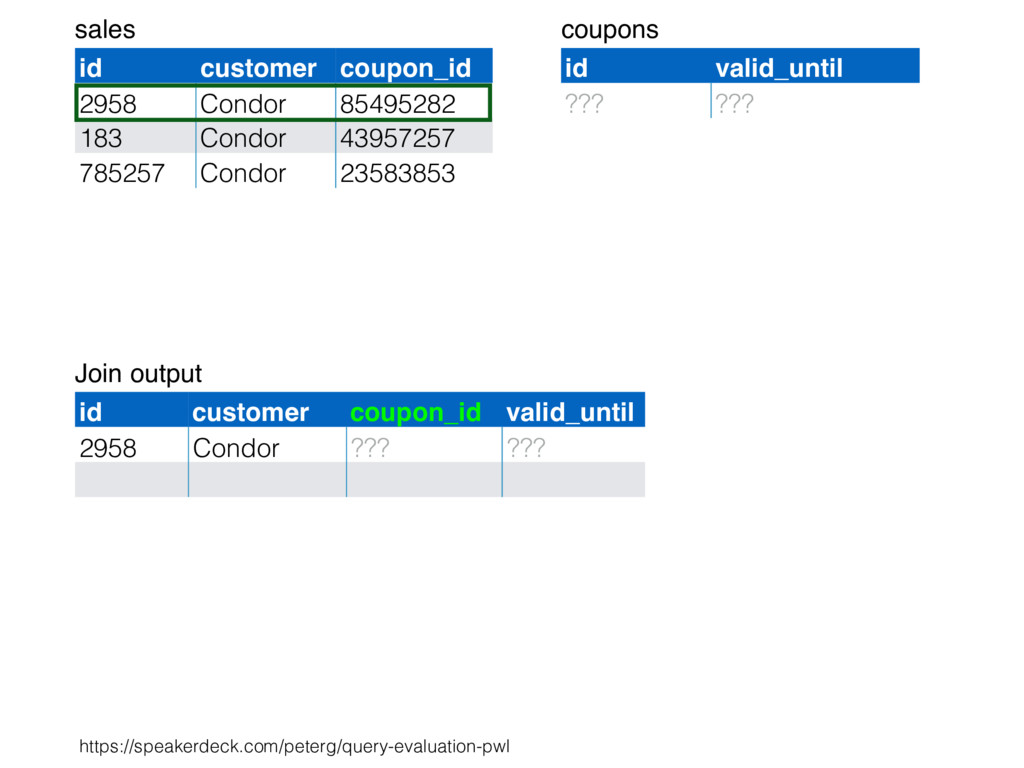
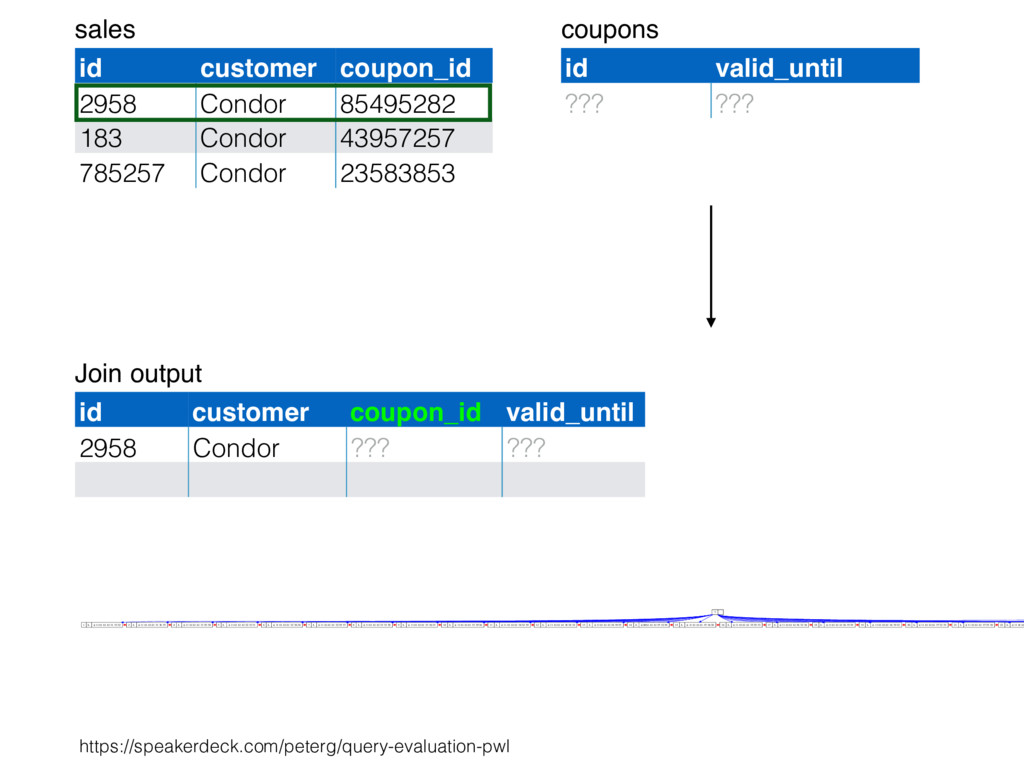
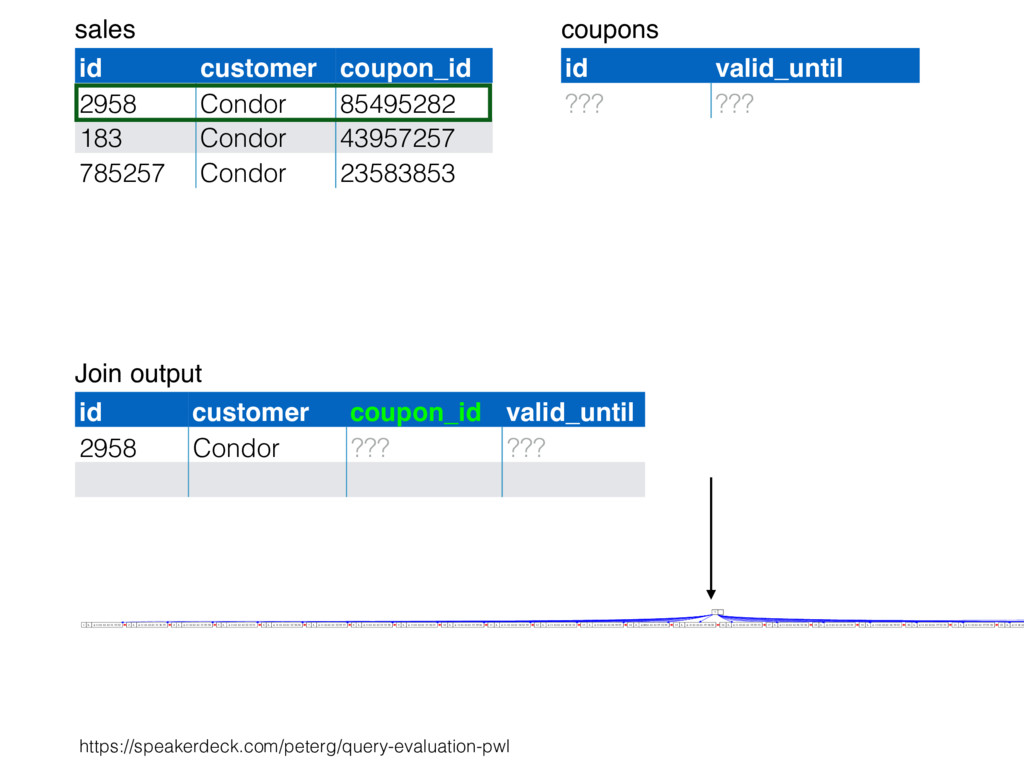
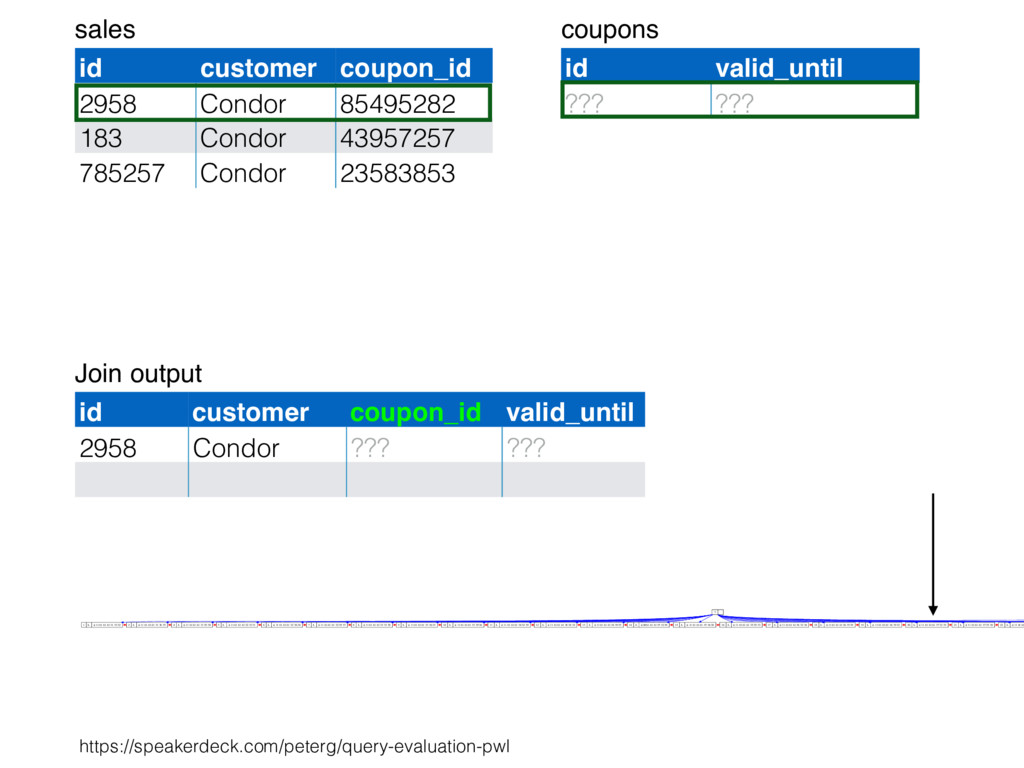
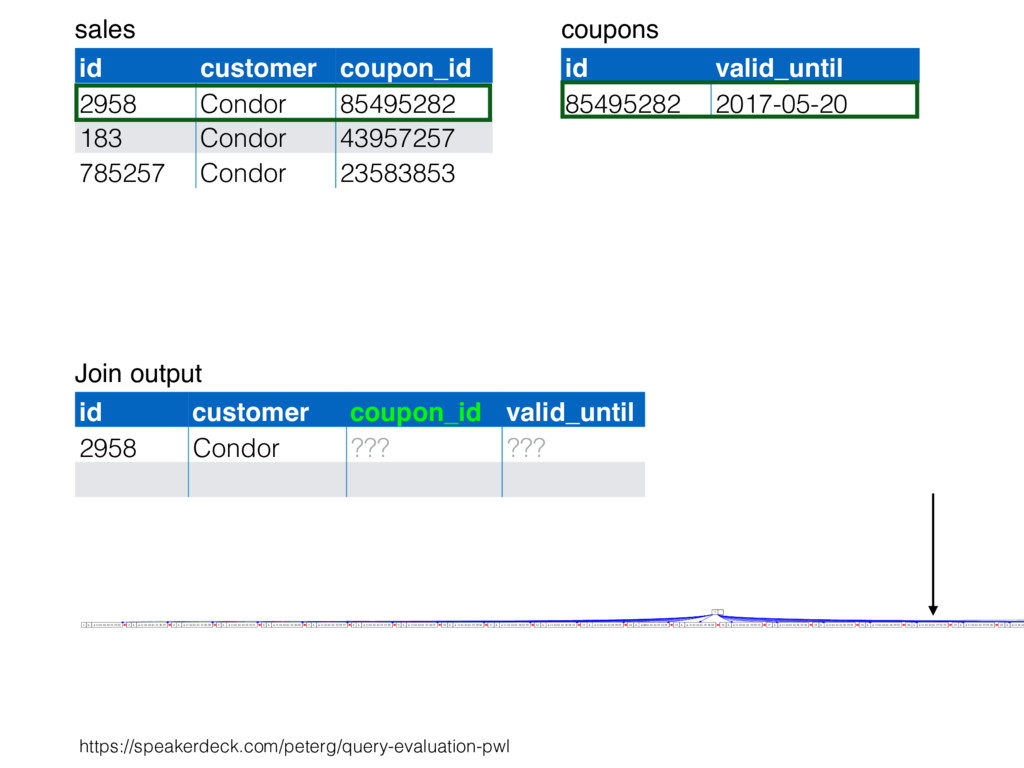
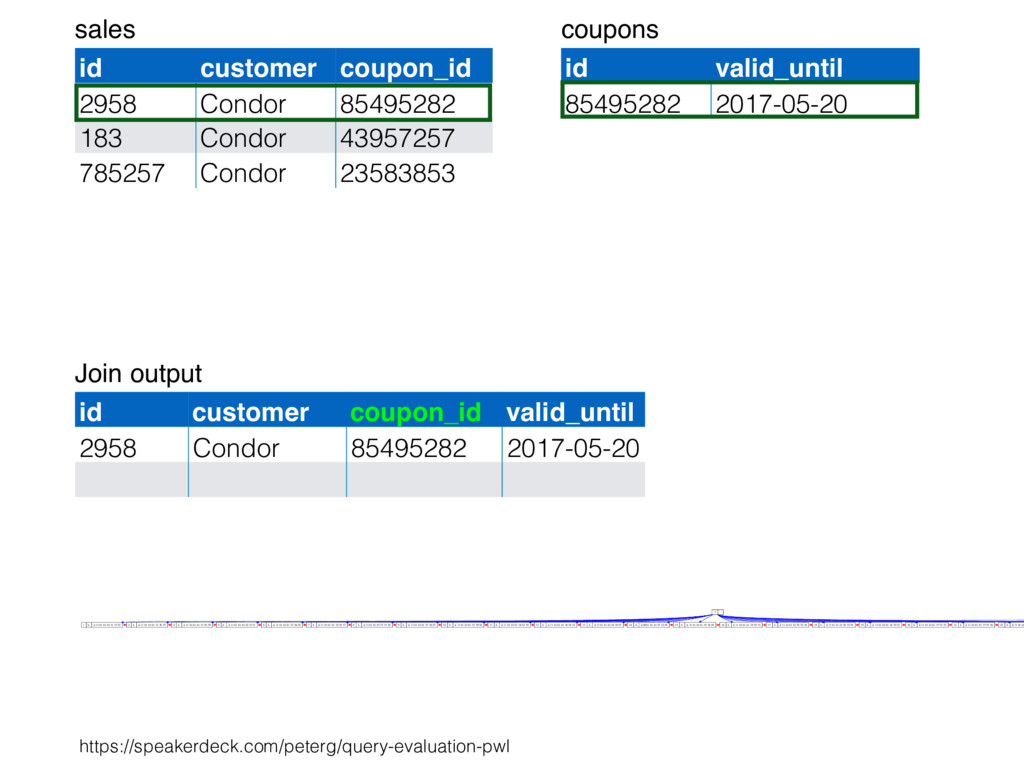
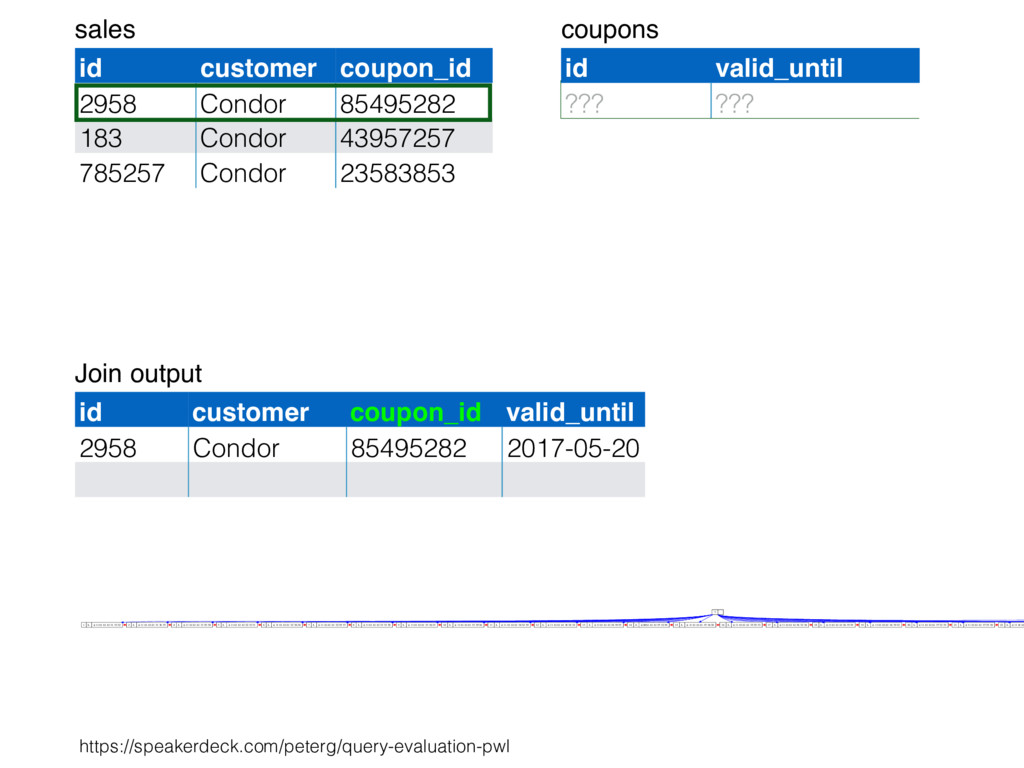
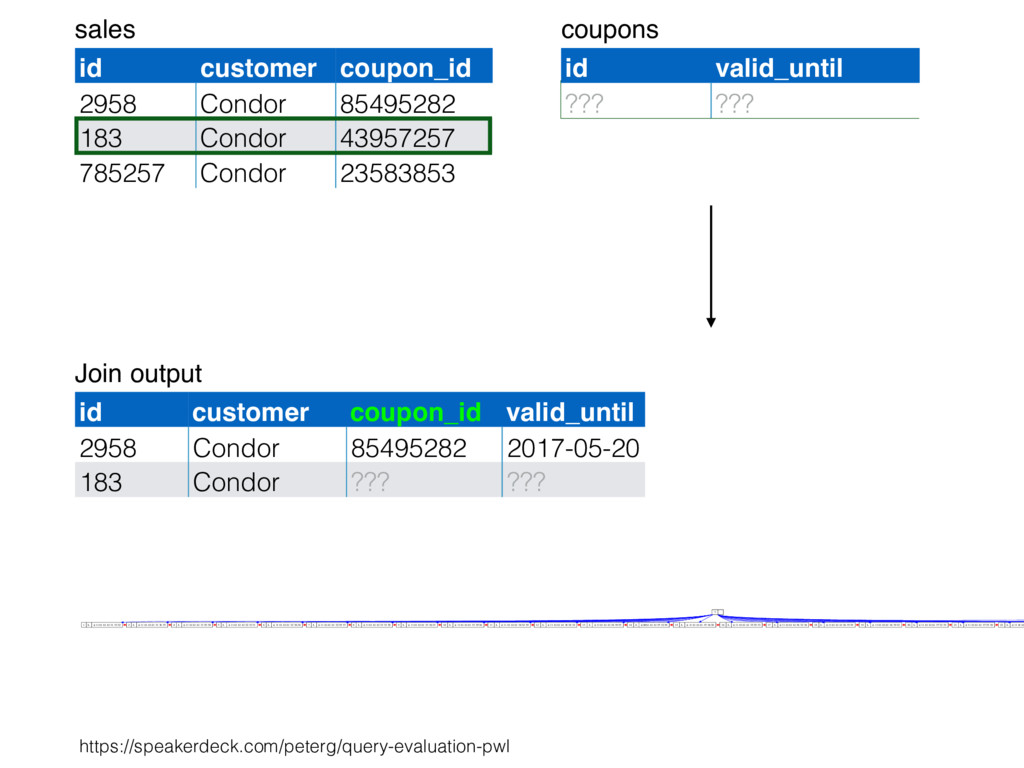
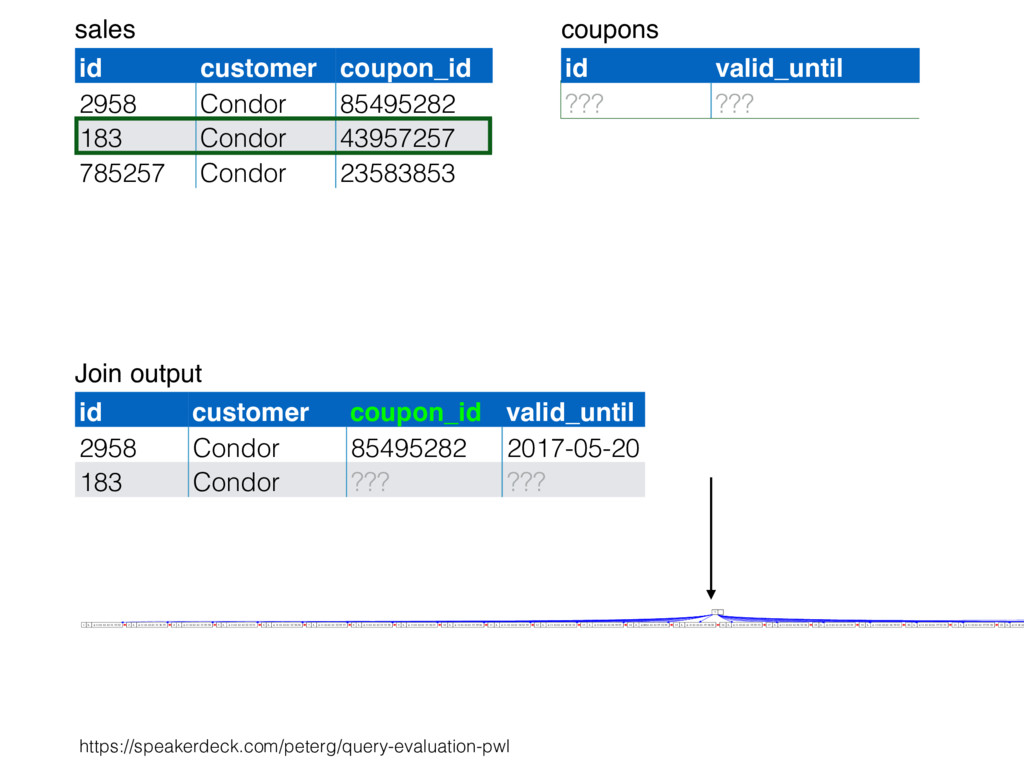
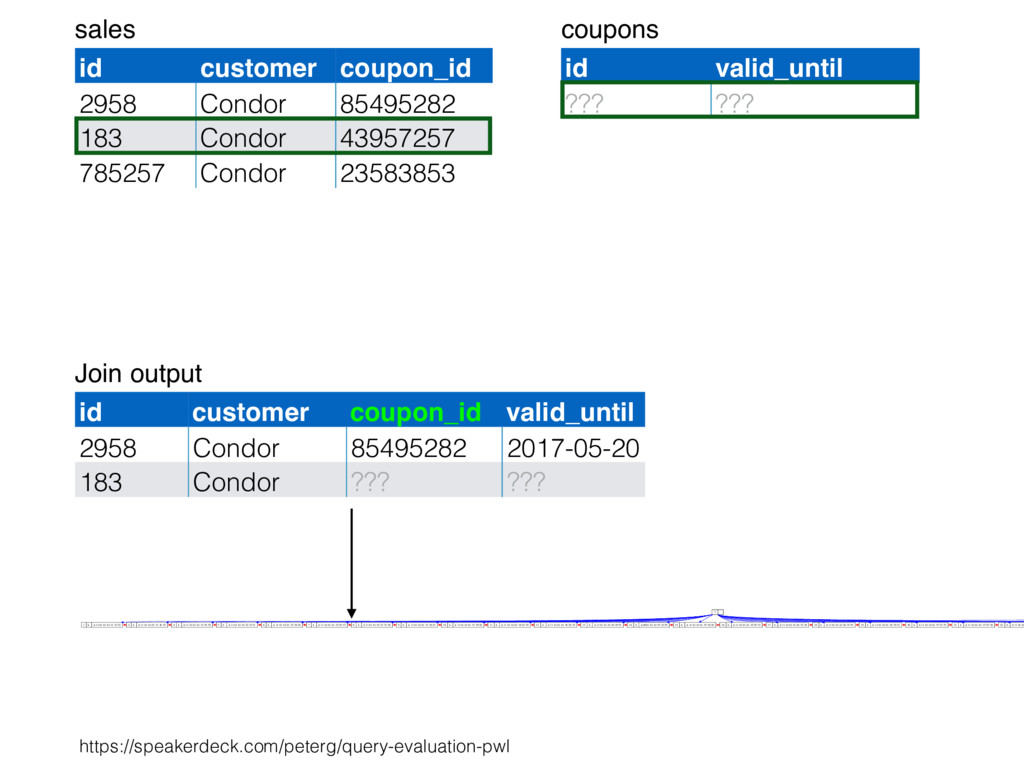
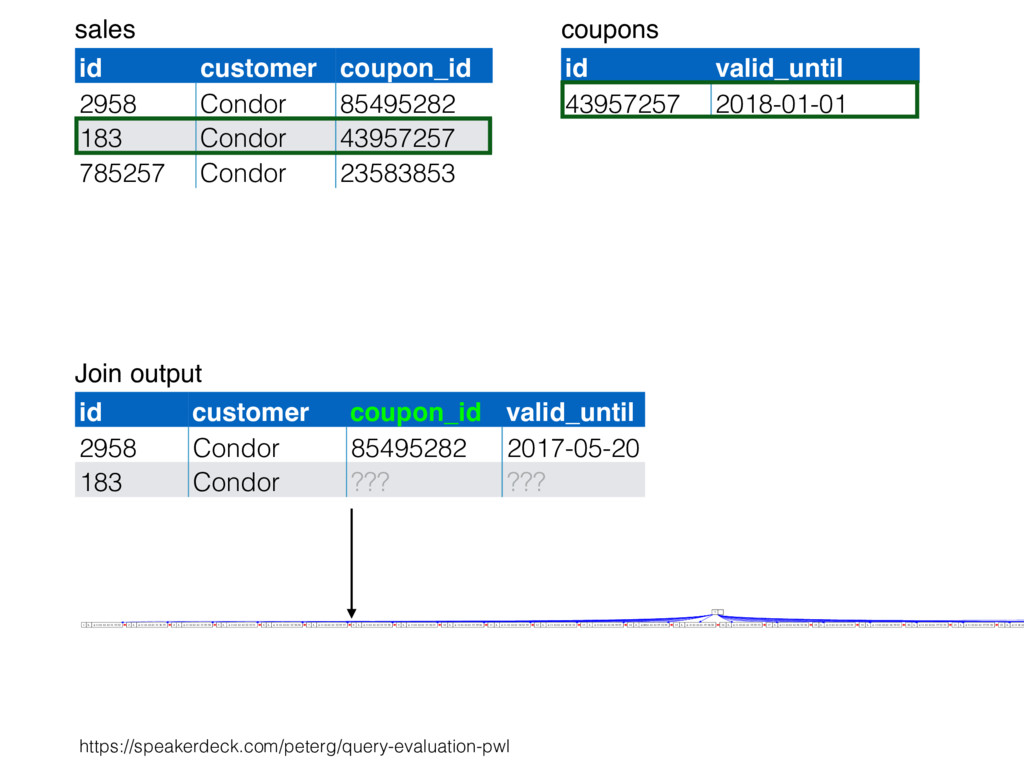
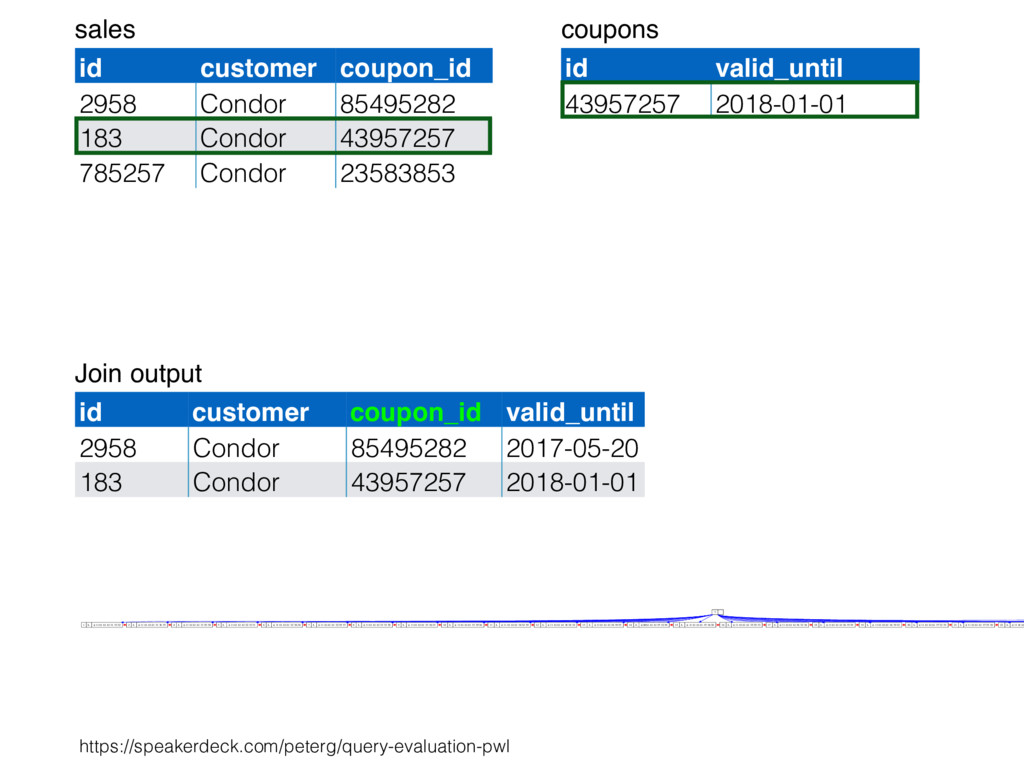
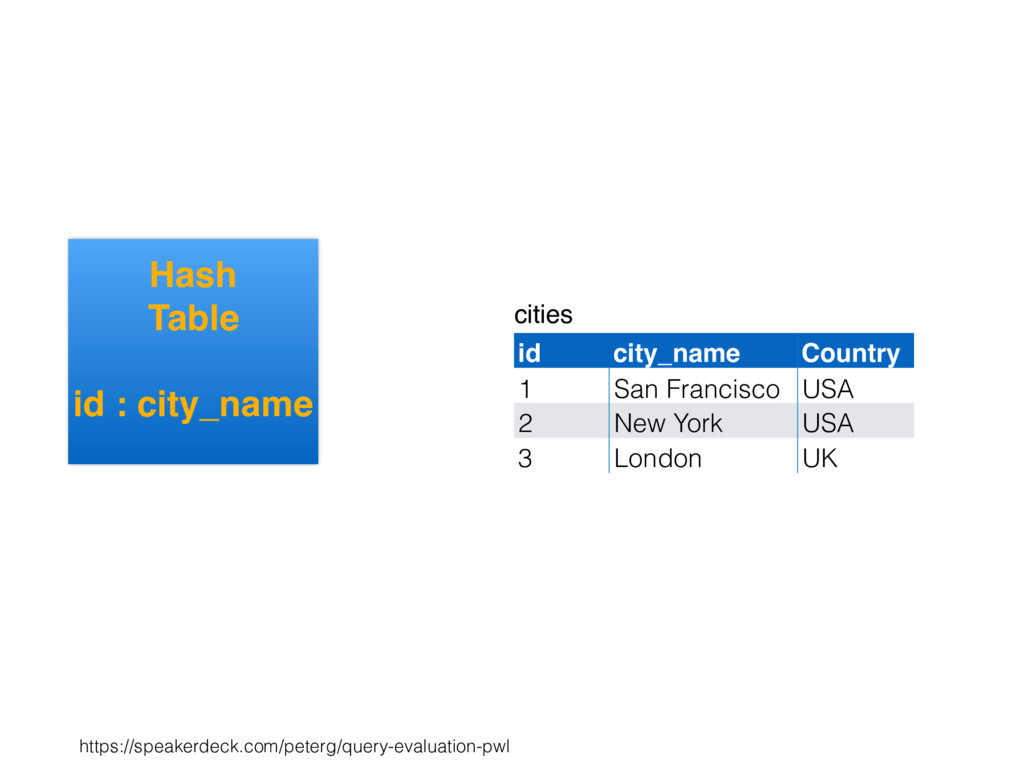
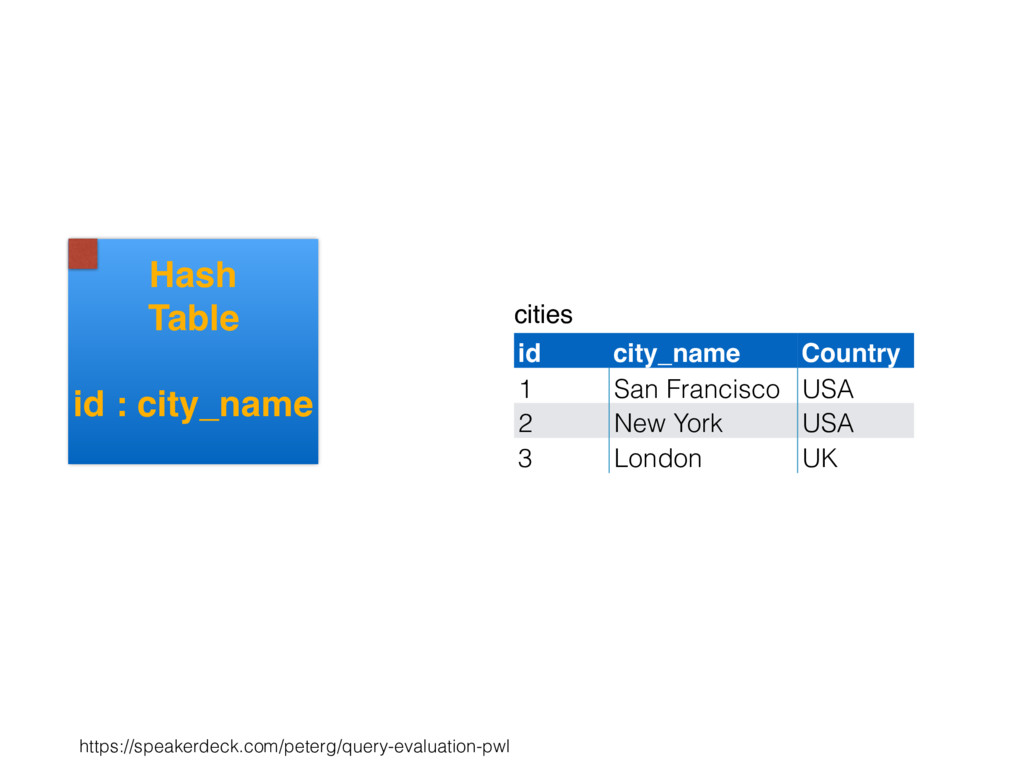
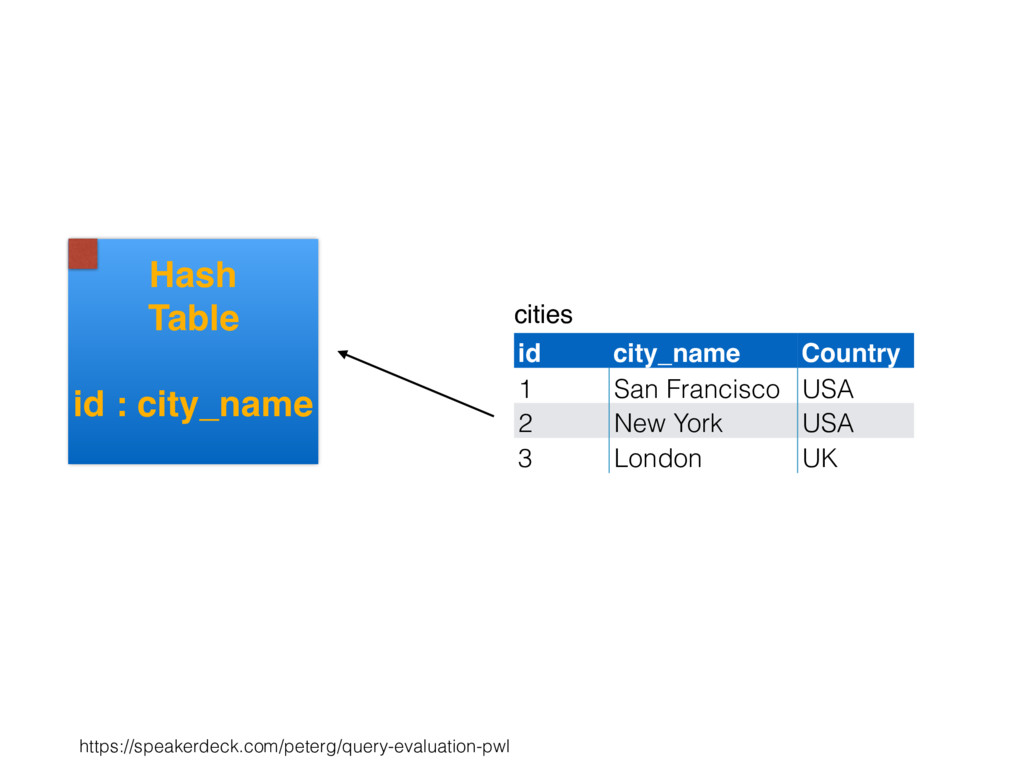
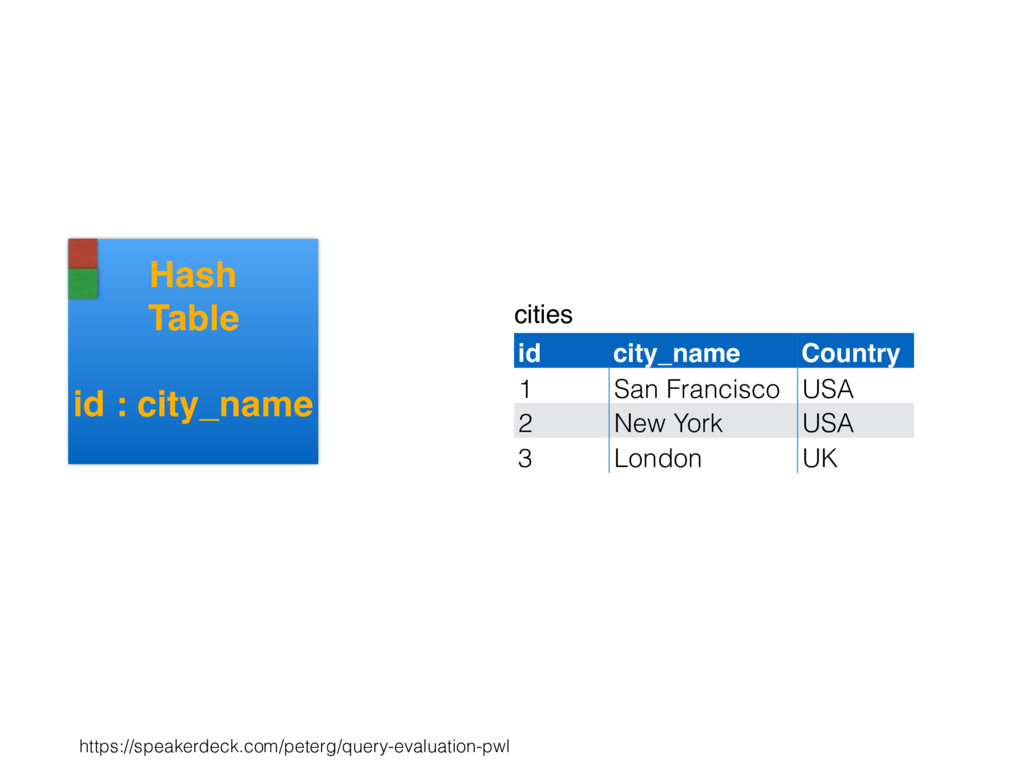
