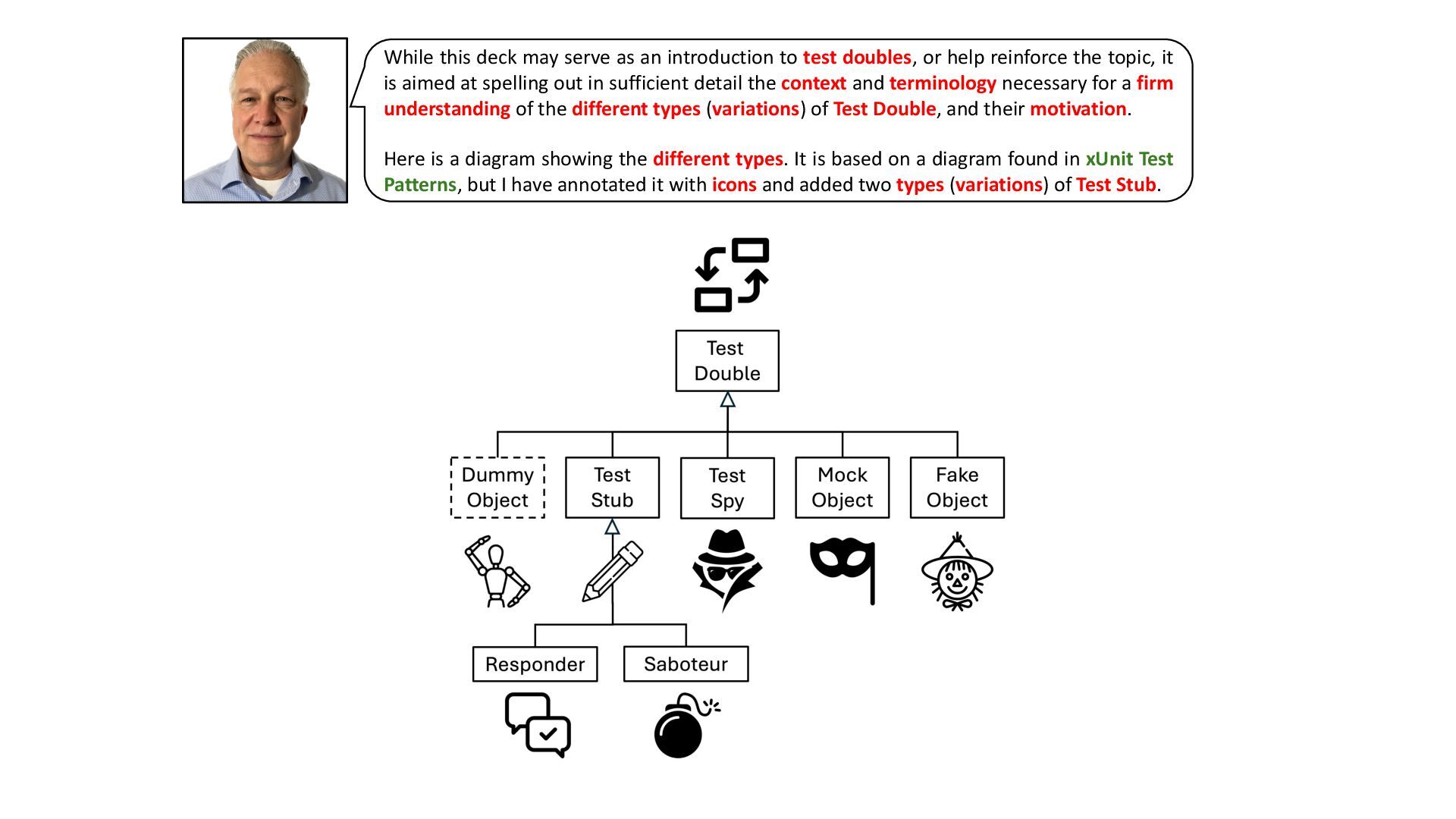
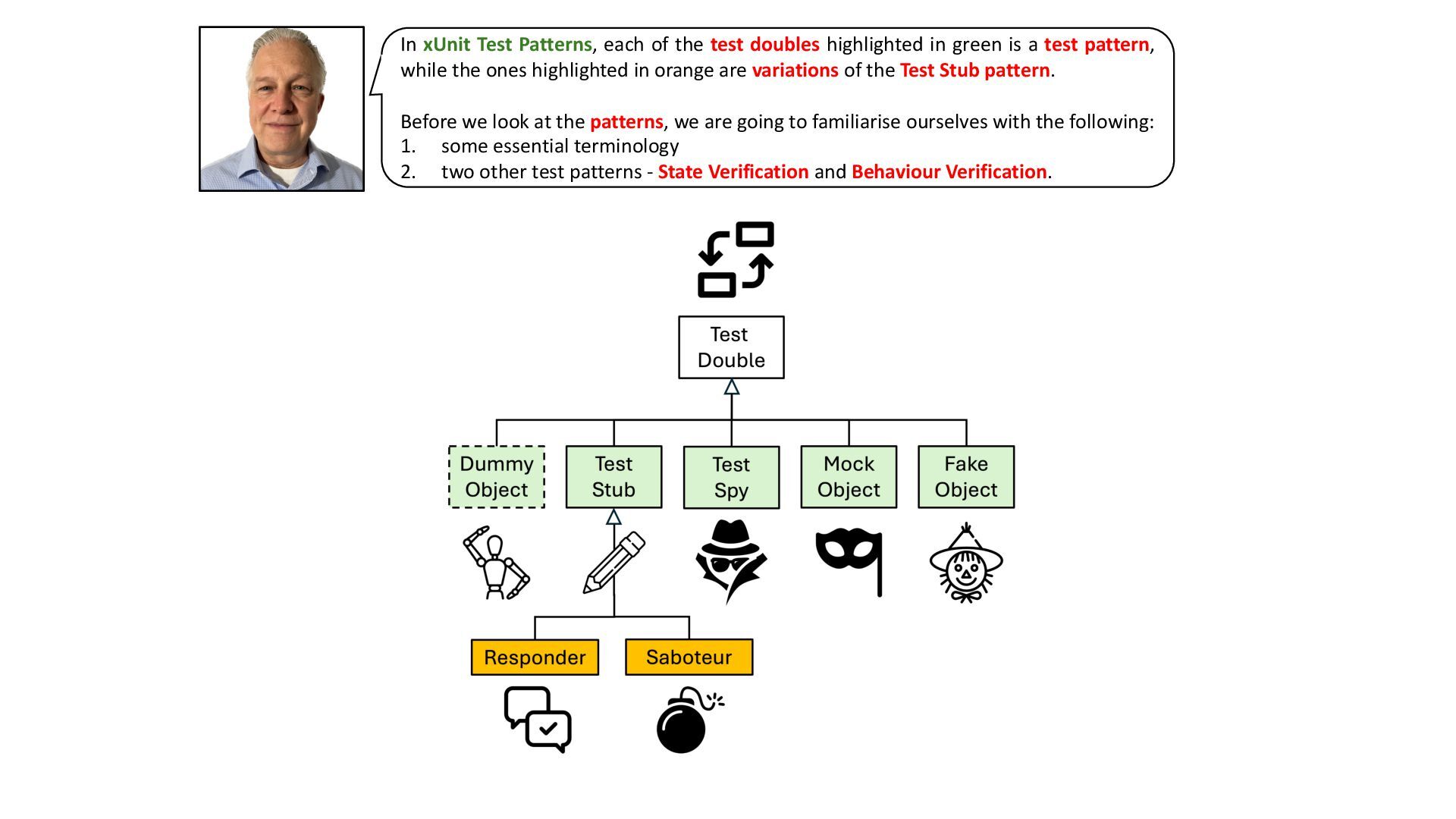
This deck is about a subset of the test automation patterns in Gerard Meszaros’ great book, xUnit Test Patterns – Refactoring Test Code.
The subset in question consists of the patterns relating to the concept of Test Doubles.
The deck is inspired by the patterns, and heavily reliant on extracts from the book.
The motivation for the deck is my belief that it is quite beneficial, when using and discussing Test Doubles, to rely on standardised terminology and patterns.
