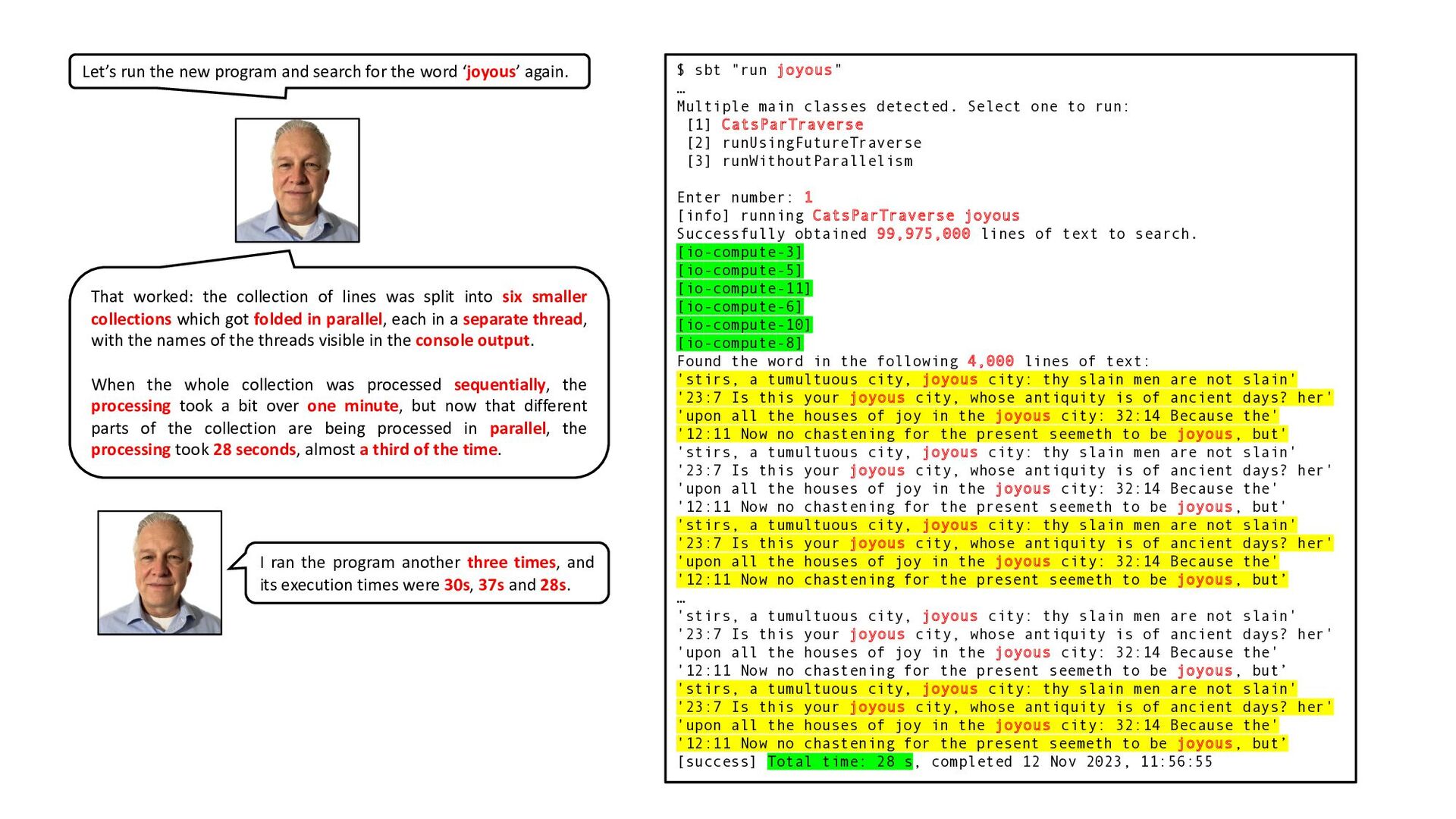
obtained 99,975,000 lines of text to search. Found the word in the following 4,000 lines of text: 'stirs, a tumultuous city, joyous city: thy slain men are not slain' '23:7 Is this your joyous city, whose antiquity is of ancient days? her' 'upon all the houses of joy in the joyous city: 32:14 Because the' '12:11 Now no chastening for the present seemeth to be joyous, but' 'stirs, a tumultuous city, joyous city: thy slain men are not slain' '23:7 Is this your joyous city, whose antiquity is of ancient days? her' 'upon all the houses of joy in the joyous city: 32:14 Because the' '12:11 Now no chastening for the present