In this deck series we are going to do the following for each of three combinatorial problems covered in chapter fourteen of a book called Coding Interview Patterns – Nail Your Next Coding Interview :
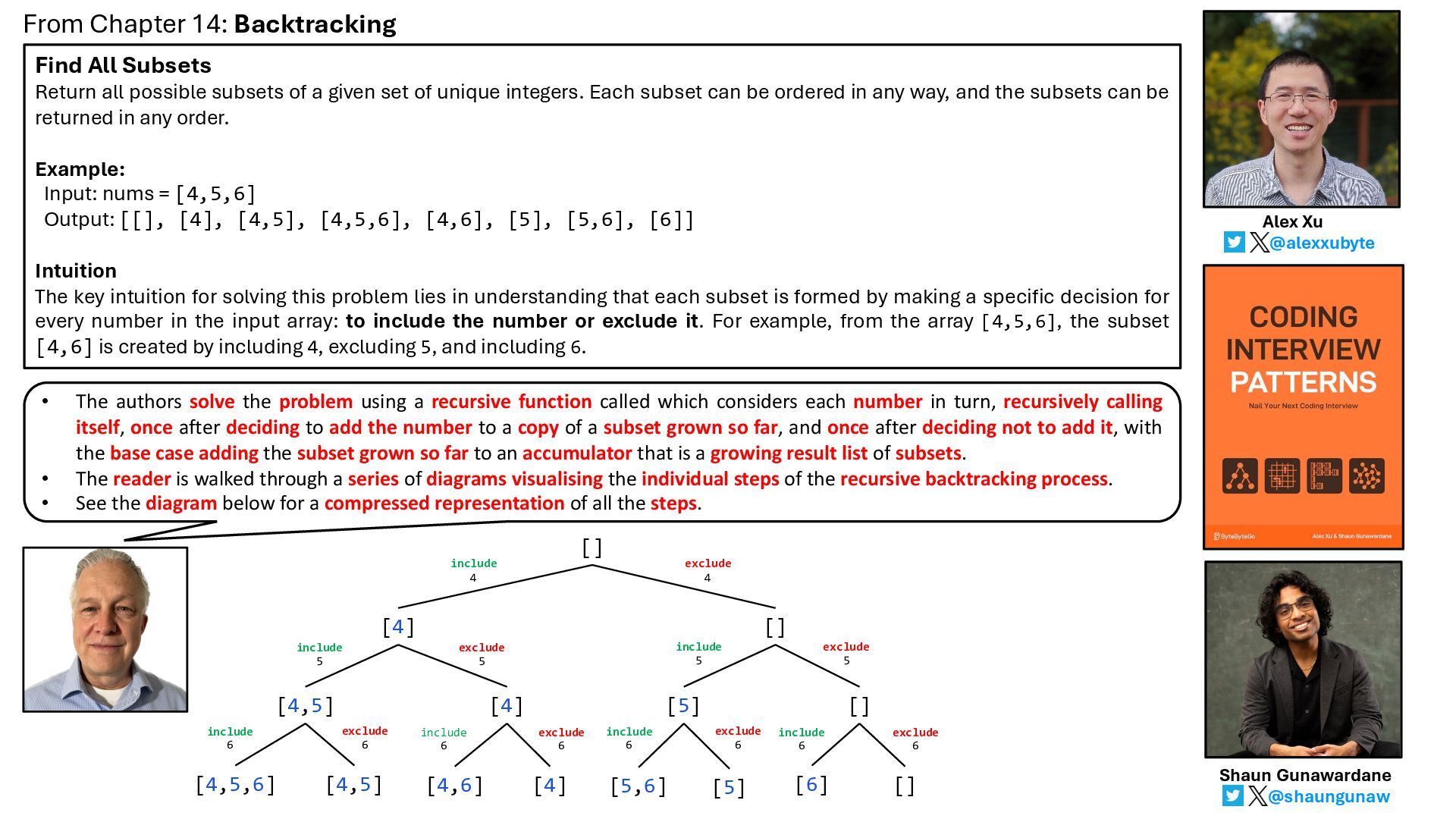
* see how the book describes the problem
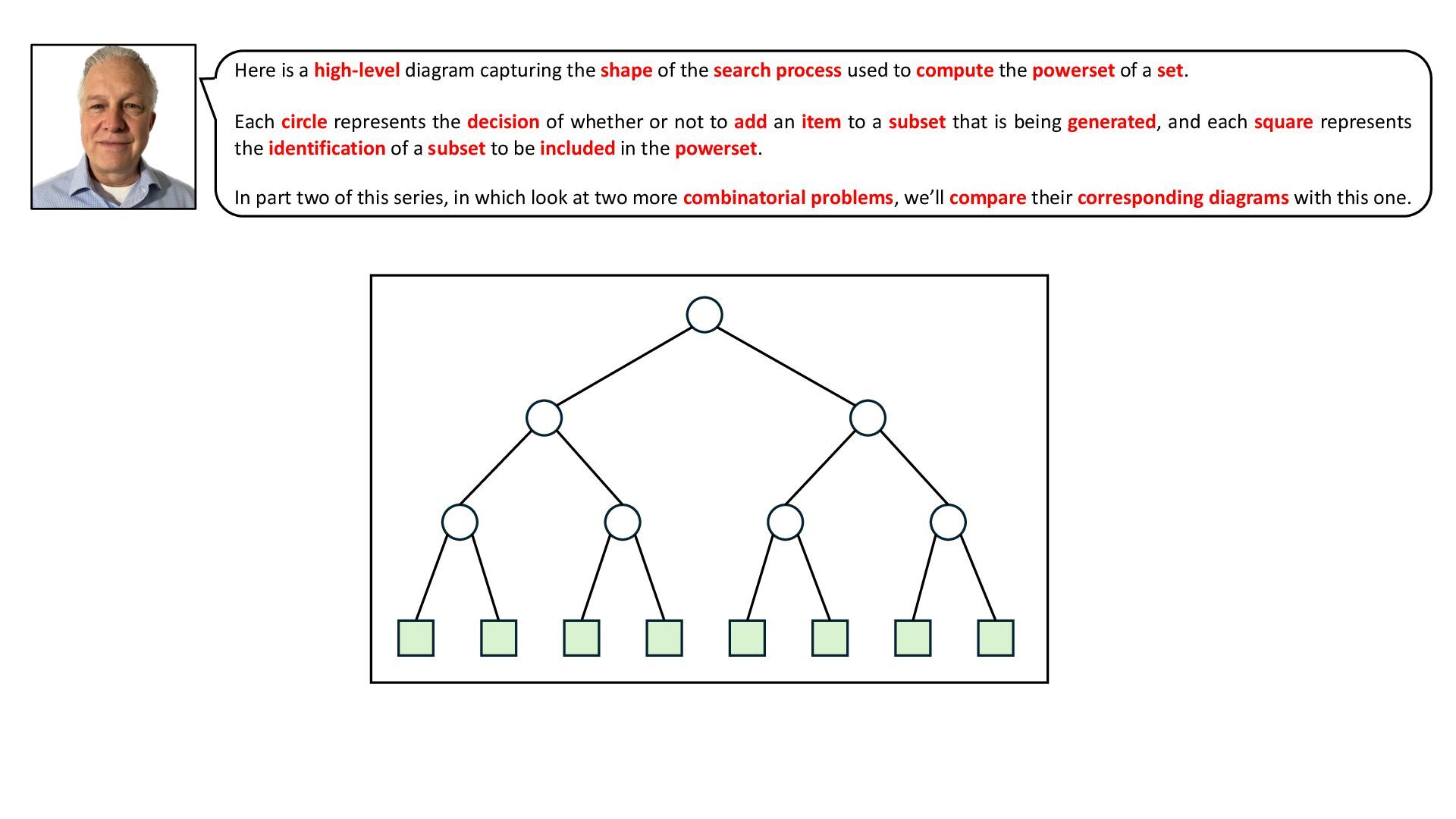