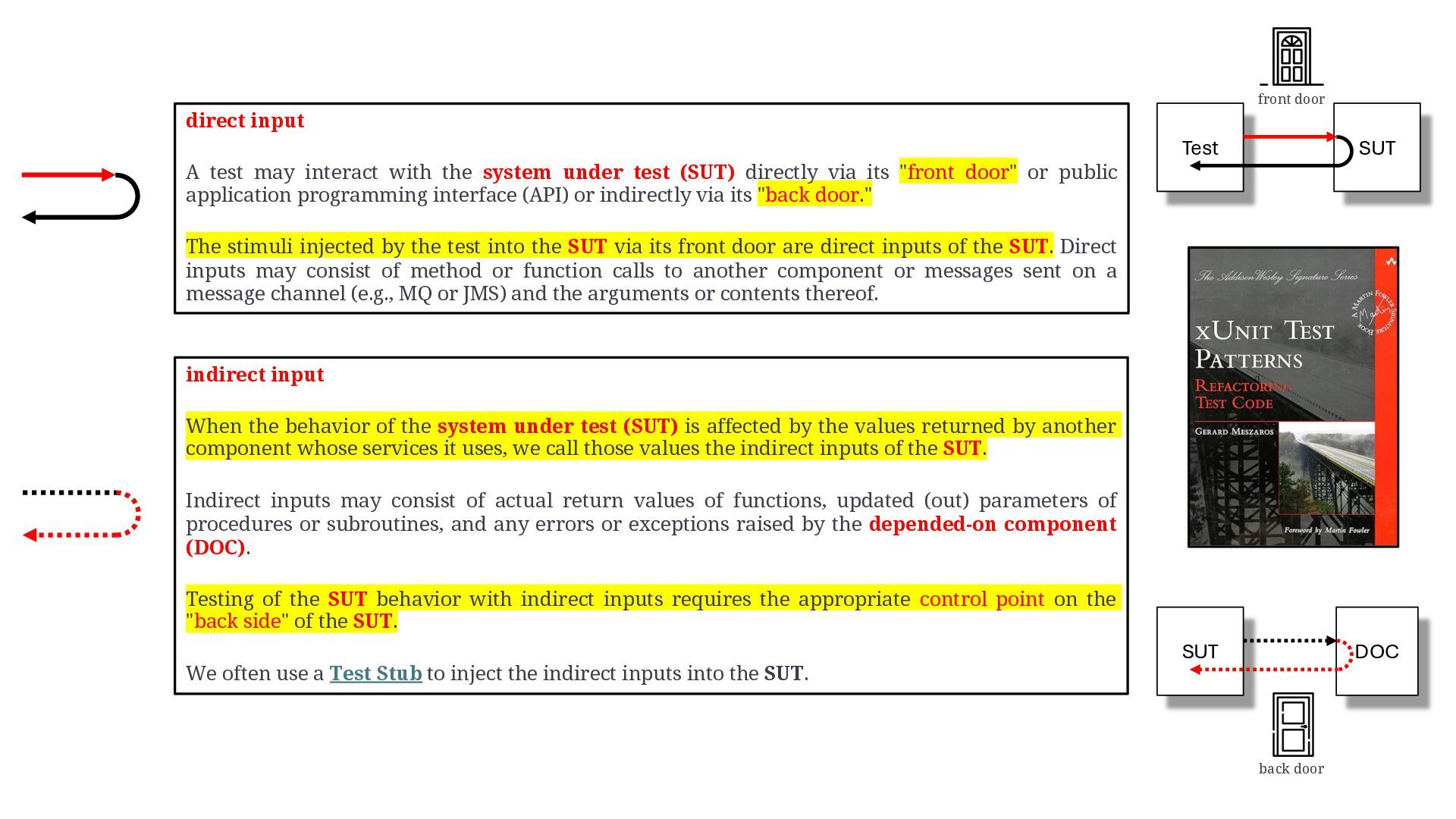
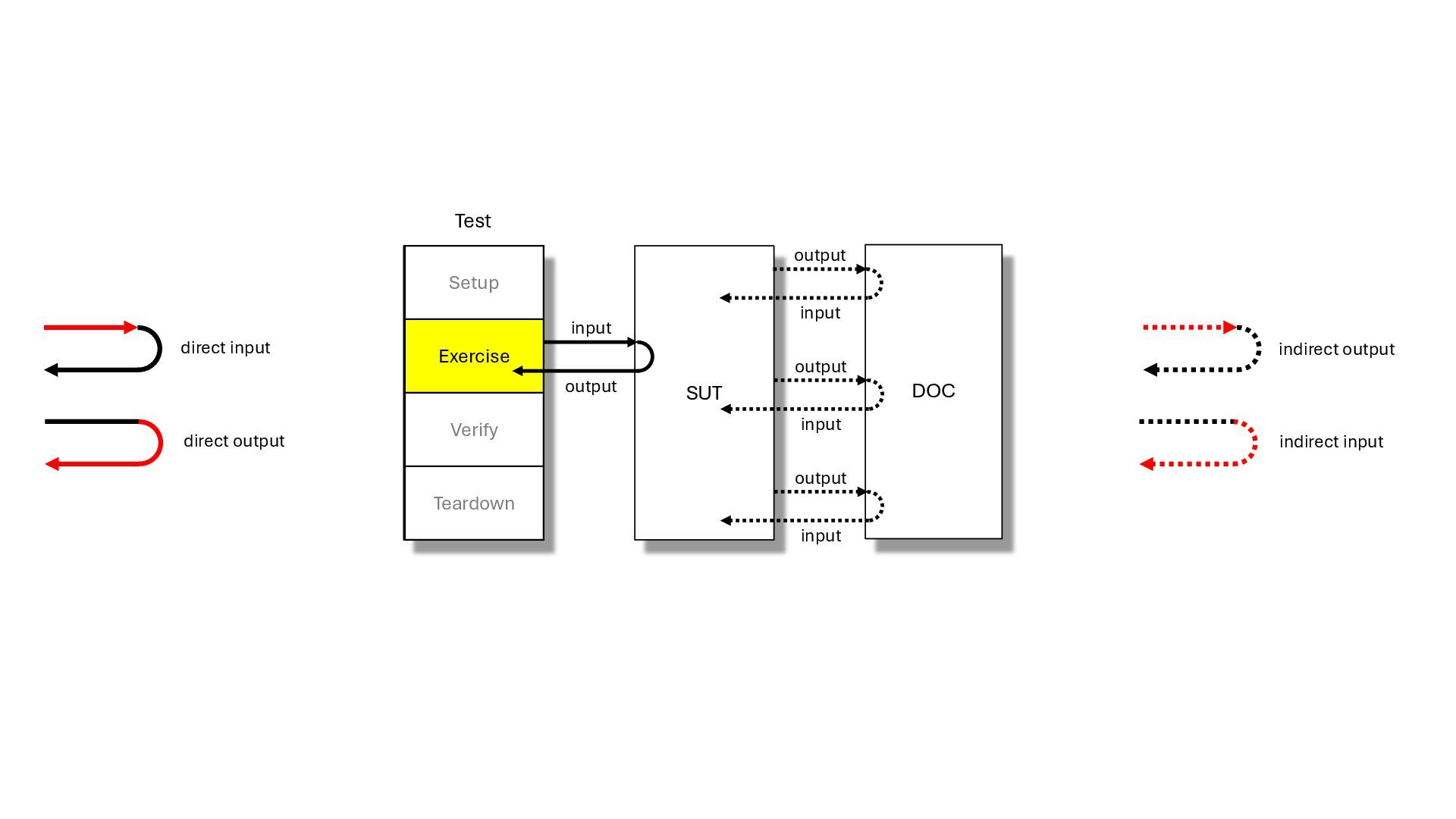
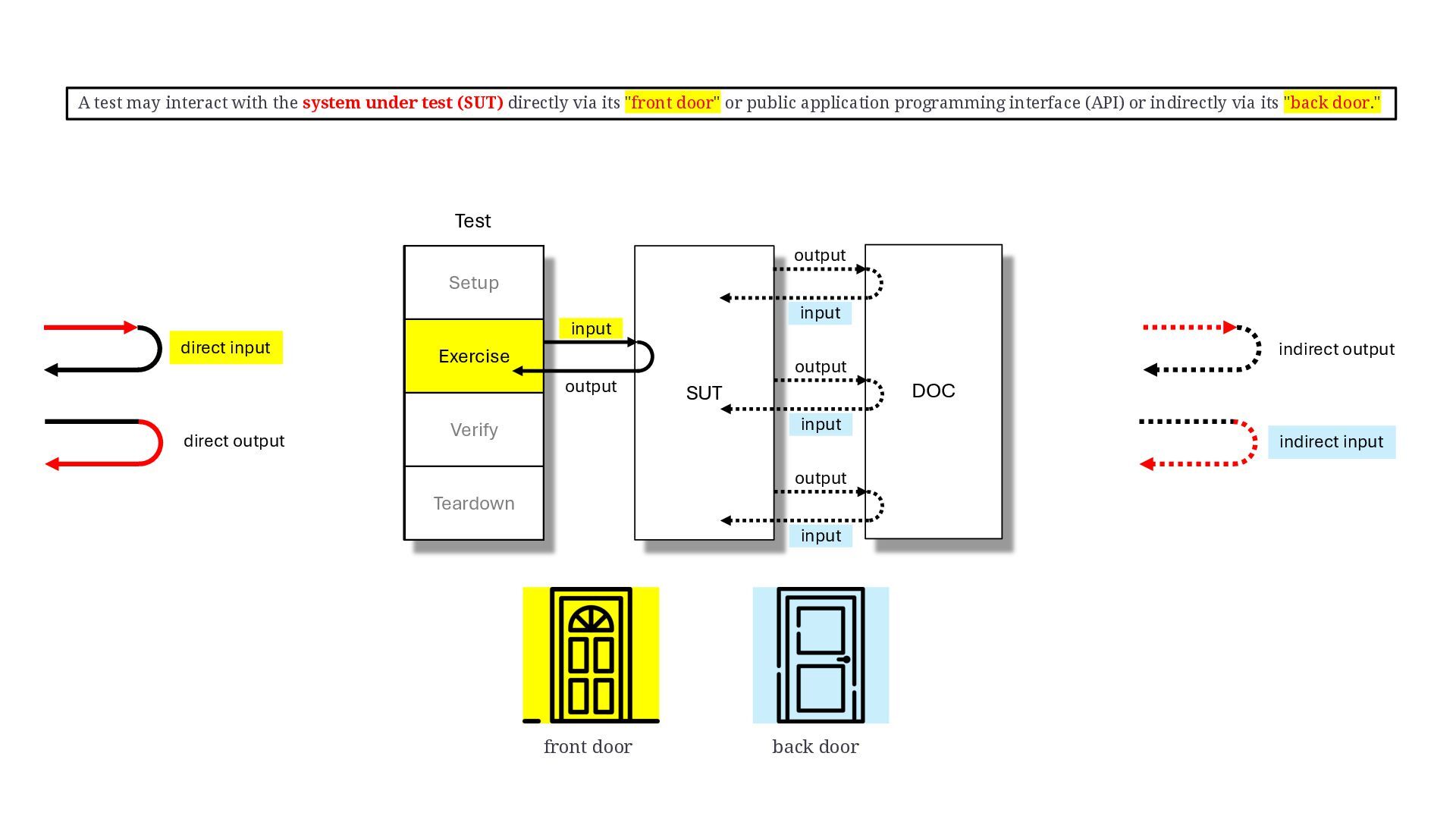
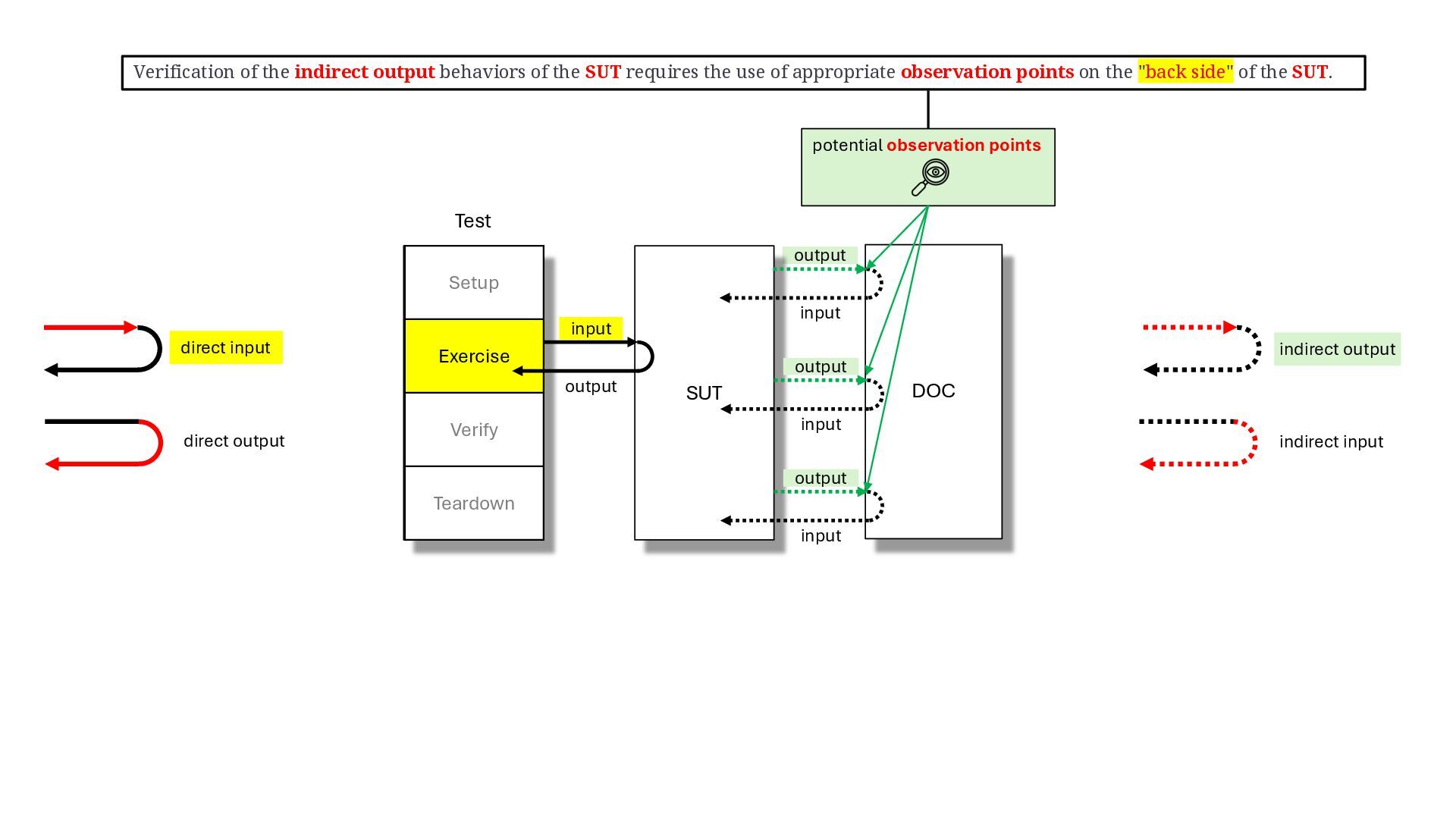
keywords: test double, xUnit test patterns, test stub, test spy, mock object, fake object, dummy object, indirect input, indirect output, control point, observation point, front