seemeth to be joyous, but' 'stirs, a tumultuous city, joyous city: thy slain men are not slain' '23:7 Is this your joyous city, whose antiquity is of ancient days? her' 'upon all the houses of joy in the joyous city: 32:14 Because the' '12:11 Now no chastening for the present seemeth to be joyous, but’ … 'stirs, a tumultuous city, joyous city: thy slain men are not slain' '23:7 Is this your joyous city, whose antiquity is of ancient days? her' 'upon all the houses of joy in the joyous city: 32:14 Because the' '12:11 Now no chastening for the present seemeth to be joyous, but’ 'stirs, a tumultuous city, joyous city: thy slain men are not slain' '23:7 Is this your joyous city, whose antiquity is of ancient days? her' 'upon all the houses of joy in the joyous city: 32:14 Because the' '12:11 Now no chastening for the present seemeth to be joyous, but' [success] Total time: 66 s (01:06), completed 5 Nov 2023, 11:11:14 Searching through a thousand copies of the book takes a little bit over one minute. When we searched one copy of the book, we found four matching lines, so it makes sense that now that we are searching a thousand copies, we are finding 4,000 matching lines. I ran the program four times, and its execution times were 66s, 65s, 65s and 66s. By the way, when I first tried to run the program, I got some warnings suggesting that I increase the heap space, so I added the following to file .sbtopts: -J-Xmx5G