* view the book’s solution to the problem, which exploits backtracking
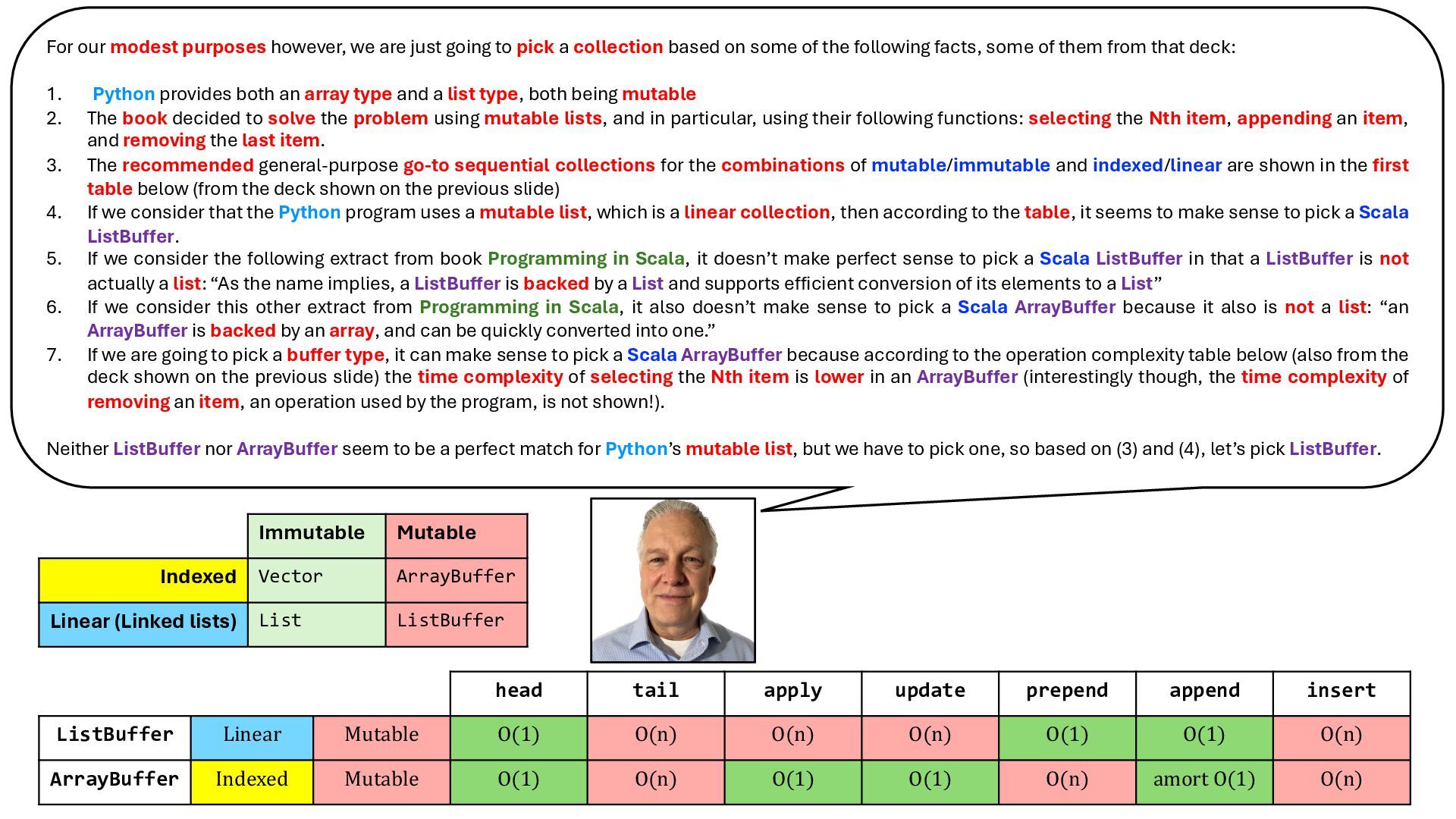
* view the book’s imperative Python code for the solution
* translate the imperative code from Python to Scala
* explore Haskell and Scala functional programming solutions.