door, back door, state verification, behaviour verification, responder, saboteur, stunt double, george meszaros, test double patterns
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
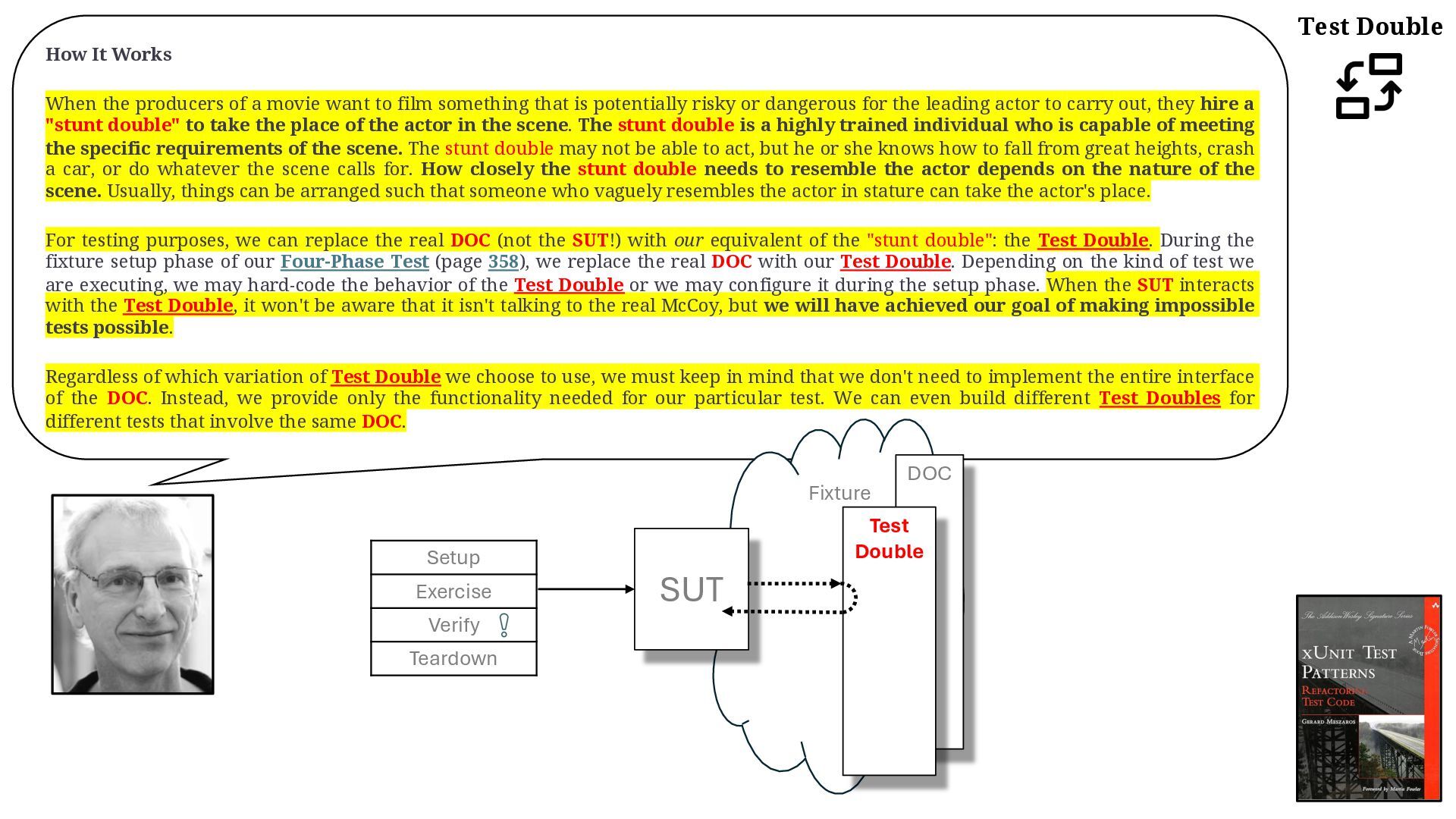{kind=link}
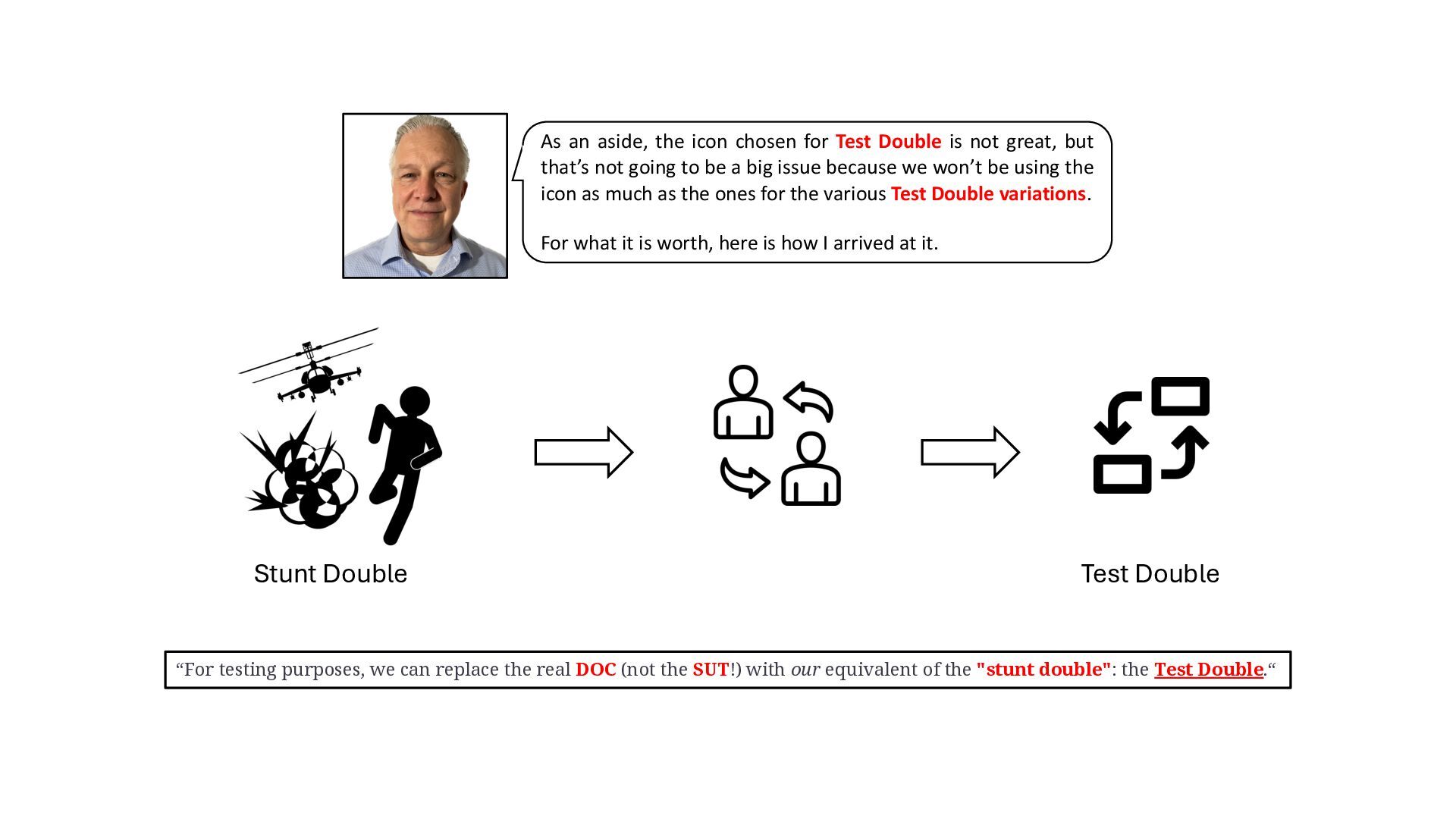{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
