KubeCon + CloudNativeCon Europe 2025 Recap: The GPUs on the Bus Go 'Round and 'Round / Kubernetes Meetup Tokyo #70
Kubernetes Meetup Tokyo #70 での発表資料です。KubeCon + CloudNativeCon Europ 2025 でのセッション "The GPUs on the Bus Go 'Round and 'Round" を recap しつつ、関連するコミュニティの動向や PFN での事例を紹介します。
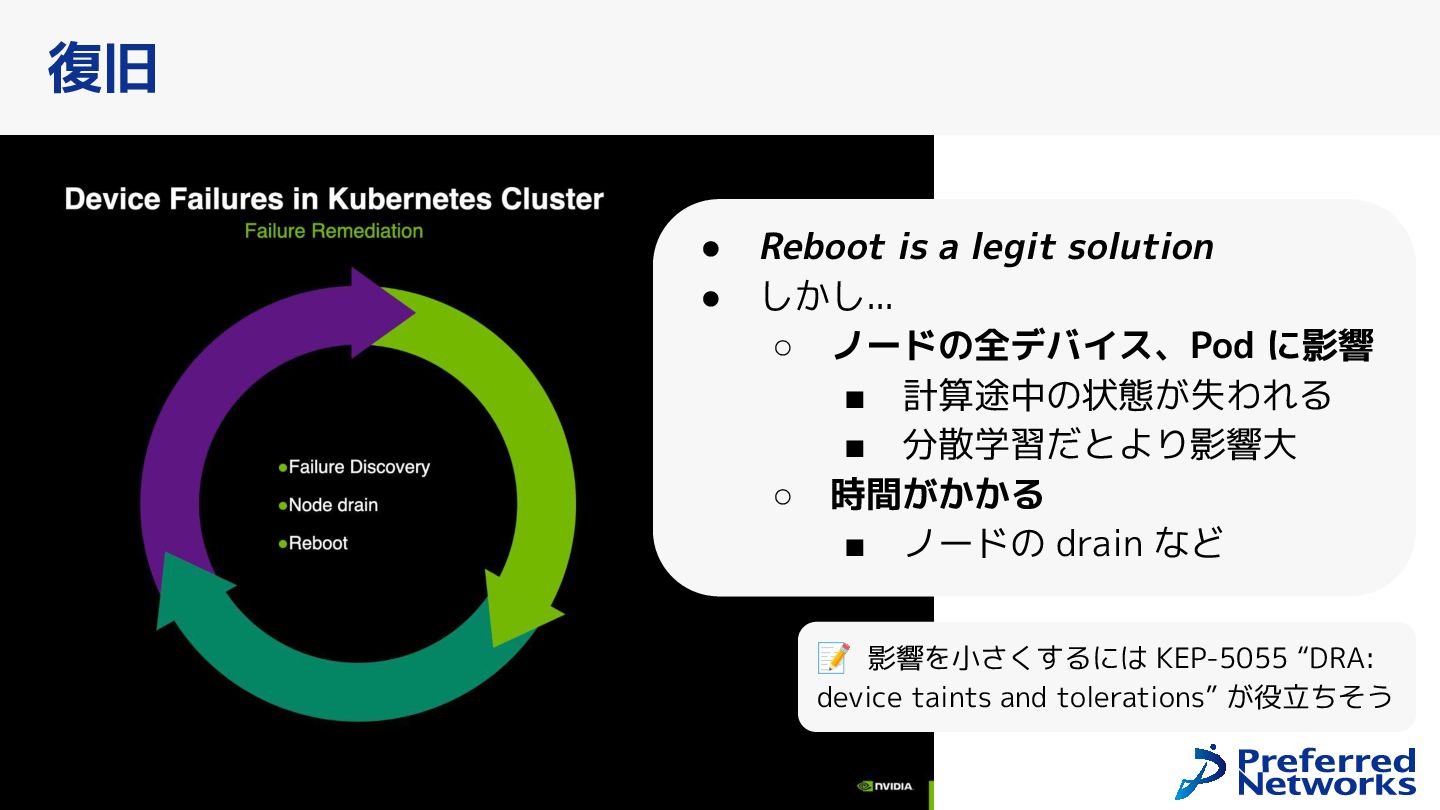
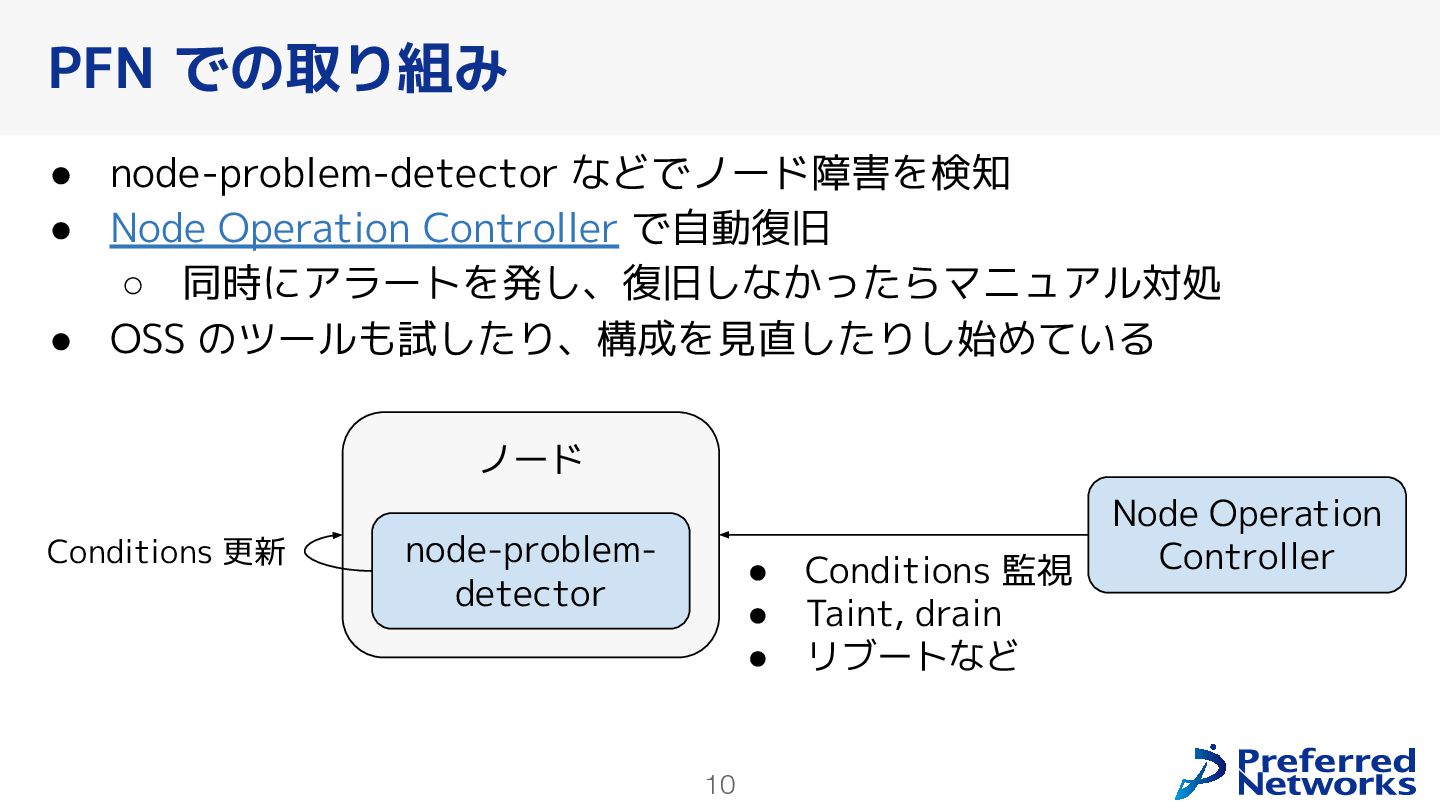
reboot the node? ◦ KEP-5055 “DRA: device taints and tolerations” が役立つ場面 ◦ 2 つ壊れたら? 3 つは? • If there is a problematic GPU that is restarted every few days, should the scheduler try to avoid this node? ◦ あやしいデバイスにどう対処するか ◦ 📝 監視で見つけて返品保証を依頼するのがいい。見つけられるよう にするのが大事 さらなる改善へ
AI and GPUs: Challenges and Opportunities - Claudia Misale & David Grove, IBM ◦ https://sched.co/1u5fr • OSS ◦ https://github.com/medik8s ◦ https://github.com/kubereboot/kured ◦ https://github.com/planetlabs/draino ◦ https://github.com/cloudflare/sciuro ◦ https://github.com/NVIDIA/pika ◦ ... みんな似たような課題をもっている
• KubeCon Japan で発表します ◦ New Cache Hierarchy for Container Images and OCI Artifact in Kubernetes Clusters Using Containerd - Toru Komatsu & Hidehito Yabuuchi, Preferred Networks, Inc. ◦ BGP Peering Patterns for Kubernetes Networking at Preferred Networks - Sho Shimizu, Preferred Networks, Inc. & Yutaro Hayakawa, Isovalent at Cisco お知らせ カジュアル面談もお気軽に!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}