Keywords: backtracking, bind, combinatorial_problems, declarative_programming, flatMap, foldM, functional_programming, haskell, imperative_programming, interview_problems, monad, monadic_folding, non-determinism, procedural_programming, python, recursion, scala
{kind=link}
{kind=link}
{kind=link}
![def find_all_subsets(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(0, [],](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def find_all_subsets(nums: List[Int]): List[List[Int]] = val res = List.empty[List[Int]] backtrack(0,](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![type Set a = [a] singleton :: a -> Set](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_21.jpg){kind=link}
![suffixes :: [a] -> Set [a] suffixes [] = singleton](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_22.jpg){kind=link}
![𝑠𝑒𝑔𝑚𝑒𝑛𝑡𝑠 ∷ 𝑎 → 𝑺𝒆𝒕 [𝑎] 𝑠𝑒𝑔𝑚𝑒𝑛𝑡𝑠 = 𝑐𝑜𝑛𝑐𝑎𝑡 ∘](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_23.jpg){kind=link}
![segments :: Eq a => [a] -> Set [a] segments](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_24.jpg){kind=link}
{kind=link}
![𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠 ∷ 𝑎 → 𝑺𝒆𝒕 [𝑎] 𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠 = 𝑟𝑒𝑡𝑢𝑟𝑛 𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_26.jpg){kind=link}
![𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠 ∷ 𝑎 → 𝑺𝒆𝒕 [𝑎] 𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠 = 𝑟𝑒𝑡𝑢𝑟𝑛 𝑝𝑟𝑒𝑓𝑖𝑥𝑒𝑠](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
: List[List[A]] = as match case Nil =>](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_31.jpg){kind=link}
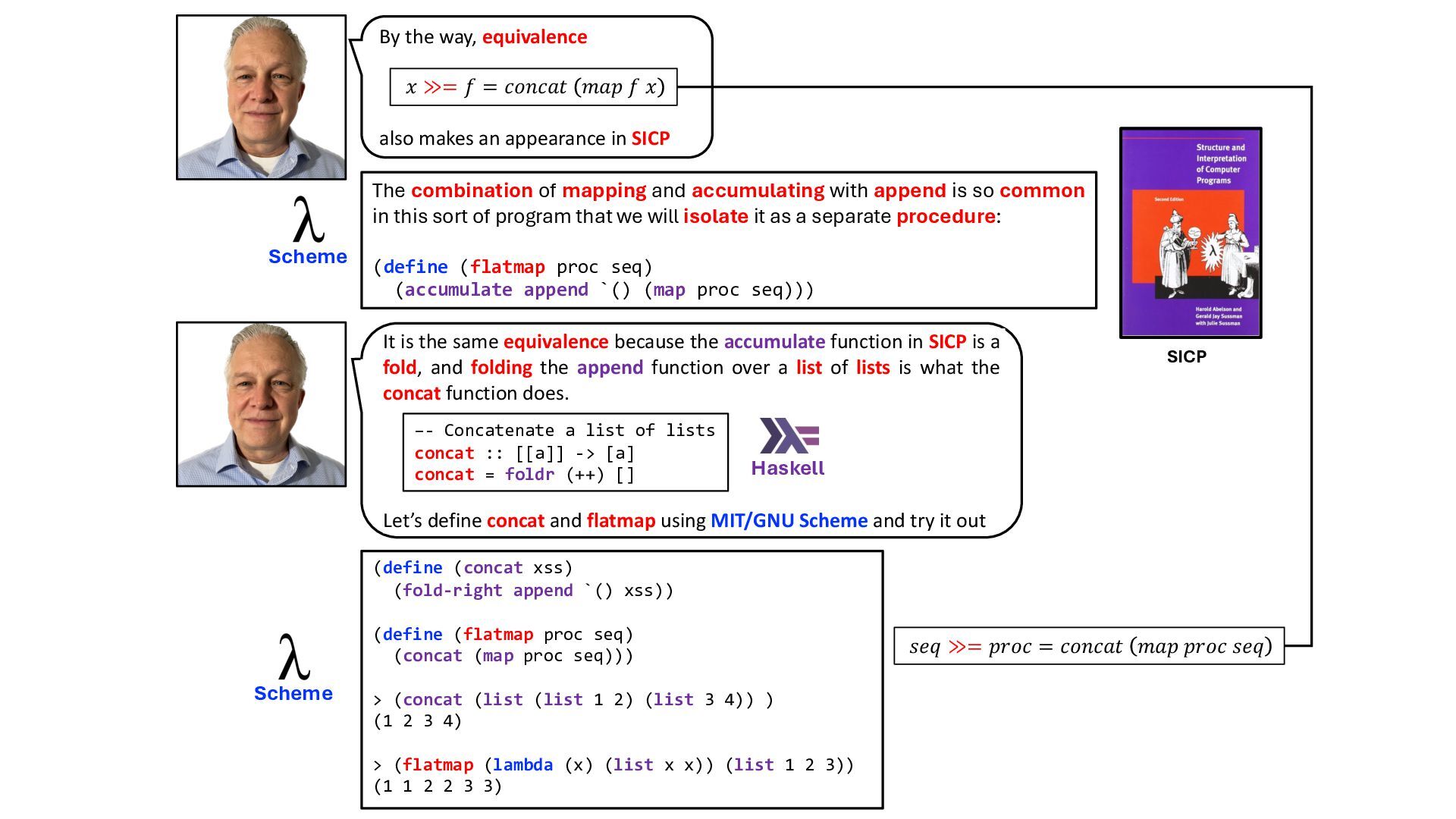{kind=link}
{kind=link}
![-- powerset of [] powerset0 = do let ss0 =](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_34.jpg){kind=link}