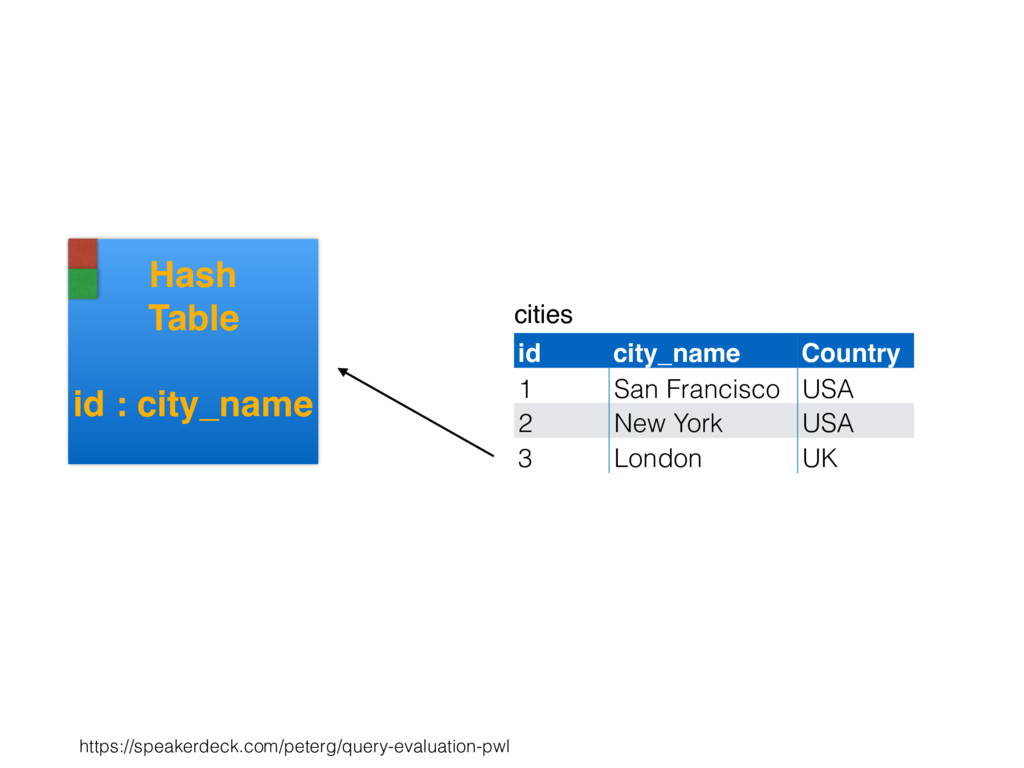
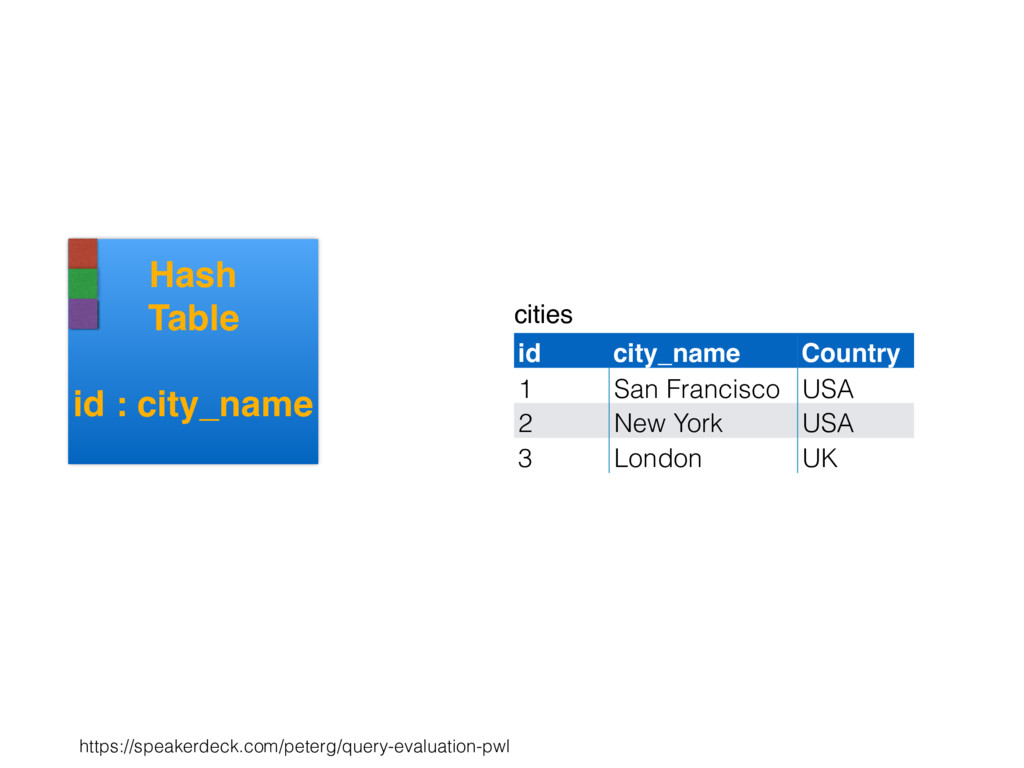
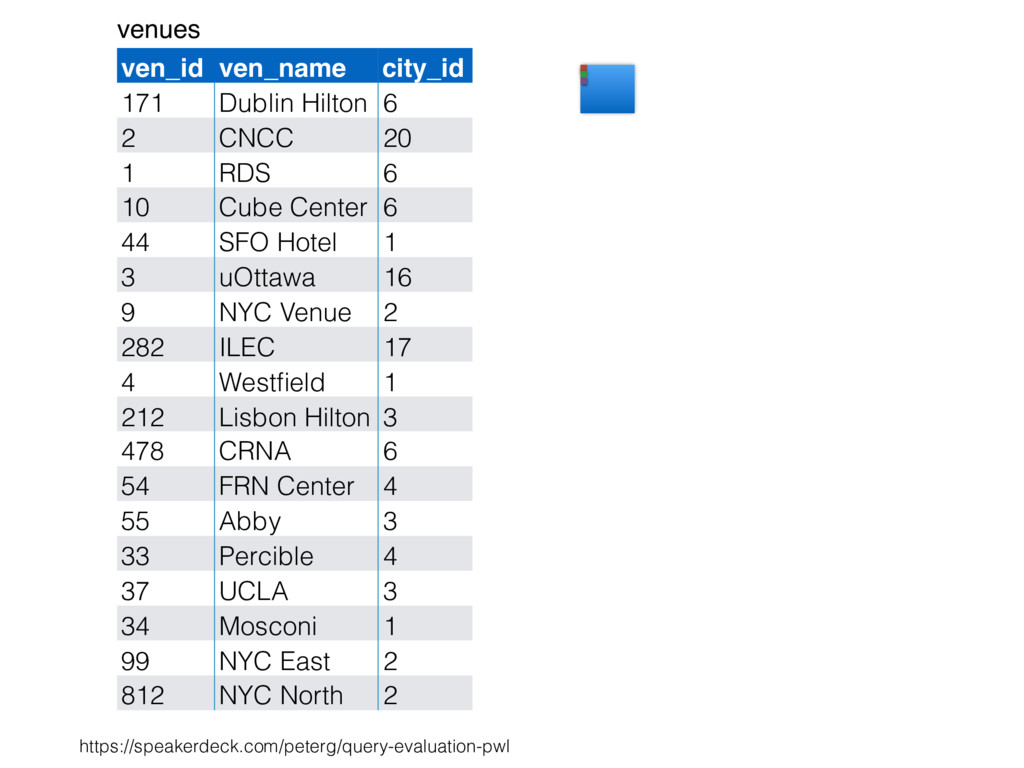
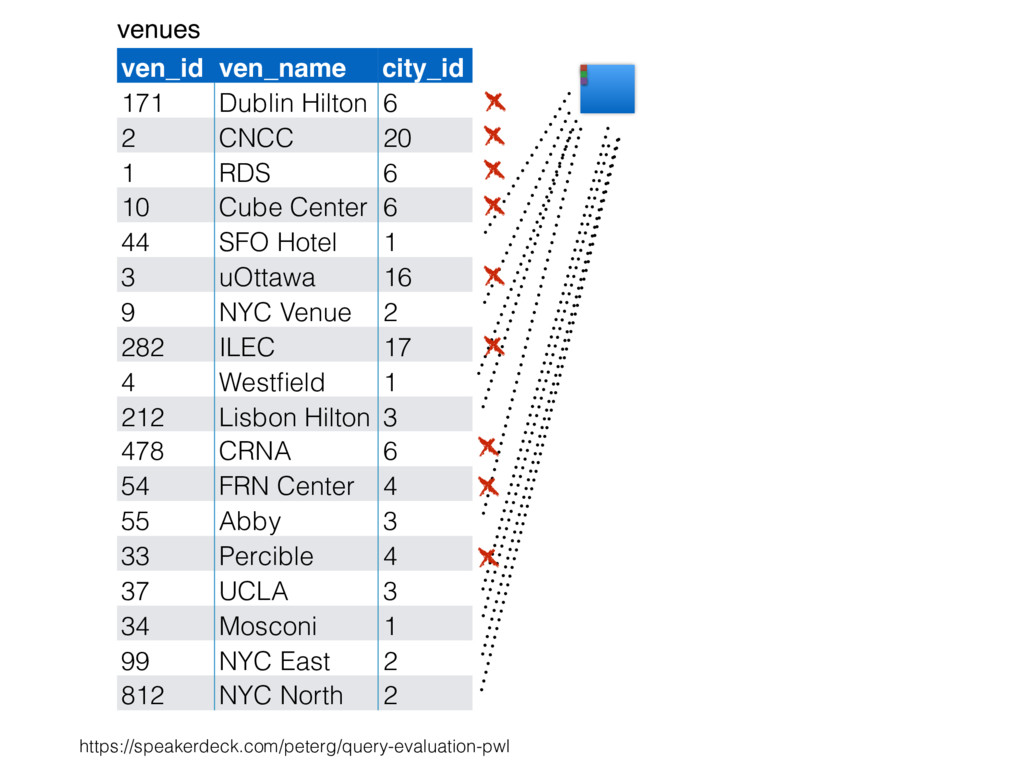
relation. Hash table consists of join attribute as hash key for each row, alongside row itself. Build hash table by scanning smaller table/input. Scan larger table, joining rows from smaller relation by performing lookups in hash table. Only supports equi-joins — joining on simple equality condition. 35
is smaller, such as a lookup table. Or, moderately large subset of table (e.g., hash table built by reading from bitmap index scan). High join selectivity works well (e.g., uncorrelated