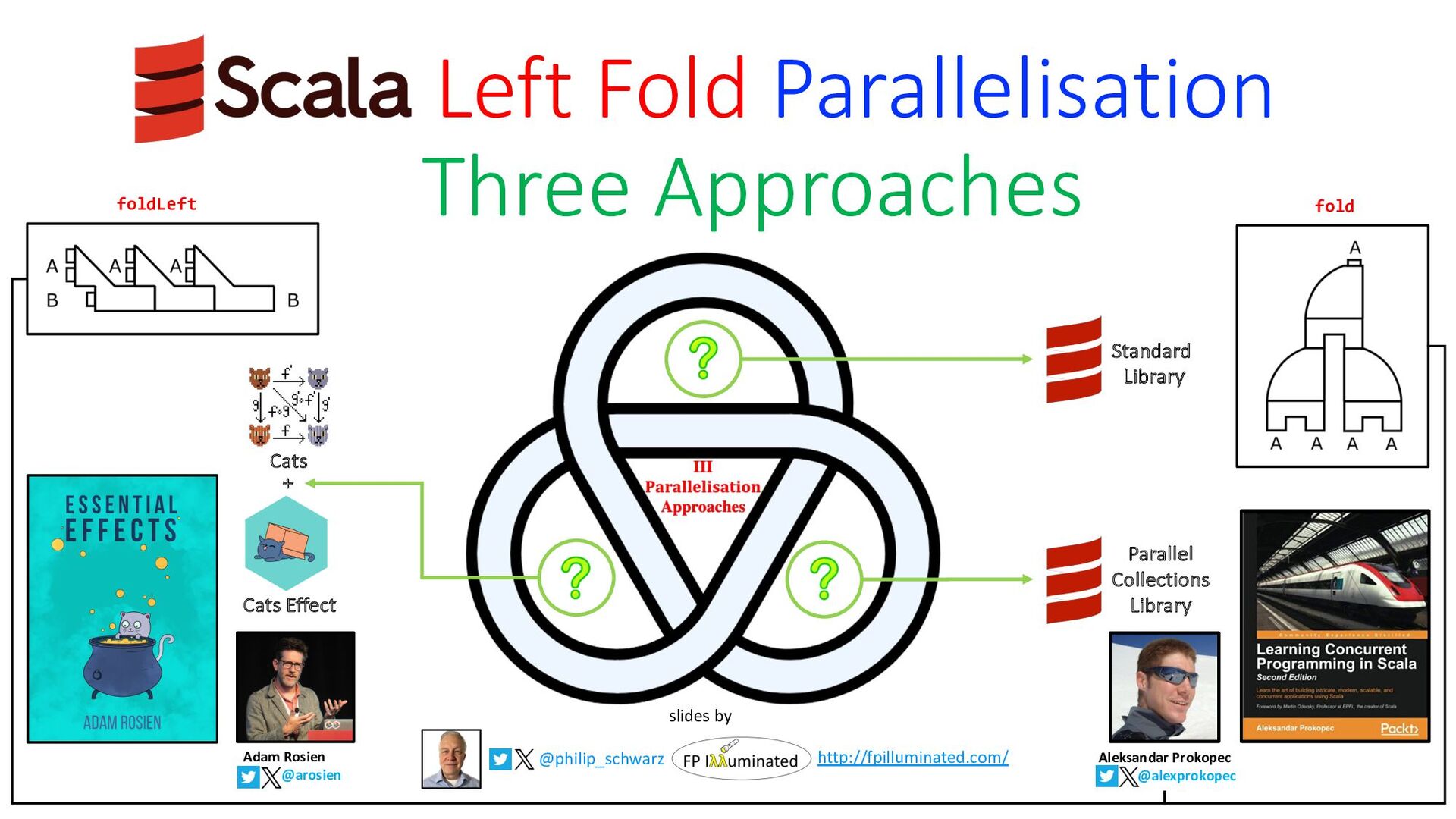{kind=link}
{kind=link}
{kind=link}
: A = throw IllegalStateException(s"Failed to obtain the](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_3.jpg){kind=link}
![$ sbt "run joyous" … [info] running run joyous Successfully](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_4.jpg){kind=link}
{kind=link}
![$ sbt "run joyous" … [info] running run joyous Successfully](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_6.jpg){kind=link}
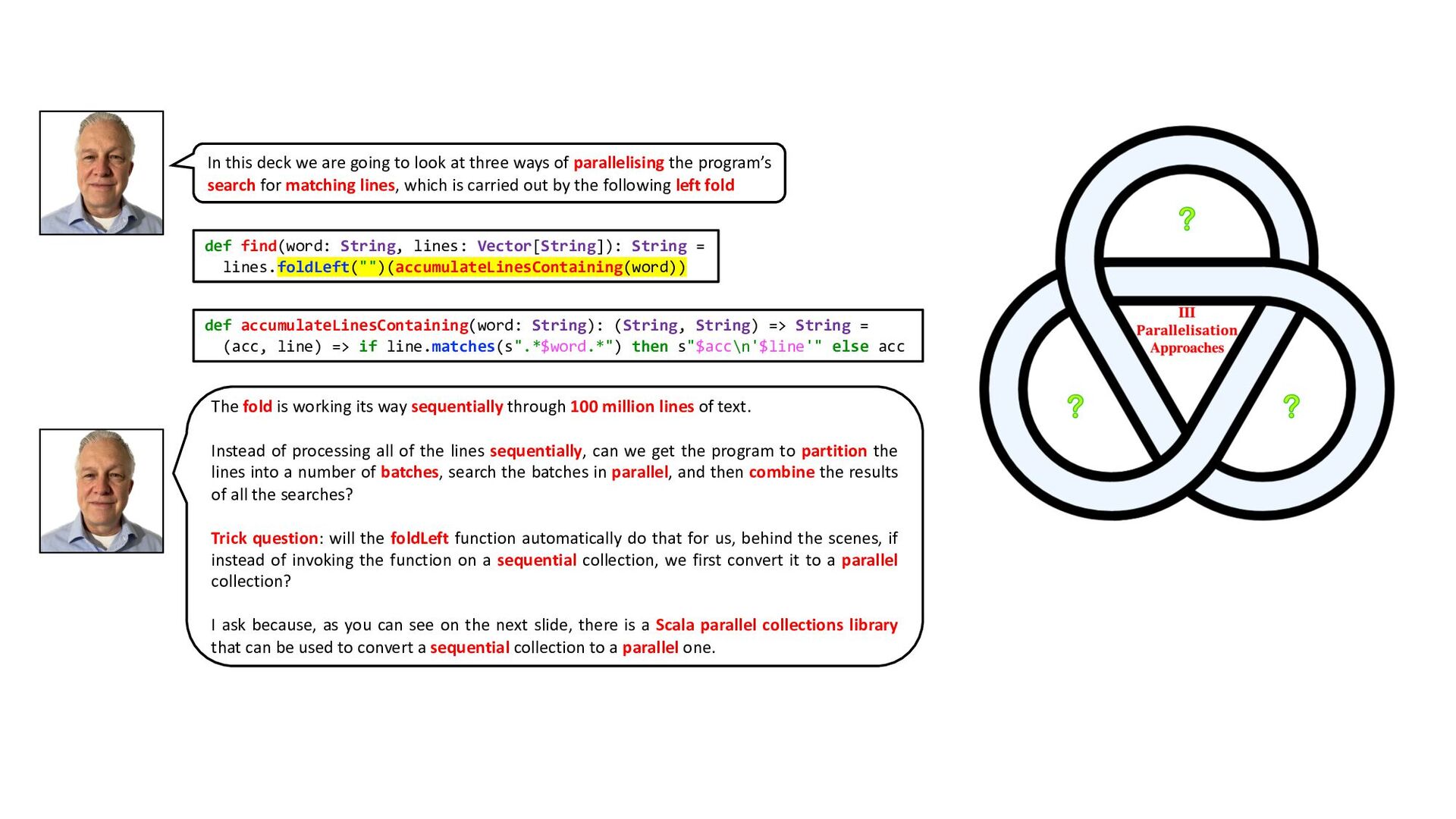{kind=link}
{kind=link}