![-- powerset of [] powerset0 = do let ss0 =](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_35.jpg){kind=link}
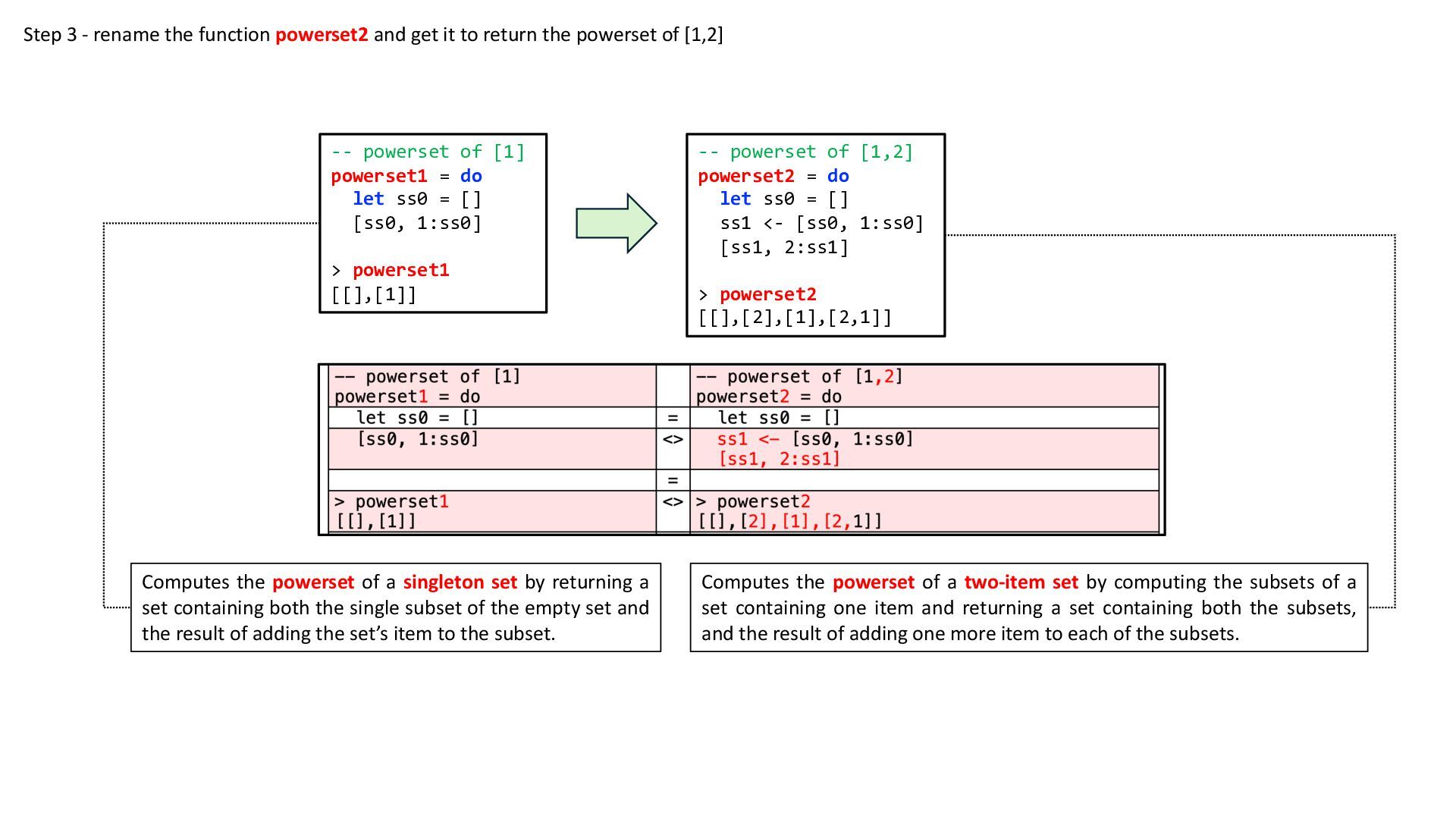{kind=link}
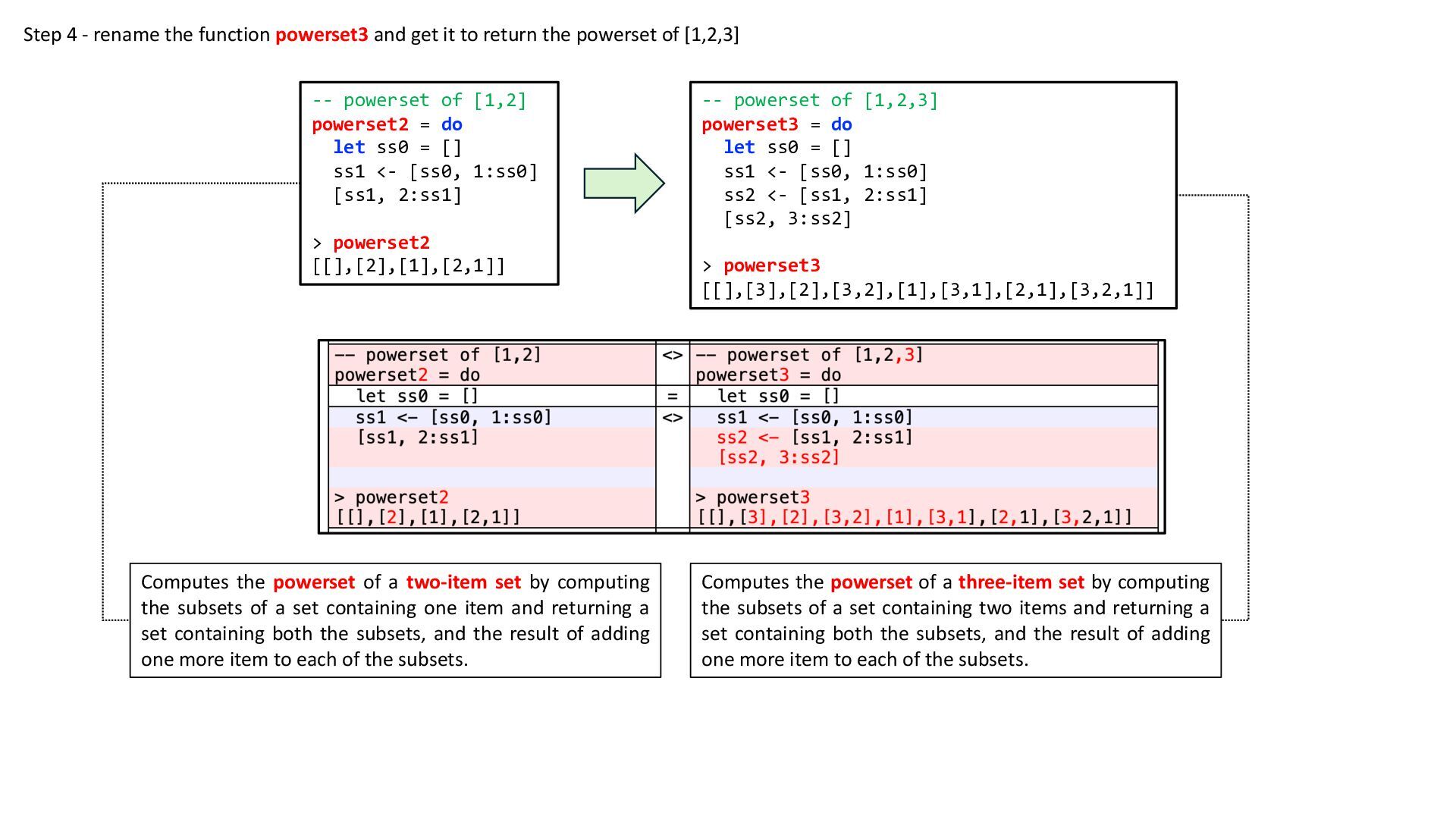{kind=link}
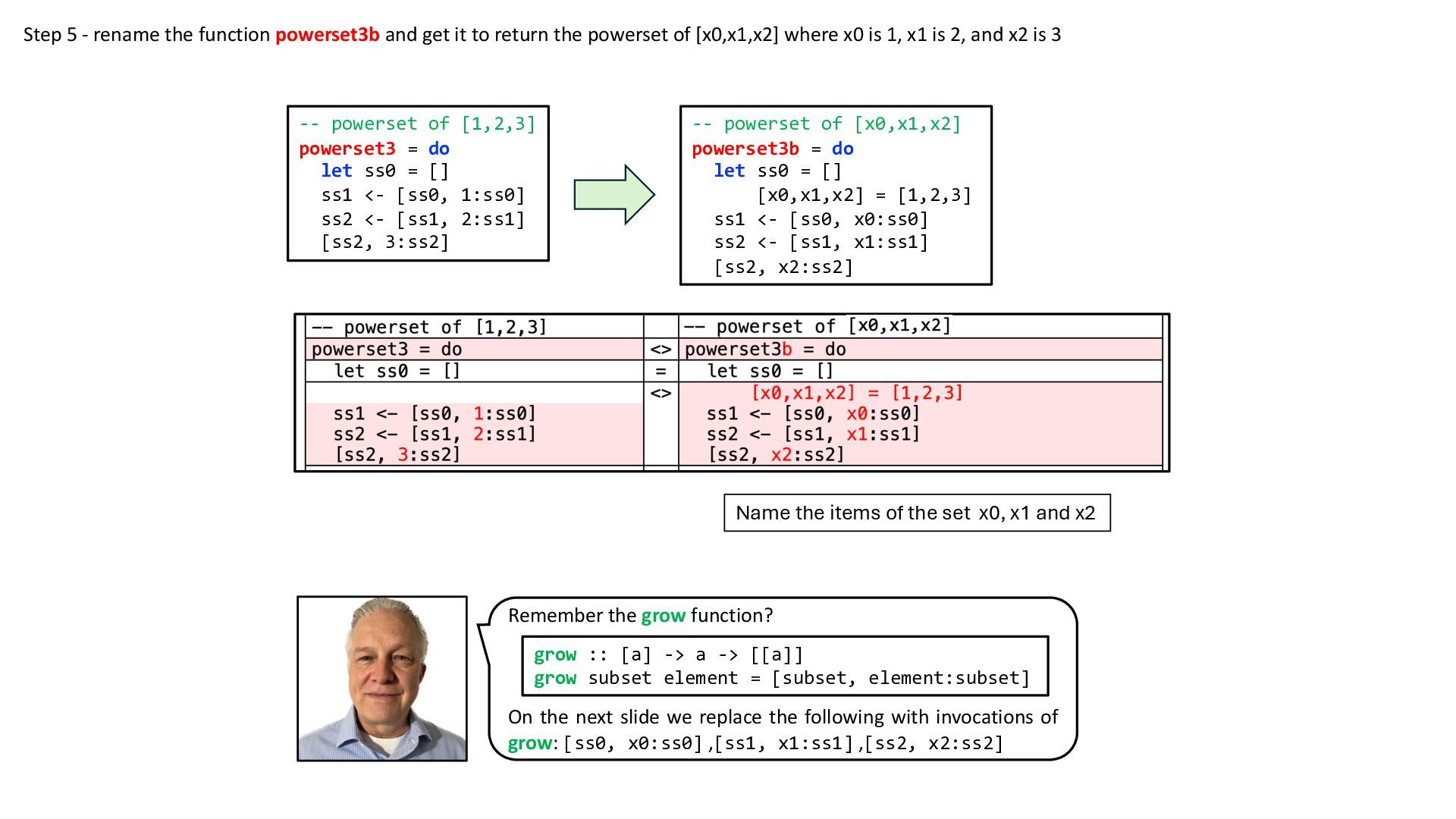{kind=link}
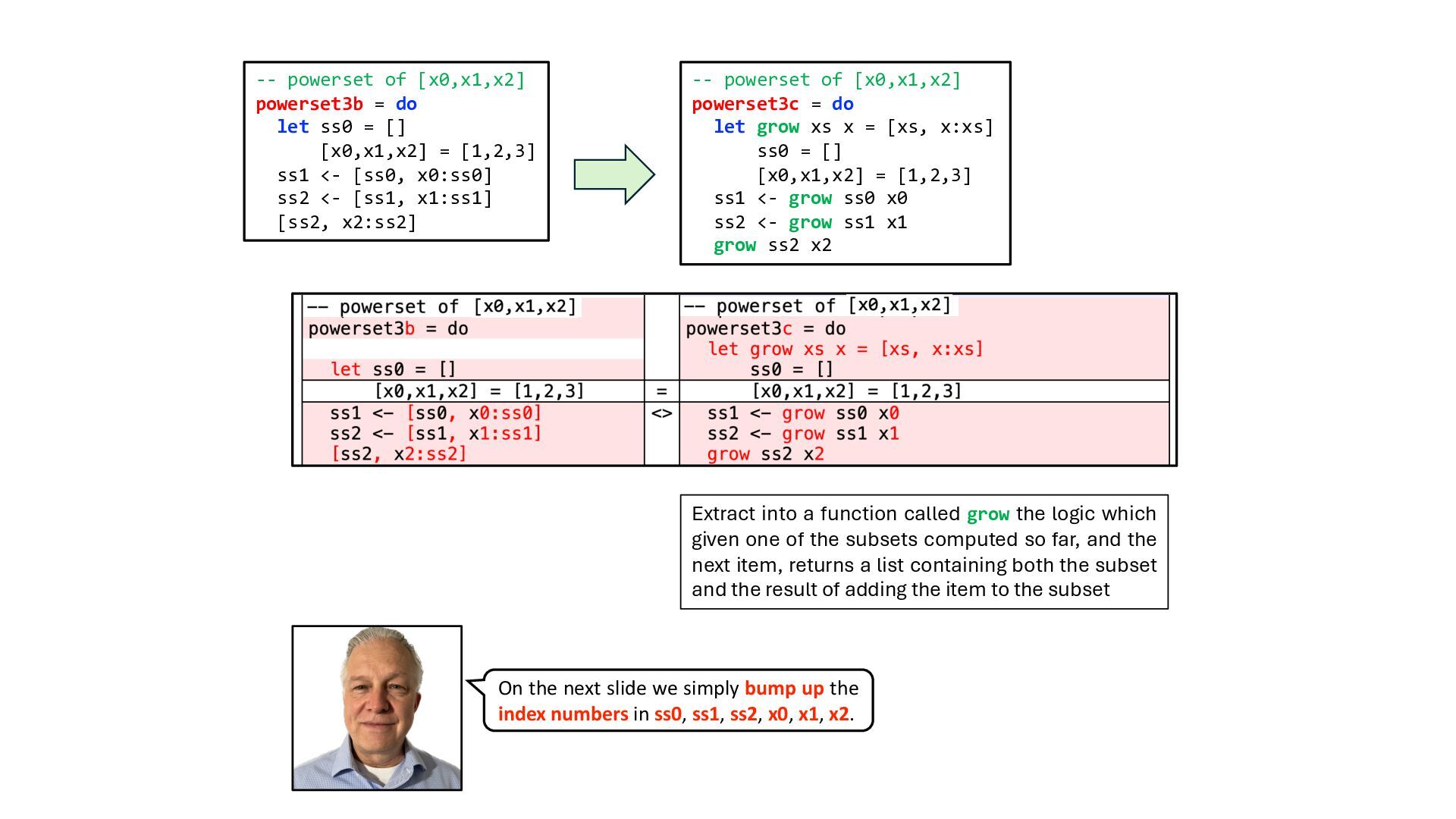{kind=link}
![-- powerset of [x0,x1,x2] powerset3c = do let grow xs](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_40.jpg){kind=link}
![-- powerset of [x1,x2,x3] powerset3d = do let grow xs](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_41.jpg){kind=link}
{kind=link}