join attributes). Hash table can “overflow”, and spill “batches” to disk when insufficient main memory available. 36
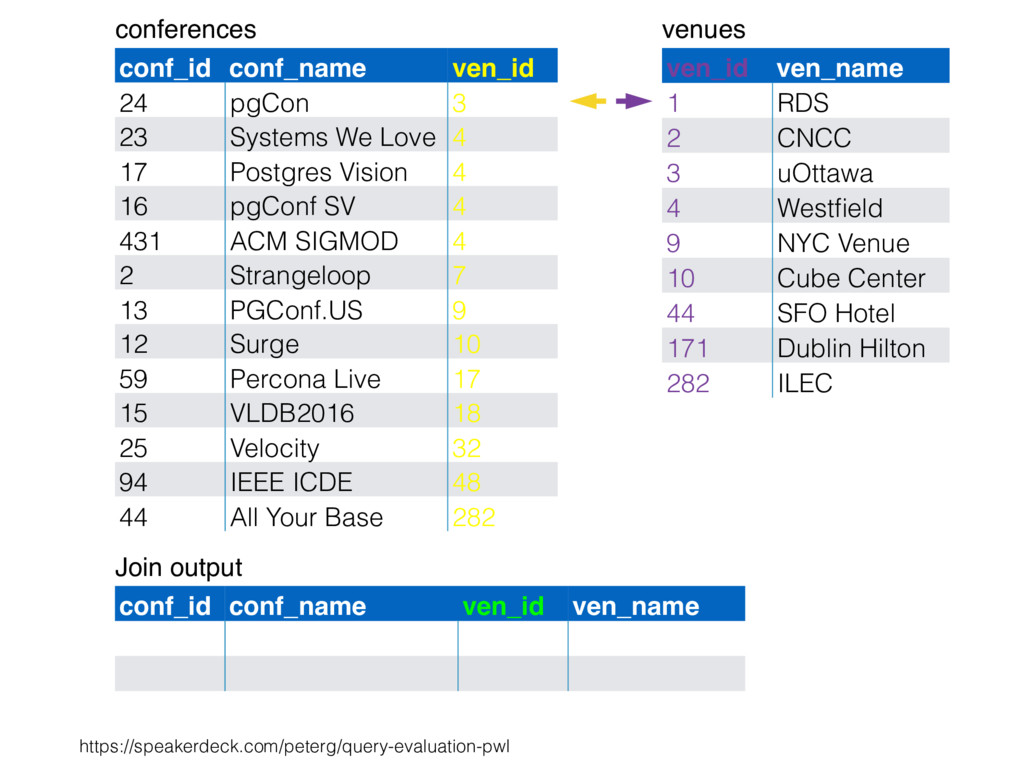
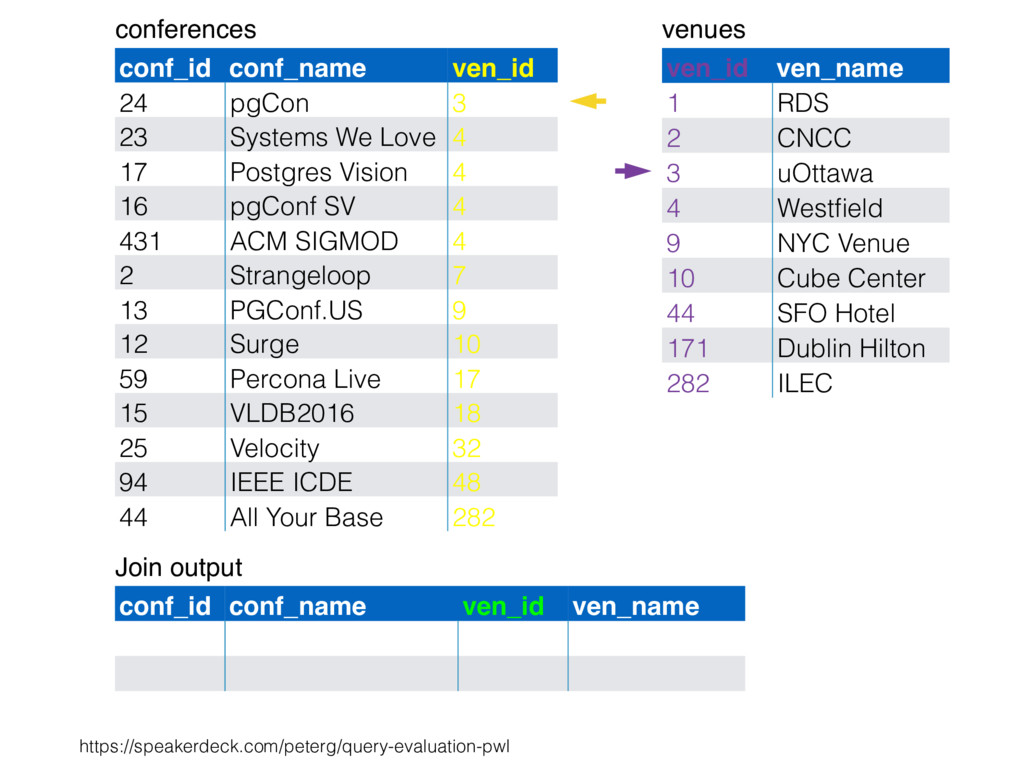
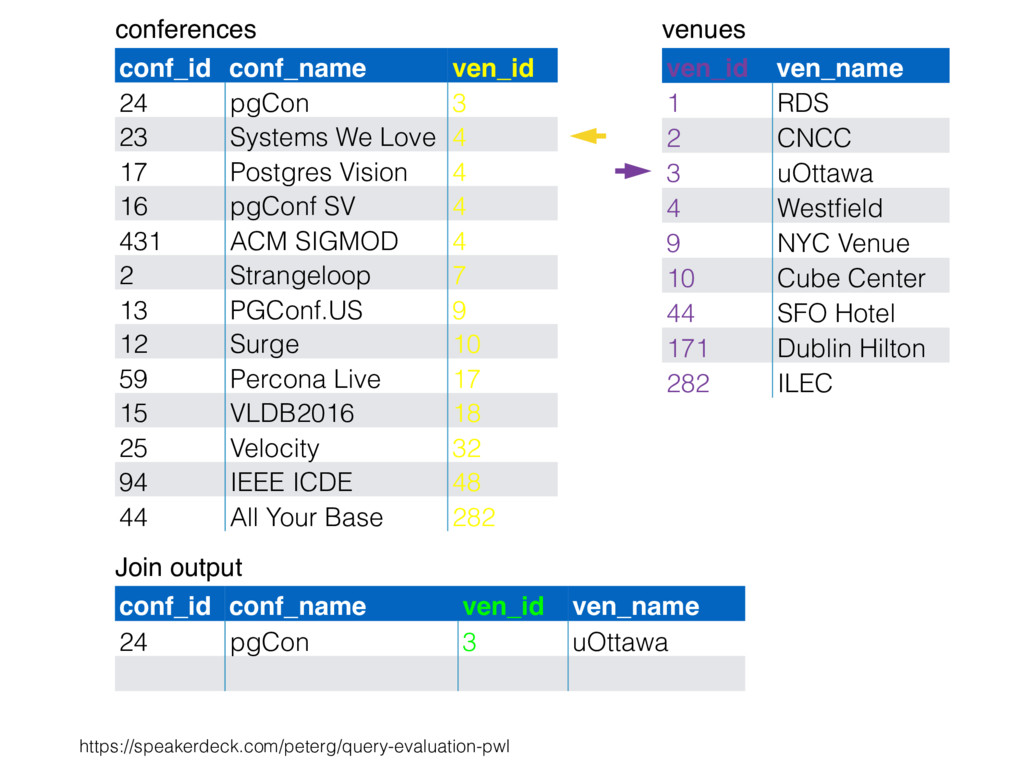
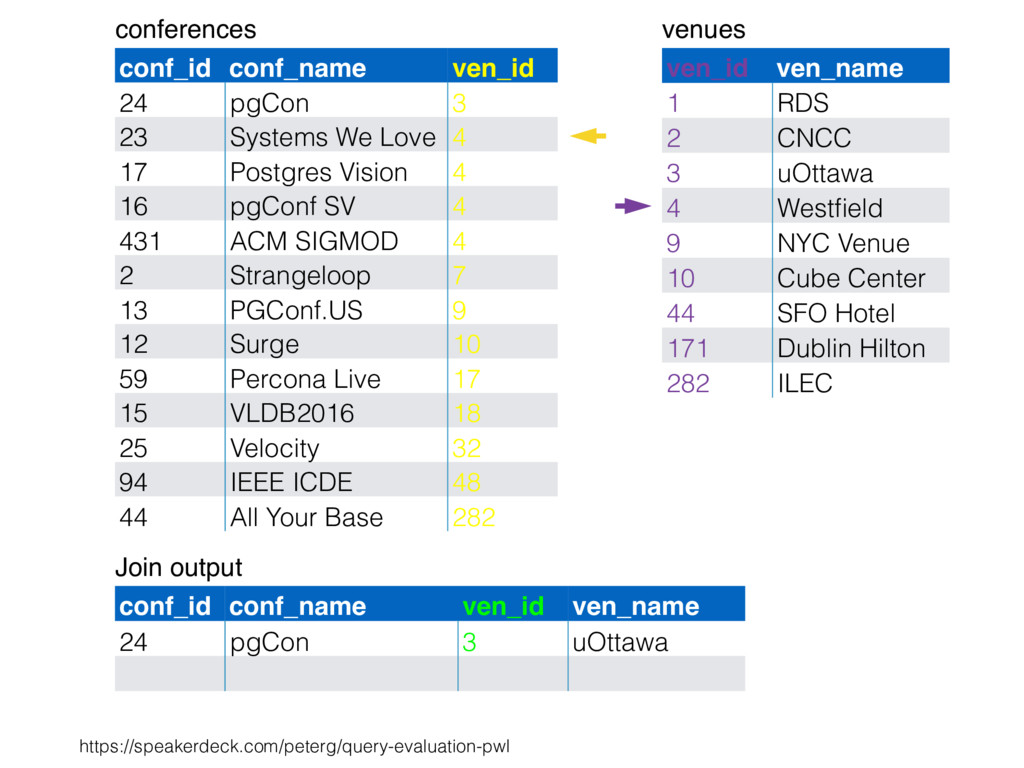
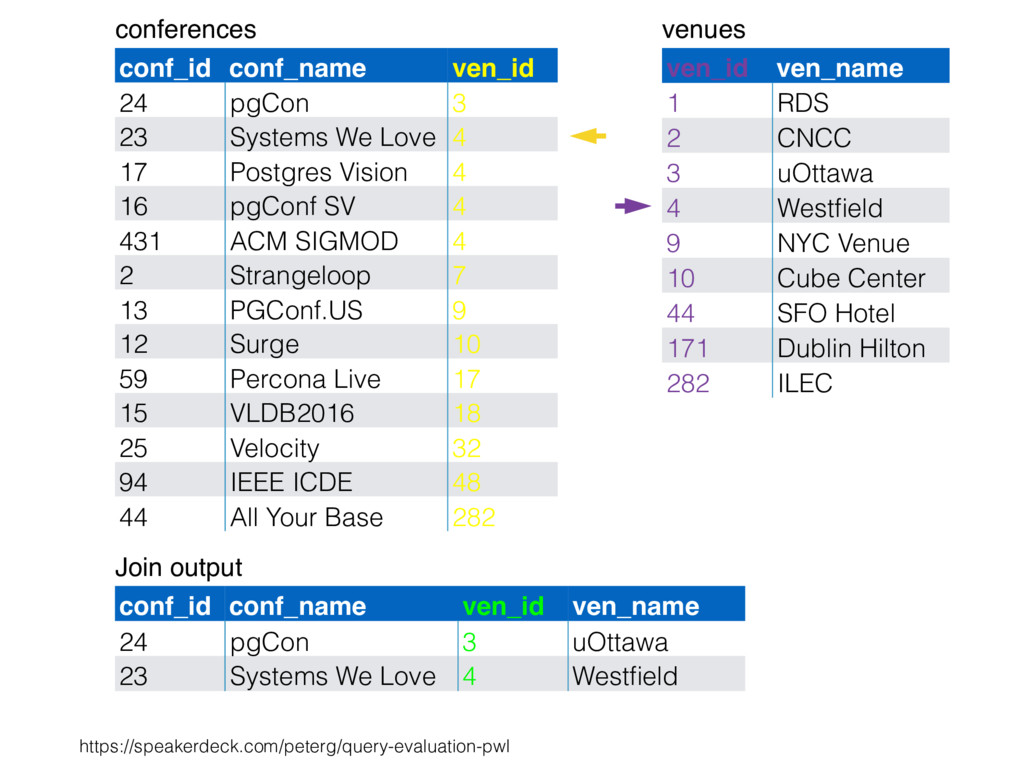
CNCC 20 1 RDS 6 10 Cube Center 6 44 SFO Hotel 1 3 uOttawa 16 9 NYC Venue 2 282 ILEC 17 4 Westfield 1 212 Lisbon Hilton 3 478 CRNA 6 54 FRN Center 4 55 Abby 3 33 Percible 4 37 UCLA 3 34 Mosconi 1 99 NYC East E 2 812 NYC North 2 x x x x x x x x x