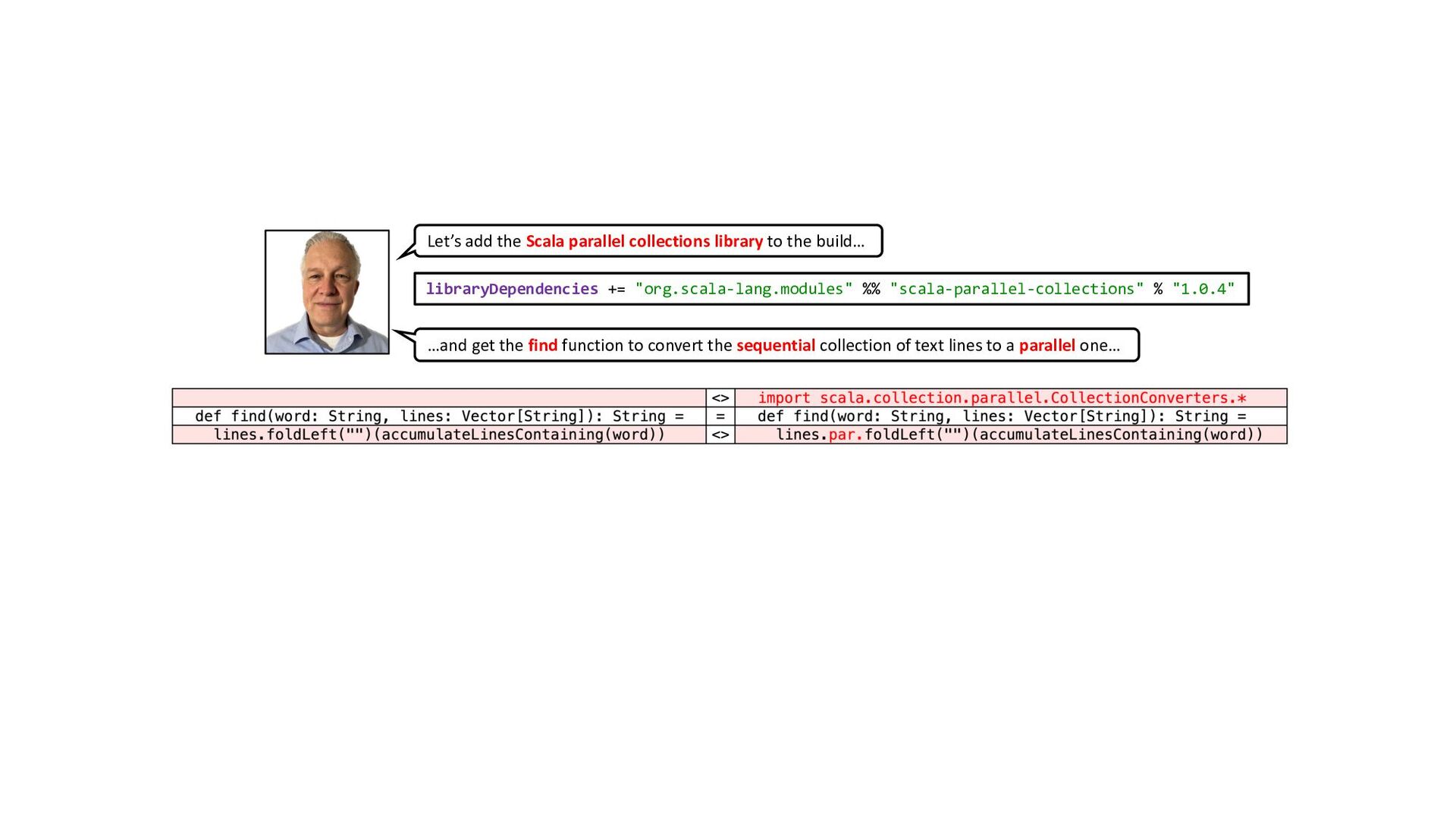{kind=link}
![$ sbt "run joyous" … [info] running run joyous Successfully](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def find(word: String, lines: Vector[String]): String = val batchSize =](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
: A = throw IllegalStateException(s"Failed to obtain the](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def searchFor(word: String)(lines: Vector[String]): IO[String] = IO(lines.foldLeft("")(accumulateLinesContaining(word))) def find(word: String,](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_28.jpg){kind=link}
{kind=link}