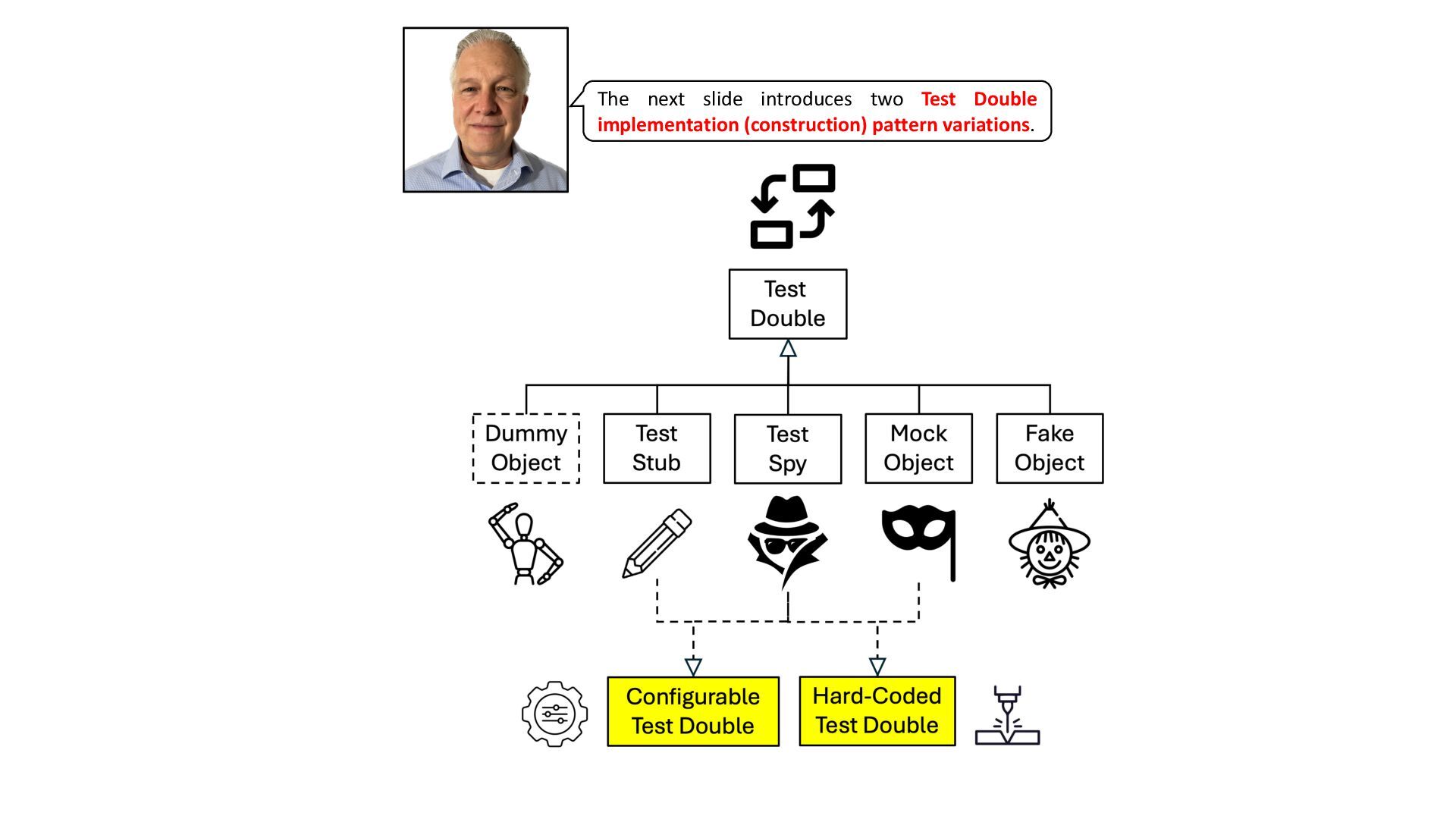{kind=link}
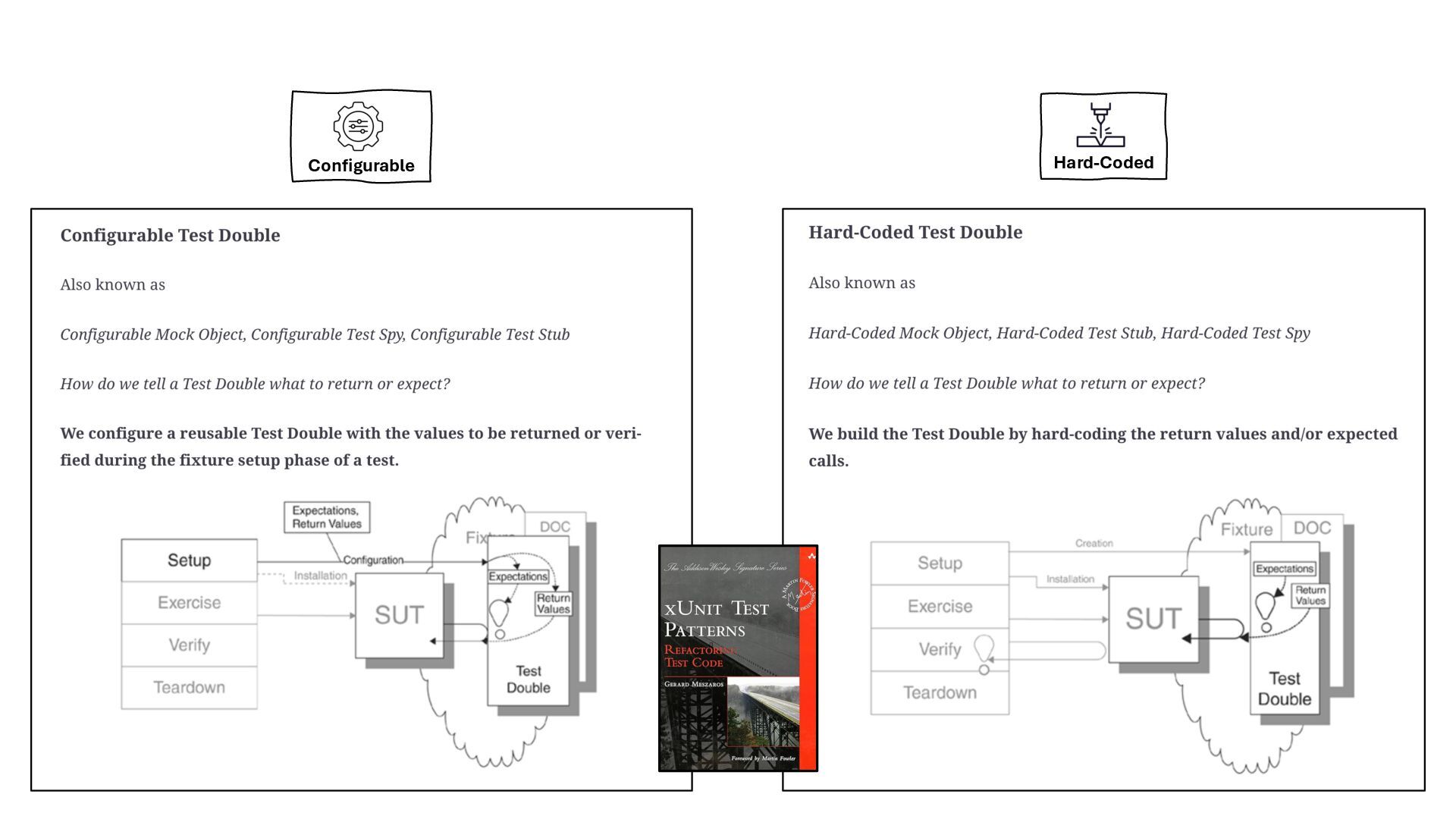{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
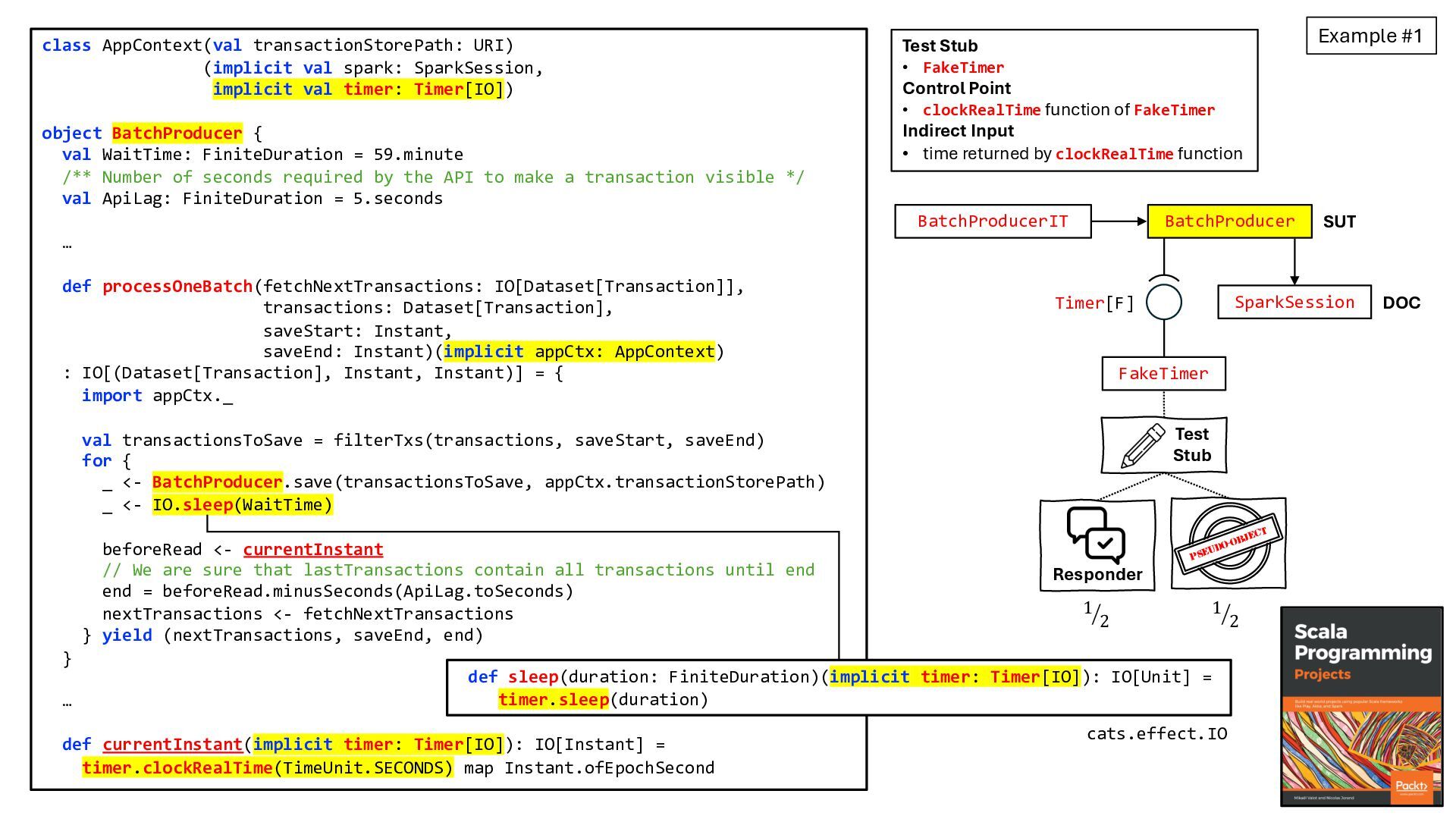
![Example #1 DOC SparkSession Timer[IO] BatchProducer SUT Timer[F] DOC DOC](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_44.jpg){kind=link}
{kind=link}
