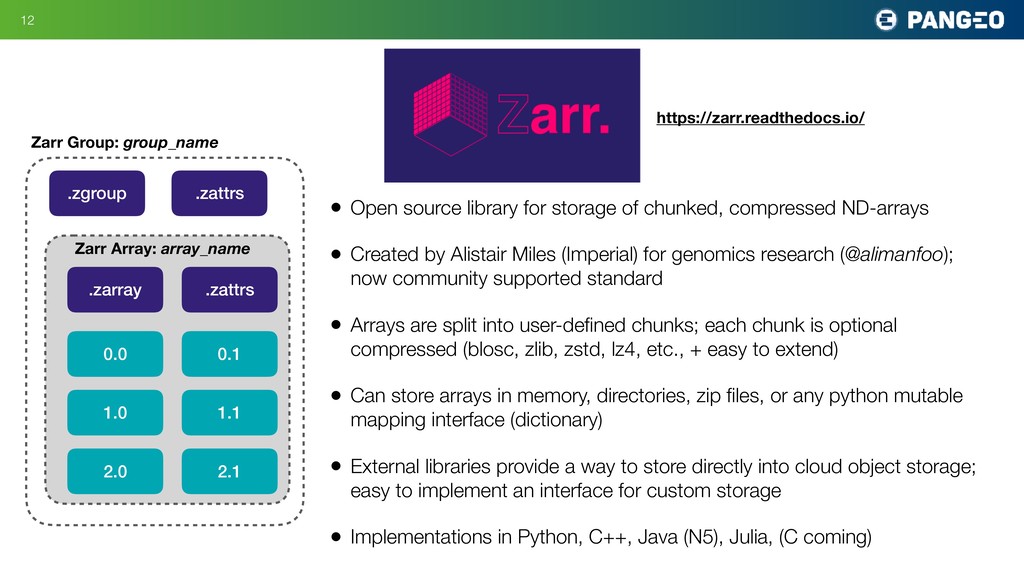
r R d ata f r o m pa n g e o c l o u d e n v i r o n m e n t s gcsmap = gcsfs.mapping.GCSMap('pangeo-data/dataset-duacs-rep-global-merged-allsat-phy-l4-v3-alt') ds = xr.open_zarr(gcsmap) <xarray.Dataset> Dimensions: (latitude: 720, longitude: 1440, nv: 2, time: 8901) Coordinates: crs int32 ... lat_bnds (time, latitude, nv) float32 dask.array<shape=(8901, 720, 2), chunksize=(5, 720, 2)> * latitude (latitude) float32 -89.875 -89.625 -89.375 -89.125 -88.875 ... lon_bnds (longitude, nv) float32 dask.array<shape=(1440, 2), chunksize=(1440, 2)> * longitude (longitude) float32 0.125 0.375 0.625 0.875 1.125 1.375 1.625 ... * nv (nv) int32 0 1 * time (time) datetime64[ns] 1993-01-01 1993-01-02 1993-01-03 ... Data variables: adt (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> err (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> sla (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> ugos (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> ugosa (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> vgos (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> vgosa (time, latitude, longitude) float64 dask.array<shape=(8901, 720, 1440), chunksize=(5, 720, 1440)> Attributes: Conventions: CF-1.6 Metadata_Conventions: Unidata Dataset Discovery v1.0 cdm_data_type: Grid comment: Sea Surface Height measured by Altimetry... contact:
[email protected] creator_email:
[email protected] creator_name: CMEMS - Sea Level Thematic Assembly Center creator_url: http://marine.copernicus.eu date_created: 2014-02-26T16:09:13Z date_issued: 2014-01-06T00:00:00Z date_modified: 2015-11-10T19:42:51Z
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}