![-- powerset of [x1,x2,…,xm] powersetm = do let f xs](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_43.jpg){kind=link}
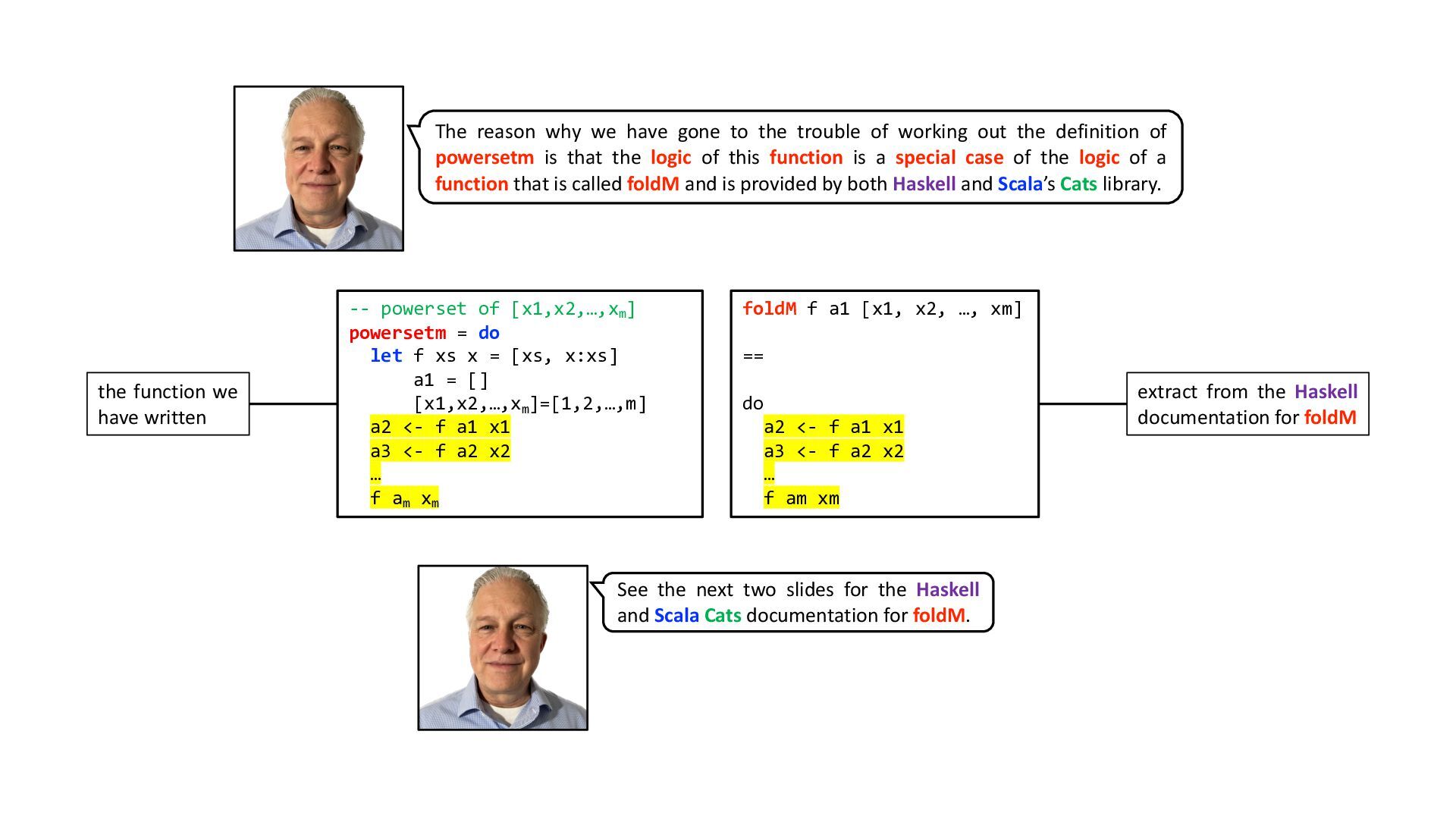{kind=link}
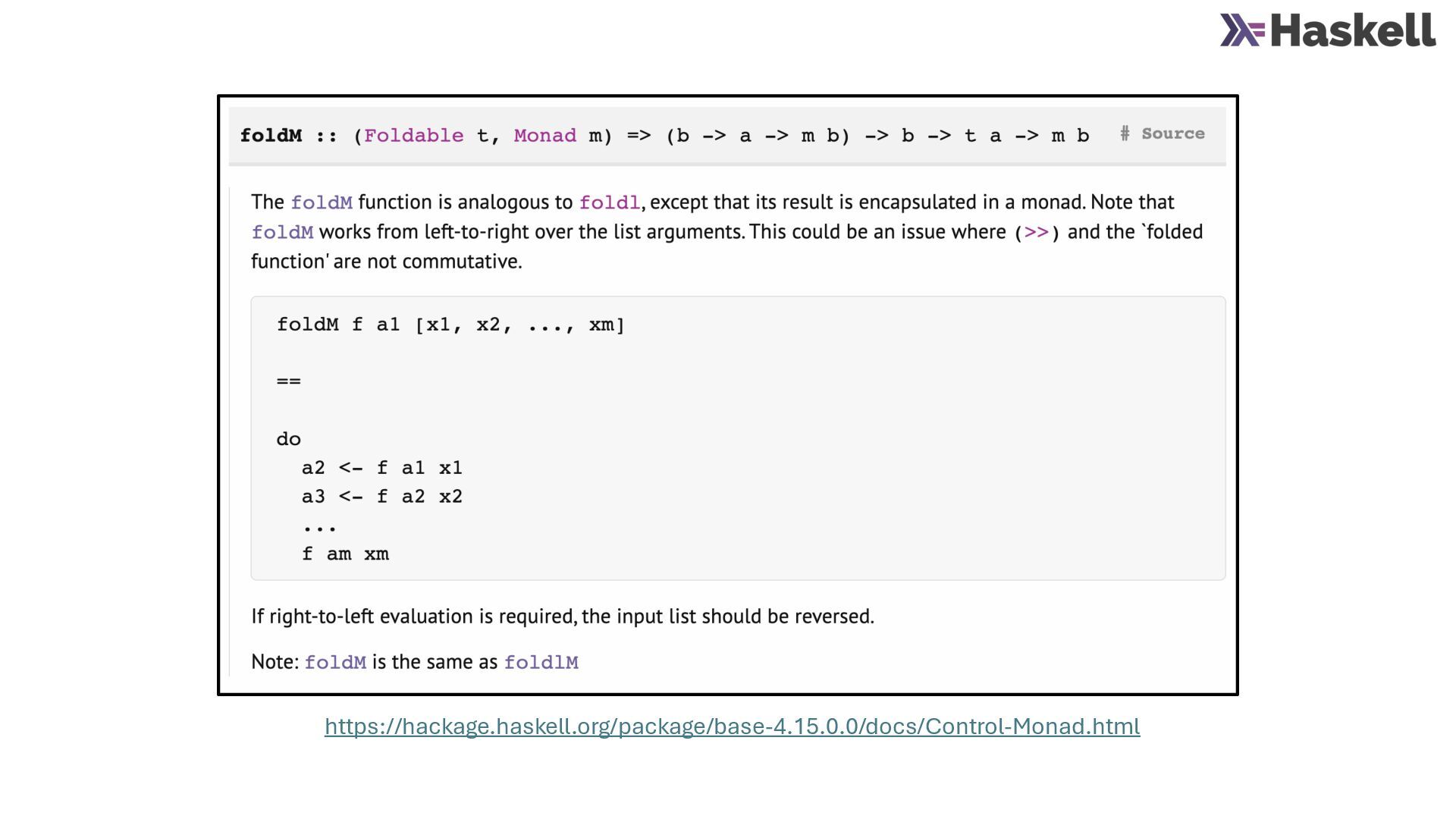{kind=link}
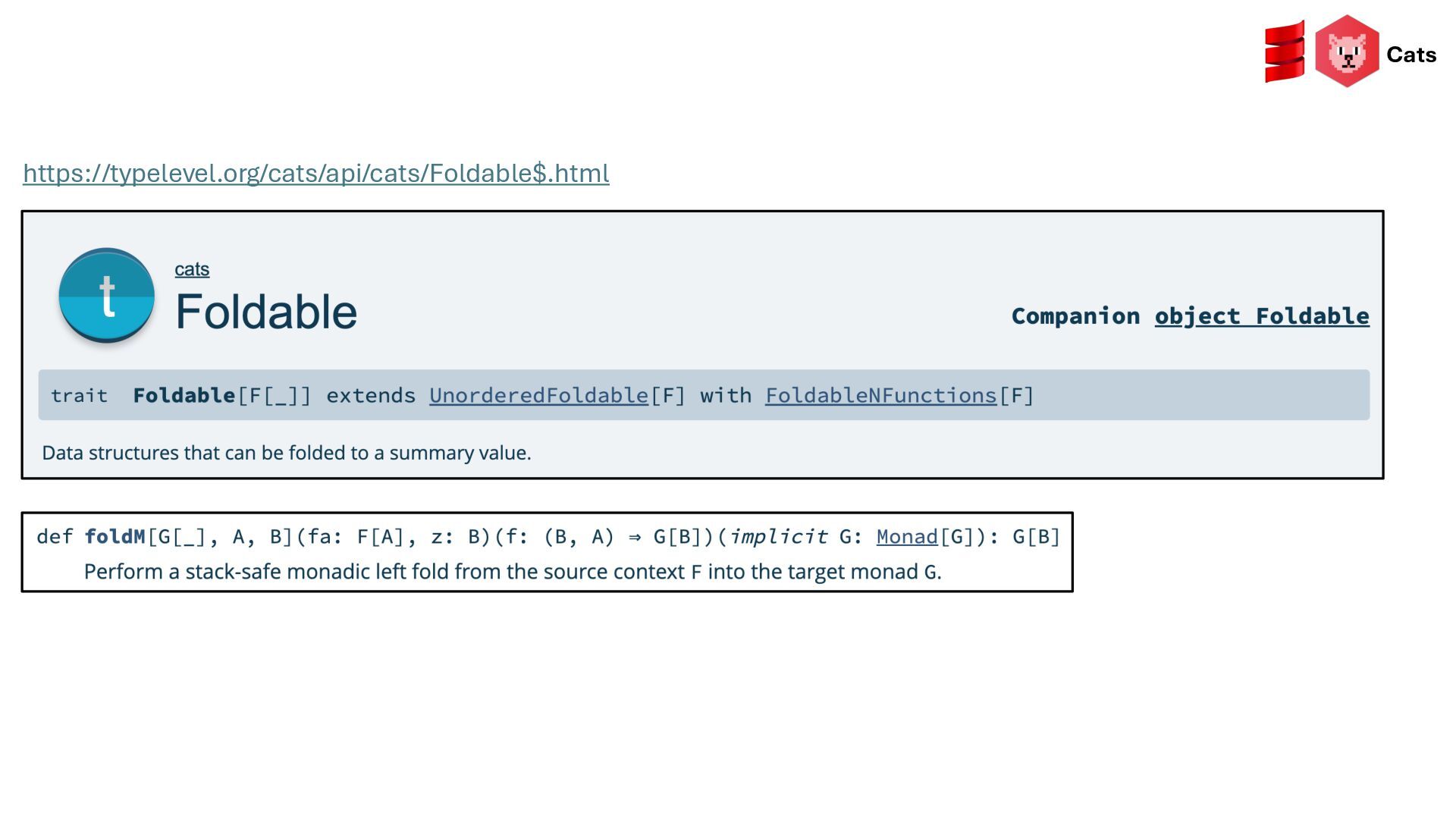{kind=link}
![powersetm = do let f xs x = [xs, x:xs]](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_47.jpg){kind=link}
: List[List[A]] = as.foldM(Nil)(grow) def grow[A](as:](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_48.jpg){kind=link}
![> powerset [] [[]] > powerset [4] [[],[4]] > powerset](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_49.jpg){kind=link}
![> powerset(Nil) val res0: List[List[Nothing]] = List(List()) > powerset(List(4)) val](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_50.jpg){kind=link}
{kind=link}
![def find_all_subsets(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(0, [],](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_52.jpg){kind=link}
![def find_all_subsets(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(0, [],](https://files.speakerdeck.com/presentations/ebbffc70a20043b09824f73f94e47a13/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}