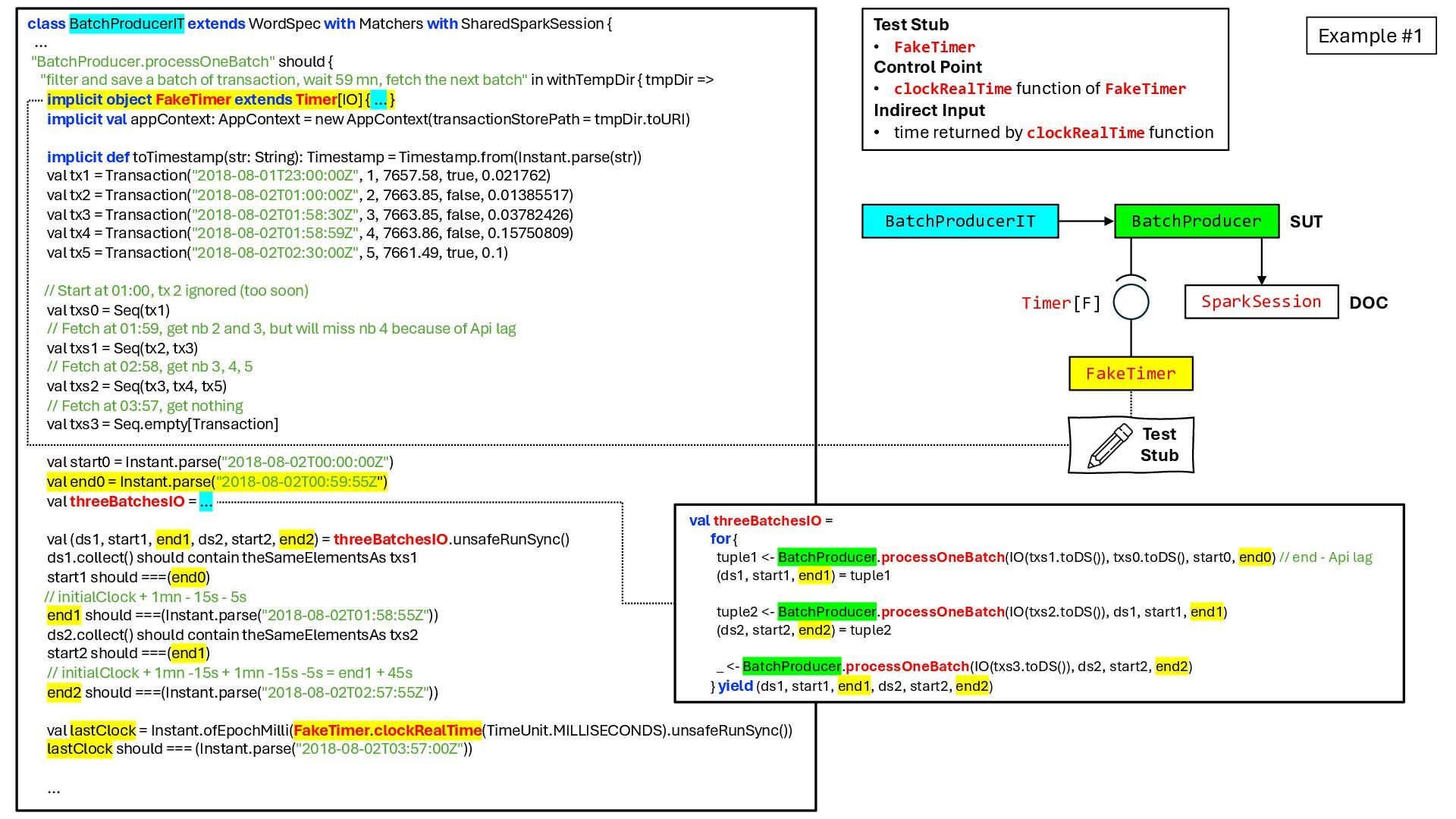
![implicit object FakeTimer extends Timer[IO] { private var clockRealTimeInMillis: Long](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
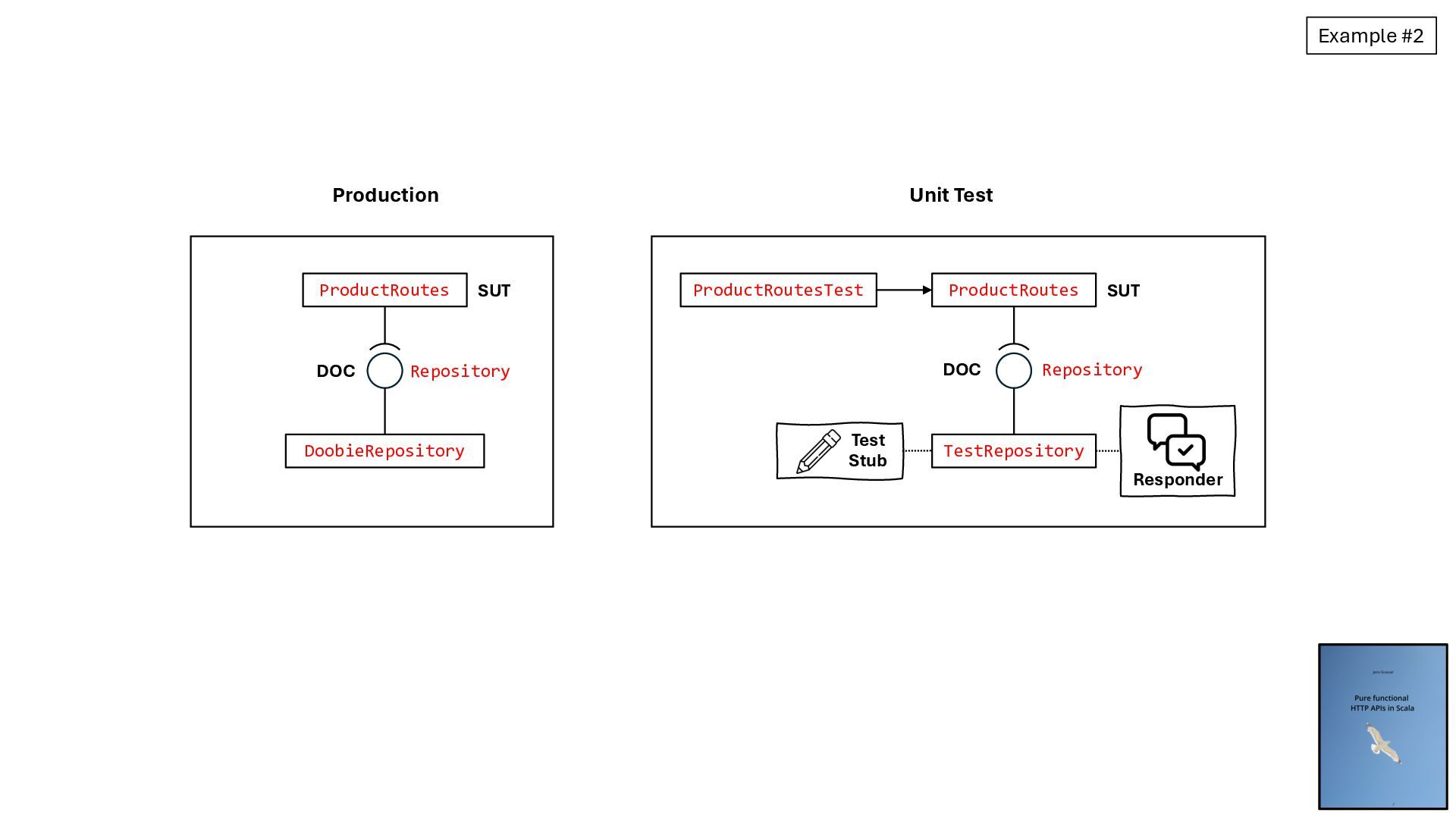{kind=link}
![final class ProductRoutes[F[_]: Sync](repo: Repository[F]) extends Http4sDsl[F] { implicit