![import cats.syntax.functor.* extension [A, F[_]: Functor](fa: F[A]) def printThreadName(): F[A]](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
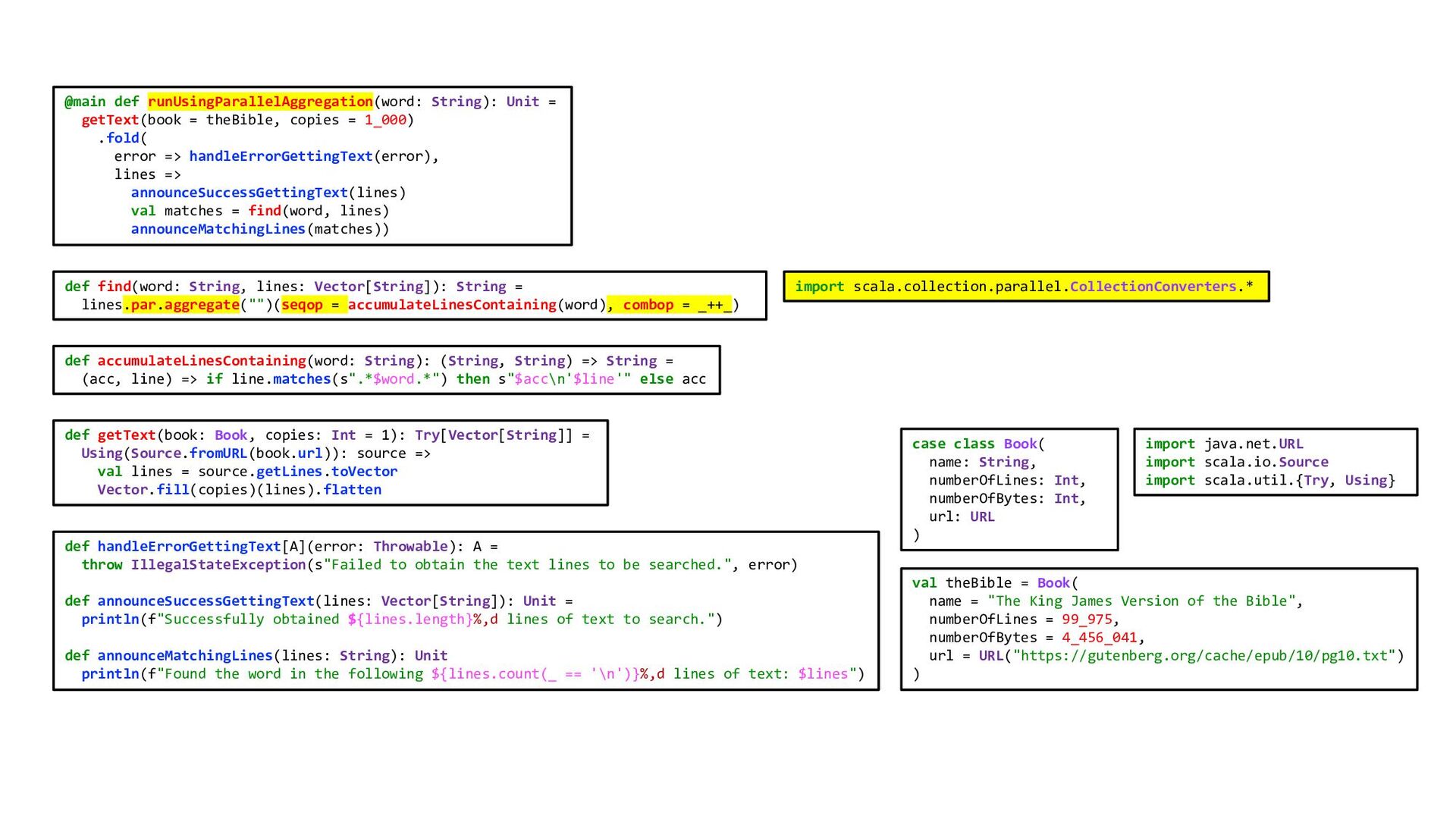
![import scala.collection.parallel.CollectionConverters.* def find(word: String, lines: Vector[String]): String = lines.par.aggregate("")(seqop](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_40.jpg){kind=link}
![import scala.collection.parallel.CollectionConverters.* def find(word: String, lines: Vector[String]): String = lines.par.aggregate("")(seqop](https://files.speakerdeck.com/presentations/2acc51917dbf485793c509731d5e8d45/slide_41.jpg){kind=link}
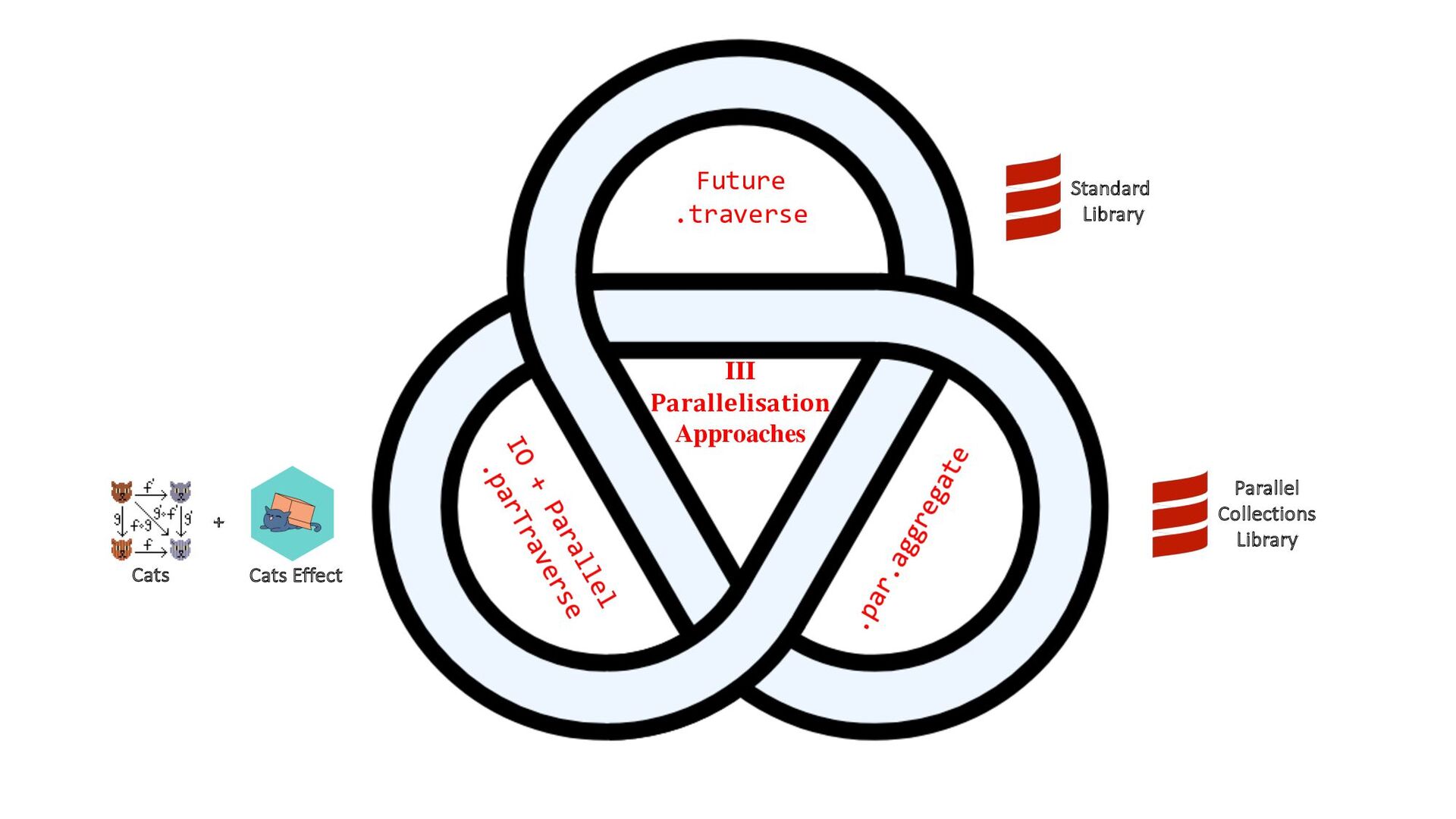{kind=link}
{kind=link}