both sides of join. Actual sort node typically appears for at least one side of join. Often both sides. Input might instead come from an index scan. B- Trees store items in the natural sort order of columns that are indexed. Sorts can, in general, spill to disk if there is much data to sort. 48
some ways — not limited to equi-joins. Can also be interval-based, for example. Sorts can, in general, spill to disk if there is much data to sort. External sorts usually still fast enough. 60
Join How nestloop is fundamentally different to hash & sort based algorithms. 2. Duality of Sort-Merge Join and Hash Join Introduction to both algorithms. 3. Trends in hardware driving “Sort vs. Hash” Why hash joins became popular in late 1980s/early 1990s. 4. Parallelism, bus contention, and algorithm choice Key design decisions for parallelism. 5. Duality between Sorting and Hashing revisited Central idea of the paper, in summary.
pull-out section of his book to various orders in which to merge runs ❖ Each of these is a different strategy with different advantages and disadvantages ❖ Some depend on being able to read tapes backwards or have an operator change tapes ❖ They all assume you have a small fixed number of tape drives Prehistory: Merge Scheduling, and early importance of Sort-merge join
book to various orders in which to merge runs ❖ Each of these is a different strategy with different advantages and disadvantages ❖ Some depend on being able to read tapes backwards or have an operator change tapes ❖ They all assume you have a small fixed number of tape drives “Readers will benefit most from this material by transplanting themselves temporarily into the mindset of the 1970s. Let us therefore pretend that we still live in that bygone era.” — Donald Knuth, The Art of Computer Programming: Volume 3: Sorting and Searching (2nd Edition,1998)
book to various orders in which to merge runs ❖ Each of these is a different strategy with different advantages and disadvantages ❖ Some depend on being able to read tapes backwards or have an operator change tapes ❖ They all assume you have a small fixed number of tape drives • Limited number of tape drives — use of actual magnetic tape decks assumed! • These days, we still almost always do one merge pass. Polyphase techniques of minimal practical value, since in practice we should be able to fit at least one record from each run in memory, for heap that merges (to produce final sorted output). • Every time main memory size doubles, our capacity to have an external sort complete with only one pass quadruples. • Capacity doubled many times since early 1970s! • External sorting often still necessary today — data sizes have grown, too.