def](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_50.jpg){kind=link}
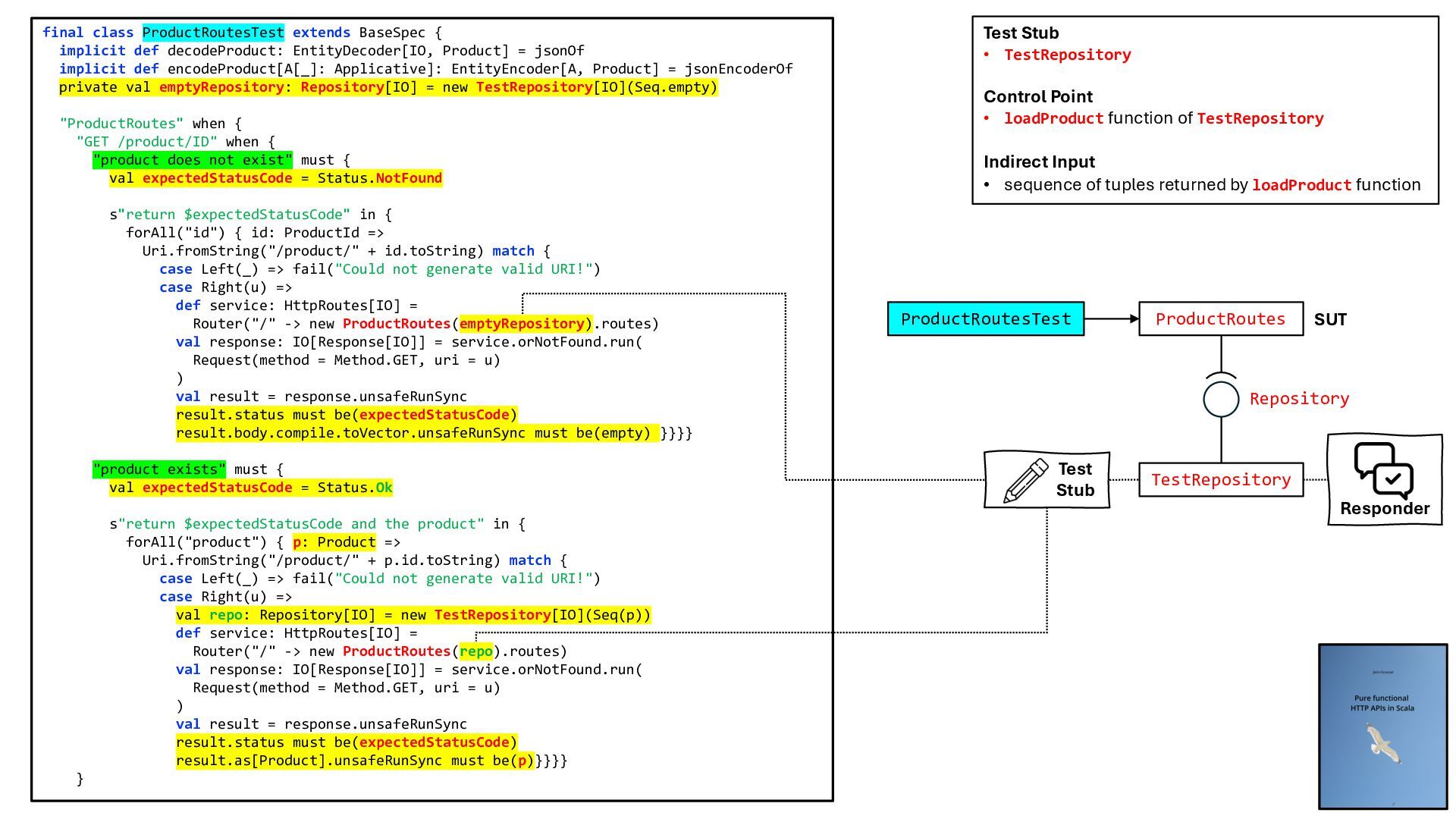{kind=link}
{kind=link}
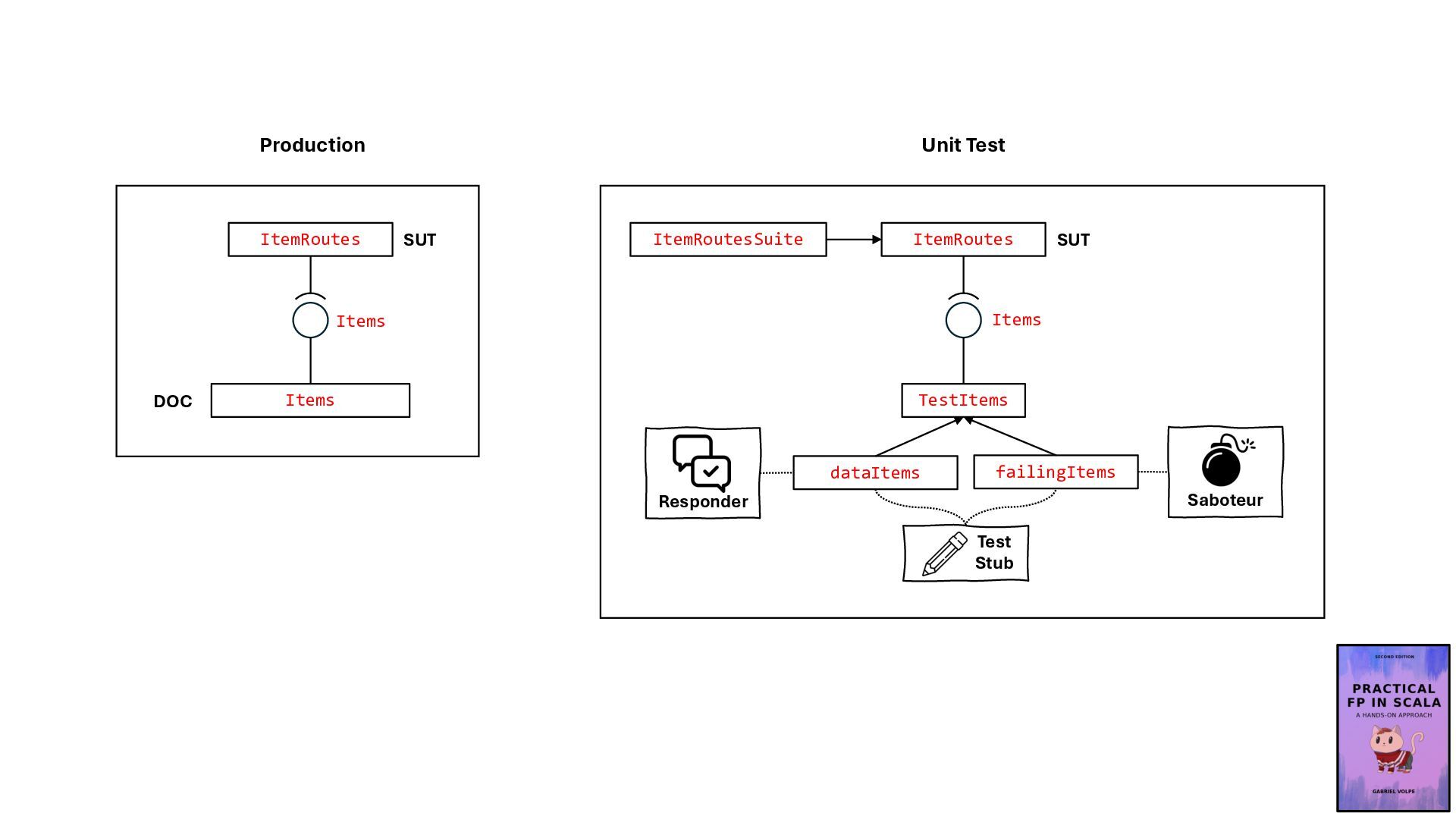{kind=link}
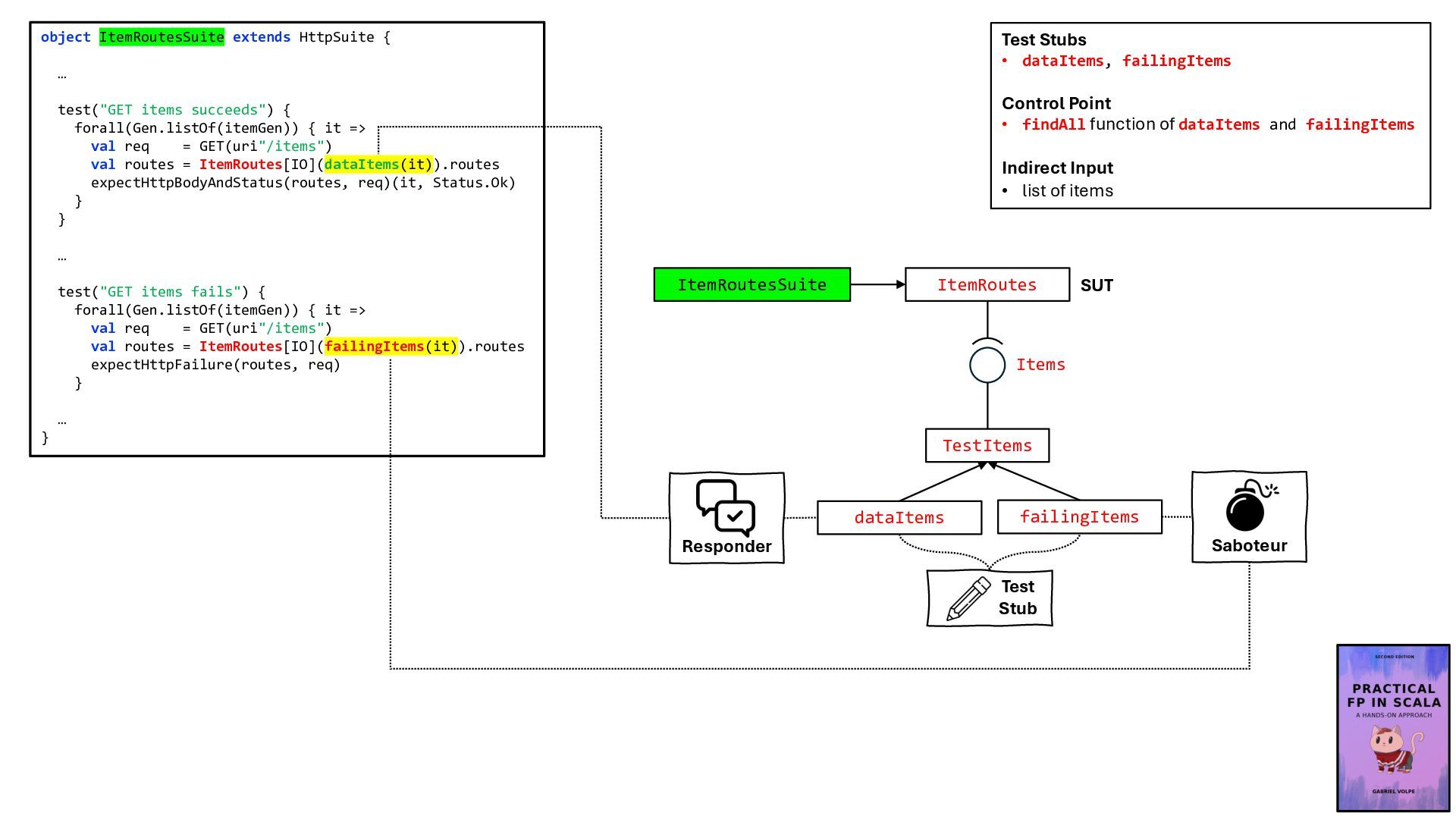
![def dataItems(items: List[Item]) = new TestItems { override def findAll:](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
