Video: https://www.youtube.com/watch?v=aic_9KNwKn0
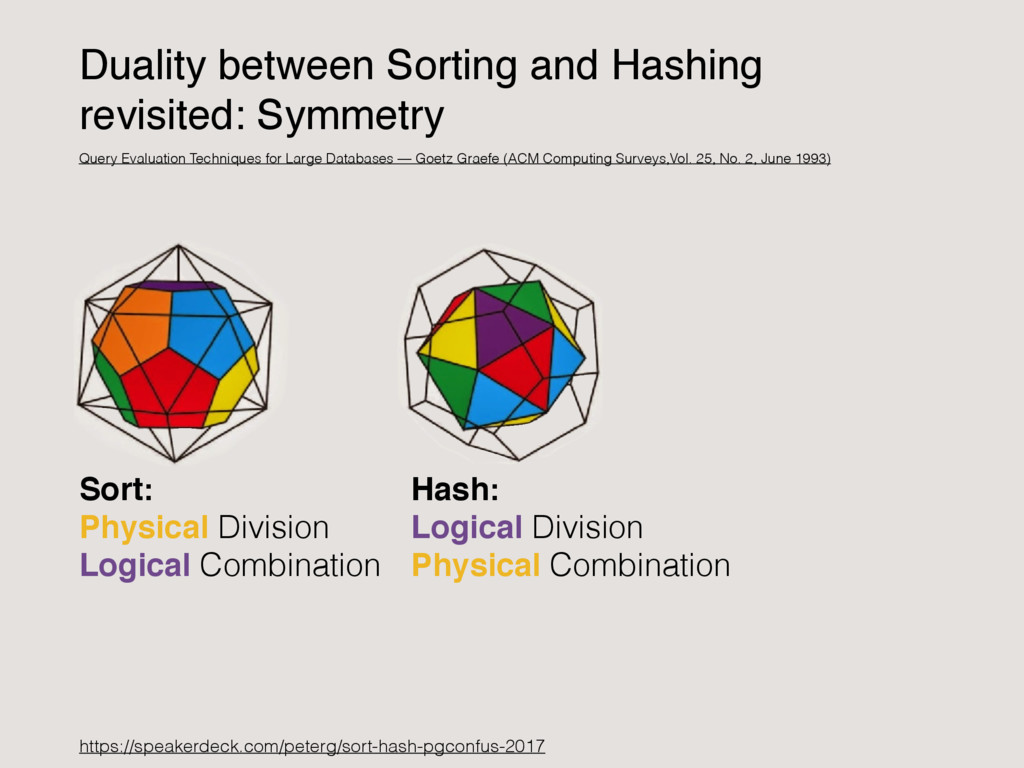
PostgreSQL 9.5 and 9.6 significantly improved upon the performance of both hash joins, and sort operations. Sorts are often used as input to GroupAggregate nodes and merge joins. While both approaches have various strengths and weaknesses, and are essential components of the PostgreSQL executor, their relative importance has somewhat shifted over the years. This happened due to trends in CPU and storage performance characteristics, and various improvements that gradually made their way into Postgres.
Capabilities expected to be part of PostgreSQL 10 may further complicate this picture; parallel hash join and parallel sort add another dimension that must be considered. This may force us to further revise the "Sort vs. Hash" analysis in the coming years.
In this talk, I'll discuss:
* Why merge joins may be faster than hash joins for particular cases, and vice-versa. (Nested-loop joins will be briefly discussed.)
* Improvements that have been made in both areas, and improvements that are tentatively scheduled for the next Postgres release.
* How to conceptualize both approaches, to understand why the optimizer may prefer one or the other of the two general approaches in practice.
* A historical perspective: the waxing and waning of sort merge join since the 1970s.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}