hash joins in major systems in late 1980s and early 1990s largely response to trends in CPU architecture. In particular, the huge increase in main memory sizes. 64-bit architectures become available in high end commodity servers. “Hybrid” hash joins have plausible spill mechanism. It now matters far less that there is no such thing as “polyphase hashing”. Sort-merge join loses a significant advantage. 67
.~o,.%°~o,. The tournament tree of replacement-selection sort at left has bad cache behavior, unless the entire tournament fits in cache. The diagram at left shows the memory references as a winner is removed, and a new element is added to the tournament. Each traversal of the tree has many cache misses at the leaves of the tree. By contrast, the QuickSort diagrammed on the right fits entirely in the on-board cache, and partially in the on-chip cache. [1] AlphaSort: A Cache-Sensitive Parallel External Sort — Nyberg, Barclay, Cvetanovic, Gray, and Lomet (VLDB Journal Volume 4, 1995)
capacity as efficiently as possible no longer first concern. Rather, CPU cache efficiency becomes first concern. Forget elegance! Focus on cache misses, and to a lesser extent instruction count and branch prediction. 70 [1] AlphaSort: A Cache-Sensitive Parallel External Sort — Nyberg, Barclay, Cvetanovic, Gray, and Lomet (VLDB Journal Volume 4, 1995)
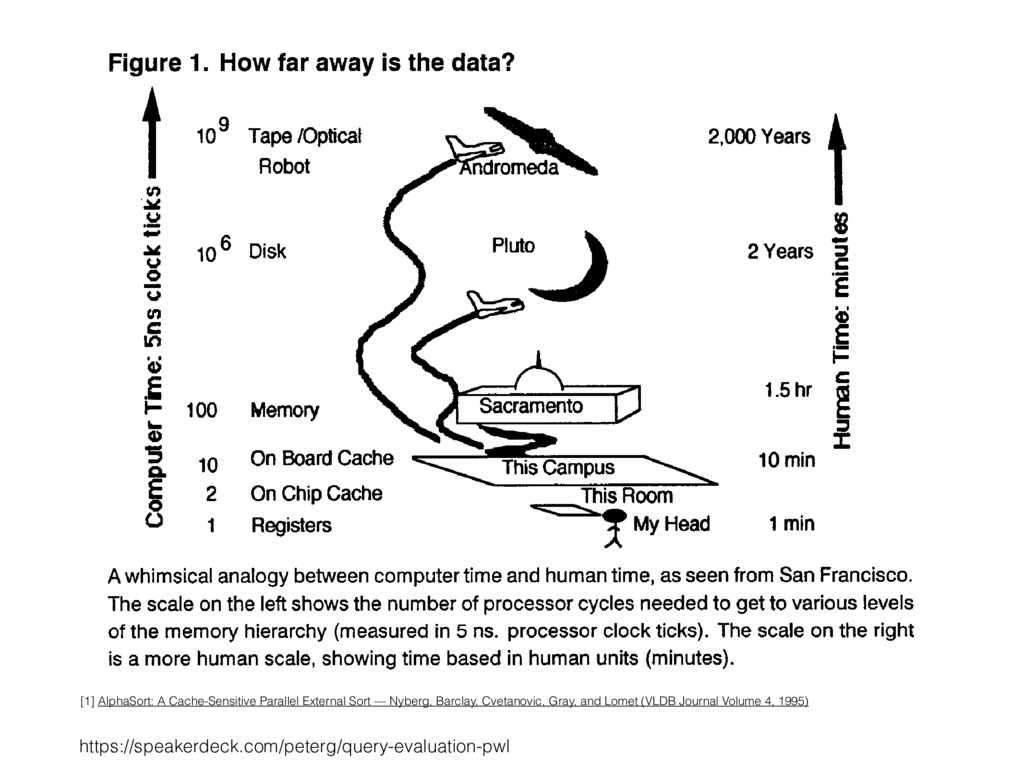
109 Tape/Optical ~ ° . m ~ ~ a cn Robot 10 6 Disk O C .E I-- 100 Memory ~, 10 On Board C ..... ~ This Campus Eo 2 On Chip Cache ]his Room O 1 Registers ~ y My Head 2,000 Years i 2 Years .g 1.5hr ~ Z 10 min 1 min A whimsical analogy between computer time and human time, as seen from San Francisco. The scale on the left shows the number of processor cycles needed to get to various levels of the memory hierarchy (measured in 5 ns. processor clock ticks). The scale on the right is a more human scale, showing time based in human units (minutes). Suppose that AlphaSort paid no attention to the cache, and that it randomly [1] AlphaSort: A Cache-Sensitive Parallel External Sort — Nyberg, Barclay, Cvetanovic, Gray, and Lomet (VLDB Journal Volume 4, 1995)
Join How nestloop is fundamentally different to hash & sort based algorithms. 2. Duality of Sort-Merge Join and Hash Join Introduction to both algorithms. 3. Trends in hardware driving “Sort vs. Hash” Why hash joins became popular in late 1980s/early 1990s. 4. Parallelism, bus contention, and algorithm choice Key design decisions for parallelism. 5. Duality between Sorting and Hashing revisited Central idea of the paper, in summary.
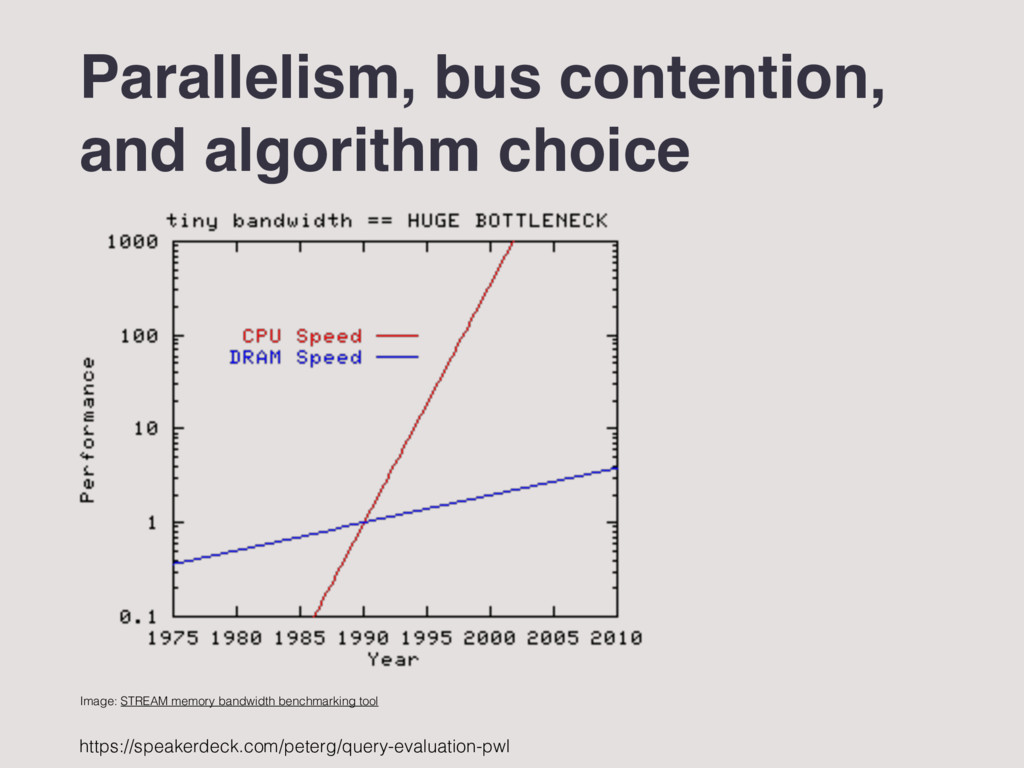
Parallelize serial algorithms to increase throughput/performance. “Bus contention” (memory bandwidth saturation) is a major bottleneck, even in 1994. This is a key design concern for parallelism. This general problem has further intensified in the years since Graefe’s paper was published. 74
be minimized — locality matters. Push as much work down to each CPU as possible. Eliminate input before transfer occurs. “Sort vs. Hash” issues mostly about locality, too. More cores active, less memory per core (favors sort). Small hash table on inner side can easily be shared (favors hash). Hash table may be very small. 75
Join How nestloop is fundamentally different to hash & sort based algorithms. 2. Duality of Sort-Merge Join and Hash Join Introduction to both algorithms. 3. Trends in hardware driving “Sort vs. Hash” Why hash joins became popular in late 1980s/early 1990s. 4. Parallelism, bus contention, and algorithm choice Key design decisions for parallelism. 5. Duality between Sorting and Hashing revisited Central idea of the paper, in summary.
be sorted gradually, increasing locality as we go. This is much less important when dataset already naturally allows locality (e.g., Zipfian distribution). Faster with equal sized inputs, especially where tuples on both sides are typically actually output (matched/joined) in the end. Sort order can be reused (e.g., for ORDER BY). 79
from hash table. Not all hash probes are truly equally expensive, though, due to memory hierarchy. Actually joining tuples often uncommon. Determining that the hash table has no match at all very fast. Slow when very memory constrained, unless input is so skewed that batches on disk are “unpopular” (i.e. it turns out that scan of bigger table mostly only needs in- memory batch of hash table anyway). 80 Hash Join’s “combination”
of the memory hierarchy, and many equal-but-opposite effects are noticeable. Sense of Déjà vu, at times. Several “Sort vs. Hash” papers have been written in last 30 years. Well researched topic. “Memory is the new disk, CPU cache is the new memory” — may drive future developments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}