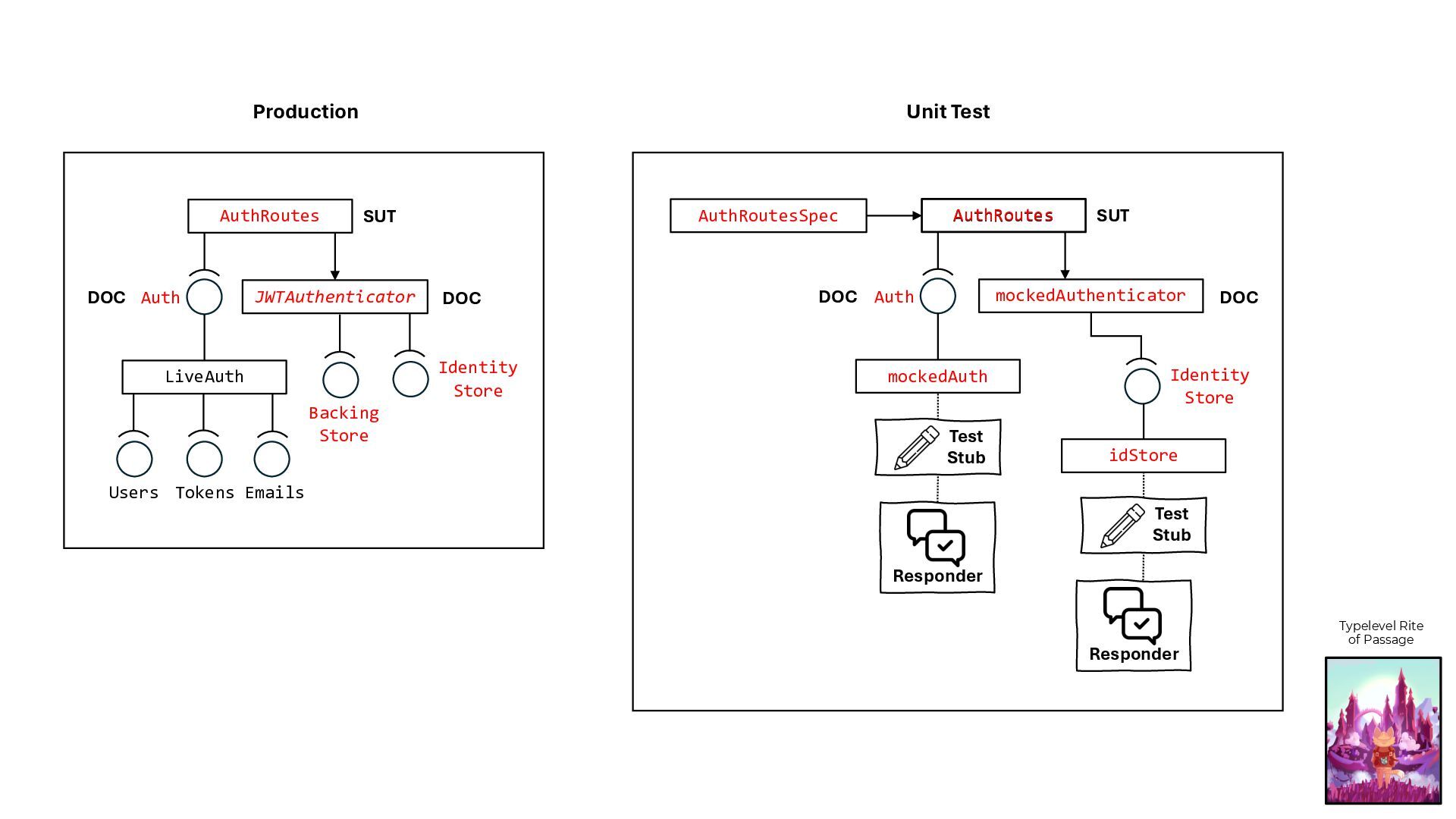
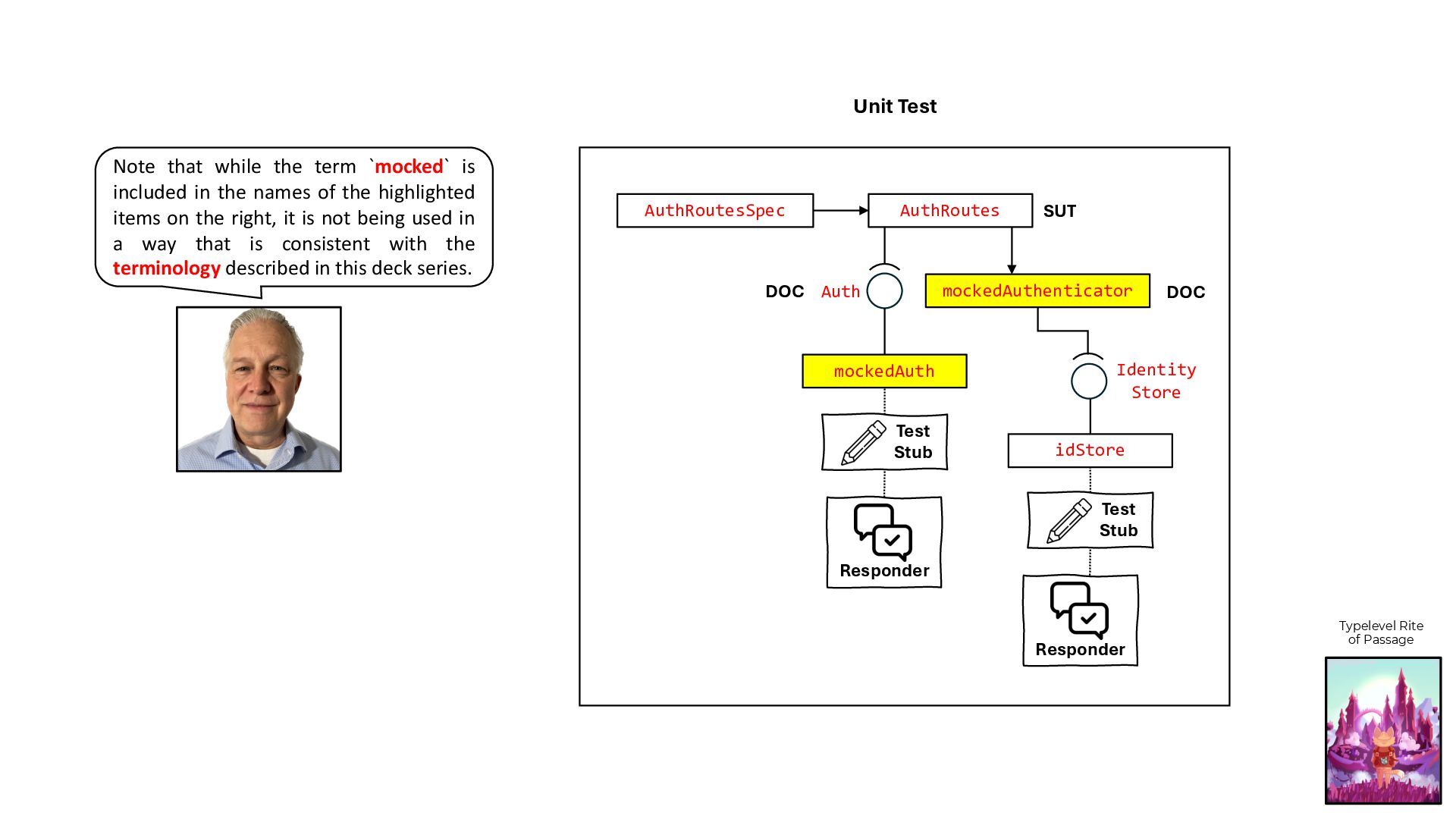
![type Authenticator[F[_]] = JWTAuthenticator[F, String, User, Crypto] class AuthRoutes[F[_]: Concurrent:](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_59.jpg){kind=link}
![val mockedAuth: Auth[IO] = probedAuth(None) def probedAuth(maybeRefEmailToTokenMap: Option[Ref[IO, Map[String, String]]]):](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_60.jpg){kind=link}
![class AuthRoutesSpec extends AsyncFreeSpec with AsyncIOSpec with Matchers with Http4sDsl[IO]](https://files.speakerdeck.com/presentations/5abff31400a44d95b10a10961e591728/slide_61.jpg){kind=link}
{kind=link}